Carregar apresentação
A apresentação está carregando. Por favor, espere

1
Lingüística de Corpus/Córpus: disciplina, metodologia ou abordagem?
We knew that corpora were “hot”, but didn't appreciate just how hot they would turn out to be. Kenneth Church, 1993 at WVLC-1 Lingüística de Corpus/Córpus: disciplina, metodologia ou abordagem? histórias de 1993 (Workshop sobre Very Large Corpora-1) até 2009 Sandra Maria Aluísio SCE 5869 – Tópicos em Processamento de Língua Natural
 até Sandra Maria Aluísio SCE 5869 – Tópicos em Processamento de Língua Natural.")
2
Agenda O que é Córpus? Tipos de pesquisa com córpus e Tipos de usos de córpus Critérios para o projeto/design de um córpus O que é Lingüística de Córpus? Tipologia de córpus Tipologia de Textos Exemplos de córpus desenvolvidos no NILC Fóruns Desafios da área Data Resources

3
Analisem os casos de design
com vistas a uma proposta de córpus. Critiquem e problematizem os 3 casos.

4
Córpus de textos jornalísticos, de 12 anos de um dado jornal de grande circulação, usando amostras dos meses de fevereiro e dezembro de cada ano para lexicografia. Quais textos/registros colocar no córpus? Córpus de teste para a tarefa de simplificação sintática em que um simplificador trabalha com 22 fenômenos diferentes. T = 116 sentenças 3. Córpus para a tarefa de terminologia sobre o assunto nanotecnologia, em Português

5
O que é Córpus? Existem várias definições de córpus na literatura, algumas vezes divergentes (seguem 8, de 92 a 2006): Atkins, Clear & Ostler 1992 A subset of an electronic text library, built according to explicit design criteria for a specific purpose, e.g. the Cobuild corpus, the Longman/Lancaster corpus

6
Terminologia X Lexicografia
Córpus para trabalhos terminológicos irão diferir dos de trabalhos lexicógraficos, pois os usuários possuem diferentes necessidades: Terminólogos precisam adquirir tanto conhecimento lingüístico como conceitual o córpus precisa ser tanto lingüística como conceitualmente rico Terminólogos tratam com campos especializados especialistas do domínio tem um papel importante na construção do córpus. Lexicógrafos geralmente não precisam de ajuda externa Córpus para terminologia pode ser menor do que para lexicografia que necessita de grandes córpus (e.g. o vocabulário do inglês é maior do que 1 milhão de palavras e a variedade no uso é grande). Por exemplo, a editora Collins tem um córpus de 450 milhões de palavras; Cambridge University Press tem 740 milhões; Longman tem 155 milhões.
. Por exemplo, a editora Collins tem um córpus de 450 milhões de palavras; Cambridge University Press tem 740 milhões; Longman tem 155 milhões.")
7
Terminologia X Lexicografia (2)
Os textos de um córpus para trabalho terminológico devem ser completos o que nem sempre acontece para lexicografia Terminólogos devem delimitar o domínio dos textos do córpus, o que não acontece com lexicógrafos Um córpus para terminologia deve ser composto de gêneros instrucionais, científicos e textos de divulgação/vulgarização científica (e.g. Revista Pesquisa Fapesp) para dar conta dos diferentes graus de tecnicalidade, além de uma variedade de autores de um dado campo Por fim, terminólogos precisam de textos atuais, pois focam em novos conceitos e termos que ainda não foram dicionarizados; os textos precisam ser originais e a maioria deve ser escrita por nativos.
 para dar conta dos diferentes graus de tecnicalidade, além de uma variedade de autores de um dado campo. Por fim, terminólogos precisam de textos atuais, pois focam em novos conceitos e termos que ainda não foram dicionarizados; os textos precisam ser originais e a maioria deve ser escrita por nativos.")
8
O que é Córpus? Existem várias definições de córpus na literatura, algumas vezes divergentes (seguem 8, de 92 a 2006): McEnery & Wilson 1996 Crystal, David An Encyclopedic Dictionary of Language and Languages. In principle, any collection of more than one text can be called a corpus, (corpus being Latin for "body", hence a corpus is any body of text). But the term "corpus" when used in the context of modern linguistics tends most frequently to have more specific connotations than this simple definition. These may be considered under four main headings: Sampling and representativeness; Finite size; Machine-readable form; A standard reference "corpus, plural: corpora, A collection of linguistic data, either compiled as written texts or as a transcription of recorded speech. The main purpose of a corpus is to verify a hypothesis about language - for example, to determine how the usage of a particular sound, word, or syntactic construction varies. A computer corpus is a large body of machine-readable texts."
. But the term corpus when used in the context of modern linguistics tends most frequently to have more specific connotations than this simple definition. These may be considered under four main headings: Sampling and representativeness; Finite size; Machine-readable form; A standard reference. corpus, plural: corpora, A collection of linguistic data, either compiled as written texts or as a transcription of recorded speech. The main purpose of a corpus is to verify a hypothesis about language - for example, to determine how the usage of a particular sound, word, or syntactic construction varies. A computer corpus is a large body of machine-readable texts.")
9
Sampling and representativeness; Finite size; Machine-readable form; A standard reference
We are therefore interested in creating a corpus which is maximally representative of the variety under examination, that is, which provides us with an as accurate a picture as possible of the tendencies of that variety, as well as their proportions. With the exception of monitor corpora, it should be noted that it is more often the case that a corpus consists of a finite number of words. Nowadays the term "corpus" nearly always implies the additional feature "machine-readable". This was not always the case as in the past the word "corpus" was only used in reference to printed text. There is often a tacit understanding that a corpus constitutes a standard reference for the language variety that it represents. This presupposes that it will be widely available to other researchers, which is indeed the case with many corpora - e.g. the Brown Corpus, the LOB corpus and the London-Lund corpus. Leech (1992) argues that the corpus is a more powerful methodology from the point of view of the scientific method, as it is open to objective verification of results
 argues that the corpus is a more powerful methodology from the point of view of the scientific method, as it is open to objective verification of results.")
10
O que é Córpus? Garside, Leech & McEnery 1997: Biber, Conrad & Reppen 1998 Traditionally, linguists have used the term corpus to designate a body of naturally-occurring (authentic) language data which can be used as basis for linguistic research. This body of data may consist of written texts, spoken discourses, or both. Often it is designed to represent a particular language or language variety. In the past 35 years, the term corpus has been increasingly applied to a body of language material which exists in electronic form, and which may be processed by computer for various purposes such as linguistics research and language engineering. ...the value of a corpus as a research tool cannot be measured in terms of brute size. The diversity of the corpus ... can be an equally important criterion. Incita a dicotomia: grande vs balanceado/equilibrado A corpus is not simply a collection of texts. Rather, a corpus seeks to represent a language or some part of a language. The appropriate design for a corpus therefore depends upon what it is meant to represent. The representativeness of the corpus, in turn, determines the kinds of research questions that can be addressed and the generalizability of the results of the research. Mostra a importância da Representatividade do córpus
 language data which can be used as basis for linguistic research. This body of data may consist of written texts, spoken discourses, or both. Often it is designed to represent a particular language or language variety. In the past 35 years, the term corpus has been increasingly applied to a body of language material which exists in electronic form, and which may be processed by computer for various purposes such as linguistics research and language engineering. ...the value of a corpus as a research tool cannot be measured in terms of brute size. The diversity of the corpus ... can be an equally important criterion. Incita a dicotomia: grande vs balanceado/equilibrado. A corpus is not simply a collection of texts. Rather, a corpus seeks to represent a language or some part of a language. The appropriate design for a corpus therefore depends upon what it is meant to represent. The representativeness of the corpus, in turn, determines the kinds of research questions that can be addressed and the generalizability of the results of the research. Mostra a importância da. Representatividade do córpus.")
11
O que é Córpus? Kilgarriff & Grefenstette 2003 Sardinha 2004 McEnery and Wilson mix the question “What is a corpus?” with “What is a good corpus (for certain kinds of linguistic study)?” muddying the simple question “Is corpus x good for task y?” with the semantic question “Is x a corpus at all?” ... So the semantic question may be set aside, the definition of corpus should be broad. ...a corpus is a collection of texts when considered as an object of language or literary study. The answer to the question “Is the web a corpus?” is yes. Traz uma definição completa do autor e itemiza os pontos importantes: A origem: os dados devem ser autênticos. O propósito: o corpus deve ter a finalidade de ser um objeto de estudo lingüístico. A composição: o conteúdo do corpus deve ser criteriosamente escolhido ....por exemplo, se é um corpus de português brasileiro que represente a língua portuguesa, tal qual é escrita no Brasil, em sua totalidade, a coleta deve ser guiada por um conjunto de critérios que garanta, entre outras coisas, que o maior número possível de tipos textuais existentes no português brasileiro esteja representado, que haja uma quantidade aceitável de cada tipo e que a seleção seja aleatória, a fim de não contaminar a coleção com variáveis indesejáveis A formatação: os dados devem ser legíveis por computador A representatividade: o corpus deve ser representativo de uma língua ou variedade (do quê? Para quem?) A extensão: o córpus deve ser vasto para ser representativo
 muddying the simple question Is corpus x good for task y with the semantic question Is x a corpus at all ... So the semantic question may be set aside, the definition of corpus should be broad. ...a corpus is a collection of texts when considered as an object of language or literary study. The answer to the question Is the web a corpus is yes. Traz uma definição completa do autor e itemiza os pontos importantes: A origem: os dados devem ser autênticos. O propósito: o corpus deve ter a finalidade de ser um objeto de estudo lingüístico. A composição: o conteúdo do corpus deve ser criteriosamente escolhido. ....por exemplo, se é um corpus de português brasileiro que represente a língua portuguesa, tal qual é escrita no Brasil, em sua totalidade, a coleta deve ser guiada por um conjunto de critérios que garanta, entre outras coisas, que o maior número possível de tipos textuais existentes no português brasileiro esteja representado, que haja uma quantidade aceitável de cada tipo e que a seleção seja aleatória, a fim de não contaminar a coleção com variáveis indesejáveis. A formatação: os dados devem ser legíveis por computador. A representatividade: o corpus deve ser representativo de uma língua ou variedade (do quê Para quem ) A extensão: o córpus deve ser vasto para ser representativo.")
12
Diana Santos, 2006, na Primeira Escola de Verão da Linguateca
O que é Córpus? Diana Santos, 2006, na Primeira Escola de Verão da Linguateca ...um corpo eletrônico, ...a conjunção de três coisas relacionadas: (i) um conjunto de textos, (ii) um conjunto de informação a marcar/classificar estes textos, e (iii) uma interface que permitisse consultar os dois primeiros. ...a escolha dos textos e da informação a eles associada tinha que ter um objetivo, senão estaríamos na presença apenas de uma coleção. Um corpo é uma coleção classificada de objetos linguísticos para uso em Processamento de Linguagem Natural/Linguística Computacional/Linguística em que uso pode ser estudo, medição, teste, ou avaliação, enquanto objetos linguísticos são textos, frases, palavras, entrevistas, erros ortográficos, entradas de dicionário, citações, pareceres jurídicos, filmes, imagens com legendas, traduções, correções (de textos de alunos de língua ou de tradução), telefonemas, simulações, programas, ...
 um conjunto de textos, (ii) um conjunto de informação a marcar/classificar estes textos, e (iii) uma interface que permitisse consultar os dois primeiros. ...a escolha dos textos e da informação a eles associada tinha que ter um objetivo, senão estaríamos na presença apenas de uma coleção. Um corpo é uma coleção classificada de objetos linguísticos para uso em Processamento de Linguagem Natural/Linguística Computacional/Linguística. em que uso pode ser estudo, medição, teste, ou avaliação, enquanto objetos linguísticos são textos, frases, palavras, entrevistas, erros ortográficos, entradas de dicionário, citações, pareceres jurídicos, filmes, imagens com legendas, traduções, correções (de textos de alunos de língua ou de tradução), telefonemas, simulações, programas, ...")
13
Diana Santos, 2006, na Primeira Escola de Verão da Linguateca (2)
A palavra classificada pode-se referir-se a muitas questões diferentes: com relação aos parâmetros da coleta: que categorias considerar; com relação à escolha: todos, alguns, amostra, ...; com relação aos fenômenos: tipo de erro, tipo de tradução, tipo de texto, ... com relação aos constituintes: análise sintática, semântica, fonológica, discursiva, etc. avaliação (quando existem julgamentos associados, como os de uma sumarização quanto a preservação do significado do texto original) Contudo, o mais importante num corpo é saber o que fazer com ele, como usá-lo, e para que tarefas ele é útil.
 Contudo, o mais importante num corpo é saber o que fazer com ele, como usá-lo, e para que tarefas ele é útil.")
14
Tipos de pesquisa com córpus
Corpus-driven approaches: hypotheses are drawn from the corpus Exploratórios: procura coisas interessantes para mais tarde estudar. Compila amostras, conta ocorrências, procura correlações, experimenta classificações, identifica conjuntos. Identifica pontos de interesse. Tecnicamente constrói uma teoria ou mapa da área. Corpus-based approaches: hypotheses are checked against a corpus Experimentais: já tem uma hipótese ou conjunto de hipóteses que pretende verificar. Quanto mais precisa a hipótese (estatística), mais dados são precisos para atestar, devido à necessidade de significância estatística a probabilidade de um desvio aleatório da média da população aumenta com a diminuição do tamanho da amostra e diminui com o aumento do tamanho da amostra. Na prática, a maior parte dos estudos têm uma componente exploratória e outra experimental. Um estudo experimental é geralmente produzido com base nas explorações de outros pesquisadores. Ou de um piloto.
, mais dados são precisos para atestar, devido à necessidade de significância estatística. a probabilidade de um desvio aleatório da média da população aumenta com a diminuição do tamanho da amostra e diminui com o aumento do tamanho da amostra. Na prática, a maior parte dos estudos têm uma componente exploratória e outra experimental. Um estudo experimental é geralmente produzido com base nas explorações de outros pesquisadores. Ou de um piloto.")
15
Tipos de usos de córpus 1. Ter uma idéia do problema
2. Medir um dado fenômeno 3. Avaliar algo (uma hipótese, um sistema, um método, uma teoria, ...) 4. Mais frequente - criar outras coisas: dicionários, materiais de teste de ensino de língua (CAA), sistemas de aprendizado de língua (CALL), sistemas de detecção de plágio, de identificação de spam, entre outros. Nem todos os córpus são apropriados para todos os usos. Embora tendem a ser de uso suficientemente geral, há um compromisso entre o projeto do córpus e os tipos de usos que fazemos deles.
 4. Mais frequente - criar outras coisas: dicionários, materiais de teste de ensino de língua (CAA), sistemas de aprendizado de língua (CALL), sistemas de detecção de plágio, de identificação de spam, entre outros. Nem todos os córpus são apropriados para todos os usos. Embora tendem a ser de uso suficientemente geral, há um compromisso entre o projeto do córpus e os tipos de usos que fazemos deles.")
16
Até agora... Não disse nada que nos ajudasse a propor o projeto (design) de um córpus... Perguntas como: (1) que “tipos de textos” incluir, (2) número deles, (3) seleção de textos, (4) seleção de uma amostra dentro do texto (se desejasse) (5) tamanho de tal amostra ???
 que tipos de textos incluir, (2) número deles, (3) seleção de textos, (4) seleção de uma amostra dentro do. texto (se desejasse) (5) tamanho de tal amostra")
17
Questões/critérios para informar o projeto de córpus
balanceamento/ equilíbrio extensão X proteção da identidade dos participantes do corpus amostragem diversidade copyright representatividade

18
Primeira dicotomia para projeto de córpus
Maior parte das pesquisas Produção/Recepção de texto VS. Texto como Produto Padrões de uso de grupos organizados demograficamente) Lista de gêneros e Tipos de Texto
 Lista de gêneros e Tipos de Texto.")
19
Amostragem Demográfica
Tem sido usada em pesquisas da área de sociologia e usa amostragem proporcional de um estrato (sexo, idade, ocupação, ...) na população. São representativas pois refletem as proporções de uma população MAS...córpus precisam de uma noção de representatividade diferente, pois senão iriam incluir 90% de fala (conversação), 3% cartas/notas/ s, 7% restantes de todo o resto dos gêneros pois as pesquisas precisam de toda a variação linguística de uma língua. Lembrem dos analfabetos
 na população. São representativas pois refletem as proporções de uma população. MAS...córpus precisam de uma noção de representatividade diferente, pois senão iriam incluir 90% de fala (conversação), 3% cartas/notas/ s, 7% restantes de todo o resto dos gêneros. pois as pesquisas precisam de toda a variação linguística de uma língua. Lembrem dos analfabetos.")
20
Problemas da amostragem proporcional
Refletem as frequências numéricas, não a importância. Livros, jornais, por exemplo, são muito mais influentes do que sua frequencia indica. Se o foco da pesquisa for sobre a variação de características em tipos de textos diferentes, a amostragem proporcional não fornece uma base boa de análise: 90% dos textos seriam similares (conversa/fala) e não teríamos a chance de estudar profundamente o restante 10% que englobaria a maioria dos gêneros/tipos de texto.
 e não teríamos a chance de estudar profundamente o restante 10% que englobaria a maioria dos gêneros/tipos de texto.")
21
Não é fácil... Entretanto, como nota Biber, 1998:246, embora a análise da representatividade seja crucial ela é uma tarefa problemática, mesmo que o foco seja em partes da linguagem, por exemplo, um córpus que pretende representar a linguagem falada (transcrições): não existe nenhum catálogo de bibliografia de textos falados e eles estão sendo expandidos diariamente. Identificar uma amostra da população nesse caso é difícil.
: não existe nenhum catálogo de bibliografia de textos falados e eles estão sendo expandidos diariamente. Identificar uma amostra da população nesse caso é difícil.")
22
Biber (1993) ... Representatividade no projeto de corpus
Quando estamos construindo um córpus geral (versus de linguagem especializada) espera-se que ele seja uma amostra representativa da língua como um todo, isto é, que inclua toda a variabilidade que ocorre na população, para que generalizações possam ser feitas sobre a língua. Representatividade se refere a quanto uma amostra inclui a totalidade da variabilidade na população. No projeto de córpus, a variabilidade pode ser considerada de: uma perspectiva externa (da situação), isto é, do modo (escrito/falado), dos participantes (quem fala ou escreve/para quem fala ou escreve), meio de distribuição (não publicado, publicado como livro, lei, Internet, jornal, revista, etc.), tópico, da função comunicativa, etc. e de uma perspectiva interna (ou lingüística), isto é, das distribuições lingüísticas Gênero/ registro Tipo de Texto
 espera-se que ele seja uma amostra representativa da língua como um todo, isto é, que inclua toda a variabilidade que ocorre na população, para que generalizações possam ser feitas sobre a língua. Representatividade. se refere a quanto uma amostra inclui a totalidade da variabilidade na população. No projeto de córpus, a variabilidade pode ser considerada de: uma perspectiva externa (da situação), isto é, do modo (escrito/falado), dos participantes (quem fala ou escreve/para quem fala ou escreve), meio de distribuição (não publicado, publicado como livro, lei, Internet, jornal, revista, etc.), tópico, da função comunicativa, etc. e. de uma perspectiva interna (ou lingüística), isto é, das distribuições lingüísticas. Gênero/ registro. Tipo de Texto.")
23
Há uma ordem para as perspectivas
A condição da representatividade linguística depende da representatividade de gêneros. O design do córpus deve proceder de forma cíclica partindo de um design inicial de um córpus piloto: (1o) que deve incluir uma grande variedade de gêneros (2o) que são avaliados quanto aos tipos de textos presentes (segundo Biber, isso requer análise das características lingüísticas) e revisado podendo ser incluídos novos textos O projeto de um córpus representativo não pára até que o córpus esteja completo e a análise dos parâmetros de variação se aplique a todo o córpus.
 que deve incluir uma grande variedade de gêneros. (2o) que são avaliados quanto aos tipos de textos presentes (segundo Biber, isso requer análise das características lingüísticas) e revisado podendo ser incluídos novos textos. O projeto de um córpus representativo não pára até que o córpus esteja completo e a análise dos parâmetros de variação se aplique a todo o córpus.")
24
Quantos textos de cada gênero?
Supor que nosso córpus tenha que ter 200 textos de 3 gêneros: conversação/ficção/acadêmico. Cada registro tem que ser representado por um número X de textos iguais. Suponha 20. Os 140 restantes serão divididos entre os 3 para termos mais amostras para gêneros com grande variância para as features de interesse.

25
Quantos textos... Conversas e textos de ficção apresentam desvios totais similares (37% e 39%), mas textos acadêmicos têm desvios maiores (49%). .37x + .39x + .49x = 140 1.25x = 140; x = 112 Amostras: .37 * 112 = 41; .39*112 = 44; .49*112 = 55 Córpus: = 200

26
O que é a Lingüística de Córpus?
Debate na definição do status da área. Não é uma disciplina como a Semântica pois seu objeto de estudo não é delimitado como em outras áreas. Não é domínio de estudo. Ocupa-se de vários fenômenos enfocados em outras áreas (morfologia, sintaxe, sociologia, etc.). Combina-se facilmente com essas divisões da lingüística. Outra divisão da lingüística que tem status parecido com a L Córpus é a L Computacional Que também é reconhecida como ferramenta ou metodologia; “investigação da linguagem por meio de computador” Existe uma sobreposição ente L Córpus e L Computacional. Essa última possui interesse em modelos computacionais de vários tipos de fenômenos lingüísticos.
. Combina-se facilmente com essas divisões da lingüística. Outra divisão da lingüística que tem status parecido com a L Córpus é a L Computacional. Que também é reconhecida como ferramenta ou metodologia; investigação da linguagem por meio de computador Existe uma sobreposição ente L Córpus e L Computacional. Essa última possui interesse em modelos computacionais de vários tipos de fenômenos lingüísticos.")
27
McEnery & Wilson 1996 afirmam que ela é “apenas uma metodologia”
Se metodologia for entendida como um instrumental poderíamos ter uma sintaxe baseada em córpus versus uma sintaxe tradicional, etc. Mas os mesmos tipos de problemas, questões, achados, etc. de um estudo baseado em córpus se aplicaria a um estudo sem córpus??? Ou a L córpus também muda o modo pelo qual se faz pesquisa e portanto os tipos de resultados??? L Córpus não se resume a um conjunto de ferramentas Se metodologia for entendida como um modo típico de aplicar um conjunto de pressupostos de caráter teórico, então pode ser vista como metodologia, pois traz mais do que o instrumental computacional

28
L Córpus = Abordagem baseada em corpus
Uma razão pela qual a L Córpus não é uma metodologia é o fato de seus praticantes produzirem conhecimento novo A análise de um córpus pode revelar, e freqüentemente revela, fatos a respeito de uma língua que nunca se pensou em procurar. Assim, uma terceira possibilidade é da L Córpus não ser nem disciplina nem metodologia Uma rota para a Lingüística Uma abordagem Uma nova empreitada de pesquisa, uma nova abordagem filosófica L Córpus = Abordagem baseada em corpus

29
Abordagem baseada em corpus (Biber et al 1998)
É empírica, analisa os padrões reais de uso em textos autênticos Utiliza uma grande coleção de textos autênticos conhecida como córpus Faz uso extensivo de computadores para análise, usando técnicas automáticas e interativas Depende de técnicas quantitativas e também qualitativas Pois o objetivo de estudos da L Córpus não é somente apresentar contagem de features lingüísticas e sim dar uma interpretação dos padrões quantitativos, isto é, a importância dessas descobertas para o aprendizado sobre os padrões do uso da língua. Além de contar freqüências há a possibilidade de se estudar associações lingüísticas (léxicas ou gramaticais). Por exemplo, se tomarmos as palavras big, large e great, que são sinônimos, veremos que big co-ocorre com toe, large co-corre com number. Esses são exemplos de associações léxicas ou colocações.
. Por exemplo, se tomarmos as palavras big, large e great, que são sinônimos, veremos que big co-ocorre com toe, large co-corre com number. Esses são exemplos de associações léxicas ou colocações.")
30
Estudos da língua: estudos da estrutura e do uso Tradicionalmente: identificação das unidades estruturais e classes de uma língua (morfemas, palavras, orações, classes gramaticais, etc.) O enfoque da LC é no uso da língua, como os usuários da língua (falada ou escrita) exploram os seus recursos. Foco no desempenho e não na competência. L Córpus estuda o desempenho como um produto, pois o córpus consiste da manifestação física da língua independente de processos mentais dos autores pesquisados
 O enfoque da LC é no uso da língua, como os usuários da língua (falada ou escrita) exploram os seus recursos. Foco no desempenho e não na competência. L Córpus estuda o desempenho como um produto, pois o córpus consiste da manifestação física da língua independente de processos mentais dos autores pesquisados.")
32
Right is very much more common in spoken English than in written English. Here's a couple of different examples in spoken dialogue taken from the Cambridge International corpus (CIC). "That's right. Cos they've never seen him." "Oh well. And it's going all right is it?"
. That s right. Cos they ve never seen him. Oh well. And it s going all right is it .")
34
Concordanciador KWIC (Keyword in Context)
The word that comes most often after 'worry' is 'about'. Look at these examples from the Cambridge International Corpus. Concordanciador KWIC (Keyword in Context) KWIC foi desenvolvido em 1958 na IBM por Luhn: Luhn, H. P. (1959). Keyword-in-Context Index for Technical Literature (KWIC Index). Yorktown Heights, N. Y.: IBM.
 KWIC foi desenvolvido em 1958 na IBM por Luhn: Luhn, H. P. (1959). Keyword-in-Context Index for Technical Literature (KWIC Index). Yorktown Heights, N. Y.: IBM.")
35
KWIC / KWAC / KWOC http://lu.com/odlis/
An acronym for Keyword out of Context, a variation on the KWIC (Keyword in Context) index, in which keywords extracted algorithmically from the title of a document (and sometimes the text) are printed as headings along the left-hand margin of the page, with the titles or portions of text containing each keyword indented under the corresponding heading. A symbol may be substituted for the keyword in the string of text. Unlike KWAC indexing, this method does not preserve multiword terms and phrases in the alphanumeric sequence of headings.
 index, in which keywords extracted algorithmically from the title of a document (and sometimes the text) are printed as headings along the left-hand margin of the page, with the titles or portions of text containing each keyword indented under the corresponding heading. A symbol may be substituted for the keyword in the string of text. Unlike KWAC indexing, this method does not preserve multiword terms and phrases in the alphanumeric sequence of headings.")
36
KWAC An acronym for Keyword and Context (also known as Keyword alongside Context), an algorithmically generated index in which keywords from the title (and sometimes the text) of a document are printed as headings along the left-hand margin of the page, with the portion of the title or text following each keyword indented under the heading, followed by the portion of the title or text preceding the word. Unlike KWOC indexing, this method preserves multiword terms and phrases in the alphanumeric sequence of headings.
, an algorithmically generated index in which keywords from the title (and sometimes the text) of a document are printed as headings along the left-hand margin of the page, with the portion of the title or text following each keyword indented under the heading, followed by the portion of the title or text preceding the word. Unlike KWOC indexing, this method preserves multiword terms and phrases in the alphanumeric sequence of headings.")
38
Flat' is used much more by the British
Flat' is used much more by the British. Both British and Americans use it when they mean 'smooth and level, with no curved, high or hollow parts', but only the British use it to mean 'a set of rooms to live in with all the rooms on one level of a building'. Americans use the word 'apartment' for this.

39
Resumindo Estudos da L Córpus podem focar na língua (P, I) ou variante da língua (IA, IB), no modo falado ou escrito Estudos analisam padrões de uso para uma estrutura Estudos também podem focar no grupo de falantes/escritores, ou como a língua falada por mulheres difere da língua usada por homens, etc. Áreas de pesquisa em conferências: Compilação de córpus Desenvolvimento de ferramentas Descrição da língua Aplicação de córpus (ensino, tradução, reconhecimento de voz, etc.)
")
40
Existem campos da Lingüística para os quais a L Córpus é a única opção
Linguística Histórica/Filologia (Historical linguistics) Córpus Thycho Brahe - relationship between prosody and syntax in the process of language change which led from Classical Portuguese to Modern European Portuguese. Linguística Diacrônica (Diachronic linguistics) The claim (Hilary Putnam, 1962) The truth value of statements (e.g., "Robots can be conscious.") can change over time as word use changes, even though the meaning of such statements remains constant. Statements that are now false under synchronic linguistics (the study of language at a given time) may become false, as revealed by diachronic linguistics (the study of language through time).
 Córpus Thycho Brahe - relationship between prosody and syntax in the process of language change which led from Classical Portuguese to Modern European Portuguese. Linguística Diacrônica (Diachronic linguistics) The claim (Hilary Putnam, 1962) The truth value of statements (e.g., Robots can be conscious. ) can change over time as word use changes, even though the meaning of such statements remains constant. Statements that are now false under synchronic linguistics (the study of language at a given time) may become false, as revealed by diachronic linguistics (the study of language through time).")
41
Existem campos da Lingüística para os quais a L Córpus é a única opção (2)
Estudos sobre aquisição de linguagem (Study of child language) Não dá para perguntar para uma criança de 18 meses se gugu-dada é verbo-nome ou nome-adjetivo. Estudos sobre o Uso da Língua (forensic linguistic, style) Lingüística forense: identificação de plágio/autoria, profile de escritores (cartas com antrax), etc. Modelos Probabilísticos/Estatísticos (Probabilistic linguistics) Modelos para várias tarefas como tagging, parsing, speech Linguística Compucional (training/evaluation) Córpus de treinamento para as tarefas acima; avaliações conjuntas (TREC´s)
 Não dá para perguntar para uma criança de 18 meses se gugu-dada é verbo-nome ou nome-adjetivo. Estudos sobre o Uso da Língua (forensic linguistic, style) Lingüística forense: identificação de plágio/autoria, profile de escritores (cartas com antrax), etc. Modelos Probabilísticos/Estatísticos (Probabilistic linguistics) Modelos para várias tarefas como tagging, parsing, speech. Linguística Compucional (training/evaluation) Córpus de treinamento para as tarefas acima; avaliações conjuntas (TREC´s)")
42
Uso de Córpus em Estudos da Língua
Córpus e Lingüística Computacional Tagging Parsing Tagging semântico Correção Gramatical Análise do discurso (anáforas) Análise Retórica Tradução Automática Sumarização Automática Extração Automática de Terminologia Simplificação Textual ... Corpora in Speech Research Corpora in Lexical Studies Corpora and Grammar Corpora and Semantics Corpora and Pragmatics Corpora and Sociolinguistics Corpora and Stylistics Corpora and Language Teaching Corpora and Historical Linguistics Corpora in Psycholinguistics Corpora and Cultural Studies ...
 Análise Retórica. Tradução Automática. Sumarização Automática. Extração Automática de Terminologia. Simplificação Textual. ... Corpora in Speech Research. Corpora in Lexical Studies. Corpora and Grammar. Corpora and Semantics. Corpora and Pragmatics. Corpora and Sociolinguistics. Corpora and Stylistics. Corpora and Language Teaching. Corpora and Historical Linguistics. Corpora in Psycholinguistics. Corpora and Cultural Studies. ...")
43
Algumas Tipologias de Córpus

44
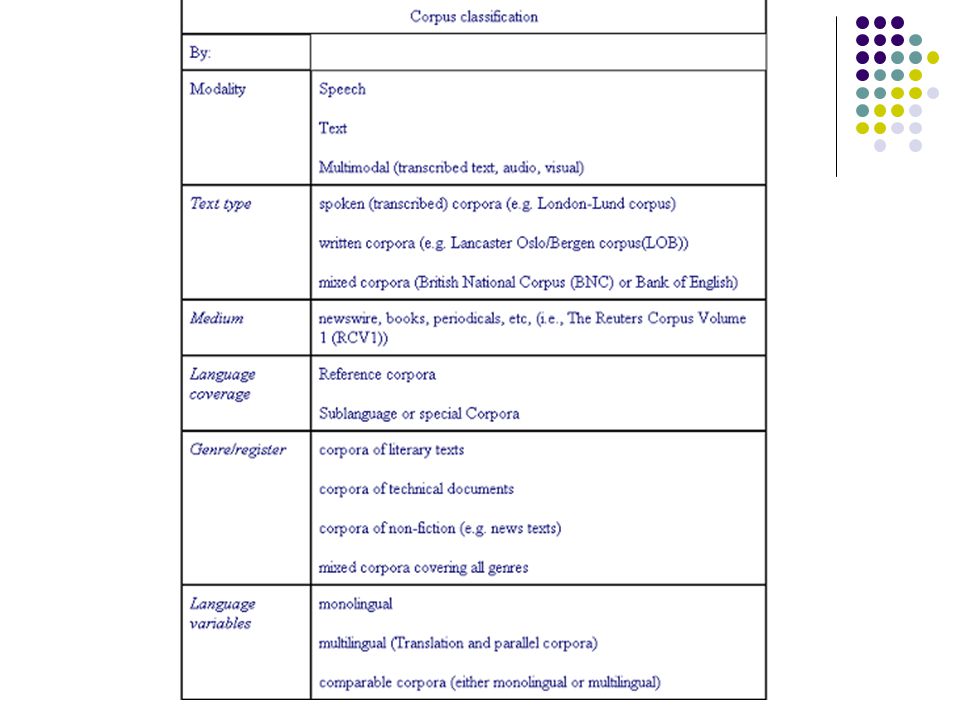
Classificação de Atkins et al (1992)
Um corpus é um conjunto de textos compilado de acordo com critérios explícitos para um propósito específico e assim, a rica variedade de córpus reflete a diversidade dos objetivos dos projetistas. Se um córpus é criado com o propósito de se estudar um único MODO então temos um córpus de fala ou córpus escritos; Um único MEIO podemos ter um córpus de livros, jornais, ou de aulas. Vejamos agora os 9 parâmetros contrastivos da tipologia:

45
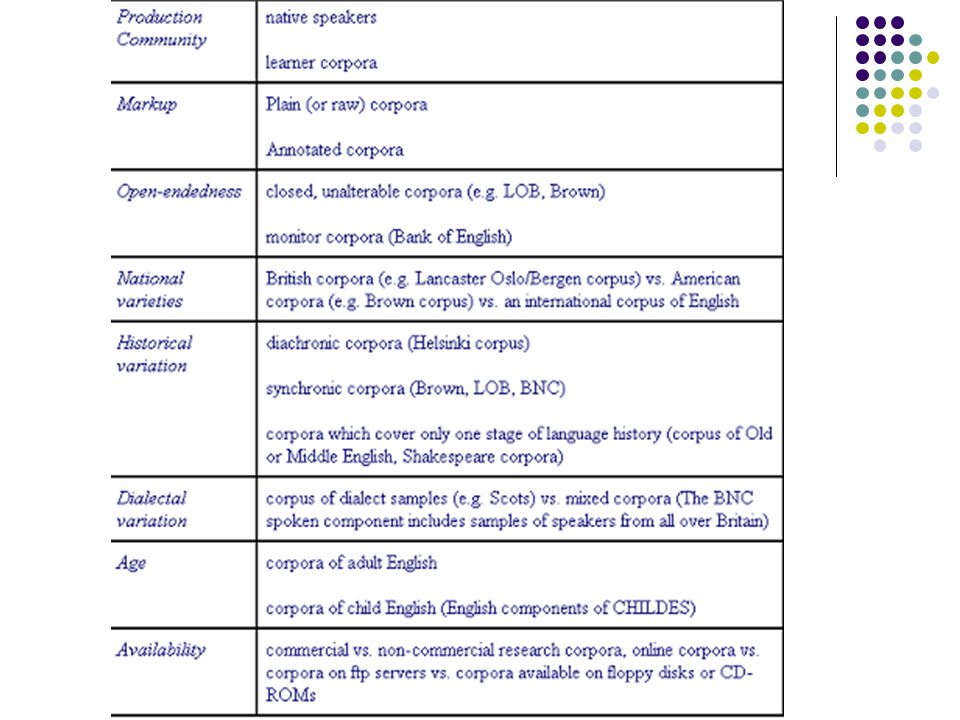
Texto inteiro X amostra X monitor
Monitor: textos são filtrados continuamente para se extrair dados para uma base de dados, mas não são permanentemente arquivados Fechado X aberto Sincrônico X diacrônico Um período específico deve ser projetado para o sincrônico Geral X terminológico Mono X bi X plurilíngüe Línguas Único X paralelo-2 X paralelo-3 ... Central X shell Shell é o restante da biblioteca eletrônica disponível quando necessário Núcleo X periférico Conceitos advindos do International Corpus of English (ICE): núcleo contém tipos de textos comuns a todas as variedades do inglês e que estão em todos os subcórpus; periférico contém aqueles tipos específicos de alguns subcórpus.
: núcleo contém tipos de textos comuns a todas as variedades do inglês e que estão em todos os subcórpus; periférico contém aqueles tipos específicos de alguns subcórpus.")
46
Classificação de Sardinha (2004)
Modo Falado: fala transcrita Escrito: textos escritos, impressos ou não Tempo Sincrônico: um período de tempo Diacrônico: vários períodos Contemporâneo: tempo corrente Histórico: período de tempo passado Seleção De amostragem: porções de textos para ser amostra finita da língua Monitor: composição reciclada para refletir o estado atual de uma língua. Opõe-se a córpus de amostragem Dinâmico: crescimento ou diminuição são permitidos; qualifica o córpus monitor Estático: oposto de dinâmico; qualifica o córpus de amostragem Equilibrado (Balanced): os componentes (gêneros, tipos de textos, etc) são distribuídos em quantidades semelhantes; por exemplo, o mesmo número de textos por gênero.
: os componentes (gêneros, tipos de textos, etc) são distribuídos em quantidades semelhantes; por exemplo, o mesmo número de textos por gênero.")
47
Conteúdo Autoria Disposição Interna Finalidade
Especializado: textos de tipos específicos Regional ou dialetal: textos de uma ou mais variedades sociolingüísticas específicas Multilíngüe: idiomas diferentes Autoria De aprendiz: não são falantes nativos De língua nativa Disposição Interna Paralelo: os textos são comparáveis, por exemplo, original e tradução Alinhado: traduções aparecem abaixo de cada linha do original Finalidade De estudo: córpus que se pretende descrever De referência: usado para fins de contraste com o córpus de estudo De treinamento ou teste: usado para o desenvolvimento de aplicações ou ferramentas de PLN.

48
Tipologia de córpus do Projeto BALRIC-Ling (14 critérios)
")
51
Conteúdo e classificação do BNC
O BNC foi construído entre 1991 e 1994 por um consórcio entre editoras de dicionários como a Oxford University Press ( OUP) e Longman, centros de pesquisas acadêmicos como a University of Lancaster e Oxford e o governo britânico. Ele foi projetado para conter uma grande variedade de inglês britanico. O córpus contém ~100 milhões de palavras de inglês moderno, tanto escrito (90%) como falado (10%). É mais caro gravar e transcrever discurso do que adquirir material escrito Possui textos dos quais 863 são transcrições de conversações e monólogos. Tipologia: Córpus de amostras cada amostra não possui mais do que palavras. Sincrônico textos de ficção a partir de 1960 e informativos a partir de 1975 Córpus geral não está restrito a qualquer assunto, registro ou gênero Monolíngue composto de amostras que são produto de falantes do inglês britânico Misto contém textos de linguagem escrita e falada.
 e Longman, centros de pesquisas acadêmicos como a University of Lancaster e Oxford e o governo britânico. Ele foi projetado para conter uma grande variedade de inglês britanico. O córpus contém ~100 milhões de palavras de inglês moderno, tanto escrito (90%) como falado (10%). É mais caro gravar e transcrever discurso do que adquirir material escrito. Possui textos dos quais 863 são transcrições de conversações e monólogos. Tipologia: Córpus de amostras. cada amostra não possui mais do que palavras. Sincrônico. textos de ficção a partir de 1960 e informativos a partir de Córpus geral. não está restrito a qualquer assunto, registro ou gênero. Monolíngue. composto de amostras que são produto de falantes do inglês britânico. Misto. contém textos de linguagem escrita e falada.")
52
Tipologia de Textos Categorias ou atributos com específicos valores usados para Organizar e balancear córpus (para pesquisa e geração de subcórpus) Por exemplo: gênero, meio, estilo, tópico, modo (escrito, escrito para ser lido (dircurso), escrito para ser falado (dialogo/peça), falado, falado para ser escrito (ditado)) Os valores podem ser definidos usando critérios externos (e.g. tipos de texto institucionalizados, lista de tópicos, features extra-lingüísticas ou culturais) e/ou internos (features da linguagem do texto, compartilhada pelos membros da classe). Muitos critérios externos e internos estão relacionados, MAS pode acontecer de textos classificados separadamente por critérios externos compartilharem mesmas features lingüísticas (Biber). O que fazer nesse caso??? Análise Multidimensional (Biber), Classificação supervisionada com nova rotulagem, etc.
, escrito para ser falado (dialogo/peça), falado, falado para ser escrito (ditado)) Os valores podem ser definidos usando critérios externos (e.g. tipos de texto institucionalizados, lista de tópicos, features extra-lingüísticas ou culturais) e/ou internos (features da linguagem do texto, compartilhada pelos membros da classe). Muitos critérios externos e internos estão relacionados, MAS pode acontecer de textos classificados separadamente por critérios externos compartilharem mesmas features lingüísticas (Biber). O que fazer nesse caso Análise Multidimensional (Biber), Classificação supervisionada com nova rotulagem, etc.")
53
Categorias geradoras de controvérsia
Gênero A classificação de textos em diferentes gêneros tem sido feita em projetos de córpus com a ajuda de critérios externos como: informações sobre o falante/escritor e audiência, objetivos do autor, função dados históricos, sócio-culturais, filosóficos e ocupacionais. Uma distinção usada pelo BNC em informativo e imaginativo não tem grande validade pois ilude ao perpetuar que muitos textos tem como principal função a transferência de informação. Tópico Tópico é também um assunto controverso em tipologias de texto. Nenhum sistema de classificação externo parece satisfatório, existem várias hierarquias que estão sempre mudando A prática em muitos projetos de córpus é usar uma extensiva lista de valores para classificação, mas que não é aceita por todos.

54
Gênero Atkins et al: Biber: Eagles:
“é impossível balancear um córpus somente com critérios extra-lingüísticos” mas “balancear um córpus somente com critérios internos não mostraria a relação entre a linguagem e seu contexto (ambiente do texto)” No artigo apresenta uma lista de 29 atributos e possíveis valores para eles (critérios externos), que são relevantes para uma tipologia de textos Sugere começar com um recorte dos 29 atributos que pode ser expandido mais tarde se os recursos permitirem Biber: Inicialmente selecionar textos com base em critérios externos depois fazer análise com critérios internos para classificar os textos. Um processo cíclico de refinamento baseado nos 2 critérios é necessário para construir um córpus, usando as duas indexações Eagles: A classificação de textos em diferentes gêneros tem sido feita nos projetos de córpus com base em critérios externos, pois esses são aceitos culturalmente, e usados em disciplinas como Teoria Literária, Retórica e outras. Entretanto, uma tipologia adequada vai consistir de uma combinação dos 2 critérios (externo e interno)
 No artigo apresenta uma lista de 29 atributos e possíveis valores para eles (critérios externos), que são relevantes para uma tipologia de textos. Sugere começar com um recorte dos 29 atributos que pode ser expandido mais tarde se os recursos permitirem. Biber: Inicialmente selecionar textos com base em critérios externos depois fazer análise com critérios internos para classificar os textos. Um processo cíclico de refinamento baseado nos 2 critérios é necessário para construir um córpus, usando as duas indexações. Eagles: A classificação de textos em diferentes gêneros tem sido feita nos projetos de córpus com base em critérios externos, pois esses são aceitos culturalmente, e usados em disciplinas como Teoria Literária, Retórica e outras. Entretanto, uma tipologia adequada vai consistir de uma combinação dos 2 critérios (externo e interno)")
55
Tópico/Assunto EAGLES:
Existe uma categoria entre a externa e interna que é chamada de reflexiva: o texto fala sobre ele e propõe a sua classificação Jornais são geralmente divididos em cadernos com tópicos variados Assim, EAGLES divide os critérios externos em 2 tipos: Circunstancial (evidência vem de fora do texto) e Reflexivo (evidência vem do texto: título, subtítulo, prefácio, etc) Uma classificação melhor de tópico deve ser desenvolvida primeiramente com base em critérios internos ao texto, como a escolha do vocabulário, através de técnicas de clusterização, e depois a evidência externa é adicionada Solução: tratamento objetivo através de softwares de análise (Mineração de Textos) Projeto Aviator: utiliza levantamento de colocações + técnicas de clusterização Seleção automática de Keywords Sumarização automática Métodos de Extração Automática de Termos (em linguagem especializada)
 e. Reflexivo (evidência vem do texto: título, subtítulo, prefácio, etc) Uma classificação melhor de tópico deve ser desenvolvida primeiramente com base em critérios internos ao texto, como a escolha do vocabulário, através de técnicas de clusterização, e depois a evidência externa é adicionada. Solução: tratamento objetivo através de softwares de análise (Mineração de Textos) Projeto Aviator: utiliza levantamento de colocações + técnicas de clusterização. Seleção automática de Keywords. Sumarização automática. Métodos de Extração Automática de Termos (em linguagem especializada)")
56
Estudo de caso: Lácio-Ref
Tipologia quadripartida em gênero, tipo de texto, domínio e meio de distribuição. Gênero textual: o gênero discrimina o texto pela intenção comunicativa, a comunidade (meio) em que circula e as atividades humanas que o tornam relevante. (critério externo) 9 gêneros: Científico, De referência, Informativo, Jurídico, Prosa, Poesia, Drama, Instrucional, Técnico-Administrativo
 em que circula e as atividades humanas que o tornam relevante. (critério externo) 9 gêneros: Científico, De referência, Informativo, Jurídico, Prosa, Poesia, Drama, Instrucional, Técnico-Administrativo.")
57
Tipo textual: considera-se “tipo de texto” o modo específico de estruturação de um texto.
Refere-se ao texto visto “de dentro”, ou seja, suas partes componentes, seu léxico, sua sintaxe, sua adequação ao tema, etc. (subjetiva – exige leitura humana, mas termina com um membro de uma lista = externa)
")
58
Domínio: é a “área de conhecimento” que tematiza a principal informação veiculada pelo texto.
(subjetiva – exige leitura humana, mas termina com um membro de uma lista = externa) Meio de distribuição: seleciona o canal através do qual o texto foi divulgado ao seu público-alvo. (critério externo)
 Meio de distribuição: seleciona o canal através do qual o texto foi divulgado ao seu público-alvo. (critério externo)")
60
Córpus construídos no NILC
PLN-BR: Lácio-Web: 2 C de Aprendizes: CORVO - Textos do ENEM de 2002 CEA-STS - Abstracts em inglês escritos por alunos brasileiros de pós-graduação 2005 2008 2005 2007 2008 C. Nano ~2.5 milhões tokens CEA: 723 abstracts pub. (Referência) Física/Farmácia Comparable CEA (I/P): 84 pares de abs. Estudo de padrões léxicos. C. NILC ~35 milhões de tokens e tokens diferentes 4 Córpus Lácio-Web: MAC-MORPHO ~1.2 milhões de tokens Lácio-REF: 4278 arquivos, ~8.2 milhões tokens Par-C: 646 pares (I/P), tokens Comp-C: pares(I/P), tokens CEA-2: 28 artigos Comp/Est/Mat. Comp. 2008 Córpus PLN-BR C PorSimples 104 pares textos jornalísticos 50 pares de textos científicos Orig./Simp. (PorSimples) C. Milênio
 Física/Farmácia. Comparable CEA (I/P): 84 pares de abs. Estudo de padrões léxicos. C. NILC. ~35 milhões de tokens e tokens diferentes. 4 Córpus Lácio-Web: MAC-MORPHO. ~1.2 milhões de tokens. Lácio-REF: 4278 arquivos, ~8.2 milhões tokens. Par-C: 646 pares (I/P), tokens. Comp-C: pares(I/P), tokens. CEA-2: 28 artigos. Comp/Est/Mat. Comp Córpus PLN-BR. C PorSimples. 104 pares textos jornalísticos. 50 pares de textos científicos. Orig./Simp. (PorSimples) C. Milênio.")
61
Problemas do C NILC Classificação Número de textos em certos subcórpus
Dentro das 3 classes principais os textos foram agrupados de forma ad hoc, ou por domínio (ou assunto) ou por gênero ou tipo textual. Número de textos em certos subcórpus Alguns subcórpus estão sub-representados, por exemplo, o subcórpus Técnico e Científico possui somente um pequeno número de textos, dissertações incompletas, sendo a maioria da Computação Tamanho das amostras (o critério principal era amostras completas) Alguns textos se desviam da regra seguida pelo C NILC de incluir textos completos. Alguns possuem partes do começo, meio e fim de um texto, por exemplo. Agrupamento e formatação Não houve preocupação em manter a formação, por exemplo, as marcas de sentença e parágrafo para muitos textos. Houve agrupamento de textos pequenos num único, causando problemas para a criação do cabeçalho do texto Alguns textos possuem a informação de autoria e detalhes da publicação, mas nada é dito sobre o seu domínio, gênero ou tipo textual; outros nem tem cabeçalho. Copyright Foram obtidos para os subcórpus não corrigidos e semi-corrigidos; os corrigidos não têm permissão de uso.
 ou por gênero ou tipo textual. Número de textos em certos subcórpus. Alguns subcórpus estão sub-representados, por exemplo, o subcórpus Técnico e Científico possui somente um pequeno número de textos, dissertações incompletas, sendo a maioria da Computação. Tamanho das amostras (o critério principal era amostras completas) Alguns textos se desviam da regra seguida pelo C NILC de incluir textos completos. Alguns possuem partes do começo, meio e fim de um texto, por exemplo. Agrupamento e formatação. Não houve preocupação em manter a formação, por exemplo, as marcas de sentença e parágrafo para muitos textos. Houve agrupamento de textos pequenos num único, causando problemas para a criação do cabeçalho do texto. Alguns textos possuem a informação de autoria e detalhes da publicação, mas nada é dito sobre o seu domínio, gênero ou tipo textual; outros nem tem cabeçalho. Copyright. Foram obtidos para os subcórpus não corrigidos e semi-corrigidos; os corrigidos não têm permissão de uso.")
62
Organização do C NILC

63
Problemas do Lácio-Web
Embora possua uma bem definida tipologia de textos Gênero Tipo de Texto Domínio Meio de Distribuição E seus textos mantiveram a estrutura, possuam cabeçalho e autorização de uso Falha em não usar padrões internacionais de intercâmbio para facilitar o reuso e na seleção dos textos (não houve uma amostragem ou balanceamento).
.")
64
Tentamos sanar esses problemas
Em 2 projetos de grande porte: Milênio e PLN-BR

65
Arquitetura Geral do PLN-BR

66
3 grandes atividades: os córpus e sua infra-estrutura de acesso
1. Definição dos Protocolos e Padrões de Representação dos Documentos XCES 2. Disponibilização dos Córpus de Treinamento Córpus Gold Standard Córpus para treinamento de classificadores de conteúdo

67
3. Construção da Plataforma de Acesso aos Córpus – o Portal de Córpus ( A plataforma possui: um Editor Web de Cabeçalhos que preenche um banco de dados (BD) com informações dos cabeçalhos dos textos. Com os dados dos textos no BD há a possibilidade de: várias formas de pesquisa aos textos dos córpus e montagem de sub-córpus. O sub-córpus criado com as pesquisas: é disponibilizado para download seguindo o padrão XCES, a partir dos dados do banco de dados e em texto crú pode ainda ser consultado via uma ferramenta de exploração gráfica – o PEx-Corpus Tool. O PEx-Corpus é uma adaptação do projeto Projection Explorer (PEx) ( que permite inspecionar visualmente um subcórpus para explorar o seu conteúdo e criar outros subcórpus com base numa seleção de tópicos.
 com informações dos cabeçalhos dos textos. Com os dados dos textos no BD há a possibilidade de: várias formas de pesquisa aos textos dos córpus e montagem de sub-córpus. O sub-córpus criado com as pesquisas: é disponibilizado para download seguindo o padrão XCES, a partir dos dados do banco de dados e em texto crú. pode ainda ser consultado via uma ferramenta de exploração gráfica – o PEx-Corpus Tool. O PEx-Corpus é uma adaptação do projeto Projection Explorer (PEx) ( que permite inspecionar visualmente um subcórpus para explorar o seu conteúdo e criar outros subcórpus com base numa seleção de tópicos.")
68
Discussões relacionadas ao Projeto do Córpus
a) Devíamos usar a infra-estrutura de disponibilização e processamento do projeto Lácio-Web, já disponível no NILC? b) talvez fosse interessante que não houvesse muita variação na forma e domínio dos textos do córpus; c) que um critério importante seria a relevância social do córpus; d) que o córpus devesse ser fechado, com textos mais simples, com estruturas sintáticas menos sofisticadas, que venham em prosa (e não em verso); e) que sejam reconhecidos por seu mérito informativo (e não pelo juízo estético); e que, f) de preferência, não sejam muito longos. Domínio/Gênero: textos de patentes; dos domínios da Nanociência & Nanotecnologia e da bioinformática; na Bíblia; no Bulário Eletrônico da Anvisa ( no Guia de Remédios do UOL ( em textos relativos a um fato histórico de importância para o Brasil; em textos de saúde pública, por exemplo, as cartilhas de órgãos governamentais em contraponto com textos científicos e de divulgação para leitores mais proficientes; em textos didáticos; e em textos da Wikipedia (um problema aqui: os textos são encomendados e não naturais)
 Devíamos usar a infra-estrutura de disponibilização e processamento do projeto Lácio-Web, já disponível no NILC b) talvez fosse interessante que não houvesse muita variação na forma e domínio dos textos do córpus; c) que um critério importante seria a relevância social do córpus; d) que o córpus devesse ser fechado, com textos mais simples, com estruturas sintáticas menos sofisticadas, que venham em prosa (e não em verso); e) que sejam reconhecidos por seu mérito informativo (e não pelo juízo estético); e que, f) de preferência, não sejam muito longos. Domínio/Gênero: textos de patentes; dos domínios da Nanociência & Nanotecnologia e da bioinformática; na Bíblia; no Bulário Eletrônico da Anvisa ( no Guia de Remédios do UOL ( em textos relativos a um fato histórico de importância para o Brasil; em textos de saúde pública, por exemplo, as cartilhas de órgãos governamentais em contraponto com textos científicos e de divulgação para leitores mais proficientes; em textos didáticos; e. em textos da Wikipedia (um problema aqui: os textos são encomendados e não naturais)")
69
I Workshop do projeto - 16 e 17 de março de 2006
Todos concordaram que o gênero de textos informativos, subgênero jornalístico era o que atenderia melhor a todos os subgrupos. Embora o NILC tivesse permissão de uso dos textos de 1994 da Folha de São Paulo (FSP), partimos para um pedido formal para a Folha, por ser o maior jornal do Brasil, em busca de dados mais atuais.
, partimos para um pedido formal para a Folha, por ser o maior jornal do Brasil, em busca de dados mais atuais.")
70
Amostragem Córpus Global (FULL) do PLN-BR O ano construído para o projeto PLN-BR toma os textos de um mês aleatório de 1994 até um mês aleatório de 2005, totalizando 12 meses diferentes A grande base contém 125 mil textos no formato Folio Views. Vários textos desta base são compostos somente de informação de cabeçalho: estes não foram utilizados no projeto PLN-BR.

71
Obtenção dos Direitos de Uso
As negociações com a FSP para obtenção da grande base de textos e de amostras representativas e balanceadas começaram em março de 2006 e em janeiro de 2007 o TERMO DE AUTORIZAÇÃO PARA UTILIZAÇÃO DE OBRA E OUTRAS AVENÇAS entre ICMC-USP (representando o Projeto PLN-BR) e a FSP foi assinado.
 e a FSP foi assinado.")
72
Os 3 córpus do PLN-BR 1. PLN-BR FULL que contém mil textos da FSP e tokens foi disponibilizado para download em setembro de 2006, principalmente para os membros dos subprojetos Glosagem da Wordnet.Br e sua Indexação à WordNet de Princeton e Aprendizagem Automática de Informações Lexicais. este córpus só pode ser acessado na Web com senha (Portal_Interno), com citação/visualização permitida de 30% de cada texto via concordâncias, por exemplo, devido à lei de direitos autorais. Cada pesquisador que o acessa assina um termo de compromisso. o córpus pode ser explorado totalmente pelos participantes do projeto para tarefas de criação de léxicos, por exemplo, entre outras.
, com citação/visualização permitida de 30% de cada texto via concordâncias, por exemplo, devido à lei de direitos autorais. Cada pesquisador que o acessa assina um termo de compromisso. o córpus pode ser explorado totalmente pelos participantes do projeto para tarefas de criação de léxicos, por exemplo, entre outras.")
73
Foi distribuído em codificação unicode
os textos possuem as informações de título, subtítulo (quando existe), autores, tipo de texto, caderno, ano, número de palavras, keywords (quando existem), seguido do texto cru. título, subtítulo e autores não ganham etiquetas e assim colaboram para a contagem de freqüência quando usados no processador de córpus Unitex. as outras meta-informações (tipo de texto, caderno, ano, número de palavras e keywords) utilizam etiquetas Unitex: Globo News dá um 'furo' mundial FRANCISCO MARTINS DA COSTA {tipo de texto Notícia,.N} {caderno TV FOLHA,.N} {ano 1999,.N} {número de palavras 125,.N} {keywords [TELEVISÃO] [GAFE] [OSCAR, 1999] [GLOBONEWS],.N} Na madrugada de domingo para segunda-feira passada, o "Em Cima da Hora", da Globo News, deu em primeira-mão que "O Resgate do Soldado Ryan", de Steven Spielberg, ganhou o Oscar de melhor filme. Foi uma notícia literalmente exclusiva, afinal o vencedor para todo o resto da humanidade foi "Shakespeare Apaixonado". Parabéns Central Globo de Jornalismo! É de "furos" como esse que o telespectador gosta. Mas gafes não são exclusividade dos canais de notícia. O cantor Vinny, ao analisar as chances de "Central do Brasil", na tarde de domingo na MTV, ponderou que a concorrência era forte. "Ouvi dizer que 'La Dolce Vita' é um ótimo filme", disse. Pena que "A Vida é Bela" em italiano seja "La Vita È Bella". (FRANCISCO MARTINS DA COSTA)
, autores, tipo de texto, caderno, ano, número de palavras, keywords (quando existem), seguido do texto cru. título, subtítulo e autores não ganham etiquetas e assim colaboram para a contagem de freqüência quando usados no processador de córpus Unitex. as outras meta-informações (tipo de texto, caderno, ano, número de palavras e keywords) utilizam etiquetas Unitex: Globo News dá um furo mundial. FRANCISCO MARTINS DA COSTA. {tipo de texto Notícia,.N} {caderno TV FOLHA,.N} {ano 1999,.N} {número de palavras 125,.N} {keywords [TELEVISÃO] [GAFE] [OSCAR, 1999] [GLOBONEWS],.N} Na madrugada de domingo para segunda-feira passada, o Em Cima da Hora , da Globo News, deu em primeira-mão que O Resgate do Soldado Ryan , de Steven Spielberg, ganhou o Oscar de melhor filme. Foi uma notícia literalmente exclusiva, afinal o vencedor para todo o resto da humanidade foi Shakespeare Apaixonado . Parabéns Central Globo de Jornalismo! É de furos como esse que o telespectador gosta. Mas gafes não são exclusividade dos canais de notícia. O cantor Vinny, ao analisar as chances de Central do Brasil , na tarde de domingo na MTV, ponderou que a concorrência era forte. Ouvi dizer que La Dolce Vita é um ótimo filme , disse. Pena que A Vida é Bela em italiano seja La Vita È Bella . (FRANCISCO MARTINS DA COSTA)")
74
O arquivo tem 141MB compactado e 400MB descompactado.
Estes textos passaram por um novo crivo exigido pela FSP em dezembro de 2006 para dar acesso somente aos textos cujos créditos eram da FSP na montagem dos dois outros córpus que prevêem acesso a textos integrais. Este novo córpus possui textos e tokens (mantemos este novo córpus em uma base de dados diferente, que chamaremos aqui de PLN-BR FULL 2).
.")
75
2. PLN-BR CATEG que possui 30 mil textos e 9.780.220 tokens.
só pode ser acessado com senha pelos membros, mas o acesso aos textos é integral. visa atender o subgrupo Categorização de Textos. uma amostra aleatória estratificada e proporcional à distribuição do córpus PLN-BR FULL com relação aos textos dos cadernos do jornal. formado por 30% dos textos do córpus PLN-BR FULL e possui somente notícias e reportagens para as quais a Folha de São Paulo possui direitos de republicação. contém o córpus PLB-BR GOLD. 3. PLN-BR GOLD que possui 1024 textos e tokens. Pode ser acessado livremente via Web. O tamanho deste córpus que recebe atenção da maioria dos subgrupos foi decidido para representar 1% do córpus PLN-BR FULL de forma a conservar, proporcionalmente, a distribuição deste córpus maior. Ele é uma amostra aleatória estratificada e proporcional à distribuição do córpus PLN-BR FULL com relação aos textos dos cadernos do jornal. Ele é formado por 1% dos textos do córpus PLN-BR FULL, e possui somente notícias e reportagens para as quais a Folha de São Paulo possui direitos de republicação.

76
Padrões Internacionais de Anotação e Codificação
Como o custo de se criar córpus anotados é muito alto tanto e termos financeiros como na demanda de trabalho especializado, pesquisadores amortizam estes custos reusando estes recursos Este alto custo contribui para o desenvolvimento de padrões de codificação e anotação para recursos de língua, que permitem o seu intercâmbio Exemplos de padrão de anotação: TEI – mais adaptado para córpus históricos e XCES – mais adaptado para criação de córpus para PLN Padrão de codificação de caracteres: Unicode Vantagens de se usar estes padrões internacionais: Facilita o intercâmbio de dados, reuso e extensibilidade Evita o desenvolvimento de software, pois podemos usar ferramentas já desenvolvidas que os atendem

77
Discussões relacionadas ao padrão a ser usado para Anotação Estrutural e Lingüística
XML Padrões atuais: TEI e XCES (há também o padrão XML CDIF, MARTIF, OLIF) ANC é um córpus de textos contemporâneos do IA, sendo atualmente construído Criação e aplicação do padrão XCES ( XCES é a versão XML do padrão CES (Corpus Encoding Standard) que é parte das recomendações do grupo EAGLES (Expert Advisory Group on Language Engineering Standards) para codificação e anotação de córpus que segue as recomendações do TEI (Text Encoding Initiative) TEI tem uma massiva documentação Novidade do XCES: anotação stand-off (vs anotação intercalada com o texto) e o uso de schemas XML que fornecem mais controle para a definição do que é valido e mais tipos de dados (vs o uso de DTD´s) Mas nem todo este poder vem de graça....é uma nova tecnologia, vários parsers não o analisam, já há muito feito em DTD, então não estaríamos reusando o que está pronto Como decidir? Inovação versus segurança e reuso XCES fornece uniformidade para representação estrutural e lingüística: Feature Structure <struct type="p" from="3" to="219"> <feat name="id" value="p1" /> </struct> Discussão sobre padrões:
 ANC é um córpus de textos contemporâneos do IA, sendo atualmente construído. Criação e aplicação do padrão XCES ( XCES é a versão XML do padrão CES (Corpus Encoding Standard) que é parte das recomendações do grupo EAGLES (Expert Advisory Group on Language Engineering Standards) para codificação e anotação de córpus que segue as recomendações do TEI (Text Encoding Initiative) TEI tem uma massiva documentação. Novidade do XCES: anotação stand-off (vs anotação intercalada com o texto) e. o uso de schemas XML que fornecem mais controle para a definição do que é valido e mais tipos de dados (vs o uso de DTD´s) Mas nem todo este poder vem de graça....é uma nova tecnologia, vários parsers não o analisam, já há muito feito em DTD, então não estaríamos reusando o que está pronto. Como decidir Inovação versus segurança e reuso. XCES fornece uniformidade para representação estrutural e lingüística: Feature Structure. <struct type= p from= 3 to= 219 > <feat name= id value= p1 /> </struct> Discussão sobre padrões:")
78
Anotação XCES Básica: PLN-BR GOLD e PLN-BR CATEG

79
Anotação Stand-off: flexibilidade
O texto primário pode ser usado sem anotações ou com anotações se necessário. O usuário pode escolher trabalhar com uma anotação em particular independente do textos. O córpus pode conter anotações de diferentes tipos, ou várias versões de um único tipo de anotação (por exemplo, múltiplas marcações de etiquetadores morfossintáticos (taggers)) sem problemas de compatibilidade. O projeto pode distribuir anotações independentes do texto para download, porque as anotações possuem links para os dados originais (conteúdo), assim qualquer usuário que já fez download do córpus pode posteriormente somente baixar as novas anotações.
) sem problemas de compatibilidade. O projeto pode distribuir anotações independentes do texto para download, porque as anotações possuem links para os dados originais (conteúdo), assim qualquer usuário que já fez download do córpus pode posteriormente somente baixar as novas anotações.")
81
Exemplo: ESPORTE_1997_640.txt (15 par.)
")
82
ESPORTE_1997_640-logical.xml <?xml version="1.0" encoding="UTF-8" ?> - <cesAna xmlns=" version="1.0.4"> - <struct type="cesDoc" from="0" to="2193"> <feat name="version" value="1.0.4" /> <feat name="id" value="ESPORTE_1997_640" /> <feat name="xmlns:xsi" value=" /> <feat name="xmlns:xlink" value=" /> <feat name="xmlns" value=" /> </struct> <struct type="text" from="0" to="2192" /> <struct type="body" from="1" to="2191" /> - <struct type="div" from="2" to="2190"> <feat name="type" value="materia" /> - <struct type="p" from="3" to="219"> <feat name="id" value="p1" /> - <struct type="p" from="220" to="413"> <feat name="id" value="p2" /> - …- - <struct type="p" from="1834" to="2119"> <feat name="id" value="p14" /> - <struct type="p" from="2120" to="2189"> <feat name="id" value="p15" /> </cesAna>

83
ESPORTE_1997_640-s.xml (20 sentenças)
<?xml version="1.0" encoding="UTF-8" ?> - <cesAna xmlns=" version="1.0.4"> - <struct type="s" from="3" to="219"> <feat name="id" value="p1s1" /> </struct> - <struct type="s" from="220" to="413"> <feat name="id" value="p2s1" /> - <struct type="s" from="414" to="538"> <feat name="id" value="p3s1" /> - <struct type="s" from="1834" to="1901"> <feat name="id" value="p14s1" /> - <struct type="s" from="1902" to="1971"> <feat name="id" value="p14s2" /> - <struct type="s" from="1972" to="2119"> <feat name="id" value="p14s3" /> - <struct type="s" from="2120" to="2179"> <feat name="id" value="p15s1" /> - <struct type="s" from="2180" to="2189"> <feat name="id" value="p15s2" /> </cesAna> O Senter erra aqui

84
ESPORTE_1997_640.xml (merged)
<?xml version="1.0" encoding="UTF-8" ?> - <cesDoc version="1.0.4" id="ESPORTE_1997_640" xmlns:xsi=" xmlns:xlink=" xmlns=" - <text> - <body> - <div type="materia"> - <p id="p1"> <s id="p1s1">Membros de torcidas uniformizadas do Corinthians emboscaram na madrugada de ontem o ônibus em que a delegação do clube viajava para São Paulo, após a derrota por 1 a 0 para o Santos, na Vila Belmiro, pelo Brasileiro.</s> </p> - <p id="p2"> <s id="p2s1">No km 45, após o trecho de serra da rodovia dos Imigrantes (sentido São Paulo), torcedores com camisa da Gaviões atravessaram um ônibus em que viajavam na pista, transformando-o numa barricada.</s> ... - <p id="p14"> <s id="p14s1">O ataque surge em hora crítica para o Corinthians e para a Gaviões.</s> <s id="p14s2">O time está em 20º lugar no Brasileiro e corre risco de rebaixamento.</s> <s id="p14s3">Já a Gaviões, proibida como todas as uniformizadas de frequentar estádios paulistas, negociava com a PM e o Ministério Público um modo de retornar.</s> - <p id="p15"> <s id="p15s1">LEIA mais sobre o ataque ao ônibus do Corinthians nas págs.</s> <s id="p15s2">4-3 e 4-4</s> </div> </body> </text> </cesDoc>
, torcedores com camisa da Gaviões atravessaram um ônibus em que viajavam na pista, transformando-o numa barricada.</s> <p id= p14 > <s id= p14s1 >O ataque surge em hora crítica para o Corinthians e para a Gaviões.</s> <s id= p14s2 >O time está em 20º lugar no Brasileiro e corre risco de rebaixamento.</s> <s id= p14s3 >Já a Gaviões, proibida como todas as uniformizadas de frequentar estádios paulistas, negociava com a PM e o Ministério Público um modo de retornar.</s> - <p id= p15 > <s id= p15s1 >LEIA mais sobre o ataque ao ônibus do Corinthians nas págs.</s> <s id= p15s2 >4-3 e 4-4</s> </div> </body> </text> </cesDoc>")
85
O cabeçalho segue o TEI <fileDesc>
Contém informações sobre o texto codificado (distribuição, fonte, etc.). <encodingDesc> Contém informações sobre a maneira como o texto foi codificado. <profileDesc> Contém informações sobre vários aspectos do texto (língua usada, classificação do texto segundo a sua tipologia, os participantes de um texto falado e sua situação, anotações, etc.). <revisionDesc> Resume o histórico de revisão (cabeçalho, segmentação e lingüística) de um documento.
. <encodingDesc> Contém informações sobre a maneira como o texto foi codificado. <profileDesc> Contém informações sobre vários aspectos do texto (língua usada, classificação do texto segundo a sua tipologia, os participantes de um texto falado e sua situação, anotações, etc.). <revisionDesc> Resume o histórico de revisão (cabeçalho, segmentação e lingüística) de um documento.")
86
Tipologia do Lácio-Web
Proposta: utilizar tipologia quadripartida do Lácio-Web

88
Tipologia do LW 3 anotações estruturais + 3 anotações lingüísticas

89
Anotação lingüística - sintática
Tokens <struct type=”token” from=”0” to=”1”> <feat name=”id” value=”t1”/> <feat name= “base” value=”A”/> </struct> <struct type=”token” from=”2” to=”8”> <feat name=”id” value=”t2”/> <feat name=”base” value=”universidade”/> …. Pos <struct type=”pos”> <feat name=”id” value=”pos1”/> <feat name=”class” value=”art”/> <feat name=”gender” value=”F”/> <feat name=”number” value=”S”/> <feat name=”canon” value=”o”/> <feat name=”complement” value=”artd”/> <feat name=”tokenref” value=”t1”/> … Phrases <struct type=”phrase” from=”t1” to=”t2”> <feat name=”id” value=”phr1”/> <feat name=”cat” value=”NP”/> <feat name=”function” value=”subj/> <feat name=”head” value=”t2”/> Tokens are linked to the main text through the attributes from and to in the structures of type token. For each token there is a corresponding POS structure. Phrases are identified for group of tokens.

90
Fóruns Conferência Lingüística de Córpus:
Internacional: 2001 a 2009, bianual Brasil de 1999 a 2009, 8 eventos: Special Interest Group on Linguistic data and corpus-based approaches to NLP (SIGDAT): com as conferências WVLC (de 1993 até 2000) e Empirical Methods in Natural Language Processing (de 1996 até 2008) International Journal of Corpus Linguistics ( ) Language Resources and Evaluation (
: com as conferências WVLC (de 1993 até 2000) e Empirical Methods in Natural Language Processing (de 1996 até 2008) International Journal of Corpus Linguistics ( series=Ijcl ) Language Resources and Evaluation. (")
91
Desafios da área Data Resources
1) Necessidade de uma Ciência da Anotação de Córpus
 Necessidade de uma Ciência da Anotação de Córpus.")
92
2) Necessidade de uma infra-estrutura de anotação robusta e extensível
Along with a better understanding of a methodology for annotation there should be a set of public domain tools and interfaces that can support, and to a certain degree enforce, “best practice” annotation guidelines. Exemplo: WYNNE, M. (Ed). Developing Linguistic Corpora: a Guide to Good Practice. Disponível em: . Acesso em14/10/2008. (Produced by AHDS Literature, Languages and Linguistics)
. Developing Linguistic Corpora: a Guide to Good Practice. Disponível em: . Acesso em14/10/2008. (Produced by AHDS Literature, Languages and Linguistics)")
93
3) Necessidade de integração de tecnologias para acelerar e produzir melhores anotações
There is considerable evidence that the productivity of manual annotation can be speeded up by pre-processing the data with sufficiently accurate automatic taggers (Chiou, et al., 2001). However, current annotation practices frequently fail to take advantage of this approach, possibly because of the difficulty of integrating these systems into new annotation tasks.
. However, current annotation practices frequently fail to take advantage of this approach, possibly because of the difficulty of integrating these systems into new annotation tasks.")
94
4) Necessidade da Criação de anotações mais ricas (informações lingüísticas)
 Necessidade da Criação de anotações mais ricas (informações lingüísticas)")
95
5) Necessidade da criação de Kits de Língua
There has long been recognition of the need to have basic language processing resources available for a broad spectrum of languages: monolingual text, parallel text, part-of-speech taggers, morphological analyzers, and Named Entity annotation. Este será o assunto da próxima aula...

96
6) Necessidade da criação de recursos léxicos de grande cobertura
In the quest for improving the portability of supervised stochastic systems, one under-utilized resource is the lexicon. Many supervised approaches depend heavily on lexical cues, and balk when given data with out-of-vocabulary lexical items.

97
Perguntas Qual a população de que seu córpus é uma amostra?
Qual a melhor maneira de lidar com o problema da representatividade? Que conselho você daria a alguém para se precaver das críticas relativas à falta de representatividade de corpus? Quais as diferenças entre Linguística de Córpus e PLN? Qual das 8 definições de córpus que lhe parece mais adequada/útil ao seu contexto de pesquisa?

98
Perguntas Quais as vantagens e desvantagens de se usar a Web como córpus? Qual a diferença de se usar a Web como córpus e como fonte de córpus? Você já usou a Web como fonte de córpus? Como córpus? Quais desafios você enfrentou/prevê? Que ferramentas você usa para análise de córpus? Você já notou problemas de aferição de frequência com esta ferramenta?

99
Textos de Suporte MORRISON, Alan; POPHAM, Michael; WIKANDER, Karen. Creating and Documenting Electronic Texts: A Guide to Good Practice. Disponível em: Acesso em 14/10/2008. (Produced by AHDS Literature, Languages and Linguistics) WYNNE, M. (Ed). Developing Linguistic Corpora: a Guide to Good Practice. Disponível em: . Acesso em14/10/2008. (Produced by AHDS Literature, Languages and Linguistics) ALUÍSIO, S. M., ALMEIDA, G. M. de B. O que é e como se constrói um corpus? Lições aprendidas na compilação de vários corpora para pesquisa lingüística. Calidoscópio (UNISINOS). , v.4, p , Disponível em: Martha Palmer, Randee Tangi, Stephanie Strassel, Christiane Fellbaum, Eduard Hovy. Historical Development and Future Directions in Data Resource Development. Relato do da área de Recursos Lingüísticos do Workshop MINDS. Disponível em:
 WYNNE, M. (Ed). Developing Linguistic Corpora: a Guide to Good Practice. Disponível em: . Acesso em14/10/2008. (Produced by AHDS Literature, Languages and Linguistics) ALUÍSIO, S. M., ALMEIDA, G. M. de B. O que é e como se constrói um corpus Lições aprendidas na compilação de vários corpora para pesquisa lingüística. Calidoscópio (UNISINOS). , v.4, p , Disponível em: Martha Palmer, Randee Tangi, Stephanie Strassel, Christiane Fellbaum, Eduard Hovy. Historical Development and Future Directions in Data Resource Development. Relato do da área de Recursos Lingüísticos do Workshop MINDS. Disponível em:")
100
Referências McENERY T. & WILSON A. (1996) Corpus linguistics, Edinburgh: Edinburgh University Press. BERBER SARDINHA, T. (2004) Lingüística de Corpus. São Paulo: Manole. GARSIDE, R.; LEECH, G.; MCENERY, A.M. (eds.) (1997). Corpus Annotation. Longman. BIBER, D.; S. Conrad; R. Reppen. (1998). Corpus linguistics: Investigating language structure and use. Cambridge University Press, Cambridge. ATKINS, S.; CLEAR, J.; OSTLER, N. (1992). Corpus design criteria. Journal of Literary and Linguistic Computing 7(1). CHURCH, K. and MERCER, R. (1993) Introduction to the Special Issue on Computational Linguistics using Large Corpora, Computational Linguistics Volume 19, Number 1, 1-24. KILGARIFF, A. and GREFENSTETTE, G. (2003) Introduction to the Special Issue on the Web as a Corpus, Computational Linguistics Volume 2, Number 3, LEECH, G. (1992) "Corpora and theories of linguistic performance", in Svartvik, J. Directions in Corpus Linguistics, pp Berlin: Mouton de Gruyter. SANTOS, Diana. "Corporizando algumas questões". In Stella E. O. Tagnin & Oto Araújo Vale (orgs.), Avanços da Lingüística de Corpus no Brasil, Editora Humanitas/FFLCH/USP, São Paulo, 2008, pp
 Lingüística de Corpus. São Paulo: Manole. GARSIDE, R.; LEECH, G.; MCENERY, A.M. (eds.) (1997). Corpus Annotation. Longman. BIBER, D.; S. Conrad; R. Reppen. (1998). Corpus linguistics: Investigating language structure and use. Cambridge University Press, Cambridge. ATKINS, S.; CLEAR, J.; OSTLER, N. (1992). Corpus design criteria. Journal of Literary and Linguistic Computing 7(1). CHURCH, K. and MERCER, R. (1993) Introduction to the Special Issue on Computational Linguistics using Large Corpora, Computational Linguistics Volume 19, Number 1, KILGARIFF, A. and GREFENSTETTE, G. (2003) Introduction to the Special Issue on the Web as a Corpus, Computational Linguistics Volume 2, Number 3, LEECH, G. (1992) Corpora and theories of linguistic performance , in Svartvik, J. Directions in Corpus Linguistics, pp Berlin: Mouton de Gruyter. SANTOS, Diana. Corporizando algumas questões . In Stella E. O. Tagnin & Oto Araújo Vale (orgs.), Avanços da Lingüística de Corpus no Brasil, Editora Humanitas/FFLCH/USP, São Paulo, 2008, pp")
Apresentações semelhantes