Carregar apresentação
A apresentação está carregando. Por favor, espere

1
Felipe Rodrigues da Silva Embrapa Recursos Genéticos e Biotecnologia
Aula de algoritmo: CAP3 Felipe Rodrigues da Silva Embrapa Recursos Genéticos e Biotecnologia

2
Seqüenciamento

3
Polimerização de DNA ATGCTTCTGGCAGATCTGAACAGTGTTACTGATATTGCTT
TACGAAGACCGTCTAGACTTGTCACAATGACTATAACGAA |||||||||||||||||||||||||||||||||||||||| 5’ 3’

4
Polimerização de DNA G T A C ATGCTTC |||||||
5’ 3’ ||||||| TACGAAGACCGTCTAGACTTGTCACAATGACTATAACGAA 3’ 5’

5
Polimerização de DNA C T T T T C C G A C A T A G T A A T T C C G A G G
ATGCTTC 5’ 3’ G A ||||||||| TACGAAGACCGTCTAGACTTGTCACAATGACTATAACGAA 3’ 5’

6
Polimerização de DNA T C T T C C G T A A A T C G T C C A A T C T G G A
ATGCTTCTG 5’ 3’ G A |||||||||| TACGAAGACCGTCTAGACTTGTCACAATGACTATAACGAA 3’ 5’

7
Polimerização de DNA C T A G C T T T C A T A T T C T G C G C A G T A C
ATGCTTCTGGCAGATCT 5’ 3’ ||||||||||||||||| TACGAAGACCGTCTAGACTTGTCACAATGACTATAACGAA 3’ 5’

8
Polimerização de DNA T T C A T A T A G C C T T C C A G T A C C T C A G
ATGCTTCTGGCAGATCT 5’ 3’ G A ||||||||||||||||| TACGAAGACCGTCTAGACTTGTCACAATGACTATAACGAA 3’ 5’

9
Polimerização de DNA A A T G A G A T T G T A C T G T G C T A T T T A G
ATGCTTCTGGCAGATCTGAACA 5’ 3’ |||||||||||||||||||||||| TACGAAGACCGTCTAGACTTGTCACAATGACTATAACGAA 3’ 5’

10
Polimerização de DNA A C C A T T G A T T G T A G C T A C A T T A G T G
ATGCTTCTGGCAGATCTGAACAGTGTT 5’ 3’ |||||||||||||||||||||||| TACGAAGACCGTCTAGACTTGTCACAATGACTATAACGAA 3’ 5’

11
Polimerização de DNA A T A T G A C C T G A T G T C T A C G G T T G A T
ATGCTTCTGGCAGATCTGAACAGTGTTACTG 5’ 3’ |||||||||||||||||||||||||||||| TACGAAGACCGTCTAGACTTGTCACAATGACTATAACGAA 3’ 5’

12
Polimerização de DNA A T A G A C C G T T C A C T T G G G T T T A T A C
ATGCTTCTGGCAGATCTGAACAGTGTTACTGAT 5’ 3’ T |||||||||||||||||||||||||||||| TACGAAGACCGTCTAGACTTGTCACAATGACTATAACGAA 3’ 5’

13
Polimerização de DNA A G G C C T T A C T T G G T T T T T A T G A T A G
ATGCTTCTGGCAGATCTGAACAGTGTTACTGAT 5’ 3’ |||||||||||||||||||||||||||||| TACGAAGACCGTCTAGACTTGTCACAATGACTATAACGAA 3’ 5’

14
Polimerização de DNA A T G G C T C A C T T T G T G G T T T A T T A G A
ATGCTTCTGGCAGATCTGAACAGTGTTACTGATATTGCTT 5’ 3’ ||||||||||||||||||||||||||||||||||||||| TACGAAGACCGTCTAGACTTGTCACAATGACTATAACGAA 3’ 5’

15
Polimerização de DNA T G G C T C T T A C T T G G G A T T T A T A T A C
ATGCTTCTGGCAGATCTGAACAGTGTTACTGATATTGCTT 5’ 3’ |||||||||||||||||||||||||||||||||||||||| TACGAAGACCGTCTAGACTTGTCACAATGACTATAACGAA 3’ 5’

16
1972 Walter Gilbert e Frederick Sanger seqüenciamento de DNA
olecular biologists by the 1970s had deciphered the genetic code and could spell out the sequence of amino acids in proteins. But inability to easily read off the precise nucleotide sequences of DNA forestalled further advances in molecular genetics and all prospects of genetic engineering. Walter Gilbert (with graduate student Allan M. Maxam) and Frederick Sanger, in 1977, working separately in the United States and England, developed new techniques for rapid DNA sequencing. Sanger and Gilbert each took advantage of recently discovered enzymes and both methods benefited from improvements in gel electrophoresis, a method used for imaging the order of nucleotides. • The Gilbert-Maxam method involved multiplying, dividing, and carefully fragmenting DNA. A stretch of DNA would be multiplied a millionfold in bacteria. Each strand was radioactively labeled at one end. Nested into four groups, chemical reagents were applied to selectively cleave the DNA strand along its bases—adenine (A), guanine (G), cytosine (C) and thymine (T). Carefully dosed, the reagents would break the DNA into a large number of smaller fragments of varying length. In gel electrophoresis, as a function of DNA's negative charge, the strands would separate according to length—revealing, via the terminal points of breakage, the position of each base. • The Sanger method revealed the precise nucleotide sequence of DNA by using "chain-terminating" or "poison" molecules that revealed the positions of the bases. Single-stranded DNA was employed. Complementary copies were synthesized with the help of DNA polymerase. The resulting sample of DNA was divided into four parts. To each part was added one of the four DNA bases, together with a small percentage of the slightly altered chemical analogues. These "dideoxy" versions of the bases, when incorporated into the growing chain, terminate it. This process generated various lengths of the DNA chain that, as in the Gilbert-Maxam method, revealed the sequence of bases through gel electrophoresis. The methods devised by Sanger and Gilbert made it possible to read the nucleotide sequence for entire genes, which run from 1,000 to 30,000 bases long. For discovering these techniques Gilbert and Sanger received the Albert Lasker Medical Research Award in 1979, and shared the Nobel Prize in Chemistry in 1980.
 and Frederick Sanger, in 1977, working separately in the United States and England, developed new techniques for rapid DNA sequencing. Sanger and Gilbert each took advantage of recently discovered enzymes and both methods benefited from improvements in gel electrophoresis, a method used for imaging the order of nucleotides. • The Gilbert-Maxam method involved multiplying, dividing, and carefully fragmenting DNA. A stretch of DNA would be multiplied a millionfold in bacteria. Each strand was radioactively labeled at one end. Nested into four groups, chemical reagents were applied to selectively cleave the DNA strand along its bases—adenine (A), guanine (G), cytosine (C) and thymine (T). Carefully dosed, the reagents would break the DNA into a large number of smaller fragments of varying length. In gel electrophoresis, as a function of DNA s negative charge, the strands would separate according to length—revealing, via the terminal points of breakage, the position of each base. • The Sanger method revealed the precise nucleotide sequence of DNA by using chain-terminating or poison molecules that revealed the positions of the bases. Single-stranded DNA was employed. Complementary copies were synthesized with the help of DNA polymerase. The resulting sample of DNA was divided into four parts. To each part was added one of the four DNA bases, together with a small percentage of the slightly altered chemical analogues. These dideoxy versions of the bases, when incorporated into the growing chain, terminate it. This process generated various lengths of the DNA chain that, as in the Gilbert-Maxam method, revealed the sequence of bases through gel electrophoresis. The methods devised by Sanger and Gilbert made it possible to read the nucleotide sequence for entire genes, which run from 1,000 to 30,000 bases long. For discovering these techniques Gilbert and Sanger received the Albert Lasker Medical Research Award in 1979, and shared the Nobel Prize in Chemistry in")
17
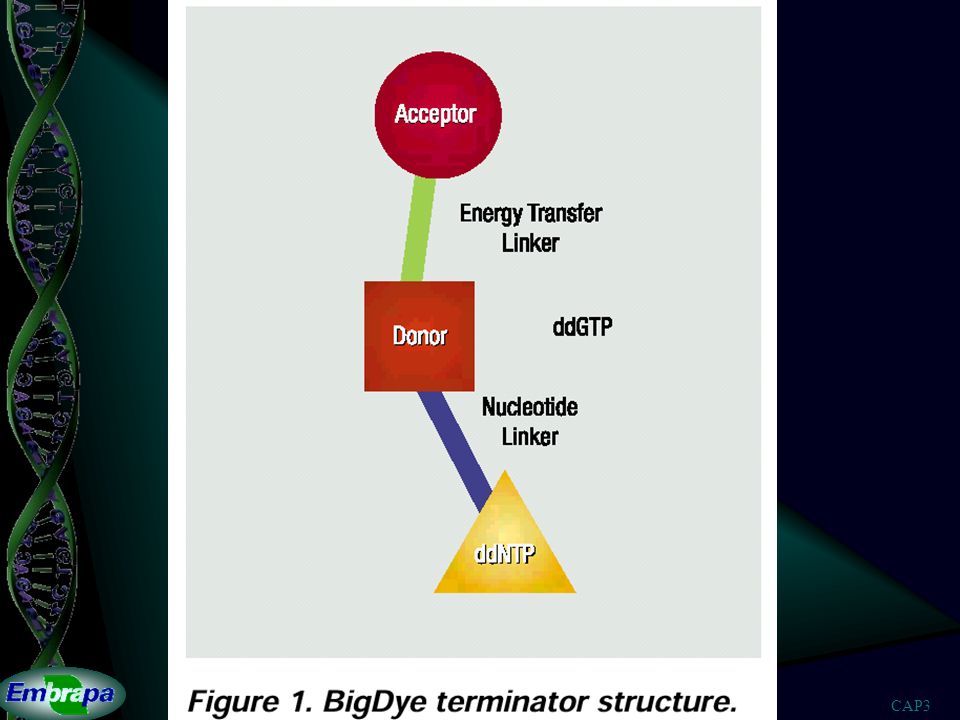
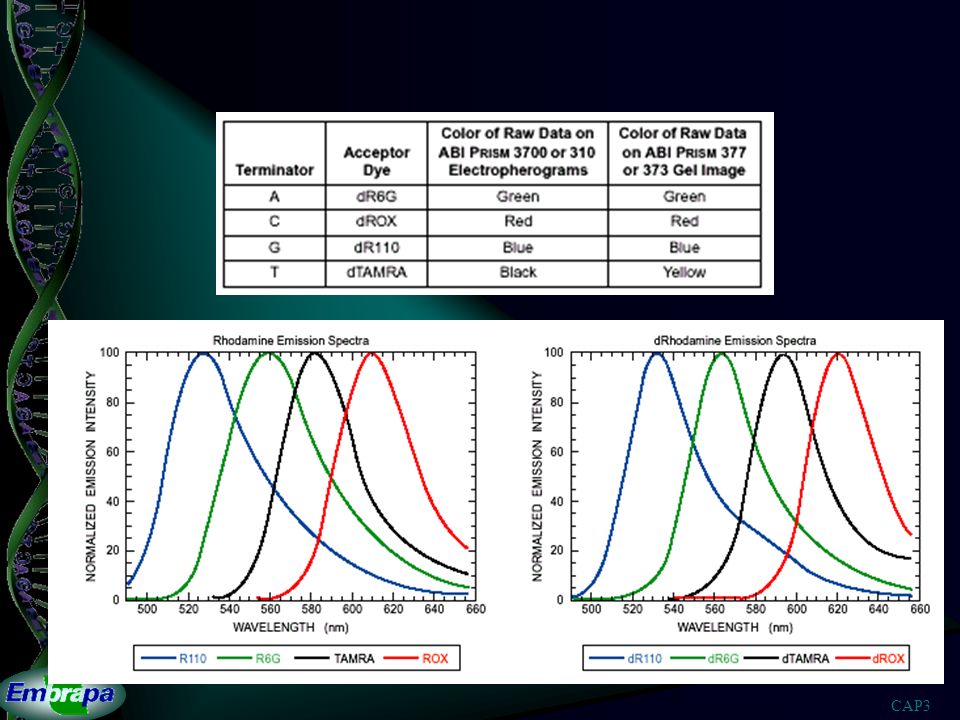
Dideoxinucleotídeo BASE BASE BASE dideoxinucleotídeo deoxinucleotídeo
- - BASE BASE O O - - P P - - P P - - P P - - O O - - CH CH - - - - - - 2 2 O O O O O O O O - - - - - - 3' 3' 2' 2' deoxinucleotídeo O - P CH 2 BASE OH 3' 2' H H H H H dideoxinucleotídeo

18
Seqüenciamento de DNA

19
Polimerização de DNA o dideoxi
T G C ATGCTTC 5’ 3’ ||||||| TACGAAGACCGTCTAGACTTGTCACAATGACTATAACGAA 3’ 5’

20
Polimerização de DNA o dideoxi
C T T T T C C G A C A T A G T A A T T C C G A G G G T T C A G C A C T C G C A ATGCTTC 5’ 3’ G A ||||||||| TACGAAGACCGTCTAGACTTGTCACAATGACTATAACGAA 3’ 5’

21
Polimerização de DNA o dideoxi
T C T T C C G T A A A T C G T C C A A T C T G G A G T T G A C G A C C C A T G ATGCTTCTG 5’ 3’ G A |||||||||| TACGAAGACCGTCTAGACTTGTCACAATGACTATAACGAA 3’ 5’

22
Polimerização de DNA o dideoxi
C T A G C T T T C A T A T T C T G C G C A G T A C G G A C A T G T A G C A G A C C ATGCTTCTGGCAGATCT 5’ 3’ ||||||||||||||||| TACGAAGACCGTCTAGACTTGTCACAATGACTATAACGAA 3’ 5’

23
Polimerização de DNA o dideoxi
T T C A T A T A G C C T T C C A G T A C C T C A G G A T A G T T G C G A C C G ATGCTTCTGGCAGATCT 5’ 3’ G A ||||||||||||||||| TACGAAGACCGTCTAGACTTGTCACAATGACTATAACGAA 3’ 5’

24
Polimerização de DNA o dideoxi
T G A G A T T G T A C T G T G C T A T T T A G C G C C A G T A C C G C C A C C ATGCTTCTGGCAGAT 5’ 3’ ||||||||||||||| TACGAAGACCGTCTAGACTTGTCACAATGACTATAACGAA 3’ 5’

25
Polimerização de DNA o dideoxi
C C A T T G A T T G T A G C T A C A T T A G T G C G G T A G T C G C C A C C A C ATGCTTCTGGCAGAT 5’ 3’ ||||||||||||||| TACGAAGACCGTCTAGACTTGTCACAATGACTATAACGAA 3’ 5’

26
Polimerização de DNA o dideoxi
T A T G A C C T G A T G T C T A C G G T T G A T A C T C G G T A G C C C C A A C ATGCTTCTGGCAGAT 5’ 3’ ||||||||||||||| TACGAAGACCGTCTAGACTTGTCACAATGACTATAACGAA 3’ 5’

27
Seqüenciamento de DNA ATGCTTCTGGCAGATCTGAACAGTGTTACTGAT
5’ 3’ ATGCTTCTGGCAGATCTGAACAGTGT ATGCTTCTGGCAGATCTGAACAGTGTTACTGATATTGCTT ATGCTTCTGGCAGATCTGAACAGTGTTACTGATAT ATGCTTCTGGCAGATCTGAACAGTGTTACT ATGCTTCTGGCAGATCTGAACAGT ATGCTTCTGGCAGATCTGAACAGTGTTACTGATATTGCT ATGCTTCTGGCAGATCTGAACAGTGTTACTGATATT ATGCTTCT ATGCTTCTGGCAGATCT ATGCTTCTGGCAGATCTGAACAGTGTTACTGATATTGCTT ATGCTTCTGGCAGATCTGAACAGTGTT ATGCTTCTGGCAGAT |||||||||||||||||||||||||||||||||||||||| TACGAAGACCGTCTAGACTTGTCACAATGACTATAACGAA 3’ 5’

28
Seqüenciamento de DNA ATGCTTCT ATGCTTCTGGCAGAT ATGCTTCTGGCAGATCT
ATGCTTCTGGCAGATCTGAACAGTGTTACTGAT ATGCTTCTGGCAGATCTGAACAGTGT ATGCTTCTGGCAGATCTGAACAGTGTTACTGATATTGCTT ATGCTTCTGGCAGATCTGAACAGTGTTACTGATAT ATGCTTCTGGCAGATCTGAACAGTGTTACT ATGCTTCTGGCAGATCTGAACAGT ATGCTTCTGGCAGATCTGAACAGTGTTACTGATATTGCT ATGCTTCTGGCAGATCTGAACAGTGTTACTGATATT ATGCTTCT ATGCTTCTGGCAGATCT ATGCTTCTGGCAGATCTGAACAGTGTT |||||||||||||||||||||||||||||||||||||||| TACGAAGACCGTCTAGACTTGTCACAATGACTATAACGAA 3’ 5’

29
Seqüenciamento de DNA ATGCTTCT ATGCTTCTGGCAGAT ATGCTTCTGGCAGATCT
ATGCTTCTGGCAGATCTGAACAGTGTTACTGAT ATGCTTCTGGCAGATCTGAACAGTGT ATGCTTCTGGCAGATCTGAACAGTGTTACTGATATTGCTT ATGCTTCTGGCAGATCTGAACAGTGTTACTGATAT ATGCTTCTGGCAGATCTGAACAGTGTTACT ATGCTTCTGGCAGATCTGAACAGT ATGCTTCTGGCAGATCTGAACAGTGTTACTGATATTGCT ATGCTTCTGGCAGATCTGAACAGTGTTACTGATATT ATGCTTCT ATGCTTCTGGCAGATCT ATGCTTCTGGCAGATCTGAACAGTGTT

30
Seqüenciamento de DNA molde polimerase dNTPs G A T C ddGTPs ddATPs
ddTTPs ddCTPs G A T C

31
Seqüenciamento de DNA G A T C ATGCTTCT ATGCTTCTG ATGCTTCTGG
ATGCTTCTGGC ATGCTTCTGGCA ATGCTTCTGGCAG ATGCTTCTGGCAGA ATGCTTCTGGCAGAT ATGCTTCTGGCAGATC ATGCTTCTGGCAGATCT ATGCTTCTGGCAGATCTG ATGCTTCTGGCAGATCTGA ATGCTTCTGGCAGATCTGAA ATGCTTCTGGCAGATCTGAAC ATGCTTCTGGCAGATCTGAACA ATGCTTCTGGCAGATCTGAACAG ATGCTTCTGGCAGATCTGAACAGT ATGCTTCTGGCAGATCTGAACAGTG ATGCTTCTGGCAGATCTGAACAGTGT ATGCTTCTGGCAGATCTGAACAGTGTT ATGCTTCTGGCAGATCTGAACAGTGTTA ATGCTTCTGGCAGATCTGAACAGTGTTAC ATGCTTCTGGCAGATCTGAACAGTGTTACT ATGCTTCTGGCAGATCTGAACAGTGTTACTG ATGCTTCTGGCAGATCTGAACAGTGTTACTGA ATGCTTCTGGCAGATCTGAACAGTGTTACTGAT ATGCTTCTGGCAGATCTGAACAGTGTTACTGATA ATGCTTCTGGCAGATCTGAACAGTGTTACTGATAT ATGCTTCTGGCAGATCTGAACAGTGTTACTGATATT ATGCTTCTGGCAGATCTGAACAGTGTTACTGATATTG ATGCTTCTGGCAGATCTGAACAGTGTTACTGATATTGC ATGCTTCTGGCAGATCTGAACAGTGTTACTGATATTGCT ATGCTTCTGGCAGATCTGAACAGTGTTACTGATATTGCTT ATGCTTCTGGCAGATCTGAACAGTGTTACTGATATTGCTT

32
Seqüenciamento de DNA ATGCTTCT ATGCTTCTG ATGCTTCTGG ATGCTTCTGGC
ATGCTTCTGGCA ATGCTTCTGGCAG ATGCTTCTGGCAGA ATGCTTCTGGCAGAT ATGCTTCTGGCAGATC ATGCTTCTGGCAGATCT ATGCTTCTGGCAGATCTG ATGCTTCTGGCAGATCTGA ATGCTTCTGGCAGATCTGAA ATGCTTCTGGCAGATCTGAAC ATGCTTCTGGCAGATCTGAACA ATGCTTCTGGCAGATCTGAACAG ATGCTTCTGGCAGATCTGAACAGT ATGCTTCTGGCAGATCTGAACAGTG ATGCTTCTGGCAGATCTGAACAGTGT ATGCTTCTGGCAGATCTGAACAGTGTT ATGCTTCTGGCAGATCTGAACAGTGTTA ATGCTTCTGGCAGATCTGAACAGTGTTAC ATGCTTCTGGCAGATCTGAACAGTGTTACT ATGCTTCTGGCAGATCTGAACAGTGTTACTG ATGCTTCTGGCAGATCTGAACAGTGTTACTGA ATGCTTCTGGCAGATCTGAACAGTGTTACTGAT ATGCTTCTGGCAGATCTGAACAGTGTTACTGATA ATGCTTCTGGCAGATCTGAACAGTGTTACTGATAT ATGCTTCTGGCAGATCTGAACAGTGTTACTGATATT ATGCTTCTGGCAGATCTGAACAGTGTTACTGATATTG ATGCTTCTGGCAGATCTGAACAGTGTTACTGATATTGC ATGCTTCTGGCAGATCTGAACAGTGTTACTGATATTGCT ATGCTTCTGGCAGATCTGAACAGTGTTACTGATATTGCTT ATGCTTCTGGCAGATCTGAACAGTGTTACTGATATTGCTT

37
Gel inteiro

38
Gel e cromatograma

40
Seqüenciamento de DNA

41
Montagem

42
Shotgun Amostrar fragmentos da seqüência-alvo da maneira mais aleatória possível. Determinar a maior porção possível das seqüências das extremidades destes fragmentos Sanger F, Coulson AR, Hong GF, Hill DF, Petersen GB. (1982) Nucleotide sequence of bacteriophage lambda DNA. J Mol Biol 162(4):
 Nucleotide sequence of bacteriophage lambda DNA. J Mol Biol 162(4):")
43
Montagem shotgun DNA original

44
Maior problema computacional
Determinar a disposição das seqüências dos fragmentos que seja mais consistente com as sobreposições encontradas Este é um problema NP-completo!

45
Para complicar... Há uma certa porcentagem de erros nas leituras
A leitura pode ser proveniente de qualquer uma das duas fitas Há desvio de representatividade Existem “falsas” sobreposições O desvio de representatividade é ruim porque obriga a amostrar mais do que o esperado para cobrir tudo!

46
Um programa para montagem de seqüências de DNA
CAP3 Um programa para montagem de seqüências de DNA Xiaoqiu Huang1 and Anup Madan2 1 Department of Computer Science, Michigan Technological University, Houghton, Michigan; 2 Department of Molecular Biotechnology, University of Washington, School of Medicine, Seattle, Washington Genome Research 9:

47
Três fases do algoritmo de montagem
Remoção das extremidades de baixa qualidade Cálculo de sobreposição de reads Remoção das “falsas” sobreposições Construção dos contigs Alinhamento múltiplo e geração do consenso

48
Três fases do algoritmo de montagem
Remoção das extremidades de baixa qualidade Cálculo de sobreposição de reads Remoção das “falsas” sobreposições Construção dos contigs Alinhamento múltiplo e geração do consenso

49
Identificação de sobreposição
Concatena todos os reads Encontram-se segmentos de alta pontuação Caracter separador Busca binária na lista ordenada de posição dos reads na seqüência combinada Não são analisadas porções anteriores ao read atual

50
Cálculo das posições de corte de read
Read h Read f Read g corte 3’

51
Smith-Waterman ponderado
Match = m * min(q1,q2) Mismatch = n * min(q1,q2) Gap = -q * min(q1,q2)
 Mismatch = n * min(q1,q2) Gap = -q * min(q1,q2)")
52
Cálculo da sobreposição de reads

53
Cálculo da sobreposição de reads
Feito por alinhamento global Banda de busca 2x maior que no alinhamento local Avaliação comprimento identidade pontuação de similaridade HQDs (max [0, min(q1, q2)-b], d=soma taxa de discrepância (r1+r2+e)
-b], d=soma. taxa de discrepância (r1+r2+e)")
54
Uso de limitadores (constraints)
Layout preeliminar Checagem de qualidade Corrige os ruins com mais que u problemas Liga contigs com mais que v limitações satisfeitas

55
Uso de limitadores (constraints)
")
56
Alinhamento e consenso
Alinha, em ordem crescente de posição, read com o consenso já montado Soma ponderada de qualidade base consenso = maior soma qualidade consenso = soma base w – soma base x – soma base y ...

57
Qualidade Média

58
Cálculo de pontuação

59
Average length of reads Length of provided sequence
Resultados do CAP3 Data set GenBank accession no. No. of reads Average length of reads Length of provided sequence Running time (min) No. of large contigs Length of CAP3 sequence No. of differences 203 AC004669 1812 598 89,779 37 1 90,292 0 216 AC004638 2353 614 124,645 154 132,057 17 322F16 AF111103 4297 1011 159,179 127 157,982 11 526N18 AF123462 3221 965 180,182 73 2 180,128 10
 No. of large contigs. Length of CAP3 sequence. No. of differences AC , , AC , , F16. AF , , N18. AF , ,")
60
Construção de Scaffolds
Data set Length of answer sequence No. of reads per kb Ability to make scaffold with CAP3 Ability to make scaffold with PHRAP 188A7 112,773 10.6 yes 201G24 184,666 10.8 213L3 135,545 10.3 257P13 184,998 10.1 488C13 187,237 11.1 501I4 231,464 11.7 no

61
Program Data set Longest Contig # large contigs length of gaps internal errors CAP3 3XA 6189 57 52,885 443 PHRAP 6396 54 38,146 529 3XB 12,368 44 71,761 71 13,116 47 60,436 228 3XC 10,709 49 54,229 227 11,406 45 34,727 332 3XD 11,408 43 67,586 115 11,350 60,312 240 5XA 10,582 42 27,965 249 18,268 31 14,396 252 5XB 26,034 17 10,405 100 33,693 18 7,322 5XC 20,939 29 20,520 172 20,912 27 16,617 261 5XD 14,219 35 23,635 46 14,696 33 17,113 129 8XA 71,025 12 4,681 83 71,395 8 1,061 80 8XB 53,127 883 59 53,078 7 542 36 8XC 52,134 752 4 76,922 6 774 8XD 72,690 1,241 102,523 648 60 10XA 91,380 28 91,329 3 11 10XB 167,655 1 5 138,551 2 10XC 106,631 321 77,747 330 10XD 79,900 468 79,978 346

62
Excelente revisão de “montadores”

Apresentações semelhantes