Carregar apresentação
1
Adaptive Resonance Theory Carpenter & Grossberg
AULA09 Adaptive Resonance Theory Carpenter & Grossberg

2
ART Proposto por Carpenter e Grossberg em 1987.
ART1 – classificação de vetores binários ART2 – vetores com valores contínuos

3
ART1 R = reset

4
ART1 Consiste de dois estágios, ou camadas F1 e F2, sendo F1 dividido em duas partes, sendo: F1(a) – entrada F1(b) – interface de processamento e F saída, que fornece a classe correspondente
 – interface de processamento e. F2 - saída, que fornece a classe. correspondente.")
5
notações n – número de componentes no vetor de entradas
m – número máximo de classes bij – pesos bottom-up (da unidade Xi de F1(b) para unidade Yj de F2) tji – pesos top-down (da unidade Yj de F2 para unidade Xi de F1(b)) r - parâmetro de vigilância s - vetor de entrada binária (n-dimensional) x – vetor de ativação para a camada F1(b)
 para unidade Yj de F2) tji – pesos top-down (da unidade Yj de F2 para unidade Xi de F1(b)) r - parâmetro de vigilância. s - vetor de entrada binária (n-dimensional) x – vetor de ativação para a camada F1(b)")
6
descrição Quando um vetor de entrada binário s é apresentado à camada F1(a), os sinais são enviados às unidades X, da camada F1(b). Em seguida a camada F2 computa a soma ponderada das entradas. A unidade de F2 com a maior soma ponderada recebe a ativação (valor 1) e todas as demais unidades continuam desativadas (valor 0). Denotando-se o índice da unidade ativa J, a unidade YJ torna-se o candidato para o aprendizado do padrão de entrada. Para isso, um sinal é enviado de F2 para F1(b), ponderado pelos pesos top-down. As unidades X da camada F1(b) continuam em 1 somente se elas recebem sinais não-zero de F1(a) e F2.
 e todas as demais unidades continuam desativadas (valor 0). Denotando-se o índice da unidade ativa J, a unidade YJ torna-se o candidato para o aprendizado do padrão de entrada. Para isso, um sinal é enviado de F2 para F1(b), ponderado pelos pesos top-down. As unidades X da camada F1(b) continuam em 1 somente se elas recebem sinais não-zero de F1(a) e F2.")
7
A norma do vetor x fornece o número de componentes em que o vetor de peso top-down para a unidade vencedora de F2 (unidade tJ) e o vetor de entrada s sejam ambos iguais a 1. Se a razão de é maior ou igual ao parâmetro de vigilância, os pesos (top down e bottom up) para a unidade vencedora são ajustados. Contudo, se a razão for menor, a unidade vencedora é rejeitada, e uma outra unidade deve ser escolhida. A unidade vencedora é inibida, tal que ela não possa ser escolhida novamente, e as ativações da unidade F1(b) são zeradas. O processo é repetido com a camada de entrada F1(a) enviando os sinais para a camada F1(b) novamente, e F2 recebendo os sinais ponderados pelos pesos bottom up, porém sem a participação da unidade inibida de F2.
 para a unidade vencedora são ajustados. Contudo, se a razão for menor, a unidade vencedora é rejeitada, e uma outra unidade deve ser escolhida. A unidade vencedora é inibida, tal que ela não possa ser escolhida novamente, e as ativações da unidade F1(b) são zeradas. O processo é repetido com a camada de entrada F1(a) enviando os sinais para a camada F1(b) novamente, e F2 recebendo os sinais ponderados pelos pesos bottom up, porém sem a participação da unidade inibida de F2.")
8
O processo continua até que um casamento (match) seja encontrado, ou todas as unidades de F2 sejam inibidas. Se todas as unidades de F2 sejam inibidas, as seguintes ações podem ser tomadas: 1) redução do valor do parâmetro de vigilância, 2) aumento do número de unidades em F2, e 3) desprezar o padrão de entrada. No fim de cada apresentação de um padrão (normalmente, após os pesos serem ajustados), todas as unidades de F2 retornam ao status de inativa (ativação = 0), e disponível para a participação na competição seguinte.
 redução do valor do parâmetro de vigilância, 2) aumento do número de unidades em F2, e. 3) desprezar o padrão de entrada. No fim de cada apresentação de um padrão (normalmente, após os pesos serem ajustados), todas as unidades de F2 retornam ao status de inativa (ativação = 0), e disponível para a participação na competição seguinte.")
9
treinamento Inicialização: 1. parâmetros: 2. pesos:
Computação: enquanto a condição de parada é falsa para cada padrão de treinamento Zerar F2 e introduzir o vetor de entrada s em F1(a) Computar a norma de s: Enviar o sinal de F1(a) par F1(b): Para cada unidade de F2: Enquanto reset = true fazer a) encontrar J tal que em todos os nós j de F2. se então todos os nós são inibidos e esse padrão não pode ser classificado b) recomputar a ativação de x de F1(b): c) computar a norma do vetor x: d) teste do reset: 6. Atualizar os pesos para o nó J: 7. Teste de parada
 Computar a norma de s: Enviar o sinal de F1(a) par F1(b): Para cada unidade de F2: Enquanto reset = true fazer. a) encontrar J tal que em todos os nós j de F2. se então todos os nós são inibidos e esse. padrão não pode ser classificado. b) recomputar a ativação de x de F1(b): c) computar a norma do vetor x: d) teste do reset: 6. Atualizar os pesos para o nó J: 7. Teste de parada.")
10
Exemplos de valores de parâmetros

11
Exemplo: ART1 com baixa vigilância
n = 4 - número de componentes de entrada m = 3 – número máximo de classes a serem formadas r = parâmetro de vigilância L = 2 - parâmetro usado para atualizar os pesos bottom up pesos iniciais bottom up pesos iniciais top down Vetores: (1,1,0,0) (0,0,0,1) (1,0,0,0) e (0,0,1,1) Inicialização: parâmetros L = 2 r = 0.4 pesos iniciais:
 (0,0,0,1) (1,0,0,0) e (0,0,1,1) Inicialização: parâmetros. L = 2. r = 0.4. pesos iniciais:")
12
Computação: primeiro vetor = (1,1,0,0)
F2=(0,0,0) s = (1,1,0,0) Norma de s: Ativação de x: x = (1, 1, 0, 0) Computar as somas em F2: enquanto reset = true a) como todos os nós são iguais, escolher J = 1 b) cálculo da ativação de x: c) norma de x: d) teste de reset: portanto reset = false Atualizar os pesos do nó 1:
 s = (1,1,0,0) Norma de s: Ativação de x: x = (1, 1, 0, 0) Computar as somas em F2: enquanto reset = true. a) como todos os nós são iguais, escolher J = 1. b) cálculo da ativação de x: c) norma de x: d) teste de reset: portanto reset = false. 6. Atualizar os pesos do nó 1:")
13
Computação: segundo vetor = (0,0,0,1)
F2=(0,0,0) s = (0,0,0,1) Norma de s: Ativação de x: x = (0,0,0,1) Computar as somas em F2: enquanto reset = true a) como y2 e y3 são iguais, escolher J = 2 b) cálculo da ativação de x: c) norma de x: d) teste de reset: portanto reset = false Atualizar os pesos do nó 2:
 s = (0,0,0,1) Norma de s: Ativação de x: x = (0,0,0,1) Computar as somas em F2: enquanto reset = true. a) como y2 e y3 são iguais, escolher J = 2. b) cálculo da ativação de x: c) norma de x: d) teste de reset: portanto reset = false. 6. Atualizar os pesos do nó 2:")
14
Computação: terceiro vetor = (1,0,0,0)
F2=(0,0,0) s = (1,0,0,0) Norma de s: Ativação de x: x = (1,0,0,0) Computar as somas em F2: enquanto reset = true a) como y1 tem maior valor, escolher J = 1 b) cálculo da ativação de x: c) norma de x: d) teste de reset: portanto reset = false Atualizar os pesos do nó 1:
 s = (1,0,0,0) Norma de s: Ativação de x: x = (1,0,0,0) Computar as somas em F2: enquanto reset = true. a) como y1 tem maior valor, escolher J = 1. b) cálculo da ativação de x: c) norma de x: d) teste de reset: portanto reset = false. 6. Atualizar os pesos do nó 1:")
15
Computação: quarto vetor = (0,0,1,1)
F2=(0,0,0) s = (0,0,1,1) Norma de s: Ativação de x: x = (0,0,1,1) Computar as somas em F2: enquanto reset = true a) como y2 tem maior valor, escolher J = 2 b) cálculo da ativação de x: c) norma de x: d) teste de reset: portanto reset = false Atualizar os pesos do nó 2: portanto não existe alterações nos pesos Teste de parada – aqui termina uma época. Além disso, não existe nenhuma alteração nos pesos aplicando as entradas novamente.
 s = (0,0,1,1) Norma de s: Ativação de x: x = (0,0,1,1) Computar as somas em F2: enquanto reset = true. a) como y2 tem maior valor, escolher J = 2. b) cálculo da ativação de x: c) norma de x: d) teste de reset: portanto reset = false. 6. Atualizar os pesos do nó 2: portanto não existe alterações nos pesos. 7. Teste de parada – aqui termina uma época. Além disso, não existe nenhuma. alteração nos pesos aplicando as entradas novamente.")
16
Exemplo: ART1, com moderada vigilância
Os mesmos vetores do exemplo anterior são aplicados com parâmetro de vigilância r = 0.7. O treinamento dos vetores (1,1,0,0), (0,0,0,1) e (1,0,0,0) ocorrem da mesma forma, resultando na matriz de pesos: bottom up e top down Contudo o resultado para a aplicação do quarto vetor (0,0,1,1) é diferente.
, (0,0,0,1) e (1,0,0,0) ocorrem da mesma forma, resultando na matriz de pesos: bottom up e top down. Contudo o resultado para a aplicação do quarto vetor (0,0,1,1) é diferente.")
17
Computação: quarto vetor = (0,0,1,1)
F2=(0,0,0) s = (0,0,1,1) Norma de s: Ativação de x: x = (0,0,1,1) Computar as somas em F2: enquanto reset = true a) como y2 tem maior valor, escolher J = 2 b) cálculo da ativação de x: c) norma de x: d) teste de reset: a) como y3 tem maior valor, escolher J = 3 portanto reset = false
 s = (0,0,1,1) Norma de s: Ativação de x: x = (0,0,1,1) Computar as somas em F2: enquanto reset = true. a) como y2 tem maior valor, escolher J = 2. b) cálculo da ativação de x: c) norma de x: d) teste de reset: a) como y3 tem maior valor, escolher J = 3. portanto reset = false.")
18
Computação: quarto vetor = (0,0,1,1) (cont.)
Atualizar os pesos do nó 3: Teste de parada – false Continua com a apresentação das entradas, iniciando o segundo lote.

19
Computação do segundo lote: primeiro vetor = (1,1,0,0)
F2=(0,0,0) s = (1,1,0,0) Norma de s: Ativação de x: x = (1,1,0,0) Computar as somas em F2: enquanto reset = true a) como y1 tem maior valor, escolher J = 1 b) cálculo da ativação de x: c) norma de x: d) teste de reset: Obviamente, o critério de vigilância não será satisfeito para nenhum dos nós de F2. O usuário pode optar por acrescentar mais um nó em F2, considerar o primeiro vetor como não-classificado, ou usar um parâmetro de vigilância menor.
 s = (1,1,0,0) Norma de s: Ativação de x: x = (1,1,0,0) Computar as somas em F2: enquanto reset = true. a) como y1 tem maior valor, escolher J = 1. b) cálculo da ativação de x: c) norma de x: d) teste de reset: Obviamente, o critério de vigilância não será satisfeito para nenhum dos. nós de F2. O usuário pode optar por acrescentar mais um nó em F2, considerar o. primeiro vetor como não-classificado, ou usar um parâmetro de vigilância. menor.")
20
Implementação biológica

21
Para que a rede seja implementada em termos neuronais, apenas com o uso de camadas F1(a), F1(b), F2 e R seria difícil, pois os neurônios devem responder diferentemente em diferentes estágios do processo. Por exemplo, unidades de F1(b) devem estar ativas quando um sinal de entrada de F1(a) estiver ativo e F2 zerado (computação de x do item 3); porém, na computação de x no item 5, uma unidade F1(b) só deve continuar ativa quando ambas as entradas, de F2 e de F1(a), são ativas. Na operação do mecanismo de reset, as unidades de F2 devem ser inibidas sob certas condições, porém, essas unidades de F2 devem estar disponíveis na etapa posterior do treinamento para uma nova entrada. Ambos os problemas apontados acima podem ser resolvidos com a introdução de duas unidades suplementares (gain control unit) G1 e G2, agindo conjuntamente com a unidade R de reset.
 devem estar ativas quando um sinal de entrada de F1(a) estiver ativo e F2 zerado (computação de x do item 3); porém, na computação de x no item 5, uma unidade F1(b) só deve continuar ativa quando ambas as entradas, de F2 e de F1(a), são ativas. Na operação do mecanismo de reset, as unidades de F2 devem ser inibidas sob certas condições, porém, essas unidades de F2 devem estar disponíveis na etapa posterior do treinamento para uma nova entrada. Ambos os problemas apontados acima podem ser resolvidos com a introdução de duas unidades suplementares (gain control unit) G1 e G2, agindo conjuntamente com a unidade R de reset.")
22
Cada unidade de F1(b), como de F2, tem 3 fontes de sinais.
F1(b) recebe sinais de F1(a), de F2 e de G1. F2 recebe sinais de F1(b) , R, e de G2. Essas unidades devem receber dois sinais excitatórios para se tornarem ativos. Como existem 3 fontes de sinais, a regra é chamada de regra dos dois terços. Assim, na computação de x, do item 3, um nó F1(b) deve enviar um sinal aos nós de F2 e R sempre que um vetor de entrada é apresentado e nenhum nó de F2 é ativo. Contudo, após um nó de F2 ser escolhido, é necessário que apenas os nós que recebem sinais ativos de F2 e de F1(a) continuem ativos em F1(b). Isso é resolvido com o uso de G1 e G2. G1 é inibido sempre que a unidade F2 é ativa; e todos os nós de F1(b) recebem um sinal de G1 sempre que nenhuma unidade de F2 é ativa. Similarmente, a unidade G2 controla o disparo das unidades de F2, usando a regra dos dois terços.
 recebe sinais de F1(a), de F2 e de G1. F2 recebe sinais de F1(b) , R, e de G2. Essas unidades devem receber dois sinais excitatórios para se tornarem ativos. Como existem 3 fontes de sinais, a regra é chamada de regra dos dois terços. Assim, na computação de x, do item 3, um nó F1(b) deve enviar um sinal aos nós de F2 e R sempre que um vetor de entrada é apresentado e nenhum nó de F2 é ativo. Contudo, após um nó de F2 ser escolhido, é necessário que apenas os nós que recebem sinais ativos de F2 e de F1(a) continuem ativos em F1(b). Isso é resolvido com o uso de G1 e G2. G1 é inibido sempre que a unidade F2 é ativa; e todos os nós de F1(b) recebem um sinal de G1 sempre que nenhuma unidade de F2 é ativa. Similarmente, a unidade G2 controla o disparo das unidades de F2, usando a regra dos dois terços.")
23
Quando nenhum nó de F2 é ativo, a unidade F1(b) recebe sinal de G1, e nesse caso, as unidades de F1(b) que recebem um sinal ativo de F1(a) será ativo. desinibido F1(b) F1(a) Quando um nó de F2 é ativo, G1 é inibido e as unidades de F1(b) que recebem sinais ativos de F2 e F1(a) são ativos. F1(b) F1(a)
 F1(a) Quando um nó de F2 é ativo, G1 é. inibido e as unidades de F1(b) que. recebem sinais ativos de F2 e F1(a) são ativos. F1(b) F1(a)")
24
Similarmente acontece com F2
Similarmente acontece com F2. A unidade G2 é ativa quando existe um padrão de entrada em F1(a).
.")
25
A unidade R corresponde à vigilância.
Quando alguma unidade de F1(a) estiver ativa, um sinal excitatório é enviado para a unidade R. A intensidade desse sinal depende de quantas unidades de F1(a) estão ativas. Contudo, R também recebe sinais inibitórios das unidades ativas de F1(b). Se uma quantidade suficiente de unidades de F1(b) estiverem ativas, quantidade essa determinada pelo parâmetro de vigilância, a unidade R é inibida do disparo. Se a unidade R disparar, inibe aquela unidade de F2 que estiver ativa. Isso força a camada F2 escolher uma nova unidade vencedora.
 estiver ativa, um sinal excitatório é enviado para a unidade R. A intensidade desse sinal depende de quantas unidades de F1(a) estão ativas. Contudo, R também recebe sinais inibitórios das unidades ativas de F1(b). Se uma quantidade suficiente de unidades de F1(b) estiverem ativas, quantidade essa determinada pelo parâmetro de vigilância, a unidade R é inibida do disparo. Se a unidade R disparar, inibe aquela unidade de F2 que estiver ativa. Isso força a camada F2 escolher uma nova unidade vencedora.")
26
Aprendizado no ART1 No aprendizado rápido assume-se que os pesos atingem o equilíbrio durante a apresentação do vetor de treinamento. Os valores de equilíbrio desses pesos são fáceis de obter para ART1, pois as ativações de F1 não mudam enquanto os pesos mudam. Como somente os pesos da unidade vencedora de F2 (denotada por J) são modificados, as equações diferenciais que definem as mudanças nos pesos são apenas para tJi e biJ. O vetor x contem as ativações das unidades de F1(b) após o teste pelo reset. Portanto, xi é 1 se a unidade Xi recebe uma entrada não zero de si e um sinal não zero da conexão de F2 com peso tJi; e xi é zero se si ou tJi é zero.
 são modificados, as equações diferenciais que definem as mudanças nos pesos são apenas para tJi e biJ. O vetor x contem as ativações das unidades de F1(b) após o teste pelo reset. Portanto, xi é 1 se a unidade Xi recebe uma entrada não zero de si e um sinal não zero da conexão de F2 com peso tJi; e xi é zero se si ou tJi é zero.")
27
A equação diferencial para os pesos top down (da unidade J vencedora de F2) é dada por:
Segundo Carpenter e Grossberg (1987) é feita uma simples escolha: A equação diferencial fica: Para o aprendizado rápido Portanto
 é feita uma simples escolha: A equação diferencial fica: Para o aprendizado rápido. Portanto.")
28
A equação dos pesos bottom up (para a unidade J, vencedora de F2) tem essencialmente a mesma forma da anterior: contudo para que a rede possa responder a diferenças nos padrões, é importante para o equilíbrio dos pesos bottom up, serem inversamente proporcionais à norma das ativações de F1(b). Isso pode ser obtido fazendo: com portanto
. Isso pode ser obtido fazendo: com. portanto.")
29
É conveniente considerar separadamente os casos em que a unidade Xi de F1 é inativa e quando é ativa: 1) inativa pois todas as unidades ativas são inclusas no somatório. A equação diferencial fica: Para obter pesos equilibrados a derivada é igual a zero, portanto:
 inativa. pois todas as unidades ativas são inclusas no somatório. A equação. diferencial fica: Para obter pesos equilibrados. a derivada é igual a zero, portanto:")
30
2) ativa pois a unidade Xi não está inclusa no somatório. A equação diferencial fica Para a obtenção de pesos equilibrados portanto A fórmula para os pesos bottom up em ambos os caso pode ser expressa por

31
Pesos iniciais Os pesos iniciais de top down devem ser escolhidos, tais que, quando um nó não comprometido ( uma unidade de F2 que ainda não aprendeu nenhum padrão) for escolhido como vencedor, o mecanismo de reset não o rejeite. Por exemplo: todos os pesos top down inicializados com 1. Os pesos bottom up devem ser menores ou iguais ao valor de equilíbrio caso contrário, durante o treinamento, um vetor pode escolher um novo nó não comprometido. Pesos iniciais bottom up grandes favorecem a criação de novos nós ao invés de tentar colocar um padrão sobre uma unidade previamente treinada.
 for escolhido como vencedor, o mecanismo de reset não o rejeite. Por exemplo: todos os pesos top down inicializados com 1. Os pesos bottom up devem ser menores ou iguais ao valor de equilíbrio. caso contrário, durante o treinamento, um vetor pode escolher um novo nó. não comprometido. Pesos iniciais bottom up grandes favorecem a criação de novos nós ao invés. de tentar colocar um padrão sobre uma unidade previamente treinada.")
32
ART2 ART2 foi projetada para processar vetores de entrada de valores contínuos. As diferenças entre ART1 e ART2 refletem nas modificações necessárias para acomodar os padrões com componentes de valores contínuos. O campo F1 de ART2 inclui uma combinação de normalização e supressão de ruído, além da necessidade da comparação de sinais top down e bottom up no mecanismo de reset. Existem dois tipos de entradas que podem ser usadas no ART2. - o primeiro seria chamado de sinais binários ruidosos - o segundo seria de sinais com valores que sejam verdadeiramente contínuos.

33
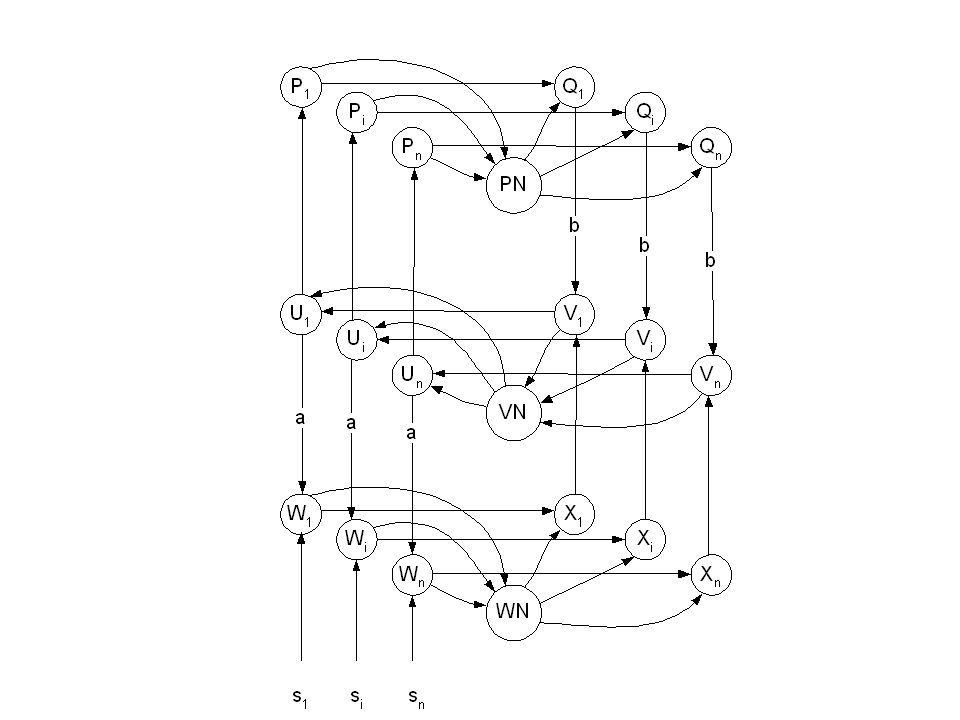
Arquitetura típica ART2 Detalhe de normalização usando a unidade N normalização

35
A camada F1 consiste de 6 tipos de unidades (W,X,U,V,P e Q).
Existem n unidades em cada um desses tipos, sendo n a dimensão do padrão de entrada. Unidades suplementares são usadas para computar a norma dos vetores W, V e P. Por exemplo, a unidade WN computa a norma do vetor de W e envia o sinal inibitório para cada uma das unidades de X. Cada unidade de X recebe também os sinais excitatórios correspondentes de W. Cada unidade de X é conectada a cada unidade correspondente de V e cada unidade de Q também é conectada a V.

36
A ativação da unidade vencedora de F2 é d onde 0<d<1.
O aprendizado ocorre somente se o vetor de peso top down para a unidade vencedora é suficientemente similar ao vetor de entrada. As unidades de U realizam um papel similar à fase de entrada da camada F1(a) no ART1. Contudo, algum processamento no vetor de entrada é necessário devido a variação das magnitudes do vetores de entrada reais. ART2 trata pequenos componentes como ruído e não distingue padrões que apenas estão em escalas diferentes. As unidades P fazem o papel da unidade F1(b) no ART1. As conexões entre W e U e entre Q e V tem pesos fixos a e b , respectivamente.
 no ART1. Contudo, algum processamento no vetor de entrada é necessário devido a variação das magnitudes do vetores de entrada reais. ART2 trata pequenos componentes como ruído e não distingue padrões que apenas estão em escalas diferentes. As unidades P fazem o papel da unidade F1(b) no ART1. As conexões entre W e U e entre Q e V tem pesos fixos a e b , respectivamente.")
37
algoritmo O passo inicial do treinamento consiste na apresentação do padrão de entrada. O sinal de entrada s = (s1,...,sn) continuo é apresentado enquanto todas as ações relativas sejam realizadas. No início todas as ativações devem ser zeradas. O ciclo de computação, pode ser considerado como sendo iniciado na ativação da unidade Ui. Em seguida, um sinal é enviado da unidade Ui para Wi e Pi. As ativações de Wi e Pi são computadas. As unidades W somam os sinais recebidos de Ui e da entrada si. Pi soma o sinal que recebe de Ui e o sinal top down que recebe de uma unidade ativa de F2. As ativações de Xi e Qi são versões normalizadas de sinais de Wi e Pi, respectivamente. Uma função de ativação é aplicada antes do envio de sinal para Vi. Vi soma os sinais que recebe concorrentemente de Xi e Qi, completando um ciclo de atualização da camada F1.
 continuo é apresentado enquanto todas as ações relativas sejam realizadas. No início todas as ativações devem ser zeradas. O ciclo de computação, pode ser considerado como sendo iniciado na ativação da unidade Ui. Em seguida, um sinal é enviado da unidade Ui para Wi e Pi. As ativações de Wi e Pi são computadas. As unidades W somam os sinais recebidos de Ui e da entrada si. Pi soma o sinal que recebe de Ui e o sinal top down que recebe de uma unidade ativa de F2. As ativações de Xi e Qi são versões normalizadas de sinais de Wi e Pi, respectivamente. Uma função de ativação é aplicada antes do envio de sinal para Vi. Vi soma os sinais que recebe concorrentemente de Xi e Qi, completando um ciclo de atualização da camada F1.")
38
É usada para a supressão de ruído a função de ativação
A rede é estável quando uma unidade vencedora de F2 é aceita e não ocorre mais nenhum reset. Após as ativações de F1 atingirem o equilibrio, as unidades de P enviam os sinais para a camada F2, onde uma competição winner-take-all ocorre e escolhe um candidato para a classe do padrão de entrada. As unidades Ui e Pi também enviam sinais para a unidade Ri. O mecanismo de reset necessita verificar a condição quando Pi recebe um sinal top down. Após as condições para o reset forem verificadas, a classe vencedora pode ser rejeitada ou aceita. Se for rejeitada será inibida e uma nova unidade vencedora deve ser escolhida. Esse processo continua até que se encontre uma classe sem rejeição, ocorrendo o ajuste dos pesos para o aprendizado.

39
No aprendizado lento, ocorre somente uma iteração das equações de atualização de pesos, para cada mudança do padrão de entrada. É requerido um grande número de apresentações de cada padrão de entrada, mas relativamente pouca computação é feita por apresentação. Por conveniência, essas apresentações repetitivas são tratadas como épocas no algoritmo seguinte. Contudo , não existe necessidade de que os padrões sejam apresentados na mesma ordem ou exatamente os mesmos padrões sejam apresentados em cada ciclo. No aprendizado rápido, a atualização dos pesos continua até que os pesos atinjam um equilibrio em cada mudança do padrão de entrada. Apenas poucas épocas são necessárias, mas um grande número de iterações através da atualização de pesos do algoritmo deve ser realizado a cada mudança do padrão de entrada. No aprendizado rápido, a definição das classes estabiliza, mas os pesos são alterados para cada padrão apresentado.

40
Cálculos Os seguintes cálculos são repetidos em vários passos do algoritmo e será referido como atualização de ativações de F1. A unidade J é a vencedora de F2, após competição. Se nenhuma unidade for vencedora, d será zero para todas as unidades. Nota-se que os cálculos para wi e pi podem ser feitas em paralelo, assim como para xi e qi. As atualizações de ativações de F1 são:

41
algoritmo Inicialização dos parâmetros:
Realizar os passos seguintes para um número especificado de épocas: para cada vetor de entrada s 1. atualizar as ativações de F1: atualizar as ativações de F1 novamente:

42
2. Computar as unidades de F2:
3. Enquanto reset= true, fazer: a) achar unidade YJ de F2 com o maior sinal. (define-se J tal que ) b) teste do reset:
 achar unidade YJ de F2 com o maior sinal. (define-se J tal que ) b) teste do reset:")
43
4. realizar um número especificado de iterações de aprendizado
a) atualizar pesos para a unidade vencedora J: b) Atualizar as ativações de F1: c) Teste da condição de parada da atualizações 5. Teste da condição de parada para o número de épocas
 atualizar pesos para a unidade vencedora J: b) Atualizar as ativações de F1: c) Teste da condição de parada da atualizações. 5. Teste da condição de parada para o número de épocas.")
44
No algoritmo apresentado as seguintes considerações foram feitas:
reset não ocorre durante a ressonância (passo 4) uma nova unidade vencedora não pode ser escolhida durante a ressonância Tipicamente em aprendizado lento, o número de iterações de aprendizado é igual a 1, e o passo 4, item b, pode ser omitido Em aprendizado rápido, para o primeiro padrão aprendido para uma classe, os pesos de equilibrio serão:
 uma nova unidade vencedora não pode ser escolhida durante a ressonância. Tipicamente em aprendizado lento, o número de iterações de aprendizado é igual a 1, e o passo 4, item b, pode ser omitido. Em aprendizado rápido, para o primeiro padrão aprendido para uma classe, os pesos de equilibrio serão:")
45
Outras condições de parada são:
Repetir o passo 4 até que os pesos mudam abaixo de uma certa tolerância especificada. Para aprendizado lento, repetir o número de épocas até que a mudança nos pesos estejam abaixo de certa tolerância especificada. Para aprendizado rápido, repetir o número de épocas até que a definição das classes em F2 não muda de uma época para outra. Os passos 1 a 4 constituem uma mudança no padrão de entrada (uma apresentação). Seria conveniente referir-se a esses passos como uma época.
. Seria conveniente referir-se a esses passos como uma época.")
46
escolhas n – número de unidades de entrada (camada F1)
m – número de unidades de classe (camada F2) a,b – pesos fixos da camada F1, sendo valores típicos a = 10 e b = 10. Fazer a = 0 e b = 0 produz instabilidade. c – peso fixo usado no teste do reset, sendo um valor típico c = 0.1 Um pequeno valor de c dá uma grande intervalo do parâmetro de vigilância. d – ativação da unidade vencedora de F2. Um valor típico é d=0.9. Nota-se que c e d devem ser escolhidos satisfazendo a inequação e – um pequeno parâmetro introduzido para prevenir a divisão por zero quando a norma de um vetor é zero.
 a,b – pesos fixos da camada F1, sendo valores típicos a = 10 e b = 10. Fazer a = 0 e b = 0 produz instabilidade. c – peso fixo usado no teste do reset, sendo um valor típico c = 0.1. Um pequeno valor de c dá uma grande intervalo do parâmetro de vigilância. d – ativação da unidade vencedora de F2. Um valor típico é d=0.9. Nota-se que c e d devem ser escolhidos satisfazendo a inequação. e – um pequeno parâmetro introduzido para prevenir a divisão por zero quando a norma de um vetor é zero.")
47
supressão de ruído, sendo um valor típico
taxa de aprendizado. Um pequeno valor torna o aprendizado lento. parâmetro de vigilância. Embora teoricamente o valor permitido varie de 0 a 1, somente valores entre 0.7 e 1 tem desempenho útil. Pesos iniciais: os pesos iniciais top down devem ser tais que não ocorra reset para o primeiro padrão de F2. os pesos iniciais bottom up devem ser escolhidos para satisfazer a inequação

48
exemplo Considerando os parâmetros: a = 10, b = 10, c = 0.1, d = 0.9, e = 0 Passo 1. calcular as atualizações de F1: Calcular novamente:

49
parâmetros: a = 10, b = 10, c = 0.1, d = 0.9, e = 0
Passo 2. calcular as unidades de F2: Passo 3. Enquanto reset= true, fazer: a) achar unidade YJ de F2 com o maior sinal. Escolher J=1 b) teste do reset:
 achar unidade YJ de F2 com o maior sinal. Escolher J=1. b) teste do reset:")
50
passo 4. realizar um número especificado de iterações de aprendizado
a) atualizar pesos para a unidade vencedora J: Com a =0.6, d = 0.9 b) Atualizar as ativações de F1:
 atualizar pesos para a unidade vencedora J: Com a =0.6, d = 0.9. b) Atualizar as ativações de F1:")
51
a) atualizar pesos para a unidade vencedora J, novamente:
Com a =0.6, d = 0.9 b) Atualizar as ativações de F1:
 Atualizar as ativações de F1:")
52
O aprendizado continua até que os pesos atinjam o valor de equilíbrio, ou seja, até que a condição de parada o aprendizado seja satisfeita. O valor tJ pode ser obtido imediatamente pelas equações:

53
Aplicações As redes ART tem sido aplicadas em:
Reconhecimento de caracteres; Robótica; Diagnóstico médico; Sensoriamento remoto; e Processamento de vozes.




>")



: Aprendizado>")



>")




>")



