Carregar apresentação
A apresentação está carregando. Por favor, espere

1
REVISÃO PARA 3a PROVA Gerência de Banco de Dados
Profa. Sandra de Amo Disciplina GBC053 Bacharelado em Ciência da Computação

2
Condições Gerais de Seleção
SELECT * FROM R WHERE (R.A op ‘a’ OR R.A op ‘a1) AND (R.B op ‘b’ OR R.B op ‘b1’) op: =, < , > , ≤ , ≥ Tamanho de R = M páginas Número de tuplas por página = Pr 2
 AND (R.B op ‘b’ OR R.B op ‘b1’) op: =, < , > , ≤ , ≥ Tamanho de R = M páginas. Número de tuplas por página = Pr. 2.")
3
Caso 1: sem OR Um só índice
Criar índice para atributo que aparece na condição de seleção, com maior “seletividade” utilizar este índice para obter os registros satisfazendo a condição da chave do índice A medida que se recupera as tuplas satisfazendo esta condição elimina-se as tuplas que não satisfazem alguma das outras condições. Diversos índices Utiliza-se diversos indices, sobre alguns atributos aparecendo na condição de seleção. Para cada condição Ai = ai recupera-se as páginas do arquivo de indice satisfazendo esta condição. Ordena-se as entradas de cada índice pelo page-id Faz-se a intersecção das entradas com os mesmos page-ids Recupera-se as tuplas contidas nas páginas indicadas pelos page-ids e elimina-se aquelas que não satisfazem as outras condições da seleção (para as quais não foram considerados indices). 3
. 3.")
4
Caso 2 : com OR A = a1 OR B = b1 (A = a1 OR B = b1) AND C = c1
Indice em A, não há indice em B Melhor solução : scan (o indice em A não ajuda nada) (A = a1 OR B = b1) AND C = c1 Indice em A, não há indice em B, indice em C Melhor solução: utilizar o indice em C Indice em A, indice em B Melhor solução: recupera-se as entradas no arquivo de indice para A = a1 : recupera-se as entradas no arquivo de indice para B = b1 : Faz-se a união destes dois conjuntos de entradas Ordena-se este conjunto pelo page-id 4
 (A = a1 OR B = b1) AND C = c1. Indice em A, não há indice em B, indice em C. Melhor solução: utilizar o indice em C. Indice em A, indice em B. Melhor solução: recupera-se as entradas no arquivo de indice para A = a1 : recupera-se as entradas no arquivo de indice para B = b1 : Faz-se a união destes dois conjuntos de entradas. Ordena-se este conjunto pelo page-id. 4.")
5
Projeção SELECT DISTINCT R.A, R.B FROM R Duas etapas principais :
Remover colunas indesejáveis Eliminar as duplicatas (o mais difícil) 5
 5.")
6
Projeção usando Ordenação
1. Scan de R para produzir as tuplas projetadas (sem os campos indesejáveis) Custo passo 1 = M + T 2. Ordena o resultado, utilizando a combinação de todos os atributos da projeção como chave da ordenação Custo passo 2 (Ordenação) = 2T ([logB-1T/B] + 1) 3. Scan do resultado ordenado para eliminação das tuplas adjacentes repetidas. Custo passo 3 = T T = número de páginas produzidas da relação projetada (T = c.M onde c < 1) T depende do número e do tamanho dos campos removidos em cada tupla. Custo total = M + T + 2T ([logB-1T/B] + 1) +T Otimização: Pode-se projetar as tuplas durante a primeira iteração da ordenação. A partir da segunda iteração da ordenação já vai-se eliminando as duplicatas à medida que são criados os subarquivos ordenados. 6
 Custo passo 1 = M + T. 2. Ordena o resultado, utilizando a combinação de todos os atributos da projeção como chave da ordenação. Custo passo 2 (Ordenação) = 2T ([logB-1T/B] + 1) 3. Scan do resultado ordenado para eliminação das tuplas adjacentes repetidas. Custo passo 3 = T. T = número de páginas produzidas da relação projetada (T = c.M onde c < 1) T depende do número e do tamanho dos campos removidos em cada tupla. Custo total = M + T + 2T ([logB-1T/B] + 1) +T. Otimização: Pode-se projetar as tuplas durante a primeira iteração da ordenação. A partir da segunda iteração da ordenação já vai-se eliminando as duplicatas à medida que são criados os subarquivos ordenados. 6.")
7
Projeção usando Hashing
Usada quando se tem um tamanho de buffer B razoável com relação ao tamanho da relação R. Usa a idéia do algoritmo de Hash Join de Junção Fase do Particionamento + Projeção: produz como resultado a relação R projetada (ainda sem a eliminação de duplicatas), organizada em partições, segundo uma função hash h, calculada sobre os atributos da projeção. Fase da Eliminação das Duplicatas. Supomos que tamanho de uma partição ≤ B Para cada partição carregada no buffer, varre-se a partição e elimina-se as duplicatas. Todos os registros de dados com valores duplicados estão numa mesma partição.
, organizada em partições, segundo uma função hash h, calculada sobre os atributos da projeção. Fase da Eliminação das Duplicatas. Supomos que tamanho de uma partição ≤ B. Para cada partição carregada no buffer, varre-se a partição e elimina-se as duplicatas. Todos os registros de dados com valores duplicados estão numa mesma partição.")
8
Fase do Particionamento e Projeção de R
Relação R’ Particionada e Projetada Relação R Pt 1 Pt 2 Pt 3 Pt 4 Pt 5 Pt 6 Projeta e Distribui usando hash h Sobre a combinação dos atributos projetados Página de R Buffer tem capacidade para B páginas, onde B – 1 = número de partições Disco Disco T páginas M páginas

9
Fase da Eliminação de Duplicatas
Relação R’ particionada Relação R’ sem duplicatas Partição n de R’ (inteira) Página de R’ sem duplicatas Buffer tem capacidade para B páginas, onde B = tamanho de uma partição de R’ Disco Disco
 Página de. R’ sem duplicatas. Buffer tem capacidade para B páginas, onde B = tamanho de uma partição de R’ Disco. Disco.")
10
Tamanho mínimo de Buffer
Fase do Particionamento + Projeção Cria-se B-1 partições Registros de cada partição são projetados T = tamanho da relação projetada R’ Tamanho de uma partição = T/B-1 Fase de Eliminação das Duplicatas B ≥ T/B-1 (B-1).B ≥ T (B-1).B > (B-1).(B-1) ≥ T Se B-1 ≥ T teremos que (B-1).B ≥ T Logo, basta considerar B ≥ T ou equivalentemente B > T
.B ≥ T. (B-1).B > (B-1).(B-1) ≥ T. Se B-1 ≥ T teremos que (B-1).B ≥ T. Logo, basta considerar B ≥ T + 1 ou equivalentemente B > T.")
11
UNION: algoritmo baseado em ordenação
Fase da Ordenação: Ordena T1 por todos os atributos Ordena T2 por todos os atributos Fase da Intercalação Intercala as tuplas de T1 e T2 de modo a obter um único arquivo ordenado e sem duplicatas. 11

12
Fase da Intercalação 1 2 1 1 2 2 5 6 5 6 7 8 7 9 9 8 9 11 13 11 13 Página de T1 Página de T2 Página de output Buffer pool CUSTO TOTAL = 2M ([LogB-1 M/B] + 1) + 2N ([LogB-1 N/B] + 1) + M + N CUSTO DA INTERCALAÇÃO = M + N M = número de páginas de T1 N = número de páginas de T2
 + 2N ([LogB-1 N/B] + 1) + M + N. CUSTO DA INTERCALAÇÃO = M + N. M = número de páginas de T1. N = número de páginas de T2.")
13
EXCEPT: algoritmo baseado em ordenação
Fase da Ordenação: Ordena T1 por todos os atributos Ordena T2 por todos os atributos Fase da Diferença Intercala as tuplas de T1 e T2 de modo a obter um único arquivo ordenado e sem duplicatas. 13

14
Fase da Diferença Se T1.r < T2.r Insere T1.r no Output
Atualiza o marcador de T1 para o próximo registro de T1 diferente de T1.r 2. Se T1.r = T2.r Atualiza os marcadores de T1 e T2 para os próximos registros de T1 dif. de T1.r e de T2 dif. de T2. r 3. Se T1.r > T2.r Atualiza o marcador de T2 para o próximo registro de T2, diferente de T2.r 1 2 1 1 2 5 6 7 8 9 9 11 13 Página de T1 Página de T2 Página de output Buffer pool

15
Fase da Diferença Se T1.r < T2.r Insere T1.r no Output
Atualiza o marcador de T1 para o próximo registro de T1 diferente de T1.r 2. Se T1.r = T2.r Atualiza os marcadores de T1 e T2 para os próximos registros de T1 dif. de T1.r e de T2 dif. de T2. r 3. Se T1.r > T2.r Atualiza o marcador de T2 para o próximo registro de T2, diferente de T2.r 1 2 1 1 2 5 5 6 7 8 9 9 11 13 Página de T1 Página de T2 Página de output Buffer pool

16
Fase da Diferença Se T1.r < T2.r Insere T1.r no Output
Atualiza o marcador de T1 para o próximo registro de T1 diferente de T1.r 2. Se T1.r = T2.r Atualiza os marcadores de T1 e T2 para os próximos registros de T1 dif. de T1.r e de T2 dif. de T2. r 3. Se T1.r > T2.r Atualiza o marcador de T2 para o próximo registro de T2, diferente de T2.r 1 2 1 1 2 5 5 6 7 7 8 9 9 11 13 Página de T1 Página de T2 Página de output Buffer pool

17
Fase da Diferença Se T1.r < T2.r Insere T1.r no Output
Atualiza o marcador de T1 para o próximo registro de T1 diferente de T1.r 2. Se T1.r = T2.r Atualiza os marcadores de T1 e T2 para os próximos registros de T1 dif. de T1.r e de T2 dif. de T2. r 3. Se T1.r > T2.r Atualiza o marcador de T2 para o próximo registro de T2, diferente de T2.r 1 2 1 1 2 5 5 6 7 7 8 11 9 9 11 13 Página de T1 Página de T2 Página de output Buffer pool CUSTO TOTAL = 2M ([LogB-1 M/B] + 1) + 2N ([LogB-1 N/B] + 1) + M + N CUSTO DA DIFERENÇA = M + N M = número de páginas de T1 N = número de páginas de T2
 + 2N ([LogB-1 N/B] + 1) + M + N. CUSTO DA DIFERENÇA = M + N. M = número de páginas de T1. N = número de páginas de T2.")
18
UNION: algoritmo baseado em hash
Fase da Particionamento: Particiona T1 em B-1 partições usando o buffer Particiona T2 em B-1 partições usando o buffer Fase da União Carrega a partição inteira n de T1 no buffer: isto é possível se B > Ordena internamente os elementos da partição n e elimina as duplicatas Para cada página da partição n de T2, ordena internamente e elimina as duplicatas. Para cada tupla da partição n de T2, varre a partição n de T1 (que está em memória) e verifica se t está nesta partição. Se não estiver, coloque-a no resultado. Retorna a partição n de T1 e as páginas construídas com os elementos da correspondente partição n de T2 que faltavam na partição n de T1. T1 18
 e verifica se t está nesta partição. Se não estiver, coloque-a no resultado. Retorna a partição n de T1 e as páginas construídas com os elementos da correspondente partição n de T2 que faltavam na partição n de T1. T")
19
EXCEPT: algoritmo baseado em hash
Fase do Particionamento: Particiona T1 em B-1 partições usando o buffer Particiona T2 em B-1 partições usando o buffer Fase da Diferença Carrega a partição inteira n de T2 no buffer: isto é possível se B > (Prove !) Ordena internamente os elementos da partição n e elimina as duplicatas Para cada página da partição n de T1, ordena internamente e elimina as duplicatas. Para cada tupla t da partição n de T1, varre a partição n de T2 (que está em memória) e verifica se t está nesta partição. Se não estiver, coloca-a no resultado. T2 19
 Ordena internamente os elementos da partição n e elimina as duplicatas. Para cada página da partição n de T1, ordena internamente e elimina as duplicatas. Para cada tupla t da partição n de T1, varre a partição n de T2 (que está em memória) e verifica se t está nesta partição. Se não estiver, coloca-a no resultado. T")
20
Algoritmos para Operador GROUP BY
SELECT S.Status, AVG(S.Idade) FROM Sailors S GROUP BY S.Status Técnicas: Ordenação Hashing
 FROM Sailors S. GROUP BY S.Status. Técnicas: Ordenação. Hashing.")
21
Algoritmo para GROUP BY baseado em ordenação
Etapa 1: Ordena-se a relação pelo atributo do Group by Etapa 2: Faz-se um scan da relação ordenada armazenando-se na variável Agreg o resultado da operação de agregação para cada grupo Custos: Etapa 1 = 2M([LogB-1 M/B] + 1) Etapa 2 = M Custo total = 2M([LogB-1 M/B] + 1) + M
 Etapa 2 = M. Custo total = 2M([LogB-1 M/B] + 1) + M.")
22
Algoritmo para GROUP BY baseado em Hash
Fase do Particionamento Particiona a relação R pelos atributos de agrupamento – do GROUP BY Desta maneira: elementos de um mesmo grupo só podem estar numa mesma partição. O particionamento é feito de modo que cada partição caiba inteira na memória. Para isso, é preciso que o tamanho do buffer (B) seja > M onde M = número de páginas da relação R. Fase do Agrupamento Carrega partição inteira de R Aplica algoritmo de ordenação interna pelos atributos do agrupamento (Group By). Varre a partição (ordenada) e calcula-se o resultado da função de agregação sobre cada grupo CUSTO = 2M + M = 3M
 seja > M. onde M = número de páginas da relação R. Fase do Agrupamento. Carrega partição inteira de R. Aplica algoritmo de ordenação interna pelos atributos do agrupamento (Group By). Varre a partição (ordenada) e calcula-se o resultado da função de agregação sobre cada grupo. CUSTO = 2M + M = 3M.")
23
Esquema Geral do Otimizador
Bloco SQL simples usuário Consulta SQL SQL Parser Transforma em Algebra Coleção de blocos simples B1, B2, ...., Bn Plano canônico Cria planos alternativos Otimizador Planos alternativos Estima custos Melhor Plano de execução Melhor Plano de execução

24
Decompor consulta em blocos simples
Um bloco SQL simples é um comando sem subconsultas aninhadas, onde aparece somente um SELECT, somente um FROM no máximo um WHERE (em FNC) no máximo um GROUP BY no máximo um HAVING
 no máximo um GROUP BY. no máximo um HAVING.")
25
Exemplo SELECT DISTINCT S.sid, Min (R.day)
FROM Sailors S, Reservas R, Boats B WHERE S.sid = R.sid AND R.bid = B.bid AND B.color = ‘red’ AND S.rating = ( SELECT MAX (S2.rating) FROM Sailors S2 ) GROUP BY S.sid HAVING COUNT (*) > 1
 FROM Sailors S2 ) GROUP BY S.sid. HAVING COUNT (*) > 1.")
26
Exemplo Bloco 1 : bloco interno SELECT MAX (S2.rating) FROM Sailors S2
Resultado : Relação temporária T(A) Bloco 2 : bloco externo SELECT DISTINCT S.sid, Min (R.day) FROM Sailors S, Reservas R, Boats B, T WHERE S.sid = R.sid AND R.bid = B.bid AND B.color = ‘red’ AND S.rating = T.A GROUP BY S.sid HAVING COUNT (*) > 1
 Bloco 2 : bloco externo. SELECT DISTINCT S.sid, Min (R.day) FROM Sailors S, Reservas R, Boats B, T. WHERE S.sid = R.sid AND R.bid = B.bid. AND B.color = ‘red’ AND S.rating = T.A. GROUP BY S.sid. HAVING COUNT (*) > 1.")
27
Plano de Execução “Canônico”
Π A,B,...,C Resultado R é ordenado O GROUP BY é executado sobre o resultado R ordenado. O HAVING é aplicado para eliminar certos grupos. Funções de agregação (MIN,MAX,...) são executadas sobre os grupos finais Operador de Projeção é executado por último. Resultado R σ X R1 R2 Rn
 são executadas sobre os grupos finais. Operador de Projeção é executado por. último. Resultado R. σ. X. R1. R2. Rn.")
28
PLANOS ALTERNATIVOS Equivalências de Expressões Algébricas
Seleção σ c1 ^ c2 ^ ... ^ cn (R) = σ c1 (σ c2 (... (σ cn (R))...) Vantagens: Permite realizar uma única seleção, verificando todas as condições simultaneamente, em vez de se executar n seleções separadamente em sequência. σ c1 (σ c2 (R) ) = σ c2 (σ c1 (R) ) As condições podem ser executadas em qualquer ordem. Vantagem: executar a condição mais seletiva primeiro.
 = σ c1 (σ c2 (... (σ cn (R))...) Vantagens: Permite realizar uma única seleção, verificando todas as condições simultaneamente, em vez de se executar n seleções separadamente em sequência. σ c1 (σ c2 (R) ) = σ c2 (σ c1 (R) ) As condições podem ser executadas em qualquer ordem. Vantagem: executar a condição mais seletiva primeiro.")
29
Equivalências de Expressões Algébricas
Projeção Π X1 (R) = Π X1 (Π X2 (... (Π Xn (R))...) Onde cada Xi é um conjunto de atributos Xi está contido em Xi+1 Exemplo: Π A (R) = Π A (ΠAB (Π ABC (R))) Vantagem: Reduz o número de execuções do algoritmo de projeção
 = Π X1 (Π X2 (... (Π Xn (R))...) Onde. cada Xi é um conjunto de atributos. Xi está contido em Xi+1. Exemplo: Π A (R) = Π A (ΠAB (Π ABC (R))) Vantagem: Reduz o número de execuções do algoritmo de projeção.")
30
Equivalências de Expressões Algébricas
Produto Cartesiano e Junção Associativa R (S T) = (R S) T Comutativa (R S) = (S R)
 = (R S) T. Comutativa. (R S) = (S R)")
31
Equivalências de Expressões Algébricas
Seleção e Projeção ΠX σc (R) = σc ΠX (R) Onde todos os atributos aparecendo na condição c estão contidos em X
 = σc ΠX (R) Onde todos os atributos aparecendo na condição c estão contidos em X.")
32
Equivalências de Expressões Algébricas
Seleção e Junção R S = σc (R S) σc (R S) = (σc R S) se todos os atributos de c são atributos de R e não de S Vantagens: junção pode ser feita entre relações menores. c
 σc (R S) = (σc R S) se todos os atributos de c são atributos de R e não de S. Vantagens: junção pode ser feita entre relações menores. c.")
33
Equivalências de Expressões Algébricas
Projeção e Produto Cartesiano ΠX (R S) = (ΠY R ΠZ S) Y = atributos de X que aparecem em R Z = atributos de X que aparecem em S Exemplo: ΠAB (R S) = (ΠA R ΠB S) onde R(AC) e S(BC) Vantagem: Produto cartesiano pode ser feito entre relações menores.
 = (ΠY R ΠZ S) Y = atributos de X que aparecem em R. Z = atributos de X que aparecem em S. Exemplo: ΠAB (R S) = (ΠA R ΠB S) onde R(AC) e S(BC) Vantagem: Produto cartesiano pode ser feito entre relações menores.")
34
Equivalências de Expressões Algébricas
Projeção e Junção ΠX (R S) = (ΠY R ΠZ S) Y = atributos de X que aparecem em R Z = atributos de X que aparecem em S Os atributos envolvidos na condição de junção c devem aparecer em X Exemplo : R(ACD), S(BEC), X = {A, B, C}, condição de junção : R.C = S.C ΠABC (R S) = (ΠAC R ΠBC S) c c c c
 = (ΠY R ΠZ S) Y = atributos de X que aparecem em R. Z = atributos de X que aparecem em S. Os atributos envolvidos na condição de junção c devem aparecer em X. Exemplo : R(ACD), S(BEC), X = {A, B, C}, condição de junção : R.C = S.C. ΠABC (R S) = (ΠAC R ΠBC S) c. c. c. c.")
35
ESTIMATIVAS DE CUSTOS DE PLANOS DE EXECUÇÃO
Uso de estatísticas sobre tabelas e indices armazenadas no catálogo Uso de Histogramas atualizados periodicamente e mantidos no catálogo do sistema.

36
Estatísticas sobre tabelas e indices armazenadas no catálogo:
NTuples (R) = Número de tuplas da tabela R NPages(R) = Número de páginas da tabela R NKeys(I) = número de chaves distintas do Indice I INPages(I) = número de páginas do indice I (no caso de B+tree = número de folhas) IHeight(I) = Altura do Indice (no caso de B+tree) ILow(I) = menor valor de chave do indice I IHigh(I) = maior valor de chave do indice I
 = Número de tuplas da tabela R. NPages(R) = Número de páginas da tabela R. NKeys(I) = número de chaves distintas do Indice I. INPages(I) = número de páginas do indice I. (no caso de B+tree = número de folhas) IHeight(I) = Altura do Indice (no caso de B+tree) ILow(I) = menor valor de chave do indice I. IHigh(I) = maior valor de chave do indice I.")
37
Pipeline versus Tabelas Materializadas
Pipeline : resultado de uma operação é transferido para a próxima operação sem a criação de uma tabela em disco. Economia de custos de armazenamento e de leitura posterior Sempre que o algoritmo do operador para o qual é transferido o resultado permitir, a técnica de pipeline é utilizada.

38
Estimativa de Custos de um Plano de Execução
Para cada nó da árvore N da árvore, seja Op(N) a operação associada a N. Tarefas do Estimador de Custos Estimar do custo de Op(N) Estimar o tamanho do resultado de Op(N)
 a operação associada a N. Tarefas do Estimador de Custos. Estimar do custo de Op(N) Estimar o tamanho do resultado de Op(N)")
39
Estimativa do Tamanho do Resultado
SELECT <lista de atributos> FROM < lista de relações R1,...,Rk > WHERE <cond1 ^ cond2 ^....^condn> Número máximo de tuplas no resultado = M1.M2....Mk, onde Mi = tamanho de Ri Cláusula WHERE atua como um redutor desta estimativa Cada condição do WHERE tem o seu fator de redução próprio

40
Fatores de Redução R.A = valor R.A = R.B
Fator de redução = 1/NKeys(I), caso exista um indice I com chave A para a relação R Fator de redução = 1/10, caso contrário (ou utiliza-se estatísticas mantidas no catálogo sobre a distribuição dos valores dos atributos) R.A = R.B Fator de redução = 1/Max(NKeys(IA),NKeys(IB)) se existe indices IA e IB com chave A e B respectivamente. Fator de redução = 1/NKeys(I) se somente um dos atributos é chave de um indice I Fator de redução = 1/10 caso contrário.
, caso exista um indice I com chave A para a relação R. Fator de redução = 1/10, caso contrário (ou utiliza-se estatísticas mantidas no catálogo sobre a distribuição dos valores dos atributos) R.A = R.B. Fator de redução = 1/Max(NKeys(IA),NKeys(IB)) se existe indices IA e IB com chave A e B respectivamente. Fator de redução = 1/NKeys(I) se somente um dos atributos é chave de um indice I. Fator de redução = 1/10 caso contrário.")
41
Fatores de Redução R.A > valor R.A IN (Lista de valores)
Fator de redução = (High(I) – valor) / High(I) – Low(I) caso exista um indice I com chave A para a relação R Fator de redução = fração < ½ caso não exista indice ou se o valor não é aritmético R.A IN (Lista de valores) Fator de redução = N*(fator de redução de R.A = valor), onde N = núm. de itens Fator de redução = fração < ½ caso não exista índice ou se o valor não é aritmético.
 – valor) / High(I) – Low(I) caso exista um indice I com chave A para a relação R. Fator de redução = fração < ½ caso não exista indice ou se o valor não é aritmético. R.A IN (Lista de valores) Fator de redução = N*(fator de redução de R.A = valor), onde N = núm. de itens. Fator de redução = fração < ½ caso não exista índice ou se o valor não é aritmético.")
42
Fatores de Redução R.A IN (Subconsulta) NOT (Cond)
Fator de redução: M/N onde M = tamanho do resultado da Subconsulta N = número de valores do atributo R.A NOT (Cond) Fator de redução: (1 – Fator de Redução(Cond)) Fator de Redução da Projeção = fração equivalente ao tamanho dos atributos que não são eliminados.
 Fator de redução: (1 – Fator de Redução(Cond)) Fator de Redução da Projeção = fração equivalente ao tamanho dos atributos que não são eliminados.")
43
Histograma 9 8 Distribuição real 4 4 3 3 3 3 2 2 2 2 1 1 1 3 3 3 3 3 3
1 2 3 4 5 6 7 8 9 10 11 12 13 14 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 1 2 3 4 5 6 7 8 9 10 11 12 13 14 Distribuição uniforme

44
Histogramas Supõe-se um conjunto de N tuplas, com valores do atributo A variando de v1 a v2. Supõe-se que para cada valor v do atributo A, v1 ≤ v ≤ v2, temos o número de tuplas N(v) com este valor para Estimativas do número de tuplas com valor x: Estimativa exata : N(x) Estimativa usando distribuição uniforme: Média aritméticas dos valores
 com este valor para. Estimativas do número de tuplas com valor x: Estimativa exata : N(x) Estimativa usando distribuição uniforme: Média aritméticas dos valores.")
45
Histogramas por Largura
Histograma por largura : particiona-se o conjunto de valores em K grupos, com o mesmo número de valores cada um. Para cada grupo de valores, determina a média do número de tuplas do grupo Como estimar N(x) usando um histograma por Largura Estimativa do número de tuplas com valor x = média do número de tuplas do grupo ao qual x pertence.
 usando um histograma por Largura. Estimativa do número de tuplas com valor x = média do número de tuplas do grupo ao qual x pertence.")
46
Histograma por largura
9 8 4 4 3 3 3 3 2 2 2 2 1 1 1 1 2 3 4 5 6 7 8 9 10 11 12 13 14 5 5 5 5 2.67 1.33 1 1 2 3 4 5 6 7 8 9 10 11 12 13 14
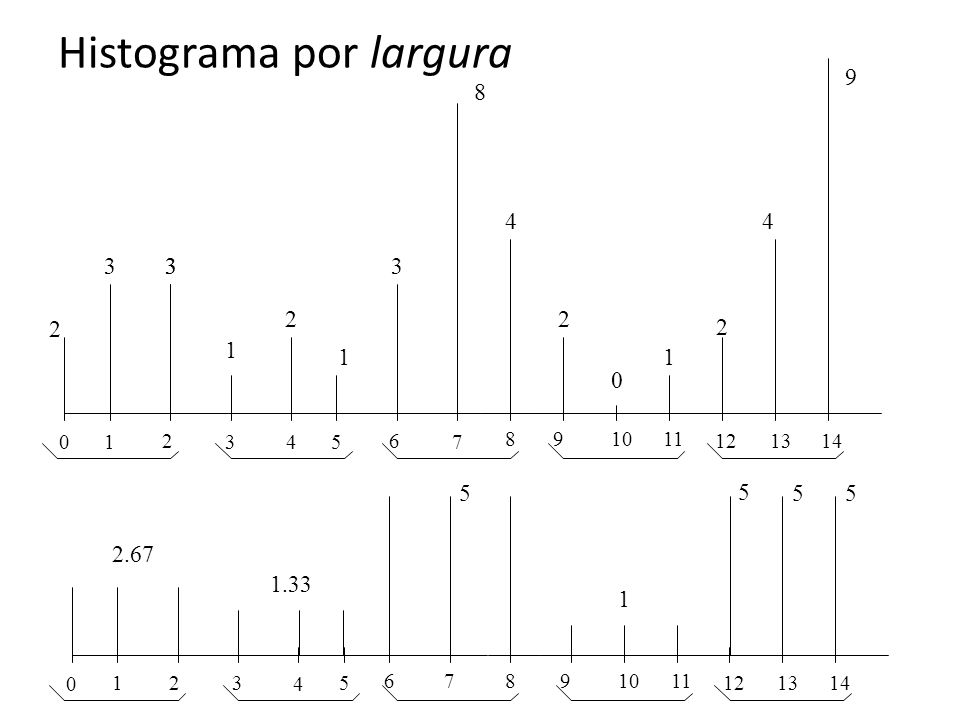
47
Uso do Histograma por largura
Qual a estimativa da quantidade de tuplas com AGE > 13 ? Distribuição uniforme: 3 tuplas Distribuição histograma por largura: 5 tuplas 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 1 2 3 4 5 6 7 8 9 10 11 12 13 14 5 5 5 5 2.67 1.33 1 1 2 3 4 5 6 7 8 9 10 11 12 13 14

48
Histogramas em Profundidade
Histograma em Profundidade : particiona-se o conjunto de valores em X grupos, com aproximadamente o mesmo número de tuplas em cada um. Para cada grupo de valores, determina a média do número de tuplas para cada valor do grupo. Como estimar N(x) usando um histograma por Comprimento Verifica em que grupo de valores o valor x se encaixa. N(x) = média do número de tuplas associado aos valores deste grupo.
 usando um histograma por Comprimento. Verifica em que grupo de valores o valor x se encaixa. N(x) = média do número de tuplas associado aos valores deste grupo.")
49
Histograma por profundidade
9 6 6 2.67 1.80 1.75 1 2 3 4 5 6 7 8 9 10 11 12 13 14 8 tuplas 7 tuplas 12 tuplas 9 tuplas 9 tuplas

50
Histograma por profundidade
Qual a estimativa da quantidade de tuplas com AGE > 13 ? Distribuição uniforme: 3 tuplas 9 Distribuição histograma por largura: 5 tuplas Distribuição histograma por profundidade = 9 tuplas 6 6 2.67 1.80 1.75 1 2 3 4 5 6 7 8 9 10 11 12 13 14 8 tuplas 7 tuplas 12 tuplas 9 tuplas 9 tuplas

51
Exercicio 4 100 tuplas, 20 valores variando de 1 a 98
1. Descrever uma distribuição uniforme para estes dados. 1 3 4 10 6 22 8 31 9 35 2 43 5 47 7 53 58 2 60 7 63 3 65 4 76 78 80 84 93 98 6 2. Fazer um histograma por largura . 3. Estimar o número de tuplas com valores > 30, supondo uma distribuição uniforme dos dados. 4. Estimar o número de tuplas com valores > 30, supondo uma distribuição de acordo com o histograma por largura.

52
100 tuplas, 20 valores variando de 1 a 98
3 4 10 6 22 8 31 9 35 2 43 5 47 7 53 58 2 60 7 63 3 65 4 76 78 80 84 93 98 6 1. Fazer um histograma por profundidade . 2. Estimar o número de tuplas com valores > 30, supondo uma distribuição de acordo com o histograma por largura.

53
Histogramas comprimidos
Histogramas por profundidade produzem melhores estimativas do que histogramas por largura Histogramas comprimidos Mantém contadores para valores mais frequentes (por exemplo idade = 7 e idade = 14) Para os outros valores, mantém um histograma por profundidade (de preferência) ou por largura. Muitos SGBDs utilizam histograma por profundidade, alguns utilizam mesmo histogramas comprimidos.
 Para os outros valores, mantém um histograma por profundidade (de preferência) ou por largura. Muitos SGBDs utilizam histograma por profundidade, alguns utilizam mesmo histogramas comprimidos.")
54
GERAÇÃO DE PLANOS COM MÚLTIPLAS RELAÇÕES
A B C D PLANO POR PROFUNDIDADE À ESQUERDA D B C D A D PLANO BUSHY C C A B A B PLANOS LINEARES

55
Planos por profundidade à esquerda
São os únicos a serem considerados: Quanto maior o número de joins maior o número de planos alternativos. Por isto opta-se por considerar somente os left-deep. Planos left-deep permitem utilizar estratégia pipeline à esquerda com a relação externa. A relação interna é sempre uma relação de base (materializada). Repare que não é possível utilizar pipeline à direita de um join. É sempre necessário que a relação interna esteja disponível em sua integralidade, pois é varrida diversas vezes. No caso de planos left-deep, este problema não acontece, pois o filho à direita de um Join é sempre uma relação de base (materializada).
. Repare que não é possível utilizar pipeline à direita de um join. É sempre necessário que a relação interna esteja disponível em sua integralidade, pois é varrida diversas vezes. No caso de planos left-deep, este problema não acontece, pois o filho à direita de um Join é sempre uma relação de base (materializada).")
Apresentações semelhantes





>")













