Carregar apresentação
A apresentação está carregando. Por favor, espere

1
Capítulo VII – A Distribuição Normal
Definição. Valor médio e desvio padrão. Significado do desvio padrão. Intervalo de confiança Grau de confiança Justificações: - da Média como a melhor estimativa - do Desvio Padrão como a melhor estimativa para a Incerteza associada a cada medida - da adição dos quadrados das incertezas - da fórmula geral de propagação de erros - do Desvio Padrão da Média como a melhor estimativa da incerteza na Média

2
Distribuição Normal Nem todas as distribuições limite têm a forma de sino simétrico que vimos anteriormente. Contudo, muitas medidas têm como distribuição limite a curva f(x) simétrica apresentada e se as medidas estão sujeitas a erros aleatórios pequenos e a desprezável erro sistemático, os valores medidos serão distribuídos de acordo com a curva referida, estando ela centrada no verdadeiro valor de x. Vamos admitir que o verdadeiro valor de uma grandeza existe (idealização), definindo-o como aquela quantidade da qual nos aproximamos cada vez mais, à medida que o número de medidas e o cuidado na sua realização crescem. Vamos designar os verdadeiros valores das grandezas x, y, z, etc. por X, Y, Z, etc.
 simétrica. apresentada e se as medidas estão sujeitas a erros aleatórios pequenos e a. desprezável erro sistemático, os valores medidos serão distribuídos de acordo. com a curva referida, estando ela centrada no verdadeiro valor de x. Vamos admitir que o verdadeiro valor de uma grandeza existe (idealização), definindo-o como aquela quantidade da qual nos aproximamos cada vez mais, à medida que o número de medidas e o cuidado na sua realização crescem. Vamos designar os verdadeiros valores. das grandezas x, y, z, etc. por X, Y, Z, etc.")
3
A função matemática que descreve a função simétrica em forma de sino
é designada por Distribuição Normal ou Função Gaussiana e tem como componente fundamental: onde s é um parâmetro fixo que será designado simplesmente por largura. Quando x = 0 a exponencial é igual a 1. É simétrica em torno de x = 0, pois dá os mesmos resultados para x e –x. À medida que x se afasta de zero, a exponencial decresce tendendo para zero. A forma em sino mais alargada e achatada ou mais estreita e alta está relacionada com o valor do parâmetro largura, maior ou menor, respectivamente. Para se obter uma Gaussiana centrada num valor x = X diferente de zero, basta substituir, na exponencial x por (x-X).
.")
4
Para obtermos a forma final da Função Gaussiana temos de a normalizar.
A função f(x) deve satisfazer: Vamos partir da função O factor A não muda a forma nem altera a posição do máximo em x = X. Vamos determiná-lo de modo a que f(x) fique normalizada: Simplifiquemos através das seguintes mudanças de variáveis: 1º) x – X = y (logo, dx = dy) 2º) y/s = z (logo dy = sdz)
 deve satisfazer: Vamos partir da função. O factor A não muda a forma nem altera a posição do máximo em x = X. Vamos determiná-lo de modo a que f(x) fique normalizada: Simplifiquemos através das seguintes mudanças de variáveis: 1º) x – X = y (logo, dx = dy) 2º) y/s = z (logo dy = sdz)")
5
Prova-se que o integral tem a seguinte solução:
Verifica-se assim que A fórmula final da Distribuição de Normal ou de Gauss é então: Centro da distribuição – é o ponto relativamente ao qual a distribuição é simétrica Largura da distribuição

6
Largura da distribuição Normal
A largura de uma distribuição Gaussiana, s, corresponde aos dois pontos de inflexão onde a curvatura muda de sinal e, portanto, a 2ª derivada é zero. Um parâmetro alternativo com uma interpretação geométrica simples e muito frequentemente usado é a largura a meia altura (FWHM - Full Width at Half Maximum). Este parâmetro corresponde à distância entre os dois pontos x onde GX,s(x) tem metade do seu valor máximo. Pode provar-se que FWHM =
. Este parâmetro. corresponde à distância entre os dois pontos x onde GX,s(x) tem metade do seu valor máximo. Pode provar-se que FWHM =")
7
Valor Médio e Desvio Padrão
Descreve a distribuição limite dos resultados das medidas da quantidade x, cujo verdadeiro valor é X, se a medida for apenas sujeita a erros aleatórios. Repare-se no efeito do parâmetro s, do denominador do expoente: um s mais pequeno assegura automaticamente uma distribuição mais estreita com um valor mais alto no centro, uma vez que a área total deve ser sempre igual a 1. Valor Médio e Desvio Padrão Vimos que o conhecimento da distribuição limite de uma medida nos permitia determinar o valor médio esperado, depois de inúmeras medidas: Tendo agora em conta a distribuição Gaussiana, f(x) = GX,s(x), a eq. anterior vem:
 = GX,s(x), a eq. anterior vem:")
8
Fazendo a mudança de variáveis y = x – X (donde dx = dy e x = y + X), podemos
dividir o integral em dois termos: É o integral de normalização da função e. como vimos, vale É zero, porque a contribuição de qualquer ponto y é exactamente cancelada pela do ponto -y O resultado final é, como esperado, , depois de um nº infinito de medidas.

9
Ou seja, se as medidas estão distribuídas de acordo com uma função
Gaussiana, então, depois de um nº infinito de medidas, o valor médio corresponde ao verdadeiro valor da grandeza, no qual a função Gaussiana está centrada. A utilidade prática deste resultado é que se fizermos um nº grande de medidas (embora não infinito), o valor médio obtido estará perto de X. Por outro lado, para o desvio padrão (variância) e de acordo com a equação geral obtida para a função limite, vem: Substituindo o valor médio por X e fazendo a mudança de variáveis y = x – X e y/s=z e integrando por partes, como anteriormente, obtém-se: (depois de um nº infinito de medidas) Ou seja, o parâmetro s, largura da distribuição Gaussiana, é exactamente o desvio padrão que obteríamos se realizássemos um nº infinito de medidas. s é, por isso, também designado por Desvio Padrão da distribuição Gaussiana.
, o valor médio obtido estará perto de X. Por outro lado, para o desvio padrão (variância) e de acordo com a equação geral. obtida para a função limite, vem: Substituindo o valor médio por X e fazendo a mudança de variáveis y = x – X e y/s=z. e integrando por partes, como anteriormente, obtém-se: (depois de um nº infinito de medidas) Ou seja, o parâmetro s, largura da distribuição Gaussiana, é exactamente o desvio. padrão que obteríamos se realizássemos um nº infinito de medidas. s é, por isso, também designado por Desvio Padrão da distribuição Gaussiana.")
10
Significado do desvio padrão. Intervalo de confiança
A distribuição limite f(x) para medidas de uma quantidade x, dá-nos a probabilidade de obtermos qualquer resultado dos possíveis para x. Especificamente o integral é a probabilidade de uma qualquer medida dar um resultado no intervalo a ≤ x ≤ b. Se a distribuição limite for uma distribuição de Gauss, podemos calcular a probabilidade de uma medida fornecer um resultado que caia, por exemplo, dentro do intervalo correspondente a um desvio padrão s, do verdadeiro valor X. Essa probabilidade é
 para medidas de uma quantidade x, dá-nos a. probabilidade de obtermos qualquer resultado dos possíveis para x. Especificamente o integral. é a probabilidade de uma qualquer medida dar um resultado no intervalo. a ≤ x ≤ b. Se a distribuição limite for uma distribuição de Gauss, podemos calcular a. probabilidade de uma medida fornecer um resultado que caia, por exemplo, dentro. do intervalo correspondente a um desvio padrão s, do verdadeiro valor X. Essa probabilidade é.")
11
O integral pode ser simplificado através da substituição (x-X)/s = z, com a qual
dx = sdz e os limites de integração passam a z = ±1. Vem então: A probabilidade de encontrarmos uma resposta dentro do intervalo 2s, 1.5s ou qualquer outro valor ts, para qualquer valor t positivo em torno de X, é também possível. Essa probabilidade é dada pela área da figura, que corresponde a: Este integral não pode ser avaliado analiticamente mas é facilmente calculado num computador. É muitas vezes designado por função erro ou integral normal do erro, erf(t).
.")
12
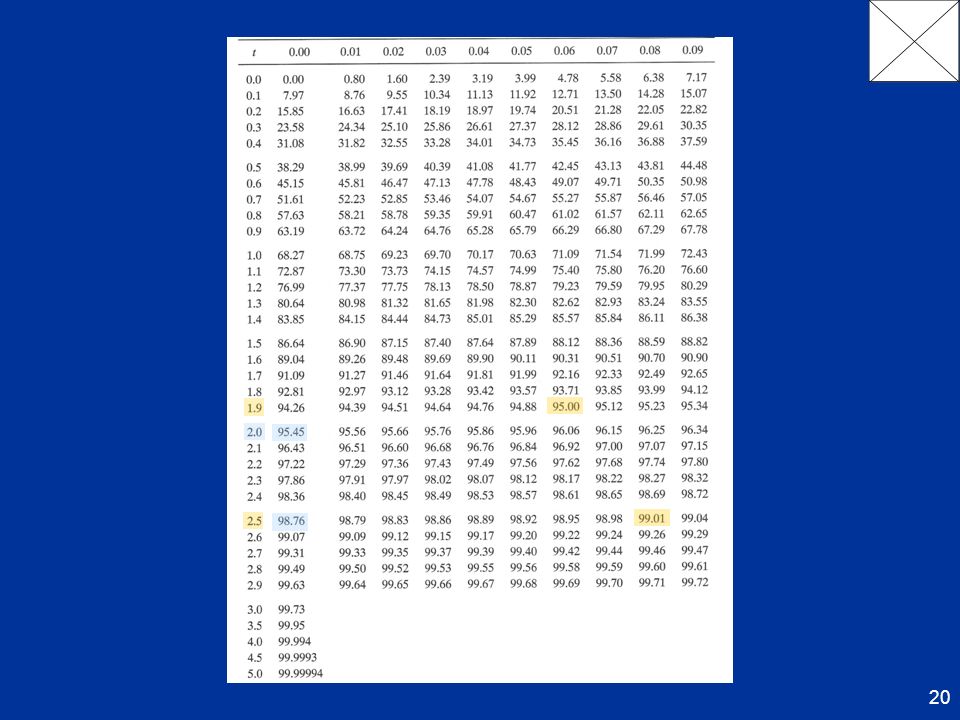
A figura e a tabela representam o integral em função de t, mostrando alguns valores:
A probabilidade de uma medida cair dentro de um intervalo s em volta do verdadeiro valor é 68%. Assim, se tomarmos um desvio padrão como a incerteza na nossa medida estaremos 68% seguros da nossa resposta.

13
A probabilidade cresce rapidamente
para 100%. A probabilidade de que uma medida caia em 2s é de 95.4%, em 3s é de 99.7%. Visto de outra maneira: a probabilidade de que o resultado de uma medida caia fora de s é apreciável (32%), mas é muito menor se se tratar de 2s (4.6%), etc. Por vezes, em vez de s, usa-se um outro parâmetro de avaliação: o erro provável (PE). O erro provável define-se como o valor para o qual há 50% de probabilidade de uma medida cair no intervalo [X-PE, X+PE]. A figura mostra que, para distribuições normais, o erro provável, PE = 0.67s.
, mas é muito. menor se se tratar de 2s (4.6%), etc. Por vezes, em vez de s, usa-se um outro parâmetro de avaliação: o erro provável (PE). O erro provável define-se como o valor para o qual há 50% de probabilidade. de uma medida cair no intervalo [X-PE, X+PE]. A figura mostra que, para distribuições normais, o erro provável, PE = 0.67s.")
14
Grau de confiança No VALOR MÉDIO Medirmos a quantidade x várias vezes.
Sabemos que a média é a melhor estimativa de x - Se distribuição limite de x é Gaussiana, o desvio padrão é uma estimativa da largura da Gaussiana e permite-nos saber que se realizarmos uma medida de x temos 68% de probabilidade dessa medida se encontrar no intervalo Por outro lado, sabemos que o desvio padrão da média, , é uma boa estimativa da incerteza associada a , o que nos permite escrever: - Então, tal como acontece com o desvio padrão, tal significa que o valor médio de um novo conjunto de medidas que realizemos nas mesmas condições tem 68% de probabilidade de pertencer ao intervalo xbest ±dx =

15
- Claro que também poderíamos escolher o intervalo 2
- Claro que também poderíamos escolher o intervalo Neste caso, o valor médio de qualquer conjunto de medidas que façamos nas mesmas condições teria 95% de probabilidade de pertencer ao novo intervalo 2) DISCREPÂNCIA ENTRE VALOR MEDIDO E VALOR ESPERADO - Quando comparamos xbest com xesperado (expectativa teórica ou baseada noutro resultado experimental), como decidimos se o acordo ou discrepância entre os dois valores é aceitável? Suponhamos que um estudante mede uma certa quantidade x na forma: (valor de x) = xbest ±dx = e quer compará-la com um valor xesperado.
 DISCREPÂNCIA ENTRE VALOR MEDIDO E VALOR ESPERADO. - Quando comparamos xbest com xesperado (expectativa teórica ou baseada. noutro resultado experimental), como decidimos se o acordo ou discrepância. entre os dois valores é aceitável Suponhamos que um estudante mede uma certa quantidade x na forma: (valor de x) = xbest ±dx = e quer compará-la com um valor xesperado.")
16
Podemos argumentar que se a discrepância for menor (ou apenas
ligeiramente maior) do que s, então o acordo é razoável. O critério é aceitável mas não nos dá uma medida quantitativa sobre quão bom ou mau é o acordo. Na verdade não há limites definidos para a fronteira da “aceitabilidade” de um valor. Por ex., uma discrepância de 1.5s seria ainda aceitável? Vamos admitir que a medida realizada pelo estudante segue uma distribuição Normal: hipótese 1) - está centrada no valor esperado xesp hipótese 2) - a largura da distribuição é igual ao desvio padrão determinado pelo estudante, sx. A hipótese 1) é aquilo que o estudante espera. Ele reduziu os erros sistemáticos a um nível desprezável de modo a que a distribuição estivesse centrada no verdadeiro valor e confia que esse valor é xesp.
 do que s, então o acordo é razoável. O critério é aceitável mas não nos dá uma medida quantitativa sobre quão bom. ou mau é o acordo. Na verdade não há limites definidos para a fronteira da. aceitabilidade de um valor. Por ex., uma discrepância de 1.5s seria ainda aceitável Vamos admitir que a medida realizada pelo estudante segue uma distribuição Normal: hipótese 1) - está centrada no valor esperado xesp. hipótese 2) - a largura da distribuição é igual ao desvio padrão. determinado pelo estudante, sx. A hipótese 1) é aquilo que o estudante espera. Ele reduziu os erros sistemáticos a. um nível desprezável de modo a que a distribuição estivesse centrada no verdadeiro. valor e confia que esse valor é xesp.")
17
A hipótese 2 é uma aproximação porque sx só é uma boa estimativa do
desvio padrão se o nº de medidas nos quais sx se baseia for grande. Para testarmos as hipóteses do aluno, vamos então começar por determinar a discrepância e depois o parâmetro t: o qual correspondente ao nº de desvios padrão pelo qual xbest difere de xesp. A partir da tabela do Integral Normal do Erro, podemos achar a probabilidade (dadas as hipóteses do aluno) de obter uma resposta que difere do xesp por t ou mais desvios padrão. Esta probabilidade é: Prob (fora de tsx) = 1 – Prob (dentro de tsx)
 de obter uma resposta que difere do xesp por t ou mais desvios padrão. Esta probabilidade é: Prob (fora de tsx) = 1 – Prob (dentro de tsx)")
18
Se esta probabilidade for grande, a discrepância é perfeitamente
razoável e o resultado xbest é aceitável. Se a probabilidade for pequena, a discrepância deve ser considerada significativa e é necessário ponderar o que se terá passado na experiência. Por exemplo: = s Prob (fora de ts) = 1 – Prob (dentro de ts) 68% 32 % Com uma probabilidade de 32%, podemos dizer que é bastante provável que haja discrepância entre o valor esperado e obtido e, portanto, considera-se que a discrepância não é significativa. Contudo se = 3s Prob (fora de ts) = 1 – Prob (dentro de ts) 99.7% 0.3 % a probabilidade de uma discrepância de 3s é muito pequena e, portanto, bastante improvável. Ou, dito de outro modo, se a discrepância for de 3s, as hipóteses do estudante estão provavelmente incorrectas.
 = 1 – Prob (dentro de ts) 68% 32 % Com uma probabilidade de 32%, podemos dizer que é bastante provável que. haja discrepância entre o valor esperado e obtido e, portanto, considera-se que a. discrepância não é significativa. Contudo se = 3s. Prob (fora de ts) = 1 – Prob (dentro de ts) 99.7% 0.3 % a probabilidade de uma discrepância de 3s é muito pequena e, portanto, bastante. improvável. Ou, dito de outro modo, se a discrepância for de 3s, as hipóteses do. estudante estão provavelmente incorrectas.")
19
A fronteira entre “aceitabilidade” ou não-aceitabilidade depende do nível abaixo
do qual julgamos a discrepância como “irrazoavelmente improvável”. Esse nível é uma questão a ser decidida pelo experimentador. Alguns consideram que 5% é um bom valor para a “improbabilidade irrazoável”. Se aceitarmos esta escolha, uma discrepância de 2s é inaceitável porque já está abaixo de 5%: Prob (fora de 2s) = 4.6 %. Podemos ver na Tabela seguinte que qualquer discrepância maior do que 1.96s é inaceitável para esta escolha de 5%. Estas discrepâncias designam-se muitas vezes por significativas. De modo análogo, para um nível de 1%, vemos que qualquer discrepância maior do que 2.58s seria inaceitável. Estas discrepâncias designam-se muitas vezes por altamente significativas. Um procedimento seguido por muitos físicos é: se uma discrepância é menor que 2s, o resultado é julgado aceitável; se a discrepância é maior do que 2.5s, o resultado é inaceitável. Se fica entre 2s e 2.5s, o resultado é inconclusivo. Se a experiência é importante, o melhor é repeti-la.
 = 4.6 %. Podemos ver na Tabela seguinte que qualquer discrepância maior do que 1.96s é. inaceitável para esta escolha de 5%. Estas discrepâncias designam-se muitas vezes. por significativas. De modo análogo, para um nível de 1%, vemos que qualquer discrepância maior do. que 2.58s seria inaceitável. Estas discrepâncias designam-se muitas vezes por. altamente significativas. Um procedimento seguido por muitos físicos é: se uma discrepância é menor que 2s, o resultado é julgado aceitável; se a discrepância é maior do que 2.5s, o resultado. é inaceitável. Se fica entre 2s e 2.5s, o resultado é inconclusivo. Se a experiência. é importante, o melhor é repeti-la.")
21
como a Melhor Estimativa
Justificação da Média como a Melhor Estimativa Se f(x) fosse conhecida → poderíamos calcular a média e o desvio padrão s obtidos após um nº infinito de medidas e, pelo menos para a distribuição Normal, poderíamos também conhecer o verdadeiro valor X. Infelizmente, nunca conhecemos a distribuição limite pois, na prática, temos sempre um nº finito de valores medidos x1, x2,…, xN O nosso problema é chegarmos à melhor estimativa para X e para s, baseando-nos nos N valores medidos. Se as medidas seguem uma distribuição Normal GX,s(x) e se conhecermos os parâmetros X e s, poderemos calcular as probabilidades de obter os valores x1, x2,…, xN que foram de facto obtidos. Assim, a probabilidade de obter um valor perto de x1 num pequeno intervalo dx1 é:
 fosse conhecida → poderíamos calcular a média e o desvio padrão s. obtidos após um nº infinito de medidas e, pelo menos para a distribuição Normal, poderíamos também conhecer o verdadeiro valor X. Infelizmente, nunca conhecemos a distribuição limite pois, na prática, temos. sempre um nº finito de valores medidos. x1, x2,…, xN. O nosso problema é chegarmos à melhor estimativa para X e para s, baseando-nos. nos N valores medidos. Se as medidas seguem uma distribuição Normal GX,s(x) e se conhecermos os. parâmetros X e s, poderemos calcular as probabilidades de obter os valores. x1, x2,…, xN que foram de facto obtidos. Assim, a probabilidade de obter um valor. perto de x1 num pequeno intervalo dx1 é:")
22
Na prática não estamos interessados no tamanho do intervalo dx1, nem o factor
tem importância. Assim, podemos abreviar a equação anterior para: e consideraremos, abusivamente, esta eq. como a probabilidade de obter o valor x1. A probabilidade de obter x2 numa segunda medida será então: . E assim sucessivamente até à probabilidade de obter xN:

23
As equações anteriores dão as probabilidades de obter cada um dos valores
x1, x2,…, xN, calculados em termos da distribuição GX,s(x). A probabilidade de observarmos toda a série de N leituras é o produto das probabilidades separadas ou Os números x1, x2,…, xN são os resultados das várias medidas; são, portanto, conhecidos, são fixos. A quantidade é a probabilidade de obter os N resultados, calculada em termos de X e s. O problema é que X e s não são conhecidos! Queremos encontrar as melhores estimativas para X e s baseados nas observações x1, x2,…, xN.
. A probabilidade de observarmos toda a série de N leituras é o produto das. probabilidades separadas. ou. Os números x1, x2,…, xN são os resultados das várias medidas; são, portanto, conhecidos, são fixos. A quantidade é a probabilidade de obter os N resultados, calculada em termos de X e s. O problema é que X e s não são conhecidos! Queremos encontrar as melhores. estimativas para X e s baseados nas observações x1, x2,…, xN.")
24
Como os valores reais de X e s não são conhecidos, podemos imaginar valores
X’ e s’ e, partindo desses valores, calcularmos a probabilidade: Depois podemos imaginar outro par de valores X’’ e s’’ e, se a probabilidade calculada a partir desses valores, , for maior, esses novos valores serão considerados melhores estimativas para X e s. Este procedimento, eventualmente moroso mas plausível, para encontrar as melhores estimativas de X e s é conhecido por Princípio da Máxima Probabilidade e pode ser enunciado da seguinte forma: Dado um conjunto de N resultados de medições de uma grandeza, x1, x2,…, xN, as melhores estimativas para X e s são os valores que tornam máxima a probabilidade de ocorrência conjunta desses resultados.

25
Ora, a probabilidade definida por
é máxima se a soma no expoente for mínima. Ou seja, a melhor estimativa para X é o valor para o qual é mínimo. Para tal, diferenciamos em ordem a X e igualamos a zero: Provamos assim que a melhor estimativa para o verdadeiro valor, X, é a média dos valores medidos.

26
Justificação do Desvio Padrão como a Melhor Estimativa para a
Incerteza associada a cada medida Para procurarmos qual é a melhor estimativa para s, a largura da distribuição limite, diferenciamos a mesma do expoente mas agora em ordem a s e igualamos a derivada a zero. Este procedimento dá o valor de s que maximiza a probabilidade sendo portanto a melhor estimativa para s, obtendo-se:

27
Como o verdadeiro valor X é desconhecido, na prática substituímos X
pela melhor estimativa de X, ou seja, pela média Vem então: Ou seja, a melhor estimativa para a largura s da distribuição limite é o desvio padrão dos N valores observados x1, ..., xN. Uma questão que surge é termos obtido o factor N na definição de s e não o factor (N – 1) que considerámos mais adequado para uma amostras de N medidas . Contudo, notemos: X (valor verdadeiro) e (a nossa melhor estimativa para o verdadeiro valor) são geralmente diferentes . O resultado da definição com é sempre menor (ou, quando muito, igual) , ao resultado da definição com o verdadeiro valor X.
 que considerámos mais adequado para uma amostras de N medidas . Contudo, notemos: X (valor verdadeiro) e (a nossa melhor estimativa para o verdadeiro valor) são geralmente diferentes . O resultado da definição com é sempre menor (ou, quando muito, igual) , ao resultado da definição com o verdadeiro valor X.")
28
Acabámos de ver que esta função é mínima para X = .
Logo, é sempre < Então, ao passarmos de uma definição para a outra, subestimámos a largura s. Ora, pode demonstrar-se que esta imprecisão é corrigida quando se substitui o factor N por (N – 1). Então a melhor estimativa para s é precisamente: Os resultados apresentados neste capítulo dependem do facto de se admitir que as medidas seguem uma distribuição Normal (e sem erros sistemáticos!). Contudo, veremos que mesmo quando a distribuição de medidas não segue uma distribuição Normal, é quase sempre possível tomarmos a distribuição Gaussiana como uma boa aproximação.
. Então a melhor estimativa para s é precisamente: Os resultados apresentados neste capítulo dependem do facto de se admitir que as medidas. seguem uma distribuição Normal (e sem erros sistemáticos!). Contudo, veremos que mesmo. quando a distribuição de medidas não segue uma distribuição Normal, é quase sempre possível. tomarmos a distribuição Gaussiana como uma boa aproximação.")
29
Justificação da adição dos quadrados das incertezas
No capítulo III, afirmou-se que, quando medimos várias quantidades x, y, r,…, z, todas com incertezas aleatórias e independentes, uma grandeza q (x, y, r,…, z) tal que q = x + y – r + … - z, vem afectada por uma incerteza dada por: Se as quantidades x, y, …., z, estiverem sujeitas apenas a incertezas aleatórias, terão uma distribuição Normal ou Gaussiana com larguras sx, sy, …, sz. Quando fizermos uma única medida de qualquer uma destas quantidades (x, por exemplo) diremos que a incerteza que lhe está associada é, precisamente, sx. A pergunta então é: conhecendo as distribuições associadas às medições de x, y, …., z, o que podemos saber sobre a distribuição dos valores de q? Em particular, qual será a largura da distribuição dos valores de q? A resposta a esta questão será apresentada em 3 passos.
 tal que q = x + y – r + … - z, vem afectada por uma incerteza dada por: Se as quantidades x, y, …., z, estiverem sujeitas apenas a incertezas aleatórias, terão. uma distribuição Normal ou Gaussiana com larguras sx, sy, …, sz. Quando. fizermos uma única medida de qualquer uma destas quantidades (x, por exemplo) diremos que a incerteza que lhe está associada é, precisamente, sx. A pergunta então é: conhecendo as distribuições associadas às medições de. x, y, …., z, o que podemos saber sobre a distribuição dos valores de q Em particular, qual será a largura da distribuição dos valores de q A resposta a esta questão será apresentada em 3 passos.")
30
1. Quantidade medida + Constante
Comecemos por considerar que medimos a quantidade x e calculamos a grandeza q = x + A onde A é uma constante e x é uma grandeza cuja distribuição é normal, de largura sx. A probabilidade de obter qualquer valor x dentro de um pequeno intervalo dx é , ou seja, simplificando, é: A probabilidade de obter o valor q = probabilidade de obter o valor x (uma vez que x = q – A)
")
31
Então: Este resultado mostra que os valores de q calculados estão distribuídos segundo uma Gaussiana centrada no valor X+A, com largura sx, como se mostra na figura (b). Ou seja, a incerteza em q é a mesma incerteza associada a x (sx).
. Ou. seja, a incerteza em q é a mesma incerteza associada a x (sx).")
32
2. Quantidade medida x Constante
Consideremos agora a quantidade x medida e o cálculo da grandeza q = Bx onde B é constante. Raciocinando como anteriormente: x = q/B e a probabilidade de obter o valor q µ probabilidade de obter o valor x (uma vez que x = q/B) Então:
 Então:")
33
Ou seja, os valores de q = B/x estão distribuídos segundo uma Gaussiana com centro
em BX e largura Bsx (figura (b)). A incerteza de q = Bx é igual a Bsx, tal como havia sido indicado no capítulo III (slide 58).
). A incerteza de q = Bx é igual a Bsx, tal. como havia sido indicado no capítulo III (slide 58).")
34
3. Soma de duas quantidades medidas
Consideremos agora que medimos duas quantidades independentes x e y e que calculamos a sua soma x + y. As medidas de x e y traduzem distribuições normais em torno dos seus valores verdadeiros X e Y, com larguras sx e sy, respectivamente. Para simplificar, vamos começar por considerar que os verdadeiros valores de x e y são ambos zero (distribuições centradas em zero). Então:
. Então:")
35
Pretendemos calcular a probabilidade de obter qualquer valor particular
(x + y). Como x e y são grandezas medidas independentemente, a probabilidade de obter qualquer valor x e qualquer valor y é o produto das probabilidades anteriores: Utilizando a relação:
. Como x e y são grandezas medidas independentemente, a probabilidade de. obter qualquer valor x e qualquer valor y é o produto das probabilidades anteriores: Utilizando a relação:")
36
A probabilidade de obter determinados valores x e y, pode então ser vista como a
probabilidade de obter os valores x+y e z. Podemos assim escrever: Estamos interessados na probabilidade de obter o valor (x+y) independentemente do valor de z. Essa probabilidade é obtida somando (integrando) para todos os valores possíveis de z, ou seja, O factor , integrado entre ± infinito dá Assim
 independentemente do. valor de z. Essa probabilidade é obtida somando (integrando) para todos os valores. possíveis de z, ou seja, O factor , integrado entre ± infinito dá . Assim.")
37
Este resultado mostra que os valores (x + y) seguem uma distribuição Gaussiana com
largura: E se X e Y não forem nulos? Podemos sempre escrever: Pelo resultado obtido no ponto 1 (slide 96), os dois primeiros termos estão centrados em zero, com larguras sx e sy. [(q = x – X; x = q + X → o expoente da exponencial fica (q +X – X)2 = q2, ou seja, distribuição centrada em zero.] Assim, a soma dos dois primeiros termos segue uma distribuição Gaussiana de largura O 3º termo é um nº fixo (A = X + Y). Portanto, também pelo resultado do ponto 1, esse termo apenas desloca o centro da distribuição para (X + Y), mas não altera a sua largura.
, os dois primeiros termos estão centrados. em zero, com larguras sx e sy. [(q = x – X; x = q + X → o expoente da exponencial fica. (q +X – X)2 = q2, ou seja, distribuição centrada em zero.] Assim, a soma dos dois primeiros termos segue uma distribuição Gaussiana de. largura. O 3º termo é um nº fixo (A = X + Y). Portanto, também pelo resultado do ponto 1, esse. termo apenas desloca o centro da distribuição para (X + Y), mas não altera a sua. largura.")
38
Então os valores (x + y) seguem uma distribuição normal centrada em (X + Y) com
largura (incerteza) dada por como pretendíamos mostrar.
 dada por. como pretendíamos mostrar.")
39
Justificação da fórmula geral de propagação de erros
Se q(x, y, …, z) Suponhamos que medimos duas quantidades independentes x e y, cujos valores observados seguem uma distribuição normal, e que queremos calcular q(x,y). As larguras sx e sy (incertezas em x e y) devem, como sempre, ser pequenas. Isto significa que apenas lidamos com valores de x e de y perto de X e de Y, respectivamente. Podemos então escrever (como em 3.1, slide 61): Esta aproximação é boa porque os únicos valores de x e y que obtemos com frequência significativa estão perto de X e Y. As duas derivadas parciais são avaliadas nos pontos X e Y e são, portanto, números fixos.
 Suponhamos que medimos duas quantidades independentes x e y, cujos valores. observados seguem uma distribuição normal, e que queremos calcular q(x,y). As larguras sx e sy (incertezas em x e y) devem, como sempre, ser pequenas. Isto. significa que apenas lidamos com valores de x e de y perto de X e de Y, respectivamente. Podemos então escrever (como em 3.1, slide 61): Esta aproximação é boa porque os únicos valores de x e y que obtemos com. frequência significativa estão perto de X e Y. As duas derivadas parciais são avaliadas. nos pontos X e Y e são, portanto, números fixos.")
40
q(x,y) é então a soma de 3 termos:
1º termo – temos q(X,Y) que é um nº fixo e, portanto, apenas desloca o centro da distribuição dos valores calculados; 2º termo – temos , que é um nº fixo, multiplicado por (x-X) que, como acabámos de ver, corresponde a uma distribuição centrada em zero e de largura sx; portanto, os valores do 2º termo seguem uma distribuição centrada em zero (passo 2 do ponto anterior) e com largura 3º termo – temos , que é um nº fixo, multiplicado por (y-Y) que corresponde a uma distribuição centrada em zero e com largura sy; portanto, os valores do 3º termo seguem uma distribuição centrada em zero e com largura
 que é um nº fixo e, portanto, apenas desloca o centro da. distribuição dos valores calculados; 2º termo – temos , que é um nº fixo, multiplicado por (x-X) que, como. acabámos de ver, corresponde a uma distribuição centrada em zero. e de largura sx; portanto, os valores do 2º termo seguem uma. distribuição centrada em zero (passo 2 do ponto anterior) e com largura. 3º termo – temos , que é um nº fixo, multiplicado por (y-Y) que corresponde. a uma distribuição centrada em zero e com largura sy; portanto, os. valores do 3º termo seguem uma distribuição centrada em zero e com. largura.")
41
Combinando os 3 termos e invocando as conclusões dos passos 1 a 3 do
ponto anterior concluímos que q(x,y) segue uma distribuição normal à volta do verdadeiro valor, q(X,Y), com largura (incerteza) dada por: Se identificarmos as incertezas dx e dy como sx e sy, obtemos precisamente a fórmula apresentada no capítulo III (slide 62). Generalizando, se q(x, y, …, z)
 segue uma distribuição normal à volta do. verdadeiro valor, q(X,Y), com largura (incerteza) dada por: Se identificarmos as incertezas dx e dy como sx e sy, obtemos precisamente a fórmula. apresentada no capítulo III (slide 62). Generalizando, se q(x, y, …, z)")
42
Desvio Padrão da Média Vamos agora provar o resultado do capítulo III:
Suponhamos que as medidas de x seguem uma distribuição normal em volta do verdadeiro valor X, com largura sx. Queremos agora investigar o grau de confiança da própria média dos N resultados obtidos nas medições. Para tal vamos imaginar que repetimos muitas vezes um conjunto de N medidas de x e que em cada uma delas determinamos o valor médio. Qual é a distribuição de valores médios que vamos obter? Em cada conjunto, fazemos N medidas e determinamos: Como o valor médio calculado é uma função simples das quantidades medidas x1, …, xN, podemos determinar a largura da distribuição de através da propagação de erros. O único facto estranho é que todas as medidas x1, …, xN, são medidas da mesma grandeza x e, portanto, têm o mesmo valor verdadeiro X e a mesma incerteza sx.

43
Notemos, em primeiro lugar, que como cada uma das quantidades medidas
x1, … xN, segue uma distribuição normal, o seu valor médio , dado pela fórmula da média, também segue a mesma distribuição. Em 2º lugar, o verdadeiro valor de cada x1,…,xN é X. Assim, o verdadeiro valor da média é dado por: Então, depois de fazermos muitas determinações da média de conjuntos de N medidas, os nossos muitos resultados de estarão distribuídos em torno de X. Resta encontrar a largura da distribuição dos valores De acordo com a fórmula de propagação do erro, essa largura é:

44
Como x1,…xN são tudo medidas da mesma quantidade x, as suas larguras
(incertezas) são todas iguais a sx: As derivadas parciais também são iguais: De onde: (c.q.d.)
 são todas iguais a sx: As derivadas parciais também são iguais: De onde: (c.q.d.)")
45
a incerteza na média, ou seja, o desvio padrão da média.
Portanto, depois de repetirmos muitas vezes um conjunto de N medidas e de calcularmos a média de cada conjunto, os nossos resultados para seguem uma distribuição Normal, estão centrados no verdadeiro valor X e a largura dessa distribuição é Esta largura corresponde a um intervalo de confiança de 68%. Traduz, portanto, a incerteza na média, ou seja, o desvio padrão da média. Se fizermos muitas determinações da média de 10 medidas, obtemos uma distribuição normal centrada em X e de largura Distribuição normal (centrada em X e de incerteza sx) das medidas individuais de x.
 das medidas individuais. de x.")
Apresentações semelhantes












>")






