Carregar apresentação
A apresentação está carregando. Por favor, espere

1
Prof. João Paulo A. Almeida (jpalmeida@inf.ufes.br) 2011/01 - INF02799
Processamento Paralelo Arquitetura de Sistemas Paralelos e Distribuídos Prof. João Paulo A. Almeida 2011/01 - INF02799

2
Informações gerais Página web: Carga horária semestral total: 60 horas Horário: terças e quintas-feiras: 15:00-17:00 Local: CT-IX sala 202 (por enquanto)
")
3
Avaliação Duas provas parciais e trabalhos
A média parcial (MP) é calculada por: MP = 0,6*P + 0,4*T onde: P é a média aritmética das provas parciais e T é a média aritmética das notas dos trabalhos. A média final (MF) será: MF = MP, se MP ≥ 7,0 (e houver presença) MF = (PF + MP)/2, se MP < 7,0 (PF é a nota da prova final) Se MF ≥ 5,0 -> Aprovado Se MF < 5,0 -> Reprovado
 é calculada por: MP = 0,6*P + 0,4*T. onde: P é a média aritmética das provas parciais e. T é a média aritmética das notas dos trabalhos. A média final (MF) será: MF = MP, se MP ≥ 7,0 (e houver presença) MF = (PF + MP)/2, se MP < 7,0 (PF é a nota da prova final) Se MF ≥ 5,0 -> Aprovado. Se MF < 5,0 -> Reprovado.")
4
Material didático COULOURIS, George F.; DOLLIMORE, Jean; KINDBERG, Tim. Sistemas distribuídos: conceitos e projeto. 4. ed. Porto Alegre: Bookman, 2007. Distributed Systems: Concepts and Design, 4. ed. Addison Wesley, 2005. Pelo menos os capítulos: 1, 2, 4, 5, 9, 19, 20

5
Material didático Artigos e tutoriais online:
P.A. Bernstein. Middleware. Communications of the ACM, Vol. 39, No. 2, February 1996, P. Eugster, P. Felber, R. Gerraoui, A.M. Kermarrec, The Many Faces of Publish/Subscribe, ACM Computing Surveys, Vol. 35, No. 2, June 2003, pp. 114–131.

6
O que é um sistema distribuído?
Rede B Rede A Rede C Fonte: Luís Ferreira Pires, Universidade de Twente

7
Distribuição é um fato, parte do problema
Usuários e recursos estão fisicamente distribuídos Temos que lidar com a distribuição Exemplos: Páginas na Internet Usuários de

8
Distribuição é parte da solução
Podemos explorar distribuição Distribuição não é requisito da aplicação ou dos usuários, mas explora-se a distribuição para obter: Aplicações mais rápidas: por exemplo, com uma pesquisa de banco de dados com menor tempo de resposta; cálculos complexos / computação científica, etc. Aplicações mais confiáveis: sistemas de bancos, seguradoras, indústrias, etc. Aplicações de maior capacidade: número de caixas eletrônicos e clientes na Internet fazendo operações bancárias / pedidos / pesquisas

9
Compartilhamento de recursos
Capacidade de processamento Memória Armazenamento Banda de rede / acesso Disponibilidade Dispositivos (impressoras, monitores) Bateria
 Bateria.")
10
Níveis de paralelismo Autonomia Paralelismo no nível de instrução
Várias linhas de execução em um mesmo processador Várias linhas de execução em diferentes processadores (SMP, dual, quad core) Computadores paralelos interconectados com redes dedicadas de alta velocidade Cluster de computadores Computadores na Internet Redes compartilhadas, comunicação peer-to-peer, máquinas heterogêneas, problemas de segurança, … Autonomia
 Computadores paralelos. interconectados com redes dedicadas de alta velocidade. Cluster de computadores. Computadores na Internet. Redes compartilhadas, comunicação peer-to-peer, máquinas heterogêneas, problemas de segurança, … Autonomia.")
11
Paralelismo no nível de instrução
Velocidade (throughput) versus custo Metodologias básicas para melhorar a velocidade (fixando circuito e ISA): Simplificar organização da máquina de modo a reduzir o período do clock; Reduzir número de ciclos de clock necessários para executar uma instrução; Sobrepor a execução das instruções (pipelines!!!) Uma CPU, fazendo uso mais adequado do hardware
 versus custo. Metodologias básicas para melhorar a velocidade (fixando circuito e ISA): Simplificar organização da máquina de modo a reduzir o período do clock; Reduzir número de ciclos de clock necessários para executar uma instrução; Sobrepor a execução das instruções (pipelines!!!) Uma CPU, fazendo uso mais adequado do hardware.")
12
Paralelismo no nível de instrução
Exemplo da lavanderia Patrícia, Fernanda, Pedro, João têm cada um saco de roupas para lavar, secar e dobrar O ciclo de lavagem leva 30 minutos O de secagem leva 30 minutos O tempo para dobrar é de 30 minutos O funcionário leva 30 minutos para colocar as roupas no armário A

13
Lavanderia sequencial
6 PM 7 8 9 10 11 12 1 2 AM 30 30 30 30 30 30 30 30 30 30 30 30 30 30 30 30 Tempo A B C D De maneira sequencial, eles levam 8 horas para 4 cargas Quanto tempo levaria se eles utilizassem a técnica de pipeline?

14
Lavanderia paralela (pipeline)
6 PM 7 8 9 10 11 12 1 2 AM B C D A 30 Tempo T a s k O r d e Lavanderia Pipelined leva 3.5 horas para 4 cargas!

15
Paralelismo no nível de instrução
I-Fetch 5 estágios básicos Carrega (fetch) instrução (F) decodifica instrução instruction / lê registradores (R) executa (X) acessa memória (M) armazena resultados nos registradores (W) Decode Execute Memory Write Result
 instrução (F) decodifica instrução instruction / lê registradores (R) executa (X) acessa memória (M) armazena resultados nos registradores (W) Decode. Execute. Memory. Write. Result.")
16
Paralelismo no nível de instrução
F R X M W F R X M W F R X M W Instrução F R X M W F R X M F R X

17
Paralelismo no nível de instrução
Pipelining é um mecanismo que permite a sobreposição temporal das diversas fases da execução de instruções Aumenta o throughput das instruções (mais instruções são executadas por unidade de tempo). Porém, pipeline não ajuda na latência da execução de uma única instrução
. Porém, pipeline não ajuda na latência da execução de uma única instrução.")
18
Paralelismo no nível de instrução
Assume independência entre fases da execução da instrução Não é sempre o caso (ex., saltos condicionais) levam a ociosidade Afeta a eficiência Um assuntos para arquitetura de computadores...
 levam a ociosidade. Afeta a eficiência. Um assuntos para arquitetura de computadores...")
19
Níveis de paralelismo Autonomia Paralelismo no nível de instrução
Várias linhas de execução em um mesmo processador Várias linhas de execução em diferentes processadores (SMP, dual, quad core) Computadores paralelos interconectados com redes dedicadas de alta velocidade Cluster de computadores Computadores na Internet Redes compartilhadas, comunicação peer-to-peer, máquinas heterogêneas, problemas de segurança, … Autonomia
 Computadores paralelos. interconectados com redes dedicadas de alta velocidade. Cluster de computadores. Computadores na Internet. Redes compartilhadas, comunicação peer-to-peer, máquinas heterogêneas, problemas de segurança, … Autonomia.")
20
Várias linhas de execução: um processador
Paralelismo “simulado” processos threads “Logicamente” há várias linhas de execução “Fisicamente” não há Um assunto de sistemas operacionais... ... mas uso de multi-threading / processos é muito importante na programação de sistemas distribuídos Fonte: Douglas Schmidt

21
Níveis de paralelismo Autonomia Paralelismo no nível de instrução
Várias linhas de execução em um mesmo processador Várias linhas de execução em diferentes processadores (SMP, dual, quad core) Computadores paralelos interconectados com redes dedicadas de alta velocidade Cluster de computadores Computadores na Internet Redes compartilhadas, comunicação peer-to-peer, máquinas heterogêneas, problemas de segurança, … Autonomia
 Computadores paralelos. interconectados com redes dedicadas de alta velocidade. Cluster de computadores. Computadores na Internet. Redes compartilhadas, comunicação peer-to-peer, máquinas heterogêneas, problemas de segurança, … Autonomia.")
22
Vários processadores, memória compartilhada
Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by B. Wilkinson & M. Allen,

23
Vários processadores, memória compartilhada
Symmetric Multiprocessing / SMP: Processadores idênticos / multi core Memória compartilhada Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by B. Wilkinson & M. Allen,

24
Quad Pentium multi-core: vários processadores, mesmo chip
Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by B. Wilkinson & M. Allen,

25
Processador de 3 cores Xenon no Xbox 360

26
Multi-computadores / Computadores paralelos Memória Local

27
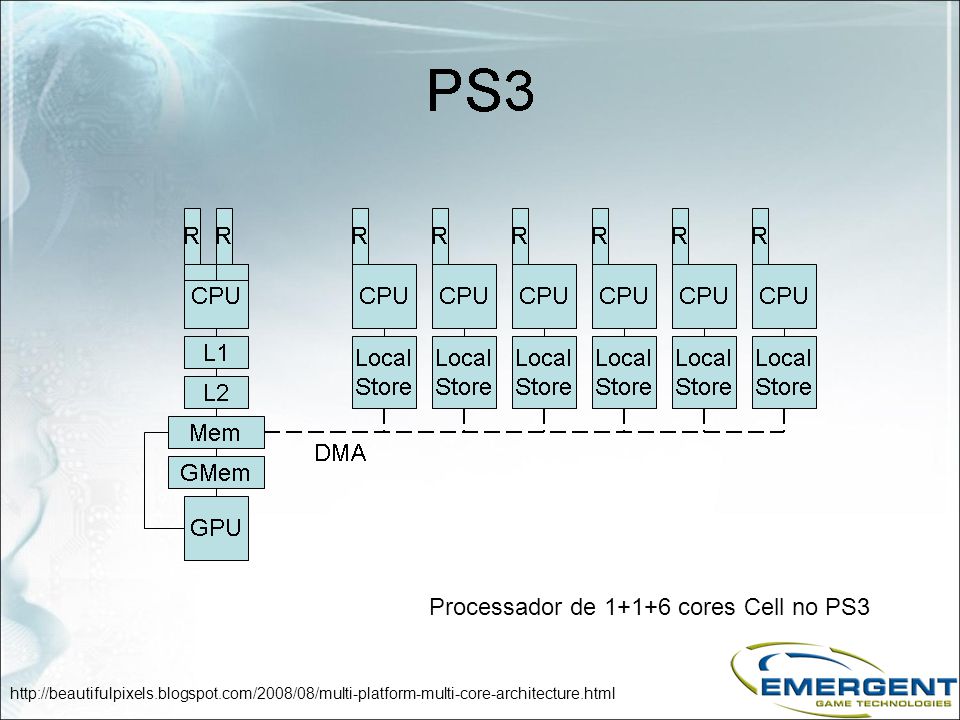
Processador de 1+1+6 cores Cell no PS3
28
Memória Compartilhada Distribuída
NUMA (Non-Uniform Memory Access) Acesso à memória local é mais rápido que acesso à memória remota
 Acesso à memória local é mais rápido que acesso à memória remota.")
29
CUDA

30
Supercomputadores O termo não tem muito sentido arquitetural
Só para identificar os (multi)computadores que tem maior poder de processamento quando são construídos Ou usado para falar sobre “computação de alto desempenho”
computadores que tem maior poder de processamento quando são construídos. Ou usado para falar sobre computação de alto desempenho")
31
Supercomputadores (nov. 2010)
Rank Site Computer/Year Vendor Cores Rmax Rpeak TFlops Power (KW) 1 National Supercomputing Center in Tianjin China Tianhe-1A - NUDT TH MPP, X Ghz 6C, NVIDIA GPU, FT C / 2010 NUDT 186368 2 DOE/SC/Oak Ridge National Laboratory United States Jaguar - Cray XT5-HE Opteron 6-core 2.6 GHz / 2009 Cray Inc. 224162 3 National Supercomputing Centre in Shenzhen (NSCS) China Nebulae - Dawning TC3600 Blade, Intel X5650, NVidia Tesla C2050 GPU / 2010 Dawning 120640 4 GSIC Center, Tokyo Institute of Technology Japan TSUBAME HP ProLiant SL390s G7 Xeon 6C X5670, Nvidia GPU, Linux/Windows / 2010 NEC/HP 73278 5 DOE/SC/LBNL/NERSC United States Hopper - Cray XE6 12-core 2.1 GHz / 2010 Cray Inc. 153408 In 2010, the fastest PC processors six-core has a theoretical peak performance of 0.107 TFLOPS (Intel Core i7 980 XE)
 1. National Supercomputing Center in Tianjin China. Tianhe-1A - NUDT TH MPP, X Ghz 6C, NVIDIA GPU, FT C / 2010 NUDT DOE/SC/Oak Ridge National Laboratory United States. Jaguar - Cray XT5-HE Opteron 6-core 2.6 GHz / 2009 Cray Inc National Supercomputing Centre in Shenzhen (NSCS) China. Nebulae - Dawning TC3600 Blade, Intel X5650, NVidia Tesla C2050 GPU / 2010 Dawning GSIC Center, Tokyo Institute of Technology Japan. TSUBAME HP ProLiant SL390s G7 Xeon 6C X5670, Nvidia GPU, Linux/Windows / 2010 NEC/HP DOE/SC/LBNL/NERSC United States. Hopper - Cray XE6 12-core 2.1 GHz / 2010 Cray Inc In 2010, the fastest PC processors six-core has a theoretical peak performance of TFLOPS (Intel Core i7 980 XE)")
32
http://www.top500.org/lists/2010/11/performance_development i7 2010
6-cores

33
No Brasil #29 National Institute for Space Research (INPE)
Tupã - Cray XT6 (AMD) 12-core 2.1 GHz / 2010 Cray Inc. 30720 cores Rmax Tflops Rpeak Tflops
 12-core 2.1 GHz / 2010 Cray Inc cores. Rmax Tflops. Rpeak Tflops.")
34
No Brasil 6464 cores #116 NACAD/COPPE/UFRJ Brazil
Intel EM64T Xeon X55xx (Nehalem-EP)
")
35
Cyclops64 (Blue Gene/C) Arquitetura celular
Objetivo: 1.1 Pflops

36
Cyclops64 (Blue Gene/C) Cada chip contém 80 processadores de 64-bits / 500 MHz, cada processador suporta 2 linhas de execução (threads). 80 gigaflops por chip (desempenho teórico de pico)
")
37
Cyclops64 (Blue Gene/C) x4
 x4")
38
Cyclops64 (Blue Gene/C) x4 x48
 x4 x48")
39
Cyclops64 (Blue Gene/C) x4 x48 x72
 x4 x48 x72")
40
Para quem perdeu as contas...
2 x 80 x 4 x 48 x 72 linhas de execução 1.1 Pflops 13.8 TB RAM

42
Taxonomia de Flynn Single Instruction Multiple Instruction Single Data SISD (PCs / Mainframes) MISD (redundância, ex: avião) Multiple Data SIMD (vector / array) MIMD (maioria dos supercomputadores atuais)
 Multiple Data. SIMD. (vector / array) MIMD. (maioria dos supercomputadores atuais)")
43
SIMD Single Instruction Multiple Data Computadores vetoriais

44
Cluster (MIMD)
")
45
Cluster Não surpreendente: Antigo Cluster do LCAD
Janeiro/2003 64 nós de processamento e 1 nó de administração (master) 256 MB de memória e 20Gb de capacidade de armazenamento por nó o cluster totaliza 16 GB de memória RAM e 1,2 TB de capacidade de armazenamento. Custo de montagem: US$ ,00 ATHLON XP 1800, 1.53 GHz 204 Gflop/s Não surpreendente: $ CTPETRO INFRA - FINEP
 256 MB de memória e 20Gb de capacidade de armazenamento por nó. o cluster totaliza 16 GB de memória RAM e 1,2 TB de capacidade de armazenamento. Custo de montagem: US$ ,00. ATHLON XP 1800, 1.53 GHz. 204 Gflop/s. Não surpreendente: $ CTPETRO INFRA - FINEP.")
46
Antigo Cluster do LCAD

47
Cluster

48
Clusters do LCAD Enterprise 2: 70 núcleos em 35 processadores Intel CORE 2 DUO 1.8GHz; Enterprise 3: 140 núcleos em 35 processadores Intel QUAD CORE 2.4GHz

49
Blade server farms

50
Wikimedia server farm

51
Cluster x “farms” Esta terminologia não é usada de forma rígida
Mas, tipicamente, farms tem alimentação compartilhada, algumas facilidades de gerenciamente em hardware (hot swapping) Disponibilidade além de capacidade de processamento Problemas de fácil paralelização Servidores web Distribuição de carga (load balancing)
 Disponibilidade além de capacidade de processamento. Problemas de fácil paralelização. Servidores web. Distribuição de carga (load balancing)")
52
Dificuldades HVAC - heating, ventilating, and air conditioning
Refrigeração desempenho por watt dissipado Antigo Cluster do LCAD dois ar-condicionados (totalizando BTU's) + ventilador de teto + ventiladores das CPUs sensores de temperatura Refrigeração a líquido Muitos farms têm refrigeração compartilhada
 + ventilador de teto + ventiladores das CPUs. sensores de temperatura. Refrigeração a líquido. Muitos farms têm refrigeração compartilhada.")
53
Dificuldades Falhas Com muitos elementos não há como não haver falhas
Faça um cálculo de probabilidade: 1024 máquinas, com taxa λ de falha... Qual a taxa de falha da máquina como um todo, se a máquina tivesse que funcionar a todo momento?

54
Programação de Clusters / Multicomputadores
Os multicomputadores têm muitas vezes sistemas operacionais dedicados E programação de baixo nível de abstração que é dependente da arquitetura Não há mecanismos sofisticados de estruturação de software como os que nós vamos estudar Por exemplo, orientado a objetos ou orientado a componentes

55
Computação de alto desempenho na Internet
Formação de clusters virtuais (grid) (na Internet) BOINC 500 Tflop/s (média), Jan. 2007 925 Tflops/s (média), Fev. 2008 1.287 Pflops, Dez. 2008 Com computadores 5.1 PFLOPS as of April 21, 2010 Universidade da Califórnia, Berkeley
 (na Internet) BOINC Tflop/s (média), Jan Tflops/s (média), Fev Pflops, Dez Com computadores. 5.1 PFLOPS as of April 21, Universidade da Califórnia, Berkeley.")
56
Botnets http://en.wikipedia.org/wiki/Botnet Date created Name
Estimated no. of bots Spam capacity Aliases 2009 (May) BredoLab 30,000,000 3.6 billion/day Oficla 2008 (around) Mariposa 12,000,000 0 ? ? Conficker 10,500,000+ 10 billion/day DownUp, DownAndUp, DownAdUp, Kido Zeus 3,600,000 (US Only) -1n/a Zbot, PRG, Wsnpoem, Gorhax, Kneber 2007 (Around) Cutwail 1,500,000 74 billion/day Pandex, Mutant (related to: Wigon, Pushdo) Grum 560,000 39.9 billion/day Tedroo Mega-D 509,000 Ozdok Kraken 495,000 9 billion/day Kracken
 BredoLab. 30,000, billion/day. Oficla (around) Mariposa. 12,000, Conficker. 10,500, billion/day. DownUp, DownAndUp, DownAdUp, Kido. Zeus. 3,600,000 (US Only) -1n/a. Zbot, PRG, Wsnpoem, Gorhax, Kneber (Around) Cutwail. 1,500, billion/day. Pandex, Mutant (related to: Wigon, Pushdo) Grum. 560, billion/day. Tedroo. Mega-D. 509,000. Ozdok. Kraken. 495, billion/day. Kracken.")
57
Aplicações distribuídas: interação entre partes
Rede B Rede A Rede C A complexidade às vezes está na forma de interação ou na coordenação entre as partes distribuídas

58
Aplicações distribuídas: interação entre partes
Rede B Rede A Rede C A complexidade às vezes está na forma de interação ou na coordenação entre as partes distribuídas

59
Diferentes modelos de interação
RPC – Remote Procedure Call Orientado a objetos distribuídos Distributed Objects Remote Method Invocation Orientado a passagem de mensagem Orientado a eventos (publish/subscribe) Orientado a streams (fluxo de dados) Multimedia streams: áudio e vídeo Orientado a serviços
 Orientado a streams (fluxo de dados) Multimedia streams: áudio e vídeo. Orientado a serviços.")
60
Falhas independentes Partes de um sistema podem falhar por diversos motivos banais: falta de energia elétrica erros de projeto (programação) no desenvolvimento de uma parte do sistema crashes de sistemas operacionais falha de hardware
 no desenvolvimento de uma parte do sistema. crashes de sistemas operacionais. falha de hardware.")
61
Falhas independentes “A distributed system is one in which the failure of a computer you didn’t even know existed can render your own computer unusable.” (Lesley Lamport, 1992)
")
62
Particionamento de rede
Rede B Rede A Rede C

63
Atraso, limitações de banda
Redes impões atraso na comunicação Não somente pela capacidade de transmissão (banda) mas também pela distância geográfica
 mas também pela distância geográfica.")
64
Escalabilidade O sistema deverá permanecer eficiente mesmo com um aumento no número de usuários (carga) e recursos: Sistema deverá comportar aumento de recursos Custo de adicionar recursos deve ser razoável Perda de desempenho com aumento de usuários/carga deve ser limitado Escalabilidade de sistemas distribuídos agrega valor: Imagina uma web que fosse limitada no número de páginas, usuários conectados simultaneamente…

65
Heterogeneidade Diferentes arquiteturas de hardware
Intel, Apple, telefones celulares, … Diferentes sistemas operacionais Windows (e suas versões), UNIX (e suas variantes), VMS e outros sistemas legados, sistemas operacionais de tempo real, sistemas operacionais para dispositivos móveis (e.g., Symbian, Windows Mobile) Diferentes tipos de rede Apesar do TCP/IP ter dominado os níveis de transporte/rede Diferentes linguagens de programação Diferentes implementações
, UNIX (e suas variantes), VMS e outros sistemas legados, sistemas operacionais de tempo real, sistemas operacionais para dispositivos móveis (e.g., Symbian, Windows Mobile) Diferentes tipos de rede. Apesar do TCP/IP ter dominado os níveis de transporte/rede. Diferentes linguagens de programação. Diferentes implementações.")
66
Heterogeneidade Fonte:

67
Padronização Padronização de algumas partes necessárias para interoperabilidade Interoperabilidade: capacidade de sistemas de trabalhar em conjunto Padronização necessária para portabilidade Portabilidade: capacidade de (partes/componentes de) sistemas de serem usados em vários contextos Não há como padronizar tudo E os padrões também mudam com o tempo
 sistemas de serem usados em vários contextos. Não há como padronizar tudo. E os padrões também mudam com o tempo.")
68
Padronização e “Abertura” (Openness)
Interfaces mais importantes são publicadas (documentadas) Mecanismo de comunicação uniforme, compartilhado Cada parte pode ser construída independentemente por diferentes vendedores/desenvolvedores Portanto devem se adequar a padrões e interfaces publicadas
 Mecanismo de comunicação uniforme, compartilhado. Cada parte pode ser construída independentemente por diferentes vendedores/desenvolvedores. Portanto devem se adequar a padrões e interfaces publicadas.")
69
Segurança Rede B Rede A Rede C

70
Segurança Confidentiality- Confidencialidade Integrity - Integridade
Availability – Disponibilidade ... da informação e de serviços Confidencialidade - propriedade que limita o acesso somente às entidades legítimas, ou seja, àquelas autorizadas pelo proprietário da informação Integridade - propriedade que garante que a informação e serviços mantenham as características originais estabelecidas pelo proprietário Disponibilidade - propriedade que garante que a informação e serviços estejam sempre disponíveis para o uso legítimo

71
Segurança Hackers também podem explorar a distribuição para seu benefício Ataques de larga escala que levam à indisponibilidade de sistemas (Denial Of Service attacks) Acesso a sistemas mau configurados e seus recursos; pense em: Disco e Banda (pirataria, material ilegal) Processamento (para quebra de criptografia) Processamento e Banda (SPAM)
 Acesso a sistemas mau configurados e seus recursos; pense em: Disco e Banda (pirataria, material ilegal) Processamento (para quebra de criptografia) Processamento e Banda (SPAM)")
72
Diferentes domínios de administração
Partes do sistema podem pertencer a diferentes organizações Autonomia no nível organizacional Diferentes tecnologias e padrões Diferentes procedimentos de manutenção Exacerba o problema de heterogeneidade Exacerba o problema de falhas independentes Exacerba o problema de segurança ≥ ≥

73
Aplicações centralizadas x Aplicações distribuídas
Custo de comunicação entre partes do sistema Falhas Particionamento Aplicações Centralizadas Baixo Todas partes do sistema falham em conjunto Não há Aplicações Distribuídas Mais alto / Variável Partes falham independentemente Partes podem ficar sem comunicação

74
Aplicações centralizadas x Aplicações distribuídas
Segurança Escalabilidade … Aplicações Centralizadas Controle mais simples Limitada por natureza Aplicações Distribuídas Vários pontos de entrada Depende de projeto adequado

75
Próxima Aula Vamos pisar no chão: middleware Rede B Rede A Rede C

76
Níveis de paralelismo Autonomia Paralelismo no nível de instrução
Várias linhas de execução em um mesmo processador Várias linhas de execução em diferentes processadores (dual, quad core) Computadores paralelos interconectados com redes dedicadas de alta velocidade Cluster de computadores Computadores na Internet Redes compartilhadas, comunicação peer-to-peer, máquinas heterogêneas, problemas de segurança, … Autonomia
 Computadores paralelos. interconectados com redes dedicadas de alta velocidade. Cluster de computadores. Computadores na Internet. Redes compartilhadas, comunicação peer-to-peer, máquinas heterogêneas, problemas de segurança, … Autonomia.")
Apresentações semelhantes













 em um único chip.>")





