Carregar apresentação
A apresentação está carregando. Por favor, espere

1
Curso: Tecnologia em Análise e Desenvolvimento de Sistemas
3º e 4º períodos Disciplina: ESTRUTURA DE DADOS Prof.: Mário Sérgio Sabbag Cunha 2015/ 2 1 Prof. Guedes 1

2
Apresentação da Disciplina

3
Carga Horária Total: 100 horas
Aulas: toda QUINTA Horário: 19:10 às 22:00 hs.

4
Ementa: Introdução à estrutura de dados
Alocação estática de memória (Revisão) Alocação dinâmica de memória Listas Pilhas Filas Algoritmos recursivos Árvores e Grafos
 Alocação dinâmica de memória. Listas. Pilhas. Filas. Algoritmos recursivos. Árvores e Grafos.")
5
Bibliografia Básica Padrão:
1) PIVA JUNIOR, Dilermando (org.). Estrutura de Dados e Técnicas de Programação. 1ª ed. São Paulo: Elsevier, 2014.
 PIVA JUNIOR, Dilermando (org.). Estrutura de Dados e Técnicas de Programação. 1ª ed. São Paulo: Elsevier,")
6
Bibliografia Básica (Anápolis):
1) VELOSO, Paulo A.S.. Estruturas de Dados. 1ª ed. Rio de Janeiro: Campus - Elsevier, 1996. 2) CELES, Waldemar. Introdução a Estruturas de dados com técnicas de programação em C. 1ª ed. Rio de Janeiro: Campus Elsevier, 2004.
 VELOSO, Paulo A.S.. Estruturas de Dados. 1ª ed. Rio de Janeiro: Campus - Elsevier, ) CELES, Waldemar. Introdução a Estruturas de dados com técnicas de programação em C. 1ª ed. Rio de Janeiro: Campus Elsevier,")
7
Sistema de Avaliação 1° AVALIAÇÃO - PESO 4,0 Prova = 9,0 ATPS = 1,0

8
Introdução

9
“Um programa é uma combinação de algoritmos e de estruturas de dados.”

10
Quando projetamos um programa, devemos pensar tanto nos algoritmos que manipulam os dados como também na forma de estruturar estes dados. O conhecimento e domínio das estruturas de dados e suas representações físicas são importantes para selecionar, de acordo com a aplicação, qual a forma mais eficiente de representar os dados.”

11
Structs

12
Uma estrutura (struct) é um grupo de itens no qual cada item é identificado por um identificador próprio, sendo cada um deles conhecido como um membro da estrutura. Em Algoritmos uma estrutura é chamada “Registro” e um membro é chamado “Campo”. As duas declarações abaixo alcançam o mesmo resultado. A segunda declaração é mais usada para se obter o máximo de clareza no programa. struct teste { char primeiro[10]; char meio; char ultimo[20]; }; struct teste snome, enome; struct { char primeiro[10]; char meio; char ultimo[20]; } snome, enome;

13
Revisão de Ponteiros

14
Um ponteiro é uma variável que contém um endereço de memória e não o conteúdo da posição.

15
Ponteiros são usados em situações em que é necessário conhecer o endereço onde está armazenada a variável e não o seu conteúdo. A memória de um computador pode ser vista como uma seqüência de bytes cada um com seu próprio endereço. Não há dois bytes com o mesmo endereço. O primeiro endereço é sempre 0 e o último geralmente é uma potência de 2. Por exemplo um computador com memória igual a 512 Mbytes tem 512x1024x1024 bytes.

16
Ponteiros são importantes por exemplo quando se deseja que uma função retorne mais de um valor.
Por exemplo, uma função pode receber não os valores dos parâmetros mas sim ponteiros que apontem para seus endereços. Assim esta função pode modificar diretamente os conteúdos destas variáveis.

17
Uma outra aplicação importante de ponteiros é apontar para áreas de memória que são administradas durante a execução do programa. Com ponteiros é possível alocar as posições de memória necessárias para armazenamento de vetores somente quando o programa estiver rodando. O programador pode reservar o número exato de posições que o programa requer.

18
Declaração de Ponteiros

19
A forma geral da declaração de um ponteiro é a seguinte:
Os ponteiros, assim como as variáveis, precisam ser declarados antes de serem usados. A forma geral da declaração de um ponteiro é a seguinte: tipo *nome; Onde tipo é qualquer tipo válido em C e nome é o nome da variável ponteiro. Por exemplo: int *res; /* ponteiro para uma variável inteira */ float *div; /* ponteiro para uma variável de ponto flutuante (real) */
 */")
20
Operações com Ponteiros

21
Existem dois operadores especiais para ponteiros: * e &.
O operador & devolve o endereço de memória do seu operando. Por exemplo: pint = &soma; /* o endereço de soma é carregado em pint */ No exemplo seguinte considere a Tabela abaixo. Após a execução do trecho de programa abaixo a variável ponteiro p termina com o valor 0xABA0. p = # Endereços Conteúdo Variável 0xABA0 10 num 0xABA1 120 res

22
significa que a variável num recebe o valor apontado por p.
O operador * é o complemento de &. O operador * devolve o valor da variável localizada no endereço que o segue. Por exemplo, o comando: num = *p; significa que a variável num recebe o valor apontado por p. Estes operadores não devem ser confundidos com os já estudados em capítulos anteriores. O operador * para ponteiros não tem nada a ver com o operador multiplicação.

23
Atribuição de Ponteiros

24
Do mesmo modo que uma variável comum, o conteúdo de um ponteiro pode ser passado para outro ponteiro do mesmo tipo. As variáveis ponteiro devem sempre apontar para os tipos de dados corretos. Uma variável ponteiro declarada como apontador de dados inteiros deve sempre apontar para dados deste tipo. Observar que em C é possível atribuir qualquer endereço a uma variável ponteiro. Deste modo é possível atribuir o endereço de uma variável do tipo float a um ponteiro inteiro. No entanto, o programa não irá funcionar da maneira correta.

25
void main() { int vetor[]={10,20,30,40,50}; int *p1, *p2; int i = 100; p1 = &vetor[2]; printf("%d\n", *p1); p2 = &i; printf("%d\n", *p2); p2 = p1; getch(); }
![void main() { int vetor[]={10,20,30,40,50}; int *p1, *p2; int i = 100; p1 = &vetor[2]; printf( %d\n , *p1);](http://slideplayer.com.br/slide/9279866/27/images/25/void+main%28%29+%7B+int+vetor%5B%5D%3D%7B10%2C20%2C30%2C40%2C50%7D%3B+int+%2Ap1%2C+%2Ap2%3B+int+i+%3D+100%3B+p1+%3D+%26vetor%5B2%5D%3B+printf%28+%25d%5Cn+%2C+%2Ap1%29%3B.jpg "p2 = &i; printf( %d\n , *p2); p2 = p1; getch(); }")
26
No trecho de programa acima, o endereço do terceiro elemento do vetor v é carregado em p1 e o endereço da variável i é carregado em p2. Além disso, no final, o endereço apontado por p1 é carregado em p2. Os comandos printf imprimem os valores apontados pelos ponteiros respectivos.

27
Acessando os endereços

28
O trecho de programa abaixo faz com que o endereço da variável x seja carregado no ponteiro p. Em seguida o programa imprime o que está apontado por p. void main() { float x=3.14; float *p; p = &x; printf("*p = %f", *p); getch(); }
 { float x=3.14; float *p; p = &x; printf( *p = %f , *p); getch(); }")
29
Incrementando e decrementando Ponteiros

30
O primeiro printf imprime 30, o segundo 40 e o terceiro 50.
O exemplo abaixo mostra que operações de incremento e decremento podem ser aplicadas em operandos. O primeiro printf imprime 30, o segundo 40 e o terceiro 50. void main() { int vetor[ ] = { 10, 20, 30, 40, 50 }; int *p1; p1 = &vetor[2]; printf("%d\n", *p1); p1++; p1 = p1 + 1; getch(); }
 { int vetor[ ] = { 10, 20, 30, 40, 50 }; int *p1; p1 = &vetor[2]; printf( %d\n , *p1); p1++; p1 = p1 + 1; getch(); }")
31
É possível usar o seguinte comando: *(p+1)=10;
Pode parecer estranho que um endereço que aponte para um número inteiro que é armazenado em dois bytes seja incrementado por um e passe para apontar para o próximo número inteiro. A resposta para isto é que sempre que um ponteiro é incrementado (decrementado) ele passa a apontar para a posição do elemento seguinte (anterior). Do mesmo modo somar três a um ponteiro faz com que ele passe apontar para o terceiro elemento após o atual. Portanto, um incremento em um ponteiro que aponta para um valor que é armazenado em n bytes faz que n seja somado ao endereço. É possível usar o seguinte comando: *(p+1)=10; Este comando armazena o valor 10 na posição seguinte àquela apontada por p. É possível somar-se e subtrair-se inteiros de ponteiros. A operação abaixo faz com que o ponteiro p passe a apontar para o terceiro elemento após o atual. p = p + 3;
 ele passa a apontar para a posição do elemento seguinte (anterior). Do mesmo modo somar três a um ponteiro faz com que ele passe apontar para o terceiro elemento após o atual. Portanto, um incremento em um ponteiro que aponta para um valor que é armazenado em n bytes faz que n seja somado ao endereço. É possível usar o seguinte comando: *(p+1)=10; Este comando armazena o valor 10 na posição seguinte àquela apontada por p. É possível somar-se e subtrair-se inteiros de ponteiros. A operação abaixo faz com que o ponteiro p passe a apontar para o terceiro elemento após o atual. p = p + 3;")
32
Exercício

33
Quais os valores impressos pelos printf do programa abaixo?
void main() { int v[]={10,20,30,40,50,60,70,80}; int *p1, *p2; p1 = &v[2]; printf("%d\n", *p1++); p2 = p1+1; printf("%d\n", *++p2); *(p1+2) = 10; printf("%d\n", *p2 – –); getch(); }
 { int v[]={10,20,30,40,50,60,70,80}; int *p1, *p2; p1 = &v[2]; printf( %d\n , *p1++); p2 = p1+1; printf( %d\n , *++p2); *(p1+2) = 10; printf( %d\n , *p2 – –); getch(); }")
34
Alocação Estática de Memória

35
A alocação estática de memória acontece antes que o programa comece a ser executado.

36
Vetores e Endereços

37
Os elementos de qualquer vetor (= array) têm endereços consecutivos na memória do computador. [Os endereços não são exatamente consecutivos, pois cada elemento do vetor pode ocupar vários bytes. Mas o compilador C trata de acertar as coisas para criar a ilusão de que a diferença entre os endereços de elementos consecutivos vale 1.] Depois da declaração int v[100]; a variável v é, essencialmente, um ponteiro para o primeiro elemento do vetor. Mais precisamente, v é uma espécie de "ponteiro constante": você não pode mudar o valor de v.
![Os elementos de qualquer vetor (= array) têm endereços consecutivos na memória do computador. [Os endereços não são exatamente consecutivos, pois cada elemento do vetor pode ocupar vários bytes. Mas o compilador C trata de acertar as coisas para criar a ilusão de que a diferença entre os endereços de elementos consecutivos vale 1.] Depois da declaração](http://slideplayer.com.br/slide/9279866/27/images/37/Os+elementos+de+qualquer+vetor+%28%3D+array%29+t%C3%AAm+endere%C3%A7os+consecutivos+na+mem%C3%B3ria+do+computador.+%5BOs+endere%C3%A7os+n%C3%A3o+s%C3%A3o+exatamente+consecutivos%2C+pois+cada+elemento+do+vetor+pode+ocupar+v%C3%A1rios+bytes.+Mas+o+compilador+C+trata+de+acertar+as+coisas+para+criar+a+ilus%C3%A3o+de+que+a+diferen%C3%A7a+entre+os+endere%C3%A7os+de+elementos+consecutivos+vale+1.%5D+Depois+da+declara%C3%A7%C3%A3o.jpg "int v[100]; a variável v é, essencialmente, um ponteiro para o primeiro elemento do vetor. Mais precisamente, v é uma espécie de ponteiro constante : você não pode mudar o valor de v.")
38
Para "carregar" um vetor v[0..9] pode-se dizer:
Como v contém o endereço do primeiro elemento do vetor, a expressão v+1 é o endereço do segundo elemento, v+2 é o endereço do terceiro elemento, etc. Se i é uma variável do tipo int, então as expressões v + i e &v[i] têm exatamente o mesmo valor. Portanto, *(v+i) = 87; tem o mesmo efeito que v[i] = 87; Para "carregar" um vetor v[0..9] pode-se dizer: for (i=0;i<10;i++) scanf("%d", &v[i]); Ou for (i=0;i<10;i++) scanf("%d", v+i); As duas formas têm exatamente o mesmo efeito.
![Para carregar um vetor v[0..9] pode-se dizer:](http://slideplayer.com.br/slide/9279866/27/images/38/Para+carregar+um+vetor+v%5B0..9%5D+pode-se+dizer%3A.jpg "Como v contém o endereço do primeiro elemento do vetor, a expressão v+1 é o endereço do segundo elemento, v+2 é o endereço do terceiro elemento, etc. Se i é uma variável do tipo int, então as expressões v + i e &v[i] têm exatamente o mesmo valor. Portanto, *(v+i) = 87; tem o mesmo efeito que. v[i] = 87; Para carregar um vetor v[0..9] pode-se dizer: for (i=0;i<10;i++) scanf( %d , &v[i]); Ou. for (i=0;i<10;i++) scanf( %d , v+i); As duas formas têm exatamente o mesmo efeito.")
39
Alocação Dinâmica de Memória

40
As declarações abaixo alocam memória para diversas variáveis:
char c; int i; int v[10]; A alocação é estática, pois acontece antes que o programa comece a ser executado. Às vezes, a quantidade de memória a alocar só se torna conhecida durante a execução do programa. Para lidar com essa situação é preciso recorrer à alocação dinâmica de memória. A alocação dinâmica é gerenciada pelas funções malloc e free, que estão na biblioteca stdlib. Para usar esta biblioteca, é preciso dizer: #include <stdlib.h> no início do programa.

41
Função malloc

42
A função malloc (abreviatura de memory allocation) aloca um bloco de bytes consecutivos na memória do computador e devolve o endereço desse bloco. O número de bytes é especificado no argumento da função. No seguinte fragmento de código, malloc aloca 1 byte: char *ptr; ptr = malloc (1); scanf ("%c", ptr); O endereço devolvido por malloc é do tipo “genérico” void *. O programador armazena esse endereço num ponteiro de tipo apropriado. No exemplo acima, o endereço é armazenado num ponteiro-para-char.
; scanf ( %c , ptr); O endereço devolvido por malloc é do tipo genérico void *. O programador armazena esse endereço num ponteiro de tipo apropriado. No exemplo acima, o endereço é armazenado num ponteiro-para-char.")
43
[As aparências enganam: sizeof não é uma função.]
Para alocar um tipo-de-dado que ocupa vários bytes, é preciso recorrer ao operador sizeof, que diz quantos bytes o tipo especificado tem: typedef struct { int dia, mes, ano; } data; data *d; d = malloc (sizeof (data)); d->dia = 31; d->mes = 12; d->ano = 2008; [As aparências enganam: sizeof não é uma função.]
![[As aparências enganam: sizeof não é uma função.]](http://slideplayer.com.br/slide/9279866/27/images/43/%5BAs+apar%C3%AAncias+enganam%3A+sizeof+n%C3%A3o+%C3%A9+uma+fun%C3%A7%C3%A3o.%5D.jpg "Para alocar um tipo-de-dado que ocupa vários bytes, é preciso recorrer ao operador sizeof, que diz quantos bytes o tipo especificado tem: typedef struct { int dia, mes, ano; } data; data *d; d = malloc (sizeof (data)); d->dia = 31; d->mes = 12; d->ano = 2008; [As aparências enganam: sizeof não é uma função.]")
44
Função free

45
A função free libera a porção de memória alocada por malloc
A função free libera a porção de memória alocada por malloc. O comando free (ptr) avisa o sistema de que o bloco de bytes apontado por ptr está livre. A próxima chamada de malloc poderá tomar posse desses bytes. A função free não deve ser aplicada a uma parte de um bloco de bytes alocado por malloc; aplique free apenas ao bloco todo. Convém não deixar ponteiros "soltos" (= dangling pointers) no seu programa, pois isso pode ser explorado por hackers para atacar o seu computador. Portanto, depois de cada free (ptr), atribua NULL a ptr: free (ptr); ptr = NULL; Atribuir um valor a um ponteiro que se tornou inútil é decididamente deselegante, mas não há como lidar com hackers de maneira elegante… Para não nos cansarmos com detalhes repetitivos, os nossos programas não vão seguir a recomendação de segurança acima.
 avisa o sistema de que o bloco de bytes apontado por ptr está livre. A próxima chamada de malloc poderá tomar posse desses bytes. A função free não deve ser aplicada a uma parte de um bloco de bytes alocado por malloc; aplique free apenas ao bloco todo. Convém não deixar ponteiros soltos (= dangling pointers) no seu programa, pois isso pode ser explorado por hackers para atacar o seu computador. Portanto, depois de cada free (ptr), atribua NULL a ptr: free (ptr); ptr = NULL; Atribuir um valor a um ponteiro que se tornou inútil é decididamente deselegante, mas não há como lidar com hackers de maneira elegante… Para não nos cansarmos com detalhes repetitivos, os nossos programas não vão seguir a recomendação de segurança acima.")
46
Vetores e Matrizes

47
tem o mesmo efeito que a alocação estática: int v[100];
Eis como um vetor (= array) com n elementos inteiros pode ser alocado (e depois desalocado) durante a execução de um programa: int *v; int n, i; scanf ( "%d", &n ); v = malloc ( n * sizeof (int) ); for ( i = 0; i < n; i++) scanf ( "%d", &v[i] ); for ( i = n – 1; i >= 0; i – – ) printf ( "%d ", v[ i ] ); free ( v ); Do ponto de vista conceitual (mas apenas desse ponto de vista) o comando: v = malloc (100 * sizeof (int)); tem o mesmo efeito que a alocação estática: int v[100]; A propósito, convém lembrar que o padrão ANSI não permite escrever "int v[n]", a menos que n seja uma constante, definida por um #define.
![tem o mesmo efeito que a alocação estática: int v[100];](http://slideplayer.com.br/slide/9279866/27/images/47/tem+o+mesmo+efeito+que+a+aloca%C3%A7%C3%A3o+est%C3%A1tica%3A+int+v%5B100%5D%3B.jpg "Eis como um vetor (= array) com n elementos inteiros pode ser alocado (e depois desalocado) durante a execução de um programa: int *v; int n, i; scanf ( %d , &n ); v = malloc ( n * sizeof (int) ); for ( i = 0; i < n; i++) scanf ( %d , &v[i] ); for ( i = n – 1; i >= 0; i – – ) printf ( %d , v[ i ] ); free ( v ); Do ponto de vista conceitual (mas apenas desse ponto de vista) o comando: v = malloc (100 * sizeof (int)); tem o mesmo efeito que a alocação estática: int v[100]; A propósito, convém lembrar que o padrão ANSI não permite escrever int v[n] , a menos que n seja uma constante, definida por um #define.")
48
Matrizes bidimensionais são tratadas como vetores de vetores
Matrizes bidimensionais são tratadas como vetores de vetores. Uma matriz com m linhas e n colunas é um vetor cada um de cujos m elementos é um vetor de n elementos. O seguinte fragmento de código faz a alocação dinâmica de uma tal matriz: int **A; int i; A = malloc (m * sizeof (int *)); for (i = 0; i < m; i++) A[i] = malloc (n * sizeof (int)); O elemento de A que está no cruzamento da linha i com a coluna j é denotado por A[i][j].
); for (i = 0; i < m; i++) A[i] = malloc (n * sizeof (int)); O elemento de A que está no cruzamento da linha i com a coluna j é denotado por A[i][j].")
49
Listas Encadeadas (Linked List)
")
50
Tipos de Listas que veremos
Uma lista encadeada é uma representação de uma seqüência de objetos na memória do computador. Cada elemento da seqüência é armazenado em uma célula da lista: o primeiro elemento na primeira célula, o segundo na segunda e assim por diante. Tipos de Listas que veremos Lista Simplesmente Encadeada Lista Simplesmente Encadeada Circular Lista Duplamente Encadeada Lista Duplamente Encadeada Circular As Listas podem ou não ter célula-cabeça

51
Listas Simplesmente Encadeadas

52
Estrutura de uma lista encadeada
Uma lista encadeada (= linked list = lista ligada) é uma seqüência de células; cada célula contém um objeto de algum tipo e o endereço da célula seguinte. Vamos supor que os objetos armazenados nas células são do tipo int. A estrutura de cada célula de uma tal lista pode ser definida assim: struct cel { int conteudo; struct cel *prox; };
 é uma seqüência de células; cada célula contém um objeto de algum tipo e o endereço da célula seguinte. Vamos supor que os objetos armazenados nas células são do tipo int. A estrutura de cada célula de uma tal lista pode ser definida assim: struct cel { int conteudo; struct cel *prox; };")
53
typedef struct cel celula;
É conveniente tratar as células como um novo tipo-de-dados e atribuir um nome a esse novo tipo: typedef struct cel celula; Uma célula c e um ponteiro p para uma célula podem ser declarados assim: celula c; celula *p; Se c é uma célula, então c.conteudo é o conteúdo da célula e c.prox é o endereço da próxima célula. Se p é o endereço de uma célula, então p->conteudo é o conteúdo da célula e p- >prox é o endereço da próxima célula. Se p aponta a última célula da lista, então p->prox vale NULL.

54
Endereço de uma lista encadeada
O endereço de uma lista encadeada é o endereço de sua primeira célula. Se p é o endereço de uma lista, convém, às vezes, dizer simplesmente “p é uma lista”. Se p é uma lista, então vale uma das seguintes alternativas: p == NULL ou p->prox é uma lista

55
Uma lista encadeada pode ser organizada de duas maneiras diferentes, uma óbvia e outra menos óbvia:
Lista com cabeça: O conteúdo da primeira célula é irrelevante: ela serve apenas para marcar o início da lista. A primeira célula é a cabeça (= head cell = dummy cell) da lista. A primeira célula está sempre no mesmo lugar na memória, mesmo que a lista fique vazia. O endereço da primeira célula nunca muda. Digamos que ini é o endereço da primeira célula. Então ini- >prox == NULL se e somente se a lista está vazia. Para criar uma lista vazia, basta dizer: celula *ini; ini = malloc (sizeof (celula)); ini->prox = NULL; Lista sem cabeça: O conteúdo da primeira célula é tão relevante quanto o das demais. Nesse caso, a lista está vazia se o endereço de sua primeira célula é NULL. Para criar uma lista vazia basta fazer: ini = NULL;
 da lista. A primeira célula está sempre no mesmo lugar na memória, mesmo que a lista fique vazia. O endereço da primeira célula nunca muda. Digamos que ini é o endereço da primeira célula. Então ini- >prox == NULL se e somente se a lista está vazia. Para criar uma lista vazia, basta dizer: celula *ini; ini = malloc (sizeof (celula)); ini->prox = NULL; Lista sem cabeça: O conteúdo da primeira célula é tão relevante quanto o das demais. Nesse caso, a lista está vazia se o endereço de sua primeira célula é NULL. Para criar uma lista vazia basta fazer: ini = NULL;")
56
void imprima (celula *ini) { celula *p;
Exemplos: // Imprime o conteúdo de uma lista encadeada com cabeça. // O endereço da primeira célula é ini. void imprima (celula *ini) { celula *p; for (p = ini->prox; p != NULL; p = p->prox) printf ("%d\n", p->conteudo); } // Imprime o conteúdo de uma lista encadeada ini. // A lista não tem cabeça. for (p = ini; p != NULL; p = p->prox)
 { celula *p; for (p = ini->prox; p != NULL; p = p->prox) printf ( %d\n , p->conteudo); } // Imprime o conteúdo de uma lista encadeada ini. // A lista não tem cabeça. for (p = ini; p != NULL; p = p->prox)")
57
void insere (int x, celula *p) { celula *nova;
Inserção em uma lista Quero inserir (= insert) uma nova célula com conteúdo x entre a posição apontada por p e a posição seguinte em uma lista encadeada. É claro que isso só faz sentido se p é diferente de NULL. // Esta função insere uma nova celula em uma lista encadeada. A nova celula // tem conteudo x e é inserida entre a celula apontada por p e a seguinte. void insere (int x, celula *p) { celula *nova; nova = malloc (sizeof (celula)); nova->conteudo = x; nova->prox = p->prox; p->prox = nova; } Veja que maravilha! Não é preciso movimentar células para "criar espaço" para um nova célula, como fizemos para inserir um elemento de um vetor. Basta mudar os valores de alguns ponteiros. Observe também que a função se comporta corretamente mesmo quando quero inserir no fim da lista, isto é, quando p->prox == NULL. Se a lista tem cabeça, a função pode ser usada para inserir no início da lista: basta que p aponte para a célula-cabeça. Infelizmente, a função não é capaz de inserir antes da primeira célula de uma lista sem cabeça. O tempo que a função consome não depende do ponto da lista onde quero fazer a inserção: tanto faz inserir uma nova célula na parte inicial da lista quanto na parte final. Isso é bem diferente do que ocorre com a inserção em um vetor.
 uma nova célula com conteúdo x entre a posição apontada por p e a posição seguinte em uma lista encadeada. É claro que isso só faz sentido se p é diferente de NULL. // Esta função insere uma nova celula em uma lista encadeada. A nova celula. // tem conteudo x e é inserida entre a celula apontada por p e a seguinte. void insere (int x, celula *p) { celula *nova; nova = malloc (sizeof (celula)); nova->conteudo = x; nova->prox = p->prox; p->prox = nova; } Veja que maravilha! Não é preciso movimentar células para criar espaço para um nova célula, como fizemos para inserir um elemento de um vetor. Basta mudar os valores de alguns ponteiros. Observe também que a função se comporta corretamente mesmo quando quero inserir no fim da lista, isto é, quando p->prox == NULL. Se a lista tem cabeça, a função pode ser usada para inserir no início da lista: basta que p aponte para a célula-cabeça. Infelizmente, a função não é capaz de inserir antes da primeira célula de uma lista sem cabeça. O tempo que a função consome não depende do ponto da lista onde quero fazer a inserção: tanto faz inserir uma nova célula na parte inicial da lista quanto na parte final. Isso é bem diferente do que ocorre com a inserção em um vetor.")
58
void remove (celula *p) { celula *morta; morta = p->prox;
Remoção em uma lista Suponha que quero remover (= to remove = to delete) uma certa célula da lista. Como posso especificar a célula em questão? A idéia mais óbvia é apontar para a célula que quero remover. Mas é fácil perceber que essa idéia não é boa. É melhor apontar para a célula anterior à que quero remover. Infelizmente, isso traz uma nova dificuldade: não há como pedir a remoção da primeira célula. Portanto, vamos nos limitar às listas com cabeça. Vamos supor que p é o endereço de uma célula de uma lista com cabeça e que desejo remover a célula apontada por p->prox. // Esta função recebe o endereço p de uma celula de uma lista encadeada. A função // remove da lista a celula p->prox. A função supõe que p != NULL e p->prox != NULL. void remove (celula *p) { celula *morta; morta = p->prox; p->prox = morta->prox; free (morta); } Veja que maravilha! Não é preciso copiar informações de um lugar para outro, como fizemos para remover um elemento de um vetor: basta mudar o valor de um ponteiro. A função consome sempre o mesmo tempo, quer a célula a ser removida esteja perto do início da lista quer esteja perto do fim.
 uma certa célula da lista. Como posso especificar a célula em questão A idéia mais óbvia é apontar para a célula que quero remover. Mas é fácil perceber que essa idéia não é boa. É melhor apontar para a célula anterior à que quero remover. Infelizmente, isso traz uma nova dificuldade: não há como pedir a remoção da primeira célula. Portanto, vamos nos limitar às listas com cabeça. Vamos supor que p é o endereço de uma célula de uma lista com cabeça e que desejo remover a célula apontada por p->prox. // Esta função recebe o endereço p de uma celula de uma lista encadeada. A função. // remove da lista a celula p->prox. A função supõe que p != NULL e p->prox != NULL. void remove (celula *p) { celula *morta; morta = p->prox; p->prox = morta->prox; free (morta); } Veja que maravilha! Não é preciso copiar informações de um lugar para outro, como fizemos para remover um elemento de um vetor: basta mudar o valor de um ponteiro. A função consome sempre o mesmo tempo, quer a célula a ser removida esteja perto do início da lista quer esteja perto do fim.")
59
Busca em uma lista encadeada
Veja como é fácil verificar se um inteiro x pertence a uma lista encadeada, ou seja, se é igual ao conteúdo de alguma célula da lista: // Esta função recebe um inteiro x e uma lista encadeada de // inteiros. O endereço da lista é ini e ela tem uma celula-cabeça. // A função devolve o endereço de uma celula que contém x. // Se tal celula não existe, a função devolve NULL. celula *busca (int x, celula *ini) { celula *p; p = ini->prox; while (p != NULL && p->conteudo != x) p = p->prox; return p; }
 { celula *p; p = ini->prox; while (p != NULL && p->conteudo != x) p = p->prox; return p; }")
60
Exercícios

61
1) Escreva uma versão da função busca para listas sem cabeça.
2) Escreva uma função que insira um novo elemento em uma lista encadeada com cabeça. 3) Escreva uma função que insira um novo elemento em uma lista encadeada sem cabeça. 4) Escreva uma função que remova uma célula de uma lista encadeada sem cabeça.
 Escreva uma função que insira um novo elemento em uma lista encadeada com cabeça. 3) Escreva uma função que insira um novo elemento em uma lista encadeada sem cabeça. 4) Escreva uma função que remova uma célula de uma lista encadeada sem cabeça.")
62
5) Escreva uma função que copie um vetor para uma lista encadeada sem cabeça. Ambos vem como parâmetro na função. 6) Escreva uma função que faça uma cópia de uma lista dada como parâmetro e retorne a nova lista. 7) Escreva uma função que concatena duas listas encadeadas (isto é, "amarra" a segunda no fim da primeira). 8) Escreva uma função que conta o número de células de uma lista encadeada. 9) Escreva uma função que verifica se duas listas dadas são iguais, ou melhor, se têm o mesmo conteúdo. 10) Escreva uma função que inverte a ordem das células de uma lista encadeada (a primeira célula passa a ser a última, a segunda passa a ser a penúltima etc.). Faça isso sem usar espaço auxiliar; apenas altere os ponteiros.
 Escreva uma função que faça uma cópia de uma lista dada como parâmetro e retorne a nova lista. 7) Escreva uma função que concatena duas listas encadeadas (isto é, amarra a segunda no fim da primeira). 8) Escreva uma função que conta o número de células de uma lista encadeada. 9) Escreva uma função que verifica se duas listas dadas são iguais, ou melhor, se têm o mesmo conteúdo. 10) Escreva uma função que inverte a ordem das células de uma lista encadeada (a primeira célula passa a ser a última, a segunda passa a ser a penúltima etc.). Faça isso sem usar espaço auxiliar; apenas altere os ponteiros.")
63
Filas

64
Uma fila é uma estrutura de dados que admite inserção de novos elementos e remoção de elementos antigos. Mais especificamente, uma fila (= queue) é uma estrutura sujeita à seguinte regra de operação: sempre que houver uma remoção, o elemento removido é o que está na estrutura há mais tempo. Em outras palavras, o primeiro objeto inserido na fila é também o primeiro a ser removido. Essa política é conhecida pela sigla FIFO (= First-In-First-Out = primeiro que entra – primeiro que sai).
.")
65
Implementação de uma Fila em um Vetor

66
A parte do vetor ocupada pela fila será
Suponha que nossa fila FIFO mora em um vetor fila[0..N-1]. Suponha que os elementos do vetor são inteiros (isso é só um exemplo; os elementos da fila poderiam ser de quaisquer outros tipos). A parte do vetor ocupada pela fila será fila[ini..fim-1]. 0 ini fim N-1
. A parte do vetor ocupada pela fila será. fila[ini..fim-1]. 0 ini fim N-1.")
67
A fila está vazia se ini == fim e cheia se fim == N.
0 ini fim N-1 O primeiro elemento da fila está na posição ini e o último na posição fim-1. A fila está vazia se ini == fim e cheia se fim == N. Para remover (= delete = de-queue) um elemento da fila basta fazer x = fila[ini++]; Isso equivale ao par de instruções "x = fila[ini]; ini += 1;", nesta ordem. É claro que você só deve fazer isso se tiver certeza de que a fila não está vazia. Para inserir (= insert = enqueue) um objeto y na fila basta fazer fila[fim++] = y; Note como a coisa funciona bem mesmo quando a fila está vazia. É claro que você só deve inserir um elemento na fila se ela não estiver cheia; caso contrário a fila transborda (transbordar = to overflow). Em geral, a tentativa de inserir em uma fila cheia é uma situação excepcional, que indica um mau planejamento lógico do seu programa.
 um elemento da fila basta fazer x = fila[ini++]; Isso equivale ao par de instruções x = fila[ini]; ini += 1; , nesta ordem. É claro que você só deve fazer isso se tiver certeza de que a fila não está vazia. Para inserir (= insert = enqueue) um objeto y na fila basta fazer fila[fim++] = y; Note como a coisa funciona bem mesmo quando a fila está vazia. É claro que você só deve inserir um elemento na fila se ela não estiver cheia; caso contrário a fila transborda (transbordar = to overflow). Em geral, a tentativa de inserir em uma fila cheia é uma situação excepcional, que indica um mau planejamento lógico do seu programa.")
68
Pilhas

69
Uma pilha é uma das várias estruturas de dados que admitem remoção de elementos e inserção de novos elementos. Mais especificamente, uma pilha (= stack) é uma estrutura sujeita à seguinte regra de operação: sempre que houver uma remoção, o elemento removido é o que está na estrutura há menos tempo. Em outras palavras, o primeiro objeto a ser inserido na pilha é o último a ser removido. Essa política é conhecida pela sigla LIFO (= Last-In-First-Out = último que entra – primeiro que sai).
.")
70
Implementação de uma Pilha em um Vetor

71
Suponha que nossa pilha está armazenada em um vetor pilha[0. n-1]
Suponha que nossa pilha está armazenada em um vetor pilha[0..n-1]. Vamos supor que os elementos de pilha são inteiros (isso é só um exemplo; os elementos de pilha poderiam ser quaisquer outros objetos). A parte do vetor ocupada pela pilha será pilha[0..t-1] . 0 t N-1
![Suponha que nossa pilha está armazenada em um vetor pilha[0. n-1]](http://slideplayer.com.br/slide/9279866/27/images/71/Suponha+que+nossa+pilha+est%C3%A1+armazenada+em+um+vetor+pilha%5B0.+n-1%5D.jpg "Suponha que nossa pilha está armazenada em um vetor pilha[0..n-1]. Vamos supor que os elementos de pilha são inteiros (isso é só um exemplo; os elementos de pilha poderiam ser quaisquer outros objetos). A parte do vetor ocupada pela pilha será pilha[0..t-1] . 0 t N-1.")
72
Para consultar a pilha sem desempilhar faça x = pilha[t-1].
0 t N-1 O índice t indica o topo (= top) da pilha. Esta é a primeira posição vaga da pilha. A pilha está vazia se t vale 0 e cheia se t vale n. Para remover um elemento da pilha (= desempilhar = to pop) faça x = pilha[--t]; Isso equivale ao par de instruções "t -= 1; x = pilha[t];" nesta ordem. É claro que você só deve desempilhar se tiver certeza de que a pilha não está vazia. Para consultar a pilha sem desempilhar faça x = pilha[t-1]. Para inserir ( = empilhar = to push) um objeto y na pilha faça pilha[t++] = y; Isso equivale ao par de instruções "pilha[t] = y; t += 1;" nesta ordem. Antes de empilhar, verifique se a pilha já está cheia para evitar que ela transborde (ou seja, para evitar um overflow). Em geral, a tentativa de inserir em uma pilha cheia é uma situação excepcional, que indica um mau planejamento lógico do seu programa.
![Para consultar a pilha sem desempilhar faça x = pilha[t-1].](http://slideplayer.com.br/slide/9279866/27/images/72/Para+consultar+a+pilha+sem+desempilhar+fa%C3%A7a+x+%3D+pilha%5Bt-1%5D..jpg "0 t N-1. O índice t indica o topo (= top) da pilha. Esta é a primeira posição vaga da pilha. A pilha está vazia se t vale 0 e cheia se t vale n. Para remover um elemento da pilha (= desempilhar = to pop) faça x = pilha[--t]; Isso equivale ao par de instruções t -= 1; x = pilha[t]; nesta ordem. É claro que você só deve desempilhar se tiver certeza de que a pilha não está vazia. Para consultar a pilha sem desempilhar faça x = pilha[t-1]. Para inserir ( = empilhar = to push) um objeto y na pilha faça pilha[t++] = y; Isso equivale ao par de instruções pilha[t] = y; t += 1; nesta ordem. Antes de empilhar, verifique se a pilha já está cheia para evitar que ela transborde (ou seja, para evitar um overflow). Em geral, a tentativa de inserir em uma pilha cheia é uma situação excepcional, que indica um mau planejamento lógico do seu programa.")
73
Pilha e Fila na Lista Encadeada

74
Insere no início... PILHA
celula *insere (celula *ini, int x) { celula *nova = malloc(sizeof(celula)); nova->conteudo = x; nova->prox = ini; return nova; } Insere no final... FILA celula *insere (celula *ini, int x) { celula *nova = malloc(sizeof(celula)); nova->conteudo = x; nova->prox = NULL; if (ini == NULL) return nova; while (p->prox != NULL) p=p->prox; p->prox = nova; return ini; } Remove tanto para PILHA quanto para FILA... celula *remove (celula *ini) { celula *p = ini; ini=ini->prox; free(p); return ini; }
 { celula *nova = malloc(sizeof(celula)); nova->conteudo = x; nova->prox = ini; return nova; } Insere no final... FILA. celula *insere (celula *ini, int x) { celula *nova = malloc(sizeof(celula)); nova->conteudo = x; nova->prox = NULL; if (ini == NULL) return nova; while (p->prox != NULL) p=p->prox; p->prox = nova; return ini; } Remove tanto para PILHA quanto para FILA... celula *remove (celula *ini) { celula *p = ini; ini=ini->prox; free(p); return ini; }")
75
EXERCÍCIOS

76
1) Implemente uma pilha numa lista simplesmente encadeada não-circular sem cabeça.
2) Implemente uma fila numa lista simplesmente encadeada circular com cabeça.
 Implemente uma fila numa lista simplesmente encadeada circular com cabeça.")
77
Listas Simplesmente Encadeadas Circulares

78
Listas Simplesmente Encadeadas Circulares
Numa lista circular, o último elemento tem como próximo o primeiro elemento da lista, formando um ciclo. A rigor, neste caso, não faz sentido falarmos em primeiro ou último elemento. A lista pode ser representada por um ponteiro para um elemento inicial qualquer da lista. Para percorrer os elementos de uma lista circular, visitamos todos os elementos a partir do ponteiro do elemento inicial até alcançarmos novamente esse mesmo elemento. Devemos salientar que o caso em que a lista é vazia ainda deve ser tratado (se a lista é vazia, o ponteiro para um elemento inicial vale NULL).
.")
79
Impressão de todos os elementos da Lista não-Circular
// Imprime o conteúdo de uma lista encadeada ini. // A lista não tem cabeça. void imprime (celula *ini) { celula *p; for (p = ini; p != NULL; p = p->prox) printf ("%d\n", p->conteudo); }
 { celula *p; for (p = ini; p != NULL; p = p->prox) printf ( %d\n , p->conteudo); }")
80
Impressão de todos os elementos da Lista Circular
// Imprime o conteúdo de uma lista simplesmente encadeada circular. // A lista não tem cabeça. // O endereço da primeira célula é ini. void imprime_circular (celula *ini) { celula *p = ini; if (p != NULL) { do { printf("%d\n", p->conteudo); p = p->prox; } while (p != ini); }
 { celula *p = ini; if (p != NULL) { do { printf( %d\n , p->conteudo); p = p->prox; } while (p != ini); }")
81
Exercícios

82
1) Faça uma função que imprima todos os elementos de uma lista encadeada circular com cabeça.
2) Faça uma função de busca numa lista encadeada circular com cabeça. 3) Escreva uma função que concatena duas listas simplesmente encadeadas circulares. 4) Escreva uma função que conta o número de células de uma lista simplesmente encadeada circular. 5) Escreva uma função que verifica se duas listas simplesmente encadeadas circulares dadas são iguais, ou melhor, se têm o mesmo conteúdo. 6) Escreva uma função que inverte a ordem das células de uma lista simplesmente encadeada circular (a primeira célula passa a ser a última, a segunda passa a ser a penúltima etc.)
 Faça uma função de busca numa lista encadeada circular com cabeça. 3) Escreva uma função que concatena duas listas simplesmente encadeadas circulares. 4) Escreva uma função que conta o número de células de uma lista simplesmente encadeada circular. 5) Escreva uma função que verifica se duas listas simplesmente encadeadas circulares dadas são iguais, ou melhor, se têm o mesmo conteúdo. 6) Escreva uma função que inverte a ordem das células de uma lista simplesmente encadeada circular (a primeira célula passa a ser a última, a segunda passa a ser a penúltima etc.)")
83
Listas Duplamente Encadeadas

84
A estrutura de lista encadeada vista caracteriza-se por formar um encadeamento simples entre os elementos: cada elemento armazena um ponteiro para o próximo elemento da lista. Desta forma, não temos como percorrer eficientemente os elementos em ordem inversa, isto é, do final para o início da lista. O encadeamento simples também dificulta a retirada de um elemento da lista. Mesmo se tivermos o ponteiro do elemento que desejamos retirar, temos que percorrer a lista, elemento por elemento, para encontrarmos o elemento anterior, pois, dado um determinado elemento, não temos como acessar diretamente seu elemento anterior. Para solucionar esses problemas, podemos formar o que chamamos de listas duplamente encadeadas. Nelas, cada elemento tem um ponteiro para o próximo elemento e um ponteiro para o elemento anterior. Desta forma, dado um elemento, podemos acessar ambos os elementos adjacentes: o próximo e o anterior. Se tivermos um ponteiro para o último elemento da lista, podemos percorrer a lista em ordem inversa, bastando acessar continuamente o elemento anterior, até alcançar o primeiro elemento da lista, que não tem elemento anterior (o ponteiro do elemento anterior vale NULL).
.")
85
Vamos usar essa declaração:
struct celula { int conteudo; struct celula *ant; struct celula *prox; }; typedef struct celula celula;

86
Inicialização: SEM CABEÇA: celula *ini = NULL; COM CABEÇA: celula *ini = malloc(sizeof(celula)); ini->prox = NULL; ini->ant = NULL;

87
Função de busca A função de busca recebe a informação referente ao elemento que queremos buscar e tem como valor de retorno o ponteiro do nó da lista que representa o elemento. Caso o elemento não seja encontrado na lista, o valor retornado é NULL. celula *busca (celula *ini, int v) { celula *p; for (p=ini; p!=NULL; p=p->prox) if (p->conteudo == v) return p; return NULL; }
 { celula *p; for (p=ini; p!=NULL; p=p->prox) if (p->conteudo == v) return p; return NULL; }")
88
Função de inserção celula *insere (celula *ini, int v) {
celula *novo = malloc(sizeof(celula)); novo->conteudo = v; novo->prox = ini; novo->ant = NULL; if (ini != NULL) ini->ant = novo; return novo; } Nessa função, o novo elemento é encadeado no início da lista. Assim, ele tem como próximo elemento o antigo primeiro elemento da lista e como anterior o valor NULL. A seguir, a função testa se a lista não era vazia, pois, neste caso, o elemento anterior do então primeiro elemento passa a ser o novo elemento. De qualquer forma, o novo elemento passa a ser o primeiro da lista, e deve ser retornado como valor da lista atualizada.
); novo->conteudo = v; novo->prox = ini; novo->ant = NULL; if (ini != NULL) ini->ant = novo; return novo; } Nessa função, o novo elemento é encadeado no início da lista. Assim, ele tem como próximo elemento o antigo primeiro elemento da lista e como anterior o valor NULL. A seguir, a função testa se a lista não era vazia, pois, neste caso, o elemento anterior do então primeiro elemento passa a ser o novo elemento. De qualquer forma, o novo elemento passa a ser o primeiro da lista, e deve ser retornado como valor da lista atualizada.")
89
Modifique a Função de inserção abaixo para inserir no final de uma lista duplamente encadeada
celula *insere (celula *ini, int v) { celula *novo = malloc(sizeof(celula)); novo->conteudo = v; novo->prox = ini; novo->ant = NULL; if (ini != NULL) ini->ant = novo; return novo; }
 { celula *novo = malloc(sizeof(celula)); novo->conteudo = v; novo->prox = ini; novo->ant = NULL; if (ini != NULL) ini->ant = novo; return novo; }")
90
Função de inserção - insere no final de uma lista duplamente encadeada
celula *insere (celula *ini, int v) { celula *novo = malloc(sizeof(celula)); novo->conteudo = v; if (ini != NULL) { for (celula *p=ini ; p->prox != NULL ; p = p->prox) {} novo->prox = NULL; novo->ant = p; p->prox = novo; } else { ini = novo; ini->ant = NULL; ini->prox = NULL; return ini;
 { celula *novo = malloc(sizeof(celula)); novo->conteudo = v; if (ini != NULL) { for (celula *p=ini ; p->prox != NULL ; p = p->prox) {} novo->prox = NULL; novo->ant = p; p->prox = novo; } else { ini = novo; ini->ant = NULL; ini->prox = NULL; return ini;")
91
Outra Função de inserção - insere no final de uma lista duplamente encadeada
celula *insere (celula *ini, int v) { celula *novo = malloc(sizeof(celula)); novo->conteudo = v; novo->prox = NULL; celula *p = ini; if (p != NULL) { while (p->prox != NULL) p = p->prox; p->prox = novo; } else ini = novo; novo->ant = p; return ini;
 { celula *novo = malloc(sizeof(celula)); novo->conteudo = v; novo->prox = NULL; celula *p = ini; if (p != NULL) { while (p->prox != NULL) p = p->prox; p->prox = novo; } else ini = novo; novo->ant = p; return ini;")
92
Função que retira um elemento da lista
A função de remoção fica mais complicada, pois temos que acertar o encadeamento duplo. Em contrapartida, podemos retirar um elemento da lista conhecendo apenas o ponteiro para esse elemento. Desta forma, podemos usar a função de busca acima para localizar o elemento e em seguida acertar o encadeamento, liberando o elemento ao final. Se p representa o ponteiro do elemento que desejamos retirar, para acertar o encadeamento devemos conceitualmente fazer: p->ant->prox = p->prox; p->prox->ant = p->ant; isto é, o anterior passa a apontar para o próximo e o próximo passa a apontar para o anterior. Quando p apontar para um elemento no meio da lista, as duas atribuições acima são suficientes para efetivamente acertar o encadeamento da lista. No entanto, se p for um elemento no extremo da lista, devemos considerar as condições de contorno. Se p for o primeiro, não podemos escrever p->ant->prox, pois p->ant é NULL; além disso, temos que atualizar o valor da lista, pois o primeiro elemento será removido.

93
Uma implementação da função para retirar um elemento é mostrada a seguir:
celula *retira (celula *ini, int v) { celula *p = busca(ini,v); if (p == NULL) return ini; /* não achou o elemento: retorna lista inalterada */ /* retira elemento do encadeamento */ if (ini == p) ini = p->prox; else p->ant->prox = p->prox; if (p->prox != NULL) p->prox->ant = p->ant; free(p); return ini; }
 { celula *p = busca(ini,v); if (p == NULL) return ini; /* não achou o elemento: retorna lista inalterada */ /* retira elemento do encadeamento */ if (ini == p) ini = p->prox; else. p->ant->prox = p->prox; if (p->prox != NULL) p->prox->ant = p->ant; free(p); return ini; }")
94
Lista Duplamente Encadeada Circular
Uma lista circular também pode ser construída com encadeamento duplo. Neste caso, o que seria o último elemento da lista passa ter como próximo o primeiro elemento, que, por sua vez, passa a ter o último como anterior. Com essa construção podemos percorrer a lista nos dois sentidos, a partir de um ponteiro para um elemento qualquer. Abaixo, ilustramos o código para imprimir a lista no sentido reverso, isto é, percorrendo o encadeamento dos elementos anteriores. void imprime_circular_rev (celula *ini) { celula *p = ini; /* faz p apontar para o nó inicial */ if (p) { /* testa se lista não é vazia */ do { /* percorre os elementos até alcançar novamente o início */ printf("%d\n", p->conteudo); /* imprime informação do nó */ p = p->ant; /* "avança" para o nó anterior */ } while (p != ini); }
 { celula *p = ini; /* faz p apontar para o nó inicial */ if (p) { /* testa se lista não é vazia */ do { /* percorre os elementos até alcançar novamente o início */ printf( %d\n , p->conteudo); /* imprime informação do nó */ p = p->ant; /* avança para o nó anterior */ } while (p != ini); }")
95
Exercícios

96
1) Escreva uma função que concatena duas listas duplamente encadeadas.
2) Escreva uma função que conta o número de células de uma lista duplamente encadeada. 3) Escreva uma função que inverte a ordem das células de uma lista duplamente encadeada.
 Escreva uma função que conta o número de células de uma lista duplamente encadeada. 3) Escreva uma função que inverte a ordem das células de uma lista duplamente encadeada.")
97
4) Escreva uma função que insere elemento numa lista duplamente encadeada circular.
5) Escreva uma função que remove um elemento de uma lista duplamente encadeada circular. 6) Escreva uma função que inverte a ordem das células de uma lista duplamente encadeada circular.
 Escreva uma função que remove um elemento de uma lista duplamente encadeada circular. 6) Escreva uma função que inverte a ordem das células de uma lista duplamente encadeada circular.")
98
Recursividade

99
Muitas vezes nos deparamos com alguns problemas de computação envolvendo loops que chegam a ficar muito complexos. Na maioria das vezes podemos simplificar estes algoritmos usando a recursividade. Algoritmos recursivos são muito usados em pesquisas de diretórios, inteligência artificial e em muitas outras áreas.

100
Funções recursivas só devem ser usadas em pontos EXTREMAMENTE críticos...
Primeiro porque funções recursivas usam mais memória; segundo porque torna seu programa extremamente lento; terceiro porque pode deixá-lo instável...

101
Um algoritmo recursivo deve fazer pelo menos uma chamada a si mesmo, de forma direta (podemos ver o algoritmo sendo chamado dentro dele mesmo) ou indireta (o algoritmo chama um outro algoritmo, que por sua vez invoca uma chamada ao primeiro).
 ou indireta (o algoritmo chama um outro algoritmo, que por sua vez invoca uma chamada ao primeiro).")
102
Um algoritmo recursivo deve ter pelo menos uma condição de parada, para que não seja invocado infinitamente. Esta condição de parada corresponde a instâncias suficientemente pequenas ou simples do problema original, que podem ser resolvidas diretamente.

103
Para todo algoritmo recursivo existe pelo menos um algoritmo iterativo correspondente e vice-versa. Todavia, muitas vezes pode ser difícil encontrar essa correspondência.

104
ser implementados em linguagens de programação de alto nível.
Vantagens Os algoritmos recursivos normalmente são mais compactos, mais legíveis e mais fáceis de ser compreendidos. Algoritmos para resolver problemas de natureza recursiva são fáceis de ser implementados em linguagens de programação de alto nível.

105
Desvantagens Por usarem intensivamente a pilha, o que requer alocações e desalocações de memória, os algoritmos recursivos tendem a ser mais lentos que os equivalentes iterativos, porém pode valer a pena sacrificar a eficiência em benefício da clareza. Algoritmos recursivos são mais difíceis de ser depurados durante a fase de desenvolvimento.

106
Nem sempre a natureza recursiva do problema garante que um algoritmo recursivo seja a melhor opção para resolvê-lo. O algoritmo recursivo para obter a seqüência de Fibonacci é um ótimo exemplo disso.

107
Algoritmos recursivos são aplicados em diversas situações como em:
1) problemas envolvendo manipulações de árvores; 2) analisadores léxicos recursivos de compiladores; 3) problemas que envolvem tentativa e erro ("Backtracking").
 problemas envolvendo manipulações de árvores; 2) analisadores léxicos recursivos de compiladores; 3) problemas que envolvem tentativa e erro ( Backtracking ).")
108
Fatorial

109
long fat(int n){ long resposta; if (n==0) return(1); resposta = fat(n - 1) * n; return (resposta); } void main() { int num; printf("\n Digite um número: "); scanf("%d",&num); printf("\n O fatorial de %d = %ld",num,fat(num));
 { int num; printf( \n Digite um número: ); scanf( %d ,&num); printf( \n O fatorial de %d = %ld ,num,fat(num));")
110
Todo cuidado é pouco ao se fazer funções recursivas
Todo cuidado é pouco ao se fazer funções recursivas. A primeira coisa a se providenciar é um critério de parada. Este vai determinar quando a função deverá parar de chamar a si mesma. Isto impede que a função se chame infinitas vezes.

111
Fibonacci

112
void fibo( int val , int N1 , int N2 ){
if (val>0){ val--; printf("%d ",N1+N2); fibo(val,N2,N1+N2); } void main(){ int TERMOS; printf("Digite a qtde de termos da serie: "); scanf("%d",&TERMOS); fibo(TERMOS,1,0);
{ val--; printf( %d ,N1+N2); fibo(val,N2,N1+N2); } void main(){ int TERMOS; printf( Digite a qtde de termos da serie: ); scanf( %d ,&TERMOS); fibo(TERMOS,1,0);")
113
Problema da Torre de Hanói

114
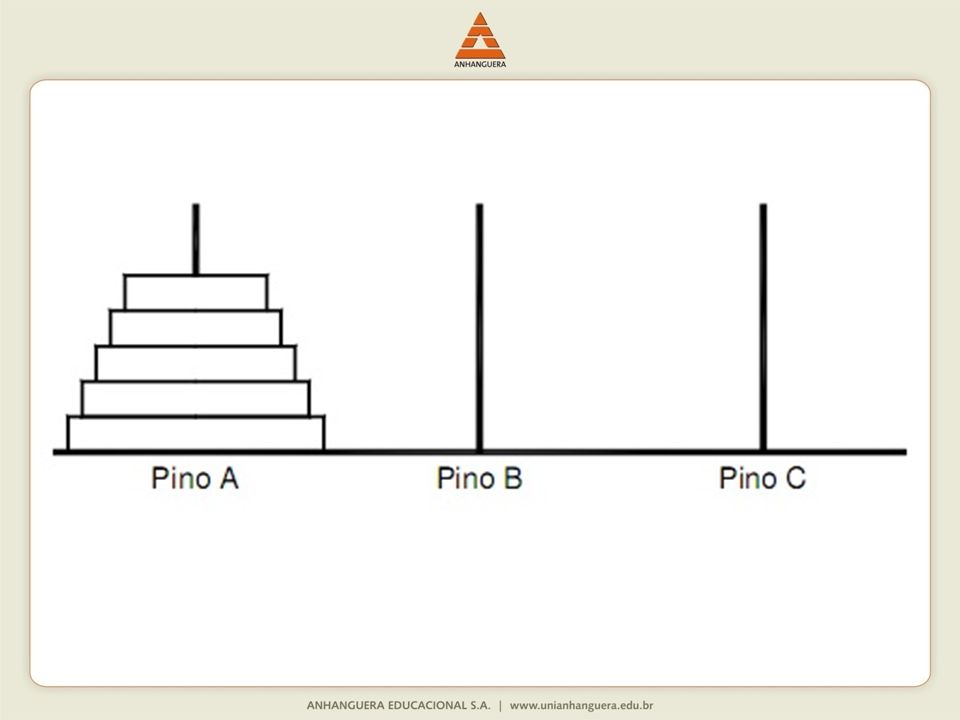
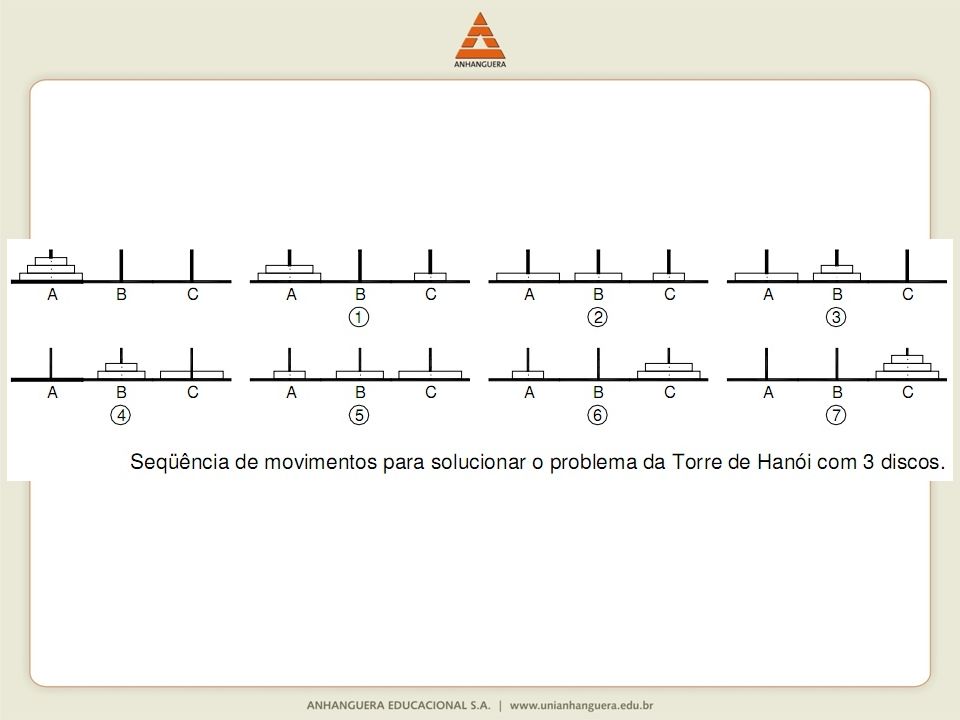
O problema ou quebra-cabeça conhecido como torre de Hanói foi publicado em 1883 pelo matemático francês Edouard Lucas, também conhecido por seus estudos com a série Fibonacci. Consiste em transferir, com o menor número de movimentos, a torre composta por N discos do pino A (origem) para o pino C (destino), utilizando o pino B como auxiliar. Somente um disco pode ser movimentado de cada vez e um disco não pode ser colocado sobre outro disco de menor diâmetro.
 para o pino C (destino), utilizando o pino B como auxiliar. Somente um disco pode ser movimentado de cada vez e um disco não pode ser colocado sobre outro disco de menor diâmetro.")
116
Solução: Transferir a torre com N-1 discos de A para B, mover o maior disco de A para C e transferir a torre com N-1 de B para C. Embora não seja possível transferir a torre com N-1 de uma só vez, o problema torna-se mais simples: mover um disco e transferir duas torres com N-2 discos. Assim, cada transferência de torre implica em mover um disco e transferir de duas torres com um disco a menos e isso deve ser feito até que torre consista de um único disco.

118
O programa que soluciona esse problema é surpreendentemente simples:
void hanoi (int n , char a , char b , char c) { if ( n==1 ) printf(“Mova disco 1 de %c para %c” ,a,c); else hanoi( n-1 , a , c , b ); printf(“Mova disco %i de %c para %c” ,n,a,c); hanoi( n-1 , b , a , c ); }
 { if ( n==1 ) printf( Mova disco 1 de %c para %c ,a,c); else. hanoi( n-1 , a , c , b ); printf( Mova disco %i de %c para %c ,n,a,c); hanoi( n-1 , b , a , c ); }")
119
Árvore Binária

120
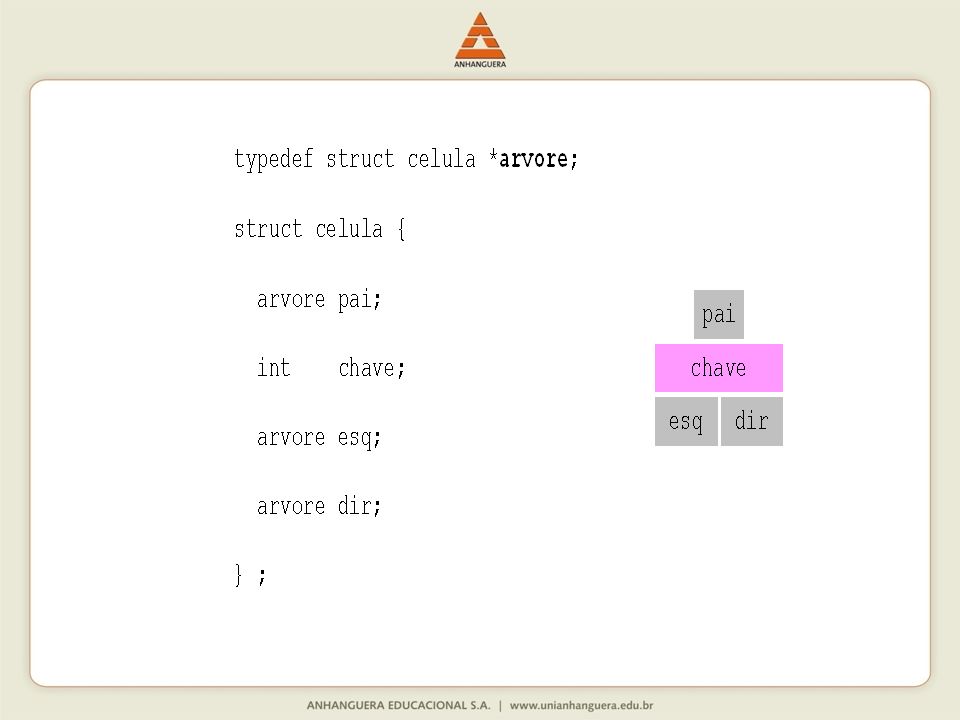
Uma árvore binária (= binary tree) é uma estrutura de dados mais geral que uma lista encadeada. Eis uma definição recursiva do conceito: uma árvore binária sobre um conjunto de objetos é NULL (esta é a árvore vazia) ou um objeto seguido de um par ordenado de árvores binárias. Cada elemento — ou célula, ou nó — de uma árvore binária consiste em uma chave e três ponteiros. A chave é a informação que realmente interessa. Os três ponteiros servem apenas para dar estrutura à árvore: um aponta para o "filho esquerdo" da célula, outro para o "filho direito" e o terceiro para o "pai" da célula. (De acordo com essa definição, uma árvore é uma generalização de uma lista duplamente encadeada.)
")
122
Para que uma estrutura montada a partir de tais células mereça o nome de árvore devemos ter x->esq->pai igual a x (desde que x->esq não seja NULL). Analogamente, devemos ter x->dir->pai igual a x. Qualquer dos três ponteiros pode ter valor NULL. Se x é o endereço de uma célula e x->pai é NULL, dizemos que x é o endereço da raiz da árvore. Se x->esq e x->dir são ambos NULL então dizemos que x é uma folha (= leaf) da árvore. Para especificar uma árvore binária, basta fornecer o endereço da raiz da árvore. Se esse endereço for NULL, dizemos que a árvore é vazia.
 da árvore. Para especificar uma árvore binária, basta fornecer o endereço da raiz da árvore. Se esse endereço for NULL, dizemos que a árvore é vazia.")
123
Terminologia: Nó pai – nó ao qual um nó está ligado (diretamente). Nó filho – cada um dos nós derivados de um nó pai. Nó ancestral – todos os nós acima de um dado nó, em direção a raiz. Nó descendente – todos os nós a baixo de um dado nó. Nós irmãos – nós com o mesmo pai. Grau – número de sub-árvores de um nó. Nó terminal (folha) – nó sem filho ou com grau zero. Nível – número de arcos entre um nó e a raiz. Altura da árvore – nível mais alto (profundidade). Floresta – conjunto de árvores disjuntas. Aplicações: relação de hierarquia (composição) / organograma / diretórios / peças de um conjunto / expressão aritmética / armazenamento de dados com acesso rápido (árvore binária de pesquisa)
 – nó sem filho ou com grau zero. Nível – número de arcos entre um nó e a raiz. Altura da árvore – nível mais alto (profundidade). Floresta – conjunto de árvores disjuntas. Aplicações: relação de hierarquia (composição) / organograma / diretórios / peças de um conjunto / expressão aritmética / armazenamento de dados com acesso rápido (árvore binária de pesquisa)")
124
Varredura e-r-d Ao contrário de uma lista encadeada, uma árvore binária pode ser percorrida de muitas maneiras diferentes. Uma maneira particularmente importante é a ordem esquerda-raiz-direita. Na varredura e-r-d visitamos primeiro a subárvore esquerda, em ordem e-r-d; depois a raiz; e finalmente a subárvore direita, em ordem e-r-d. Na figura abaixo, as células estão numeradas na ordem da varredura e-r-d.

125
Eis uma função recursiva que faz a varredura e-r-d de uma árvore cuja raiz tem endereço r:
// Recebe a raiz r de uma árvore binária. // Imprime as chaves das celulas em ordem e-r-d. void erd (arvore r) { if (r != NULL) { erd (r->esq); printf ("%d\n", r->chave); erd (r->dir); }
 { if (r != NULL) { erd (r->esq); printf ( %d\n , r->chave); erd (r->dir); }")
126
Existem funções semelhantes para fazer varreduras:
red (raiz-esquerda-direita) edr (esquerda-direita-raiz)
 edr (esquerda-direita-raiz)")
127
void erd (arvore r) { if (r != NULL) { erd (r->esq); printf ("%d\n", r->chave); erd (r->dir); } void red (arvore r) { red (r->esq); red (r->dir); void edr (arvore r) { edr (r->esq); edr (r->dir);
 { red (r->esq); red (r->dir); void edr (arvore r) { edr (r->esq); edr (r->dir);")
128
Grafos

129
A teoria dos grafos estuda objetos combinatórios - os grafos - que são um bom modelo para muitos problemas em vários ramos da matemática, da informática, da engenharia e da indústria. Muitos dos problemas sobre grafos tornaram-se célebres porque são um interessante desafio intelectual e porque têm importantes aplicações práticas.

130
Você seria capaz de desenhar a figura abaixo sem tirar o lápis do papel? Tem que ir de ponto a ponto e não pode passar pela mesma linha duas vezes.

131
Dica... Tente seguir os pontos pela ordem das letras...

132
Foi fácil? Experimente agora começar pelo ponto B...
Bem, esse problema é importante? Pensemos numa pequena cidade, com pequeno orçamento. O serviço de recolhimento de lixo é feito por um pequeno caminhão. Queremos evitar o desperdício; uma boa idéia seria fazer o caminhão passar uma única vez por cada rua e retornar ao ponto de partida. Na verdade, é o mesmo problema.

133
Um outro problema que propomos às crianças para que se aquietem é o seguinte: temos que ligar Luz, Gás e Telefone a três casas sem que as linhas se cruzem. Você já tentou?

134
Outra vez, cabe a pergunta: esse problema é importante
Outra vez, cabe a pergunta: esse problema é importante? Pensemos então numa fábrica de placas de circuito integrado. Encontrar esquemas de ligação que evitem cruzamento é crucial para baratear os custos de manufatura; quanto menos camadas, mais rápido e rentável se torna o serviço. Nos dois casos só nos interessou considerar um conjunto de pontos e um conjunto de ligações entre eles. É a essa estrutura que chamamos grafo. O que estamos vendo aqui tratam da Teoria dos Grafos - uma modesta introdução. Desde o século XVIII até nossos dias essa teoria tem conhecido extraordinário desenvolvimento teórico e aplicado.

135
Numa escola algumas turmas resolveram realizar um torneio de vôlei
Numa escola algumas turmas resolveram realizar um torneio de vôlei. Participam do torneio as turmas 6A, 6B, 7A, 7B, 8A e 8B. Alguns jogos foram realizados até agora: 6A jogou com 7A, 7B, 8B 6B jogou com 7A, 8A, 8B 7A jogou com 6A, 6B 7B jogou com 6A, 8A, 8B 8A jogou com 6B, 7B, 8B 8B jogou com 6A, 6B, 7B, 8A Mas será que isto está correto? Pode ter havido um erro na listagem. Uma maneira de representar a situação através de uma figura: as turmas serão representadas por pontos e os jogos serão representados por linhas.

136
Não é difícil agora constatar a consistência das informações
Não é difícil agora constatar a consistência das informações. A estrutura que acabamos de conhecer é um grafo. Apresentamos duas formas de representar esta estrutura: • Por uma lista, dizendo quem se relaciona com quem. Por um desenho, isto é, uma representação gráfica. Qual é a forma correta? As duas são corretas. A estrutura “grafo” admite várias maneiras de ser representada. Isso não é novidade: a palavra “dois” e o símbolo “2” representam o mesmo conceito matemático.

137
Conclusão

Apresentações semelhantes