Carregar apresentação
A apresentação está carregando. Por favor, espere

1
Davi de Andrade Lima Castro RA: 107072

2
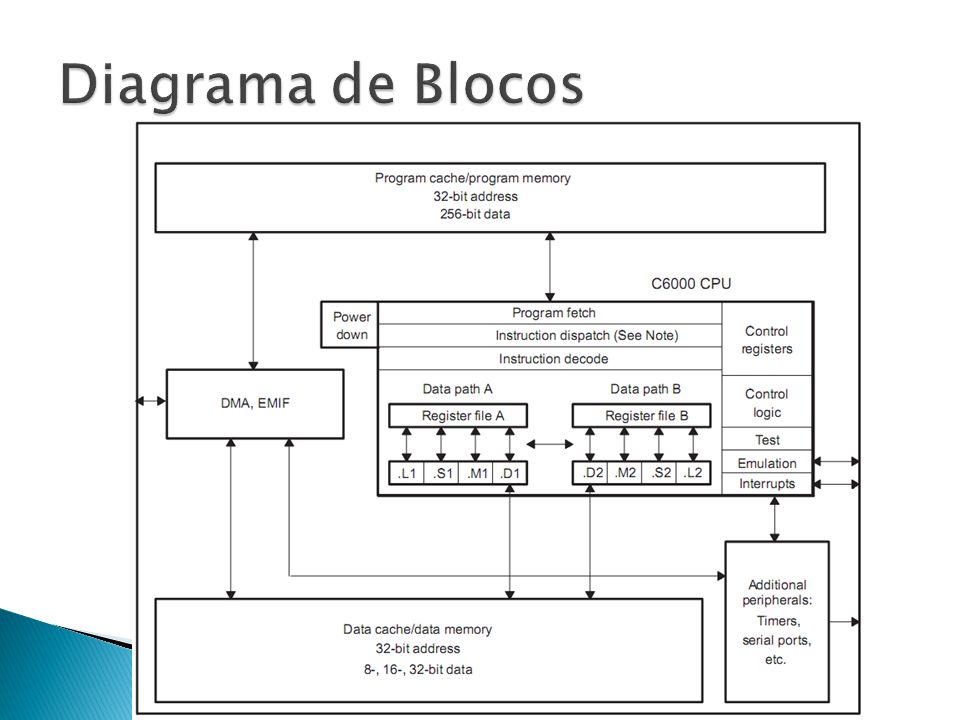
A plataforma C6000: ◦ Ponto-fixo: C62x C64 / C64x+ ◦ Ponto-flutuante: C67x / C67x+ ◦ Arquitetura VLIW: VelociTI ◦ Plataforma de Alto Desempenho da Texas Instruments

3
VLIW: ◦ Instruções de 32-bits ◦ 8 instruções por vez ◦ Execução Serial ou Paralela de cada instrução do pacote Oito Unidades Funcionais: dois multiplicadores e seis unidades de lógica e aritmética (ALUs) Execução condicional de cada instrução 32 registradores de 32-bits Datapath de 32-bits / 40-bits Operações em ponto-flutuante – Simples e Duplo
 Execução condicional de cada instrução 32 registradores de 32-bits Datapath de 32-bits / 40-bits Operações em ponto-flutuante – Simples e Duplo")
4
Arquitetura do tipo Harvard Arquitetura do tipo load-store, somente certas instruções acessam a memória, enquanto todas as outras operam somente nos registradores Suporte a dados de 8/16/32-bits Endereçamento Circular

6
Dois datapaths ◦ Dois Bancos de Registradores ◦ Dois grupos de 4 Unidades Funcionais Memória Registradores ◦ 2x 32-bits MEM => Registr. ◦ 1x 32-bits Registr. => MEM Registradores de Controle: ◦ Program Counter ◦ Modo de Endereçamento

7
Dois bancos, um para cada datapath, ambos com 16 registradores de 32-bits 8 portas de escrita ao todo => 8 escritas em um mesmo ciclo Suporte a 8-bits/16-bits: ◦ Instruções que operam em apenas 8/16-bits dos registradores! Suporte a 40-bits/64-bits: ◦ Par de registradores Cruzamento de dados entre datapaths

8
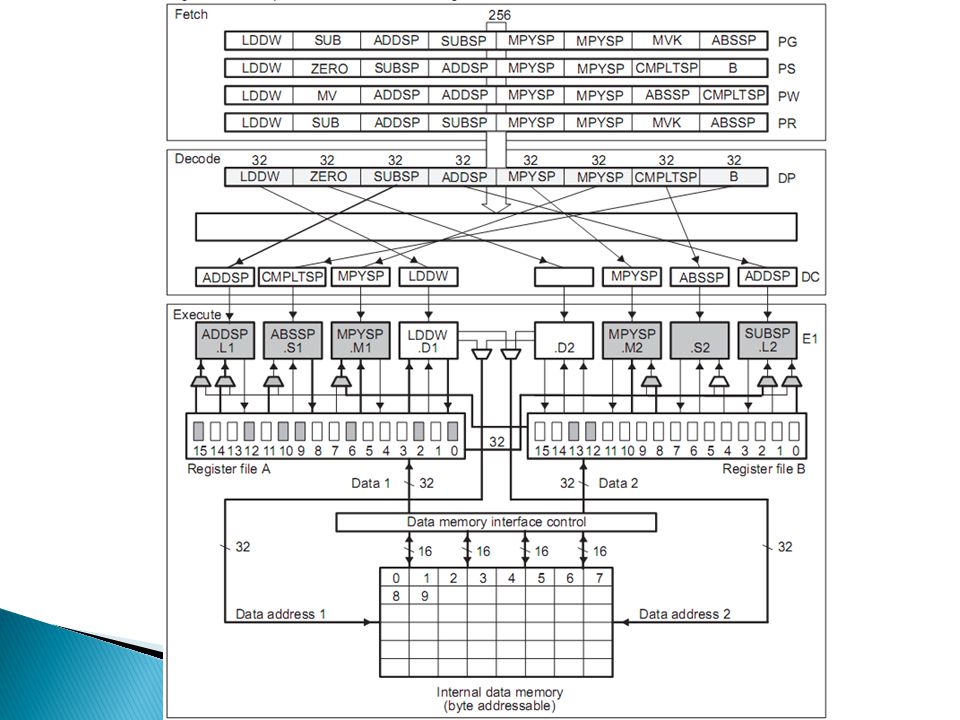
.L ◦ ULA 32-bits Inteiro ◦ Aritiméticas Ponto-Flutuante ◦ Conversões Ponto Fixo Ponto Flutuante .S ◦ ULA 32-bits Inteiro ◦ Branches ◦ Acesso aos Registradores de Controle (.S2) .M ◦ Multiplicações. Ponto fixo e flutuante .D ◦ Cálculo de Endereços => responsáveis por load e store.

9
Pacote de Busca: ◦ 8x Instruções de 32-bits = 256-bits ◦ “Bit de Paralelismo”

10
Pacote de Execução: ◦ De 1 a 8 em um mesmo Pacote de Busca

11
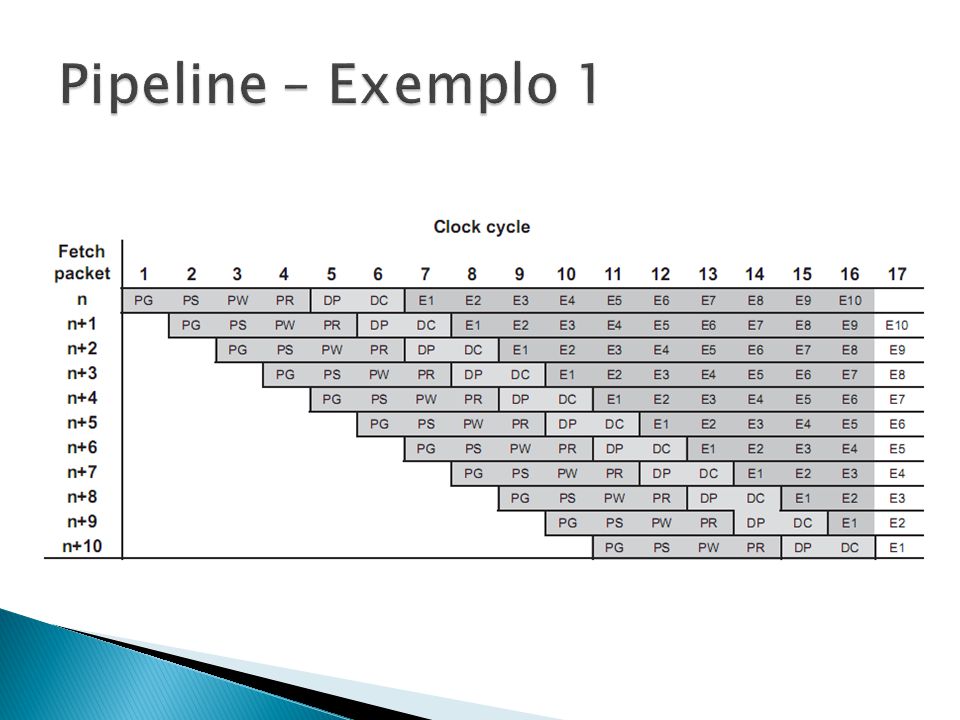
Busca ◦ 4 Estágios Decodificação ◦ 2 Estágios Execução ◦ Depende da instrução

12
PG: é gerado o endereço de programa PS: o endereço de programa é enviado à memória PW: a leitura na memória de programa ocorre PR: o Pacote de Busca é recebido ◦ O Pacote de Busca, como um todo, passa pelos 4 estágios.

13
DP: despacho de instruções. É neste estágio que o Pacote de Busca é dividido em Pacotes de Execução DC: decodifica informações sobre registradores e caminhos de dados ◦ As instruções passam por estes estágios em conjunto num mesmo Pacote de Execução!

14
E1 a E10. Varia entre instruções.

18
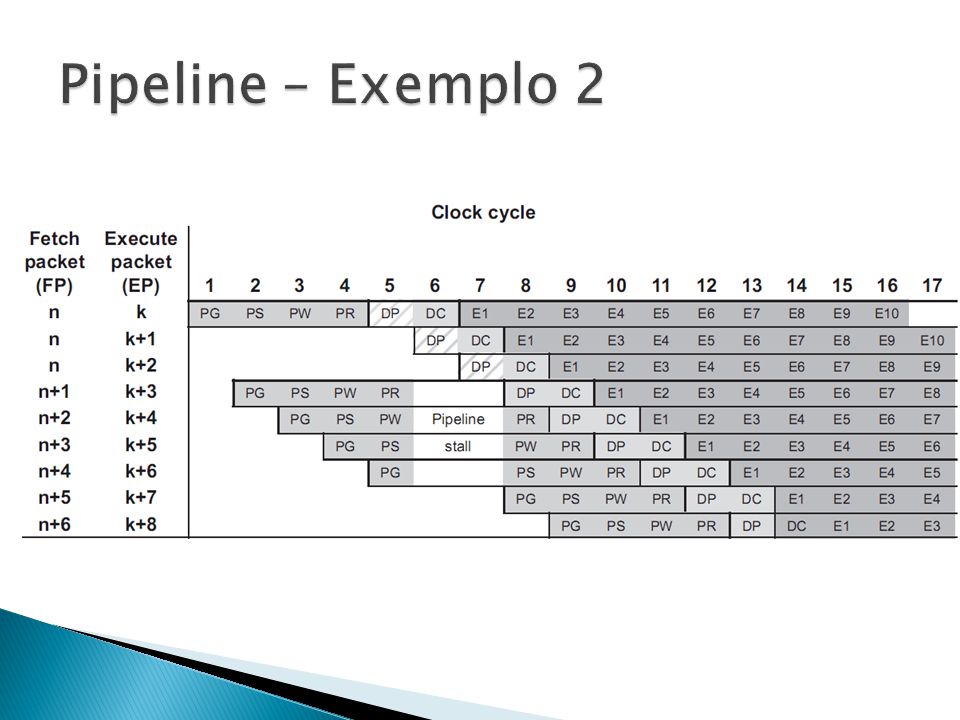
Branch termina de executar no E1 Neste mesmo ciclo o endereço alvo já se encontra no estágio PG, porém o pacote alvo tem ainda 5 estágios até iniciar o E1

19
Grande responsabilidade do programador/compilador: ◦ Extração Estática de Paralelismo (VLIW) ◦ Verificação de Dependência de Dados A arquitetura não avalia nada dinamicamente! ◦ Conhecimentos dos detalhes da arquitetura LDDW.D1 *A0−−[4],B5:B4 || ADDSP.L1 A9,A10,A12 || SUBSP.L2X B12,A2,B12 || MPYSP.M1X A6,B13,A11 || MPYSP.M2 B5,B13,B11 || ABSSP.S1 A12,A15

20
DSP programming: C versus Assembly ◦ “Kernel” codes: menores e mais executados Proposta Texas: ◦ Compilador C, Otimizador Assembly, Assembler, Linker, Depuração ◦ C para a maior parte ◦ Assembly nos trechos críticos

21
Controlador DMA Host-Port Interface ◦ Porta de acesso a um processador host EMIF ◦ Interface de memória externa, com suporte a diferentes tecnologias, SDRAM, SRAM, e outras Timers Gerenciador de Interrupções Lógica de Power-Down entre outros

22
VLIW Trade-off: ◦ Hardware “simples” (x) Compilador Complexo Ponto-Fixo (x) Ponto Flutuante: ◦ C64x (x) C67x Importância dos DSPs
 Compilador Complexo Ponto-Fixo (x) Ponto Flutuante: ◦ C64x (x) C67x Importância dos DSPs")
Apresentações semelhantes