Carregar apresentação
A apresentação está carregando. Por favor, espere

1
Query processing in main memory Vitor Silva

2
Bibliografia “Query Processing in Main Memory Database Management Systems” - Tobin J. Lehman & Michael J. Carey, 1986 “Implementation Techniques for Main Memory Database Systems” - David J. deWitt, Randy H. Katz, Frank Olken, Leonard D. Shapiro, Michael R. Stonebraker, David Wood, 1984 “Database Management Systems”, 2nd Edition - Mcgraw Hill “Join Processing in Database with Large Main Memories” - Leonard D. Shapiro, 1986 “A Study of Index Structures for Main Memory Database Management Systems” - Tobin J. Lehman, Michael J. Carey http://en.wikipedia.org/wiki/Relational_algebra

3
O que nos espera (nesta apresentação) Analisar estruturas de dados que permitem colocar a informação em memória para ser processada Procurar explorar alguns algoritmos para quatro operadores de querys Selecção Join Projecção Agregação
 Analisar estruturas de dados que permitem colocar a informação em memória para ser processada Procurar explorar alguns algoritmos para quatro operadores de querys Selecção Join Projecção Agregação")
4
Estruturas de Dados AVL Tree (Árvores Binárias) B+ Tree Array Chained Bucket Hashing Linear Hashing Modified Linear Hashing T Tree
 B+ Tree Array Chained Bucket Hashing Linear Hashing Modified Linear Hashing T Tree")
5
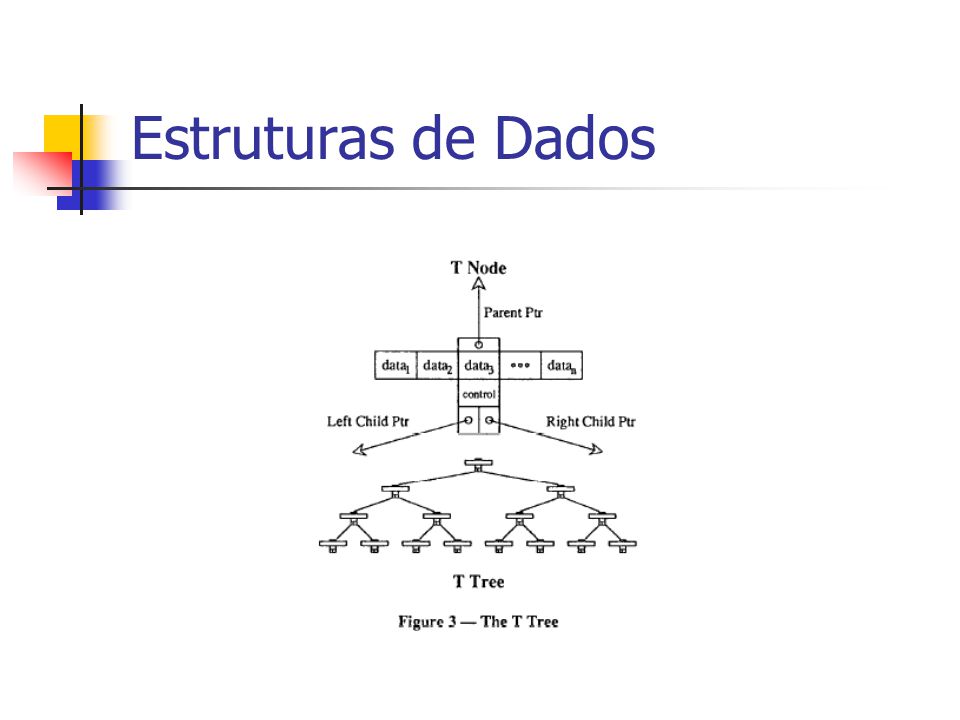
Estruturas de Dados

7
Sistema de Testes PDP VAX 1 l/750 – 2 MB de memória Linguagem C 30.000 elementos unívocos Índices compostos apenas por ponteiros Teste de 60% pesquisas, 20% Inserções, 20% Remoções

8
Velocidade T Tree melhor que AVL Tree e B Tree no conjunto pesquisa, actualização AVL mais rápido que B Tree em pesquisa, mas em actualizações a B Tree é mais rápida Os algoritmos de hashing têm velocidades semelhantes de pesquisa para valores baixos de nós, e enquanto não é necessário redimensionar o directório têm velocidades de actualização iguais Linear Hashing mais lento porque para manter uma utilização de espaço estável perde muito tempo a fazer reorganização de dados Os arrays são ineficazes devido à necessidade de reorganização de dados para manter-se ordenado (1 actualização significa mover ½ array, em média)
")
9
Espaço Arrays ocupam menos espaço AVL Tree ocupam sensivelmente o triplo do espaço dos arrays (para cada ponteiro para dados existem mais dois ponteiros para nós filhos) Chained Bucket Hashing e Modified Linear Hashing ocupa o espaço dos elementos + espaço da tabela de hash (sensivelmente o dobro do espaço do array) Linear Hashing, B Trees, Extendible Hashing and T Trees neste teste ocuparam sensivelmente 1,5 do tamanho do array Extendible Hashing obtém os piores resultados chegando a ocupar cerca de 6 vezes mais que um array devido ao facto de duplicar a tabela de hash de cada vez que um bucket fica cheio
 Chained Bucket Hashing e Modified Linear Hashing ocupa o espaço dos elementos + espaço da tabela de hash (sensivelmente o dobro do espaço do array) Linear Hashing, B Trees, Extendible Hashing and T Trees neste teste ocuparam sensivelmente 1,5 do tamanho do array Extendible Hashing obtém os piores resultados chegando a ocupar cerca de 6 vezes mais que um array devido ao facto de duplicar a tabela de hash de cada vez que um bucket fica cheio")
10
Relação Velocidade/Espaço Extendible Hashing e Modified Linear Hashing têm boa performance para quantidade de nós baixa, mas à custa de uma grande quantidade de espaço Chained Bucket Hashing tem boa performance na pesquisa e na actualização, mas à custa de algum espaço Linear Hashing é simplesmente demasiado lento AVL Tree em tempos de execução de pesquisa e actualização razoáveis mas grandes custos de espaço Arrays têm um tempo de pesquisa razoável e um custo de espaço baixo, mas o tempo de actualização é muito elevado T Trees e B Trees tem o melhor desempenho no conjunto

11
Ponto de Situação Estas estruturas de dados proporcionam a pesquisa de tuplo(s) - um dos operadores básicos de querys – Selecção “ SELECT * FROM Reserves R WHERE R.rname=`Joe‘ ”
 - um dos operadores básicos de querys – Selecção SELECT * FROM Reserves R WHERE R.rname=`Joe‘")
12
Algoritmos de Join Nested Loops Join Hash Join Tree Join Sort Merge Join Tree Merge Join

13
Nested Loops Join Para cada tuplo r Є R Para cada tuplo s Є S Se ri==sj adiciona (r,s) ao resultado O(N²)
 ao resultado O(N²)")
14
Sort Merge Join A ideia base passa por ordenar as duas relações a juntar e depois procurar fundir as duas relações. Ao ordenar os tuplos é mais fácil identificar grupos com o mesmo valor de atributo de join. Ao identificarmos as partições comparamos as partições da primeira relação com as partições iguais na segunda relação O algoritmo começa por pesquisar duas relações R e S, à procura de tuplos cujo valor do atributo de join seja igual. De seguida é feito uma pesquisa com o primeiro tuplo de cada relação. Vai-se avançando na relação R enquanto o tuplo de R for menor que o tuplo de S Analogamente, avança-se na relação S enquanto o valor do atributo de join for menor que o valor de R Vai-se alternando a pesquisa até encontrar os valores pretendidos

15
Tree Merge Join O conceito é similar ao Sort Merge Join, mas com recurso a T Trees de índices

16
Hash Join Similar as sort merge mas baseado em tabelas de hash Se a função de hash for perfeitamente uniforme os buckets de R terão correspondência nos buckets de S

17
Tree Join Conceptalmente similar ao Hash Join, mas com recurso a T Trees

18
Bateria de Testes 1. Variar Cardinalidade – variar a dimensão das relações |R1|=|R2| 2. Variar Cardinalidade da relação interior – variar a dimensão de R2 (|R2| = 1-100% de |R1l, com |R1l = 30,000 elementos) 3. Variar Cardinalidade da relação exterior – variar a dimensão de R1 (|R1l = 1-100% de |R2|, com |R2| = 30,000 elementos) 4. Variar percentagem de duplicados (enviesada) – variar a percentagem de duplicados das duas relações de 0-100% com |R1l=|R2|=20,000 elementos, de distribuição de duplicados enviesada 5. Variar percentagem de duplicados (uniforme) – variar a percentagem de duplicados das duas relações de 0-100% com |R1|=|R2|=20,000 elementos, de distrbuição de duplicados uniforme 6. Variar selectividade de semijoin – variar a selectividade de semijoin entre 1-100% com |R1|=|R2|=30,000 elementos e uma percentagem de duplicados de 50% de distribuição uniforme Foram feitos apenas join de igualdade
 3. Variar Cardinalidade da relação exterior – variar a dimensão de R1 (|R1l = 1-100% de |R2|, com |R2| = 30,000 elementos) 4. Variar percentagem de duplicados (enviesada) – variar a percentagem de duplicados das duas relações de 0-100% com |R1l=|R2|=20,000 elementos, de distribuição de duplicados enviesada 5. Variar percentagem de duplicados (uniforme) – variar a percentagem de duplicados das duas relações de 0-100% com |R1|=|R2|=20,000 elementos, de distrbuição de duplicados uniforme 6. Variar selectividade de semijoin – variar a selectividade de semijoin entre 1-100% com |R1|=|R2|=30,000 elementos e uma percentagem de duplicados de 50% de distribuição uniforme Foram feitos apenas join de igualdade.")
19
Resultado do Nested Loop Join Mesmo com menos elementos nas relações (de 1-20,000) os resultados demonstram que o Nested Loop Join nunca deverá ser considerado como eficaz
 os resultados demonstram que o Nested Loop Join nunca deverá ser considerado como eficaz")
20
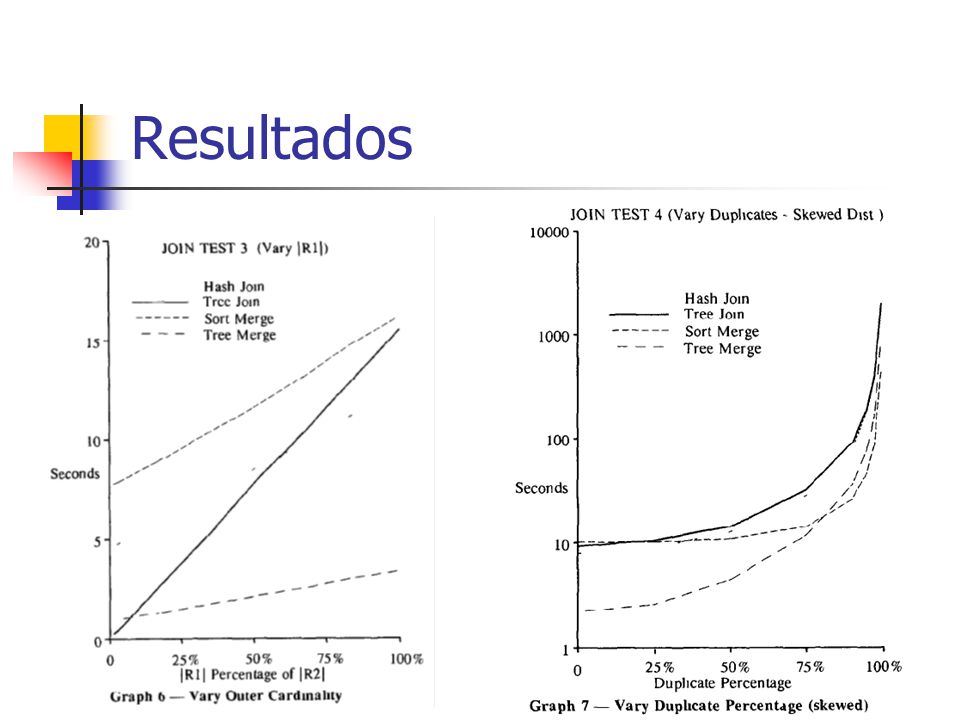
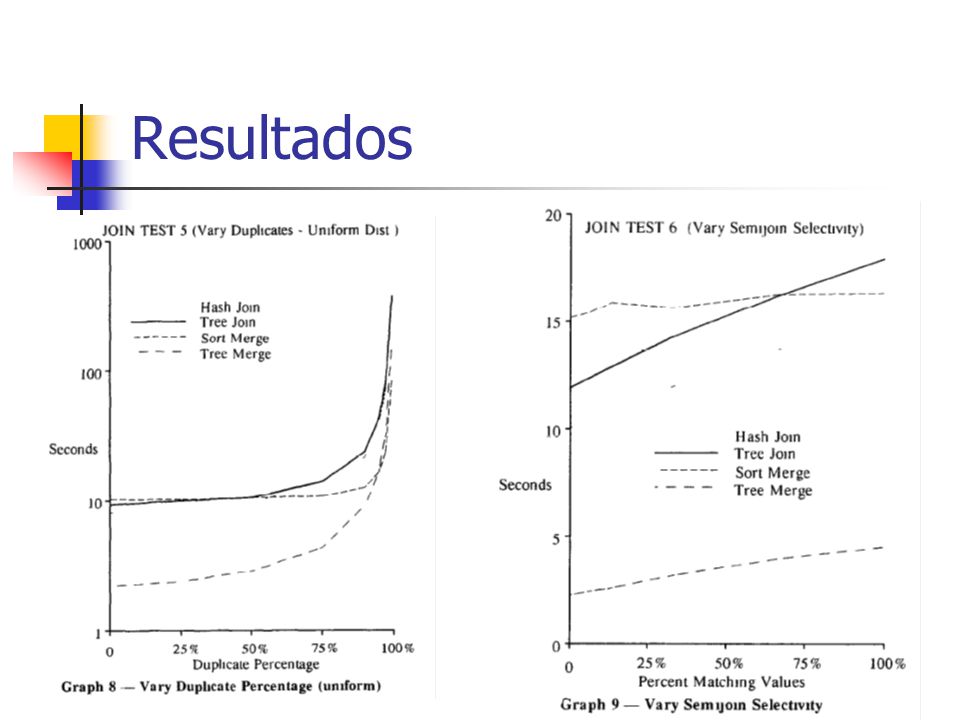
Resultados

23
Resultados algoritmos de Join Se já existirem as àrvores de índices o Tree Merge demonstra ser o algoritmo mais vantajoso Se não existir pelo menos um dos índices ou os dois índices o algoritmo de Hash Join demonstra ser o mais eficaz Excepções: (que confirmam a regra) Se apenas existirem índices numa relação e na outra não, mas esta segunda fôr menos de metade da maior então o T Tree Join é mais rápido que o Hash Join porque o tempo de pesquisa nos tuplos da relação menor é inferior ao tempo de construção e pesquisa da tabela de hash Se a selectividade de semijoin e a percentagem de duplicados forem elevadas a melhor opção é o Sort Merge dado que este lida melhor com grandes volumes de pesquisa
 Se apenas existirem índices numa relação e na outra não, mas esta segunda fôr menos de metade da maior então o T Tree Join é mais rápido que o Hash Join porque o tempo de pesquisa nos tuplos da relação menor é inferior ao tempo de construção e pesquisa da tabela de hash Se a selectividade de semijoin e a percentagem de duplicados forem elevadas a melhor opção é o Sort Merge dado que este lida melhor com grandes volumes de pesquisa")
24
Projecção SELECT DISTINCT R.sid, R.bid FROM Reserves R Critíco: Remoção de duplicados Sort Scan Hashing

25
Resultados

26
Resultados Algoritmos de Projecção No 1º teste não foram inseridos duplicados e o que domina o desempenho dos algoritmos é o tempo de inserção dos elementos nas estruturas de dados (no hashing o crescimento é linear, enquanto o custo do sort scan é O(|R| log |R|)) No 2º teste, ao inserir elementos duplicados, a tabela de hash passa a guardar menos elementos (descarta duplicados) o que leva a que o desempenho seja melhor que o sort scan em que só se eliminam os duplicados após todos os elementos já estarem inseridos e ordenados no array
) No 2º teste, ao inserir elementos duplicados, a tabela de hash passa a guardar menos elementos (descarta duplicados) o que leva a que o desempenho seja melhor que o sort scan em que só se eliminam os duplicados após todos os elementos já estarem inseridos e ordenados no array")
27
Agregação SELECT AVG(S.age) FROM Sailors S O algortimo básico passa por pesquisar em toda a tabela e ir guardando informação adicional que permita calcular o valor final Para querys com grouping novamente pode recorrer-se ao sorting e ao hashing
 FROM Sailors S O algortimo básico passa por pesquisar em toda a tabela e ir guardando informação adicional que permita calcular o valor final Para querys com grouping novamente pode recorrer-se ao sorting e ao hashing")
28
Pontos Finais Uma ideia sobre alguns dos algoritmos que podem implementar três dos operadores de query Existem mais algoritmos (pelo menos de Join) como o Hybrid Hash ou o GRACE Existem critérios que permitem efectuar a escolha dos algortimos (quantidade de tuplos, quantidade de duplicados, entre outros)
 como o Hybrid Hash ou o GRACE Existem critérios que permitem efectuar a escolha dos algortimos (quantidade de tuplos, quantidade de duplicados, entre outros)")
29
Obrigado

Apresentações semelhantes

>")

.>")















