Carregar apresentação
1
Análise de Agrupamentos (Clusters) Marcílio C. P. de Souto DIMAp/UFRN
 Marcílio C. P. de Souto DIMAp/UFRN")
2
O que é análise de agrupamentos? (1/4) Dado um conjunto de objetos, colocar os objetos em grupos (clusters) baseados na similaridade entre eles Utilizado para encontrar padrões inesperados nos dados Inerentemente é um problema não definido claramente Como agrupar os animais seguintes?
 Dado um conjunto de objetos, colocar os objetos em grupos (clusters) baseados na similaridade entre eles Utilizado para encontrar padrões inesperados nos dados Inerentemente é um problema não definido claramente Como agrupar os animais seguintes .")
3
O que é análise de agrupamentos? (2/4) Dado um conjunto de objetos, colocar os objetos em grupos baseados na similaridade entre eles Utilizado para encontrar padrões inesperados nos dados Inerentemente é um problema não definido claramente Como agrupar os animais seguintes? Com bico Sem bico
 Dado um conjunto de objetos, colocar os objetos em grupos baseados na similaridade entre eles Utilizado para encontrar padrões inesperados nos dados Inerentemente é um problema não definido claramente Como agrupar os animais seguintes. Com bico Sem bico.")
4
O que é análise de agrupamentos? (3/4) Dado um conjunto de objetos, colocar os objetos em grupos baseados na similaridade entre eles Utilizado para encontrar padrões inesperados nos dados Inerentemente é um problema não definido claramente Como agrupar os animais seguintes? TerraÁgua
 Dado um conjunto de objetos, colocar os objetos em grupos baseados na similaridade entre eles Utilizado para encontrar padrões inesperados nos dados Inerentemente é um problema não definido claramente Como agrupar os animais seguintes. TerraÁgua.")
5
O que é análise de agrupamentos? (4/4) Dado um conjunto de objetos, colocar os objetos em grupos baseados na similaridade entre eles Utilizado para encontrar padrões inesperados nos dados Inerentemente é um problema não definido claramente Como agrupar os animais seguintes? Ovíparo Mamífero
 Dado um conjunto de objetos, colocar os objetos em grupos baseados na similaridade entre eles Utilizado para encontrar padrões inesperados nos dados Inerentemente é um problema não definido claramente Como agrupar os animais seguintes. Ovíparo Mamífero.")
6
Análise de Agrupamentos Aprendizado não-Supervisionado Dado um conjunto de objetos descritos por múltiplos valores (atributos) (1) atribuir grupos (clusters) aos objetos particionando-os objetivamente em grupos homogêneos de maneira a: Maximizar a similaridade de objetos dentro de um mesmo grupo Minimizar a similaridade de objetos entre grupos distintos (2) atribuir uma descrição para cada grupor formado Cluster 1 Cluster 2 Cluster K...... Dados Algoritmo de Agrupamento (1) cor=azul cor=laranja cor=amarelo (2)
 cor=azul cor=laranja cor=amarelo (2).")
7
Representação dos Grupos a d k j h g i f e c b (a) (c) 123 a b c 0.40.10.5 0.1 0.80.1 0.3 0.4... (b) a d k j h g i f e c b (d) g acie dkbjfh
 a d k j h g i f e c b (d) g acie dkbjfh.")
8
Formalmente,... Dado um conjunto de instâncias X={x 1, x 2,..., x N } (meus dados), em que x j ={x j1, x j2,..., x jd } T d e cada x ji é um atributo:
, em que x j ={x j1, x j2,..., x jd } T d e cada x ji é um atributo:.")
9
Agrupamento Particional Um algoritmo de agrupamento particional (hard) gera uma K-partição de X, C={C 1, C 2,..., C K } (K N), tal que: C i (i=1,...,K) i=1 C i = X C i C j = (i,j=1,...,K e i j)
 gera uma K-partição de X, C={C 1, C 2,..., C K } (K N), tal que: C i (i=1,...,K) i=1 C i = X C i C j = (i,j=1,...,K e i j)")
10
Exemplo: Agrupamento Particional C2C2 C1C1 C3C3

11
Agrupamento Hierárquico Um algoritmo de agrupamento hierárquico gera uma estrutura aninhada (árvore) de X, H={H 1, H 2,..., H Q } (K N), tal que: C i H m e C j H l (m > l), implica que C i C j ou C i C j = (i,j,m,l=1,...,Q e i j)
 de X, H={H 1, H 2,..., H Q } (K N), tal que: C i H m e C j H l (m > l), implica que C i C j ou C i C j = (i,j,m,l=1,...,Q e i j)")
12
Agrupamento Hierárquico: Exemplo 0 G F C A B D E 1 2 3 4 1 2 3 4 5 6

13
Agrupamento Fuzzy Para algoritmos de agrupamentos particional hard, cada instância (objeto) pertence a apenas um grupo (cluster) No entanto, pode ser permitido a uma instância pertencer a todos os grupos com um grau de pertinência, u i,j [0,1], que representa o coeficiente de pertinência da j-ésima instância ao i-ésimo grupo (cluster) j i k =1 u i,j =1 e i j N =1 u i,j < N
![Agrupamento Fuzzy Para algoritmos de agrupamentos particional hard, cada instância (objeto) pertence a apenas um grupo (cluster) No entanto, pode ser permitido a uma instância pertencer a todos os grupos com um grau de pertinência, u i,j [0,1], que representa o coeficiente de pertinência da j-ésima instância ao i-ésimo grupo (cluster) j i k =1 u i,j =1 e i j N =1 u i,j < N](http://images.slideplayer.com.br/1/50927/slides/slide_13.jpg "Agrupamento Fuzzy Para algoritmos de agrupamentos particional hard, cada instância (objeto) pertence a apenas um grupo (cluster) No entanto, pode ser permitido a uma instância pertencer a todos os grupos com um grau de pertinência, u i,j [0,1], que representa o coeficiente de pertinência da j-ésima instância ao i-ésimo grupo (cluster) j i k =1 u i,j =1 e i j N =1 u i,j < N")
14
Como funciona a análise de agrupamentos? (1/2) Suponha que um biólogo queira identificar subtipos de um determinado câncer(tumor) com base na expressão gênica do tecido extraído do tumor Uma pequena amostra de sete pacientes é selecionada A expressão gênica de dois genes - V1 e V2 - foi medida para o tumor de cada paciente
 Suponha que um biólogo queira identificar subtipos de um determinado câncer(tumor) com base na expressão gênica do tecido extraído do tumor Uma pequena amostra de sete pacientes é selecionada A expressão gênica de dois genes - V1 e V2 - foi medida para o tumor de cada paciente.")
15
Como funciona a análise de agrupamentos? (2/2) O objetivo principal da análise de agrupamentos é definir a estrutura dos dados colocando observações (instâncias ou objetos) mais parecidas em grupos Mas para conseguir isso, devemos abordar três questões básicas Como medir a similaridade? Correlação, Distância, Medida de Associação,... Como formamos os grupos (clusters)? Não importa apenas medir a similaridade, deve haver um procedimento para agregar as observações mais similares em grupos Quantos grupos formamos? Compromisso entre menos grupos e mais homogeneidade
 O objetivo principal da análise de agrupamentos é definir a estrutura dos dados colocando observações (instâncias ou objetos) mais parecidas em grupos Mas para conseguir isso, devemos abordar três questões básicas Como medir a similaridade. Correlação, Distância, Medida de Associação,... Como formamos os grupos (clusters). Não importa apenas medir a similaridade, deve haver um procedimento para agregar as observações mais similares em grupos Quantos grupos formamos. Compromisso entre menos grupos e mais homogeneidade.")
16
Medida de Similaridade: Distância Euclidiana d(A,B)=Sqrt[(3-4) 2 +(2-5) 2 ] d(C,F)=Sqrt[(4-7) 2 +(7-7) 2 ]........
![Medida de Similaridade: Distância Euclidiana d(A,B)=Sqrt[(3-4) 2 +(2-5) 2 ] d(C,F)=Sqrt[(4-7) 2 +(7-7) 2 ]](http://images.slideplayer.com.br/1/50927/slides/slide_16.jpg "Medida de Similaridade: Distância Euclidiana d(A,B)=Sqrt[(3-4) 2 +(2-5) 2 ] d(C,F)=Sqrt[(4-7) 2 +(7-7) 2 ]")
17
Formação de Grupos Como já temos a medida de similaridade, devemos desenvolver um procedimento para formar grupos Para nosso propósito, usaremos uma regra simples: Identifique as duas observações mais semelhantes (mais próximas) que ainda não estão no mesmo grupo e combine seus grupos Aplicamos essa regra repetidamente, começando com cada observação em seu próprio grupo e combinando dois grupos por vez, até que todas as observações estejam em um único grupo Procedimento Hierárquico e Aglomerativo
 que ainda não estão no mesmo grupo e combine seus grupos Aplicamos essa regra repetidamente, começando com cada observação em seu próprio grupo e combinando dois grupos por vez, até que todas as observações estejam em um único grupo Procedimento Hierárquico e Aglomerativo")
18
Formação de Grupos: Passo 1

19
Formação de Grupos: Passo 2

20
Formação de Grupos: Passo 3

21
Formação de Grupos: Passo 4

22
Formação de Grupos: Passo 5

23
Formação de Grupos: Passo 6

24
Dendograma

25
Solução Inicial 0 G F C A B D E 1 2 3 4

26
Passo 1 0 G F C A B D E 1 2 3 4 1

27
Passo 2 0 G F C A B D E 1 2 3 4 1 2

28
Passo 3 0 G F C A B D E 1 2 3 4 1 2 3

29
Passo 4 0 G F C A B D E 1 2 3 4 1 2 3 4

30
Passo 5 0 G F C A B D E 1 2 3 4 1 2 3 4 5

31
Passo 6 0 G F C A B D E 1 2 3 4 1 2 3 4 5 6

32
Quantos grupos a solução final deve ter? Um método hierárquico resulta em diversas soluções de agrupamentos (partições) No caso do exemplo anterior, elas variam de um a seis grupos Qual devemos escolher? Sabemos que quando nos afastamos de grupos unitários, a homogeneidade diminui Então, por que não ficamos com sete grupos, a opção mais homogênea possível? O problema é que não definimos qualquer estrutura com sete grupos Assim, devemos devemos verificar cada solução para a sua descrição de estrutura versus a homogeneidade dos grupos
 No caso do exemplo anterior, elas variam de um a seis grupos Qual devemos escolher. Sabemos que quando nos afastamos de grupos unitários, a homogeneidade diminui Então, por que não ficamos com sete grupos, a opção mais homogênea possível. O problema é que não definimos qualquer estrutura com sete grupos Assim, devemos devemos verificar cada solução para a sua descrição de estrutura versus a homogeneidade dos grupos.")
33
Quantos grupos a solução final deve ter? Para fins de ilustração, no nosso exemplo foi usada uma medida muito simples homogeneidade: As distâncias médias de todas as observações dentro dos grupos

34
Solução Inicial Na solução inicial com sete grupos, essa medida de similaridade geral é 0 (nenhum observação faz par com alguma outra)
")
35
Passo 1 Nesse passo, a similaridade média (1,414) é a distância entre as duas observações reunidas (E-F)
 é a distância entre as duas observações reunidas (E-F)")
36
Passo 2 Um agrupamento de três elementos (E, F e G) é formado A medida de similaridade geral é a média das distâncias entre E e F (1,414), e E e G (2,000), e F e G (3,162), que nos dá 2,192 Aumento do valor da similaridade geral, em relação ao passo anterior
 é formado A medida de similaridade geral é a média das distâncias entre E e F (1,414), e E e G (2,000), e F e G (3,162), que nos dá 2,192 Aumento do valor da similaridade geral, em relação ao passo anterior")
37
Passo 3 No Passo 3, um novo grupo de dois membros é formado com a distância 2,000 Ligeira diminuição do valor da similaridade geral, em relação ao passo anterior

38
Passo 4 Ligeira alteração do valor da similaridade geral, em relação ao passo anterior Isto significa que estamos gerando outros grupos essencialmente com a homogeneidade dos grupos existentes

39
Passo 5 Combinação de dois grupos com três observações. Grande aumento no valor da similaridade geral, em relação ao passo anterior Isso é indicativo de que reunir esses dois grupos resultou em um agregado que é bem menos homogêneo Segundo a nossa medida, poderíamos considerar a solução do Passo 4 muito melhor do que esta

40
Passo 6 Nesse passo, a medida geral novamente aumenta consideravelmente Ou seja, a observação A mesmo sozinha ainda foi capaz de mudar a homogeneidade do agrupamento. Observação atípica? Portanto, segundo a nossa medida, ainda consideraríamos a solução do Passo 4 muito melhor do que esta

41
Pré-Proc Alg. Clustering Interpretação Validação Conhecimento Dados Partição Passos na Análise de Agrupamentos

42
Medidas de Similaridade Marcilio Souto DIMAp/UFRN

43
Medidas de Similaridade A similaridade entre objetos (instâncias) é uma medida de correspondência ou semelhança entre objetos a serem agrupados Ela pode ser medida de diversas formas Medidas Correlacionais (e.g., correlação de Pearson) Medidas de Distância (e.g., distância euclidiana) Medidas de Associação (e.g., índice de Jaccard) Cada uma dessas formas representa uma perspectiva particular da similaridade, dependendo de seus objetivos e do tipo de dados Tanto as medidas correlacionais quanto as medidas de distância requerem dados métricos, ao passo que as medidas de associação são para dados não-métricos
 é uma medida de correspondência ou semelhança entre objetos a serem agrupados Ela pode ser medida de diversas formas Medidas Correlacionais (e.g., correlação de Pearson) Medidas de Distância (e.g., distância euclidiana) Medidas de Associação (e.g., índice de Jaccard) Cada uma dessas formas representa uma perspectiva particular da similaridade, dependendo de seus objetivos e do tipo de dados Tanto as medidas correlacionais quanto as medidas de distância requerem dados métricos, ao passo que as medidas de associação são para dados não-métricos")
44
Medidas de Similaridade: Fórmulas

45
Medidas Correlacionais Medidas correlacionais representam similaridades pela correspondência de padrões ao longo dos atributos Ela não olha a magnitude do valores dos atributos, apenas o padrão global de valores

46
Exemplo

47
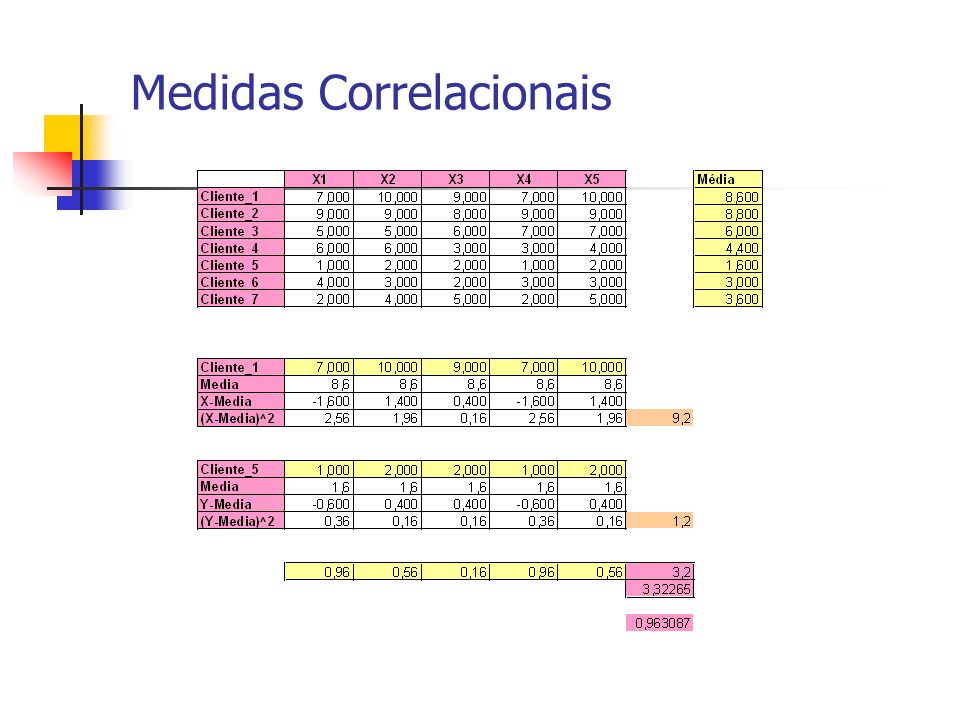
Medidas Correlacionais

49
As instâncias 1, 5 e 7 têm padrões semelhantes e correlação (positiva) alta Da mesma forma instâncias 2, 4 e 6 A instância 3 tem correlação baixa ou negativas com todas as demais, de modo que talvez forme um grupo por si mesma Portanto, as correlações representam padrões ao longo dos atributos, muito mais do que as magnitudes
 alta Da mesma forma instâncias 2, 4 e 6 A instância 3 tem correlação baixa ou negativas com todas as demais, de modo que talvez forme um grupo por si mesma Portanto, as correlações representam padrões ao longo dos atributos, muito mais do que as magnitudes")
50
Medidas de Distância Representam a similaridade como a proximidade entre observações (instâncias) ao longo dos atributos As medidas de distância são, na verdade, uma medida de dissimilaridade, em que os valores maiores denotam menor similaridade A distância é convertida em similaridade pelo uso da relação inversa (1 - distância)
 ao longo dos atributos As medidas de distância são, na verdade, uma medida de dissimilaridade, em que os valores maiores denotam menor similaridade A distância é convertida em similaridade pelo uso da relação inversa (1 - distância)")
51
Medidas de Distância: Exemplo Distância Euclidiana

52
Distância versus Correlação As medidas de distância se concentram na magnitude dos valores e representam casos similares que estão próximos, mas podem ter padrões muito diferentes ao longo dos atributos No caso do exemplo anterior, vemos emergir grupos muitos diferentes quando a distância é considerada em lugar da correlação Como as distâncias menores representam maior similaridade, percebemos que as instâncias 1 e 2 formam um grupo e as instâncias 4, 5, 6 e 7 formam outro Um terceiro grupo, que consiste apenas do caso 3, difere dos outros dois porque possui valores que são tantos altos quanto baixos

53
Distância versus Correlação Agrupamentos baseados em medidas correlacionais podem não ter valores similares, mas sim padrões similares Agrupamentos baseados em distância têm valores mais similares no conjunto de atributos, mas os padrões podem ser bem diferentes

54
Medidas para Atributos Binários Considere dos vetores binários x i e x k n 11 - quantidade de vezes que x il e x kl são ambos 1 n 00 - quantidade de vezes que x il e x kl são ambos 0 n 01 - quantidade de vezes que x il =0 e x kl =1 n 10 - quantidade de vezes que x il =1 e x kl =0

55
Medidas para Atributos Binários Coeficiente de matching simplesÍndice (coeficiente) de Jaccard
 de Jaccard")
56
Medidas para Atributos Categóricos Pode-se transformar esses atributos em binários e, depois, aplicar uma medida binária Outra possibilidade

57
Medidas para Strings Programação Dinâmica Sejam s e t duas seqüências, com |s|=m e |t|=n, construir uma matriz (m+1) x (n+1), em que M(i, j) contém a similaridade entre s[1..i] e t[1..j]. M (i, j) = max M (i, j-1) - 2 (último passo = Inserção) M (i-1, j-1) + p(i,j) (último passo = Substituição/Match) M (i-1, j) - 2 (último passo = Remoção)
![Medidas para Strings Programação Dinâmica Sejam s e t duas seqüências, com |s|=m e |t|=n, construir uma matriz (m+1) x (n+1), em que M(i, j) contém a similaridade entre s[1..i] e t[1..j].](http://images.slideplayer.com.br/1/50927/slides/slide_57.jpg "M (i, j) = max M (i, j-1) - 2 (último passo = Inserção) M (i-1, j-1) + p(i,j) (último passo = Substituição/Match) M (i-1, j) - 2 (último passo = Remoção).")
58
Bibliografia Hair-Jr., J. F. et al (2005). Análise multivariada de dados. Capítulo 9 - Análise de Agrupamentos. pp. 381-419. Bookman. Xu, R. and Wunsch II, D. (2005). Survey of Clustering Algorithms. IEEE Trans. on Neural Networks, v. 16, pp. 645-678.
. Survey of Clustering Algorithms. IEEE Trans. on Neural Networks, v. 16, pp")








>")
>")










