Carregar apresentação
A apresentação está carregando. Por favor, espere

1
Aula 03: Análise de Performance e Benchmarks
ARQUITETURA DE COMPUTADORES DEPT. DE CIÊNCIA DA COMPUTAÇÃO - UFMG

2
O Perigo das Previsões...

3
O Perigo das Previsões...

4
Ferramentas para Medidas de Performance
Benchmarks, Traces, Mixes Custo, atraso, área, estimativa de potência Simulação (muitos níveis) ISA, RT, Gate, Circuito Teoria das filas Basic Rules Leis fundamentais
 ISA, RT, Gate, Circuito. Teoria das filas. Basic Rules. Leis fundamentais.")
5
Performance (e Custo) Tempo para rodar tarefa (ExTime ou ET)
Avião DC à Paris 6.5 horas 3 horas Veloc. 610 mph 1350 mph Passageiros 470 132 Throughput (pmph) 286,700 178,200 Boeing 747 BAD/Sud Concodre Tempo para rodar tarefa (ExTime ou ET) tempo de execução, tempo de resposta, latência Tarefas por dia, hora, semana, sec, ns … (Performance) Throughput, bandwidth
 286, ,200. Boeing 747. BAD/Sud Concodre. Tempo para rodar tarefa (ExTime ou ET) tempo de execução, tempo de resposta, latência. Tarefas por dia, hora, semana, sec, ns … (Performance) Throughput, bandwidth.")
6
Performance (e Custo) "X é n vezes mais veloz que Y" significa
ExTime(Y) Performance(X) = ExTime(X) Performance(Y) Velocidade do Concorde vs. Boeing 747 Throughput do Boeing 747 vs. Concorde
 Performance(X) = ExTime(X) Performance(Y) Velocidade do Concorde vs. Boeing 747. Throughput do Boeing 747 vs. Concorde.")
7
Terminologia de Performance
“X é n% mais veloz que Y” significa: ExTime(Y) Performance(X) n = = ExTime(X) Performance(Y) n = 100(Performance(X) - Performance(Y)) Performance(Y) Exemplo: Y leva 15 segundos para completar tarefa, X leva 10 segundos. Quantos % X é mais rápido?
 Performance(X) n = = ExTime(X) Performance(Y) 100. n = 100(Performance(X) - Performance(Y)) Performance(Y) Exemplo: Y leva 15 segundos para completar tarefa, X leva 10 segundos. Quantos % X é mais rápido")
8
Exemplo ExTime(Y) ExTime(X) 15 10 1.5 1.0 Performance (X)
Performance (Y) = = = 100 ( ) 1.0 n = n = 50%
 = = = 100 ( ) 1.0. n. = n. = 50%")
9
Lei de Amdahl Speedup devido à melhoria E:
ExTime sem E Performance com E Speedup(E) = = ExTime com E Performance sem E Suponha que melhoria E acelere porção F da tarefa por fator S, e que restante da tarefa permanece sem alteração, então ExTime(E) = Speedup(E) =
 = = ExTime com E Performance sem E. Suponha que melhoria E acelere porção F da tarefa por fator S, e que restante da tarefa permanece sem alteração, então. ExTime(E) = Speedup(E) =")
10
Lei de Amdahl ExTimenew = ExTimeold x (1 - Fractionenhanced) + Fractionenhanced Speedupenhanced 1 ExTimeold ExTimenew Speedupoverall = = (1 - Fractionenhanced) + Fractionenhanced Speedupenhanced Em última análise, performance de qualquer sistema será limitada por porção que não é melhorada...
 + Fractionenhanced. Speedupenhanced. Em última análise, performance de qualquer sistema será limitada por porção que não é melhorada...")
11
Lei de Amdahl Instruções de ponto flutuante são melhoradas para rodar 2X mais rápidas, mais somente 10% das instruções são de ponto flutuante (FP). ExTimenew = Speedupoverall =

12
Lei de Amdahl Instruções de ponto flutuante são melhoradas para rodar 2X mais rápidas, mais somente 10% das instruções são de ponto flutuante (FP). ExTimenew = ExTimeold x ( /2) = 0.95 x ExTimeold 1 Speedupoverall = = 1.053 0.95
 = 0.95 x ExTimeold. 1. Speedupoverall. = =")
13
Corolário: Make the common case fast
Todas as instruções requerem busca de instrução, somente uma fração requer busca ou escrita de dados. Otimize acessos à instruções ao invés de otimizar o acesso a dados Programas exibem localidade de referência Localidade espacial Localidade temporal Acesso a memórias menores é mais rápido Mantenha hierarquia de memória de modo a fazer acessos mais freqüentes estar localizados nas memórias menores. CPU Reg's Cache Memória Disco / Fita

14
Regra Básica: Make the common case fast
Os casos mais simples são usualmente mais freqüentes e mais fáceis de se otimizar!!! Faça as coisas simples e rápidas em hardware e tenha certeza de que o resto seja feito corretamente em software.

15
Métricas de Performance
Compilador Linguagens de Programação Aplicação Datapath Control Transistores Lógica ISA Unidades Funcionais Respostas por mês Operações por segundo (milhões) de instruções por segundo: MIPS (milhões) de operações FP por segundo: MFLOP/s Megabytes / segundo Ciclos por segundo (clock rate)
 de instruções por segundo: MIPS. (milhões) de operações FP por segundo: MFLOP/s. Megabytes / segundo. Ciclos por segundo (clock rate)")
16
Aspectos da Performance de uma CPU
CPU time = Seconds = Instructions x Cycles x Seconds Program Program Instruction Cycle Instr. Cnt CPI Clock Rate Programa X Compilador X (X) Conj. Instrs X X Organização X X Tecnologia X
 Conj. Instrs. X X. Organização X X. Tecnologia X.")
17
Métricas de Marketing MIPS = IC / CPU time * 10^6 = Clock Rate / CPI * 10^6 Máquinas com diferentes conjuntos de instruções ? Programas com instruções diferentes ? Freqüência dinâmica das instruções Sem correlação com performance MFLOP/s = Operações FP / CPU time * 10^6 Dependente de máquina Tempo da máquina pode estar sendo gasto em outro lugar Normalizado: add,sub,compare,mult 1 div, sqrt exp, sin,

18
Ciclos Por Instrução Cycles per Instruction
“Média do número de ciclos por instrução CPI = (CPU Time * Clock Freq) / Instruction Count = Cycles / Instruction Count n CPU time = Cycle Time * S CPI * I i i i = 1 “Freqüência de instruções” n CPI = S CPI * F onde F = IC i i i i i = 1 Instruction Count
 / Instruction Count. = Cycles / Instruction Count. n. CPU time = Cycle Time * S CPI * I. i. i. i = 1. Freqüência de instruções n. CPI = S CPI * F onde F = IC. i. i. i. i. i = 1. Instruction Count.")
19
Compromissos da Organização da CPU
Compilador Linguagens de Programação Aplicação Datapath Control Transistores Lógica ISA Unidades Funcionais Instruction Mix CPI Cycle Time

20
Exemplo de Cálculo de CPI
Típico Máquina Base (Reg / Reg) Operação Freq Ciclos CPI(i) (% Time) ALU 50% (33%) Load 20% (27%) Store 10% (13%) Branch 20% (27%) 1.5
 Operação Freq Ciclos CPI(i) (% Time) ALU 50% 1 .5 (33%) Load 20% 2 .4 (27%) Store 10% 2 .2 (13%) Branch 20% 2 .4 (27%) 1.5.")
21
Exemplo Adição de operações registrador / memória:
Um operando em memória Um operando em registrador Leva 2 ciclos para completar Branch passa a levar 3 ciclos para completar. Que fração dos loads tem que ser eliminada para modificação ser vantajosa? Máquina Base (Reg / Reg) Operação Freq Ciclos ALU 50% 1 Load 20% 2 Store 10% 2 Branch 20% 2 Típico
 Operação Freq Ciclos. ALU 50% 1. Load 20% 2. Store 10% 2. Branch 20% 2. Típico.")
22
Solução Exec Time = Instr Cnt x CPI x Clock Op Freq Ciclos Freq Ciclos ALU – X 1 .5 – X Load – X 2 .4 – 2X Store Branch Reg/Mem X 2 2X – X (1.7 – X)/(1 – X) Instr CntOld x CPIOld x ClockOld = Instr CntNew x CPINew x ClockNew x = (1 – X) x (1.7 – X)/(1 – X) = – X = X TODOS os loads devem ser eliminados para esta versão ser vantajosa!
/(1 – X) Instr CntOld x CPIOld x ClockOld = Instr CntNew x CPINew x ClockNew x 1.5 = (1 – X) x (1.7 – X)/(1 – X) 1.5 = 1.7 – X. 0.2 = X. TODOS os loads devem ser eliminados para esta versão ser vantajosa!")
23
Programas para Avaliação da Performance de Processadores
(Toy) Benchmarks Programas de linhas e.g.: sieve, puzzle, quicksort Benchmarks sintéticos Tentativa de se ter na média a mesma freqüência de instruções de programas reais e.g., Whetstone, dhrystone Kernels Partes críticas de programas reais e.g., Livermore loops Programas reais e.g., gcc, spice
 Benchmarks. Programas de linhas. e.g.: sieve, puzzle, quicksort. Benchmarks sintéticos. Tentativa de se ter na média a mesma freqüência de instruções de programas reais. e.g., Whetstone, dhrystone. Kernels. Partes críticas de programas reais. e.g., Livermore loops. Programas reais. e.g., gcc, spice.")
24
Truques Utilizados para Ganhar o Jogo dos Benchmarks
Configurações diferentes das máquinas utilizadas para rodar o mesmo programa Compilador otimizado para benchmark Utilizar benchmark escrito para melhorar performance de uma única máquina Sincronizar jobs intensivos em CPU/IO Utilização de benchmarks pequenos Benchmarks “compilados na mão” para otimizar performance

25
Erros Comuns em Benchmarking
Variações das demandas de dispositivos ignorados Loading level controlled inappropriately Efeitos de cache ignorados Tamanho de buffers inapropriados Imprecisão devido a amostragem ignorada

26
Erros Comuns em Benchmarking
Ignorar overhead dos monitores Medições sem validação Não manter mesmas condições iniciais Não medir performance transiente (cold start) Coleta de muitos dados com pouca análise
 Coleta de muitos dados com pouca análise.")
27
SPEC: System Performance Evaluation Cooperative
Primeiro Round 1989 10 programas Segundo Round 1992 SpecInt92 (6 programas inteiros) e SpecFP92 (14 programas de ponto flutuantes) Sem limite para flags de compiladores Terceiro Round 1995 Limite de um único flag para todos os programas Novo conjunto de programas Quarto Round 2000 CPU 2000, CFP 2000, SPECviewperf
 e SpecFP92 (14 programas de ponto flutuantes) Sem limite para flags de compiladores. Terceiro Round Limite de um único flag para todos os programas. Novo conjunto de programas. Quarto Round CPU 2000, CFP 2000, SPECviewperf.")
28
SPEC Primeiro Round Um programa: 99% do tempo em única linha de código
Fácil para compilador (não testa a máquina)
")
29
Como Agrupar Dados de Medições de Performance
Média aritmética Média harmônica Média geométrica

30
Média Aritmética 1 10 20 1000 100 500.50 55.00 20.00 P1 (seg) P2 (seg)
Computer A Computer B Computer C P1 (seg) 1 10 20 P2 (seg) 1000 100 Total (W1) 500.50 55.00 20.00
 P2 (seg) Total (W1)")
31
Média Harmônica Usada para sumarizar resultados com taxas de execução (MIPS, MFLOPS), pois mantém relação entre tempos de execução
, pois mantém relação entre tempos de execução.")
32
Média Geométrica Usada para sumarizar resultados normalizados 1.0 10.0
Computer A Computer B Computer C P1 (seg) 1.0 10.0 20 P2 (seg) 0.1 0.02 Média Geométrica 0.63 Não corresponde a realidade do tempo de execução
 P2 (seg) Média Geométrica Não corresponde a realidade do tempo de execução.")
33
Avaliação de Performance
Vendas é uma função da performance relativa à competição. Logo, espere investimentos altos em melhoria da performance do produto dado pela melhoria da performance dos benchmarks Bons produtos aparecem quando: Bons benchmarks Boas maneiras de sumarizar a performance Se benchmarks/sumário é inadequado, então melhoria do produto para melhorar vendas sempre ganha de outras opções Ex. time é a única medida real de performance! Que tal o custo?

34
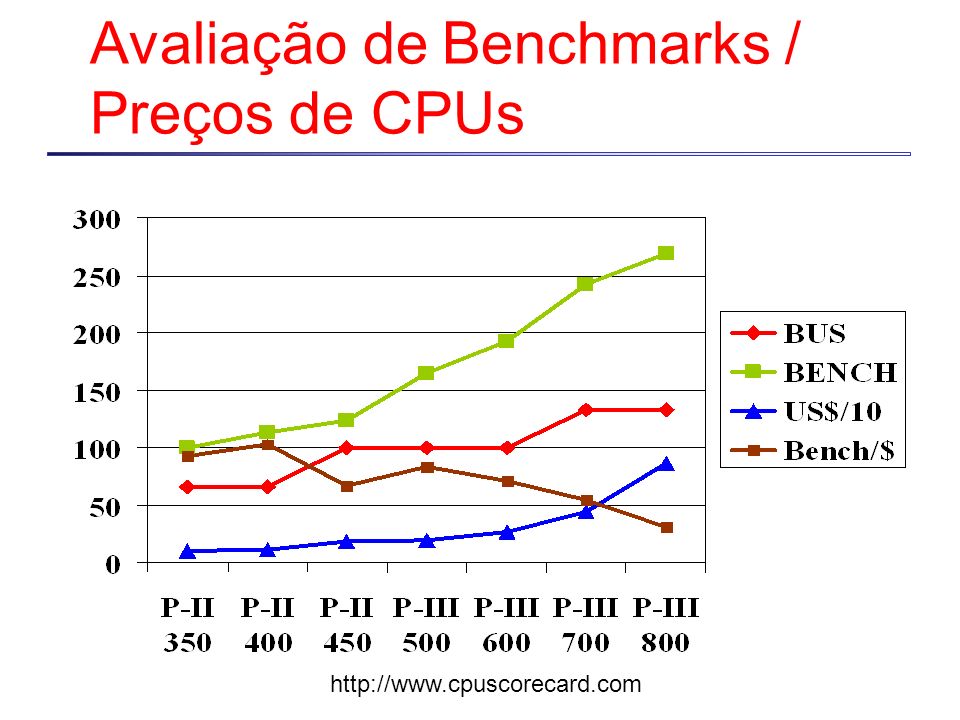
Avaliação de Benchmarks / Preços de CPUs
35
Lista de exercícios 1.1 1.2 1.7 1.8 1.14

Apresentações semelhantes

.>")

















