Carregar apresentação
A apresentação está carregando. Por favor, espere

1
Análise Exploratória de Dados R – LIG/08 – maio de 2008

2
Objetivos Análise de duas variáveis quantitativas: Análise de duas variáveis quantitativas: traçar diagramas de dispersão, para avaliar possíveis relações entre as duas variáveis; traçar diagramas de dispersão, para avaliar possíveis relações entre as duas variáveis; calcular o coeficiente de correlação entre as duas variáveis; calcular o coeficiente de correlação entre as duas variáveis; obter uma reta que se ajuste aos dados segundo o critério de mínimos quadrados. obter uma reta que se ajuste aos dados segundo o critério de mínimos quadrados.

3
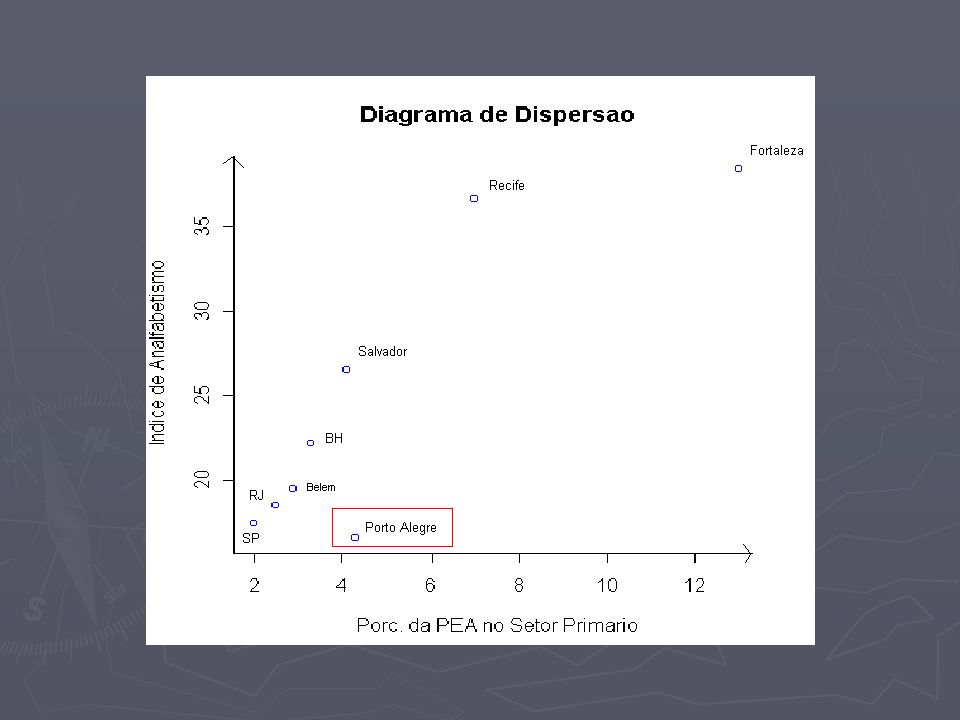
DIAGRAMAS DE DISPERSÃO E CORRELAÇÃO DADOS: Começaremos a aula de hoje trabalhando com dados referentes à porcentagem da população economicamente ativa empregada no setor primário e o respectivo índice de analfabetismo para algumas regiões metropolitanas brasileiras (exercício 11 do capítulo 4). DADOS: Começaremos a aula de hoje trabalhando com dados referentes à porcentagem da população economicamente ativa empregada no setor primário e o respectivo índice de analfabetismo para algumas regiões metropolitanas brasileiras (exercício 11 do capítulo 4).
..")
4
DADOS: Fonte: Indicadores Sociais para Áreas Urbanas - IBGE - 1977. volta

5
PROBLEMA Será que existe alguma relação entre as variáveis porcentagem da população economicamente ativa no setor primário e índice de analfabetismo? Será que existe alguma relação entre as variáveis porcentagem da população economicamente ativa no setor primário e índice de analfabetismo? Em caso afirmativo, como quantificar esta relação? Em caso afirmativo, como quantificar esta relação?

6
Diagrama de dispersão Vejamos como obter o diagrama de dispersão destes dados usando o R. Vejamos como obter o diagrama de dispersão destes dados usando o R. Primeiro, vamos ler os dados: Primeiro, vamos ler os dados: dados= read.table("http://www.im.ufrj.br/~flavia/aed06/analfab.txt) dados= read.table("http://www.im.ufrj.br/~flavia/aed06/analfab.txt) names(dados)=c(RM,SP,AN) #comando que fornece nomes para as variáveis names(dados)=c(RM,SP,AN) #comando que fornece nomes para as variáveis
=c(RM,SP,AN) #comando que fornece nomes para as variáveis names(dados)=c(RM,SP,AN) #comando que fornece nomes para as variáveis.")
7
DIAGRAMA DE DISPERSÃO plot(dados$SP, dados$AN, xlab="Porc. da PEA no Setor Primario", ylab="Indice de Analfabetismo", main= "Diagrama de Dispersao,col=blue) plot(dados$SP, dados$AN, xlab="Porc. da PEA no Setor Primario", ylab="Indice de Analfabetismo", main= "Diagrama de Dispersao,col=blue)
 plot(dados$SP, dados$AN, xlab= Porc. da PEA no Setor Primario , ylab= Indice de Analfabetismo , main= Diagrama de Dispersao,col=blue).")
8
Análise dos dados Você diria que há dependência linear entre estas variáveis? Você diria que há dependência linear entre estas variáveis? Calcule a correlação entre elas. Calcule a correlação entre elas. cor(dados$SP,dados$AN) cor(dados$SP,dados$AN) 0.866561 (0.867) 0.866561 (0.867)
 cor(dados$SP,dados$AN) (0.867) (0.867).")
9
CORRELAÇÃO Há alguma região com comportamento diferente das demais? Há alguma região com comportamento diferente das demais? Em caso afirmativo, retire-a da base de dados e recalcule a correlação. Em caso afirmativo, retire-a da base de dados e recalcule a correlação. dados

11
Porto Alegre Retirando os dados da região metropolitana de Porto Alegre temos a seguinte correlação: (observe que Porto Alegre está na linha 6 da base de dados). Retirando os dados da região metropolitana de Porto Alegre temos a seguinte correlação: (observe que Porto Alegre está na linha 6 da base de dados). dad=matrix(0,7,2) dad=matrix(0,7,2) dad[,1]=c(dados[1:5,2],dados[7:8,2]) dad[,1]=c(dados[1:5,2],dados[7:8,2]) dad[,2]=c(dados[1:5,3],dados[7:8,3]) dad[,2]=c(dados[1:5,3],dados[7:8,3]) cor(dad[,1],dad[,2]) cor(dad[,1],dad[,2]) 0.9081915 (0.908) 0.9081915 (0.908) porcentagem de variação em relação à correlação inicial: 4,8% (em valor absoluto) porcentagem de variação em relação à correlação inicial: 4,8% (em valor absoluto)
. dad=matrix(0,7,2) dad=matrix(0,7,2) dad[,1]=c(dados[1:5,2],dados[7:8,2]) dad[,1]=c(dados[1:5,2],dados[7:8,2]) dad[,2]=c(dados[1:5,3],dados[7:8,3]) dad[,2]=c(dados[1:5,3],dados[7:8,3]) cor(dad[,1],dad[,2]) cor(dad[,1],dad[,2]) (0.908) (0.908) porcentagem de variação em relação à correlação inicial: 4,8% (em valor absoluto) porcentagem de variação em relação à correlação inicial: 4,8% (em valor absoluto).")
12
A porcentagem de variação foi calculada da seguinte forma: r é a correlação calculada com base em todas as observações r(i) é a correlação calculada retirando-se a i-ésima observação.
 é a correlação calculada retirando-se a i-ésima observação.")
14
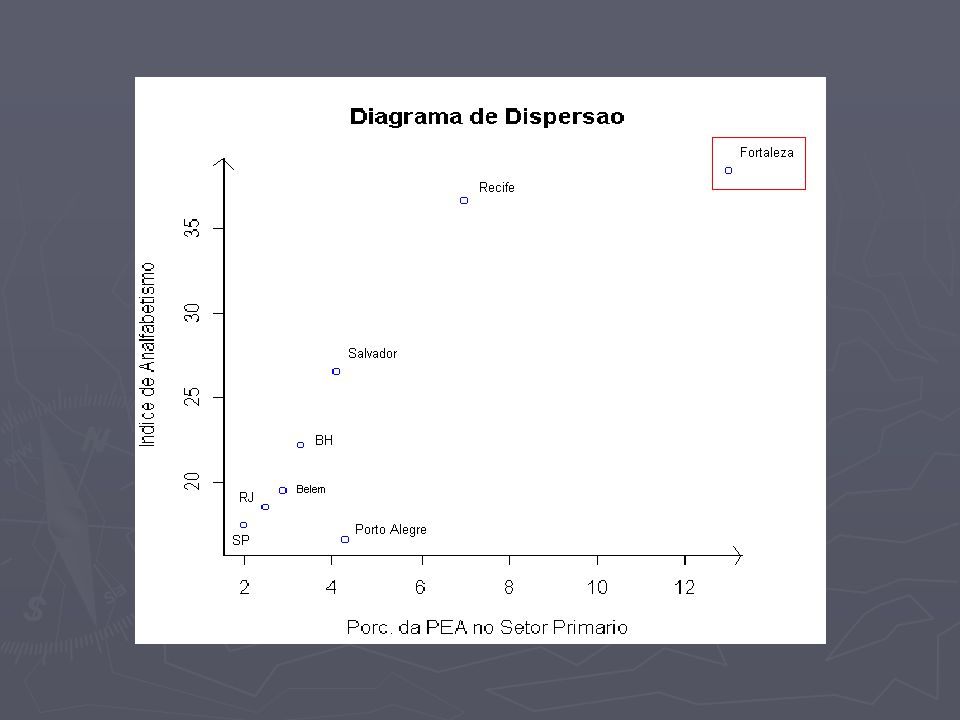
Fortaleza dad[,1]=c(dados[1:7,2]) dad[,1]=c(dados[1:7,2]) dad[,2]=c(dados[1:7,3]) dad[,2]=c(dados[1:7,3]) cor(dad[,1],dad[,2]) cor(dad[,1],dad[,2]) 0.8581972 (0.858) 0.8581972 (0.858) porcentagem de variação em relação à correlação inicial: 0,96% (em valor absoluto) porcentagem de variação em relação à correlação inicial: 0,96% (em valor absoluto)
![Fortaleza dad[,1]=c(dados[1:7,2]) dad[,1]=c(dados[1:7,2]) dad[,2]=c(dados[1:7,3]) dad[,2]=c(dados[1:7,3]) cor(dad[,1],dad[,2]) cor(dad[,1],dad[,2]) (0.858) (0.858) porcentagem de variação em relação à correlação inicial: 0,96% (em valor absoluto) porcentagem de variação em relação à correlação inicial: 0,96% (em valor absoluto)](http://images.slideplayer.com.br/5/1600600/slides/slide_14.jpg "Fortaleza dad[,1]=c(dados[1:7,2]) dad[,1]=c(dados[1:7,2]) dad[,2]=c(dados[1:7,3]) dad[,2]=c(dados[1:7,3]) cor(dad[,1],dad[,2]) cor(dad[,1],dad[,2]) (0.858) (0.858) porcentagem de variação em relação à correlação inicial: 0,96% (em valor absoluto) porcentagem de variação em relação à correlação inicial: 0,96% (em valor absoluto)")
16
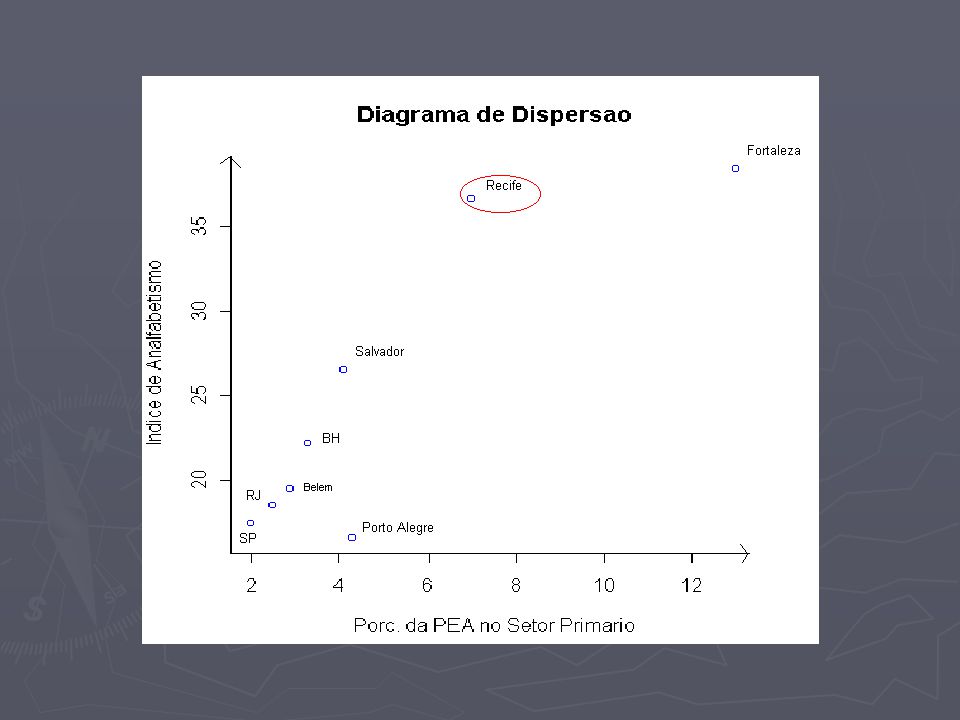
Recife dad[,2]=c(dados[1:6,3],dados[8,3]) dad[,2]=c(dados[1:6,3],dados[8,3]) dad[,1]=c(dados[1:6,2],dados[8,2]) dad[,1]=c(dados[1:6,2],dados[8,2]) cor(dad[,1],dad[,2]) cor(dad[,1],dad[,2]) 0.9158657 (0.916) 0.9158657 (0.916) porcentagem de variação em relação à correlação inicial: 5,7% (em valor absoluto) porcentagem de variação em relação à correlação inicial: 5,7% (em valor absoluto)
![Recife dad[,2]=c(dados[1:6,3],dados[8,3]) dad[,2]=c(dados[1:6,3],dados[8,3]) dad[,1]=c(dados[1:6,2],dados[8,2]) dad[,1]=c(dados[1:6,2],dados[8,2]) cor(dad[,1],dad[,2]) cor(dad[,1],dad[,2]) (0.916) (0.916) porcentagem de variação em relação à correlação inicial: 5,7% (em valor absoluto) porcentagem de variação em relação à correlação inicial: 5,7% (em valor absoluto)](http://images.slideplayer.com.br/5/1600600/slides/slide_16.jpg "Recife dad[,2]=c(dados[1:6,3],dados[8,3]) dad[,2]=c(dados[1:6,3],dados[8,3]) dad[,1]=c(dados[1:6,2],dados[8,2]) dad[,1]=c(dados[1:6,2],dados[8,2]) cor(dad[,1],dad[,2]) cor(dad[,1],dad[,2]) (0.916) (0.916) porcentagem de variação em relação à correlação inicial: 5,7% (em valor absoluto) porcentagem de variação em relação à correlação inicial: 5,7% (em valor absoluto)")
18
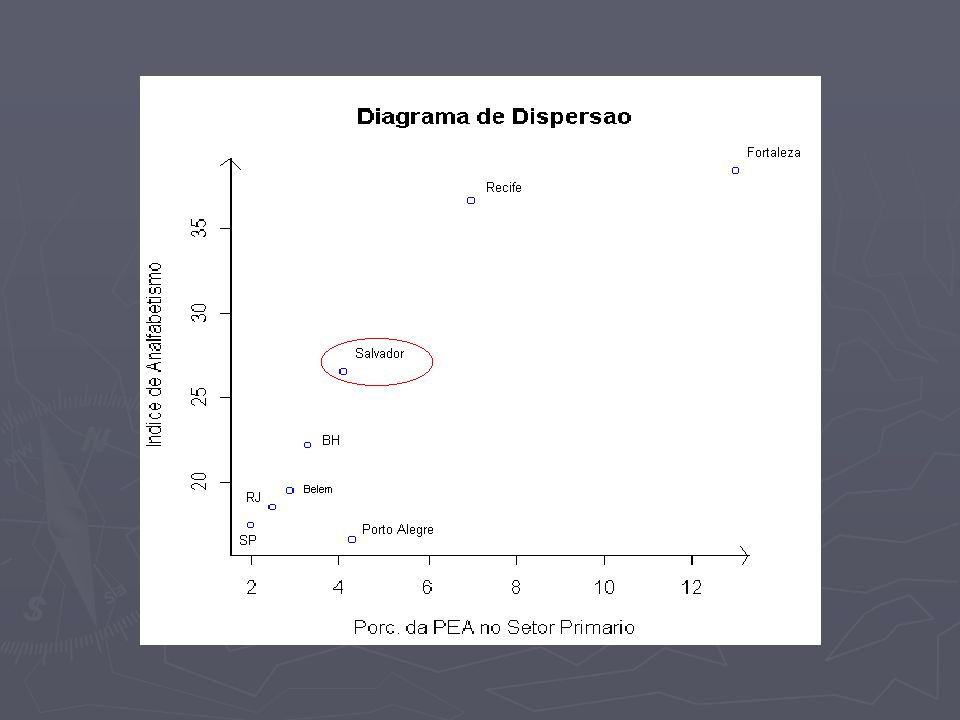
Salvador dad[,1]=c(dados[1:4,2],dados[6:8,2]) dad[,1]=c(dados[1:4,2],dados[6:8,2]) dad[,2]=c(dados[1:4,3],dados[6:8,3]) dad[,2]=c(dados[1:4,3],dados[6:8,3]) cor(dad[,1],dad[,2]) cor(dad[,1],dad[,2]) 0.8822678 (0.882) 0.8822678 (0.882) porcentagem de variação em relação à correlação inicial: 1,8% (em valor absoluto) porcentagem de variação em relação à correlação inicial: 1,8% (em valor absoluto)
![Salvador dad[,1]=c(dados[1:4,2],dados[6:8,2]) dad[,1]=c(dados[1:4,2],dados[6:8,2]) dad[,2]=c(dados[1:4,3],dados[6:8,3]) dad[,2]=c(dados[1:4,3],dados[6:8,3]) cor(dad[,1],dad[,2]) cor(dad[,1],dad[,2]) (0.882) (0.882) porcentagem de variação em relação à correlação inicial: 1,8% (em valor absoluto) porcentagem de variação em relação à correlação inicial: 1,8% (em valor absoluto)](http://images.slideplayer.com.br/5/1600600/slides/slide_18.jpg "Salvador dad[,1]=c(dados[1:4,2],dados[6:8,2]) dad[,1]=c(dados[1:4,2],dados[6:8,2]) dad[,2]=c(dados[1:4,3],dados[6:8,3]) dad[,2]=c(dados[1:4,3],dados[6:8,3]) cor(dad[,1],dad[,2]) cor(dad[,1],dad[,2]) (0.882) (0.882) porcentagem de variação em relação à correlação inicial: 1,8% (em valor absoluto) porcentagem de variação em relação à correlação inicial: 1,8% (em valor absoluto)")
19
Resumo RM retirada variação % Porto Alegre4,8 Fortaleza 0,96 Salvador 1,8 Recife 5,7

20
Comentários As regiões metropolitanas que mais influenciaram no valor da correlação foram Porto Alegre e Recife. As regiões metropolitanas que mais influenciaram no valor da correlação foram Porto Alegre e Recife. Porto Alegre tem um comportamento diferente, pois sua taxa de analfabetismo é pequena comparada a sua PEA e as demais regiões. Porto Alegre tem um comportamento diferente, pois sua taxa de analfabetismo é pequena comparada a sua PEA e as demais regiões.

21
Comentários Recife, ao contrário, tem uma taxa de analfabetismo alta demais comparada a sua PEA e as demais regiões. Recife, ao contrário, tem uma taxa de analfabetismo alta demais comparada a sua PEA e as demais regiões. Fortaleza, apesar de ser um ponto afastado dos demais, mantém o padrão da maior parte dos pontos. Fortaleza, apesar de ser um ponto afastado dos demais, mantém o padrão da maior parte dos pontos.

22
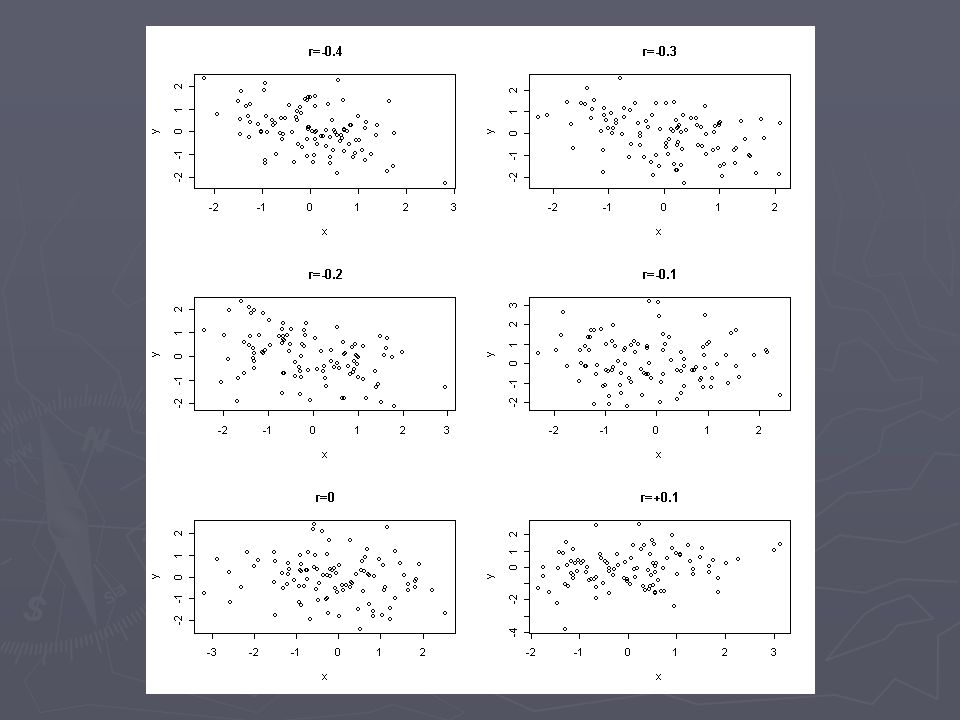
Gráficos de ilustração

25
Cuidados na interpretação Uma correlação alta (próxima de 1 ou -1) pode indicar forte dependência linear entre as variáveis. Nesse caso, os pontos no diagrama de dispersão espalham-se em torno de uma reta. Uma correlação alta (próxima de 1 ou -1) pode indicar forte dependência linear entre as variáveis. Nesse caso, os pontos no diagrama de dispersão espalham-se em torno de uma reta. Pode haver variáveis cuja correlação é próxima de 1 (ou -1), mas, na verdade, não são diretamente relacionadas. (correlação espúria) Pode haver variáveis cuja correlação é próxima de 1 (ou -1), mas, na verdade, não são diretamente relacionadas. (correlação espúria) Uma correlação zero ou próxima de zero indica ausência de linearidade, podendo significar ausência de relação entre as variáveis ou outro tipo de dependência entre elas. Uma correlação zero ou próxima de zero indica ausência de linearidade, podendo significar ausência de relação entre as variáveis ou outro tipo de dependência entre elas.
 pode indicar forte dependência linear entre as variáveis. Nesse caso, os pontos no diagrama de dispersão espalham-se em torno de uma reta. Pode haver variáveis cuja correlação é próxima de 1 (ou -1), mas, na verdade, não são diretamente relacionadas. (correlação espúria) Pode haver variáveis cuja correlação é próxima de 1 (ou -1), mas, na verdade, não são diretamente relacionadas. (correlação espúria) Uma correlação zero ou próxima de zero indica ausência de linearidade, podendo significar ausência de relação entre as variáveis ou outro tipo de dependência entre elas. Uma correlação zero ou próxima de zero indica ausência de linearidade, podendo significar ausência de relação entre as variáveis ou outro tipo de dependência entre elas..")
26
Exemplo 2 dados= read.table("http://www.im.ufrj.br/~flavia/aed06/relquadratica.txt", header=T) dados= read.table("http://www.im.ufrj.br/~flavia/aed06/relquadratica.txt", header=T) cor(dados$x,dados$y) cor(dados$x,dados$y) 0 Observe que existe relação de dependência entre x e y, porém essa. relação NÃO é linear.

27
Correlação: Cuidados na interpretação Uma correlação amostral entre duas variáveis próxima de 1 ou -1 pode só indicar que as variáveis crescem no mesmo sentido (ou em sentidos contrários), e não que, aumentos sucessivos em uma, acarretarão aumentos sucessivos (ou diminuições sucessivas) na outra. Uma correlação amostral entre duas variáveis próxima de 1 ou -1 pode só indicar que as variáveis crescem no mesmo sentido (ou em sentidos contrários), e não que, aumentos sucessivos em uma, acarretarão aumentos sucessivos (ou diminuições sucessivas) na outra.
, e não que, aumentos sucessivos em uma, acarretarão aumentos sucessivos (ou diminuições sucessivas) na outra..")
28
Reta de mínimos quadrados Quando as variáveis em análise são altamente correlacionadas e de fato pode haver uma relação de causa e efeito entre elas, o problema de fazer previsão do valor de uma delas dado o valor da outra variável pode ser resolvido através de uma regressão linear simples (ajuste pela reta de mínimos quadrados). Quando as variáveis em análise são altamente correlacionadas e de fato pode haver uma relação de causa e efeito entre elas, o problema de fazer previsão do valor de uma delas dado o valor da outra variável pode ser resolvido através de uma regressão linear simples (ajuste pela reta de mínimos quadrados). Em geral, uma das variáveis é considerada como variável que pode ser controlada de alguma forma variável explicativa (independente - preditora) e a outra, sobre a qual deseja-se fazer previsões, é chamada variável resposta (dependente). Em geral, uma das variáveis é considerada como variável que pode ser controlada de alguma forma variável explicativa (independente - preditora) e a outra, sobre a qual deseja-se fazer previsões, é chamada variável resposta (dependente).
. Em geral, uma das variáveis é considerada como variável que pode ser controlada de alguma forma variável explicativa (independente - preditora) e a outra, sobre a qual deseja-se fazer previsões, é chamada variável resposta (dependente). Em geral, uma das variáveis é considerada como variável que pode ser controlada de alguma forma variável explicativa (independente - preditora) e a outra, sobre a qual deseja-se fazer previsões, é chamada variável resposta (dependente)..")
29
EXEMPLO 3: Fonte: http://lib.stat.cmu.edu/DASL/ Fonte: http://lib.stat.cmu.edu/DASL/http://lib.stat.cmu.edu/DASL/ Trabalharemos com uma base de dados sobre o hábito de fumar e mortalidade por câncer de pulmão. Trabalharemos com uma base de dados sobre o hábito de fumar e mortalidade por câncer de pulmão.

30
Exemplo 3 (cont.) Descrição: Os dados sumariam um estudo entre homens distribuídos em 25 grupos classificados por tipo de ocupação na Inglaterra. Descrição: Os dados sumariam um estudo entre homens distribuídos em 25 grupos classificados por tipo de ocupação na Inglaterra. Dois índices são apresentados para cada grupo. Dois índices são apresentados para cada grupo.

31
Exemplo 3: variáveis índice de fumo: razão do número médio de cigarros fumados por dia por homem no particular grupo de ocupação sobre a média global de cigarros fumados por dia, calculada levando-se em contas todos os homens. (média do grupo sobre média global) índice de fumo: razão do número médio de cigarros fumados por dia por homem no particular grupo de ocupação sobre a média global de cigarros fumados por dia, calculada levando-se em contas todos os homens. (média do grupo sobre média global) índice de mortalidade: razão da taxa de mortes causadas por câncer de pulmão entre os homens de um particular grupo de ocupação sobre a taxa global de mortes por câncer de pulmão, calculada levando-se em conta todos os homens. (taxa no grupo sobre taxa global) índice de mortalidade: razão da taxa de mortes causadas por câncer de pulmão entre os homens de um particular grupo de ocupação sobre a taxa global de mortes por câncer de pulmão, calculada levando-se em conta todos os homens. (taxa no grupo sobre taxa global) Número de observações: 25 Número de observações: 25
 índice de fumo: razão do número médio de cigarros fumados por dia por homem no particular grupo de ocupação sobre a média global de cigarros fumados por dia, calculada levando-se em contas todos os homens. (média do grupo sobre média global) índice de mortalidade: razão da taxa de mortes causadas por câncer de pulmão entre os homens de um particular grupo de ocupação sobre a taxa global de mortes por câncer de pulmão, calculada levando-se em conta todos os homens. (taxa no grupo sobre taxa global) índice de mortalidade: razão da taxa de mortes causadas por câncer de pulmão entre os homens de um particular grupo de ocupação sobre a taxa global de mortes por câncer de pulmão, calculada levando-se em conta todos os homens. (taxa no grupo sobre taxa global) Número de observações: 25 Número de observações: 25.")
32
Fumo versus câncer Nomes das variáveis: Nomes das variáveis: 1.Grupo de ocupação: grupo 1.Grupo de ocupação: grupo 2.Índice de fumo: ifumo (100 = base) 2.Índice de fumo: ifumo (100 = base) ifumo=100: número médio de cigarros por dia para o grupo é igual ao número médio global de cigarros fumados por dia. ifumo=100: número médio de cigarros por dia para o grupo é igual ao número médio global de cigarros fumados por dia. ifumo>100 indica grupo que fuma em média mais que o geral; ifumo>100 indica grupo que fuma em média mais que o geral; ifumo<100, grupo que fuma em média menos que o geral. ifumo<100, grupo que fuma em média menos que o geral.

33
Fumo versus câncer 3.Índice de Mortalidade: imorte (100 = base) 3.Índice de Mortalidade: imorte (100 = base) imorte=100, número médio de mortes por câncer de pulmão para o grupo é igual ao número médio global de mortes por câncer de pulmão. imorte=100, número médio de mortes por câncer de pulmão para o grupo é igual ao número médio global de mortes por câncer de pulmão. imorte>100 indica grupo com incidência de mortes por câncer de pulmão maior que o geral; imorte>100 indica grupo com incidência de mortes por câncer de pulmão maior que o geral; imorte<100, incidência menor que o geral. imorte<100, incidência menor que o geral. arquivo: fumo.txt em www.im.ufrj.br/~flavia/aed06/ arquivo: fumo.txt em www.im.ufrj.br/~flavia/aed06/

34
Fumo versus câncer Analise estes dados avaliando se há relação entre estes índices. Analise estes dados avaliando se há relação entre estes índices. Construa o diagrama de dispersão e calcule a correlação. Construa o diagrama de dispersão e calcule a correlação.

36
abline Para inserir as retas tracejadas em x=100 e em y=100 após ter construído o diagrama, use os comandos: abline(h=100,lty=2) abline(v=100,lty=2)
 abline(v=100,lty=2)")
37
Indice de fumo versus mortalidade por câncer de pulmão Indice de fumo versus mortalidade por câncer de pulmão A partir do diagrama de dispersão é possível perceber claramente uma correlação positiva entre as duas variáveis em análise. cor(dados$ifumo,dados$imorte) [1] 0.7162398 No contexto deste exemplo faz sentido prever o índice de mortalidade por câncer de pulmão num particular grupo, dado o índice de fumo do grupo.
 [1] No contexto deste exemplo faz sentido prever o índice de mortalidade por câncer de pulmão num particular grupo, dado o índice de fumo do grupo..")
38
Reta de mínimos quadrados O comando no R que calcula os coeficientes da reta de mínimos quadrados é lm(...), de linear model. O comando no R que calcula os coeficientes da reta de mínimos quadrados é lm(...), de linear model. No caso específico deste exemplo podemos pedir reta=lm(dados$imorte~dados$ifumo) No caso específico deste exemplo podemos pedir reta=lm(dados$imorte~dados$ifumo)
, de linear model. No caso específico deste exemplo podemos pedir reta=lm(dados$imorte~dados$ifumo) No caso específico deste exemplo podemos pedir reta=lm(dados$imorte~dados$ifumo).")
39
Reta de mínimos quadrados Obtém-se Coefficients: (Intercept) dados$ifumo -2.885 1.088 Obtém-se Coefficients: (Intercept) dados$ifumo -2.885 1.088 É o coeficiente linear da reta de mínimos quadrados É o coeficiente angular da reta de mínimos quadrados Modelo ajustado: Indice de morte=-2.885+1.088x(indice de fumo)
 dados$ifumo Obtém-se Coefficients: (Intercept) dados$ifumo É o coeficiente linear da reta de mínimos quadrados É o coeficiente angular da reta de mínimos quadrados Modelo ajustado: Indice de morte= x(indice de fumo)")
40
Gráfico da reta obtida Para inserir o gráfico da reta obtida no ajuste de mínimos quadrados no diagrama de dispersão dos pontos, basta, após obter o diagrama de dispersão, pedir abline(reta$coefficients)
")
41
points Para inserir o ponto médio no gráfico use o comando: points(mean(dados$ifumo),mean(dados$imorte),pch=*,col=red,cex=2)
,mean(dados$imorte),pch=*,col=red,cex=2)")
42
Comentários Depois de proposto um modelo é fundamental realizar a etapa de validação do modelo em que boa parte consiste numa análise exploratória detalhada dos resíduos do modelo. Depois de proposto um modelo é fundamental realizar a etapa de validação do modelo em que boa parte consiste numa análise exploratória detalhada dos resíduos do modelo. Apenas após a etapa de validação e a escolha do modelo é que podemos partir para a etapa de previsões. Apenas após a etapa de validação e a escolha do modelo é que podemos partir para a etapa de previsões.

43
Valores ajustados Após ajustar a reta, usando a função lm várias informações ficam disponíveis, entre elas os valores ajustados da variável resposta pela reta obtida. Após ajustar a reta, usando a função lm várias informações ficam disponíveis, entre elas os valores ajustados da variável resposta pela reta obtida. reta$fitted (#usando reta=lm(dados$imorte~dados$ifumo fornece os valores ajustados) reta$fitted (#usando reta=lm(dados$imorte~dados$ifumo fornece os valores ajustados)
 reta$fitted (#usando reta=lm(dados$imorte~dados$ifumo fornece os valores ajustados).")
44
Resíduos Resíduos da reta de mínimos quadrados: reta$residuals round(reta$residuals,digits=2) 1 2 3 4 5 6 7 8 9 10 11 3.15 -30.11 -1.36 28.66 31.73 -7.04 0.17 14.74 11.18 -20.04 7.92 12 13 14 15 16 17 18 19 20 21 22 18.78 -27.48 -22.92 23.99 22.26 -20.06 4.24 5.82 3.69 -12.73 -11.08 23 24 25 14.13 -19.77 -17.89 O resíduo do modelo é definido pela diferença entre O valor observado da variável resposta e o valo Ajustado pelo modelo.
 O resíduo do modelo é definido pela diferença entre O valor observado da variável resposta e o valo Ajustado pelo modelo.")
45
Análise dos resíduos > stem(round(reta$residuals,digits=2)) -2 | 073000 -0 | 83171 0 | 0344681459 2 | 2492 Ramo-e-folhas dos resíduos: Também avaliamos o histograma, e o gráfico dos resíduos versus os valores ajustados.
) -2 | | | | 2492 Ramo-e-folhas dos resíduos: Também avaliamos o histograma, e o gráfico dos resíduos versus os valores ajustados.")
46
Valores ajustados Valores ajustados da reta de mínimos quadrados: reta$fitted round(reta$fitted,digits=2) 80.85 146.11 124.36 99.34 123.27 108.04 117.83 98.26 92.82 108.04 96.08 110.22 113.48 118.92 120.01 116.74 133.06 141.76 122.18 111.31 91.73 96.08 105.87 79.77 68.89
")
47
Critério de mínimos quadrados Como são obtidos os coeficientes da reta de mínimos quadrados? Como são obtidos os coeficientes da reta de mínimos quadrados? Nossos dados podem ser pensados como uma coleção bivariada: Foi considerado adequado o modelo para explicar.

48
Critério de mínimos quadrados Critério de Mínimos quadrados: escolha e de tal maneira que seja minimizada a soma de quadrados dos resíduos: Critério de Mínimos quadrados: escolha e de tal maneira que seja minimizada a soma de quadrados dos resíduos:

49
Critério de mínimos quadrados Solução: Solução: Coeficiente de inclinação da reta Coeficiente linear da reta (intercepto)
")
50
Resumo: lista de novas funções cor: calcula a correlação; cor: calcula a correlação; lm: ajusta a reta de mínimos quadrados; lm: ajusta a reta de mínimos quadrados; abline: insere uma reta num plot; abline: insere uma reta num plot; points: insere pontos(x,y) num plot; points: insere pontos(x,y) num plot; round(x,digits=n); arredonda os valores em x para n casas decimais. round(x,digits=n); arredonda os valores em x para n casas decimais.
; arredonda os valores em x para n casas decimais..")
Apresentações semelhantes

















>")



