Carregar apresentação
A apresentação está carregando. Por favor, espere

1
Armazenamento e Organização de Arquivos
Professores: Maria Claudia Reis Cavalcanti e Ronaldo Ribeiro Goldschmidt Material adaptado das notas de aula da Professora Ana Maria de C. Moura - IME

2
Sumário Introdução e Motivação Memórias Alocação de Registros
Operações em Arquivos Organização de Arquivos em Disco Armazenamento em Dicionário de Dados Exercícios

3
Sumário Introdução e Motivação Memórias Alocação de Registros
Operações em Arquivos Organização de Arquivos em Disco Armazenamento em Dicionário de Dados Exercícios

4
Introdução e Motivação
BDs são muito grandes para caber na memória principal Discos: persistência dos BDs Usualmente, as aplicações necessitam de apenas uma pequena parte do BD a cada momento. Quando uma “porção de dados” for necessária, ela precisará ser localizada e copiada para memória principal SGBD faz muitas operações de I/O: READ: transferência de dados de disco para memória . WRITE: transferência de dados da memória para disco Operações caras, se comparadas com operações em memória A escolha de estruturas de armazenamento adequadas procura minimizar o número de operações de I/O

5
Sumário Introdução e Motivação Memórias Alocação de Registros
Operações em Arquivos Organização de Arquivos em Disco Armazenamento em Dicionário de Dados Exercícios

6
Memórias – Hierarquia CPU CACHE (RAM) MEMÓRIA PRINCIPAL
solicitação dado Armazenam. primário MEMÓRIA PRINCIPAL DISCO MAGNÉTICO Armazenam. secundário dado satisfazendo solicitação FITA Armazenam. terciário

7
Memórias Armazenamento Primário:
memória cache: RAM (random access memory) estática - usada pela CPU p/ acelerar execução de programas memória principal: DRAM (RAM dinâmica) - área de trabalho p/ armazenar/executar programas e dados custo em baixa volátil velocidade inferior à memória cache
 estática - usada pela CPU p/ acelerar execução de programas. memória principal: DRAM (RAM dinâmica) - área de trabalho p/ armazenar/executar programas e dados. custo em baixa. volátil. velocidade inferior à memória cache.")
8
leitura/ gravação bloco
Memórias Armazenamento Secundário: suporte p/ memória virtual e p/ sistema de arquivos unidade de transferência de dados entre disco e memória principal: blocos, sob controle do SO SGBD: autonomia no gerenciamento de blocos arquivo buffer de 4Kbytes leitura/ gravação bloco

9
Memórias Armazenamento Terciário:
característica principal: tempo leitura/gravação bem mais altos que o secundário; grande capacidade armazenamento; custo bem menor fitas: acesso exclusivamente seqüencial armazenamento ótico de dados: CD-ROM (Compact Disk-Read-Only Memory) Jukeboxes de discos óticos armazenam centenas de GB
 Jukeboxes de discos óticos. armazenam centenas de GB.")
10
Memórias – Custo x Benefício
Cache Memória Principal Disco (Armazenamento secundário) Armazenamento terciário VELOCIDADE DE ACESSO PREÇO DO BYTE
 Armazenamento terciário. VELOCIDADE DE ACESSO. PREÇO DO BYTE.")
11
Memórias – Acesso aos Dados
DISCO MEMÓRIA PRINCIPAL “swap” Mapeamento Programa dados Endereço virtual real .

12
Sumário Introdução e Motivação Memórias Alocação de Registros
Operações em Arquivos Organização de Arquivos em Disco Armazenamento em Dicionário de Dados Exercícios

13
Alocação de Registros “Correspondência” entre conceitos: Nível Lógico
Nível Físico Tabela Arquivo Tupla Registro Atributo Campo Chave Primária Campo Chave

14
Alocação de Registros Tipo de registro Campo Tipo de Dado
type EMPREGADO = record Nome : packed array[1..30] of character; CPF : packed array [1..11] of character; Salário : integer; Profissão : integer; Departamento : packed array[1..20] of character; end;

15
Alocação de Registros Um registro é uma coleção de valores ou itens relacionados. Cada valor é formado por um ou mais bytes e corresponde a um campo do registro. Arquivo é uma seqüência de registros. Em muitos casos, todos os registros de um arquivo são do mesmo tipo.

16
Alocação de Registros Registros são mapeados em blocos de disco.
Blocos têm tamanhos fixos. Tamanho dos registros pode variar. Em BDRs: tuplas de relações distintas variam de tamanho. tuplas de uma mesma relação podem variar de tamanho. Registros de tamanho fixo e Registros de tamanho variável.

17
Alocação de Registros Registros de Tamanho Fixo Salário Profissão Nome
CPF Departamento 1 31 42 46 50 69 Registros de Tamanho Variável Maria Silva xxxx Pessoal 1 13 24 28 32 39 Nome=Maria Silva CPF= Departamento=Pessoal 18 34 54 = separador de nome de campo / valor separador de campo separador de registro Exs de caracteres separadores:

18
Alocação de Registros Abordagens para mapeamento BD – arquivos:
Utilização de diversos arquivos. Cada arquivo contendo registros de tamanho fixo. Implementação mais simples, porém com aplicação menos econômica. Estruturação de arquivos para acomodar registros de tamanhos múltiplos. Aplicação mais econômica, porém de implementação mais complexa.

19
Organização Espalhada e Não Espalhada
bloco i registro 1 registro 2 registro 3 bloco i+1 registro 4 registro 5 registro 6 organização não espalhada (“unspanned”) (usual para registros de tamanho fixo) bloco i registro 1 registro 2 registro 3 registro 4 p bloco i+1 reg. 4 registro 5 registro 6 registro 7 p organização espalhada (“spanned”) OBS: Quando o tamanho do registro é maior que o tamanho do bloco ( R > B), a organização espalhada é obrigatória.
 (usual para registros de tamanho fixo) bloco i. registro 1. registro 2. registro 3. registro 4. p. bloco i+1. reg. 4. registro 5. registro 6. registro 7. p. organização espalhada ( spanned ) OBS: Quando o tamanho do registro é maior que o tamanho do bloco ( R > B), a organização espalhada é obrigatória.")
20
Alocação de Registros Se o tamanho do registro for inferior ao tamanho do bloco: fator de bloco (bfr)= B/R registros por bloco, onde: B: n0 de bytes do bloco R: n0 de bytes do registro P/ registros de comprimento variável, com organização espalhada cada bloco pode armazenar um n0 diferente de registros bfr: n0 médio de registros por bloco, que pode ser usado p/ calcular o n0 de blocos b requerido p/ um arquivo de r registros N0 blocos p/ arquivo= (r/bfr)
 ")
21
Alocação de Blocos em Arquivo
Alocação contígua blocos alocados consecutivamente leitura rápida dificulta expansão do arquivo Alocação encadeada cada bloco possui ponteiro para o próximo bloco facilita expansão do arquivo leitura do arquivo fica mais lenta Clusters combinação dos anteriores blocos consecutivos são alocados em clusters (segmentos/extensões) os clusters são ligados por ponteiros
 os clusters são ligados por ponteiros.")
22
Cabeçalhos de Arquivo Também denominado descritor de arquivo
Contém informações sobre o arquivo: Endereços dos blocos no disco Tamanho e ordem dos campos (formato) Tipos de dados e caracteres separadores
 Tipos de dados e caracteres separadores.")
23
Sumário Introdução e Motivação Memórias Alocação de Registros
Operações em Arquivos Organização de Arquivos em Disco Armazenamento em Dicionário de Dados Exercícios

24
Operações em Arquivos Subdividem-se em operações de recuperação (não alteram valor) e de atualização (alteram conteúdo) Em ambos os casos, pode ser necessária a localização prévia de registros Localização feita com base em condições de seleção Quando diversos registros satisfazem às condições de seleção, o primeiro registro (na seqüência física) é designado com registro atual Após processamento do registro atual, operações subseqüentes localizam o próximo registro, que passa a ser considerado o registro atual.
 é designado com registro atual. Após processamento do registro atual, operações subseqüentes localizam o próximo registro, que passa a ser considerado o registro atual.")
25
Operações em Arquivos No contexto de programas p/ SGBDs Open Reset
prepara buffers p/ receber blocos do disco (cabeçalho) posiciona início arquivo Reset arquivo já aberto, posiciona ponteiro no início do arquivo Find busca o primeiro registro que satisfaça condição e transfere bloco p/ buffer Read/Get copia conteúdo do buffer p/ variável do programa avança próximo registro FindNext procura o próximo registro que satisfaça condição e transfere bloco p/ buffer
 posiciona início arquivo. Reset. arquivo já aberto, posiciona ponteiro no início do arquivo. Find. busca o primeiro registro que satisfaça condição e transfere bloco p/ buffer. Read/Get. copia conteúdo do buffer p/ variável do programa. avança próximo registro. FindNext. procura o próximo registro que satisfaça condição e transfere bloco p/ buffer.")
26
Operações em Arquivos (cont.)
Delete Modify Insert Obs: Após realizar as 3 operações acima, o buffer em mem. principal é gravado de volta no disco Close Scan combina as operações Find, FindNext e Read, conforme necessário retorna o 10 registro após op. open/reset; senão o próximo FindAll Find n FindOrdered localiza registros, segundo sua ordenação por algum campo

27
Sumário Introdução e Motivação Memórias Alocação de Registros
Operações em Arquivos Organização de Arquivos em Disco Armazenamento em Dicionário de Dados Exercícios

28
Organização de Arquivos
Considerações Iniciais Arquivos de Registros Desordenados (Heap Files) Arquivos de Registros Ordenados (Sorted Files) Arquivos de Acesso Direto (Hash Files)
 Arquivos de Registros Ordenados (Sorted Files) Arquivos de Acesso Direto (Hash Files)")
29
Considerações Iniciais
Distinção entre Organização de Arquivo e Método de Acesso A organização de arquivo se refere à organização dos dados de um arquivo em registros, blocos e estruturas de acesso. Inclui a maneira como registros e blocos são posicionados e interligados. Um método de acesso fornece um grupo de operações que podem ser aplicadas a um arquivo. É possível aplicar vários métodos de acesso a uma organização de arquivo. No entanto, alguns métodos de acesso só podem ser aplicados a arquivos organizados de uma certa maneira.

30
Considerações Iniciais
Escolha da Organização de Arquivo e do Método de Acesso Alguns arquivos podem ser mais estáticos (poucas atualizações) enquanto outros podem ser mais dinâmicos (muitas atualizações) A organização de arquivo mais adequada deverá viabilizar da forma mais eficiente possível as operações pretendidas. Ex. com o arquivo Empregado (slide anterior): consultas freqüentes por CPF podem ser indicativo de uma organização de arquivo (ordenação física ou criação de índices) que facilite essa operação. Por outro lado para facilitar a geração cheques de pagamento os empregados deveriam ser agrupados por departamento (colocando-os em blocos interligados)
 enquanto outros podem ser mais dinâmicos (muitas atualizações) A organização de arquivo mais adequada deverá viabilizar da forma mais eficiente possível as operações pretendidas. Ex. com o arquivo Empregado (slide anterior): consultas freqüentes por CPF podem ser indicativo de uma organização de arquivo (ordenação física ou criação de índices) que facilite essa operação. Por outro lado para facilitar a geração cheques de pagamento os empregados deveriam ser agrupados por departamento (colocando-os em blocos interligados)")
31
Arquivos de Registros Desordenados (Heap Files)
Nesta organização: Não há ordem entre os registros. Novos registros são alocados onde há espaço. Incluir um registro é muito eficiente: apenas o último bloco do arquivo é lido e reescrito Eficiente em operações de seleção de todos os registros ("full table scan"). Ineficiente em operações com restrições ("where") A busca é sequencial: todos os blocos, bloco a bloco, devem ser lidos (não importa qtos registros satisfazem à consulta) A remoção de registros gera desperdícios Exige a reorganização periódica do arquivo Normalmente utilizado com estruturas adicionais (caminhos de acesso ou índices) Usado para tabelas pequenas ou temporárias (dependendo do propósito destas) Uma tecnica para reaproveitar o espaço dos registros removidos deveria manter informacoes extras sobre o bloco onde há as areas vazias... Pois se fosse necessario percorrer sequencialmente o arquivo em busca de areas vazias, recairiamos no mesmo problema das operações de consulta com restrições
. Ineficiente em operações com restrições ( where ) A busca é sequencial: todos os blocos, bloco a bloco, devem ser lidos (não importa qtos registros satisfazem à consulta) A remoção de registros gera desperdícios. Exige a reorganização periódica do arquivo. Normalmente utilizado com estruturas adicionais (caminhos de acesso ou índices) Usado para tabelas pequenas ou temporárias (dependendo do propósito destas) Uma tecnica para reaproveitar o espaço dos registros removidos deveria manter informacoes extras sobre o bloco onde há as areas vazias... Pois se fosse necessario percorrer sequencialmente o arquivo em busca de areas vazias, recairiamos no mesmo problema das operações de consulta com restrições.")
32
Arquivos de Registros Desordenados (Heap Files)
Exemplo: Codigo Nome Cidade UF Select * From Tabela; 200 Silva Rio RJ Select * From Tabela Where Codigo = 100; 400 Mendes Salvador BA Insert Into Tabela Values (310, “Ana", “Rio“, “RJ”); 300 Lima Recife PE Delete From Tabela where Codigo=400; 100 Neves Natal RN Exercício: Quais os efeitos das operações de inserção e de exclusão indicadas ? Discuta os problemas decorrentes e alternativas de tratamento.
; 300. Lima. Recife. PE. Delete From Tabela where. Codigo=400; 100. Neves. Natal. RN. Exercício: Quais os efeitos das operações de inserção e de exclusão indicadas Discuta os problemas decorrentes e alternativas de tratamento.")
33
Arquivos de Registros Ordenados (Sorted Files)
Também chamados de heap ordenados Registros ordenados segundo um campo de classificação Registros podem ser ordenados na ordem da PK (chave de classificação) Processamento eficiente qdo é preciso recuperar os registros na classificação escolhida Mesmo que não sejam todos, pois os registros próximos deverão estar em um mesmo bloco. Mas de nada adianta para buscas sobre campos não ordenados Pesquisa binária X Pesquisa linear Pesquisa binária torna eficiente operações com restrições sobre o campo de classificação Complexidade da pesquisa binária: log2n Complexidade da pesquisa linear: n/2 Para buscar um registro por uma restricao do campo-classificacao nao ha vantagem grande, pois a busca acaba sendo linear. Mas eh possivel parar ao verificar que o registro nao se encontra na posicao esperada (encontramos um registro com maior valor)... Assim nao serah preciso ir ateh o fim do arquivo... Diferentemente do arquivo heap desordenado. A pesquisa binária poderia ser usada neste caso, se os blocos estivessem ordenados de 1 a b (número de blocos) e fosse possível, através de um cabeçalho do arquivo, ter a sua localização física. A pesquisa binária é mais eficiente pois reduz de b/2 para log2 b o tempo médio de acesso a um registro em particular
 Processamento eficiente qdo é preciso recuperar os registros na classificação escolhida. Mesmo que não sejam todos, pois os registros próximos deverão estar em um mesmo bloco. Mas de nada adianta para buscas sobre campos não ordenados. Pesquisa binária X Pesquisa linear. Pesquisa binária torna eficiente operações com restrições sobre o campo de classificação. Complexidade da pesquisa binária: log2n. Complexidade da pesquisa linear: n/2. Para buscar um registro por uma restricao do campo-classificacao nao ha vantagem grande, pois a busca acaba sendo linear. Mas eh possivel parar ao verificar que o registro nao se encontra na posicao esperada (encontramos um registro com maior valor)... Assim nao serah preciso ir ateh o fim do arquivo... Diferentemente do arquivo heap desordenado. A pesquisa binária poderia ser usada neste caso, se os blocos estivessem ordenados de 1 a b (número de blocos) e fosse possível, através de um cabeçalho do arquivo, ter a sua localização física. A pesquisa binária é mais eficiente pois reduz de b/2 para log2 b o tempo médio de acesso a um registro em particular.")
34
Arquivos de Registros Ordenados (Sorted Files)
Exemplo:

35
Arquivos de Registros Ordenados (Sorted Files)
Operações de inclusão e exclusão são caras Os registros precisam ser mantidos em ordem Inserção: é preciso “abrir” espaço para o registro de acordo com o valor do campo-classificação Exclusão: pode-se usar marcadores e reorganizações periódicas Alteração: no campo-classificação implica na exclusão e re-inserção do registro (o registro muda fisicamente de lugar) Técnicas comuns Manter espaços não utilizados em cada bloco Utilizar arquivos de overflow temporários (desordenados) Inclusão fica eficiente, mas a busca perde Ambas associadas a reorganizações periódicas Manter espaços não utilizados... O problema ressurge qdo o espaço é tomado... É preciso fazer reorganizações periódicas A busca no caso de arquivos de overflow fica mais complexa pois ao nao encontrar via busca binária no arquivo mestre, parte-se para a busca linear no arquivo de overflow
 Técnicas comuns. Manter espaços não utilizados em cada bloco. Utilizar arquivos de overflow temporários (desordenados) Inclusão fica eficiente, mas a busca perde. Ambas associadas a reorganizações periódicas. Manter espaços não utilizados... O problema ressurge qdo o espaço é tomado... É preciso fazer reorganizações periódicas. A busca no caso de arquivos de overflow fica mais complexa pois ao nao encontrar via busca binária no arquivo mestre, parte-se para a busca linear no arquivo de overflow.")
36
Arquivos de Acesso Direto (Hash Files – Arquivos Diretos)
Organização primária de arquivo baseada em técnicas de hashing. Fornece acesso rápido aos registros quando consultas envolvem condições de igualdade em um único campo (campo de hash). Chave de hash: campo-chave é campo de hash Idéia do hashing: utilizar função h que, aplicada ao campo de hash de um registro, gere o endereço do bloco de disco onde o registro está armazenado. A busca do registro dentro do bloco pode ser realizada em memória principal.
. Chave de hash: campo-chave é campo de hash. Idéia do hashing: utilizar função h que, aplicada ao campo de hash de um registro, gere o endereço do bloco de disco onde o registro está armazenado. A busca do registro dentro do bloco pode ser realizada em memória principal.")
37
Arquivos de Acesso Direto (Hash Files – Arquivos Diretos)
Uma função de hashing é definida sobre algum atributo para “particionar” os dados. Ex: Recuperar sempre os empregados por departamento O resultado da função indica o bucket (depósito) do registro. Bucket equivale ao bloco de disco – unidade de armazenamento de um ou mais registros – ou um cluster de blocos consecutivos. Eficiente para operações com restrições de igualdade sobre o atributo da função. Sem vantagem para operações com restrição diferente de igualdade. Também usado para acesso direto na memória Exemplo do Empregado: Recuperar sempre os empregados por departamento.
 do registro. Bucket equivale ao bloco de disco – unidade de armazenamento de um ou mais registros – ou um cluster de blocos consecutivos. Eficiente para operações com restrições de igualdade sobre o atributo da função. Sem vantagem para operações com restrição diferente de igualdade. Também usado para acesso direto na memória. Exemplo do Empregado: Recuperar sempre os empregados por departamento.")
38
Função Hash H(K) = E “H” é uma função, “K” é o valor de um atributo e “E” é a identificação do depósito do registro. “E” assume valores entre 0 e M-1, sendo M a qtde de depósitos Uma tabela é mantida no cabeçalho do arquivo para converter o numero do bucket para o endereço do bloco de disco correspondente

39
(ex: os três últimos dígitos do CPF
Técnicas de “Hashing” Hashing : Randomização, Aleatorização h(C) função de hashing Geralmente o numero de valores que uma fc hash pode assumir é geralmente muito maior que o espaco de enderecos. Assume-se que vai haver colisão, pois os registros com mesmo valor de atributo vao ficar armazenados no mesmo bucket… Em uma consulta, todo bucket vai para a memoria e o acesso a um registro mais especifico é feito sequencialmente em memoria. Uma boa fç de hash deve prever uma distribuição uniforme. espaço dos endereços espaço dos valores (ex: os três últimos dígitos do CPF 1.000 posições) (ex: CPF possíveis valores)
 função de hashing. Geralmente o numero de valores que uma fc hash pode assumir é geralmente muito maior que o espaco de enderecos. Assume-se que vai haver colisão, pois os registros com mesmo valor de atributo vao ficar armazenados no mesmo bucket… Em uma consulta, todo bucket vai para a memoria e o acesso a um registro mais especifico é feito sequencialmente em memoria. Uma boa fç de hash deve prever uma distribuição uniforme. espaço dos endereços. espaço dos valores. (ex: os três últimos dígitos do CPF posições) (ex: CPF possíveis valores)")
40
Funções de Hashing Característica desejável: distribuição uniforme, isto é, uma chave qualquer C tem igual chance de “apontar diretamente” para qualquer posição. Algumas funções usuais: mod (mais usada em geral): h(k)=K mod M [V. Lum, P. Yuen, M. Dodd. Key to Address Transform Techniques: a Fundamental Performance Study on Large Existing Formatted Files, Communications of the ACM, 14(4), April 1971]
: h(k)=K mod M. [V. Lum, P. Yuen, M. Dodd. Key to Address Transform Techniques: a Fundamental Performance Study on Large Existing Formatted Files, Communications of the ACM, 14(4), April 1971]")
41
Funções de Hashing ... Exemplo: h(CPF) = CPF mod 1000 CPF Nome
Profissão Salário 000 001 999 ... h(CPF) = CPF mod 1000 E se quisessemos manter a ordem… supondo em ordem de cpf… Algumas fcs de hash preservam a ordem, como eh o caso de usarmos os digitos mais significativos de um numero, mas ainda neste caso dentro do bucket os registros estariam desordenados.
 = CPF mod E se quisessemos manter a ordem… supondo em ordem de cpf… Algumas fcs de hash preservam a ordem, como eh o caso de usarmos os digitos mais significativos de um numero, mas ainda neste caso dentro do bucket os registros estariam desordenados.")
42
Colisões Colisão: Tratamento de Colisão:
Ocorre quando o valor do campo de hash de um registro que está sendo incluído levar a um endereço hash que já contiver um registro diferente. Tratamento de Colisão: Incluir o novo registro em alguma outra posição, uma vez que o endereço hash está ocupado. O processo para encontrar outra posição é chamado resolução ou tratamento de colisão. O encadeamento eh o mais simples, pois para alocacao de espaco e remocao sempre se comporta de forma igual… Mas como recuperar ou excluir via enderamento aberto? Teria que se verificar linearmente em uma vizinhanca provavel onde estariam possiveis registros que colidiram… Hashing multiplo parece ser melhor, mas como prever qtas fcs de hash vou usar?

43
Tratamento de Colisões – Hashing Estático (No. Fixo de Buckets)
Endereçamento aberto ou linear A partir da posição de colisão, procurar uma posição subseqüente vaga. Encadeamento Manter uma lista encadeada de registros de overflow para cada posição no espaço de endereços. Hashing múltiplo: Aplicar uma segunda função de hashing quando ocorrer uma colisão. Se ocorrer nova colisão, aplicar endereçamento aberto ou nova função de hashing. O encadeamento eh o mais simples, pois para alocacao de espaco e remocao sempre se comporta de forma igual… Mas como recuperar ou excluir via enderamento aberto? Teria que se verificar linearmente em uma vizinhanca provavel onde estariam possiveis registros que colidiram… Hashing multiplo parece ser melhor, mas como prever qtas fcs de hash vou usar?

44
Hashing Estático: Encadeamento utilizando Buckets de Overflow
buckets principais bucket 0 340 460 buckets de overflow ponteiro 981 182 ponteiro ponteiro ponteiro bucket 1 321 761 91 ponteiro . bucket 2 Os ponteiros da lista encadeada devem ser ponteiros para registros, isto eh, incluem tanto o endereco do bloco qto a posicao relativa do registro no bloco. 22 72 522 652 ponteiro ponteiro ponteiro ponteiro . Os ponteiros são para registros dentro dos buckets de overflow bucket 9 399 89 ponteiro

45
Tratamento de Colisões – Hashing Estático (No. Fixo de Buckets)
Cada método de resolução de colisão requer seus próprios algoritmos para inclusão, recuperação e exclusão de registros. Objetivo de uma boa função hash: Minimizar colisões e não deixar endereços sem uso Estudos de simulação e análise recomendam manter entre 70% e 90% de uma tabela hash cheia. Sendo um arquivo com r registros, deve-se escolher M localizações para o espaço de endereços de modo que r/M esteja entre 0,7 e 0,9. Escolher número primo para M para a função hash mod O encadeamento eh o mais simples, pois para alocacao de espaco e remocao sempre se comporta de forma igual… Mas como recuperar ou excluir via enderamento aberto? Teria que se verificar linearmente em uma vizinhanca provavel onde estariam possiveis registros que colidiram… Hashing multiplo parece ser melhor, mas como prever qtas fcs de hash vou usar?

46
Tabela Hash – Inserção (1)
Ex: Supondo que temos um esquema de tratamento de colisão por encadeamento, um total de 4 depósitos e que cada bloco pode conter apenas 2 registros h(a) = 3 h(b) = 2 h(c) = 1 h(d) = 0 h(e) = 1 h(f) = 3 1 2 3 a
 = 3. h(b) = 2. h(c) = 1. h(d) = 0. h(e) = 1. h(f) = a.")
47
Tabela Hash – Inserção (1)
Ex: Supondo que temos um esquema de tratamento de colisão por encadeamento, um total de 4 depósitos e que cada bloco pode conter apenas 2 registros h(a) = 3 h(b) = 2 h(c) = 1 h(d) = 0 h(e) = 1 h(f) = 3 1 2 b 3 a
 = 3. h(b) = 2. h(c) = 1. h(d) = 0. h(e) = 1. h(f) = b. 3. a.")
48
Tabela Hash – Inserção (1)
Ex: Supondo que temos um esquema de tratamento de colisão por encadeamento, um total de 4 depósitos e que cada bloco pode conter apenas 2 registros h(a) = 3 h(b) = 2 h(c) = 1 h(d) = 0 h(e) = 1 h(f) = 3 1 c 2 b 3 a
 = 3. h(b) = 2. h(c) = 1. h(d) = 0. h(e) = 1. h(f) = c. 2. b. 3. a.")
49
Tabela Hash – Inserção (1)
Ex: Supondo que temos um esquema de tratamento de colisão por encadeamento, um total de 4 depósitos e que cada bloco pode conter apenas 2 registros h(a) = 3 h(b) = 2 h(c) = 1 h(d) = 0 h(e) = 1 h(f) = 3 d 1 c 2 b 3 a
 = 3. h(b) = 2. h(c) = 1. h(d) = 0. h(e) = 1. h(f) = 3. d. 1. c. 2. b. 3. a.")
50
Tabela Hash – Inserção (1)
Ex: Supondo que temos um esquema de tratamento de colisão por encadeamento, um total de 4 depósitos e que cada bloco pode conter apenas 2 registros h(a) = 3 h(b) = 2 h(c) = 1 h(d) = 0 h(e) = 1 h(f) = 3 d 1 c e 2 b 3 a
 = 3. h(b) = 2. h(c) = 1. h(d) = 0. h(e) = 1. h(f) = 3. d. 1. c. e. 2. b. 3. a.")
51
Tabela Hash – Inserção (1)
Ex: Supondo que temos um esquema de tratamento de colisão por encadeamento, um total de 4 depósitos e que cada bloco pode conter apenas 2 registros h(a) = 3 h(b) = 2 h(c) = 1 h(d) = 0 h(e) = 1 h(f) = 3 d 1 c e 2 b 3 a f
 = 3. h(b) = 2. h(c) = 1. h(d) = 0. h(e) = 1. h(f) = 3. d. 1. c. e. 2. b. 3. a. f.")
52
Tabela Hash – Inserção (2)
Considerando o exemplo anterior, seja h(g) = 1 d 1 c e g 2 b 3 a f O depósito 1 passa a conter 2 blocos
 = 1. d. 1. c. e. g. 2. b. 3. a. f. O depósito 1 passa a. conter 2 blocos.")
53
Tabela Hash – Remoção (1)
Suponha que vamos remover o registro de chave “e”. Como h(e) = 1, vamos percorrer a cadeia de blocos deste depósito até encontrarmos o(s) registro(s) d 1 c e g 2 b 3 a f O depósito 1 pode ser reorganizado para voltar a ter somente um bloco
 = 1, vamos percorrer a cadeia de blocos deste depósito até encontrarmos o(s) registro(s) d. 1. c. e. g. 2. b. 3. a. f. O depósito 1 pode ser reorganizado para voltar a ter somente um bloco.")
54
Tabela Hash - Remoção (2)
Ao remover o registro de chave “a”, “consolidamos” o depósito 3, trazendo o registro “f” para a primeira posição d d c g 1 b 2 f 3 1 c g 2 b 3 a f

55
Eficiência de tabelas Hash
Ideal: um depósito possa conter somente 1 bloco Avaliar: número de depósitos (M) tamanho do bloco (m registros por depósito) número de registros e a taxa de crescimento (m*M) Poucos Registros Sobra espaço Muitos registros Pode ultrapassar tamanho previsto Então como evitar problemas de crescimento? Tabelas hash dinâmicas: Hash Extensível Hash Linear O número de buckets é fixo. Por isto este tipo de hash é chamado de estático. Alocação de espaço: m*M. Quando há poucos registros, sobra espaço. Quando há muitos, pode ultrapassar o tamanho previsto...
 tamanho do bloco (m registros por depósito) número de registros e a taxa de crescimento (m*M) Poucos Registros Sobra espaço. Muitos registros Pode ultrapassar tamanho previsto. Então como evitar problemas de crescimento Tabelas hash dinâmicas: Hash Extensível. Hash Linear. O número de buckets é fixo. Por isto este tipo de hash é chamado de estático. Alocação de espaço: m*M. Quando há poucos registros, sobra espaço. Quando há muitos, pode ultrapassar o tamanho previsto...")
56
Hash Extensível h(chave) gera uma seqüência binária de k bits
Os i primeiros bits de h(chave) são utilizados para selecionar o depósito em que um dado registro será colocado. Um array (tabela Hash) de 2i ponteiros para depósitos é mantido. i = 1 0001 1 1 1001 1100 1
 são utilizados para selecionar o depósito em que um dado registro será colocado. Um array (tabela Hash) de 2i ponteiros para depósitos é mantido. i =")
57
Hash Extensível i cresce à medida em que novos registros são inseridos, não sendo necessário utilizar depósitos de estouro (overflow). Cada depósito possui um número de bits de pertinência (j), que indica quantos bits foram examinados para direcionar os registros presentes no bloco. j também cresce com a inserção de registros. 1 0001 1001 1100 i = 1 00 01 10 11 0001 1001 1010 1 2 i = 2 1100
, que indica quantos bits foram examinados para direcionar os registros presentes no bloco. j também cresce com a inserção de registros i = i =")
58
i = 1 Inserção em hash extensível caso 1
1 array de depósitos (ponteiros p/ blocos) Inserção em hash extensível caso 1 : Duplicação do array e redistribuição de registros i = 1 j - bits de pertinência do bloco h(chave) inicia com 0 h(chave) inicia com 1 h(chave) B A inserir registro com h(chave) = bloco B está cheio e j = i : o conteúdo de B tem que ser redistribuído e array tem que ser duplicado
 Inserção em hash extensível. caso 1. : Duplicação do array e redistribuição de registros. i = 1. j - bits de pertinência do bloco. h(chave) inicia com 0. h(chave) inicia com 1. h(chave) B. A. inserir registro com. h(chave) = bloco B está cheio e j = i. : o conteúdo de B tem que ser redistribuído e. array tem que ser duplicado.")
59
i = 2 A h(chave) inicia com 00 h(chave) inicia com 01 B
1 A h(chave) inicia com 10 h(chave) inicia com 11 2 B' B o array foi duplicado - i foi incrementado Como seu conteúdo não foi redistribuído, o j do depósito A não foi incrementado e A passou a ser apontado por duas entradas na tabela hash j foi incrementado e o conteúdo de B foi redistribuído entre B e B' de acordo com o valor dos j primeiros bits de h(chave)
 inicia com 10. h(chave) inicia com B B. o array foi. duplicado - i foi incrementado. Como seu conteúdo não foi. redistribuído, o j do depósito A não foi. incrementado e A passou a ser. apontado por duas entradas na tabela hash. j foi incrementado e o conteúdo de B foi. redistribuído entre B e B de acordo com o. valor dos j primeiros bits de h(chave)")
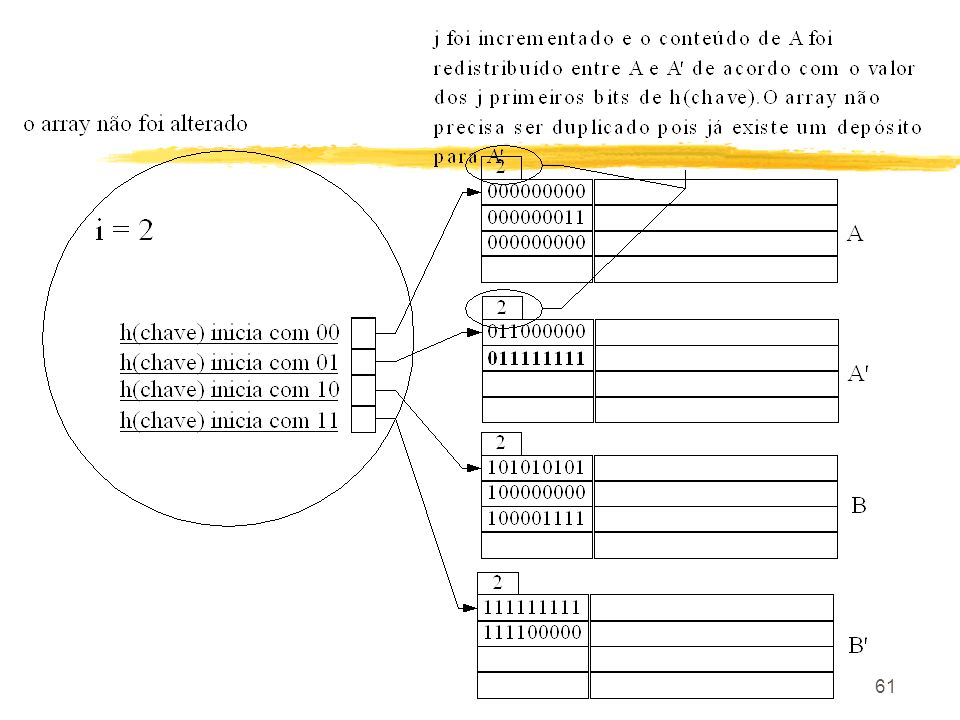
60
i = 2 caso 2 : Apenas redistribuição de registros
h(chave) inicia com 00 h(chave) inicia com 01 1 A h(chave) inicia com 10 h(chave) inicia com 11 2 B' B Inserção em hash extensível inserir registro com h(chave) = bloco A está cheio e j < i : o conteúdo de A tem que ser redistribuído mas o array não precisa ser duplicado
 inicia com 00. h(chave) inicia com A. h(chave) inicia com 10. h(chave) inicia com B B. Inserção em hash extensível. inserir registro com. h(chave) = bloco A está cheio e j < i. : o conteúdo de A tem que ser redistribuído. mas o array não precisa ser duplicado.")
62
(Des)Vantagens do Hash Extensível
A busca nunca precisa fazer acesso a mais de um depósito de dados Se o array de depósitos couber na memória, o acesso a ele não requer operação E/S Quando o array de depósitos é muito grande (i grande) o momento da duplicação pode tornar uma inserção bastante custosa em especial quando não couber mais na memória ou ainda, quando ocupar memória demais, impedindo o uso desta por outros programas e dados
 o momento da duplicação pode tornar uma inserção bastante custosa. em especial quando não couber mais na memória. ou ainda, quando ocupar memória demais, impedindo o uso desta por outros programas e dados.")
63
Exercício: Suponha a seguinte sequência de inserções:
Qual será o i ao final das inserções? Quantos blocos estarão com somente um registro? Qual o bloco mais apontado pelo array de depósitos? É possível que haja um depósito que precise ser dividido muitas vezes, desequilibrando a distribuição da tabela de Hash.

64
(Des)Vantagens do Hash Extensível
Conclusão Desperdício de memória i cresce muito rápido mantendo várias entradas apontando para um único depósito Depósitos descaracterizados Desperdício de disco Alocação de depósitos com um único registro

65
Hash Linear O crescimento do array de depósitos é mais lento.
Um array de n depósitos é mantido: n é dado conforme a taxa de preenchimento médio de registros nos depósitos Os i últimos bits de h(chave) são utilizados para selecionar o depósito em que um dado registro será colocado. i = 2 n = 3 r = 3 00 0000 01 0101 10 1010
 são utilizados para selecionar o depósito em que um dado registro será colocado. i = 2. n = 3. r =")
66
Hash Linear Seja m o valor expresso pelos i últimos bits de h(chave). Se m < n, o registro é colocado no bloco correspondente ao depósito numerado como m. Caso contrário, é utilizado o depósito numerado como m-2i-1 (m com o primeiro bit mudado de 1 para 0). Veja o que acontece quando vamos inserir o registro cuja chave gera a sequência 1111: 00 0000 i = 2 n = 3 r = 3 01 0101 10 1010
. Se m < n, o registro é colocado no bloco correspondente ao depósito numerado como m. Caso contrário, é utilizado o depósito numerado como m-2i-1 (m com o primeiro bit mudado de 1 para 0). Veja o que acontece quando vamos inserir o registro cuja chave gera a sequência 1111: i = 2. n = 3. r =")
67
Hash Linear Seja m o valor expresso pelos i últimos bits de h(chave). Se m < n, o registro é colocado no bloco correspondente ao depósito numerado como m. Caso contrário, é utilizado o depósito numerado como m-2i-1 (m com o primeiro bit mudado de 1 para 0). Veja o que acontece quando vamos inserir o registro cuja chave gera a sequência 1111: 00 0000 i = 2 n = 3 r = 4 01 0101 1111 10 1010
. Se m < n, o registro é colocado no bloco correspondente ao depósito numerado como m. Caso contrário, é utilizado o depósito numerado como m-2i-1 (m com o primeiro bit mudado de 1 para 0). Veja o que acontece quando vamos inserir o registro cuja chave gera a sequência 1111: i = 2. n = 3. r =")
68
Hash Linear Seja r o número de registros na tabela. Considere r/n < 1.7 n cresce à medida em que novos registros são inseridos de forma a manter a razão r/n abaixo de um limiar pré-determinado. i cresce quando n ultrapassa 2i. Quando os parâmetros crescem pode haver redistribuição de registros entre blocos. Sempre após inserirmos, verificamos a razão r/n Ex: inserir 0101, como r/n > 1.7, após a inserção, n já pode crescer, i = 1 n = 2 r = 4 i = 1 n = 2 r = 3 0000 1010 0000 1010 1 1111 1 1111 0101

69
Hash Linear Seja r o número de registros na tabela. Considere r/n < 1.7 n cresce à medida em que novos registros são inseridos de forma a manter a razão r/n abaixo de um limiar pré-determinado. i cresce quando n ultrapassa 2i. Quando os parâmetros crescem pode haver redistribuição de registros entre blocos. Sempre após inserimos verificamos a razão r/n Ex: inserir 0101, como r/n > 1.7, após a inserção, n já pode crescer, i cresce, o depósito, que corresp. ao novo, com dif do 1o bit é redistribuído (00) 00 0000 i = 2 n = 3 r = 4 i = 1 n = 2 r = 4 0000 1010 01 1111 0101 1 1111 0101 10 1010
 i = 2. n = 3. r = 4. i = 1. n = 2. r =")
70
Hash Linear Depósitos de estouro podem ser utilizados. 00 i = 2 n = 3
Inserir 0001 Cria-se um depósito de estouro para o depósito 01 razão r/n permanece < 1.7, então não precisa aumentar n E se inserirmos 0111? 00 0000 i = 2 n = 3 r = 4 01 1111 0101 10 1010 00 0000 i = 2 n = 3 r = 5 01 1111 0101 0001 10 1010

71
Hash Linear 00 i = 2 n = 3 01 r = 6 10 00 01 i = 2 n = 4 r = 6 10 11
E se inserirmos 0111? A razão ultrapassa 1.7, então devemos aumentar n 0000 00 1111 0101 01 1010 10 i = 2 n = 3 r = 6 0001 0111 0000 00 0101 0001 01 1010 10 i = 2 n = 4 r = 6 1111 0111 11

72
Hash Linear Que cuidado é preciso tomar quando vamos buscar um dado registro? Considere a situação abaixo na busca pelo registro cuja chave gera a seqüência 1011 0000 00 1111 0101 01 1010 10 i = 2 n = 3 r = 5 0001 Não há o depósito 11, logo, realiza a busca no depósito 01.

73
Hash Linear - Inserção n = 2 i = 1 r = 5 r/n < 3
array de h(chave) depósitos n = 2 i = 1 r = 5 h(chave) termina com 0 h(chave) termina com 1 inserir registro com h(chave) = r/n ultrapassará o limiar : n tem que ser incrementado. n ultrapassará 2 i e i terá que ser incrementado também
 depósitos. n = 2. i = r = 5. h(chave) termina com 0. h(chave) termina com 1. inserir registro com h(chave) = r/n ultrapassará o limiar. : n. tem que ser incrementado. n. ultrapassará. 2. i. e i terá que ser incrementado também.")
74
Hash Linear - Inserção

75
Sumário Introdução e Motivação Memórias Alocação de Registros
Operações em Arquivos Organização de Arquivos em Disco Armazenamento em Dicionário de Dados Exercícios

76
Armazenamento em Dicionário de Dados
SGBDR precisa manter dados sobre as relações (Catálogo do Sistema). Exemplos: Nomes das relações Nomes dos atributos de cada relação Domínios e tamanhos dos atributos Nomes e definições das visões Restrições de integridade Nomes de usuários autorizados Número de tuplas em cada relação Método de armazenamento para cada relação
. Exemplos: Nomes das relações. Nomes dos atributos de cada relação. Domínios e tamanhos dos atributos. Nomes e definições das visões. Restrições de integridade. Nomes de usuários autorizados. Número de tuplas em cada relação. Método de armazenamento para cada relação.")
77
Armazenamento em Dicionário de Dados
Exemplo de esquema sobre metadados: Relação(nome-relação, numero_atbs, organização_armazenamento, local) Atributo(nome-atributo, nome-relação, tipo_domínio, posição, tamanho) Usuário(nome_usuário, senha_criptografada, grupo) Índice(nome_indice, nome_relação, tipo_indice, atbs_indice) Visão(nome_visão, definição)
 Atributo(nome-atributo, nome-relação, tipo_domínio, posição, tamanho) Usuário(nome_usuário, senha_criptografada, grupo) Índice(nome_indice, nome_relação, tipo_indice, atbs_indice) Visão(nome_visão, definição)")
78
Sumário Introdução e Motivação Memórias Alocação de Registros
Operações em Arquivos Organização de Arquivos em Disco Armazenamento em Dicionário de Dados Exercícios

79
Exercício 1: Considerando os depósitos da figura, mostre como ficará a situação após: g a j forem inseridos nos depósitos 0 a 3, resp. a e b forem eliminados k a n forem inseridos nos depósitos 0 a 3, resp. c e d forem eliminados d 1 c e 2 b 3 a f

80
Exercício 2: Considere a tabela de hash abaixo.
O que acontece com a inclusão de g, dado que h(g) = 3? d 1 c e 2 b 3 a f
 = 3 d. 1. c. e. 2. b. 3. a. f.")
81
Armazenamento e Organização de Arquivos
Leituras Recomendadas Cap. 13 – Elmasri e Navathe Cap. 11 – Silberschatz e Korth Atividades Práticas Lista de Exercícios em Anexo

Apresentações semelhantes


 Túlio Toffolo www. decom. ufop>")





. Nenhuns direitos reservados, excepto para fins comerciais. Por favor, não coloque.>")










