Carregar apresentação
A apresentação está carregando. Por favor, espere

1
Wladimir Araújo Tavares
Redes Neurais Wladimir Araújo Tavares

2
Características Degradação progressiva e qualidade.
Significa que a performance de um sistema baseado em rede neural diminui lenta e monotonicamente em presença de informações falsas ou ausentes. Raciocínio por Default. Capacidade de manipular e representar informações incompletas e ausentes. Generalização. Uma vez uma rede aprendendo um conceito ela é capaz de funcionar com conceitos similares que não foram aprendidos e isto sem esforço suplementar. • Raciocínio impreciso. Capacidade de representar e manipular incertezas

3
Aplicações Classificação Reconhecimento de padrões Predição de Falhas
Otimização Filtragem de ruído

4
Neurônio Biológico

5
Conceitos importantes
Axônio: responsável pela transmissão de sinais a partir do corpo celular. Em geral são compridos e apresentam poucas ramificações Dendritos: conduzem sinais para a célula; têm muitas ramificações (zonas receptivas) Sinapse: local de contato entre neurônios, onde ocorre a transmissão de impulsos nervosos de uma célula para outra Plasticidade: capacidade de adaptação de um neurônio ao ambiente. Fundamental para as redes neurais. Mecanismos de plasticidade: criação de novas conexões sinápticos; Modificação das sinapses existentes, etc.
 Sinapse: local de contato entre neurônios, onde ocorre. a transmissão de impulsos nervosos de uma célula para. outra. Plasticidade: capacidade de adaptação de um neurônio. ao ambiente. Fundamental para as redes neurais. Mecanismos de plasticidade: criação de novas conexões. sinápticos; Modificação das sinapses existentes, etc.")
6
Neurônio de McCulloch-Pitts

7
Neurônio de McCulloch-Pitts
O neurônio artificial funciona como sendo um circuito binário. A entrada do neurônio também é binária. A atividade do neurônio é tudo ou nada. O neurônio pode estar no estado ativado ou desativado.

8
Conceitos: [x1,...,xn] são os estímulos.
[w1,...,wn] são os pesos sinápticos. Σ é a integração sináptica, ou seja, a soma ponderada dos estímulos que produzem um nível de atividade do neurônio. Ѳ é o limiar. Se a atividade neural exceder o limiar a unidade produz determinada saída. f é chamada função de transferência ou função excitatória.
![Conceitos: [x1,...,xn] são os estímulos.](http://slideplayer.com.br/slide/2261325/8/images/8/Conceitos%3A+%5Bx1%2C...%2Cxn%5D+s%C3%A3o+os+est%C3%ADmulos..jpg "[w1,...,wn] são os pesos sinápticos. Σ é a integração sináptica, ou seja, a soma ponderada dos estímulos que produzem um nível de atividade do neurônio. Ѳ é o limiar. Se a atividade neural exceder o limiar a unidade produz determinada saída. f é chamada função de transferência ou função excitatória.")
9
Função de Transferência

10
Defina o neurônio McCulloch-Pitts, para representar a função booleana E para a seguinte função booleana utilizando a seguinte função de transferência: f(x)=0, x<=0 e f(x)=1, se x>0.
=0, x<=0 e f(x)=1, se x>0.")
11
Ѳ 1 w x y AND Σ Σ-Ѳ f(Σ-Ѳ) -1 2
 -1 2")
12
Interpretação Geométrica
(0,1) (1,1) (0,0) (1,0) X+Y-1=0
 (1,1) (0,0) (1,0) X+Y-1=0.")
13
Ѳ 0.5 w 1 x y AND Σ Σ-Ѳ f(Σ-Ѳ) -0.5 2 1.5
")
14
Interpretação Geométrica
(0,1) (1,1) (0,0.5) (0,0) (1,0) (0.5,0) X+Y-1=0
 (1,1) (0,0.5) (0,0) (1,0) (0.5,0) X+Y-1=0.")
15
Defina o neurônio McCulloch-Pitts, para representar a função booleana OU para a seguinte função booleana utilizando a seguinte função de transferência: f(x)=0, x<=0 e f(x)=1, se x>0.
=0, x<=0 e f(x)=1, se x>0.")
16
Ѳ W 1 x y OU Σ Σ-Ѳ f(Σ-Ѳ) 2
 2")
17
Interpretação Geométrica
(0,1) (1,1) (0,0) (1,0) X+Y=0
 (1,1) (0,0) (1,0) X+Y=0.")
18
Defina o neurônio McCulloch-Pitts, para representar a função booleana XOR para a seguinte função booleana utilizando a seguinte função de transferência: f(x)=0, x<=0 e f(x)=1, se x>0.
=0, x<=0 e f(x)=1, se x>0.")
19
Ѳ ? W 1 x y XOR Σ 2 Existe Ѳ tal que 1- Ѳ > 0 e 2- Ѳ <= 0 ?

20
Interpretação Geométrica
(0,1) (1,1) (0,1) (1,1) (0,0) (0,0) (1,0) (1,0) (0,1) (1,1) (0,1) (1,1) (0,0) (0,0) (1,0) (1,0)
 (1,1) (0,1) (1,1) (0,0) (0,0) (1,0) (1,0) (0,1) (1,1) (0,1) (1,1) (0,0) (0,0) (1,0) (1,0)")
21
Função XOR O neurônio McCulloch-Pitts consegue representar qualquer função booleana linearmente separável. Minsk e Papert (1969) escrevem artigo afirmando que o problema da separabilidade linear não poderia ser resolvido por uma rede neural do tipo perceptron.
 escrevem artigo afirmando que o problema da separabilidade linear não poderia ser resolvido por uma rede neural do tipo perceptron.")
22
Analise as duas funções booleanas abaixo e veja
se cada uma é linearmente separável.

23
Analise a seguinte função booleana com três entradas e diga se ela é linearmente separável.
X Y Z FB1 FB2 FB3 1

24
Aprendizagem Em 1949, o biólogo Hebb propôs um princípio
pelo qual o aprendizado em sistemas neurais complexos (biológicos) poderia ser reduzido a um processo puramente local, em que a intensidade das conexões sinápticas é alterada apenas em função dos erros detectáveis localmente.
 poderia ser reduzido a. um processo puramente local, em que a. intensidade das conexões sinápticas é alterada. apenas em função dos erros detectáveis. localmente.")
25
Hipótese de Hebb Baseada na hipótese proposta por Hebb (um neuropsicólogo) de que a probabilidade de um neurónio disparar esta correlacionada com a possibilidade de este neurónio levar os outros neurónios que estão ligados a si a dispararem também. Quando isto acontece (um neurónio dispara e leva aqueles que estão ligados a dispararem também) o peso entre eles será fortalecido (aumentado).
 de que a probabilidade de um neurónio disparar esta correlacionada com a possibilidade de este neurónio levar os outros neurónios que estão ligados a si a dispararem também. Quando isto acontece (um neurónio dispara e leva aqueles que estão ligados a dispararem também) o peso entre eles será fortalecido (aumentado).")
26
O conhecimento em um RNA(Rede Neural Artificial) está distribuído por toda a rede, ou seja, nenhum neurônio retém em si todo o conhecimento, mas a sua operação em conjunto permite às RNAS resolver problemas complexos. Exemplo : Formigas.

27
Regra Delta

28
Algoritmo de Aprendizagem
Inicialize os pesos e o limiar com 0. Para cada padrão de entrada e a saída correspondente aplique a regra delta para atualizar os pesos sinápticos até que o resultado esteja satisfatório

29
Treine um neurônio McCulloch-Pitts para aprender a função booleana OR.
x y OR 1

30
w1 X w2 saída Y Ѳ bias

31
Inicialize os pesos e o limiar com 0.
η = 1 X saída Y bias

32
Para a entrada (0,1), a saída desejada deve ser 1.
Δw2 = 1*(1-0)*1 = 1 w2 = = 1. X 0*0 + 0*1 – 0 = 0 Y bias
*1 = 1. w2 = = 1. X. 0*0 + 0*1 – 0 = 0. Y. bias.")
33
Para a entrada (1,0), a saída desejada deve ser 1.
Δw1 = 1*(1-0)*1 = 1 w1 = = 1. X 1 1*0 + 0*1 – 0 = 0 Y bias
*1 = 1. w1 = = 1. X. 1. 1*0 + 0*1 – 0 = 0. Y. bias.")
34
Para todas as entradas, o ajuste do peso sináptico obtido produz o resultado
desejado. 1 X 1 saída Y bias

35
Treine um neurônio McCulloch-Pitts para aprender a função booleana AND.
x y AND 1

36
w1 X w2 saída Y Ѳ bias

37
Inicialize os pesos e o limiar com 0.
η = 1 X saída Y bias

38
Para a entrada (1,1), a saída desejada deve ser 1.
Δw1 = 1*(1-0)*1 = 1 w1 = = 1. X 1*0 + 1*0 – 0 = 0 Y bias
*1 = 1. w1 = = 1. X. 1*0 + 1*0 – 0 = 0. Y. bias.")
39
Para a entrada (1,0), a saída desejada deve ser 0.
ΔѲ = 1*(-1)*(0-1) = 1 Ѳ = = 1. 1 X 1*1 + 1*0 – 0 = 1 Y bias
*(0-1) = 1. Ѳ = = X. 1*1 + 1*0 – 0 = 1. Y. bias.")
40
Para a entrada (1,1), a saída desejada deve ser 1.
Δw2 = 1*(1)*(1-0) = 1 w2 = = 1. 1 X 1*1 + 1*0 – 1 = 0 Y bias 1
*(1-0) = 1. w2 = = X. 1*1 + 1*0 – 1 = 0. Y. bias. 1.")
41
Para todas as entradas, o ajuste do peso sináptico obtido produz o resultado
desejado. O neurônio está treinado corretamente. 1 X 1 X+Y-1 Y bias 1

42
Regra Delta Pode-se provar que esta regra converge em número finito de passos quando: Os dados de treinamento são linearmente separáveis. η é suficientemente pequeno. Quando os dados de treinamento não são linearmente separáveis falha em convergi.

43
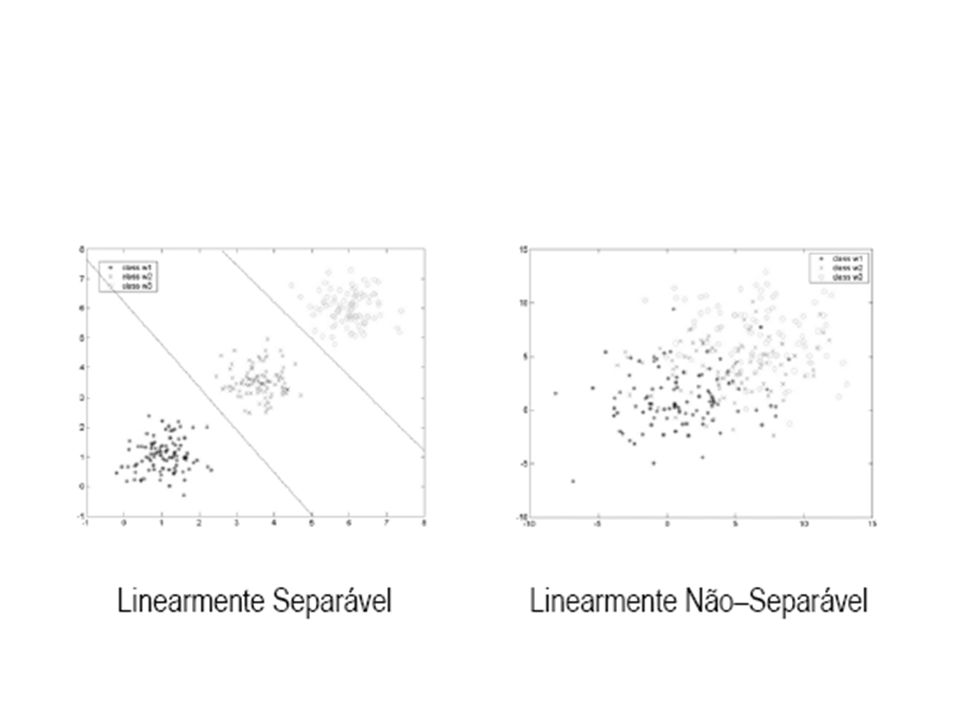
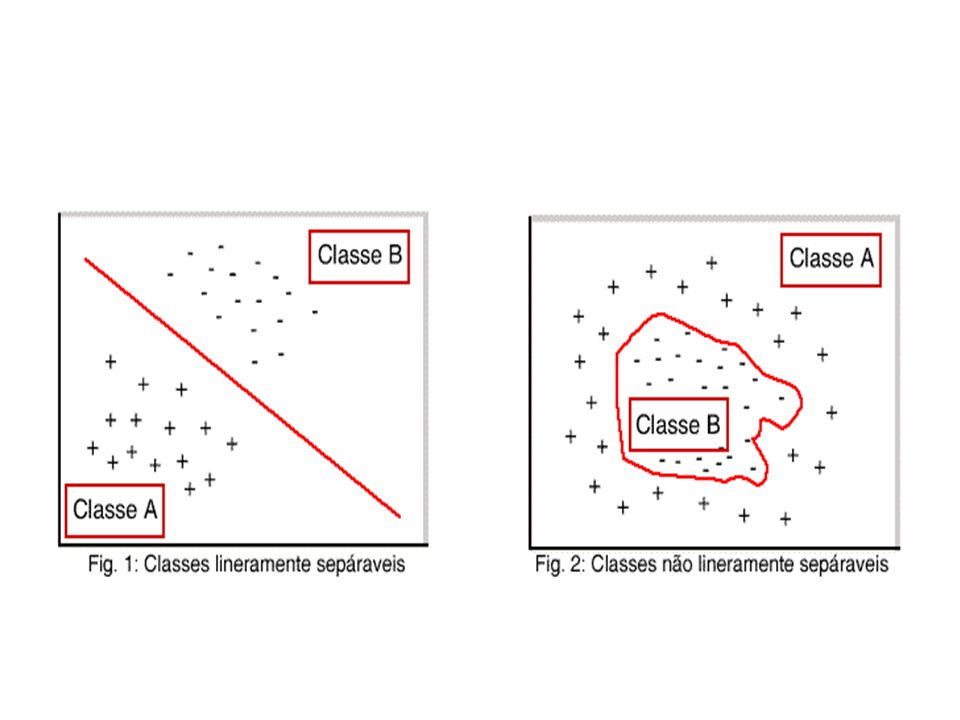
Modelo Perceptron O Perceptron, proposto por Rosenblatt, é composto pelo neurônio de McCulloch-Pitts, com Função de Limiar, e Aprendizado Supervisionado. Sua arquitetura consiste na entrada e uma camada de saída. A limitação desta Rede Neural se encontra na reduzida gama de problemas que consegue tratar: classificação de conjuntos linearmente separáveis.

44
O algoritmo de aprendizagem converge em um número finito de passos que classifica corretamente um conjunto de treinamento linearmente separável. A superfície de decisão(curva de separação) forma um hiperplano, ou seja, para um dos lados está uma classe e para o outro lado está a outra classe.
 forma um hiperplano, ou seja, para um dos lados está uma classe e para o outro lado está a outra classe.")
45
Superfície de Decisão Podemos “ver” o perceptron como uma
superfície de separação em um espaço N-dimensional de instâncias. Um único perceptron consegue separar somente conjuntos de exemplo linearmente separáveis.

48
Variáveis e Parâmetros:
X(n) = vetor de entrada (m+1)-por-1; W(n) = vetor de pesos (m+1)-por-1; b(n) = bias; y(n) = resposta real; d(n) = resposta desejada; e(n) = erro na saída da unidade; h = taxa de aprendizagem, uma constante positiva entre 0 e 1; n = contador dos passos do algoritmo.
 = vetor de entrada (m+1)-por-1; W(n) = vetor de pesos (m+1)-por-1; b(n) = bias; y(n) = resposta real; d(n) = resposta desejada; e(n) = erro na saída da unidade; h = taxa de aprendizagem, uma constante positiva. entre 0 e 1; n = contador dos passos do algoritmo.")
49
Funções Linearmente Separáveis

50
1 - Inicialização: Inicializar os valores do vetor w e da taxa de aprendizado h.
2 - Repetir: 2.1- Apresentar o vetor de entrada X(n) e a saída desejada d(n), de cada par do conjunto de treinamento T = {(x,d)} 2.2- Calcular a resposta real do Perceptron, da seguinte forma: y(n) = f(W(n)X(n)+b(n)), onde f(.) é a Função de Limiar utlizada como função de ativação. 2.3- Calcular o erro da saída da unidade da seguinte forma: e(n) = d(n) - y(n);
 e a saída desejada d(n), de cada par do conjunto de treinamento T = {(x,d)} 2.2- Calcular a resposta real do Perceptron, da seguinte forma: y(n) = f(W(n)X(n)+b(n)), onde f(.) é a Função de Limiar utlizada como função de ativação Calcular o erro da saída da unidade da seguinte forma: e(n) = d(n) - y(n);")
51
2.4- Atualizar o vetor de pesos para cada uma das unidades da rede segundo a regra: W(n+1) = W(n) + he(n)X(n); 3 - Incremento: Incremente o passo de tempo (n), volte ao passo 2.1. Até que e(n) = 0 para todos os elementos do conjunto de treinamento em todas as unidades da rede.
, volte ao passo 2.1. Até que e(n) = 0 para todos os elementos do conjunto de treinamento em todas as unidades da rede.")
52
Rosenblatt provou através do Teorema da Convergência do Perceptron, que este algoritmo consegue encontrar um conjunto de pesos ideais para que a Rede classifique corretamente as entradas desde que seja aplicado a classes linearmente separaveis (fig 1).
.")
53
Perceptron binário de duas etapas
A utilização de mais um neurônio, em uma camada adicional, pode, em princípio, realizar um sistema para classificar polígonos convexos. A dificuldade é justamente encontrar um procedimento de treinamento para este tipo de rede.

55
Problema XOR (0,1) (1,1) (0,0) (1,0) Encontrar um neurônio capaz de classificar este padrão.Utilizando a função de Ativação f(x) = 0 , x<=0 e f(x) = 1 ,x > 0.
 = 0 , x<=0 e f(x) = 1 ,x > 0.")
56
Problema XOR (0,1) (1,1) (0,0.8) 1.2 (0,0) (0.8,0) (1,0)
 (1,1) (0,0.8) 1.2 (0,0) (0.8,0) (1,0)")
57
Problema XOR X-Y-0.8=0 (0,1) (1,1) (0,0.8) 1.2 (0,0) (0.8,0) (1,0)
 (1,1) (0,0.8) 1.2 (0,0) (0.8,0) (1,0)")
58
X 1 X-Y-0.8 -1 Y 0.8

59
Problema XOR -X+Y-0.8=0 (0,1) (1,1) (0,0.8) 1.2 (0,0) (0.8,0) (1,0)
 (1,1) (0,0.8) 1.2 (0,0) (0.8,0) (1,0)")
60
X -1 -X+Y-0.8 1 Y 0.8

61
Problema XOR (0,1.6) (0,1) (1,1) (0,0.8) 1.2 (0,0) (0.8,0) (1,0)
(2.4,1.6)
")
62
0.8 1 1 -1 -1 1 1 0.8
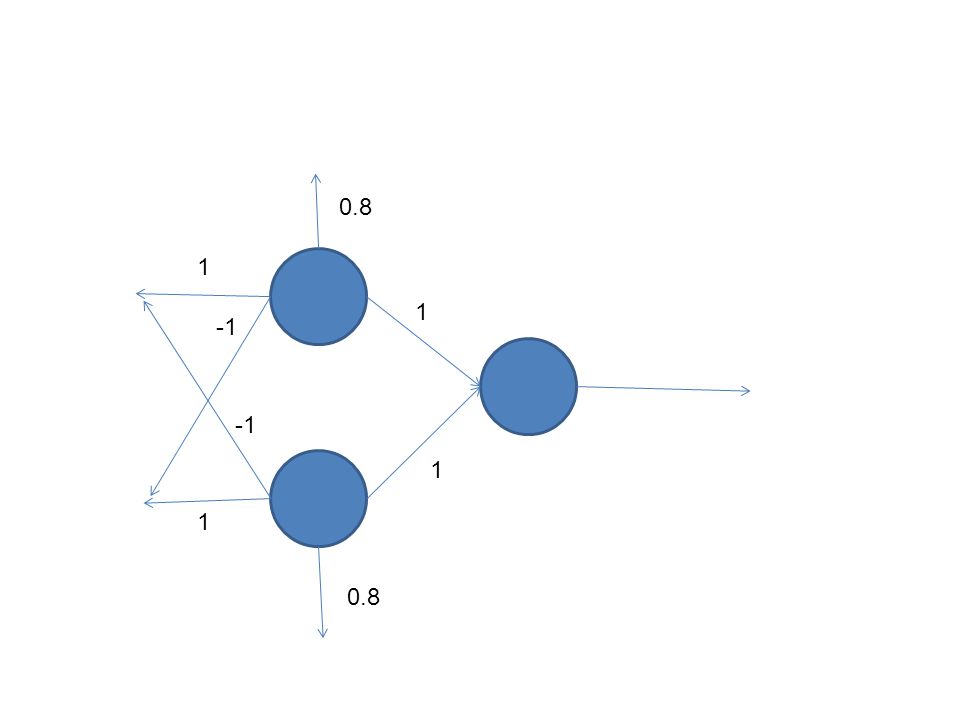
63
Muitos unidades combinadas e a última camada implementando um consenso entre as unidades da primeira camada. Problemas relacionados com a convergência.

64
Perceptron binário de três etapas

65
Cálculo do erro na saída: Sdesejada - Sobtida = Erro
Cálculo do erro de um neurônio interno da rede: Como fazer a atribuição da “culpa” em relação ao erro final na saída ? Década perdida – (1970 – 1980)
")
66
Adaline(Adaptive Linear Element)
Unidade linear sem limiar, aprendizado supervisionado utilizando convergindo apenas assintoticamente para um vetor de pesos com um erro mínimo, possivelmente um número ilimitado de passos, independemente do conjunto de treinamento ser linearmente separável.

67
Considere uma unidade linear simples, onde:
Especificando uma medida para o erro de treinamento de uma hipótese (vetor de pesos) relativamente aos exemplos de treinamento:
 relativamente aos. exemplos de treinamento:")
68
O algoritmo de descida do gradiente pode
entendido através da visualização do espaço de hipóteses. A descida do gradiente determina um vetor de pesos que minimiza E, começando com um vetor inicial de pesos arbitrário e modificando–o repetidamente em pequenos passos.

69
A cada passo, o vetor de pesos é alterado na
direção que produz a maior queda ao longo da superfície de erro. Este processo continua até atingir um erro mínimo global.

70
Descida do Gradiente

74
Resumindo o algoritmo descida do gradiente
para a aprendizagem de unidade lineares: 1. Pegar um vetor inicial aleatório de pesos; 2. Aplicar a unidade linear para todos os exemplos de treinamento e calcular Δwi para cada peso de acordo com a equação anterior; 3. Atualizar cada peso wi adicionando Δwi e Então repetir este processo. O algoritmo convergirá para um vetor de pesos com erro mínimo.

75
A regra de treinamento perceptron tem sucesso se:
Exemplos de treinamento são linearmente separáveis Taxa de aprendizagem η for suficientemente pequena

76
Regra de treinamento da unidade linear utiliza a descida do gradiente
Convergência garantida para a hipótese com erro quadrado mínimo Dada uma taxa de aprendizagem η suficientemente pequena Mesmo quando dados de treinamento contém ruído Mesmo quando dados de treinamento não forem separáveis

77
Quando devemos parar o treinamento, ou seja, parar a atualização dos pesos?
Escolha óbvia: continuar o treinamento até que o erro E seja menor que o valor pré-estabelecido. Porém, isto implica em sobreajuste(overfitting). O sobreajuste diminui a generalização da rede neural.
. O sobreajuste diminui a generalização da rede neural.")
78
Modelo mais gerais de neurônio
Temos diversos modelos de neurônios mais gerais que o modelo de neurônio McCulloch-Pitts, no qual a função de transferência utilizada obtém o estado de ativação de maneira menos abrupta e as saídas não são apenas 0 e 1.

79
Função Linear

80
Hard Limiter

81
Em Rampa

82
Sigmoid

83
Sigmoid

84
Gaussiana

85
Tipos de Entrada Binários aqueles modelos que aceitam entradas discretas,ou seja, somente na forma de 0 e 1. os intervalares são os que aceitam qualquer valor numérico como entrada (forma contínua).
.")
86
Formas de conexão alimentação à frente(feedforward), onde os sinais de entrada são simplesmente transformados em sinais de saída;
, onde os sinais de entrada são simplesmente transformados em sinais de saída;")
87
Formas de conexão retro-alimentação, no qual os sinais cam sendo alterados em diversas transições de estado, sendo a saída também alimentadora da entrada;

88
Retroalimentação

89
Formas de conexão competitiva, que realiza a interação lateral dos sinais recebidos na entrada entre os elementos dentro de uma zona de vizinhança.

90
Formas de conexão

91
Formas de Aprendizagem
Aprendizado Supervisionado Neste caso o ‘professor’ indica explicitamente um comportamento bom ou ruim. Por exemplo, seja o caso de reconhecimento de caracteres e para simplificar seja reconhecer entre um A ou X.

92
Formas de Aprendizagem
Aprendizado não Supervisionado é quando para fazer modificações nos valores das conexões sinápticas não se usa informações sobre se a resposta da rede foi correta ou não. Usa-se por outro lado um esquema, tal que, para exemplos de coisas semelhantes, a rede responda de modo semelhante.

93
Exercício Defina uma rede neural?

94
Exercício Defina uma rede neural? Redes Neurais são sistemas paralelos
distribuídos compostos por unidades de processamento simples interligadas entre si e com o ambiente por um número de conexões.

95
Exercício Defina uma rede neural?
Um Modelo inspirado na estrutura paralela do cérebro e que buscam reter algumas de suas propriedades, as unidades representando os neurônios, enquanto que a interconexão, as redes neurais.

96
Quais são os componentes do neurônio McCulloch e Pitts?

97
Quais são os componentes do neurônio McCulloch e Pitts?
Entrada Pesos sinápticos Integração sináptica Limiar (bias) Função de Ativação
 Função de Ativação.")
98
Em relação a atividade de um neurônio, quais foram a conclusão obtida por McCulloch e Pitts?

99
Em relação a atividade de um neurônio, quais
foram a conclusão obtida por McCulloch e Pitts? A atividade de um neurônio é tudo ou nada, ou seja, o neurônio funciona como um circuito binário.

100
O que representa a integração sináptica nas redes neurais e o limiar?

101
O que representa a integração sináptica nas redes neurais e o limiar?
A integração sináptica define o nível atividade do neurônio e o limiar define se o neurônio está ativado ou desativado.

102
Por que podemos dizer que o perceptron é um classificador linear?

103
Por que podemos dizer que o perceptron é um classificador linear?
O perceptron é usado para classificar funções linearmente separáveis.

104
Quais são as vantagens e desvantagens do método descida de gradiente?

105
Quais são as vantagens e desvantagens do método descida de gradiente?
O método pode tratar dados com ruído e dados não linearmente separáveis. O método pode não convergi em número finito de passos mesmo quando os dados são linearmente separáveis.

106
A decáda ( ) é considerada a década perdida para as pesquisas em rede neural. O que explica este fato?

107
A decáda ( ) é considerada a década perdida para as pesquisas em rede neural. O que explica este fato? Este problema deve-se principalmente aos problemas encontrados com o treinamento supervisionado com redes multicamadas.

Apresentações semelhantes








: Introdução>")










>")



