Carregar apresentação
A apresentação está carregando. Por favor, espere

1
SPSS Curso Introdutório Profa. Dra. Ana Alayde Werba Saldanha
Universidade Federal da Paraíba

2
Análise de Dados recorrendo ao SPSS
1. CONCEITOS ELEMENTARES DE ESTATÍSTICA - CONCEITOS USUAIS - ESTUDO DAS VARIÁVEIS - ESCALAS DE MEDIDA 2. O QUE É UMA MATRIZ DE DADOS 3. MANIPULAÇÃO DE ARQUIVOS - ABRIR UMA MATRIZ DE DADOS JÁ EXISTENTE - GUARDAR OS DADOS - GUARDAR OU ABRIR ARQUIVOS CONTENDO RELATÓRIOS DE ANÁLISES - EDIÇÃO DE MATRIZES DE DADOS - CRIAR UMA MATRIZ DE DADOS - DEFINIÇÃO DAS VARIÁVEIS - PREENCHER A MATRIZ DE DADOS - EXCLUIR UMA VARIÁVEL OU UM CASO - INSERIR UMA NOVA VARIÁVEL NO MEIO DE VARIÁVEIS JÁ EXISTENTES 4. TRANSFORMAÇÃO DE DADOS - CALCULO ENTRE VARIÁVEIS

3
Análise de Dados recorrendo ao SPSS
RECODIFICAÇÃO DE VARIÁVEIS - RECODIFICAR UMA VARIÁVEL - RECODIFICAÇÃO NA VARIÁVEL ORIGINAL - RECODIFICAÇÃO NUMA NOVA VARIÁVEL 5. SELEÇÃO DE CASOS PARA ANÁLISE - SELECCIONAR CASOS ESPECÍFICOS A SEREM ANALISADOS ANÁLISE DESCRITIVA UNIVARIADA - ANÁLISE DESCRITIVA BASEADA NA DISTRIBUIÇÃO DE FREQUÊNCIA ANÁLISE DE CORRELAÇÃO/ ASSOCIAÇÃO ENTRE VARIÁVEIS - RELAÇÃO ENTRE VARIÁVEIS (CROSSTABS) - ANÁLISES DE CORRELAÇÃO ENTRE VARIÁVEIS - QUI-QUADRADO - TESTES T
 - ANÁLISES DE CORRELAÇÃO ENTRE VARIÁVEIS. - QUI-QUADRADO. - TESTES T.")
4
Apresentação O SPSS é um software apropriado para a elaboração de análises estatísticas de matrizes de dados. O seu uso permite gerar relatórios tabulados, gráficos e dispersões de distribuições utilizados na realização de análises descritivas e de correlações entre as variáveis. O objetivo deste módulo é fornecer noções básicas de manipulação do software. Por isso, cobre apenas uma pequena parte do conjunto das ferramentas presente no pacote estatístico. Os principais tópicos aqui abordados são: Manipulação de Arquivos de Dados: abrir e guardar matrizes de dados; Edição de Dados: criar e editar matrizes de dados; Transformação de Dados: recodificar e criar novas variáveis a partir de cálculos com as variáveis já existentes; Seleção de Casos: seleção de casos para realização da análise; Análise Descritiva dos Dados: tabelas de freqüência, medidas de tendência central e dispersão; Análise de Correlação entre Variáveis: testa a independência entre variáveis e a intensidade da correlação entre elas.

5
Conceitos Elementares de Estatística
“É a técnica que computa e numera os fatos e os indivíduos suscetíveis de serem enumerados ou medidos: coordena e classifica os dados obtidos com o objetivo de determinar suas causas, conseqüências e tendências” (Escotet, 1973).
.")
6
Conceitos Elementares de Estatística
Divide-se em: - Estatística Descritiva Refere-se apenas aos dados observados e compreende sua coleta, tabulação, apresentação, análise, interpretação, representação gráfica e descrição, a fim de torna-los mais manejáveis, podendo, assim, compreendê-los e interpretá-los melhor. Estatística Inferencial Pretende inferir características de uma população a partir dos dados observados em uma amostra de indivíduos. Também é conhecida como estatística amostral. Estatística Univariada Refere-se a uma única variável. Inclui basicamente as medidas de tendência central, variabilidade, assimetria e curtose. Estatística Bivariada Estabelece uma relação entre duas variáveis, como , por exemplo, a correlação de Pearson e a análise de variância unidirecional. Estatística Multivariada Analisa simultaneamente mais de duas variáveis, como por exemplo, a regressão múltipla, a analise multivariada de variância, a analise fatorial, a analise discriminante e a correlação canônica.

7
Conceitos Elementares de Estatística
População Conjunto de todos os indivíduos que possuem, ao menos, uma característica comum entre eles e nos quais se deseja estudar um fenômeno. A população pode ser finita ou infinita. Amostra Subconjunto da população, selecionado por algum método de amostragem, sobre o qual se coletam os dados para o estudo do fenômeno. Indivíduo Cada um dos elementos que compõem a população e também a amostra. Os indivíduos não são necessariamente pessoas, podem ser também objetos ou acontecimentos.

8
Conceitos Elementares de Estatística
Variável é uma característica que pode adotar diferentes valores. Por exemplo, o peso, a idade, a inteligência, o rendimento acadêmico, etc. Apresentam ainda duas características fundamentais: são observáveis (cor, peso) e são suscetíveis de mudança ou variação. Variável Independente é a suposta causa de uma modificação em uma relação de causa-efeito; é uma variável experimental, manipulada e controlada pelo pesquisador; pretende explicar as mudanças ocorridas na variável dependente. Variável Dependente é o efeito que age como conseqüência da variável independente. Variáveis Intervenientes são as variáveis alheias ao experimento, mas que podem exercer uma influencia sobre os resultados; incluem basicamente variáveis organísmicas e fatores ambientais
 e são suscetíveis de mudança ou variação. Variável Independente. é a suposta causa de uma modificação em uma relação de causa-efeito; é uma variável experimental, manipulada e controlada pelo pesquisador; pretende explicar as mudanças ocorridas na variável dependente. Variável Dependente. é o efeito que age como conseqüência da variável independente. Variáveis Intervenientes. são as variáveis alheias ao experimento, mas que podem exercer uma influencia sobre os resultados; incluem basicamente variáveis organísmicas e fatores ambientais.")
9
Conceitos Elementares de Estatística
Variável Qualitativa (atributo ou categóricas) referem-se a características que não podem ser quantificadas. Podem ser dicotômicas (sexo, itens de verdadeiro ou falso, sim/não, etc.) ou politômicas (classe social, nível de estudos, tipo de escola, etc). As categorias das variáveis qualitativas devem estar bem definidas, ser mutuamente excludentes e devem ser exaustivas. Variável Quantitativa caráter suscetível de ser medido numericamente, como a idade, o rendimento acadêmico, etc. Podem ser: discretas, quando só podem assumir determinados valores, que costumam coincidir com os números inteiros (numero de filhos, numero de alunos, numero de livros, etc); e contínuas, podem assumir qualquer valor intermediário dentro de um continuum (idade, rendimento acadêmico).
 referem-se a características que não podem ser quantificadas. Podem ser dicotômicas (sexo, itens de verdadeiro ou falso, sim/não, etc.) ou politômicas (classe social, nível de estudos, tipo de escola, etc). As categorias das variáveis qualitativas devem estar bem definidas, ser mutuamente excludentes e devem ser exaustivas. Variável Quantitativa. caráter suscetível de ser medido numericamente, como a idade, o rendimento acadêmico, etc. Podem ser: discretas, quando só podem assumir determinados valores, que costumam coincidir com os números inteiros (numero de filhos, numero de alunos, numero de livros, etc); e contínuas, podem assumir qualquer valor intermediário dentro de um continuum (idade, rendimento acadêmico).")
10
Conceitos Elementares de Estatística
Escalas de Medidas Referem-se ao sistema utilizado por um instrumento de medição. Podem ser classificadas em: Nominal Os elementos são atributos ou qualidades.Os números servem apenas para identificar ou categorizar os elementos. Ex: Camisas de um time de futebol. Outras variáveis incluem, por exemplo, o sexo, a raça, a religião. Ordinal Distinguem diferentes graus de um atributo ou variável, existindo, portanto, uma relação de ordem. Os números são associados de modo que a relação de ordem seja mantida, por exemplo: 1 = classe social baixa; 2 = classe social média; 3 = classe social alta. Os escalões de rendimento, as classes etárias, as ordens de preferências, são alguns exemplos.

11
Conceitos Elementares de Estatística
Intervalar Atribuem valores numéricos aos indivíduos. O uso de números para classificar os elementos é feito de forma que, a igual diferença entre os números, corresponda igual diferença nas quantidades do atributo medido. O zero é um valor arbitrário e não representa a ausência da característica medida. Como exemplo tem-se o termômetro, as medidas de atitudes, de personalidade, onde o zero não indica a total ausência de calor. Razão São escalas de intervalos, mas que acrescentam a existência do zero absoluto. O zero absoluto é considerado como a ausência total de qualidade medida e, portanto, é um valor que não pode ser rebaixado na parte inferior. Muitas variáveis quantitativas de tipo físico são medidas em escala de razão, como a idade, o peso, a extensão, etc. Escala Nominal ou Ordinal = Qualitativas Escala de Intervalo ou Razão = Quantitativas.

12
O que é uma Matriz de Dados
Abrindo o SPSS: Para abrir a matriz para um novo banco de dados: “Type in data” Para abrir um banco de dados existente: “Open an existing data source”

13
O que é uma Matriz de Dados
Open file Extensões dos arquivos criados pelo SPSS: .sav - extensão atribuída aos arquivos de dados. .spo - extensão atribuída aos arquivos de “output”. .sps - extensão atribuída aos arquivos de sintaxe (com o código de programação. Como se pode observar o SPSS permite abrir arquivos de muitos tipos, entre eles os de tipo Excel.

14
O que é uma Matriz de Dados
Aspecto de um arquivo com extensão .sav Nome do arquivo Variáveis Ao clicar neste botão aparecem as etiquetas (“labels”) das variáveis categóricas Para muitos dos procedimentos estatísticos é conveniente atribuir códigos numéricos às variáveis categóricas
 das variáveis categóricas. Para muitos dos procedimentos estatísticos é conveniente atribuir códigos numéricos às variáveis categóricas.")
15
O que é uma Matriz de Dados
Data View versus Variable View Quando se está em Variable View tem-se acesso às definições das variáveis – nome, tipo, máximo de dígitos ou caracteres, “labels”, designação de cada código, convenção para “missing values”, largura da coluna e o “nível” de medida da variável (nominal, ordinal e “scale”) Quando se está em Data View podemos ver os dados. Cada coluna representa uma variável e cada linha representa um caso.
 Quando se está em Data View podemos ver os dados. Cada coluna representa uma variável e cada linha representa um caso.")
16
O que é uma Matriz de Dados
Barra de Menus Clicando no Menu “Edit” e “Options”, pode-se escolher tipos de letras e formatações gerais de gráficos e tabelas para os arquivos de output. Também se tem a possibilidade de escolher a ordem por que desejamos que os nomes das variáveis se apresentem ao abrir um menu de qualquer dos procedimentos estatísticos.

17
Manipulação de Arquivos
Abrir uma Matriz de Dados já existente Selecionar, na barra de ferramentas: File (arquivo) 2) Open (abrir) 3) No campo Look in, selecionar o diretório onde se encontra o arquivo desejado 4) Selecione ou digite no campo File Name o nome do arquivo 5) Selecione a opção Open (abrir). O padrão do SPSS é trabalhar com a opção SPSS (*.sav) no campo Files of Type. Se quiser abrir um arquivo criado noutro sistema, por exemplo do Excel (*.xls), basta selecionar este tipo de arquivo no Files of Type.
 2) Open (abrir) 3) No campo Look in, selecionar o diretório onde se encontra o arquivo desejado. 4) Selecione ou digite no campo File Name o nome do arquivo. 5) Selecione a opção Open (abrir). O padrão do SPSS é trabalhar com a opção SPSS (*.sav) no campo Files of Type. Se quiser abrir um arquivo criado noutro sistema, por exemplo do Excel (*.xls), basta selecionar este tipo de arquivo no Files of Type.")
18
Manipulação de Arquivos
Salvar os Dados Selecionar FILE na barra de ferramentas, atribuir o nome e depois SAVE. 2)Através do campo SAVE IN ou do retângulo abaixo deste campo você poderá selecionar o lugar onde o arquivo será guardado. 3)Preencher o campo FILE NAME com o nome que se deseja dar ao arquivo. É importante utilizar nomes que sejam claros na descrição do conteúdo da matriz de dados. Caso você queira salvar o arquivo em outro formato diferente do padrão estabelecido pelo SPSS (*.sav), selecione o novo tipo nocampo SAVE AS TYPE.
Através do campo SAVE IN ou do retângulo abaixo deste campo você poderá selecionar o lugar onde o arquivo será guardado. 3)Preencher o campo FILE NAME com o nome que se deseja dar ao arquivo. É importante utilizar nomes que sejam claros na descrição do conteúdo da matriz de dados. Caso você queira salvar o arquivo em outro formato diferente do padrão estabelecido pelo SPSS (*.sav), selecione o novo tipo nocampo SAVE AS TYPE.")
19
Manipulação de Arquivos
Salvar ou Abrir Arquivos contendo Relatórios de Análises A seção do SPSS onde é feita a criação, manipulação, exclusão e impressão dos resultados das análises estatísticas feitas pelo SPSS é denominada SPSS Viewer (output). O output divide-se em dois painéis: índice de todas as tabelas e gráficos produzidos na análise (esquerda) conteúdo da análise (direita)
. O output divide-se em dois painéis: índice de todas as tabelas e gráficos produzidos na análise (esquerda) conteúdo da análise (direita)")
20
Manipulação de Arquivos
Ao selecionar o item Notes no espaço da esquerda, uma série de características da análise serão mostradas: data em que foi criado o relatório, nome e localização do arquivo de origem da analise, se foi utilizado algum filtro para selecionar os casos ou peso para atribuir importância diferente, número total de casos analisados, existência de missing values, comando para utilizar o relatório e o tempo total que o computador levou para emitir o relatório. Tal campo também pode ser editado ao clicar duas vezes repetidas sobre o campo. Ao selecionar o item Statistics ou Case Processing no espaço da esquerda, será mostrado o número total de casos considerados válidos para análise e o número total de casos caracterizados como missing values e que por isso não foram computados na análise. Por fim, o último item nos mostrará o relatório final da análise. Neste caso, a tabela de freqüência ou o gráfico BOX PLOT. Para salvar o output, o processo é semelhante ao realizado para as bases de dados. A única exceção é que o tipo de arquivo padrão para o SPSS passa a ter extensão spo (*.spo).
.")
21
Edição de uma Matriz de Dados
Criar uma Matriz de Dados O passo mais importante na criação de uma matriz de dados é a definição das variáveis. Cada variável é criada separadamente, indicando seu nome, definição, tipo, categorias, formato da coluna na tabela e missing values (valores que por definição não entram nas análises estatísticas). Cada caso é registrado em uma linha separada; Cada coluna corresponde a uma variável. É importante que a primeira variável seja “Sujeito”, possibilitando manter a seqüência original das informações; É importante criar um código numérico para as variáveis nominais (Ex: 1 = feminino; 2 = masculino). Data View = Matriz de Dados Variable View = Caracterização das Variáveis
. Cada caso é registrado em uma linha separada; Cada coluna corresponde a uma variável. É importante que a primeira variável seja Sujeito , possibilitando manter a seqüência original das informações; É importante criar um código numérico para as variáveis nominais. (Ex: 1 = feminino; 2 = masculino). Data View = Matriz de Dados. Variable View = Caracterização das Variáveis.")
22
Edição de uma Matriz de Dados
Definição das Variáveis 1 – Nome da Variável – Não deve conter espaço ou símbolo ou ser duplicado. Ao trabalhar com grande número de variáveis é indicado confeccionar um “Livro de Códigos”. 2 – Tipos de Variável – Para modificar o tipo de variável (numérica por default) deve-se selecionar a célula na coluna Type e clicar na área sombreada para que apareçam as opções. Para ciências sociais são importantes: Numérica: (default) estabelece que o campo será numérico (variáveis ordinais e categóricas. Date: formato para entrada de datas. Dollar: entrada de valores monetários. String: campo alfa-numérico, podendo incluir qualquer tipo de informação deseja. Ex: nome de um município.
 deve-se selecionar a célula na coluna Type e clicar na área sombreada para que apareçam as opções. Para ciências sociais são importantes: Numérica: (default) estabelece que o campo será numérico (variáveis ordinais e categóricas. Date: formato para entrada de datas. Dollar: entrada de valores monetários. String: campo alfa-numérico, podendo incluir qualquer tipo de informação deseja. Ex: nome de um município.")
23
Edição de uma Matriz de Dados
3 – Width: tamanho total de caracteres da variável (8 por default) 4 – Decimals: número de decimais da variável. 5 – Label : descrição detalhada da natureza da variável, identificando o que o nome indica. Até 256 caracteres. 6 – Values: permite a definição das diversas categorias de respostas, atribuindo-se valores a variáveis categóricas. (Ex: 1 = feminino e 2 = masculino). O valor a ser digitado na matriz deve ser inserido no campo VALUE e o significado corresponde inserido no campo VALUE LABEL. Para cada par de informações deve ser selecionada a opção Add para adiciona-la. Caso algumas das categorias tenham sido definida de maneira errada, utilize as opções Change ou Remove para corrigir.
 4 – Decimals: número de decimais da variável. 5 – Label : descrição detalhada da natureza da variável, identificando o que o nome indica. Até 256 caracteres. 6 – Values: permite a definição das diversas categorias de respostas, atribuindo-se valores a variáveis categóricas. (Ex: 1 = feminino e 2 = masculino). O valor a ser digitado na matriz deve ser inserido no campo VALUE e o significado corresponde inserido no campo VALUE LABEL. Para cada par de informações deve ser selecionada a opção Add para adiciona-la. Caso algumas das categorias tenham sido definida de maneira errada, utilize as opções Change ou Remove para corrigir.")
24
Edição de uma Matriz de Dados
7 – Missing Values: (valores desconhecidos ou omissos que não entrarão nas análises estatísticas) Para atribuir códigos para valores omissos deve-se: Na caixa de diálogo Missing Values, assinalar em Discrete Missing values para os valores categóricos ou em range plus one optional discrete missing value para inserir um intervalo de valores quantitativos. Atribuir um valor para a variável desconhecida (por ex. 999); Os valores desconhecidos não são considerados para efeitos estatísticos. 8 – Column e Align: diminuir ou aumentar a largura da coluna e o alinhamento de seu conteudo. De um modo geral, estes campos não são preenchidos, utilizando o padrão do SPSS (8 caracteres).
 Para atribuir códigos para valores omissos deve-se: Na caixa de diálogo Missing Values, assinalar em Discrete Missing values para os valores categóricos ou em range plus one optional discrete missing value para inserir um intervalo de valores quantitativos. Atribuir um valor para a variável desconhecida (por ex. 999); Os valores desconhecidos não são considerados para efeitos estatísticos. 8 – Column e Align: diminuir ou aumentar a largura da coluna e o alinhamento de seu conteudo. De um modo geral, estes campos não são preenchidos, utilizando o padrão do SPSS (8 caracteres).")
25
Edição de uma Matriz de Dados
9 – Measure: deve ser preenchido com o tipo de medida característica da variável: Scale: existe uma relação ordinal entre os valores mas a distância entre estas é desconhecida e não regular (ideal para variáveis quantitativas – intervalar/razão) Ordinal: Existe uma relação ordinal entre os valores e a distância entre estes é conhecida e regular (ideal para variáveis ordinais). Nominal: não existe nenhuma relação ordinal entre os valores (ideal para variáveis nominais)
 Ordinal: Existe uma relação ordinal entre os valores e a distância entre estes é conhecida e regular (ideal para variáveis ordinais). Nominal: não existe nenhuma relação ordinal entre os valores (ideal para variáveis nominais)")
26
Edição de uma Matriz de Dados
Preencher a Matriz de Dados Tendo definido todas as variáveis da matriz de dados, passamos para a entrada dos dados caso por caso; de um modo geral, recomenda-se que os dados sejam digitados por questionário, ou seja, linha por linha. O preenchimento é feito digitando o valor atribuído à variável em cada caso seguido de tab (o que fará com que se passe para a próxima variável do mesmo caso) ou ENTER (o que fará com que se passe para o próximo caso na mesma variável). Para situações em que os valores se repetem muito, a utilização das opções CORTAR e COLAR permite a agilização do trabalho.
 ou ENTER (o que fará com que se passe para o próximo caso na mesma variável). Para situações em que os valores se repetem muito, a utilização das opções CORTAR e COLAR permite a agilização do trabalho.")
27
Edição de uma Matriz de Dados
Excluir uma Variável Caso seja necessário excluir uma variável da matriz de dados, colocar o cursor sobre o cabeçalho da coluna correspondente à variável que se deseja excluir e dar um click para selecionar a coluna que se pretende apagar. Tendo selecionado a variável, basta clicar a tecla DELETE. O mesmo procedimento deve ser usado em relação à exclusão de casos, selecionando a linha que se pretende apagar através de um click sobre a margem esquerda da linha na matriz de dados.

28
Edição de uma Matriz de Dados
Inserir uma nova variável entre as já existentes Caso seja necessário inserir uma nova variável no meio de variáveis já existentes numa matriz de dados, devemos utilizar o comando inserir variável seguindo os seguintes passos: 1. Escolha o lugar onde a variável deve ser inserida; 2. Selecione a variável que estará à direita da nova variável a ser inserida clicando sobre o cabeçalho da coluna desta variável; 3. Na barra de ferramentas selecionamos DATA e depois INSERT VARIABLE; 4. Em seguida deve seguir todos os passos necessários para a definição da nova variável.

29
Transformação de Dados
Cálculo entre Variáveis Trata-se da criação de uma nova variável a partir das variáveis já existentes. 1 – Selecionar Menu Transform e, em seguida, o comando COMPUTE. 2 – Preencher o campo Target Variable com o nome da nova variável. É possível especificar o tipo e definição desta nova variável ao selecionar Type & Label. 3 – Realizar a operação matemática no campo Numeric Expression. Operação lógica “e” Operação lógica “ou”

30
Transformação de Dados
Exemplos de operações: Operação Expressão Variável C é igual a soma de A e B C = A + B Variável C é igual a soma de A e B C = sum (A to B) Variável C é igual a divisão de A por C = A / 100 Variável C é igual a média aritmética de A e B C = (A + B) / 2 A operação matemática pode envolver também a utilização de algumas ferramentas matemáticas de maior complexidade características, por exemplo, da estatística ou da trigonometria. Para este caso, existe uma série de funções matemáticas definidas na caixa FUNCTIONS. A sua inserção deve ser feita da seguinte forma: 1. Escolha a função desejada utilizando os recursos disponibilizados pela barra de rodagem. 2.Após escolhida a função, insira a função no campo NUMERIC EXPRESSION clicando sobre a seta que está acima do campo FUNCTiONS.
 Variável C é igual a divisão de A por 100 C = A / 100. Variável C é igual a média aritmética de A e B C = (A + B) / 2. A operação matemática pode envolver também a utilização de algumas ferramentas matemáticas de maior complexidade características, por exemplo, da estatística ou da trigonometria. Para este caso, existe uma série de funções matemáticas definidas na caixa FUNCTIONS. A sua inserção deve ser feita da seguinte forma: 1. Escolha a função desejada utilizando os recursos disponibilizados pela barra de rodagem. 2.Após escolhida a função, insira a função no campo NUMERIC EXPRESSION clicando sobre a seta que está acima do campo FUNCTiONS.")
31
Transformação de Dados
Outra opção presente no comando COMPUTE é a possibilidade de selecionar em que casos a operação indicada será realizada. Ao selecionar a opção IF chegaremos na seguinte figura: A opção padrão é a include all cases, ou seja, a operação será realizada em todos os casos existentes no banco de dados. Podemos, no entanto, selecionar o caso em que esta operação se realizará ao clicarmos na opção: include if case satisfies condition. Indicaremos, então, uma nova expressão numérica que deve ser satisfeita para que a operação matemática indicada seja realizada.

32
Transformação de Dados
Também neste caso, a expressão numérica pode incluir funções matemáticas mais complexas. Apresentamos, a seguir, alguns exemplos básicos para facilitar a compreensão da utilização do comando: Condição Expressão Variável C é menor que C < 100 Variável C é diferente de A C <> A Variável C é menor que a soma de A e B C < A + B Ex: Obtenção de uma variável satisfa que seja a média de três variáveis: satisfa1, satisfa2 e satisfa3 Comandos: Transform Compute target variable satisfa Numeric expression (satisfa1 + satisfa2 + satisfa3) / 3 ok
 / 3 ok.")
33
Transformação de Dados
O comando Transform Compute também permite criar novas variáveis que resultem de combinações de outras. Por exemplo: para criar uma nova variável - grupo - , com 4 categorias que resultam da transformação das variáveis sexo e idade, onde 1 = homens com menos de 34 anos, 2 = homens com 34 anos ou mais, 3 = mulheres com menos de 34 anos, 4 = mulheres com 34 anos ou mais, usam-se os comandos: Transform Compute Target variable grupo Numeric Expression 1 if include if cases satisfies condition idade < 34 & sexo = 1 Continue Ok Repete-se o comando anterior substituindo-se a expressão numérica 1 por 2 e acrescentando a nova condição.

34
Recodificação de Variáveis
É possível recodificar valores por meio do: Recode: Into same variable na mesma variável (realiza a recodificação da variável sobre ela mesma, apagando o conteúdo da variável original), Recode: Into Different Variable criando uma nova variável (realiza a recodificação em uma nova variável, mantendo a original). Exemplo: IDADE COMANDO DE RECODIFICAÇÃO NOVA VARIÁVEL RECODIFICADA até 4 → até 9 → até 14 → até 19 → até 24 → até 29 → Deixamos de ter uma variável com valor absoluto para termos uma variável com categorias e com um significado específico para cada uma delas.
, Recode: Into Different Variable criando uma nova variável (realiza a recodificação em uma nova variável, mantendo a original). Exemplo: IDADE COMANDO DE RECODIFICAÇÃO NOVA VARIÁVEL RECODIFICADA. 2 0 até 4 → até 9 → até 14 → até 19 → até 24 → até 29 →6 6. Deixamos de ter uma variável com valor absoluto para termos uma variável com categorias e com um significado específico para cada uma delas.")
35
Recodificação de Variáveis
Recodificação na Variável Original 1 – Selecionar no painel da esquerda a variável a ser recodificada; 2 – Clicar para conduzir a variável no campo Numeric Variable; Assim como para o comando COMPUTE, podemos selecionar através do IF os casos onde esta recodificação será realizada 9usando o mesmo padrão de procedimentos).
.")
36
Recodificação de Variáveis
3 – Indicar os valores novos que substituirão so valores a serem recodificados através da opção Old and New Values. 4 - O campo Old Value deverá ser preenchido com os valores a serem recodificados, enquantoque o Campo New Value deverá ser preenchido com os valores que substituirão os valores a serem recodificados. 5 – No campo Old Value, os valores´podem ser preenchidos na forma de valores absolutos ou intervalos. No campo New Value, os valores só podem ser preenchidos na forma de valores absolutos. A cada par de Old Value e New Value deve se clicar no campo Add para inseri-lo na lista de recodificações planejadas. Qualquer alteração pode ser realizada utilizando os recursos CHANGE e REMOVE. Após escolher todos os pares de valores a serem recodificados, basta apenas selecionar o campo CONTINUE.

37
Recodificação de Variáveis
Recodificação numa Nova Variável 1- Selecionar a variável a ser recodificada conduzindo-a ao campo Input Variable/Output/Variable 2 – Preencher o campo Output Variable com o nome da nova variável. Nome da Variável codificada 3 – Clicar em Change. Variável a codificar. 4 – Os comandos IF e Old and New Value seguem as mesmas regras descritas para a opção Recode into Same Variable.

38
Seleção de Casos para Análise
- Bastante utilizado quando se quer restringir a análise a um grupo especifico dentre a amostra. 1 – Abrir Data e, em seguida, Select Cases. O campo Select Cases mostrará 5 opções para seleção dos casos. Todos os casos Se condição for satisfeita Amostragem aleatória dos casos Baseado em Intervalo de casos Uso de variável filtro A opção All Cases permite trabalhar com todos os casos da amostra e é automaticamente definida pelo SPSS.

39
Seleção de Casos para Análise
A opção If Condition is satisfied permite estabelecer uma condição em função de uma expressão matemática que deve ser satisfeita, muito semelhante ao encontrado no comando Compute. Random Sample of Cases permite escolher o número de casos a ser analisado em função de uma seleção aleatória simples. Poderemos indicar aproximadamente a percentagem de casos a serem selecionados no total de casos ou o número exato de casos dentro de um número específico de primeiros casos; por exemplo: cinco casos dentro dos 100 primeiros.

40
A quarta opção, Based on Case Range, permite escolher os casos dentro de uma faixa específica de ordem de codificação. Com base no código do caso (número do caso presente na margem esquerda da tabela de matriz de dados ) indica o intervalo de casos a serem selecionados. A quinta e última opção, User Filter Variable, permite selecionar os casos em função de uma variável filtro definida previamente. Esta opção exige uma variável de tipo especial (dummy) composta apenas de valores 0 e 1, onde os valores 1 serão selecionados e os valores 0 não serão selecionados.
 composta apenas de valores 0 e 1, onde os valores 1 serão selecionados e os valores 0 não serão selecionados.")
41
Análise Descritiva Univariada
Costuma-se iniciar qualquer análise de dados por uma descrição das variáveis observadas, o que inclui, principalmente, medidas de tendência central, variabilidade, assimetria e curtose. Permitem uma aproximação da descrição dos resultados; Descobrir indivíduos com pontuações extremas ou situados fora do âmbito da variável (outliers) Encontrar erros de codificação das variáveis (Depuração dos dados) O estudo descritivo de cada variável de per si, quer seja nominal, ordinal e intervalar, ou de razão, abrange as estatísticas adequadas à interpretação dos dados, a sua representação gráfica, a análise das não respostas e à identificação de observações outliers. Tanto a ocorrência de não-respostas superiores a 20%, como a existência de outliers, devem ser referidos e analisados quando da interpretação dos resultados, pois podem caracterizar segmentos populacionais com características distintas. Caso provenham de erro de introdução ou codificação dos dados devem ser corrigidos. Os outliers podem influenciar a média, aumentando ou diminuindo, quando se situam respectivamente para além do valor máximo ou aquem do valor mínimo dos dados. Os outliers aumentam sempre a dispersão dos dados.
 Encontrar erros de codificação das variáveis (Depuração dos dados) O estudo descritivo de cada variável de per si, quer seja nominal, ordinal e intervalar, ou de razão, abrange as estatísticas adequadas à interpretação dos dados, a sua representação gráfica, a análise das não respostas e à identificação de observações outliers. Tanto a ocorrência de não-respostas superiores a 20%, como a existência de outliers, devem ser referidos e analisados quando da interpretação dos resultados, pois podem caracterizar segmentos populacionais com características distintas. Caso provenham de erro de introdução ou codificação dos dados devem ser corrigidos. Os outliers podem influenciar a média, aumentando ou diminuindo, quando se situam respectivamente para além do valor máximo ou aquem do valor mínimo dos dados. Os outliers aumentam sempre a dispersão dos dados.")
42
Análise Descritiva Univariada
- Distribuição de Freqüências Na barra de ferramentas devemos selecionar ANALYSE, depois DESCRIPTIVES STATISTICS e depois FREQUENCIES. Chegaremos, então, a seguinte figura: Oferece uma descrição geral das distribuições das variáveis.

43
Análise Descritiva Univariada
Fomatar: Após escolhermos a variável sobre a qual queremos construir a tabela de freqüênciapoderemos escolher no campo FORMAT algumas opções em relação ao formato desta tabela. Chegaremos a seguinte figura: ascending values: categorias aparecem em ordem crescente do valor da categoria descending values:categorias surgem em ordem decrescente ascending counts: categorias aparecem em ordem crescente do valor do número total de casos por categoria descending counts:categorias surgem em ordem decrescente do valor do número total de casos por categoria Na opção MULTIPLE VARIABLE poderemos escolher entre incluir os resultados das análises de todas as variáveis trabalhadas num mesmo relatório (compare variable) ou produzir um relatório por variável (organize output by variable). Na opção SUPRESS TABLES WITH MORE THAN poderemos escolher por excluir do relatório aquelas tabelas que tenham um certo número definido de categorias.
 ou produzir um relatório por variável (organize output by variable). Na opção SUPRESS TABLES WITH MORE THAN poderemos escolher por excluir do relatório aquelas tabelas que tenham um certo número definido de categorias.")
44
Análise Descritiva Univariada
Medidas de Tendência Central e Dispersão As medidas de tendencia central são valores representativos de distribuição. A mais importante é a média, seguida da moda e mediana. Ao clicar sobre o campo STATISTICS surge a figura ao lado, devendo-se selecionar entre as opções existentes. Entre as medidas de tendência central temos : média, moda, mediana e soma; Entre as medidas de dispersão dos valores temos: desvio padrão, variância, intervalo, valor máximo e mínimo e média do erro padrão; Em relação aos valores percentuais poderemos obter os quartis, os diversos percentis desejados e os valores que dividem a amostra no número de partes iguais desejadas. Tendo feito a seleção das medidas desejadas, basta clicar em CONTINUE.

45
Análise Descritiva Univariada
Medidas de Tendência Central Média Aritmética: representa o valor médio da distribuição. Mediana: é o valor que ocupa o lugar central de uma serie de valores ordenados, ou seja, deixa 50% de cada lado dos indivíduos. Se o número de indivíduos é par, a mediana será a média dos que ocupam os lugares centrais. Moda: é o valor que mais se repete. Uma distribuição pode ser unimodal quando tem apenas uma moda, bimodal se tem duas, multimodal se tem mais de duas e amodal se não tem nenhuma moda.

46
Análise Descritiva Univariada
Medida de Variabilidade As medidas de variabilidade ou dispersão indicam como os valores estão agrupados. As principais medidas de variabilidade são: Limites: (amplitude ou percurso) é a distância entre os dois valores extremos de uma distribuição (máximo e mínimo). Variância: é a média aritmética dos quadrados dos desvios de cada valor com referencia à sua média.Pode ser descritiva (quando não se pretende generalizar) e inferencial (quando pretende-se a generalização). Desvio Padrão: é a raiz quadrada da variância. Quanto menor o desvio padrão, menor a dispersão dos dados.
 é a distância entre os dois valores extremos de uma distribuição (máximo e mínimo). Variância: é a média aritmética dos quadrados dos desvios de cada valor com referencia à sua média.Pode ser descritiva (quando não se pretende generalizar) e inferencial (quando pretende-se a generalização). Desvio Padrão: é a raiz quadrada da variância. Quanto menor o desvio padrão, menor a dispersão dos dados.")
47
Análise Descritiva Univariada
Medidas de Tendência Central e Dispersão (output)
")
48
Análise Descritiva Univariada
Gráficos A opção CHART relaciona uma série de recursos para a visualização gráfica da distribuição de dados. Ao clicarmos na opção CHART chegaremos na figura ao lado:

49
Análise de Correlação/Associação entre as Variáveis
Tabela de Associação entre Variáveis (Crosstabs) Um passo inicial para as análises de correlação/ associação é a construção de tabelas de contingência, que tem o formato de (x) linhas por (y) colunas. Procedimentos: ANALYSE - DECRIPTIVES STATISTICS – CROSSTABS O campo ROW deverá ser preenchido com a variável a ser colocada na linha da tabela (padrão: variável independente – linha da tabela). . O campo COLUMN deverá ser preenchido com a variável a ser colocada na coluna da tabela (variável dependente). Note que estes campos poderão ser preenchidos com mais de uma variável, sendo construídas, então, quantas tabelas forem necessárias envolvendo 2 variáveis para cumprir com as alternativas possíveis de cruzamento. O retângulo abaixo do campo COLUMN poderá ser preenchido com uma nova variável (ou mais).
 Um passo inicial para as análises de correlação/ associação é a construção de tabelas de contingência, que tem o formato de (x) linhas por (y) colunas. Procedimentos: ANALYSE - DECRIPTIVES STATISTICS – CROSSTABS. O campo ROW deverá ser preenchido com a variável a ser colocada na linha da tabela (padrão: variável independente – linha da tabela). . O campo COLUMN deverá ser preenchido com a variável a ser colocada na coluna da tabela (variável dependente). Note que estes campos poderão ser preenchidos com mais de uma variável, sendo construídas, então, quantas tabelas forem necessárias envolvendo 2 variáveis para cumprir com as alternativas possíveis de cruzamento. O retângulo abaixo do campo COLUMN poderá ser preenchido com uma nova variável (ou mais).")
50
Análise de Correlação/Associação entre as Variáveis

51
Análise de Correlação/Associação entre as Variáveis
Qui-Quadrado A estatística do Qui-quadrado é adequada para variáveis qualitativas, com duas ou mais categorias, para comprovar se existe diferença significativa entre os dois grupos. O resultado do qui-quadrado será 0 quando não houver diferença entre os grupos, ficando maior à medida que aumentam as discrepâncias. A análise do qui-quadrado permite levantar em que medida a associação encontrada decorre de uma coincidência dos casos analisados , ou seja, se decorre de um erro amostral, ou de uma real correlação entre as variáveis.

52
Análise de Correlação/Associação entre as Variáveis
Procedimento: Analyze – Descriptives Statistics - Crosstabs Na caixa de diálogo Crosstabs, selecionar as variáveis nas colunas Row e Column Clicar em Cells e selecionar em Counts: Observed e em Percentagens:Row Continue Selecionar Statistics e selecionar Chi-Square OK

53
Análise de Correlação/Associação entre as Variáveis
Se p > 0,05 não existe diferença Se p ≤ 0,05 existe diferença (X2 = 3,812, com um p = 0,04) Ou seja, existe diferença entre os gêneros feminino e masculino em relação a qualidade de vida.
 Ou seja, existe diferença entre os gêneros feminino e masculino em relação a qualidade de vida.")
54
Análise de Correlação/Associação entre as Variáveis
Teste t de Student O teste t de Student é um procedimento de analise de dados para testar a hipótese de que duas médias são iguais. Quanto maior for a diferença entre as médias, maior será o valor t calculado. (p ≤ 0,05) Alguns critérios devem ser obedecidos para executar o teste t: As variáveis devem ser, preferencialmente, intervalares ou de razão, mas dependendo do tamanho da escala, pode ser utilizado em variáveis ordinais. As amostras devem ser aleatórias. Em caso de amostras pequenas (menores que 30), a variável observacional deverá ter distribuição normal na população (Teste de Kolmogorov-Smirnov. Existem vários tipos de teset t, dos quais os mais usados são: Teste t para uma amostra Teste t para amostras independentes Teste t par amostras emparelhadas
 Alguns critérios devem ser obedecidos para executar o teste t: As variáveis devem ser, preferencialmente, intervalares ou de razão, mas dependendo do tamanho da escala, pode ser utilizado em variáveis ordinais. As amostras devem ser aleatórias. Em caso de amostras pequenas (menores que 30), a variável observacional deverá ter distribuição normal na população (Teste de Kolmogorov-Smirnov. Existem vários tipos de teset t, dos quais os mais usados são: Teste t para uma amostra. Teste t para amostras independentes. Teste t par amostras emparelhadas.")
55
Análise de Correlação/Associação entre as Variáveis
Teste t para uma amostra Compara a média de uma amostra com a média conhecida de uma população, ou seja, compara os valores observados com um valor pré-definido pelo analista. Por exemplo: a comparação do QI dos alunos de uma turma com o valor 11. Com este teste, pretende-se verificar se a média de determinada variável em análise é igual à média da população geral. Procedimentos: Analyze – Compare Means One-Sample T Test Selecionar a variável a analisar e o valor hipotético da população (test value. 3) Ok
 Ok.")
56
Análise de Correlação/Associação entre as Variáveis
Hipótese: a amostra de indivíduos com Aids tem índices de massa corporal significativamente superiores a 25 kg/m2. O resultado mostra que para um nívelde significância de 5%, deve rejeitar a hipótese nula de que o IMC da amostra é 25 pois o pvalue ou significance level da amostra é de 0,001 <0.05. O IMC dos indivíduos com Aids é significativamente superior à média da População investigada.

57
Análise de Correlação/Associação entre as Variáveis
Test t para amostras independentes - Aplica-se quando se pretende comparar as médias de uma variável quantitativa em dois grupos diferentes e se desconhecem as respectivas variâncias populacionais. - Os indivíduos devem ser aleatoriamente distribuídos. Procedimentos: Analyze – Compare Means – Independente-Samples T- Test... Selecionar a variável como Test Variable. Ex. sexo Selecionar a variavel que define os grupos (ex: Qualidade de Vida) como Grouping Variable (variável de agrupamento). Esta variável é fundamental para definir os grupos a serem comparados. Clicar no Define Groups para definir os grupos. Digitar os valores correspondentes Ex. sexo: 1 e 2 Continue
 como Grouping Variable (variável de agrupamento). Esta variável é fundamental para definir os grupos a serem comparados. Clicar no Define Groups para definir os grupos. Digitar os valores correspondentes Ex. sexo: 1 e 2. Continue.")
58
Análise de Correlação/Associação entre as Variáveis
Assumindo a igualdade de variâncias (Equal Variances assumed) Assumindo que as variâncias são desiguais (Equal variances not assumed) Teste de Levene (testa a hipótese de igualdade de variâncias) Se o valor da significância do teste de Levene for ≤ 0,05, então rejeita-se a igualdade de variâncias e se deve assumir os resultados do test t para variâncias desiguais. - Se o valor da significância do teste de Levene for > 0,05 (como é o caso – 0,54), então utilizam-se os resultados do test t para variâncias iguais entre os dois grupos. - Nesse caso, o valor do teste a interpretar será de t=13,918, cujo p é inferior a 0,05, o que leva a rejeitar a Ho, ou seja, o teste t revela que a diferença entre as médias (9,238) é grande para ser atribuivel ao acaso. - Esta tabela ainda fornece os valores dos limites do intervalo de confiança de 95% para a diferença entre as médias, onde o 0 está fora do intervalo, portanto a diferença não é nula.
 Assumindo que as variâncias são desiguais (Equal variances not assumed) Teste de Levene (testa a hipótese de igualdade de variâncias) Se o valor da significância do teste de Levene for ≤ 0,05, então rejeita-se a igualdade de variâncias e se deve assumir os resultados do test t para variâncias desiguais. - Se o valor da significância do teste de Levene for > 0,05 (como é o caso – 0,54), então utilizam-se os resultados do test t para variâncias iguais entre os dois grupos. - Nesse caso, o valor do teste a interpretar será de t=13,918, cujo p é inferior a 0,05, o que leva a rejeitar a Ho, ou seja, o teste t revela que a diferença entre as médias (9,238) é grande para ser atribuivel ao acaso. - Esta tabela ainda fornece os valores dos limites do intervalo de confiança de 95% para a diferença entre as médias, onde o 0 está fora do intervalo, portanto a diferença não é nula.")
59
Análise de Correlação/Associação entre as Variáveis
Test t para amostras emparelhadas Compara as médias de duas variáveis ou características para uma mesma amostra de indivíduos. Critérios: - somente para casos onde a variável de cada individuo é medida antes e depois de intervenções. Ex. Medida do peso antes e depois de uma dieta. deve haver pares de observação, de modo que ambas as amostras tenham o mesmo numero de observações. Procedimentos: Analyse – Compare Means Paired T Test Selecionar as duas variáveis emparelhadas e clicar na seta Clicar Ok

60
No primeiro quadro são apresentados alguns parâmetros estatísticos de cada uma das amostras. Repare que foram só levados em conta 386 das 387 observações em cada amostra. O quadro seguinte apresenta o valor do coeficiente de correlação de Pearson entre as duas variáveis (r=0.859). No último quadro é apresentado o valor da diferença entre dois momentos: fatores de risco cardiovasculares antes de uma ação de formação sobre como prevenir problemas cardíacos e1 ano após ação de formação (1,2578), o intervalo de confiança para a diferença entre médias (1,1754 , 1,3402]) e o valor da estatística de teste t= 30.007, bem como os graus de liberdade do teste e o valor pvalue ou verdadeiro nível de significância (0.000). Portanto, se conclui que as médias são significativamente inferiores depois da ação de informação, ou seja, a intervenção foi eficaz.
. No último quadro é apresentado o valor da diferença entre dois momentos: fatores de risco cardiovasculares antes de uma ação de formação sobre como prevenir problemas cardíacos e1 ano após ação de formação (1,2578), o intervalo de confiança para a diferença entre médias (1,1754 , 1,3402]) e o valor da estatística de teste t= , bem como os graus de liberdade do teste e o valor pvalue ou verdadeiro nível de significância (0.000). Portanto, se conclui que as médias são significativamente inferiores depois da ação de informação, ou seja, a intervenção foi eficaz.")
61
Análise de Variância - ANOVA
Compara médias, geralmente entre três ou mais grupos, em um único teste, visando identificar se há diferença entre eles. Pressupõe preferencialmente amostra aleatória e distribuição normal. É assumida a igualdade de variância entre os grupos (teste de Levene)
")
62
PROCEDIMENTO ONE WAY ANOVA
Seleccionar para o campo factor o nome da variável nominal (por exemplo potencial de contaminação) e para o campo da dependent list a variável que contém os resultados a analisar (no exemplo, duração da cirurgia).
 e para o campo da dependent list a variável que contém os resultados a analisar (no exemplo, duração da cirurgia).")
63
Na caixa Options, selecionar:
- Descriptives - Homogeneity of variances - Means plot - Exclude cases analysis by analysis - Continue - Ok

64
Teste de homogeneidade de variâncias de Levene: como p-value=0,327 > 0,05, conclui-se que as variâncias são homogêneas, isto é, dentro de cada um dos grupos dentro de cada um dos grupos com potencial de contaminação a variabilidade da duração cirúrgica é apenas devida a causas aleatórias.

66
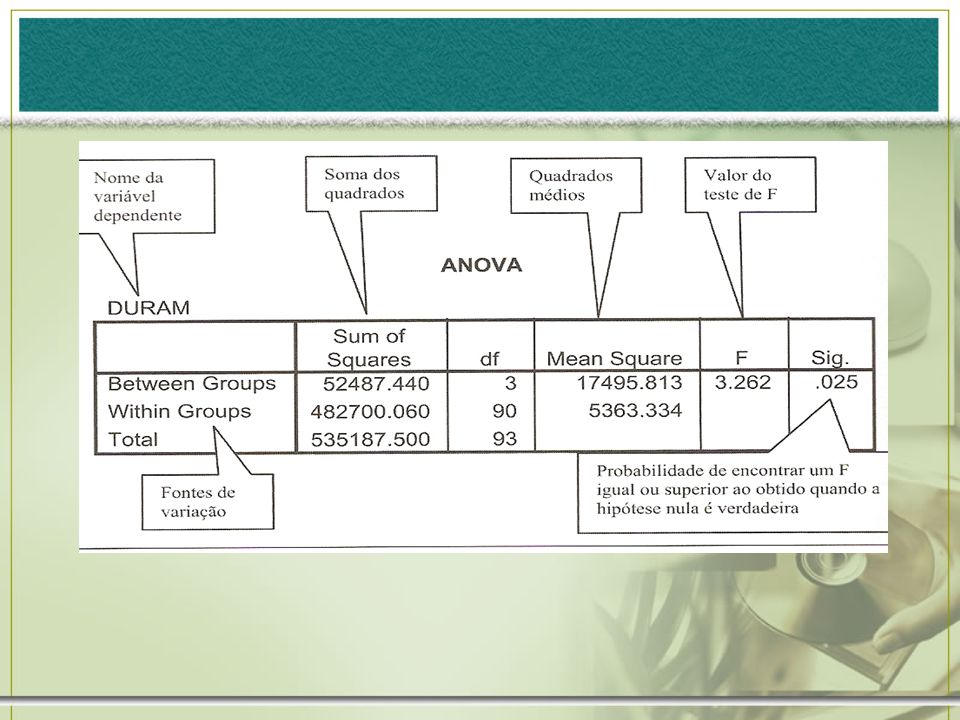
A variação total é dividida em dois componentes:
Between Groups (entre grupos) – representa a variação das médias de todos os grupos em torno da média geral; Within Groups (dentro dos grupos) – representa a variação das observações individuais em torno da média do respectivo grupo. Valores abaixo de .05 indicam a existência de pelo menos um diferença entre as médias dos grupos testados. Sendo assim, rejeita-se a hipótese nula (a variabilidade entre os grupos foi suficientemente grande face à variabilidade dentro dos grupos)
 – representa a variação das médias de todos os grupos em torno da média geral; Within Groups (dentro dos grupos) – representa a variação das observações individuais em torno da média do respectivo grupo. Valores abaixo de .05 indicam a existência de pelo menos um diferença entre as médias dos grupos testados. Sendo assim, rejeita-se a hipótese nula (a variabilidade entre os grupos foi suficientemente grande face à variabilidade dentro dos grupos)")
67
Na ANOVA, quando a diferença entre grupos não é significativa, nenhum teste adicional é necessário. No entanto, quando a diferença entre as médias é significante pelo F-teste, isso não implica, contudo, que todos os grupos difiram entre si. Para determinar onde está a diferença, são necessários testes de comparação múltiplas de médias (Post Hoc).
..")
68
Testes de comparação múltiplas de médias (Post Hoc).
Repetir o procedimento anterior: Analyze – Compare Means – One-Way ANOVA Além das opções escolhidas no procedimento anterior : Descriptives; Homogeneity of variances; Means plot; Exclude cases analysis by analysis Clicar na opção Post Hoc Selecionar Tuckey Continue Ok

69
Além das tabelas de resultados obtidas anteriormente, também surgirá uma tabela com as comparações entre as médias dos grupos dois a dois. A coluna mean difference lista as diferenças entre as médias das amostras. As diferenças significativas são assinaladas com (*). A coluna Sig lista a significancia estatística (p) para as diferenças entre as médias das amostras. Esta coluna lista os limites dos intervalos de confiança de 95% para as diferenças entre as médias das amostras O grupo 2 apresentou diferença significativa em relação ao grupo 1, mas não aos grupos 3 e 4. Esta diferença ode ser explicada pelo tamanho da amostra reduzida para os grupos 3 e 4, dificultando sua diferenciação.
. A coluna Sig lista a significancia estatística (p) para as diferenças entre as médias das amostras. Esta coluna lista os limites dos intervalos de confiança de 95% para as diferenças entre as médias das amostras. O grupo 2 apresentou diferença significativa em relação ao grupo 1, mas não aos grupos 3 e 4. Esta diferença ode ser explicada pelo tamanho da amostra reduzida para os grupos 3 e 4, dificultando sua diferenciação.")
70
O gráfico de Boxplot foi obtido com o comando Explore e representa melhor do que o Means Plot, a distribuição dos tempos cirúrgicos nos grupos.

Apresentações semelhantes