Carregar apresentação
A apresentação está carregando. Por favor, espere

1
Sumarização Automática para a Tarefa de Recuperação de Informação Textual
Relação entre SA e RI

2
2 protótipos extrativos
Perspectiva inicial 2 protótipos extrativos GistSumm (PARDO et al., 2003; PARDO, 2005) SuPor (MÓDOLO, 2003; RINO E MÓDOLO, 2004) 1 protótipo fundamental RHeSumaRST (SENO, 2004; SENO & RINO, 2005)
 SuPor (MÓDOLO, 2003; RINO E MÓDOLO, 2004) 1 protótipo fundamental. RHeSumaRST (SENO, 2004; SENO & RINO, 2005)")
3
Tarefas previstas Prototipação e avaliação de um buscador baseado em extratos topicais Verificação das características que interferem na busca Validação do GistSumm e suas variações no contexto da RI

4
Sistemas em perspectiva
RecEG Batista Jr., W.S. (2006). Dissertação de Ms ExtraWeb Pedreira-Silva, P. (2006). Dissertação de Ms
. Dissertação de Ms. ExtraWeb. Pedreira-Silva, P. (2006). Dissertação de Ms.")
5
Recuperação baseada em Extratos Genéricos
RecEG Recuperação baseada em Extratos Genéricos GistSumm (PARDO et al., 2003; Pardo, 2005) Pseudo-relevance feedback Plataforma: Java
 Pseudo-relevance feedback. Plataforma: Java.")
6
RecEG CLEF 2005 RDoc RExt Batista Jr. & Rino (2007) RDocExt RFGenS
RFQBS RFQBM RFFullDoc CLEF 2005 Batista Jr. & Rino (2007) Revista Iberoamericana de Inteligencia Artificial Batista Jr. & Rino (2006) TIL2006
 Revista Iberoamericana de Inteligencia Artificial. Batista Jr. & Rino (2006) TIL2006.")
7
Ontologia do Yahoo para o PORT
ExtraWeb SA de textos da WEB Apoio (ou substituição) à RI Ontologia do Yahoo para o PORT Subconjunto refinado manualmente a partir de corpus
 à RI. Ontologia do Yahoo para o PORT. Subconjunto refinado manualmente a partir de corpus.")
8
Perspectivas encaminhadas (2006-)
Modelo extrativo SuPor SuPor-2 Daniel Leite – IC, Ms (2008) IdealXtractor Rodolfo Golombieski – ITI/PLN-Br (2007) Fundamental RHeSumaRST RHeSuma-2 RHeSuma-2 VeinSum Thiago Carbonel – Ms (2007) Élen Tomazela – Ms (2007) RAPM Amanda Chaves – Ms (2007)
 IdealXtractor. Rodolfo Golombieski – ITI/PLN-Br (2007) Fundamental. RHeSumaRST RHeSuma-2. RHeSuma-2 VeinSum. Thiago Carbonel – Ms (2007) Élen Tomazela – Ms (2007) RAPM. Amanda Chaves – Ms (2007)")
9
Consistência e aplicabilidade Várias técnicas clássicas de AM (WEKA)
SuPor-2 Consistência e aplicabilidade Várias técnicas clássicas de AM (WEKA) Múltiplas features do modelo do SuPor, otimizadas Múltiplas features (SuPor-2 e Redes Complexas) Categorização de Textos via extratos GoogleSets™ + SuPor-2 Fonte de informação para construção de extratos Fuzzy Supor-2 Fuzzy: Sistema Híbrido para SA extrativa
 Múltiplas features do modelo do SuPor, otimizadas. Múltiplas features (SuPor-2 e Redes Complexas) Categorização de Textos via extratos. GoogleSets™ + SuPor-2. Fonte de informação para construção de extratos. Fuzzy. Supor-2 Fuzzy: Sistema Híbrido para SA extrativa.")
10
SuPor-2 (retreino do SuPor)
System ROUGE NGram(1,1) SuPor-2 0,5839 *TextRank+Thesaurus 0,5603 TextRank+Stem+StopwordsRem 0,5426 … Baseline 0,4963 * Mihalcea and Tarau (2004) Mihalcea (2005) – TeMário
 SuPor-2. 0,5839. *TextRank+Thesaurus. 0,5603. TextRank+Stem+StopwordsRem. 0,5426. … Baseline. 0,4963. * Mihalcea and Tarau (2004) Mihalcea (2005) – TeMário.")
11
SuPor-2 & Redes Complexas
Features do SuPor-2 (Leite&Rino, 06) + features de redes complexas (Antiqueira, 07) 37 sistemas distintos Método automático de seleção de features (Correlation Feature Selection – Hall, 2000) 4 classificadores: Bayes, SVM, C4.5 e Regressão Logística Resultados ligeiramente superiores SuPor-2 (0,5839) TextRank (Mihalcea,2005)
 + features de redes complexas (Antiqueira, 07) 37 sistemas distintos. Método automático de seleção de features (Correlation Feature Selection – Hall, 2000) 4 classificadores: Bayes, SVM, C4.5 e Regressão Logística. Resultados ligeiramente superiores. SuPor-2 (0,5839) TextRank (Mihalcea,2005)")
12
SuPor-2 & Categorização de Textos
Categorizar os extratos é menos custoso que o texto original Extratos “seletores” de atributos importantes Avaliação Corpus Jornal MT (855 textos de 5 categorias) 3-fold cross validation Stemmer Orengo Sumarizar para categorizar piora Resultados ruins tb com GistSumm
 3-fold cross validation. Stemmer Orengo. Sumarizar para categorizar piora. Resultados ruins tb com GistSumm.")
13
SuPor-2 & GoogleSets GoogleSets (http://labs.google.com/sets)
Determinação de grupos similares de palavras Em conjunto com o TextRank (Mihalcea, 2005) Enriquecer o cálculo de similaridades do TextRank Originalmente medida dos co-senos Thesaurus já havia sido utilizado (Leite et al., 2007) com bons resultados GoogleSets não trouxe melhora significativa para o PORT Verificar potencial para INGL
 Enriquecer o cálculo de similaridades do TextRank. Originalmente medida dos co-senos. Thesaurus já havia sido utilizado (Leite et al., 2007) com bons resultados. GoogleSets não trouxe melhora significativa para o PORT. Verificar potencial para INGL.")
14
SuPor-2 Fuzzy Híbrido Parte das features do SuPor-2 (12 ao todo)
Sistema de Classificação Fuzzy + Algoritmos Genéticos para Treino Parte das features do SuPor-2 (12 ao todo) Classificação Fuzzy Abordagem de Pittsburgh Utilizada para avaliar sentenças candidatas Treino dirigido pelas medidas da ROUGE-1 Sistema retroalimentado pela medida ROUGE-1 dos extratos que produz Em fase de ajustes no treino visando melhores resultados
 Classificação Fuzzy. Abordagem de Pittsburgh. Utilizada para avaliar sentenças candidatas. Treino dirigido pelas medidas da ROUGE-1. Sistema retroalimentado pela medida ROUGE-1 dos extratos que produz. Em fase de ajustes no treino visando melhores resultados.")
15
Leite, Rino, Pardo & Nunes (2007) Leite & Rino (2006)
SuPor-2 Leite & Rino (2008) PROPOR’2008 Leite, Rino, Pardo & Nunes (2007) Workshop on TextGraphs-2, NAACL2007 Leite & Rino (2006) IBERAMIA/SBIA'2006 TIL’2006, Poster
 PROPOR’2008. Leite, Rino, Pardo & Nunes (2007) Workshop on TextGraphs-2, NAACL2007. Leite & Rino (2006) IBERAMIA/SBIA TIL’2006, Poster.")
16
IdealXtractor: Geração dos extratos ideais
Dados de referência para avaliações automáticas de SA

17
IdealXtractor Medida do Cosseno (Salton, 1989)
K-means (Leader & Kohonen)
")
18
Extrato Ideal TeMário-2006

19
IdealXtractor: Perspectivas
Comparar extratos ideais IdealXtractor GEI (Thiago Pardo) Usar extratos ideais para avaliação de outros sistemas extrativos
 Usar extratos ideais para avaliação de outros sistemas extrativos.")
20
VeinSum (pós RHeSuma-2)
Reimplementação do RheSumaRST Formato de entrada mais adequado a acoplamentos as demais módulos de um sistema completo de SA Sumários nos limites da taxa de compressão Utilização adequada do domínio de acessibilidade referencial Implementação da Teoria das Veias (Cristea et al., 1998)
")
21
VeinSum AddVeins Elaboration anotada com veins e acc motivation Árvore
RST AddVeins anotada com veins e acc MarcuRank Ranqueamento RankSum Sumário

22
Corpus anotado com CCRs
VeinSum Corpus Summ-it Subconjunto de 12 textos (Collovini et al., 2007) Apenas SNs definidos Corpus anotado com CCRs Guidelines e ferramenta de suporte: MMAX (Müller & Strube, 2001) Anotação em XML Corpus anotado com estruturas retóricas (RST) Guidelines (Carlson & Marcu, 2001) Ferramenta de suporte: RSTTool (O´Donnel, 2000)
 Apenas SNs definidos. Corpus anotado com CCRs. Guidelines e ferramenta de suporte: MMAX (Müller & Strube, 2001) Anotação em XML. Corpus anotado com estruturas retóricas (RST) Guidelines (Carlson & Marcu, 2001) Ferramenta de suporte: RSTTool (O´Donnel, 2000)")
23
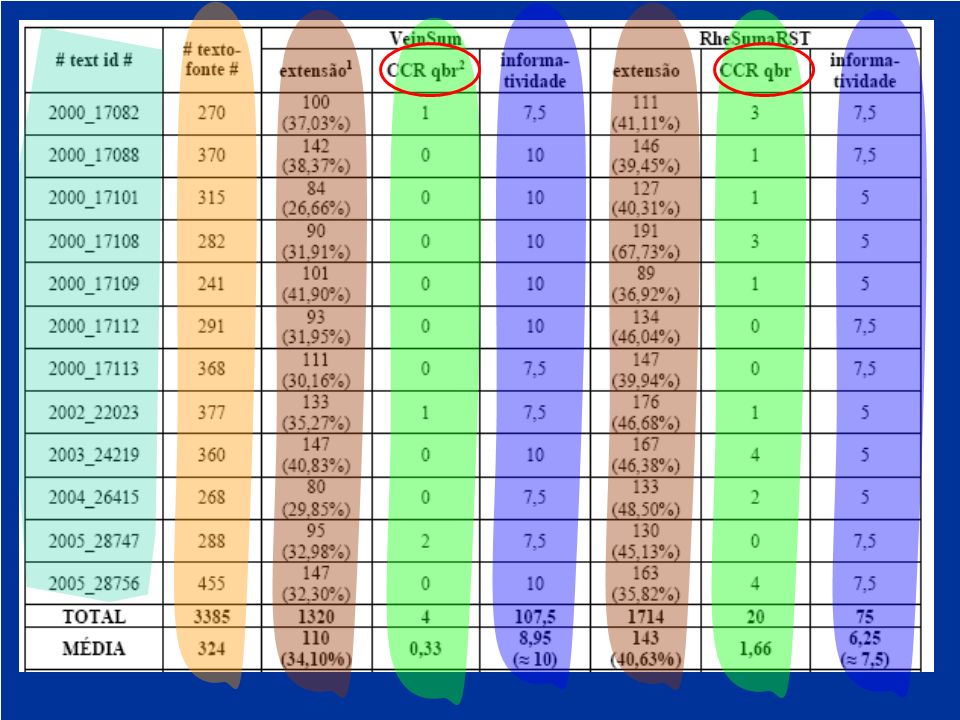
VeinSum Informatividade Avaliação subjetiva ROUGE-1

25
AVALIAÇÃO DA INFORMATIVIDADE – MEDIDA ROUGE

26
Carbonel, Pelizzoni & Rino (2007) Pelizzoni, Carbonel & Rino (2006)
VeinSum Collovini et al. (2007) Carbonel, Pelizzoni & Rino (2007) TIL2007 Pelizzoni, Carbonel & Rino (2006) LREC 2006 Alignment for Black-Box Evaluation Carbonel et al. (2006) TIL2006 Várias outras GEL, INPLA, SILEL
 Carbonel, Pelizzoni & Rino (2007) TIL2007. Pelizzoni, Carbonel & Rino (2006) LREC Alignment for Black-Box Evaluation. Carbonel et al. (2006) TIL2006. Várias outras. GEL, INPLA, SILEL.")
27
Algoritmo de Mitkov algorithm
RAPM Algoritmo de Mitkov algorithm AR do PORT Indicadores de antecedentes de Mitkov Adaptados ao PORT Gêneros distintos Thiago Coelho – Ms Algoritmo de Lappin e Leass Corpora jurídico, literário e jornalístico

28
RAPM: Avaliação geral 8 versões diferentes Taxa de sucesso (%) RAPM_8
67,01 RAPM_3 66,02 RAPM_6_NNP 64,94 RAPM_6_PN 63,40 RAPM_2 62,50 RAPM_5 61,45 RAPM_4 61,21 RAPM_6_SP 60,26

29
RAPM vs. Algor. Lappin & Leass
Taxa de sucesso (%) Corpus RAPM_8 Coelho (2005) Jornalístico 67,01 43,56 Literário 38 31,32 Jurídico 54 35,15
 Corpus. RAPM_8. Coelho (2005) Jornalístico. 67,01. 43,56. Literário ,32. Jurídico ,15.")
30
LR = Lexical Reiteration INP = Indefinite NP PNP = Prepositional NP
RAPM: Avaliação geral 8 versões diferentes RAPM_8 FNP = First NP LR = Lexical Reiteration INP = Indefinite NP PNP = Prepositional NP RD = Referential Distance SP = Syntactic Parallelism NNP = Nearest NP PN = Proper Noun

31
RAPM Chaves &Rino (2008) Chaves & Rino (2007) PROPOR’2008
VI Encontro de Lingüística de Corpus

32
Síntese: Produção escrita
Participação em concursos CLEF 2005 Artigos revistas (1) Revista Iberoamericana de Inteligencia Artificial Artigos conferências internacionais PROPOR2008, NAACL2007, IBERAMIA/SBIA'2006, LREC2006 (5) Artigos conferências nacionais TIL2006 (3) TIL2007 (2) Outras (GEL, INPLA, SILEL)
 Revista Iberoamericana de Inteligencia Artificial. Artigos conferências internacionais. PROPOR2008, NAACL2007, IBERAMIA/SBIA 2006, LREC2006 (5) Artigos conferências nacionais. TIL2006 (3) TIL2007 (2) Outras (GEL, INPLA, SILEL)")
33
Síntese: Sistemas automáticos
Sumarizadores extrativos (n, n>4) Gerador de extrato ideal (1) Sumarizador fundamental (1) Resolvedor de anáforas pronominais (1)
 Gerador de extrato ideal (1) Sumarizador fundamental (1) Resolvedor de anáforas pronominais (1)")
34
Summ-it em suas diversas formas
Síntese: Corpora Summ-it em suas diversas formas Manualmente anotado com infos referenciais Manualmente anotado com RST Árvores RST dos 50 textos do Summ-it Adição de conhecimento especialista (RhetDB) Árvores RST dos 50 textos do Summ-it com infos subjetivas do analista de discurso, especialista em RST Extratos (grupos de 50) VeinSum, GistSumm, SuPor-2
 Árvores RST dos 50 textos do Summ-it com infos subjetivas do analista de discurso, especialista em RST. Extratos (grupos de 50) VeinSum, GistSumm, SuPor-2.")
35
Síntese: Realizado vs. proposta original
Foco em RI Abandonada (temporariamente, talvez) Novas perspectivas Aprimoramento dos sumarizadores automáticos extrativos Exploração de novos métodos extrativos Produção de dados e recursos diversos Proposta de novo sumarizador profundo (RST + Teoria das Veias)
 Novas perspectivas. Aprimoramento dos sumarizadores automáticos extrativos. Exploração de novos métodos extrativos. Produção de dados e recursos diversos. Proposta de novo sumarizador profundo (RST + Teoria das Veias)")
36
Tarefas de avaliação mais robustas e escaláveis
Perspectivas futuras Foco em RI Talvez? Tarefas de avaliação mais robustas e escaláveis Perspectiva de construção de um sumarizador fundamental completo Acoplamento do VeinSum ao DiZer? Agregação de conhecimento e experiência Grupo da PUC-RS Grupo do ICMC-USP

37
FIM FIM

38
SuPor-2 para Categorização de Textos
Naive-Bayes 70 - 50 30 0* Taxa de Acerto Taxa de Compressão

39
Élen Investigação das etiquetas providas pelo parser;
Objetivo: Utilizar as etiquetas semânticas provenientes do parser PALAVRAS (Bick, 2000) para o reconhecimento automático de termos co-referentes em prol da manutenção coesiva em sumários produzidos automaticamente. Tarefas realizadas até o momento Investigação das etiquetas providas pelo parser; Levantamento de possíveis problemas de reconhecimento automático de Cadeias de Co-referência (CCRs);
 para o reconhecimento automático de termos co-referentes em prol da manutenção coesiva em sumários produzidos automaticamente. Tarefas realizadas até o momento. Investigação das etiquetas providas pelo parser; Levantamento de possíveis problemas de reconhecimento automático de Cadeias de Co-referência (CCRs);")
40
Problemas encontrados até o momento
não existe uma ontologia pronta que mostre a real hierarquia entre as etiquetas; ex.: como se dará o reconhecimento entre itens como: alvo (Labst) e mira (act-d)? Inconsistências entre etiquetas; ex: gás carbônico (cm-chem) e CO2 (mat) A maioria das entidades mencionadas utilizadas no corpus Summ-it (Collovini, 2007) não é etiquetada pela ferramenta; ex: Brasil (sem etiqueta); Tailândia (inst) instituição;
 e mira (act-d) Inconsistências entre etiquetas; ex: gás carbônico (cm-chem) e CO2 (mat) A maioria das entidades mencionadas utilizadas no corpus Summ-it (Collovini, 2007) não é etiquetada pela ferramenta; ex: Brasil (sem etiqueta); Tailândia (inst) instituição;")
41
Problemas encontrados até o momento
Desambiguação “ineficiente”; ex: a física nuclear Eva Maria – física (domain) Impossibilidade de uso da WordNet-Br para a identificação de hipônimos e hiperônimos, sendo que a sua base de dados só engloba os verbos até o momento; ex: canídeos (Adom) e cachorros (Azo) Alguns itens lexicais não são identificados corretamente como uma única unidade; ex: vaso sangüíneo é etiquetado como: vaso (container) e sangüíneo não recebe etiqueta
 Impossibilidade de uso da WordNet-Br para a identificação de hipônimos e hiperônimos, sendo que a sua base de dados só engloba os verbos até o momento; ex: canídeos (Adom) e cachorros (Azo) Alguns itens lexicais não são identificados corretamente como uma única unidade; ex: vaso sangüíneo é etiquetado como: vaso (container) e sangüíneo não recebe etiqueta.")
Apresentações semelhantes