Carregar apresentação
A apresentação está carregando. Por favor, espere

1
O Servidor Web Distribuído da Google
Os segredos da Google revelados… César Salgado Fernando Teles Leandro Leite Tiago Camolesi

2
Motivação Evolução dos aplicativos web Anos 90 1999 ~ 2003 2004 ~ 2007
Páginas em sua grande maioria estáticas Pouco volume de conteúdo 1999 ~ 2003 Transição para páginas dinâmicas Surgimento de conteúdo gerado por usuários 2004 ~ 2007 Redes sociais Serviços mais complexos Enfoque a conteúdo gerado por usuários

3
Motivação Evolução dos aplicativos web 2007 ~ Presente
Ubiqüidade de conteúdo gerado por usuários Altíssimo volume de dados Dados pouco estruturados Tentativa de explorar os dados Mineração de dados em bancos de dados Web mining Análise de opinião Marketing direcionado Agregação

4
Motivação Evolução dos aplicativos web Presente Boom de startups
Tentativas bem sucedidas chegam a 50 milhões de US$ nos dois primeiros anos. Serviços inteligentes Cloud computing Amazon EC2 Google AppEngine Proliferação de smartphones Altíssimo volume de dados – ”Big Data” Dados, em geral, pouco estruturados De centenas de TB a dezenas de PB

5
Motivação Exemplos de startups: Tineye.com : Busca reversa de imagens
Usuário envia uma imagem – ou pedaço de imagem – e o serviço encontra as páginas onde está hospedada twittersentiment.appspot.com Mineração de opinião realizada sobre o twitter

6
Motivação Como processar tanta informação ?
Clusters de centenas ~ milhares de máquinas Cloud Computing Ferramentas de alto desempenho Para bancos relacionais: Memcached MySQL Drizzle NoSQL MongoDB CouchDB Apache Cassandra Hadoop

7
Google - Hardware Segredo industrial
Cerca de 12 datacenters de grande porte Estimativa de servidores por datacenter Uso de computadores x86 comuns Baixo custo/benefício para utilização de servidores de alta confiabilidade

8
BigTable Sistema distribuído de armazenamento de dados estruturados
Objetivos: Escalabilidade: Petabytes de dados Centenas de milhares de computadores Alto Desempenho Alta Disponibilidade

9
BigTable Usado no back-end de: Indexação e busca Google Maps
Google Earth Google Finance Google AppEngine

10
BigTable - Estrutura NoSQL Orientado a pares (chave,valor)
Estrutura geral de uma grande tabela Linhas Chaves do tipo string de até 64KB Ordem Lexicográfica Permite explorar localidade dos dados maps.google.com <=> com.google.maps Famílias de Colunas Conjunto ilimitado de colunas Idealmente até 100 por linha Funcionam como um mapa chave=>valor

11
BigTable - Estrutura Exemplo:

12
Big Table – Exemplo // Open the table
Table *T = OpenOrDie("/bigtable/web/webtable"); // Write a new anchor and delete an old anchor RowMutation r1(T, "com.cnn.www"); r1.Set("anchor: "CNN"); r1.Delete("anchor: Operation op; Apply(&op, &r1); Scanner scanner(T); ScanStream *stream; stream = scanner.FetchColumnFamily("anchor"); stream->SetReturnAllVersions(); scanner.Lookup("com.cnn.www"); for (; !stream->Done(); stream->Next()){ printf("%s %s %lld %s\n", scanner.RowName(), stream->ColumnName(), stream->MicroTimestamp(), stream->Value()); }
; // Write a new anchor and delete an old anchor. RowMutation r1(T, com.cnn.www ); r1.Set( anchor: , CNN ); r1.Delete( anchor: ); Operation op; Apply(&op, &r1); Scanner scanner(T); ScanStream *stream; stream = scanner.FetchColumnFamily( anchor ); stream->SetReturnAllVersions(); scanner.Lookup( com.cnn.www ); for (; !stream->Done(); stream->Next()){ printf( %s %s %lld %s\n , scanner.RowName(), stream->ColumnName(), stream->MicroTimestamp(), stream->Value()); }")
13
BigTable – Funcionamento
Cada coluna armazena dados com timestamps Diversas versões das colunas são armazenadas Cliente especifica como armazenar versões antigas Últimas N versões Versões com até 7 dias de idade Controle de acesso realizado a nível de família de colunas

14
BigTable – Implementação
Construído sobre diversos outros aplicativos: GFS Armazenamento de logs e dados Chubby Controle de concorrência Alta disponibilidade: 5 cópias ativas Controle de consistência: Algoritmo Paxos Downtime médio: % SSTable Formato de armazenamento de chave<=>valor

15
BigTable – Implementação

16
Google File System Sistema distribuído e escalável de arquivos, para aplicações com consultas intensas a grandes quantidades de dados. Os arquivos são replicados, fornecendo tolerância a falhas e performance para um grande número de usuários.

17
Google File System Um nó Master e vários Chunkservers.
Chunkservers armazenam os dados, e são replicados na rede no mínimo três vezes. Master armazena as localizações dos Chunks e os arquivos que eles contêm, suas cópias, quais processos estão lendo ou gravando em cada um. Recebe periodicamente updates (“Heart Beats”) de cada Chunk.
 de cada Chunk.")
18
Google File System Arquitetura do GFS

19
Google File System Atende às necessidades de armazenamento da Google.
Amplamente adotado como plataforma de armazenamento para a geração e processamento de dados de seus serviços. O maior cluster oferece centenas de TeraBytes de armazenamento através de milhares de disco em mais de mil máquinas, e é acessado simultaneamente por centenas de clientes.

20
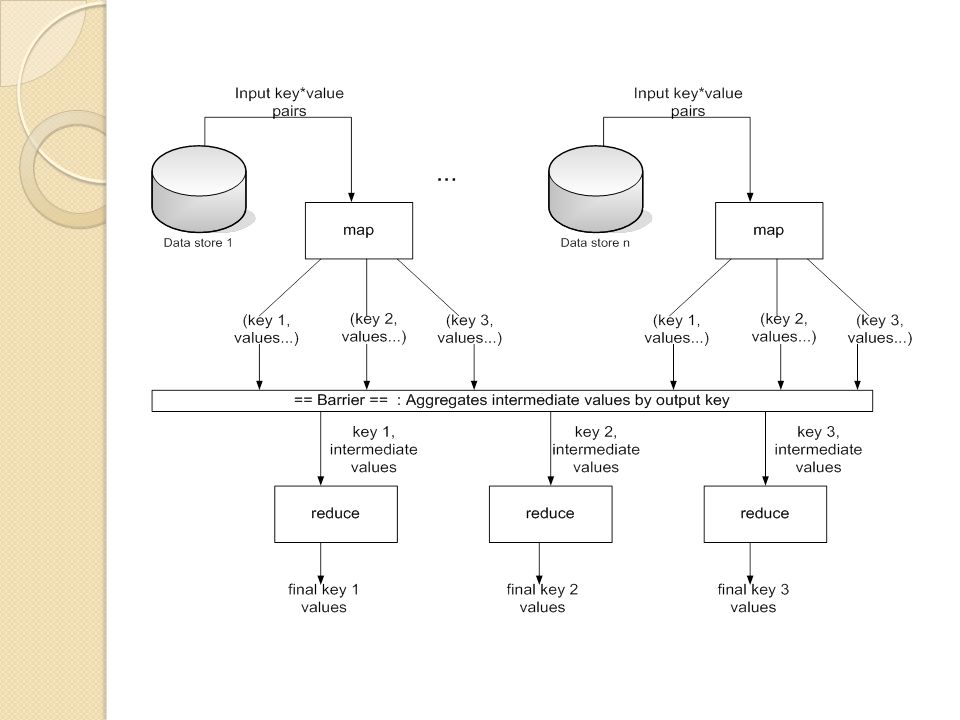
Um modelo de programação para processar dados distribuídos
MapReduce Um modelo de programação para processar dados distribuídos

21
Por que Distribuir? Problemas na Google são muito grandes
Exemplo: 20 bilhões de páginas x 20KB = terabytes Um computador pode ler MB/seg do disco 4 meses para ler a web

22
Se distribuir? Em 1000 máquinas < 3 horas.

23
Exemplo de Processamento
Contar a ocorrência de palavras em um grande conjunto de documentos. Um possível problema de processamento distribuído Contruir um histograma As máquinas quebram todo tempo, pois o número delas é muito grande. - Programador tem que fazer: Código para particionar os dados de entrada Código para escalonar a execução dos trabalhos num conjunto de máquinas Saber o estado de cada máquina para saber se pode enviar um trabalho Código para comunicação entre as máquinas Programar código para tolerar falhas Se recuperar de falhas Código para monitorar a execução Debugging E pior de tudo: repetir esse mesmo trabalho para toda nova aplicação

24
Que tal uma biblioteca para facilitar?
Esconder a complexidade do programador E se existisse uma biblioteca para sua linguagem de programação, onde você não precisasse lidar com as complexidade de sistema distribuídos em aplicações onde envolvem o processamento de grande quantidade de dados. Bem, ela existe e se chama MapReduce

25
O que é MapReduce? Interface ou Modelo de Programação introduzido pela Google desenvolvida em 2003 Criado por Jeffrey Dean e Sanjay Ghemawat

26
O que MapReduce faz? MapReduce runtime library provê:
Paralelização automática Balanceamento de Carga Otimizações para rede e para traferências no disco Tratamento de falhas de máquinas

27
Vantagens do MapReduce
Pessoas leigas conseguem fazer programas distribuídos Redução no tempo de desenvolvimento Tolerância a falhas Suporte a debugação Melhorias na biblioteca beneficiam todos os usuários - Antes cada um tinha que fazer seu código para tolerar falhas e as pessoas não iriam ter o melhor código para esse fim desenvolvido até o momento na google. - Máquinas na google quebram bastante

28
Como especificar um problema para o MapReduce?
Usuário determina alguns parâmetros Define como a entrada será inserida na função map Usuário cria duas funções map reduce MapReduce run-time library faz praticamente todo o resto Como fazer ele entender qual é o seu problema? Map reduce baseado em programação funcional tipo lisp

29
MapReduce – map e reduce
map (in_key, in_value) -> (out_key, intermediate_value) list reduce (out_key, intermediate_value list) -> out_value list
 -> (out_key, intermediate_value) list. reduce (out_key, intermediate_value list) -> out_value list.")
30
Número de Ocorrências de Palavras - Revisitado
map(String input_key, String input_value): // input_key: nome do documento // input_value: conteúdo do documento for each word w in input_value: EmitIntermediate(w, "1"); reduce(String output_key, Iterator intermediate_values): // output_key: a word // output_values: a list of counts int result = 0; for each v in intermediate_values: result += ParseInt(v); Emit(AsString(result));
: // input_key: nome do documento. // input_value: conteúdo do documento. for each word w in input_value: EmitIntermediate(w, 1 ); reduce(String output_key, Iterator intermediate_values): // output_key: a word. // output_values: a list of counts. int result = 0; for each v in intermediate_values: result += ParseInt(v); Emit(AsString(result));")
32
Resumindo Leia muito dados
Map: Transforme esses dados num conjunto de pares <chave, valor> Agrupe e ordene esses pares por suas chaves Reduce: agregue, resuma, filtre, ou transforme Escreva os resultados

33
Ordenar 1 terabyte 1800 máquinas 15 minutos em 2003
Matando 200 máquinas aumenta menos de um minuto Hoje Hadoop faz em 2 minutos

34
Tolerância a Falhas no MapReduce
Mestre pings todo worker periodicamente Qualquer tarefa map completa pelo worker que falhou se tornam elegíveis para escalonamento em outros workers Qualquer tarefa map ou reduce em progresso num worker que falhou se tornam elegíveis para escalonamento em outros workers Falha no Master? Completed map tasks are re-executed on a failure because their output is stored on the local disk(s) of the failed machine and is therefore inaccessible. Completed reduce tasks do not need to be re-executed since their output is stored in a global le system. When a map task is executed rst by worker A and then later executed by worker B (because A failed), all workers executing reduce tasks are notied of the reexecution. Any reduce task that has not already read the data from worker A will read the data from worker B. It is easy to make the master write periodic checkpoints of the master data structures described above. If the master task dies, a new copy can be started from the last checkpointed state. However, given that there is only a single master, its failure is unlikely; therefore our current implementation aborts the MapReduce computation if the master fails. Clients can check for this condition and retry the MapReduce operation if they desire.
 of the. failed machine and is therefore inaccessible. Completed. reduce tasks do not need to be re-executed since their. output is stored in a global le system. When a map task is executed rst by worker A and. then later executed by worker B (because A failed), all. workers executing reduce tasks are notied of the reexecution. Any reduce task that has not already read the. data from worker A will read the data from worker B. It is easy to make the master write periodic checkpoints. of the master data structures described above. If the master. task dies, a new copy can be started from the last. checkpointed state. However, given that there is only a. single master, its failure is unlikely; therefore our current. implementation aborts the MapReduce computation. if the master fails. Clients can check for this condition. and retry the MapReduce operation if they desire.")
35
Protocol Buffers Criado de novo por Jeffrey Dean e Sanjay Ghemawat em 2000

36
O que é Protocol Buffer? Formato de serialização e linguagem de descrição de interface Sua implementação oferece um mecanismo automático de serializar dados Protocol buffers are a flexible, efficient, automated mechanism for serializing structured data – think XML, but smaller, faster, and simpler. You define how you want your data to be structured once, then you can use special generated source code to easily write and read your structured data to and from a variety of data streams and using a variety of languages. You can even update your data structure without breaking deployed programs that are compiled against the "old" format.

37
Vantagens do Protocol Buffer
Boa alternativa ao XML. Menor Mais rápido Menos ambíguo Mais simples? Assim como XML é: Independente da linguagem Independente da plataforma are simpler are 3 to 10 times smaller are 20 to 100 times faster are less ambiguous generate data access classes that are easier to use programmatically nano seconds 5,000-10,000 nano seconds

38
Como funciona Protocol Buffer?
Crie arquivos .proto para especificar a estrutura que quer serializar You specify how you want the information you're serializing to be structured by defining protocol buffer message types in .proto files

39
Exemplo arquivo .proto As you can see, the message format is simple – each message type has one or more uniquely numbered fields, and each field has a name and a value type, where value types can be numbers (integer or floating-point), booleans, strings, raw bytes, or even (as in the example above) other protocol buffer message types, allowing you to structure your data hierarchically. You can specify optional fields, required fields, and repeated fields.
, booleans, strings, raw bytes, or even (as in the example above) other protocol buffer message types, allowing you to structure your data hierarchically. You can specify optional fields, required fields, and repeated fields.")
40
Como funciona Protocol Buffer?
Compile o arquivo .proto Gera data access classes Provê accessors e métodos para fazer o parse e serializar para/de bytes Nesse caso gerou classe chamada Person

41
Como funciona Protocol Buffer?
Se estiver programando em C++ Você pode então usar essa classe na sua aplicação para criar, serializar e recuperar as mensagens

42
Criar, escrever e recuperar dados em com Protocol Buffer

43
Processamento de grandes massas de dados de forma distribuída
Hadoop Processamento de grandes massas de dados de forma distribuída

44
O que é o Hadoop? Uma estrutura lógica de programação para o processamento de dados distribuídos. É o núcleo da redução de dados para alguns dos maiores mecanismos de pesquisa. Abstração que une códigos comuns entre vários projetos de software provendo a funcionalidade de processar grande quantidades de dados. Programado em Linguagem Java.

45
História do Hadoop Criado por Doug Cutting.
A idéia surgiu inicialmente com o Nutch, que tinha os mesmos objetivos (2002). Divulgação do artigo que descrevia a arquitetura do sistema de arquivos da Google: o Google FS. Criação do NDFS (Nutch Distributed Filesystem)
. Divulgação do artigo que descrevia a arquitetura do sistema de arquivos da Google: o Google FS. Criação do NDFS (Nutch Distributed Filesystem)")
46
História do Hadoop Google publica o artigo que descrevia o MapReduce.
Implementação open-source do MapReduce funcionando em conjunto como NDFS (2005). Estes projetos foram fundidos em um novo sub projeto do Lucene chamado Hadoop (2006). Doug Cutting entrou para o Yahoo!. Hadoop se torna um sistema completo para trabalhar na escala da web.
. Estes projetos foram fundidos em um novo sub projeto do Lucene chamado Hadoop (2006). Doug Cutting entrou para o Yahoo!. Hadoop se torna um sistema completo para trabalhar na escala da web.")
47
O Projeto Hadoop Projeto independente dentro da hierarquia de projetos da fundação Apache. Os componentes mais conhecidos do Hadoop são seu sistemas de arquivos distribuídos (HDFS) e o MapReduce. Adicionando valor a estrutura básica muitos outros projetos surgiram. Estes projetos facilitam a utilização do Hadoop assim como adicionam abstrações de alto nível para facilitarem a criação de sistemas mais complexos.
 e o MapReduce. Adicionando valor a estrutura básica muitos outros projetos surgiram. Estes projetos facilitam a utilização do Hadoop assim como adicionam abstrações de alto nível para facilitarem a criação de sistemas mais complexos.")
48
Sub-projetos Hadoop Hadoop MapReduce: é um modelo de programação e framework para criação de aplicações que rapidamente processam vastas quantidades de dados em paralelo através de grandes clusters de computadores comuns. HDFS: Hadoop Distributed File System (HDFS) é o sistema básico de armazenamento utilizado por aplicações Hadoop. O HDFS cria réplicas de blocos de dados e que são distribuídos no cluster para permitir computações extremamente rápidas.
 é o sistema básico de armazenamento utilizado por aplicações Hadoop. O HDFS cria réplicas de blocos de dados e que são distribuídos no cluster para permitir computações extremamente rápidas.")
49
Sub-projetos Hadoop Hive: é uma infraestrutura de data warehouse construído em cima do Hadoop que provê ferramentas que facilitam a criação de relatórios e a análise de quantidades gigantescas de dados armazenados em arquivos Hadoop. Pig: é uma plataforma de processamento de dados em larga escala que possui uma linguagem de alto nível e um “compilador” que transforma scripts feitos nesta linguagem em programas MapReduce.

50
Sub-projetos Hadoop HBase: É um banco de dados NoSQL distribuído e orientado a colunas. Usa como sistema de arquivos o HDFS e permite tanto processamento de dados em batch utilizando MapReduce como query’s online. ZooKeeper: Um serviço de coordenação distribuído. O ZooKeeper fornece primitivas básicas para construção de sistemas distribuídos. Chukwa: É um sistema distribuído para coletar e analisar logs dinamicamente.

51
Mais Dados X Melhores Algorítmos
Por muito tempo o maior enfoque nas áreas de IA era desenvolver algoritmos cada vez mais poderosos para conseguir extrair o máximo dos dados disponíveis. Em geral, algoritmos mais poderosos são também mais complexos e não escalam bem para grandes quantidades de dados. Uma propriedade interessante do uso de datasets massivos é que algoritmos mais simples com mais dados conseguem um desempenho superior a algoritmos “melhores” com menos dados.

52
Mais Dados X Melhores Algorítmos
Um exemplo disto é o Google Translate. Muitos pensam que o grande sucesso do Google se deve aos seus brilhantes algoritmos... Boa parte da inovação trazida pelo PageRank se deve ao fato de ele utilizar dados que até então não estavam sendo usados por outros buscadores: os hiperlinks são uma fonte de informação importante para medir a popularidade de uma página o texto âncora dos hiperlinks é importante para definir o assunto da página para qual o link aponta

53
Mais Dados X Melhores Algorítmos
A utilização de volumes gigantes de dados não oferece maior desempenho sempre. Existe, em muitos casos, um limite onde o tamanho da base de dados não mais possuirá grande influência sobre o desempenho do algoritmo.

54
Mais Dados X Melhores Algorítmos
Grandes oportunidades para o processamento de grandes volumes de dados estão se abrindo graças aos crescentes avanços da computação distribuída. O projeto Hadoop junto com as plataformas de computação em nuvem, permitem hoje que várias empresas possam utilizar um volume computacional grande a custos razoáveis, algo inimaginável a 4 anos atrás... Hoje eles são utilizados pelas maiores empresas web do mundo e estão migrando rapidamente para empresas de outros setores (Facebook, Last.fm, Twitter e até mesmo IBM e Microsoft ).
.")
55
Cassandra Sistema de gerenciamento de banco de dados de código aberto.
Criado pelo Facebook, teve seu código aberto em Hoje é desenvolvido pela Apache. Usado por Digg, Facebook, Twitter, Reddit, Rackspace, Cloudkick, Cisco e mais companhias que possuem grandes quantidades de dados. O maior cluster possui 100 TeraBytes de dados em mais de 150 máquinas.

56
Cassandra Tolerante a falha: Dados replicados em múltiplos nós.
Descentralizado: Cada nó é idêntico, não há gargalos ou pontos de falha. Elástico: Leitura e escrita aumentam conforme novas máquinas são adicionadas, sem interrupção nas aplicações. Durável: Indicado quando não se pode perder dados, mesmo quando um centro de dados cai.

57
Cassandra NoSQL Famílias de colunas são fixadas quando o banco de dados é criado. O sistema gerencia essas famílias e colunas podem ser adicionadas à elas a qualquer momento. Caso do site Digg.

58
Perspectivas de mercado
Busca por profissionais com conhecimento de Hadoop e Cloud Computing em crescimento acentuado Poucos desenvolvedores qualificados Início do boom há cerca de 2 anos Altos salários

59
Perspectivas de mercado

60
Conclusões

61
Referências BigTable labs.google.com/papers/bigtable- osdi06.pdf

62
Referências GFS

63
Referências MapReduce
ce_and_hdfs ads/2010/01/2-MapReduceAndHDFS.pdf osdi04.pdf mapreduce-minilecture/listing.html

64
Referências ProtocolBuffer
rs/docs/overview.html

65
Referências Hadoop http://hadoop.apache.org/

66
Referências Cassandra

Apresentações semelhantes