Carregar apresentação
A apresentação está carregando. Por favor, espere

1
Classificação

2
Classificação: Atribuição a uma classe (rótulo de um atributo categórico). Classifica dados (constrói um modelo) baseado em um conjunto de treinamento previamente rotulado e usa o modelo para classificar novas observações. Previsão (regressão): Modela funções contínuas, previsão de valores desconhecidos ou ausentes. Aplicações Aprovação de crédito Diagnóstico médico etc. Classificação versus Predição (regressão)
 baseado em um conjunto de treinamento previamente rotulado e usa o modelo para classificar novas observações. Previsão (regressão): Modela funções contínuas, previsão de valores desconhecidos ou ausentes. Aplicações Aprovação de crédito Diagnóstico médico etc. Classificação versus Predição (regressão).")
3
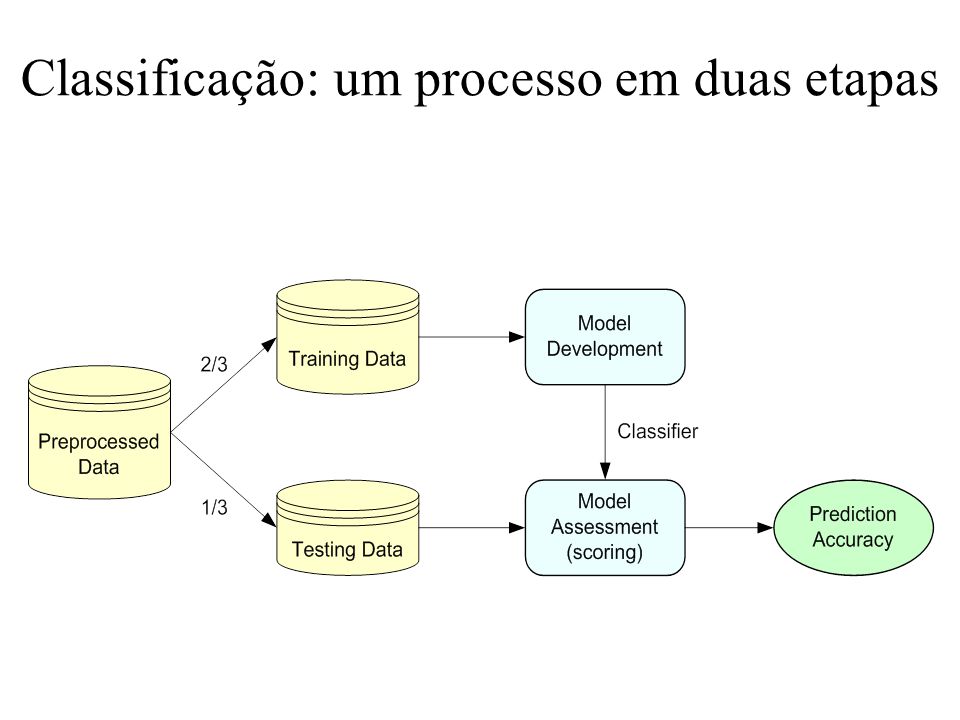
Classificação: um processo em duas etapas Construção do modelo (aprendizagem): descrição de um conjunto de classes a priori Supõe-se que cada observação é oriunda de uma classe predefinida, como indicado pelo atributo rótulo da classe. Conjunto de treinamento: o conjunto de observações usadas para construir o modelo. Exemplos de modelos: regras de classificação, árvores de decisão, fórmulas matemáticas.

4
Classificação: um processo em duas etapas Uso do modelo: para classificar observações desconhecidas Avaliação da precisão do modelo O rótulo conhecido de uma observação é comparado com o resultado do modelo (conjunto de teste). A taxa de erro é a percentagem de observações do conjunto teste que são classificadas incorretamente pelo modelo. O conjunto de teste deve ser independente do conjunto de treinamento, senão poderá ocorrer super ajustamento (over-fitting).
..")
5
Classificação: um processo em duas etapas

7
Processo de classificação (1): construção do modelo Dados de treinamento Algoritmos de Classificação IF categoria = professor OU Anos > 6 THEN Efetivo = sim Classificador (Modelo)
: construção do modelo Dados de treinamento Algoritmos de Classificação IF categoria = professor OU Anos > 6 THEN Efetivo = sim Classificador (Modelo)")
8
Processo de classificação (2): uso do modelo para a previsão Classificador Dados de teste Dados não (Jeferson, Professor, 4) Efetivo?
: uso do modelo para a previsão Classificador Dados de teste Dados não (Jeferson, Professor, 4) Efetivo")
9
Aprendizagem supervisionada vs. Aprendizagem não supervisionada Aprendizagem supervisionada (classificação) Supervisão: os dados de treinamento são rótulados pelas classes as quais pertencem As novas observações são classificadas com base no conjunto de aprendizagem Aprndizagem não supervisionada (clustering) As classes dos dados de treinamento são desconhecidas O objetivo é formar/descobrir classes à partir dos dados
 Supervisão: os dados de treinamento são rótulados pelas classes as quais pertencem As novas observações são classificadas com base no conjunto de aprendizagem Aprndizagem não supervisionada (clustering) As classes dos dados de treinamento são desconhecidas O objetivo é formar/descobrir classes à partir dos dados.")
10
Preparação de dados para classificação Preparação de dados Pré-processamento dos dados para reduzir o ruído e tratar os valores ausentes Seleção de variáveis Remoção dos atributos irrelevantes ou redundantes Transformação dos dados Generalização e/ou normalização dos dados

11
Avaliação dos métodos de classificação Previsão da taxa de erro Velocidade e escalabilidade Tempo para a construção do modelo Tempo para o uso do modelo Robustez Ruido e valores ausentes Escalabilidade Eficiencia em grandes base de dados Interpretabilidade: Compreensão fornecida pelo modelo Adequação das regras Tamanho das árvores de decisão Compacticidade das regras de classificação

12
Classificação via árvores de decisão Árvores de Decisão Estrutura semelhante a uma árvore. Os nós internos representam um teste em um atributo. Os ramos representam o resultado do teste. As folhas representam os rótulos das classes.

13
Classificação via árvores de decisão Duas fases na geração de uma árvore de decisão Construção da árvore No início, todos os exemplos de treinamento estão na raíz. Os exemplos são particionados recursivamente com base nos atributos selecionados. Poda da árvore Identificar e remover ramos que refletem ruidos e aberrações.

14
Conjunto de treinamento

15
Saída: árvore de decisão para compra_computador Idade? overcast Estudante?Crédito? nãosim Passável excelente <=30 >40 não sim Sim 30..40

16
Algoritmo de árvores de decisão Algoritmo básico A árvore é construída recursivamente de cima para baixo no modo dividir para conquistar. No início, todos os exemplos se encontram na raíz Os atributos são discretos (os atributos contínuos são discretizados previamente). Os exemplos são particionados recursivamente com base em atributos selecionados. Os atributos são selecionados heuristicamente ou através de uma critério estatístico (ex., ganho de informação).
. Os exemplos são particionados recursivamente com base em atributos selecionados. Os atributos são selecionados heuristicamente ou através de uma critério estatístico (ex., ganho de informação)..")
17
Algoritmo de árvores de decisão Condições de parada Todas as amostras de um dado nó pertencem a mesma classe. Não há mais atributo disponível para futuras partições – usa-se voto da maioria para classificar a folha. Não há mais exemplos disponíveis.

18
Critério para a seleção de atributos ganho de informação (ID3/C4.5) Supõe-se que todos os atributos são categóricos Pode ser modificado para atributos contínuos Selecione o atributo com o maior ganho de informação Suponha que existem duas classes, P e N Seja S o conjunto de exemplos com p elementos da classe P e n elementos da classe N
 Supõe-se que todos os atributos são categóricos Pode ser modificado para atributos contínuos Selecione o atributo com o maior ganho de informação Suponha que existem duas classes, P e N Seja S o conjunto de exemplos com p elementos da classe P e n elementos da classe N")
19
Ganho de informação (ID3/C4.5) A quantidade de informação necessária para decidir se um exemplo arbitrário de S pertence a P ou a N é definido como
 A quantidade de informação necessária para decidir se um exemplo arbitrário de S pertence a P ou a N é definido como")
20
Suponha que usando-se um atributo A um conjunto S será particionado em {S 1, S 2, …, S v } Se S i contem p i exemplos de P e n i exemplos de N, a entropia, ou a informação esperada necessária para classificar objetos em todas as sub árvores S i é A informação que seria ganha ao ramificar-se por A Ganho de informação (ID3/C4.5)
")
21
Ganho de informação para o atributo raíz Idade? overcast Sim Não Sim Não <=30 >40 Sim 30..40

22
Renda? overcast Sim Não Sim Não alta baixa Sim Não média Ganho de informação para o atributo raíz

23
Estudante? Sim Não Sim Não não sim Ganho de informação para o atributo raíz

24
Crédito? Sim Não Sim Não passável excelente Ganho de informação para o atributo raíz

25
Seleção de atributos pelo calculo do ganho de informação Classe P: computador? = sim Classe N: computador? = não I(p, n) = I(9, 5) = 0.940 Calculo da entropia para idade: E(idade) = (5 / 14)I(2,3) + (4 / 14)I(4,0)+ (5 / 14)I(3,2) = 0.693 Logo Gain(idade) =I(9,5) – E(idade) Gain(idade) = 0.247 Da mesma forma Gain(renda) = 0.029 Gain(estudante) = 0.151 Gain(crédito) = 0.048
 = I(9, 5) = Calculo da entropia para idade: E(idade) = (5 / 14)I(2,3) + (4 / 14)I(4,0)+ (5 / 14)I(3,2) = Logo Gain(idade) =I(9,5) – E(idade) Gain(idade) = Da mesma forma Gain(renda) = Gain(estudante) = Gain(crédito) =")
26
Idade? overcast Estudante? nãosim <=30 >40 Não Sim 30..40 Ganho de informação para o atributo seguinte

27
Idade? overcast Crédito? passávelexcelente <=30 >40 Sim Não Sim Não 30..40 Ganho de informação para o atributo seguinte

28
Idade? overcast Renda? alta média <=30 >40 Não Sim Não 30..40 baixa Sim Ganho de informação para o atributo seguinte

29
Extração de regras de classificação a partir de árvores de decisão Representa o conhecimento na forma de regras IF-THEN Cria-se uma regra para cada caminho ligando a raíz a uma folha Cada par atributo-valor ao longo de um caminho forma uma conjunção A folha fornece a previsão da classe Exemplo IF idade = <=30 AND estudante = não THEN computador? = não IF idade = <=30 AND estudante = sim THEN computador? = sim IF idade = 31…40 THEN computador? = sim IF idade = >40 AND crédito = excelente THEN computador? = sim IF idade = <=30 AND crédito = passável THEN computador = não

30
Overfitting em Classificação A árvore gerada pode super ajustar os dados de treinamento Ramos demais, alguns podem ser o resultado de anomalias devido a ruidos e dados aberrantes Taxa de erro maior para as observações desconhecidas Duas abordagens para evitar o overfitting Pré-Poda: Parar a construção da árvore cedonão dividir um nó se isso resultar em um critério abaixo de um limiar Difícil escolher o limiar apropriado Pos-Poda: Remover ramos de uma árvore completaobter uma sequencia de árvores progressivamente podadas Usar um conjunto de dados diferente dos dados de treinamento para decidir qual é a melhor árvore podada

31
Abordagens para determinar o tamanho final da árvore Conjuntos de treinamento (2/3) e teste (1/3) separados Usar cross validation, ex., 10-fold cross validation Usar todos os dados para treinar mas aplicar um teste estatístico (ex., qui-quadrado) para estimar se a expansão ou a poda de um nó pode ser realizada
 e teste (1/3) separados Usar cross validation, ex., 10-fold cross validation Usar todos os dados para treinar mas aplicar um teste estatístico (ex., qui-quadrado) para estimar se a expansão ou a poda de um nó pode ser realizada")
32
Melhoramentos na árvore de decisão básica Permitir a manipulação de atributos contínuos Definir dinamicamente novos atributos discretos que particionam os atributos contínuos em um conjunto de intervalos Manipular valores ausentes Atribuir o valor mais comum do atributo Atribuir o valor mais provável Construção de atributos Criar novos atributos com base naqueles representados esparsamente

33
O que é previsão Previsão é similar a classificação Primeiro, o modelo é construído Depois, usa-se o modelo para prever valores desconhecidos O mais importante método de previsão é a regressão Regressão linear e múltipla Regressão não linear Previsão é diferente de classificação Classificação diz respeito a previsão do rótulo de uma classe Previsão é apropriada para modelar funções contínuas

Apresentações semelhantes










 Universidade do Minho.>")








