Carregar apresentação
A apresentação está carregando. Por favor, espere

1
Agrupamento (clustering)
Tarefa descritiva que agrupa exemplos (objetos) de acordo com suas características Objetivo: agrupar objetos em clusters (agrupamentos) de modo que objetos pertencentes a um mesmo cluster são mais similares entre si de acordo com alguma medida de similaridade pré-definida, enquanto que objetos pertences a clusters diferentes têm uma similaridade menor Consumo de um carro em função de suas características Valor de um imóvel em função das características dele e do bairro
 de acordo com suas características. Objetivo: agrupar objetos em clusters (agrupamentos) de modo que objetos pertencentes a um mesmo cluster são mais similares entre si de acordo com alguma medida de similaridade pré-definida, enquanto que objetos pertences a clusters diferentes têm uma similaridade menor. Consumo de um carro em função de suas características. Valor de um imóvel em função das características dele e do bairro.")
2
Tarefas de MD Data Mining Atividade Preditiva Atividade Descritiva
Classificação Regressão Regras de Associação Clustering Sumarização

3
Agrupamento Tarefa de aprendizado não-supervisionado:
Exemplos não estão rotulados – não existe uma classe conhecida considerada o atributo meta

4
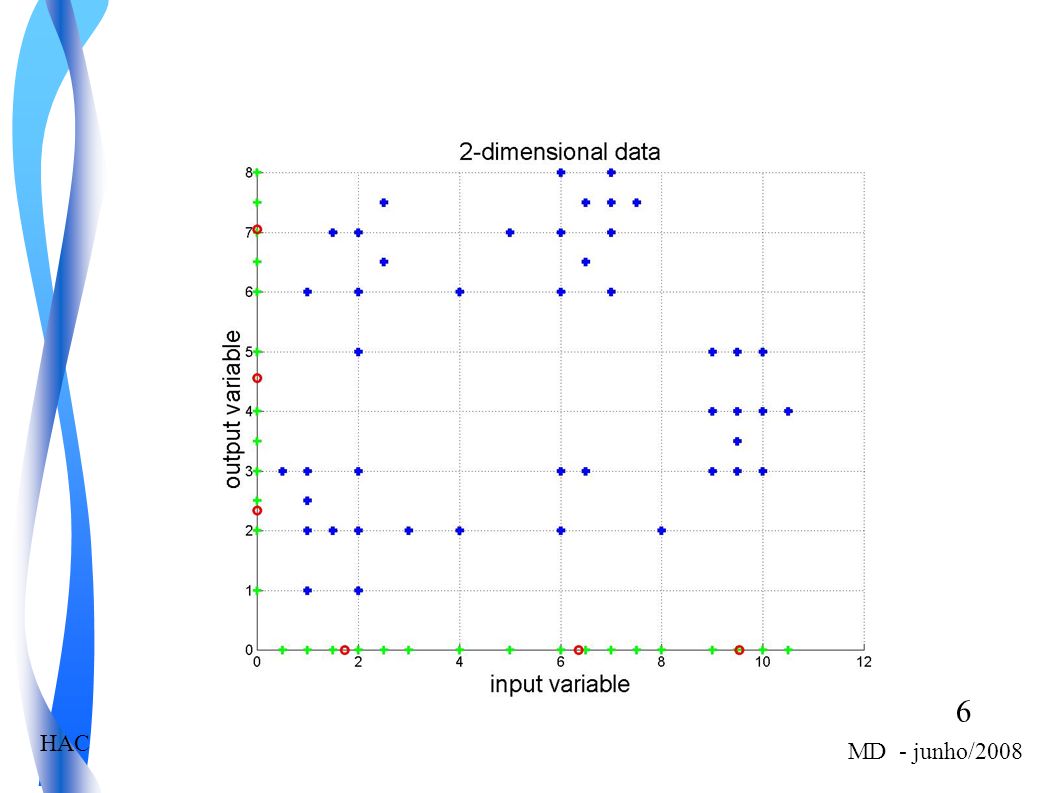
Exemplo 1 2 3 4 5 6 xk1 xk2

5
Examplo – conjunto de dados
1) 0.5 3 16) 6 8 31) 6.5 7.5 2) 1 17) 7 32) 4 2 3) 18) 10 33) 4) 19) 10.5 34) 5) 20) 35) 6) 2.5 21) 9.5 36) 7) 1.5 22) 37) 5 8) 23) 38) 9) 24) 39) 10) 25) 40) 11) 26) 3.5 41) 12) 9 27) 42) 13) 28) 43) 14) 29) 44) 15) 30) 45)
 ) ) ) 1. 17) 7. 32) ) 18) ) 4) 19) ) 5) 20) 35) 6) ) ) 7) ) 37) 5. 8) 23) 38) 9) 24) 39) 10) 25) 40) 11) 26) ) 12) 9. 27) 42) 13) 28) 43) 14) 29) 44) 15) 30) 45)")
7
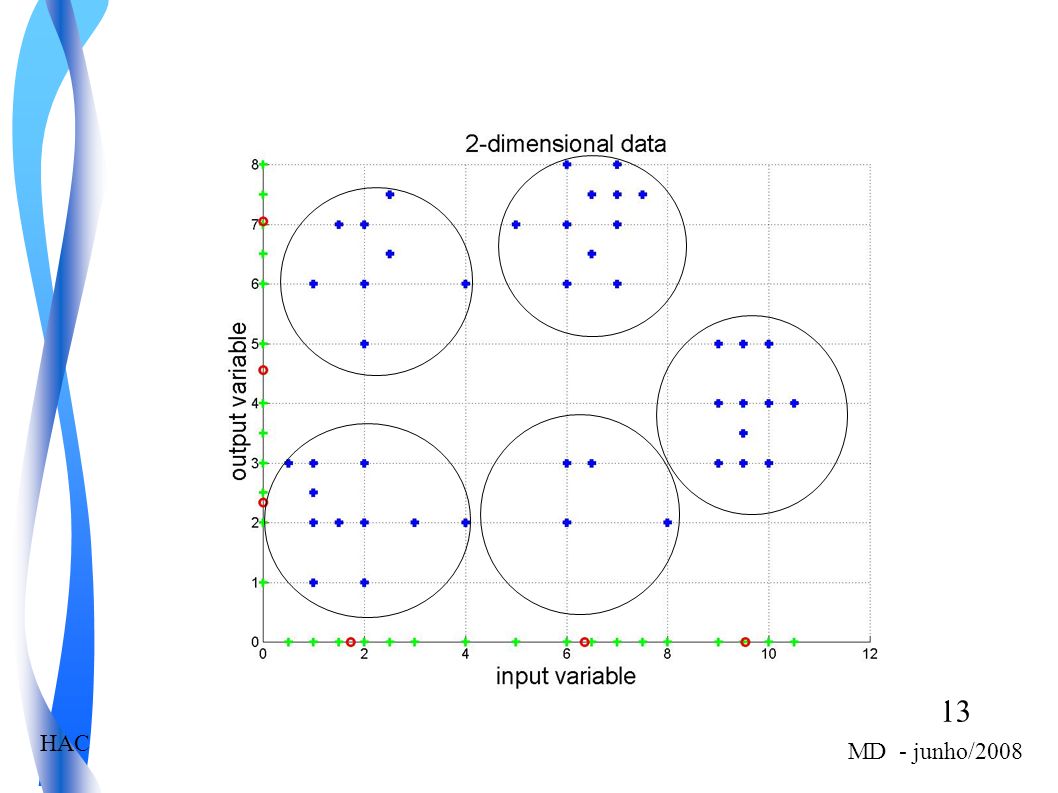
Processo de agrupamento
1. seleção de exemplos e seleção ou construção de atributos seleciona atributos relevantes ou constroi atributos representativos 2. Similaridade entre exemplos seleciona a medida de similaridade a ser utilizada, que deve ser adequada ao domínio 3. Agrupamento aplicação do algoritmo de agrupamento

8
Medidas de similaridade
medidas de distância (para dados contínuos) medidas de correlação medidas de associação (para dados discretos)
 medidas de correlação. medidas de associação. (para dados discretos)")
9
Medidas de distância atributos dos exemplos são considerados como dimensões de um espaço multidimensional cada exemplo corresponde a um ponto no espaço similaridade entre dois pontos é a distância entre eles

10
Medidas de distância Manhattan/city-block D(x,y) = ∑(abs(xi – yi))
formato do cluster encontrado: 0,0

11
D(x,y) = SQRT(∑(xi – yi)2)
Medidas de distância euclidiana D(x,y) = SQRT(∑(xi – yi)2) formato do cluster encontrado: 0,0
 = SQRT(∑(xi – yi)2) formato do cluster encontrado: 0,0.")
12
Formatos de clusters Manhattan Euclidiana Chebychev Mahalanobis

14
Algoritmo k-means usuário define previamente o número k de partições
repetir até que os cluster se estabilizem: Escolher aleatoriamente k pontos que serão os centros dos clusters iniciais – centróides determinar para cada exemplo do conjunto de dados, o cluster ao qual ele pertence, calculando a distância entre o exemplo e o centro do cluster calcular um novo centróide para cada cluster, que passa a ser o novo centro (os pontos iniciais não são os centros definitivos dos clusters, mas sim uma tentativa inicial)
")
Apresentações semelhantes


 Marcílio C. P. de Souto DIMAp/UFRN.>")

. Nenhuns direitos reservados, excepto para fins comerciais. Por favor, não coloque.>")














