Carregar apresentação
A apresentação está carregando. Por favor, espere

1
Agrupamento e Classificação de Padrões

3
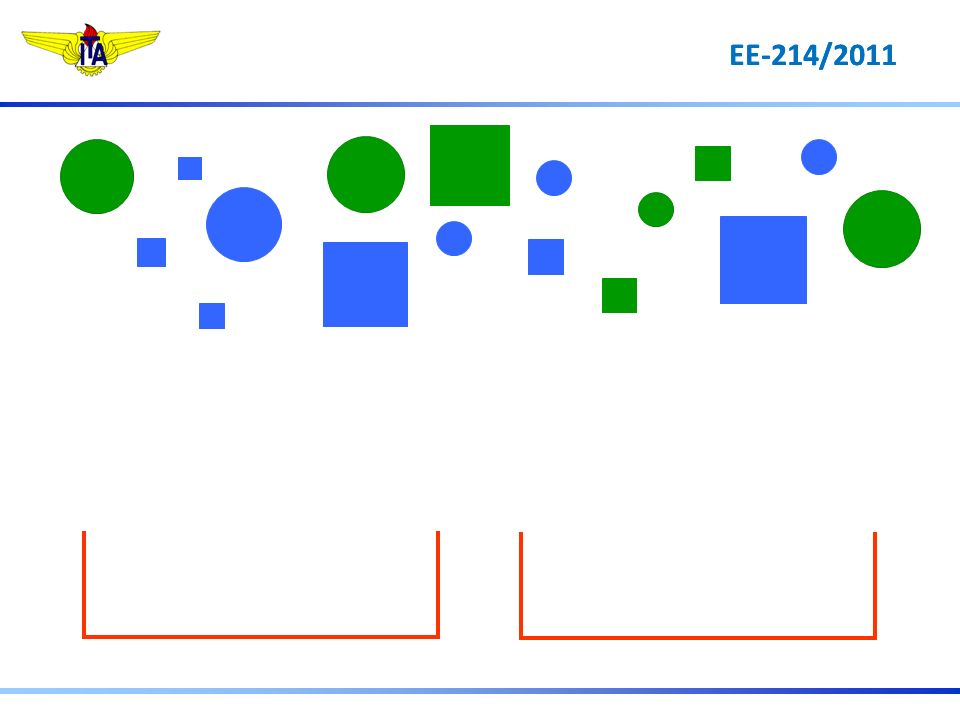
Característica = Número de Vértices
Agrupamento: Característica = Número de Vértices 0 vértices 4 vértices

5
Característica = Cor (Comprimento de Onda)
Agrupamento: Característica = Cor (Comprimento de Onda) = 470 nm = 550 nm
 = 470 nm. = 550 nm.")
7
Agrupamento: Característica = Área A > 3 cm2 A 3 cm2

8
Classificação ? 0 vértices 4 vértices

9
Classificação ? 0 vértices 4 vértices

10
Classificação ? 0 vértices 4 vértices

11
Classificação ? 0 vértices 4 vértices

12
Classificação ? 0 vértices 4 vértices

13
? 0 vértices 4 vértices

14
Reconhecimento de Padrões
Círculo

15
Reconhecimento de Padrões
Quadrado

16
Reconhecimento de Padrões
Uh?

17
Ventilador acionado por Motor DC
W TAC MOT J,B BAT I mot W,t

18
Ventilador acionado por Motor DC
t,W F A V W TAC MOT J,B BAT I mot W,t

19
Ventilador acionado por Motor DC
t,W F t nom W w nom

20
Ventilador acionado por Motor DC
t,W F B t nom W w nom

21
Ventilador acionado por Motor DC
RBAT + Ra W

22
Ventilador acionado por Motor DC
VBAT W

23
Ventilador acionado por Motor DC
Eixo Quebrado W

24
Ventilador acionado por Motor DC
Curto-ciruito Eixo-travado W

25
Imot E – Escova com R N – Nominal B – Bateria com V C – Curto
T – Eixo Travado Q – Eixo Quebrado T T E E E E E N N N B N N B B B B Q Q Q Q Q W

26
Imot E – Escova com R N – Nominal B – Bateria com V C – Curto
T – Eixo Travado Q – Eixo Quebrado T T E E E E E N N N B N N B B B B Q Q Q Q Q W

27
Imot E – Escova com R N – Nominal B – Bateria com V C – Curto
g( W , Imot ) = 0 C < 0 > 0 C Curto-circuito Motor-travado T E – Escova com R N – Nominal B – Bateria com V C – Curto T – Eixo Travado Q – Eixo Quebrado T T E E Eixo Quebrado E E E N N N B N N B B B B Q Q d Q Q Qnew Q W
 = 0. C. < 0. > 0. C. Curto-circuito. Motor-travado. T. E – Escova com R N – Nominal. B – Bateria com V C – Curto. T – Eixo Travado. Q – Eixo Quebrado. T. T. E. E. Eixo Quebrado. E. E. E. N. N. N. B. N. N. B. B. B. B. Q. Q. d. Q. Q. Qnew. Q. W.")
29
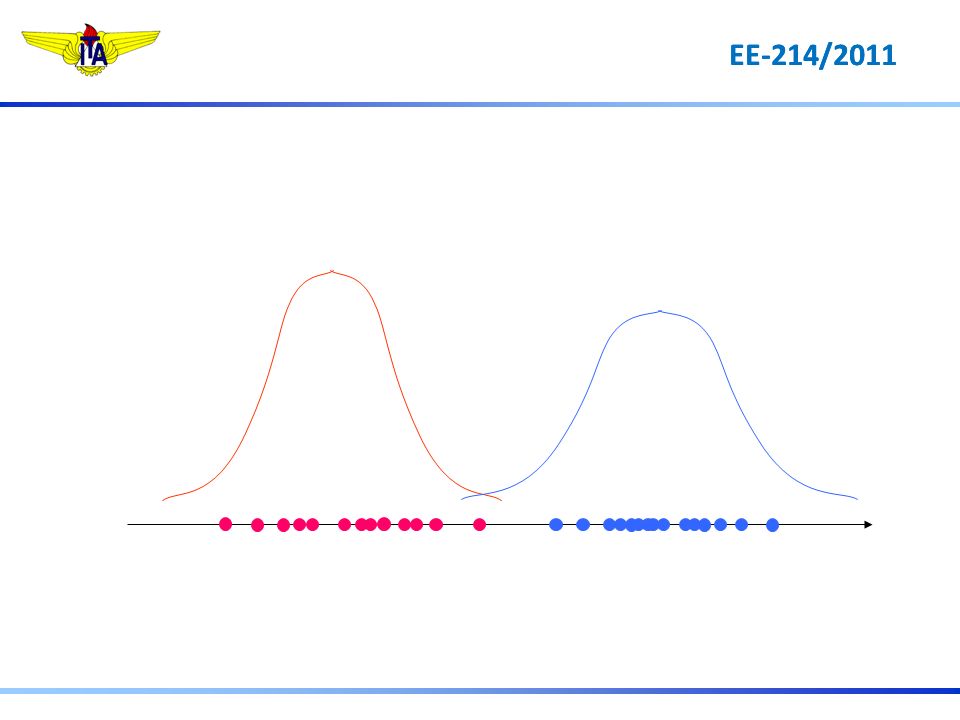
Clusters?

30
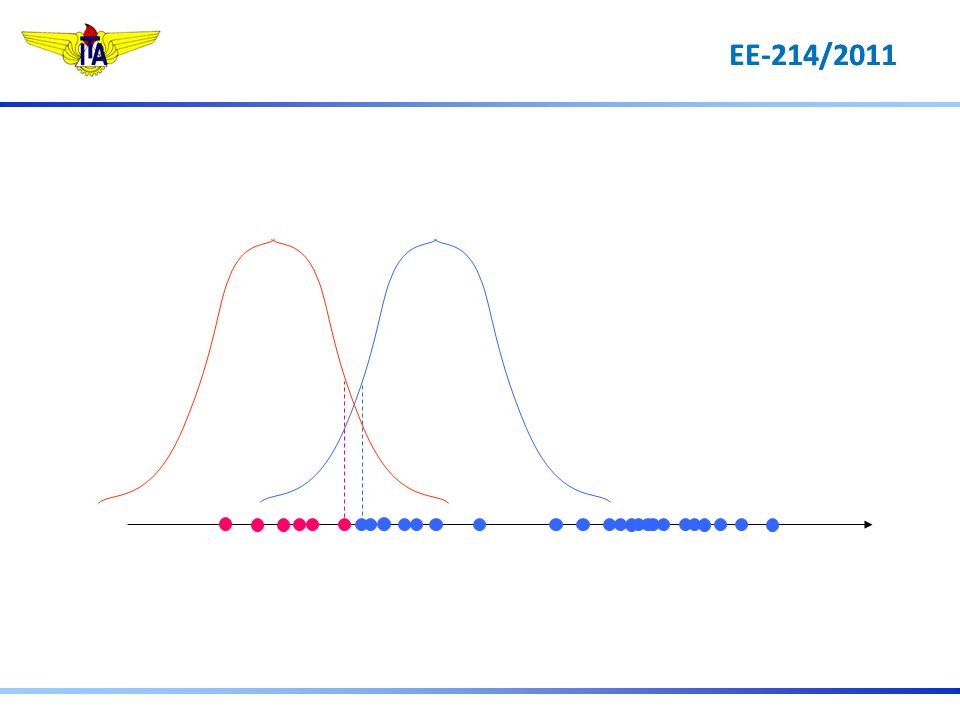
No passado, a causa de motor parado tem sido:
Observou-se W = 0 No passado, a causa de motor parado tem sido: - 70% casos = curto-circuito - 30 % casos = eixo-travado Sem dados adicionais Curto-circuito é a causa mais provável Critério Utilizado: P(curto) > P(travado)
 > P(travado)")
31
Observou-se W = 0 e mediu-se a corrente Imot = 21 A
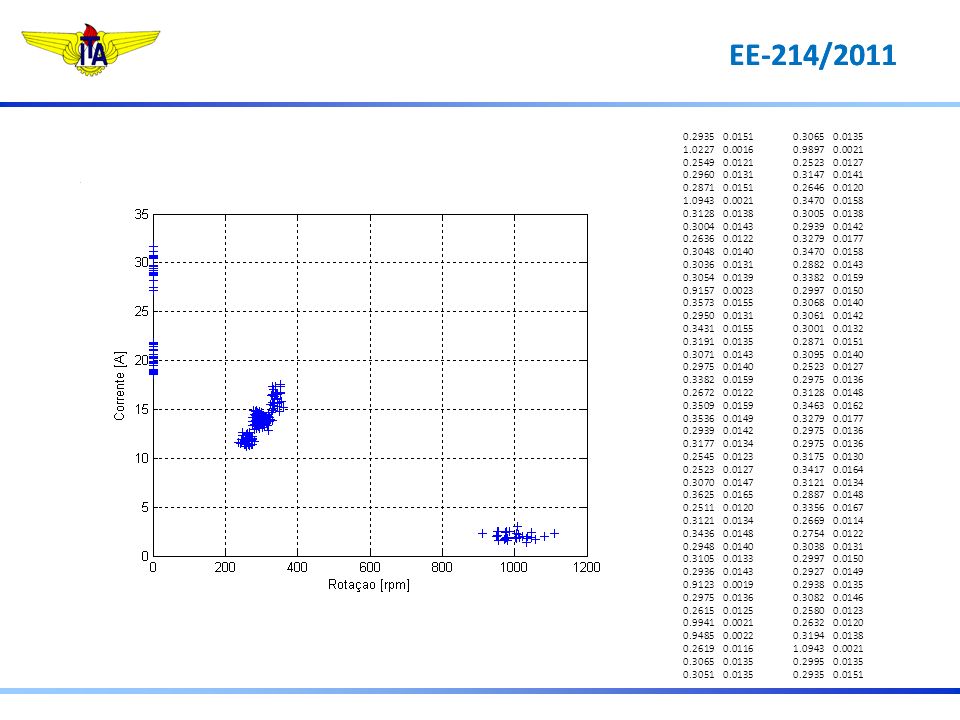
Dados Históricos + = eixo-travado + = curto-circuito [A] + + + + + + + + + + + + + 10 20 30 Como aproveitar a informação de que Imot = 21A ?

32
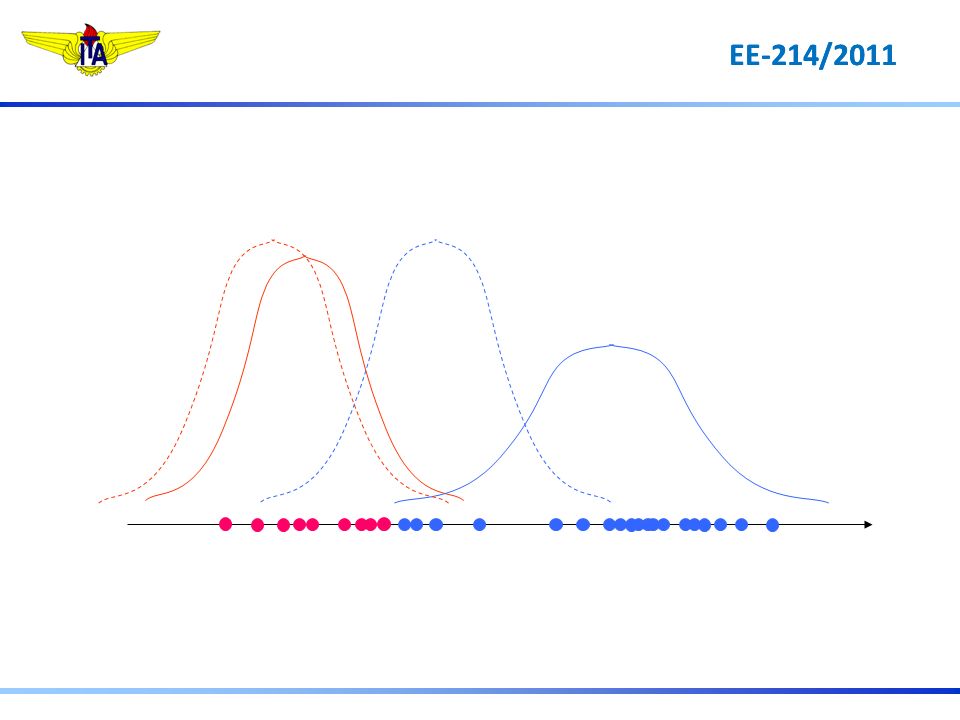
Observou-se = 0 e mediu-se a corrente Imot = 21 A
Fórmula de Bayes P(a|b)= P(b|a)P(a)/P(b) Dados Históricos P(Imot|eixo-travado) P(Imot|curto-circuito) P(curto|Imot)=P(Imot|curto)P(curto)/P(Imot) P(travado|Imot)=P(Imot|travado)P(travado)/P(Imot) [A] + + + + + + + + + + + + + 10 20 30 P(Imot) é comum nas 2 expressões Imot Eixo-travado é a causa mais provável Critério Utilizado: P(travado | Imot ) > P(curto| Imot )
= P(b|a)P(a)/P(b) Dados Históricos. P(Imot|eixo-travado) P(Imot|curto-circuito) P(curto|Imot)=P(Imot|curto)P(curto)/P(Imot) P(travado|Imot)=P(Imot|travado)P(travado)/P(Imot) [A] P(Imot) é comum nas 2 expressões. Imot. Eixo-travado é a causa mais provável. Critério Utilizado: P(travado | Imot ) > P(curto| Imot )")
33
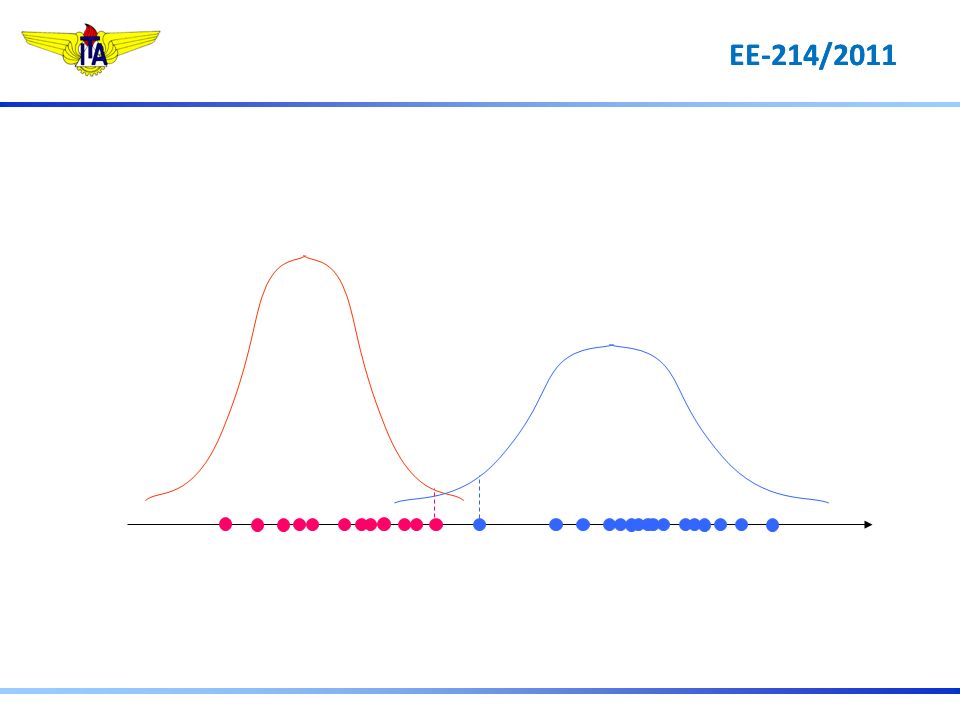
Notação Geral 1 = curto 2 = travado x = Imot
P(curto|Imot)=P(Imot|curto)P(curto)/P(Imot) P(travado|Imot)=P(Imot|travado)P(travado)/P(Imot) P(1|x)=P(x| 1)P(1) P(2|x)=P(x| 2)P(2) P(travado | Imot ) > P(curto| Imot ) P(2|x) > P(1|x) P(x| 2)P(2) > P(x| 1)P(1)
=P(Imot|curto)P(curto)/P(Imot) P(travado|Imot)=P(Imot|travado)P(travado)/P(Imot) P(1|x)=P(x| 1)P(1) P(2|x)=P(x| 2)P(2) P(travado | Imot ) > P(curto| Imot ) P(2|x) > P(1|x) P(x| 2)P(2) > P(x| 1)P(1)")
34
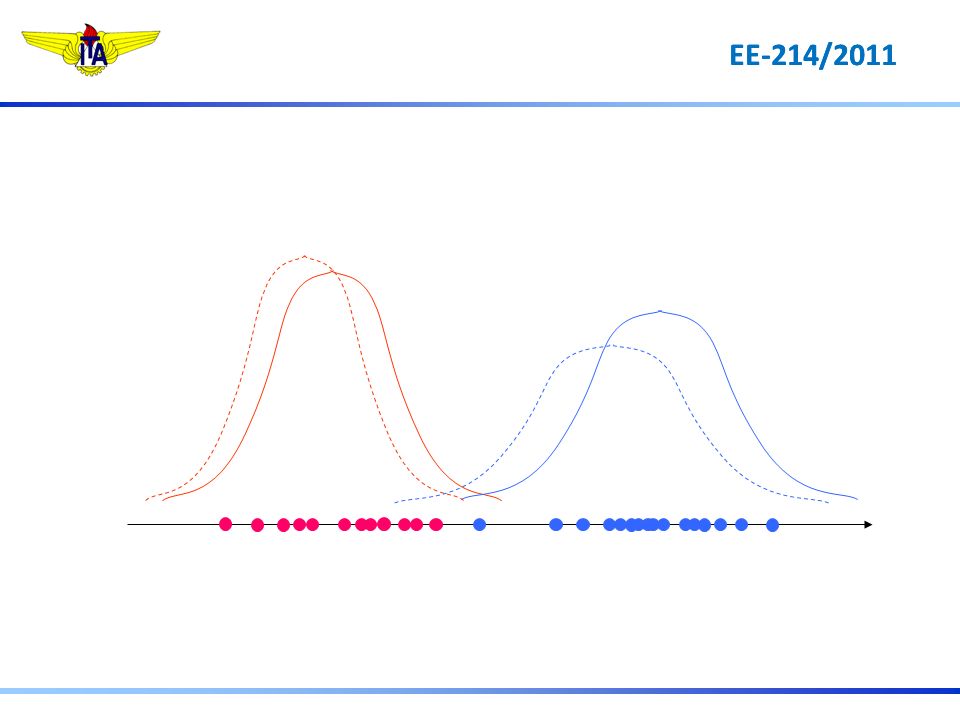
decide w2 P(x| 2)P(2) > P(x| 1)P(1)
P(2) > P(x| 1)P(1)")
35
decide w2 decide w2 decide w2 decide w2 decide w1

36
( 2, 2 ) ( 1, 1 ) No caso particular
 ( 1, 1 ) No caso particular")
37
No caso particular

38
Caso I :

39
Caso I : Igual para todos os i ai

40
Caso I : g(x)
")
41
Caso II : arbitrário mas igual para i g(x)
")
42
Caso III : i arbitrários ( cada i )
")
43
A ou B ? A B

44
A ou B ? A B

45
Distância de Mahalanobis
A ou B ? A B

46
Propriedades requeridas: d(x,y) 0 d(x,y) = 0 x=y d(x,y) = d(y,x)
Distância d: X X R+ Propriedades requeridas: d(x,y) 0 d(x,y) = 0 x=y d(x,y) = d(y,x) d(x,z) + d(z,y) d(x,y) Distância de Minkowski: k=1 Manhattan k=2 Euclidiana
 0. d(x,y) = 0 x=y. d(x,y) = d(y,x) d(x,z) + d(z,y) d(x,y) Distância de Minkowski: k=1. Manhattan. k=2. Euclidiana.")
47
Agrupamento Hierárquico
1 2 x1 x2 Dados:

48
>> x = >> y=pdist(x,'euclidean'); >> z=linkage(y,'average'); >> dendrogram(z) Dados:
; >> z=linkage(y, average ); >> dendrogram(z) Dados:")
49
Agrupamento Hierárquico
Dados:

50
Agrupamento Hierárquico
1 2 x1 x2 Dados:

51
Agrupamento Hierárquico
x2 Dados: 2 1 x1 1 2

52
Agrupamento Hierárquico
1 2 x1 x2 Dados:

53
Agrupamento Hierárquico
1 2 x1 x2 Dados:

54
Agrupamento Hierárquico
1 2 x1 x2 Dados:

55
Agrupamento Hierárquico
1 2 x1 x2 Dados:

56
Agrupamento Hierárquico
1 2 x2 x1 Dados:

57
K-means 1 2 x1 x2 Dados:

58
>> x = >> [idx,c]=kmeans(x,2) idx = 2 1 c = Dados:
 idx = c = Dados:")
59
>> x = >> [idx,c]=kmeans(x,2) idx = 2 1 c = Dados:
 idx = c = Dados:")
60
K-means x2 c = Dados: 2 1 x1 1 2

61
K-means x2 2 1 x1 1 2

62
K-means x2 2 1 x1 1 2

63
K-means x2 2 1 x1 1 2

64
K-means x2 2 1 x1 1 2

65
K-means x2 2 1 x1 1 2

66
K-means x2 2 1 x1 1 2

67
K-means x2 2 1 x1 1 2

68
K-means x2 2 1 x1 1 2

69
K-means x2 2 1 x1 1 2

70
K-means x2 2 1 x1 1 2

71
K-means x2 2 1 x1 1 2

72
K-means x2 2 1 x1 1 2

73
Ventilador acionado por Motor DC

74
Centróides 251, ,2 0, ,5 1.000, ,5 351, ,0 0, ,7 298, ,0

75
1 2 3 4 5 6

76
Aprendizado Competitivo
Entrada RNA Padrão 1 Padrão 3 Padrão 2

77
wi wi* wi x A regra competitiva de atualização dos pesos é:
O tamanho do passo (0 < < 1) controla o tamanho da atualização em cada passo. wi wi* wi x
 controla o tamanho da atualização em cada passo. wi. wi* wi. x.")
78
>> net=newc([0 10 ; 0 20],3); >> net=train(net,P);
x = >> P=x'; >> net=newc([0 10 ; 0 20],3); >> net=train(net,P); >> xsim = sim(net,P); >> Yc = vec2ind(xsim);
![>> net=newc([0 10 ; 0 20],3); >> net=train(net,P);](http://slideplayer.com.br/slide/344554/2/images/78/%3E%3E+net%3Dnewc%28%5B0+10+%3B+0+20%5D%2C3%29%3B+%3E%3E+net%3Dtrain%28net%2CP%29%3B.jpg "x = >> P=x ; >> net=newc([0 10 ; 0 20],3); >> net=train(net,P); >> xsim = sim(net,P); >> Yc = vec2ind(xsim);")
79
NEWC Create a competitive layer.
net = newc(PR,S,KLR,CLR) TRAIN Train a neural network. [net,tr,Y,E,Pf,Af] = train(NET,P,T,Pi,Ai,VV,TV) VEC2IND Transform vectors to indices. vec = ind = >> P=x'; >> net=newc([0 10 ; 0 20],3); >> net=train(net,P); >> xsim = sim(net,P); >> Yc = vec2ind(xsim);
 TRAIN Train a neural network. [net,tr,Y,E,Pf,Af] = train(NET,P,T,Pi,Ai,VV,TV) VEC2IND Transform vectors to indices. vec = ind = >> P=x ; >> net=newc([0 10 ; 0 20],3); >> net=train(net,P); >> xsim = sim(net,P); >> Yc = vec2ind(xsim);")
80
x =
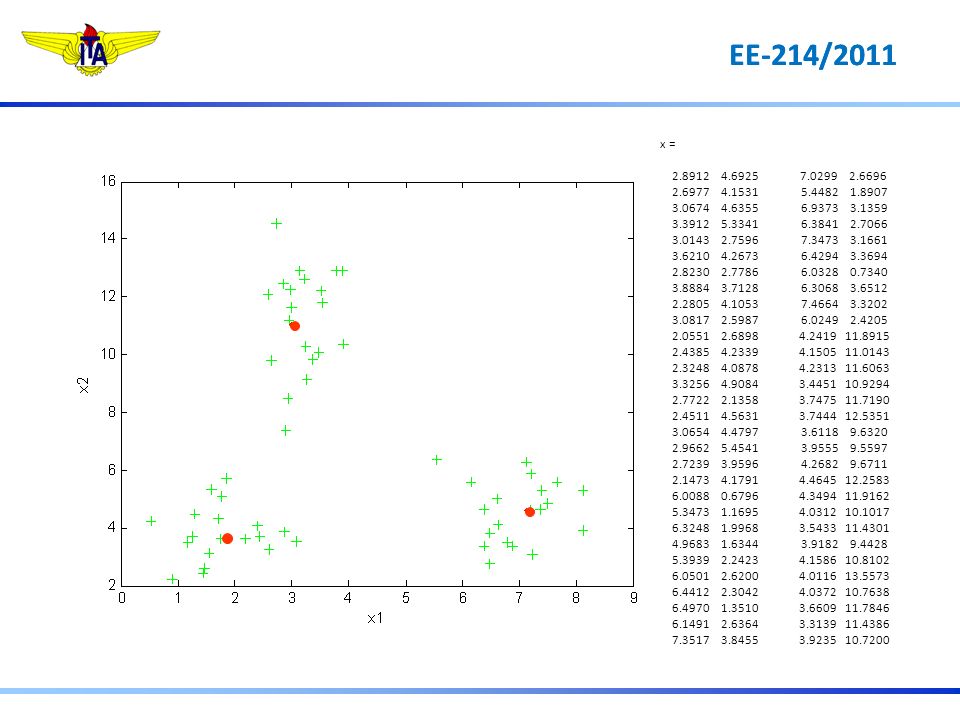
81
Padrão 1 Padrão 3 Padrão 2 Padrão 1 Padrão 2 Padrão 3 RNA Entrada

82
Padrão 1 Padrão 3 Padrão 2 Padrão 1 Padrão 2 Padrão 3 RNA x1 = 2 x2 = 4

83
Padrão 1 Padrão 3 Padrão 2 Padrão 1 Padrão 2 Padrão 3 RNA x1 = 6 x2 = 5

84
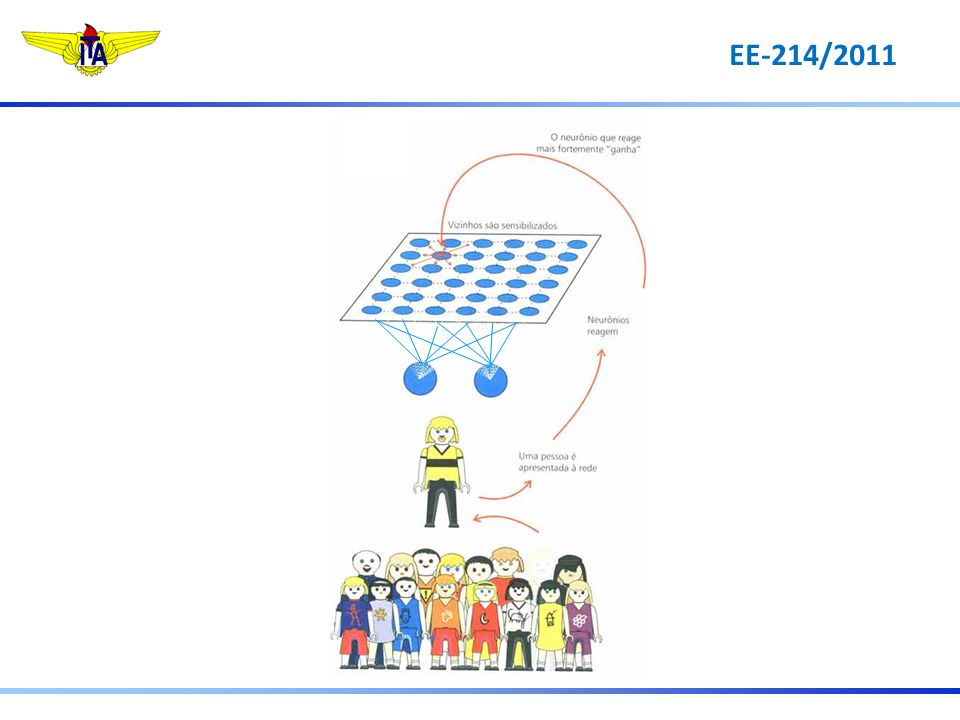
Redes de Kohonen RNA de 1 camada simples composta de uma camada de entrada e outra de saída Aprendizado não-supervisionado Unidades de Entrada Unidades concorrentes de Saída

85
Redes de Kohonen Unidades de Entrada Unidades concorrentes de Saída

86
1. Camada de entrada é apresentada
Unidades de Entrada Unidades concorrentes de Saída

87
Onde j é a unidade de saída e é a distância resultante.
2. A distância do padrão de entrada para os pesos para cada unidade de saída é calculada através da fórmula euclidiana: Onde j é a unidade de saída e é a distância resultante. Unidades de Entrada Unidades concorrentes de Saída

88
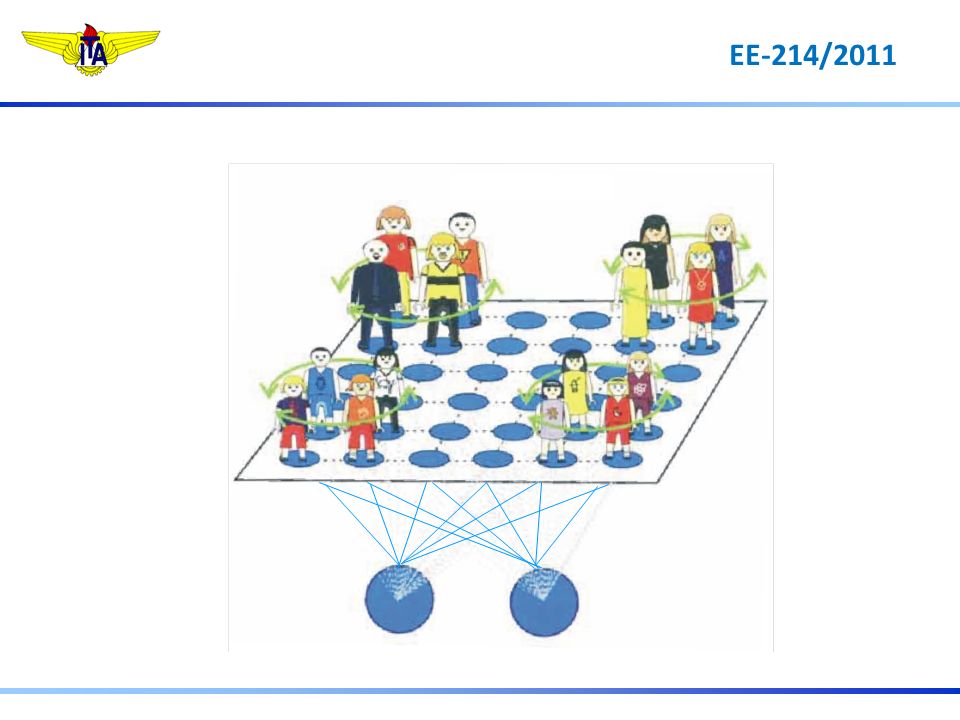
Cada vez que um vetor de entrada é apresentado para a rede, a distância em relação a ele para cada unidade na camada de saída é calculada A unidade de saída com a menor distância em relação ao vetor de entrada é a vencedora Unidades de Entrada Unidades concorrentes de Saída unidade vencedora

89
Os pesos são ajustados de acordo com o vencedor
Os vizinhos se aproximam de acordo com o treinamento e a estrutura se auto-organiza Unidades de Entrada Unidades concorrentes de Saída unidade vencedora

90
di,i* wi wi* wi x

91
Sexo Idade Pessoas de Sexo e Idades Variados

95
net.trainParam.epochs = 100; net = train(net,P);
x = P=x'; net = newsom([0 10; 0 20],[1 3],... 'gridtop','dist',0.9,200,0.01,0); net.trainParam.epochs = 100; net = train(net,P); NEWSOM Create a self-organizing map. net = newsom(PR,[d1,d2,...],tfcn,dfcn,olr,osteps,tlr,tns) PR Rx2 matrix of min and max values for R input elements. Di Size of ith layer dimension, defaults = [5 8]. TFCN - Topology function, default = 'hextop'. DFCN - Distance function, default = 'linkdist'. OLR - Ordering phase learning rate, default = 0.9. OSTEPS - Ordering phase steps, default = 1000. TLR - Tuning phase learning rate, default = 0.02; TNS - Tuning phase neighborhood distance, default = 1.
; net.trainParam.epochs = 100; net = train(net,P); NEWSOM Create a self-organizing map. net = newsom(PR,[d1,d2,...],tfcn,dfcn,olr,osteps,tlr,tns) PR - Rx2 matrix of min and max values for R input elements. Di - Size of ith layer dimension, defaults = [5 8]. TFCN - Topology function, default = hextop . DFCN - Distance function, default = linkdist . OLR - Ordering phase learning rate, default = 0.9. OSTEPS - Ordering phase steps, default = TLR - Tuning phase learning rate, default = 0.02; TNS - Tuning phase neighborhood distance, default = 1.")
96
net = newsom([0 10; 0 20],[1 3],'gridtop','dist',0.9,200,0.01,0);
![net = newsom([0 10; 0 20],[1 3], gridtop , dist ,0.9,200,0.01,0);](http://slideplayer.com.br/slide/344554/2/images/96/net+%3D+newsom%28%5B0+10%3B+0+20%5D%2C%5B1+3%5D%2C+gridtop+%2C+dist+%2C0.9%2C200%2C0.01%2C0%29%3B.jpg "net = newsom([0 10; 0 20],[1 3], gridtop , dist ,0.9,200,0.01,0);")
97
Padrão 1 Padrão 3 Padrão 2 Padrão 1 Padrão 2 Padrão 3 RNA x1 = 2 x2 = 4 net = newsom([0 10; 0 20],[1 3],'gridtop','dist',0.9,200,0.01,1);
;")
98
net = newsom([0 10; 0 20],[1 50],'gridtop','dist',0.9,200,0.01,3);
![net = newsom([0 10; 0 20],[1 50], gridtop , dist ,0.9,200,0.01,3);](http://slideplayer.com.br/slide/344554/2/images/98/net+%3D+newsom%28%5B0+10%3B+0+20%5D%2C%5B1+50%5D%2C+gridtop+%2C+dist+%2C0.9%2C200%2C0.01%2C3%29%3B.jpg "net = newsom([0 10; 0 20],[1 50], gridtop , dist ,0.9,200,0.01,3);")
99
net = newsom([0 10; 0 20],[3 3],'hextop','dist',0.9,200,0.01,1);
![net = newsom([0 10; 0 20],[3 3], hextop , dist ,0.9,200,0.01,1);](http://slideplayer.com.br/slide/344554/2/images/99/net+%3D+newsom%28%5B0+10%3B+0+20%5D%2C%5B3+3%5D%2C+hextop+%2C+dist+%2C0.9%2C200%2C0.01%2C1%29%3B.jpg "net = newsom([0 10; 0 20],[3 3], hextop , dist ,0.9,200,0.01,1);")
100
EM (Expectation-Maximization)
")
108
Cluster A Cluster B

109
Cluster A Cluster B

110
Dept of Electrical and Computer Eng University of Waterloo
>> [W,M,V,L] = EM_GM(X,3,[],[],1,[]) EM algorithm for k multidimensional Gaussian mixture estimation X(n,d) - input data n=number of observations d=dimension of variable k - maximum number of Gaussian components allowed ltol - percentage of log likelihood difference between 2 iterations maxiter - maximum number of iteration allowed ([] for none) pflag - 1 for plotting GM for 1D or 2D cases only, 0 otherwise Init - structure of initial W, M, V: Init.W, Init.M, Init.V W(1,k) - estimated weights of GM M(d,k) - estimated mean vectors of GM V(d,d,k) - estimated covariance matrices of GM L - log likelihood of estimates Patrick P. C. Tsui, Dept of Electrical and Computer Eng University of Waterloo
 EM algorithm for k multidimensional Gaussian mixture estimation. X(n,d) - input data. n=number of observations. d=dimension of variable. k - maximum number of Gaussian components allowed. ltol - percentage of log likelihood difference between 2 iterations. maxiter - maximum number of iteration allowed ([] for none) pflag - 1 for plotting GM for 1D or 2D cases only, 0 otherwise. Init - structure of initial W, M, V: Init.W, Init.M, Init.V. W(1,k) - estimated weights of GM. M(d,k) - estimated mean vectors of GM. V(d,d,k) - estimated covariance matrices of GM. L - log likelihood of estimates. Patrick P. C. Tsui, Dept of Electrical and Computer Eng. University of Waterloo.")
111
x =
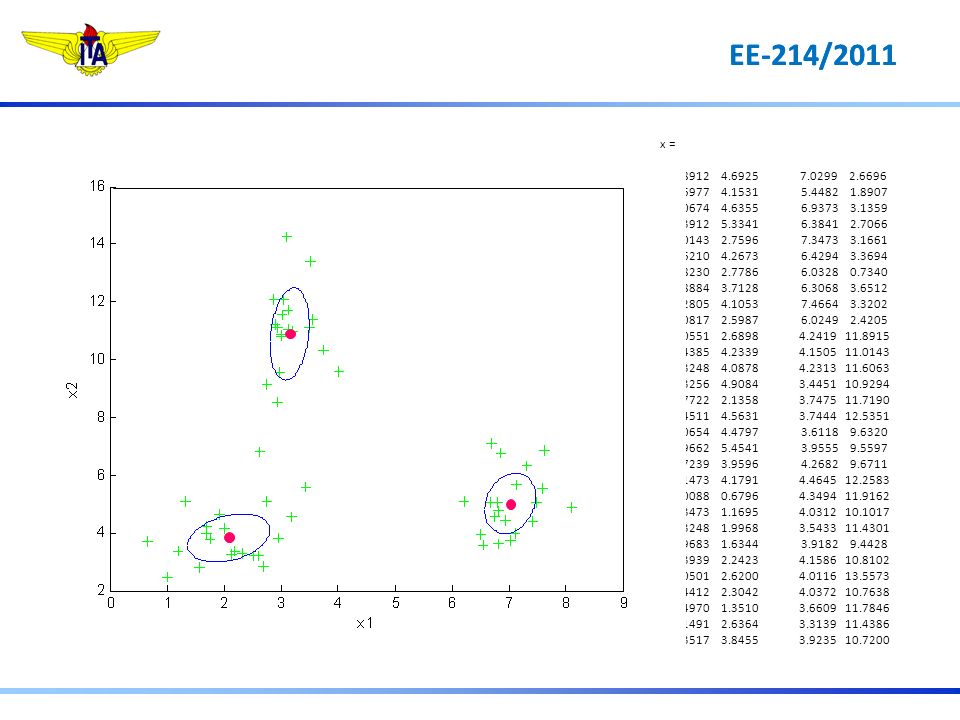
112
Muito Obrigado!

Apresentações semelhantes






>")



: Perceptron>")
: Aprendizado>")



>")






