Carregar apresentação
A apresentação está carregando. Por favor, espere

1
Uma Infraestrutura para a
Análise Semântica Uma Infraestrutura para a Análise Semântica

2
Fases do compilador (revisão)
")
3
Análise léxica • Separa o texto de entrada numa seqüência de tokens • Detecta textos de entrada com tokens ilegais Análise sintática • Aplica regras gramaticais • Constrói (por vezes implicitamente) uma árvore de parse com os tokens de entrada • Detecta textos com seqüências de tokens ilegais (erros sintáticos) Cada uma destas fases detecta certos erros de programação mas não todos A última fase da parte frontal (front-end) de um compilador é a análise semântica • Detecta todos os restantes erros do texto de entrada (exceto os erros de concepção do programa e de execução)
 uma árvore de parse com os tokens de entrada. • Detecta textos com seqüências de tokens ilegais (erros sintáticos) Cada uma destas fases detecta certos erros de programação mas não todos. A última fase da parte frontal (front-end) de um compilador é a análise semântica. • Detecta todos os restantes erros do texto de entrada (exceto os erros de concepção do programa e de execução)")
4
Funções do analisador semântico
Executar uma grande quantidade de verificações • todos os identificadores foram declarados • não existência de declarações múltiplas e incompatíveis para um mesmo identificador • determinar os tipos de expressões e variáveis e a sua compatibilidade quando aparecem numa mesma expressão • relações de herança (em linguagens OO) • boa utilização de palavras e identificadores reservados • não existência de métodos com definição múltipla numa classe (em linguagens OO) Os requisitos exatos dependem da linguagem em questão Praticamente todas as linguagens requerem as três primeiras verificações
 • boa utilização de palavras e identificadores reservados. • não existência de métodos com definição múltipla numa classe (em linguagens OO) Os requisitos exatos dependem da linguagem em questão. Praticamente todas as linguagens requerem as três primeiras verificações.")
5
Implementação da análise semântica
A análise semântica é implementada utilizando extensões das gramáticas livres de contexto (GLC) utilizadas pelos analisadores sintáticos. Essas extensões designam-se por definições dirigidas pela sintaxe (syntax-directed definitions). Estas definições são compostas por dois tipos de extensões das GLC: • atributos - valores associados a cada símbolo (terminais e não- -terminais) da gramática
 utilizadas pelos analisadores sintáticos. Essas extensões designam-se por definições dirigidas pela sintaxe. (syntax-directed definitions). Estas definições são compostas por dois tipos de extensões das GLC: • atributos - valores associados a cada símbolo (terminais e não- -terminais) da gramática.")
6
Implementação da análise semântica
Os atributos podem representar uma multiplicidade de propriedades dos símbolos gramaticais, tais como: Tipos das variáveis Valores de constantes e expressões Endereços das variáveis Endereços dos procedimentos e funções • regras ou ações semânticas - cálculos ou outras ações executadas, quando se aplica uma regra gramatical (produção) na análise sintática; Estas ações deverão ser executadas no final ou durante o reconhecimento das regras. Calculam atributos ou executam outras ações.
 na análise sintática; Estas ações deverão ser executadas no final ou durante o reconhecimento das regras. Calculam atributos ou executam outras ações.")
7
Atributos e ações Considere uma produção de uma GLC da forma:
Y→X1 X2 … Xn • Os atributos são valores associados aos símbolos da gramática (nós da árvore de parse). Por exemplo poderão existir os atributos Y.type, X1.val, X2.type, etc. associados aos símbolos da regra anterior. Cada símbolo pode ter vários atributos. • Os terminais obtêm os seus atributos do analisador léxico (valor de uma constante, nome de uma variável, etc.) • As ações são pedaços de código associados à regra (geralmente no fim)
. Por exemplo poderão existir os atributos Y.type, X1.val, X2.type, etc. associados aos símbolos da regra anterior. Cada símbolo pode ter vários atributos. • Os terminais obtêm os seus atributos do analisador léxico (valor de uma constante, nome de uma variável, etc.) • As ações são pedaços de código associados à regra (geralmente no fim)")
8
Atributos e ações Exemplos:
Considere a seguinte regra de uma gramática: N → N digit em que o não-terminal N e o terminal digit possuem um atributo chamado val. Esta regra e a respectiva ação semântica poderia ser escrita como: N1 → N2 digit { N1.val = N2.val × digit.val; } Os índices distinguem apenas as várias instâncias de N dentro da regra. Outro exemplo : Duas regras de uma gramática e respectivas ações R1 → + { print(‘+’); } T R2 T → num { print (num.val); }
; } T R2. T → num { print (num.val); }")
9
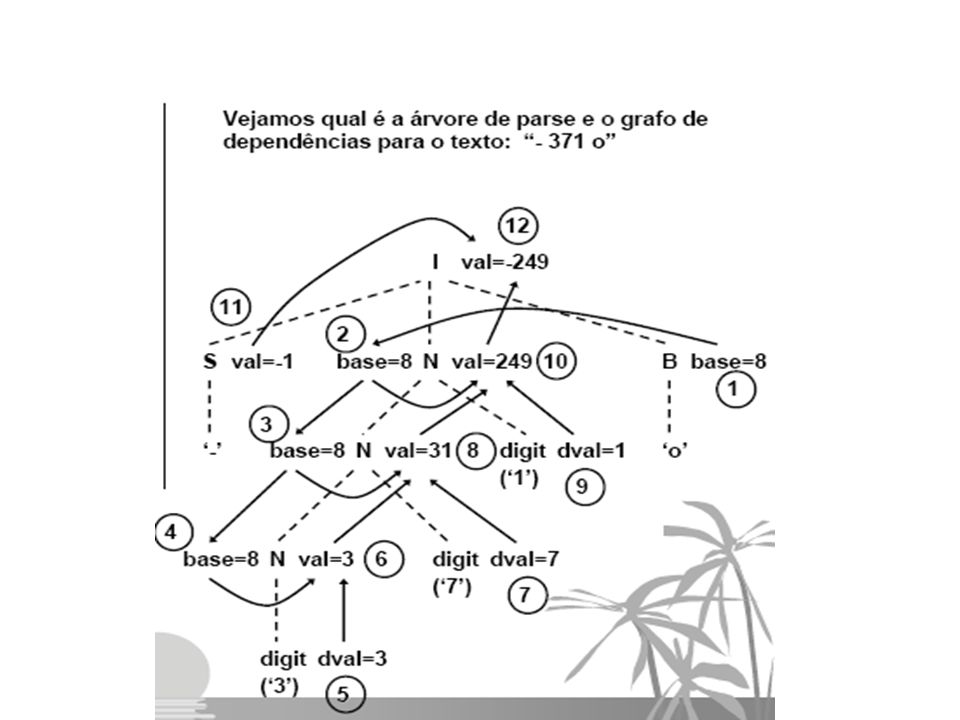
Exemplo 1 Considere-se a seguinte gramática para números inteiros em que os tokens são os dígitos (‘0’ a ‘9’) e os sinais ‘+’ e ‘-’. O objetivo é a determinação do valor de cada inteiro. Para isso associa-se aos não-terminais I, S e N um atributo inteiro val e pressupõe-se que o analisador léxico retorne para o token ‘digit’ um atributo dval (digit value) entre 0 e 9.
 entre 0 e 9.")
10
Exemplo 1 As ações semânticas estabelecem
dependências entre os atributos, indicadas pelas setas, nesta árvore concreta

11
Exemplo 2 Seja agora a seguinte gramática para declarações de variáveis (numa linguagem tipo C). O objetivo é adicionar a uma estrutura de dados externa – a tabela de símbolos – os nomes das variáveis declaradas, juntamente com o seu tipo. Para isso associa-se aos não-terminais T e L um atributo type que pode ter os valores real e integer. Pressupõe-se que o analisador léxico retorna o atributo name para os tokens id. A função insert_var(name, type) insere uma nova variável na tabela de símbolos.
 insere uma nova variável na tabela de símbolos.")
12
Exemplo 2 Considere o seguinte texto e a respectiva
Árvore de parse e execução das ações: “int n1, n2, n3”

13
Atributos sintetizados e herdados
As ações semânticas definem dependências entre os atributos • Se, por exemplo, existir uma ação do tipo a = f(b1, b2, …, bn), onde a e b1 a bn são atributos associados aos símbolos de uma regra, diz-se que a depende dos atributos b1 a bn• Essa dependência pode exprimir-se através de um grafo (de dependências) onde os atributos são nós, e há ramos dirigidos dos atributos usados no cálculo para os atributos dependentes:
, onde a e b1 a bn são atributos associados aos símbolos de uma regra, diz-se que a depende dos atributos b1 a bn• Essa dependência pode exprimir-se através de um grafo (de dependências) onde os atributos são nós, e há ramos dirigidos dos atributos usados no cálculo para os atributos dependentes:")
14
Atributos sintetizados e herdados
• Se na totalidade do conjunto de ações de uma gramática apenas houver atributos que dependam dos atributos dos filhos numa árvore de parse, diz-se que essa gramática (estendida com atributos e ações) é S-attributed e esses atributos dizem-se sintetizados (exemplo 1 atrás). • Se houver dependências entre atributos de símbolos do lado direito das regras (filhos), ou estes dependerem de atributos do não-terminal do lado esquerdo (pai), estes atributos dizem-se herdados. • Se, para os atributos herdados, estes dependerem apenas de atributos à sua esquerda ou do pai, diz-se que essa gramática é L-attributed. (exemplo 2 atrás)
 é S-attributed e esses atributos dizem-se sintetizados (exemplo 1 atrás). • Se houver dependências entre atributos de símbolos do lado direito das regras (filhos), ou estes dependerem de atributos do não-terminal do lado esquerdo (pai), estes atributos dizem-se herdados. • Se, para os atributos herdados, estes dependerem apenas de atributos à sua esquerda ou do pai, diz-se que essa gramática é L-attributed. (exemplo 2 atrás)")
15
Cálculo dos atributos Os atributos são calculados nas ações semânticas. As ações de cálculo só podem ser executadas quando todos os atributos de que dependem já estivem disponíveis As ações de todas as gramáticas S-attributed e de muitas outras que sejam L-attributed podem ser executadas durante a análise sintática pelo parser e sem necessidade da construção explícita da árvore de parse. No caso geral poderá ser necessário construir explicitamente a árvore de parse e o grafo de dependências • Cálculo dos atributos no caso geral: Construir a árvore de parse Construir o grafo de dependências Fazer uma ordenação topológica do grafo de dependências Seguir essa ordenação • Para que seja possível efetuar a ordenação topológica o grafo de dependências terá que ser acíclico.

16
Exemplo Seja novamente a gramática do exemplo anterior, mas agora estendida de modo a indicar a base do número inteiro (octal ou decimal): Regras gramaticais Ações semânticas

18
Ações e atributos durante a análise sintática (top-down)
Praticamente todas as gramáticas S-attributed ou L-attributted são de fácil avaliação durante a análise sintática num parser de descida recursiva top-down

19
Recursividade à esquerda com atributos
Como se sabe, para que seja possível construir um parser top-down de descida recursiva, a respectiva gramática deverá ser LL(1); entre as condições necessárias para isso, destaca-se a não recursividade à esquerda. Existem regras para tornar uma gramática não recursiva à esquerda; mas que fazer, se já existirem ações semânticas associadas à gramática ? Há que transformar também essas ações. Seja uma gramática com as produções (com atributos sintetizados): A1 → A2Y {A1.a = g(A2.a, Y.y} A → X {A.a = f(X.x)} Sem considerar as ações semânticas, a eliminação da recursividade à esquerda conduz a: A → X R R → Y R | ε Considerando-se as ações semânticas tem-se:: A → X {R.i = f(X.x)} R {A.a = R.s} R1 → Y {R2.i = g(R1.i, Y.y)} R2 {R1.s = R2.s} R → ε {R.s = R.i} Os atributos i e s não-terminal R são respectivamente herdado e sintetizado; os atributos a, x e y são iguais aos originais e todos sintetizados
; entre as condições necessárias para isso, destaca-se a não recursividade à esquerda. Existem regras para tornar uma gramática não recursiva à esquerda; mas que fazer, se já existirem ações semânticas associadas à gramática Há que transformar também essas ações. Seja uma gramática com as produções (com atributos sintetizados): A1 → A2Y {A1.a = g(A2.a, Y.y} A → X {A.a = f(X.x)} Sem considerar as ações semânticas, a eliminação da recursividade à. esquerda conduz a: A → X R. R → Y R | ε. Considerando-se as ações. semânticas tem-se:: A → X {R.i = f(X.x)} R {A.a = R.s} R1 → Y {R2.i = g(R1.i, Y.y)} R2 {R1.s = R2.s} R → ε {R.s = R.i} Os atributos i e s não-terminal R são respectivamente herdado e sintetizado; os atributos a, x e y são iguais aos originais e todos sintetizados.")
20
Exemplo de eliminação de recursividade
Relativamente ao caso anterior, vejamos como seria calculado o último atributo a, associado a A, se na árvore de parse aparecesse alguma forma sentencial X Y1 Y2:

21
Cálculo de atributos sintetizados em parsers bottom-up
Os parsers bottom-up mantêm uma stack onde vão sendo armazenando terminais e não-terminais. Quando os n símbolos do topo da stack coincidem com a parte direita de alguma regra gramatical, podem ser substituídos pelo símbolo da parte esquerda (efetua-se uma redução). Nas reduções são executadas as ações semânticas. Para tanto a stack do parser é estendida para incorporar os atributos associados a cada símbolo; (cada elemento da stack pode ser uma estrutura com vários campos).
. Nas reduções são executadas as ações semânticas. Para tanto a stack do parser é estendida para incorporar os atributos associados a cada símbolo; (cada elemento da stack pode. ser uma estrutura com vários campos).")
22
Os atributos sintetizados dependem apenas dos atributos dos filhos, numa árvore de parse.
Os filhos, na aplicação de uma regra sintática, estão no topo da stack do parser.

23
Exemplo Cálculo de expressões de dígitos Produções Ações semânticas

24
Implementação de ações a meio em parsers bottom-up
Nos esquemas de tradução aparecem ações semânticas no meio das produções. Num parser bottom-up só é possível executar as ações semânticas quando de uma redução de uma regra gramatical. Como se implementam então as execuções destas ações semânticas ? Com a introdução de novos não-terminais marcadores. Gramática e semântica para a escrita pósfixa de expressões

25
Atributos herdados em parsers bottom-up
Certos atributos herdados podem facilmente ser implementados num parser bottom-up • Num parser bottom-up uma regra do tipo A → XY é aplicada quando na stack do parser já existem os símbolos X e Y (este no topo); eles são então substituídos pelo símbolo A. • No entanto quando o símbolo Y é construído (através de reduções na sua sub-árvore), já se encontram disponíveis quaisquer atributos sintetizados de X (na stack do parser). • Estes atributos podem então ser herdados por um ou mais atributos de Y: por exemplo pela regra Y.i = X.s, em que i é um atributo herdado de Y e s um atributo sintetizado de X
; eles são então substituídos pelo símbolo A. • No entanto quando o símbolo Y é construído (através de reduções na sua sub-árvore), já se encontram disponíveis quaisquer atributos sintetizados de X (na stack do parser). • Estes atributos podem então ser herdados por um ou mais atributos de Y: por exemplo pela regra Y.i = X.s, em que i é um atributo herdado de Y e s um atributo sintetizado de X.")
26
Consideremos novamente a gramática para declarações dos exemplos 3 e 4
agora num esquema de tradução: Produções Ações semânticas Produções Ações semânticas

27
A seqüência de ações que um parser bottom-up executaria para a entrada “float p, q, r”é mostrada a seguir:

28
Análise Semântica: Verificação de tipos (type checking)
Sistemas de tipos Um sistema de tipos é uma coleção de regras para associar expressões de tipos às várias partes de um programa. Os sistemas de tipos podem ser especificados através de definições dirigidas pela sintaxe, ou seja com atributos e ações semânticas. As regras definidas num sistema de tipos, são regras que podem ser lidas em linguagem corrente como: • “Se ambos os operandos dos operadores aritméticos de adição, subtração e multiplicação forem do tipo inteiro, então o resultado dessa operação é do tipo inteiro”; • “O resultado do operador unário '&' é o endereço do seu operando; se o tipo do operando for " …", o tipo do resultado é "apontador para …" “. A expressão "apontador para …" é uma expressão de tipos (operação sobre tipos).
.")
29
Conversão entre tipos Muitas linguagens de programação definem regras para a conversão automática de um tipo de um operando, de modo a torná-lo compatível com o seu contexto. Estas conversões automáticas são efetuadas pelo compilador, afirma-se, então, que houve uma conversão de tipos. • Geralmente numa expressão como "x + i", em que x é do tipo 'real' e i do tipo 'inteiro', a variável i sofre uma conversão para real antes de se efetuar a adição. Muitas linguagens de programação definem casos nos quais o programador pode explicitamente converter o tipo de dados de uma expressão num outro, utilizando operadores especiais de conversão (operadores de cast). Estes operadores são estaticamente tipados, uma vez que possuem tipos de entrada e saída bem definidos susceptíveis de serem verificados pelo compilador. • Exemplo em C: p = (table *) calloc(n, sizeof(table)); O operador table* é um cast
. Estes operadores são estaticamente tipados, uma vez que possuem tipos de entrada e saída bem definidos susceptíveis de serem verificados pelo compilador. • Exemplo em C: p = (table *) calloc(n, sizeof(table)); O operador table* é um cast.")
30
Expressões de tipos Uma expressão de tipos é qualquer expressão cujo resultado é um tipo: pode ser um tipo básico, ou o resultado da aplicação de um operador, designado por construtor de tipo, a qualquer outra expressão de tipos. Os tipos básicos e construtores dependem da linguagem. Tipos básicos(primitivos): são normais os seguintes - boolean, char, integer, real, void; um tipo básico especial é o tipo 'type_error', utilizado para marcar situações de erro durante a verificação de tipos. Certas linguagens permitem associar um nome (identificador) a tipos definidos pelo utilizador; para essas linguagens os nomes que designam tipos são também expressões de tipos. Um construtor de tipo aplicado a uma expressão de tipos é uma expressão de tipos.
: são normais os seguintes - boolean, char, integer, real, void; um tipo básico especial é o tipo type_error , utilizado. para marcar situações de erro durante a verificação de tipos. Certas linguagens permitem associar um nome (identificador) a tipos definidos pelo utilizador; para essas linguagens os nomes que designam tipos são também expressões de tipos. Um construtor de tipo aplicado a uma expressão de tipos é uma expressão de tipos.")
31
Construtores de tipos Arrays - Seja T uma expressão de tipos; então array(I, T) é uma expressão que representa o tipo de um array com elementos do tipo T e conjunto de índices I; geralmente I é um subconjunto (subrange) dos inteiros. Subrange – Seja T um tipo simples ordenado; então subrange(min, max, T) é uma expressão que representa o conjunto dos valores t: {t T e min ≤ t ≤ max} Produtos - Se T1 e T2 forem expressões de tipos então o produto cartesiano T1 × T2 é uma expressão de tipos; o produto cartesiano é associativo à esquerda; o produto cartesiano de 2 tipos pode representar o tipo de um par de operandos. Registros - Este construtor associa nomes e tipos dos campos de um registo ou estrutura; • Exemplo: record((address × integer) × (lexeme × array(1..15, char))) define um tipo registo com 2 campos (address e lexeme) do tipo integer e array de char (com posições de 1 a 15
 é uma expressão que representa o tipo de um array com elementos do tipo T e conjunto de índices I; geralmente I é um subconjunto (subrange) dos inteiros. Subrange – Seja T um tipo simples ordenado; então subrange(min, max, T) é uma expressão que representa o conjunto dos valores t: {t T e min ≤ t ≤ max} Produtos - Se T1 e T2 forem expressões de tipos então o produto cartesiano T1 × T2 é uma expressão de tipos; o produto cartesiano é associativo à esquerda; o produto cartesiano de 2 tipos pode representar o tipo de um par de operandos. Registros - Este construtor associa nomes e tipos dos campos de um registo ou estrutura; • Exemplo: record((address × integer) × (lexeme × array(1..15, char))) define um tipo registo com 2 campos (address e lexeme) do tipo integer. e array de char (com posições de 1 a 15.")
32
Construtores de tipos (cont.)
A expressão (de tipos) apontador(T), em que T também é uma expressão, designa um tipo que é “um apontador para um objeto de tipo T”. Funções - Associa-se também um tipo às funções. O respectivo construtor é normalmente notado por →. O tipo de função escreve-se D → C, em que D é o tipo do domínio da função e C o do contradomínio (ou resultado); quando os parâmetros de entrada são mais do que um, o tipo do domínio é um produto cartesiano. • Exemplo: A seguinte função em Pascal - function f (a, b : char) : ↑integer; tem tipo: char × char → pointer(integer) • Em Lisp é possível definir funções que tomam funções como argumento e retornam outra função; assim em Lisp é legal o tipo: (integer → integer) → (integer → integer) Variáveis - Em certas situações pode haver necessidade de ter, em expressões de tipos, variáveis que representam tipos.
 apontador(T), em que T também é uma expressão, designa um tipo que é um apontador para um objeto de tipo T . Funções - Associa-se também um tipo às funções. O respectivo construtor é normalmente notado por →. O tipo de função escreve-se D → C, em que D é o tipo do domínio da função e C o do. contradomínio (ou resultado); quando os parâmetros de entrada são mais do que um, o tipo do domínio é um produto cartesiano. • Exemplo: A seguinte função em Pascal - function f (a, b : char) : ↑integer; tem tipo: char × char → pointer(integer) • Em Lisp é possível definir funções que tomam funções como argumento. e retornam outra função; assim em Lisp é legal o tipo: (integer → integer) → (integer → integer) Variáveis - Em certas situações pode haver necessidade de ter, em. expressões de tipos, variáveis que representam tipos.")
33
Representação dos tipos com construtores
Os tipos podem ser representados por árvores, onde as folhas serão os tipos básicos e os nós internos representam os construtores.

34
Equivalência estrutural de tipos
Em muitas situações, na verificação de tipos, é necessário saber se dois tipos (ou o que está armazenado no atributo type) são iguais. Muitas linguagens permitem construir novos tipos e nomeá-los. Muitas vezes nomes diferentes podem representar o mesmo tipo. Em algumas linguagens, identificadores que têm tipos de nome diferente, mas que representam a mesma construção a partir dos tipos básicos, podem ser operados como se tratassem do mesmo tipo. Necessita-se pois de uma ferramenta para testar a equivalência de tipos; essa ferramenta poderá ser a seguinte função recursiva:
 são iguais. Muitas linguagens permitem construir novos tipos e nomeá-los. Muitas vezes nomes diferentes podem representar o mesmo tipo. Em algumas linguagens, identificadores que têm tipos de nome diferente, mas que representam a mesma construção a partir dos tipos básicos, podem ser operados como se tratassem do mesmo tipo. Necessita-se pois de uma ferramenta para testar a equivalência de tipos; essa ferramenta poderá ser a seguinte função recursiva:")
36
Implementação da verificação de tipos
A verificação de tipos faz-se normalmente através de regras semânticas, que devem implementar o sistema de tipos da linguagem, e de um atributo (type) associado aos não-terminais da gramática que contém o resultado de uma expressão de tipos. Em muitos casos esse atributo pode ser sintetizado, o que torna muito fácil executar a verificação de tipos juntamente com a análise sintática. Em muitas linguagens os identificadores devem ser declarados antes da sua utilização e nessas declarações indicam-se os respectivos tipos. Em outros casos os tipos são inferidos da forma como o identificador é escrito (Fortran, Basic).
 associado aos não-terminais da gramática que contém o resultado de uma expressão de tipos. Em muitos casos esse atributo pode ser sintetizado, o que torna muito fácil executar a verificação de tipos juntamente com a análise sintática. Em muitas linguagens os identificadores devem ser declarados antes da sua utilização e nessas declarações indicam-se os respectivos tipos. Em outros casos os tipos são inferidos da forma como o identificador é escrito (Fortran, Basic).")
37
Uma linguagem simples e a sua verificação de tipos
Detalhamento da verificação de tipos para uma linguagem simples com a seguinte gramática: Esta linguagem produz programas compostos por declarações (D), seguidas de instruções (S) As declarações associam tipos (T) a identificadores; possui 3 tipos básicos (char, integer e boolean), além de apontadores e arrays. Os arrays são declarados com um único valor de índice, assumindo-se que este vai de 1 até esse valor; assim a declaração: array[256] of char corresponde a um array de 256 caracteres com índices que vão de 1 a 256. No sistema de tipos a implementar são usados ainda os nomes simples type_error, para assinalar erros e o valor void, associado às instruções sem erro. Como na 1ª produção o D aparece antes de S, todas as declarações deverão ser feitas antes das instruções. Um programa gerado por esta gramática poderá ser: key : integer; result : boolean; result = key < 1999
, seguidas de instruções (S) As declarações associam tipos (T) a identificadores; possui 3 tipos básicos (char, integer e boolean), além de apontadores e arrays. Os arrays são declarados com um único valor de índice, assumindo-se que este vai de 1 até esse valor; assim a declaração: array[256] of char. corresponde a um array de 256 caracteres com índices que vão de 1 a 256. No sistema de tipos a implementar são usados ainda os nomes simples type_error, para assinalar erros e o valor void, associado às instruções sem erro. Como na 1ª produção o D aparece antes de S, todas as declarações deverão ser feitas antes das instruções. Um programa gerado por esta gramática poderá ser: key : integer; result : boolean; result = key <")
38
Ações semânticas para as declarações
Durante as declarações vão-se tomando nota dos tipos dos identificadores que nelas aparecem. Associado a todos os compiladores existe sempre uma tabela de símbolos, onde é colocado o nome de todos os identificadores definidos pelo usuário. Poderá caber ao analisador léxico a tarefa de ir preenchendo a tabela de símbolos com os identificadores que vai descobrindo, retornando como atributo um apontador ou índice do local onde o identificador ficou armazenado na tabela. Sempre que se descobre nova informação sobre um identificador, essa informação deve ser adicionada à respectiva entrada na tabela de símbolos. É o que acontece neste esquema quando se descobre o tipo de um identificador numa declaração.

39
Vamos associar a cada não-terminal um atributo type para tomar nota do respectivo tipo.
Conforme afirmado anteriormente, os identificadores vêm do analisador léxico com um atributo (entry) que permite o acesso à sua entrada na tabela de símbolos. A função addtype( ), usada nas ações semânticas, preenche um campo de uma entrada da tabela de símbolos onde deverá estar o respectivo tipo. O terminal num vem do analisador léxico com o atributo val, que contém o seu valor.
 que permite o acesso à sua entrada na tabela de símbolos. A função addtype( ), usada nas ações semânticas, preenche um campo de uma entrada da tabela de símbolos onde deverá estar o respectivo tipo. O terminal num vem do analisador léxico com o atributo val, que contém o seu valor.")
40
Verificação dos tipos de expressões
Durante as declarações apenas são verificados os tipos das variáveis. Já é possível, nesse momento, identificar alguns erros, como as declarações múltiplas. Por exemplo, se na tabela de símbolos já existir um tipo associado ao identificador, a função addtype( ) poderá identificar esse erro. É nas expressões onde é mais necessária a verificação de tipos.
 poderá identificar esse erro. É nas expressões onde é mais necessária a verificação de tipos.")
41
No esquema aqui apresentado faz-se uso de uma função lookup( ) que retorna o tipo associado a um identificador, presente na tabela de símbolos. Quando o atributo type ganha o valor type_error, poder-se-á aí emitir uma mensagem de erro. Os terminais (tokens) poderão trazer do analisador léxico informação acerca da sua posição no texto fonte, que poderá ser aproveitada para a emissão das mensagens de erro.
 poderão. trazer do analisador léxico. informação acerca da sua posição no texto fonte, que poderá ser aproveitada para a emissão das mensagens de erro.")
42
Verificação de funções
A declaração de funções de somente um parâmetro pode ser feita acrescentando-se a seguinte regra para tipo: T → T1 ‘→’ T2 A seta que aparece entre os não terminais é um terminal da linguagem; uma declaração de uma função, com essa regra poderia ser: func : char → integer que informa que func é uma função de argumento de tipo char com resultado de tipo inteiro. Para permitir a chamada de funções acrescenta-se mais uma regra às expressões, ou seja: E → E1 (E2)
")
43
As regras semânticas de verificação de tipos poderiam ser:

44
Overloading de funções e operadores
Diz-se que uma função ou operador está overloaded se tiver significados diferentes, dependentes do contexto. Exemplos: Uma função ou operador overloaded, em cada situação, só poderá ter um único significado; não são permitidas ambiguidades. A resolução de uma situação de overloading designa-se por identificação de operadores.

45
Resolução de situações de overloading
Muitas vezes a situação de overloading resolve-se apenas pelo exame dos tipos dos operandos. Exemplo: Nesses casos os esquemas de verificação de tipos já abordados anteriormente servem para a resolução da situação de overloading presente.

46
Resolução de situações de overloading (cont.)
Outras vezes não é suficiente examinar apenas os tipos dos operandos ou argumentos das funções. Exemplo: Suponhamos que o operador * pode ter os seguintes três significados: * integer × integer → integer (1) * integer × integer → complex (2) * complex × complex → complex (3) O tipo do operador * na expressão com dois operandos inteiros não pode ser determinado conhecendo apenas os operandos.
 * integer × integer → complex (2) * complex × complex → complex (3) O tipo do operador * na expressão com dois operandos inteiros não pode ser determinado conhecendo apenas os operandos.")
47
Resolução de situações de overloading (cont.)
Nesses casos, associa-se às expressões, não apenas um único tipo, mas sim um conjunto de tipos possíveis. O símbolo inicial para expressões (ou outros símbolos intermédios definidos na gramática), deverá ter associado um conjunto singular (um único tipo); caso contrário assinala-se um erro de tipos. Assim, as ação semânticas associadas a regras do tipo E → E1 op E2 que eram { E.type = (E1.type == t && E2.type == t) ? t : type_error } deverá ser substituída por outras regras que consigam determinar o conjunto dos possíveis tipos associados a cada expressão.
, deverá ter associado um conjunto singular. (um único tipo); caso contrário assinala-se um erro de tipos. Assim, as ação semânticas associadas a regras do tipo. E → E1 op E2 que eram. { E.type = (E1.type == t && E2.type == t) t : type_error } deverá ser substituída por outras regras que consigam determinar. o conjunto dos possíveis tipos associados a cada expressão.")
48
Resolução de situações de overloading (cont.)
Deve-se ter para a regra anterior: E’ → E {E’.types = E.types} … E → id {E.types = {lookup(id.entry)} } E → E1 op E2 { E.types = {todos os t | s1 E1.types e s2 E2.types e s1 × s2 → t op.types } } Ou seja: Se s1 é um dos tipos de E1.types e s2 um dos tipos de E2.types e s1 × s2 → t uma das possibilidades do operador op, então t é um dos tipos de E.types. Aqui o conjunto vazio denota um erro de tipos. Este conjunto de regras semânticas não garante a singularidade de E’.types.
} } E → E1 op E2 { E.types = {todos os t | s1 E1.types e s2 E2.types e s1 × s2 → t op.types } } Ou seja: Se s1 é um dos tipos de E1.types e s2 um dos tipos de E2.types e s1 × s2 → t uma das possibilidades do operador op, então t é um dos tipos de E.types. Aqui o conjunto vazio denota um erro de tipos. Este conjunto de regras semânticas não garante a singularidade de. E’.types.")
49
Exemplo Aplicação das regras anteriores (ou similares) a expressões, para determinação do seu conjunto de tipos.

50
Geração do Código Intermediário
O gerador de código intermediário será acionado quando o programa for analisado léxica, sintática e semanticamente, e estiver correto do ponto de vista das três análises citadas. Neste ponto, finda-se a parte de análise e inicia-se o processo de síntese. Para essa geração, deve-se percorrer a árvore em profundidade (depth first), para que o código seja gerado das folhas para os nós. A geração de código se dá através do uso de quádruplas, ou seja, quatro campos que já deixam o código numa linguagem bem acessível para a posterior tradução para código de máquina. Os quatro campos são: Operador, Operando 1, Operando 2 e Resultado. Além disso, tem-se um quinto campo, que guarda a linha da quádrupla, a qual será útil para endereços que necessitem de resolução mais adiante no processo (endereços não resolvidos). Por exemplo, x:=(a+c)*(d-10);
, para que o código seja gerado das folhas para os nós. A geração de código se dá através do uso de quádruplas, ou seja, quatro campos que já deixam o código numa linguagem bem acessível para a posterior tradução para código de máquina. Os quatro campos são: Operador, Operando 1, Operando 2 e Resultado. Além disso, tem-se um quinto campo, que guarda a linha da quádrupla, a qual será útil para endereços que necessitem de resolução mais adiante no processo (endereços não resolvidos). Por exemplo, x:=(a+c)*(d-10);")
51
Geração do Código Intermediário
x:=(a+c)*(d-10); forneceria a seguinte tabela de código intermediário:
*(d-10); forneceria a seguinte tabela de código intermediário:")
52
Geração do Código Intermediário
Com expressões aritméticas ou booleanas, devem ser usadas variáveis temporárias, para guardarem resultados de cálculos intermediários. Para as construções if e while deve-se manter saltos (ou jumps GOTO), para que determinados trechos de código possam ser evitados no momento da execução. Ainda no caso do while, deve-se ter um salto para o teste da condição de repetição caracterizando assim o loop dessa estrutura. Na próxima tabela, pode-se ver o resultado da geração de código intermediário para o exemplo de programa dado, com todos os aspectos acima citados:
, para que determinados trechos de código possam ser evitados no momento da execução. Ainda no caso do while, deve-se ter um salto para o teste da condição de repetição caracterizando assim o loop dessa estrutura. Na próxima tabela, pode-se ver o resultado da geração de código intermediário para o exemplo de programa dado, com todos os aspectos acima citados:")
53
Geração do Código Intermediário
:

54
Geração do Código Objeto
O gerador de código objeto é a última parte de um compilador. Contudo, é muito comum existir otimizações de código entre o código intermediário e o código objeto. A tarefa central do gerador de código é transformar uma especificação de código intermediário vinda da etapa anterior para uma especificação de código assembly, para poder ser executado no processador do computador. O código intermediário disponibiliza um conjunto de quádruplas, com as informações de label, operador, operandos e resultado. No gerador de código objeto as quádruplas são geradas sempre no mesmo formato, ou seja, uma quádrupla: + x y _temp1.

55
Geração do Código Objeto
+ x y _temp1 sempre fará a soma de x com y e guardará esse resultado em _temp1. Sendo assim, pode-se estabelecer um conjunto de mnemônicos aceitos pela linguagem assembly, que representam cada tipo de quádrupla do código intermediário. Os conjuntos de mnemônicos, bem como a quem se referem, são mostrados a seguir:

56
Geração do Código Objeto
: Geração do Código Objeto

Apresentações semelhantes