Carregar apresentação
A apresentação está carregando. Por favor, espere

1
Aula19: Desempenho de SSM Large-Scale MP Sincronização
ARQUITETURA DE COMPUTADORES DEPT. DE CIÊNCIA DA COMPUTAÇÃO - UFMG

2
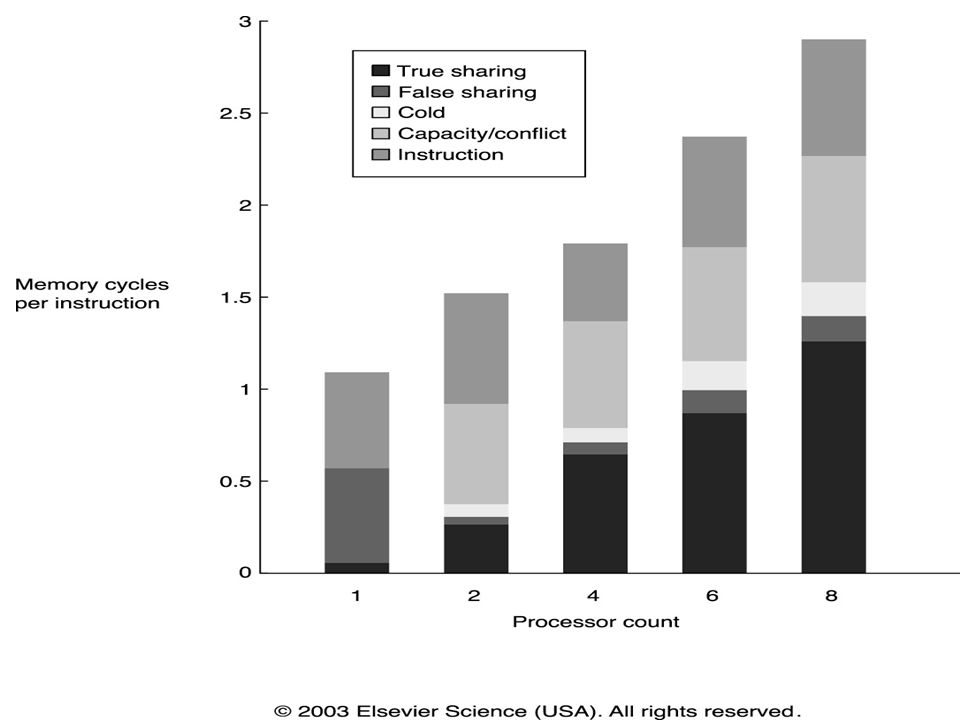
Coerência de Caches Classificação de MR em 3 C’s
O que pode acontecer em uma cache coerente? Sharing miss False sharing

4
Extendendo Coerência de Caches para Memórias Compartilhadas Distribuídas
Ao contrário de memórias compartilhadas centralizadas, não possuímos neste caso um recurso centralizado que vê todas as transações (bus) Não há meio de broadcast Não há maneira de serializar transações barramento funciona como meio de garantir serialização das operações Técnicas Extender protocolos do tipo snoopy Protocolos baseados em diretórios
 Não há meio de broadcast. Não há maneira de serializar transações. barramento funciona como meio de garantir serialização das operações. Técnicas. Extender protocolos do tipo snoopy. Protocolos baseados em diretórios.")
5
Snoopy Hierárquico Maneira mais simples: hierarquia de barramentos, coerência snoopy a cada nível Duas possibilidades L1 P L2 L1 P L1 P L1 P L1 P B1 B1 Mem L2 L2 Mem B2 B2 Main Mem

6
Hierarquias com Memória Global
Caches primárias: Alta performance (SRAM) B1 segue protocolo snoopy básico Caches secundárias: Muito maiores que L1 (precisam manter propriedade de inclusão) L2 funciona como filtro p/ B1 e L1 L2 pode ser baseada em tecnologia DRAM L1 P L2 B1 B2 Main Mem
 B1 segue protocolo snoopy básico. Caches secundárias: Muito maiores que L1 (precisam manter propriedade de inclusão) L2 funciona como filtro p/ B1 e L1. L2 pode ser baseada em tecnologia DRAM. L1. P. L2. B1. B2. Main Mem.")
7
Hierarquias com Memória Global
Vantagens: Misses na memória principal requerem tráfego único para a raiz da hierarquia Utilização de dados compartilhados não é uma questão importante Desvantagens: Misses para dados locais também trafegam na hierarquia Memória em barramento global deve ser intercalada para aumentar BW

8
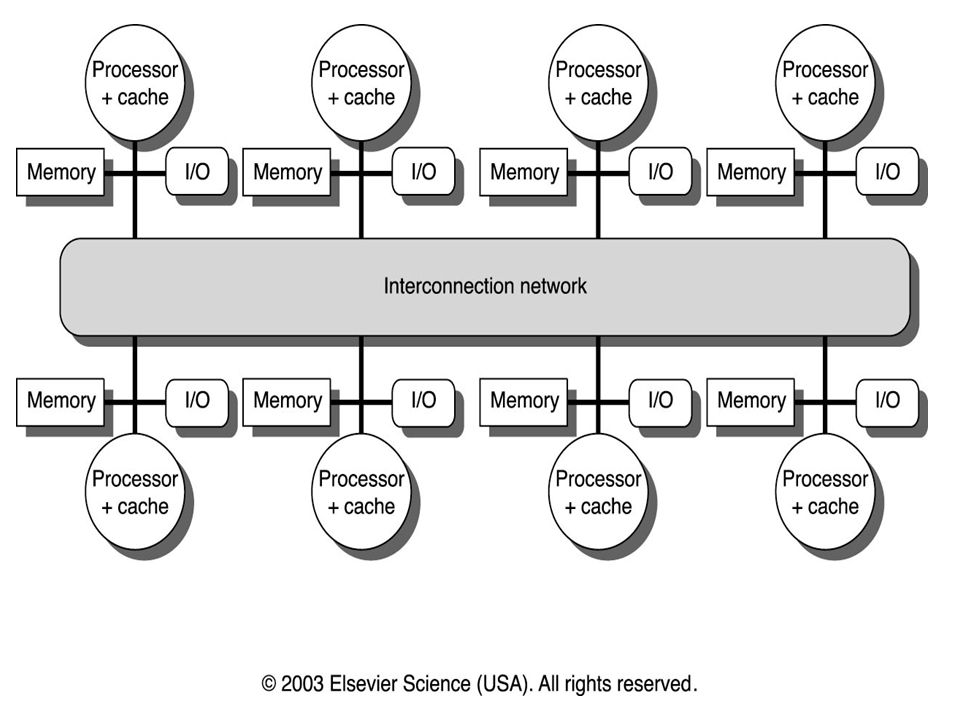
Hierarquias Baseadas em Clusters
P L2 Mem B2 B1 Memória principal é distribuída entre clusters Alocação de dados locais pode reduzir tráfego em barramento global Reduz latência (acessos locais mais rápidos) Exemplos: Encore Gigamax L2 pode ser substituída por uma chave roteadora baseada em tags com coerência
 Exemplos: Encore Gigamax. L2 pode ser substituída por uma chave roteadora baseada em tags com coerência.")
9
Resumo de Hierarquias Vantagens: Desvantagens:
Conceitualmente simples de se construir (aplica-se snoopy recursivamente) Pode-se reduzir hardware necessário ao se combinar as funcionalidades Desvantagens: Gargalo de comunicação na direção da raiz Latências podem ser grandes na direção da raiz
 Pode-se reduzir hardware necessário ao se combinar as funcionalidades. Desvantagens: Gargalo de comunicação na direção da raiz. Latências podem ser grandes na direção da raiz.")
11
Protocolos de Coerência Baseados em Diretórios
Protocolos do tipo snoopy não escalam bem porque dependem de algum meio de broadcast Snoop hierarquico faz raiz se tornar um gargalo Mecanismos baseados em diretório escalam bem Evitam broadcasts Mantém informação de todas as caches que possuem cópia do bloco Utilizam mensagens ponto-a-ponto para manter coerência

12
Protocolo Baseado em Diretório
Cache P Rede de Interconexão Memória Diretório Bits de presença Dirty K processadores Para cada bloco de cache na memória => k bits de presença, 1 dirty-bit Para cada bloco na cache Invalid Exclusive Shared

13
Estados Shared: um ou mais processadores possuem o bloco cached, e o bloco na memória é atualizado Invalid ou Uncached: nenhum processador possui uma cópia do bloco Exclusivo: um único processador possui uma cópia do bloco

14
Protocolo Baseado em Diretório

15
Protocolo (Cache) Invalidade Invalid Shared CPU read CPU read hit
CPU read miss Read miss Send read miss message Data write-back, read miss CPU read miss Fetch invalidade Data write-back CPU write Send write miss Fetch Data write-back CPU write Send write miss message Exclusive CPU write hit CPU read hit CPU write miss Data write-back Write miss

16
Protocolo (Diretório)
Uncached Shared Read miss Data value reply Sharers = {P} Read miss Data value reply Sharers += {P} Data write back Sharers = {} Read miss Fetch, data value reply, Sharers += {P} Data value reply Sharers = {P} Write miss Invalidate; Sharers = {P}; data value reply Write miss Exclusive Write miss Fetch/Invalidate Data value reply Sharers = {P}

17
Organização de Diretórios
Implementação dos diretórios na memória (como o apresentado anteriormente) Apresenta problemas de escalabilidade Pode apresentar problemas de BW Implementação dos diretórios na cache (SCI) Listas encadeadas (simples ou duplo) Mantém em cada cache “link” do próximo processador compartilhando bloco SCI utiliza listas duplamente encadeadas Precisamos agora da mensagem “desconectar da lista” e “conectar à lista” (a última equivalente a um MISS)
 Apresenta problemas de escalabilidade. Pode apresentar problemas de BW. Implementação dos diretórios na cache (SCI) Listas encadeadas (simples ou duplo) Mantém em cada cache link do próximo processador compartilhando bloco. SCI utiliza listas duplamente encadeadas. Precisamos agora da mensagem desconectar da lista e conectar à lista (a última equivalente a um MISS)")
18
Sincronização SSM: sequência de instruções capazes de recuperar ou alterar valores atomicamente LSM: latência pode adicionar problemas de desempenho

19
Primitivas de Hardware
Atomic exchange Test-and-set Fetch-and-increment Load-linked

20
Load-linked try: OR R3,R4,R0 LL R2,0(R1) SC R3,0(R1) BEQZ R3,try
MOV R4,R2

21
Implementando fetch-and-increment com load-linked
try: LL R2,0(R1) DADDUI R3,R2,#1 SC R3,0(R1) BEQZ R3,try
 DADDUI R3,R2,#1. SC R3,0(R1) BEQZ R3,try.")
22
Implementando Locks com Coerência de Cache
DADDU R2,R0,#1 lockit: EXCH R2,0(R1) BNEZ R2,lockit lockit: LD R2,0(R1) BNEZ R2,lockit DADDUI R2,R0,#1 EXCH R2,0(R1)
 BNEZ R2,lockit. lockit: LD R2,0(R1) BNEZ R2,lockit. DADDUI R2,R0,#1. EXCH R2,0(R1)")
23
Implementando Locks com Coerência de Cache
lockit: LL R2,0(R1) BNEZ R2,lockit DADDUI R2,R0,#1 SC R2,0(R1) BEQZ R2,lockit
 BNEZ R2,lockit. DADDUI R2,R0,#1. SC R2,0(R1) BEQZ R2,lockit.")
Apresentações semelhantes




 Aula 5 Luciana A. F. Martimiano 2002>")





 em um único chip.>")








