Carregar apresentação
A apresentação está carregando. Por favor, espere

1
Programação em GPUs (OpenGL/GLSL CUDA)
Yalmar Ponce 25 de março de 2017

2
Roteiro Introdução Shaders Exemplos Textura e Multitextura
Tipos de dados, Estruturas, Funções Shaders Exemplos Luz (Direcional, Pontual, Spot) Efeitos (Parede de Tijolos, Madeira, Desenho animado) Modificando Geometria Textura e Multitextura Shader de Geometria FBO CUDA Projeto Final Mapeamento de Sombra (Shadow mapping) 25 de março de 2017
 Efeitos (Parede de Tijolos, Madeira, Desenho animado) Modificando Geometria. Textura e Multitextura. Shader de Geometria. FBO. CUDA. Projeto Final. Mapeamento de Sombra (Shadow mapping) 25 de março de")
3
Introdução Aplicações Renderização em tempo real Efeitos Jogos
25 de março de 2017

4
Introdução GPUs são rápidas... 3.0 GHz Intel Core Extreme
96 GFLOPS – pico Memory Bandwidth: 13 GB/s Preço: 800~ dólares NVIDIA GeForce GTX 280: 930 GFLOPS Memory Bandwidth: 141 GB/s Preço: 499 dólares 25 de março de 2017

5
Introdução Versão simplificada da pipeline CPU GPU Application
Graphics State Xformed, Lit Vertices (2D) Screenspace triangles (2D) Fragments (pre-pixels) Final Pixels (Color, Depth) Application Transform & Light Assemble Primitives Rasterize Shade Vertices (3D) Video Memory (Textures) Render-to-texture Versão simplificada da pipeline 25 de março de 2017
 Screenspace triangles (2D) Fragments (pre-pixels) Final Pixels (Color, Depth) Application. Transform & Light. Assemble Primitives. Rasterize. Shade. Vertices (3D) Video Memory (Textures) Render-to-texture. Versão simplificada da pipeline. 25 de março de")
6
Introdução Processador de Processador de Vértices Programável
CPU GPU Graphics State Vertex Processor Fragment Processor Xformed, Lit Vertices (2D) Screenspace triangles (2D) Fragments (pre-pixels) Final Pixels (Color, Depth) Application Transform & Light Assemble Primitives Rasterize Shade Vertices (3D) Video Memory (Textures) Render-to-texture Processador de Vértices Programável Processador de fragmentos Programável 25 de março de 2017
 Screenspace triangles (2D) Fragments (pre-pixels) Final Pixels (Color, Depth) Application. Transform & Light. Assemble Primitives. Rasterize. Shade. Vertices (3D) Video Memory (Textures) Render-to-texture. Processador de. Vértices Programável. Processador de. fragmentos. Programável. 25 de março de")
7
Introdução Geração de geometria programável
CPU GPU Graphics State Geometry Processor Xformed, Lit Vertices (2D) Screenspace triangles (2D) Fragments (pre-pixels) Final Pixels (Color, Depth) Application Vertex Processor Assemble Primitives Rasterize Fragment Processor Vertices (3D) Video Memory (Textures) Render-to-texture Geração de geometria programável Acesso a memória mais flexível 25 de março de 2017
 Screenspace triangles (2D) Fragments (pre-pixels) Final Pixels (Color, Depth) Application. Vertex Processor. Assemble Primitives. Rasterize. Fragment Processor. Vertices (3D) Video Memory (Textures) Render-to-texture. Geração de geometria programável. Acesso a memória mais flexível. 25 de março de")
8
Shaders Shaders são programas que executam em determinadas etapas do pipeline Não são aplicações stand-alone Necessitam de uma aplicação que utilize um API (OpenGL ou Direct3D) 25 de março de 2017
 25 de março de")
9
Shaders No caso: Vertex shader – Vertex Processor
Fragment shader – Fragment Processor Geometry shader – Geometry Processor 25 de março de 2017

10
Shaders Vertex Processor
Transforma do espaço de mundo para o espaço de tela Calcula iluminação per-vertex 25 de março de 2017

11
Shaders Geometry Processor
Como os vértices se conectam para formar a geometria Operações por primitiva 25 de março de 2017

12
Shaders Fragment Processor Calcula a cor de cada pixel
Obtém cores de texturas 25 de março de 2017
![]()
13
Shaders Hoje a programação de shaders é feita em linguagens de alto nível No estilo de c/c++ As principais que temos hoje: GLSL – OpenGL Shader Language HLSL – High Level Shader Language Cg – C for Graphics 25 de março de 2017

14
Shaders Temos algumas ferramentas que servem tanto para criação e edição de shaders: NVIDIA FX Composer 2.5 RenderMonkey ATI 25 de março de 2017

15
Shaders 25 de março de 2017

16
Shaders 25 de março de 2017

17
Tipos de dados Estruturas bem intuitivas Vetores: Matrizes
vec2, vec3 e vec4 – floating point ivec2, ivec3 e ivec4 – interger bvec2, bvec3 e bvec4 – boolean Matrizes mat2, mat3 e mat4 – floating point 25 de março de 2017

18
Tipos de dados Texturas Sampler1D, Sampler2D, Sampler3D -
texturas 1D, 2D e 3D SamplerCube – Cube map textures Sampler1Dshadow, Sampler2DShadow – mapa de profundidade 1D e 2D 25 de março de 2017

19
Input/Output Existem 3 tipos de input em um shader: Uniforms Varyings
Attributes 25 de março de 2017

20
Input/Output Uniforms Varyings Não mudam durante o rendering
Ex: Posição da luz ou cor da luz Esta presente em todos os tipos de shader Varyings Usado para passar dados do vertex shader para o fragment shader ou geometry shader 25 de março de 2017

21
Input/Output Varyings Attributes
São read-only no fragment e geometry shader mas read/write no vertex shader Deve-se declarar a mesma varying em todos os programas Attributes Estão presentes apenas nos Vertex shaders São valores (possivelmente diferentes) associados a cada vértice 25 de março de 2017
 associados a cada vértice. 25 de março de")
22
Input/Output Attributes Ex: Posição do vértice ou normais
São apenas read-only 25 de março de 2017

23
Input/Output Exemplos de Attributes no vertex shader
gl_Vertex – vetor 4D, posição do vértice gl_Normal – vetor 3D, Normal do vértice gl_Color – vetor 4D, cor do vértice gl_MultiTexCoordX – vetor 4D, coordenada de textura na unit X Existem vários outros atributos 25 de março de 2017

24
Input/Output Exemplos de Uniforms gl_ModelViewMatrix
gl_ModelViewProjectionMatrix gl_NormalMatrix 25 de março de 2017

25
Input/Output Exemplos de Varyings
gl_FrontColor - vetor 4D com a cor frontal das primitivas gl_BackColor – vetor 4D com a cor de trás das primitivas gl_TexCoord[N] – vetor 4D representando a n-ésima coordenada de textura 25 de março de 2017

26
Input/Output Exemplos de output:
gl_Position – vetor 4D representando a posição final do vértice gl_FragColor – vetor 4D representando a cor final que será escrita no frame buffer gl_FragDepth – float representando o depth que será escrito do depth buffer 25 de março de 2017

27
Input/Output Também é possível definir attributes, uniforms e varyings
Ex: Passar um vetor tangente 3D por todos os vértices da sua aplicação É possível especificar o atributo “tangente” attribute vec3 tangente; 25 de março de 2017

28
Input/Output Alguns outros exemplos:
uniform sampler2D my_color_texture; varying vec3 vertex_to_light_vector; varying vec3 vertex_to_eye_vector; attribute vec3 binormal; 25 de março de 2017

29
Funções e Estruturas de Controle
Similar a linguagem C Suporta estruturas de repetição e decisão If/else For Do/while Break Continue 25 de março de 2017

30
Funções e Estruturas de Controle
Possui funções como: Seno (sin) Cosseno (cos) Tangente (tan) Potencia (pow) Logaritmo (log) Logaritmo (log2) Raiz (sqrt) 25 de março de 2017
 Cosseno (cos) Tangente (tan) Potencia (pow) Logaritmo (log) Logaritmo (log2) Raiz (sqrt) 25 de março de")
31
GLSL-Setup Antes de criar os shaders é necessário implementar uma função (no caso do GLSL) para ler e enviar os shaders para o hardware 25 de março de 2017

32
GLSL-Setup void setShaders(){ char *vs = NULL,*fs = NULL,*fs2 = NULL;
v = glCreateShader(GL_VERTEX_SHADER); f = glCreateShader(GL_FRAGMENT_SHADER); vs = textFileRead("minimal.vert"); fs = textFileRead("minimal.frag"); const char * vv = vs; const char * ff = fs; glShaderSource(v, 1, &vv,NULL); glShaderSource(f, 1, &ff,NULL); free(vs);free(fs); glCompileShader(v); glCompileShader(f); p = glCreateProgram(); glAttachShader(p,v); glAttachShader(p,f); glLinkProgram(p); glUseProgram(p); } 25 de março de 2017
; f = glCreateShader(GL_FRAGMENT_SHADER); vs = textFileRead( minimal.vert ); fs = textFileRead( minimal.frag ); const char * vv = vs; const char * ff = fs; glShaderSource(v, 1, &vv,NULL); glShaderSource(f, 1, &ff,NULL); free(vs);free(fs); glCompileShader(v); glCompileShader(f); p = glCreateProgram(); glAttachShader(p,v); glAttachShader(p,f); glLinkProgram(p); glUseProgram(p); } 25 de março de")
33
Exemplos simples 25 de março de 2017

34
Hello World O código shader mais simples Vertex Shader Fragment Shader
void main() { gl_Position = ftransform(); } Fragment Shader void main(){ gl_FragColor = vec4(0.4,0.4,0.8,1.0); 25 de março de 2017
 { gl_Position = ftransform(); } Fragment Shader. void main(){ gl_FragColor = vec4(0.4,0.4,0.8,1.0); 25 de março de")
35
Modificando a geometria
Achatar o modelo 3D, ou seja, z = 0 void main(void) { vec4 v = vec4(gl_Vertex); v.z = 0.0; gl_Position = gl_ModelViewProjectionMatrix * v; } 25 de março de 2017
 { vec4 v = vec4(gl_Vertex); v.z = 0.0; gl_Position = gl_ModelViewProjectionMatrix * v; } 25 de março de")
36
Modificando a geometria II
void main(void){ vec4 v = vec4(gl_Vertex); v.z = sin(5.0*v.x )*0.25; gl_Position = gl_ModelViewProjectionMatrix * v; } 25 de março de 2017
{ vec4 v = vec4(gl_Vertex); v.z = sin(5.0*v.x )*0.25; gl_Position = gl_ModelViewProjectionMatrix * v; } 25 de março de")
37
Animação É necessário manter a passagem do tempo nos frames
No vertex shader não é possível guardar valores a variável é definida na aplicação OpenGL 25 de março de 2017

38
Animação O shader recebe o valor time numa variável Uniform
uniform float time; void main(void){ vec4 v = vec4(gl_Vertex); v.z = sin(5.0*v.x + time*0.01)*0.25; gl_Position = gl_ModelViewProjectionMatrix*v; } A função de render: void renderScene(void){ ... glUniform1fARB(loc, time); glutSolidTeapot(1); time+=0.01; glutSwapBuffers(); } 25 de março de 2017
{ vec4 v = vec4(gl_Vertex); v.z = sin(5.0*v.x + time*0.01)*0.25; gl_Position = gl_ModelViewProjectionMatrix*v; } A função de render: void renderScene(void){ ... glUniform1fARB(loc, time); glutSolidTeapot(1); time+=0.01; glutSwapBuffers(); } 25 de março de")
39
Manipulação de Texturas
GLSL permite acesso as coordenadas de textura por vértice GLSL provê variáveis do tipo Attribute, para cada unidade de textura (max 8) attribute vec4 gl_MultiTexCoord[0..8] 25 de março de 2017
 attribute vec4 gl_MultiTexCoord[0..8] 25 de março de")
40
Manipulação de Texturas
Precisa calcular a coordenada de textura Armazenar numa variável varying gl_TexCoord[i] onde i é a unidade de textura utilizada gl_TexCoord[0] = gl_MultiTexCoord0; Um simples código para definir coordenadas de textura para uma textura utilizando a unit 0 Vertex Shader void main(){ gl_Position = ftransform(); } 25 de março de 2017
{ gl_Position = ftransform(); } 25 de março de")
41
Manipulação de Texturas
gl_TexCoord é uma variável varying Será utilizada no fragment shader para acessar as coordenadas de textura interpoladas Para acessar os valores de textura temos que declarar uma variável do tipo uniform no fragment shader Para uma textura 2D temos: uniform sampler2D tex; 25 de março de 2017

42
Manipulação de Texturas
A função que nos retorna um textel é a texture2D Os valores retornados levam em consideração todos as definições de textura feitos no OpenGL (filtering, mipmap, clamp, etc) 25 de março de 2017
 25 de março de")
43
Manipulação de Texturas
Vertex Shader void main(){ gl_TexCoord[0] = gl_MultiTexCoord0; gl_Position = ftransform(); } Fragment shader uniform sampler2D tex; void main() { vec4 color = texture2D(tex,gl_TexCoord[0].st); gl_FragColor = color; 25 de março de 2017
{ gl_TexCoord[0] = gl_MultiTexCoord0; gl_Position = ftransform(); } Fragment shader. uniform sampler2D tex; void main() { vec4 color = texture2D(tex,gl_TexCoord[0].st); gl_FragColor = color; 25 de março de")
44
Múltiplas Texturas Definir as texturas
glGenTextures(1, &Textura); glBindTexture(GL_TEXTURE_2D, Textura); glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_NEAREST); glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_NEAREST); glTexImage2D(GL_TEXTURE_2D, level, format, Width, Height, 0, GL_RGB,GL_UNSIGNED_BYTE, TexureInfo); Na aplicação OpenGL, é necessário habilitar as texturas que serão usadas. glActivateTexture(GL_TEXTUREi) onde i = 0..8 25 de março de 2017
; glBindTexture(GL_TEXTURE_2D, Textura); glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_NEAREST); glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_NEAREST); glTexImage2D(GL_TEXTURE_2D, level, format, Width, Height, 0, GL_RGB,GL_UNSIGNED_BYTE, TexureInfo); Na aplicação OpenGL, é necessário habilitar as texturas que serão usadas. glActivateTexture(GL_TEXTUREi) onde i = de março de")
45
Múltiplas Texturas Multi Texturing glEnable (GL_TEXTURE_2D);
glActiveTexture(GL_TEXTURE0); glBindTexture(GL_TEXTURE_2D, texid0); glActiveTexture(GL_TEXTURE1); glBindTexture(GL_TEXTURE_2D, texid1); ... glBegin(GLenum Mode); . glEnd(); glDisable (GL_TEXTURE_2D); 25 de março de 2017
; glBindTexture(GL_TEXTURE_2D, texid0); glActiveTexture(GL_TEXTURE1); glBindTexture(GL_TEXTURE_2D, texid1); ... glBegin(GLenum Mode); . glEnd(); glDisable (GL_TEXTURE_2D); 25 de março de")
46
GLSL e Multi-Textura Cada textura que será usada no programa GLSL deve ser associada a uma textura na aplicação OpenGL. Vertex/Fragment Shader uniform sampler2D textureName1, textureName2; Programa OpenGL (inicialiazação) GLuint tex1, tex2; GLint texLoc1, texLoc2; texLoc1 = glGetUniformLocation(programObj, "textureName1"); texLoc2 = glGetUniformLocation(programObj, "textureName2"); glUniform1i(texLoc1, 0); // a primeira deve ser 0 glUniform1i(texLoc2, 1); Programa OpenGL ( ativar multitextura) glEnable(GL_TEXTURE_2D); glActiveTexture(GL_TEXTURE0); // habilita para uso tex1 glActiveTexture(GL_TEXTURE1); // habilita para uso tex2 drawQuad(); Note que a textura atribuída com a função glUniform1i(texLoc1, i) i = 0, 1, ... deve ser ativada com glActiveTexture(GL_TEXTUREi) antes de usar um programa GLSL 25 de março de 2017
 GLuint tex1, tex2; GLint texLoc1, texLoc2; texLoc1 = glGetUniformLocation(programObj, textureName1 ); texLoc2 = glGetUniformLocation(programObj, textureName2 ); glUniform1i(texLoc1, 0); // a primeira deve ser 0. glUniform1i(texLoc2, 1); Programa OpenGL ( ativar multitextura) glEnable(GL_TEXTURE_2D); glActiveTexture(GL_TEXTURE0); // habilita para uso tex1 glActiveTexture(GL_TEXTURE1); // habilita para uso tex2. drawQuad(); Note que a textura atribuída com a função glUniform1i(texLoc1, i) i = 0, 1, ... deve ser ativada com glActiveTexture(GL_TEXTUREi) antes de usar um programa GLSL. 25 de março de")
47
Textura 3D glGenTextures(1, &TexName); glBindTexture(GL_TEXTURE_3D, TexName); glTexParameterf(GL_TEXTURE_3D, GL_TEXTURE_WRAP_S, GL_REPEAT); glTexParameterf(GL_TEXTURE_3D, GL_TEXTURE_WRAP_T, GL_REPEAT); glTexParameterf(GL_TEXTURE_3D, GL_TEXTURE_WRAP_R, GL_REPEAT); glTexParameterf(GL_TEXTURE_3D, GL_TEXTURE_MAG_FILTER, GL_LINEAR); glTexParameterf(GL_TEXTURE_3D, GL_TEXTURE_MIN_FILTER, GL_LINEAR); glTexImage3D(GL_TEXTURE_3D, 0, GL_RGBA, TexSize, TexSize, TexSize, 0, GL_RGBA,GL_UNSIGNED_BYTE, data); 25 de março de 2017
; glBindTexture(GL_TEXTURE_3D, TexName); glTexParameterf(GL_TEXTURE_3D, GL_TEXTURE_WRAP_S, GL_REPEAT); glTexParameterf(GL_TEXTURE_3D, GL_TEXTURE_WRAP_T, GL_REPEAT); glTexParameterf(GL_TEXTURE_3D, GL_TEXTURE_WRAP_R, GL_REPEAT); glTexParameterf(GL_TEXTURE_3D, GL_TEXTURE_MAG_FILTER, GL_LINEAR); glTexParameterf(GL_TEXTURE_3D, GL_TEXTURE_MIN_FILTER, GL_LINEAR); glTexImage3D(GL_TEXTURE_3D, 0, GL_RGBA, TexSize, TexSize, TexSize, 0, GL_RGBA,GL_UNSIGNED_BYTE, data); 25 de março de")
48
Exemplos mais complexos
25 de março de 2017

49
Efeito tijolo Vertex Shader Fragment Shader
Fragment Shader 25 de março de 2017

50
Effeito madeira Vertex Shader Fragment Shader
Fragment Shader 25 de março de 2017

51
Efeito nuvem Vertex Shader
Fragment Shader 25 de março de 2017

52
Geometry Shader 25 de março de 2017

53
Geometry Shader Permite mudar a geometria de entrada
Necessário especificar a geometria de entrada e saida glProgramParameteriEXT(GLhandleARB program, GL_GEOMETRY_INPUT_TYPE_EXT, GL_LINES_ADJACENCY_EXT); glProgramParameteriEXT(GLhandleARB program, GL_GEOMETRY_OUTPUT_TYPE_EXT, GL_TRIANGLE_STRIP); Adicionalmente deve ser especificado o número máximo de vértices a serem criados glGetIntegerv(GL_MAX_GEOMETRY_OUTPUT_VERTICES_EXT,&temp); glProgramParameteriEXT(GLhandleARB program, GL_GEOMETRY_VERTICES_OUT_EXT,temp); 25 de março de 2017
; glProgramParameteriEXT(GLhandleARB program, GL_GEOMETRY_OUTPUT_TYPE_EXT, GL_TRIANGLE_STRIP); Adicionalmente deve ser especificado o número máximo de vértices a serem criados. glGetIntegerv(GL_MAX_GEOMETRY_OUTPUT_VERTICES_EXT,&temp); glProgramParameteriEXT(GLhandleARB program, GL_GEOMETRY_VERTICES_OUT_EXT,temp); 25 de março de")
54
Geometry Shader Convenções #version 120
#extension GL_EXT_geometry_shader4 : enable Geometry language built-in outputs: varying out vec4 gl_FrontColor; varying out vec4 gl_BackColor; varying out vec4 gl_FrontSecondaryColor; varying out vec4 gl_BackSecondaryColor; varying out vec4 gl_TexCoord[]; // at most gl_MaxTextureCoords varying out float gl_FogFragCoord; Geometry language input varying variables: varying in vec4 gl_FrontColorIn[gl_VerticesIn]; varying in vec4 gl_BackColorIn[gl_VerticesIn]; varying in vec4 gl_FrontSecondaryColorIn[gl_VerticesIn]; varying in vec4 gl_BackSecondaryColorIn[gl_VerticesIn]; varying in vec4 gl_TexCoordIn[gl_VerticesIn][]; varying in float gl_FogFragCoordIn[gl_VerticesIn]; varying in vec4 gl_PositionIn[gl_VerticesIn]; varying in float gl_PointSizeIn[gl_VerticesIn]; varying in vec4 gl_ClipVertexIn[gl_VerticesIn]; 25 de março de 2017

55
Exemplo #version 120 #extension GL_EXT_geometry_shader4:enable
#extension GL_EXT_gpu_shader4:enable varying out vec3 eyeNormal; varying out vec3 vNormal; varying out vec3 eyePosition; varying out vec3 LightPosition; void main(void){ vec4 v = gl_PositionIn[0]; LightPosition = gl_LightSource[0].position; vec4 p0 = texture2D(vtx_tex, getPos(v.x)); vec4 p1 = texture2D(vtx_tex, getPos(v.y)); vec4 p2 = texture2D(vtx_tex, getPos(v.z)); vec4 p3 = texture2D(vtx_tex, getPos(v.w)); ... ... eyeNormal = n0; vNormal = vn0; eyePosition = py0; gl_Position = pt0; EmitVertex(); vNormal = vn1; eyePosition = py1; gl_Position = pt1; vNormal = vn2; eyePosition = py2; gl_Position = pt2; EndPrimitive(); } 25 de março de 2017
{ vec4 v = gl_PositionIn[0]; LightPosition = gl_LightSource[0].position; vec4 p0 = texture2D(vtx_tex, getPos(v.x)); vec4 p1 = texture2D(vtx_tex, getPos(v.y)); vec4 p2 = texture2D(vtx_tex, getPos(v.z)); vec4 p3 = texture2D(vtx_tex, getPos(v.w)); eyeNormal = n0; vNormal = vn0; eyePosition = py0; gl_Position = pt0; EmitVertex(); vNormal = vn1; eyePosition = py1; gl_Position = pt1; vNormal = vn2; eyePosition = py2; gl_Position = pt2; EndPrimitive(); } 25 de março de")
56
Exemplo #version 120 #extension EXT_gpu_shader4 : require
varying vec3 eyeNormal; varying vec3 vNormal; varying vec3 eyePosition; varying vec3 LightPosition; void main() { vec3 light = normalize( LightPosition ); vec3 r = reflect( eyePosition, eyeNormal)*0.5; vec3 red = vec3( 0.23, 0.52, 0.72); const vec3 white = vec3( 1, 1, 1); float ndotl = max(dot( eyeNormal, light), 0.0); if (ndotl == 0.0) ndotl = dot( eyeNormal, -light); ndotl = min( max( ndotl, 0.0) + 0.2, 1.0); float spec = pow( max( 0.0, dot( r, light)), 32.0); vec3 color = clamp( ndotl*red + spec*white, 0.0, 1.0); gl_FragColor = vec4( color, 1.0); } 25 de março de 2017
 { vec3 light = normalize( LightPosition ); vec3 r = reflect( eyePosition, eyeNormal)*0.5; vec3 red = vec3( 0.23, 0.52, 0.72); const vec3 white = vec3( 1, 1, 1); float ndotl = max(dot( eyeNormal, light), 0.0); if (ndotl == 0.0) ndotl = dot( eyeNormal, -light); ndotl = min( max( ndotl, 0.0) + 0.2, 1.0); float spec = pow( max( 0.0, dot( r, light)), 32.0); vec3 color = clamp( ndotl*red + spec*white, 0.0, 1.0); gl_FragColor = vec4( color, 1.0); } 25 de março de")
57
Conclusões Diversos tipos de aplicações 25 de março de 2017

58
Conclusões 25 de março de 2017

59
Classe C++ para o Setup GLSL
LCG Toolkit 25 de março de 2017

60
Exemplo de uso #include "glslkernel.h“ GLSLKernel VBOShader;
VBOShader.vertex_source("vertex.glsl"); VBOShader.geometry_source("geometry.glsl"); VBOShader.fragment_source("fragment.glsl"); VBOShader.set_geom_max_output_vertices(12); VBOShader.set_geom_input_type(GL_POINTS); VBOShader.set_geom_output_type(GL_TRIANGLE_STRIP); VBOShader.install(true); VBOShader.use(true); VBOShader.set_uniform("vtx_tex", 0); glDrawElements( GL_POINTS, n_points, GL_UNSIGNED_INT, 0); VBOShader.use(false); 25 de março de 2017
; VBOShader.geometry_source( geometry.glsl ); VBOShader.fragment_source( fragment.glsl ); VBOShader.set_geom_max_output_vertices(12); VBOShader.set_geom_input_type(GL_POINTS); VBOShader.set_geom_output_type(GL_TRIANGLE_STRIP); VBOShader.install(true); VBOShader.use(true); VBOShader.set_uniform( vtx_tex , 0); glDrawElements( GL_POINTS, n_points, GL_UNSIGNED_INT, 0); VBOShader.use(false); 25 de março de")
61
Framebuffers 25 de março de 2017

62
Frame buffer Escrita em memória é feito pelo processador de fragmentos
Memória GPU apenas de escrita VS 3.0 GPUs Texture er result to ``other GPU memory'' (i.e., texture) - Write directly to ``other GPU memory'' instead of framebuffer. - Does the OS or OpenGL own GPU memory? - What other memory can we write to? - Textures - Vertex array buffers? - Fbuffer? - Mechanisms by which GPU can write to its own memory - Copy from framebuffer/pbuffer to texture - Cross platform - 2D output, save in 1D, 2D, 3D texture memory - Slow... - WGL_ARB_render_texture - RTT using pbuffers (only on Windows) - Fast RTT, but context switch is slow (time this!) - Current state of the art and lots of hacks to speed up - See next section for details of hackery - GL_EXT_Render_Target - Lightweight extension to enable x-platform, efficient RTT. - Spec. not yet approved and no implemenation - GL_EXT_pixel_buffer_object - Copy from frame buffer to vertex buffer - Asynchronous CPU readbacks - Supported by current NVIDIA drivers - TODO: Can I talk about this? - Uber buffers - General memory model for GPUs - Textures, frame buffers, vertex buffers are all just ``memory'' - Render to any GPU memory: N-D Texture, Vertex arrays, stencil bufer, frame buffer, etc. - Cross platform (OpenGL owns the memory, not the OS) - Mix-and-match depth buffers/color buffers/etc. - Alpha ATI drivers and spec. not approved - Stream/GPU-Based Data Structures 1) Multi-dimensional streams - Read/Write GPU memory optimized for 2D (images!) - But isn't memory all really 1D? - Yes, but GPU memory heirarchy is optimized for 2D accesses. Texture caches must capture multidimensional locality for texture filtering and 2D rasterization. - Reference texture cache stanford paper. - Result is that GPGPU programmer should use illusion of 2D physical memory. - Large 1D streams - Lay out in 2D - 3D streams - Update slice-by-slice (potentially limits parallelism) - Flatten parts or all into large 2D texture(s) - Streams of higher dimension (> 3D) - Layout in 2D memory in the same way that N-D arrays use 1D CPU memory. - 2D memory is limited in size. 4) How does the GPU get memory addresses? - Per-Vertex - Vertex attributes - Computed in vertex program - Read from vertex texture - Per-Fragment - Per-vertex addresses interpolated by rasterizer - Computed in fragment stage - Read from texture memory 2) Pointers - Dependent texture lookups 3) Sparse Data - Two options - Store entire dataset on GPU and create substreams out of it (depth culling or geometry-based substreams). - Sherbondy et al., IEEE Visualization 2003 - Purcell et al. - Only store sparse data on GPU (in packed format) - Sparse matrices: Kruger, Bolz - Sparse volume: Lefohn - Performance - Pbuffers - Currently the state-of-the-art for RTT - Most implementations optimized for RGBA??? (TODO: Is this true?) - Avoid context switches (TIME this!!) - Pack scalar data into RGBA channels - Use multiple surfaces (front/back/aux0/...) - Pack 2D domains into larger buffers (dangerous!) - Texture Cache Considerations - Caches designed to capture 2D locality wrt. to rasterization and texture filtering. - Dependent Texture Reads - NVIDIA: Based on cache locality - ATI: ??? - Compute addresses at lowest possible computational frequency - Neighbor offsets in vertex program - Avoid fragment-level address computation whenever possible Vertex Processor Fragment Processor Frame Buffer(s) Vertex Buffer Rasterizer 25 de março de 2017 62
 - Write directly to ``other GPU memory instead of framebuffer. - Does the OS or OpenGL own GPU memory - What other memory can we write to - Textures. - Vertex array buffers - Fbuffer - Mechanisms by which GPU can write to its own memory. - Copy from framebuffer/pbuffer to texture. - Cross platform. - 2D output, save in 1D, 2D, 3D texture memory. - Slow... - WGL_ARB_render_texture. - RTT using pbuffers (only on Windows) - Fast RTT, but context switch is slow (time this!) - Current state of the art and lots of hacks to speed up. - See next section for details of hackery. - GL_EXT_Render_Target. - Lightweight extension to enable x-platform, efficient RTT. - Spec. not yet approved and no implemenation. - GL_EXT_pixel_buffer_object. - Copy from frame buffer to vertex buffer. - Asynchronous CPU readbacks. - Supported by current NVIDIA drivers. - TODO: Can I talk about this - Uber buffers. - General memory model for GPUs. - Textures, frame buffers, vertex buffers are all just ``memory - Render to any GPU memory: N-D Texture, Vertex arrays, stencil. bufer, frame buffer, etc. - Cross platform (OpenGL owns the memory, not the OS) - Mix-and-match depth buffers/color buffers/etc. - Alpha ATI drivers and spec. not approved. - Stream/GPU-Based Data Structures. 1) Multi-dimensional streams. - Read/Write GPU memory optimized for 2D (images!) - But isn t memory all really 1D - Yes, but GPU memory heirarchy is optimized for 2D. accesses. Texture caches must capture multidimensional. locality for texture filtering and 2D rasterization. - Reference texture cache stanford paper. - Result is that GPGPU programmer should use illusion of 2D. physical memory. - Large 1D streams. - Lay out in 2D. - 3D streams. - Update slice-by-slice (potentially limits parallelism) - Flatten parts or all into large 2D texture(s) - Streams of higher dimension (> 3D) - Layout in 2D memory in the same way that N-D arrays use. 1D CPU memory. - 2D memory is limited in size. 4) How does the GPU get memory addresses - Per-Vertex. - Vertex attributes. - Computed in vertex program. - Read from vertex texture. - Per-Fragment. - Per-vertex addresses interpolated by rasterizer. - Computed in fragment stage. - Read from texture memory. 2) Pointers. - Dependent texture lookups. 3) Sparse Data. - Two options. - Store entire dataset on GPU and create substreams out. of it (depth culling or geometry-based substreams). - Sherbondy et al., IEEE Visualization Purcell et al. - Only store sparse data on GPU (in packed format) - Sparse matrices: Kruger, Bolz. - Sparse volume: Lefohn. - Performance. - Pbuffers. - Currently the state-of-the-art for RTT. - Most implementations optimized for RGBA (TODO: Is this true ) - Avoid context switches (TIME this!!) - Pack scalar data into RGBA channels. - Use multiple surfaces (front/back/aux0/...) - Pack 2D domains into larger buffers (dangerous!) - Texture Cache Considerations. - Caches designed to capture 2D locality wrt. to rasterization. and texture filtering. - Dependent Texture Reads. - NVIDIA: Based on cache locality. - ATI: - Compute addresses at lowest possible computational frequency. - Neighbor offsets in vertex program. - Avoid fragment-level address computation whenever possible. Vertex. Processor. Fragment. Processor. Frame. Buffer(s) Vertex Buffer. Rasterizer. 25 de março de")
63
OpenGL Framebuffer Objects
Ideia Geral Framebuffer object pode ser visto como uma estrutura de ponteiros Associar memória da GPU a um framebuffer como write-only A memória não pode ser lida enquanto estiver associada ao framebuffer Qual memória? Texture Renderbuffer Vertex buffer?? Texture (RGBA) Framebuffer Object Renderbuffer (Depth) 25 de março de 2017 63 63
 Framebuffer. Object. Renderbuffer. (Depth) 25 de março de")
64
Framebuffer Objects O que é um FBO?
Uma estrutura que manipula ponteiros e objetos memória Cada objeto memória associado pode ser usado como um framebuffer para rendering 25 de março de 2017 64 64

65
Framebuffer Objects (FBOs)
OpenGL extension Habilita render-to-texture in OpenGL Mix-and-match depth/stencil buffers Substitui pbuffers! Platform-independent 25 de março de 2017 65 65

66
Framebuffer Objects Quais tipos de memória podem ser associados a um FBO? Textures Renderbuffers Depth, stencil, color Framebuffers de escrita tradicionais 25 de março de 2017 66 66

67
Que é um Renderbuffer? Modelo “Traditional” de memória framebuffer
Memória GPU Write-only Color buffer Depth buffer Stencil buffer Novo objeto de memória OpenGL Parte do Framebuffer Object extension 25 de março de 2017 67 67

68
Renderbuffer Operações suportadas CPU interface Allocate Free
Copia GPU CPU Associar para acesos write-only no framebuffer 25 de março de 2017 68 68

69
Framebuffer Objects Modo de uso
Pode ter N texturas associadas a um FBO (até 16) destinos de rendering são cambiados com glDrawBuffers Manter uma FBO para cada tamanho/formato Mudar destinos de rendering attach/unattach textures Pode ter diferentes FBOs com texturas vinculadas Mudar destinos de rendering ligando (bind) FBOs 25 de março de 2017 69 69
 destinos de rendering são cambiados com glDrawBuffers. Manter uma FBO para cada tamanho/formato. Mudar destinos de rendering. attach/unattach textures. Pode ter diferentes FBOs com texturas vinculadas. Mudar destinos de rendering ligando (bind) FBOs. 25 de março de")
70
Framebuffer Objects Performance Render-to-texture Readback
glDrawBuffers Mais eficientes que pbuffers Attach/unattach texturas é mais eficiente que mudar de FBO Manter formato/tamanho idêntico para todas as memórias associadas ao FBO Readback glReadPixels 25 de março de 2017 70 70

71
Framebuffer Object Exemplos e maiores detalhes
Classes C++ de FBO e Renderbuffer OpenGL Spec 25 de março de 2017 71 71

72
Pixel Buffer Objects Mecanismo eficiente para transferir pixel data
API parecido com vertex buffer objects VS 3.0 GPUs Texture Vertex Processor Fragment Processor Frame Buffer(s) Vertex Buffer Rasterizer 25 de março de 2017 72 72
![]()
73
Pixel Buffer Objects Usos Render-to-vertex-array
glReadPixels no GPU-based pixel buffer Usar pixel buffer como vertex buffer Streaming de textures rápido Mapear PBO na memória da CPU Escrever diretamente ao PBO Reduz uma ou mais cópias Readback asincrono Cópia de dados GPU CPU não-bloqueante glReadPixels no PBO não bloqueiado É bloqueiado quando PBO é mapeiado na memória da CPU 25 de março de 2017 73 73
![]()
74
Resumo : Render-to-Texture
Operação básica em apps GPGPU Suporte OpenGL Valores de 16, 32-bit por pixel Multiple Render Targets (MRTs) e Copy-to-texture glCopyTexSubImage Render-to-texture GL_EXT_framebuffer_object 25 de março de 2017 74
 e Copy-to-texture. glCopyTexSubImage. Render-to-texture. GL_EXT_framebuffer_object. 25 de março de")
75
Resumo : Render-To-Vertex-Array
Habilita retro-alimentação Suporte OpenGL Copy-to-vertex-array GL_ARB_pixel_buffer_object NVIDIA e ATI Render-to-vertex-array Não disponível 25 de março de 2017 75 75

76
Estruturas de dados básicas na GPU
“Implementing Efficient Parallel Data Structures on GPUs” Chapter 33, GPU Gems II Low-level details 25 de março de 2017 76 76

77
GPU Arrays Large 1D Arrays
Limite das GPUs em array 1D até 2048 ou 4096 Empacotados em memória 2D Precisa de mapear o endereço 1D-to-2D 25 de março de 2017 77 77

78
GPU Arrays 3D Arrays Problem Soluções
GPUs não possuem 3D frame buffers Soluções Empilhar fatias 2D Múltiplas fatias de buffers 2D Render-to-slice-of-3D-texture (NVidia G8) 25 de março de 2017 78 78
 25 de março de")
79
Exemplo: Simulação de Tecido
Integration de Verlet Jakobsen, GDC 2001 Evita guardar velocidade explicita new_x = x + (x – old_x)*damping + a*dt*dt Não é exato, mas sim estável! Precisa guardar a posição atual é a anterior para cada partícula 2 RGB float textures O Fragment shader calcula a nova posição e escreve o resultado em outra textura textura (float buffer) Logo, intercambia as texturas atual e anterior 25 de março de 2017
*damping + a*dt*dt. Não é exato, mas sim estável! Precisa guardar a posição atual é a anterior para cada partícula 2 RGB float textures. O Fragment shader calcula a nova posição e escreve o resultado em outra textura textura (float buffer) Logo, intercambia as texturas atual e anterior. 25 de março de")
80
Algoritmo Requer de 4 passos
A cada passo renderiza uma quad com o fragment shader: 1.Executa a integração (move as partículas) 2.Aplica restrições (constraints): Restrição de distância entre partículas Colisão com os obstáculos (piso, esfera) 3.Calcula as normais 4. Renderiza a malha do tecido usando VBO May need to perform constrain pass several times for it to converge 25 de março de 2017
 2.Aplica restrições (constraints): Restrição de distância entre partículas. Colisão com os obstáculos (piso, esfera) 3.Calcula as normais. 4. Renderiza a malha do tecido usando VBO. May need to perform constrain pass several times for it to converge. 25 de março de")
81
Código da Integração uniform sampler2DRect oldp_tex;
uniform sampler2DRect currp_tex; // Verlet integration step void Integrate(inout vec3 x, inout vec3 oldx, vec3 a, float timestep2){ vec3 tmpx = x; x = 2*x - oldx + a*timestep2; oldx = tmpx; } void main() { float timestep = 0.02; vec3 gravity = vec3(0.0, -9.8, 0.0); vec2 uv = gl_TexCoord[0].st; // get current and previous position vec3 oldx = texture2DRect(oldp_tex, uv).rgb; vec3 x = texture2DRect(currp_tex, uv).rgb; // move the particle Integrate(x, oldx, gravity, timestep*timestep); gl_FragColor = vec4(x, 1.0); 25 de março de 2017
{ vec3 tmpx = x; x = 2*x - oldx + a*timestep2; oldx = tmpx; } void main() { float timestep = 0.02; vec3 gravity = vec3(0.0, -9.8, 0.0); vec2 uv = gl_TexCoord[0].st; // get current and previous position. vec3 oldx = texture2DRect(oldp_tex, uv).rgb; vec3 x = texture2DRect(currp_tex, uv).rgb; // move the particle. Integrate(x, oldx, gravity, timestep*timestep); gl_FragColor = vec4(x, 1.0); 25 de março de")
82
Código das restrições 25 de março de 2017 void main(){
const float stiffness = 0.2; // this should really be 0.5 vec2 uv = gl_TexCoord[0].st; vec3 x = texture2DRect(x_tex, uv).rgb; // get current position x = clamp(x, worldMin, worldMax); // satisfy world constraints SphereConstraint(x, spherePos, 1.0); // collision constraint with the sphere // get positions of neighbouring particles vec3 x1 = texture2DRect(x_tex, uv + vec2(1.0, 0.0)).rgb; vec3 x2 = texture2DRect(x_tex, uv + vec2(-1.0, 0.0)).rgb; vec3 x3 = texture2DRect(x_tex, uv + vec2(0.0, 1.0)).rgb; vec3 x4 = texture2DRect(x_tex, uv + vec2(0.0, -1.0)).rgb; vec3 x5 = texture2DRect(x_tex, uv + vec2(-1.0, -1.0)).rgb; vec3 x6 = texture2DRect(x_tex, uv + vec2(1.0, 1.0)).rgb; // apply distance constraints vec3 dx = vec3(0.0); if (uv.x < meshSize.x) dx = DistanceConstraint(x, x1, dist, stiffness); if (uv.x > 0.5) dx = dx + DistanceConstraint(x, x2, dist, stiffness); if (uv.y < meshSize.y) dx = dx + DistanceConstraint(x, x3, dist, stiffness); if (uv.y > 0.5) dx = dx + DistanceConstraint(x, x4, dist, stiffness); if (uv.x > 0.5 && uv.y > 0.5) dx = dx + DistanceConstraint(x, x5, dist2, stiffness); if (uv.x < meshSize.x && uv.y < meshSize.y) dx = dx + DistanceConstraint(x, x6, dist2, stiffness); x = x + dx; gl_FragColor = vec4(x, 1.0); } 25 de março de 2017
.rgb; // get current position. x = clamp(x, worldMin, worldMax); // satisfy world constraints. SphereConstraint(x, spherePos, 1.0); // collision constraint with the sphere. // get positions of neighbouring particles. vec3 x1 = texture2DRect(x_tex, uv + vec2(1.0, 0.0)).rgb; vec3 x2 = texture2DRect(x_tex, uv + vec2(-1.0, 0.0)).rgb; vec3 x3 = texture2DRect(x_tex, uv + vec2(0.0, 1.0)).rgb; vec3 x4 = texture2DRect(x_tex, uv + vec2(0.0, -1.0)).rgb; vec3 x5 = texture2DRect(x_tex, uv + vec2(-1.0, -1.0)).rgb; vec3 x6 = texture2DRect(x_tex, uv + vec2(1.0, 1.0)).rgb; // apply distance constraints. vec3 dx = vec3(0.0); if (uv.x < meshSize.x) dx = DistanceConstraint(x, x1, dist, stiffness); if (uv.x > 0.5) dx = dx + DistanceConstraint(x, x2, dist, stiffness); if (uv.y < meshSize.y) dx = dx + DistanceConstraint(x, x3, dist, stiffness); if (uv.y > 0.5) dx = dx + DistanceConstraint(x, x4, dist, stiffness); if (uv.x > 0.5 && uv.y > 0.5) dx = dx + DistanceConstraint(x, x5, dist2, stiffness); if (uv.x < meshSize.x && uv.y < meshSize.y) dx = dx + DistanceConstraint(x, x6, dist2, stiffness); x = x + dx; gl_FragColor = vec4(x, 1.0); } 25 de março de")
83
Resultado 25 de março de 2017

84
Objetos deformáveis A abordagem massa-mola usada na simulação de tecido pode ser estendida para simular objetos deformáveis. O objeto é representado por uma malha tetraédrica (sem slivers) Define-se uma restrição de distância (constraint) para cada aresta da malha. Cada vértice requer a lista de arestas incidentes (processo de relaxamento) 25 de março de 2017
 Define-se uma restrição de distância (constraint) para cada aresta da malha. Cada vértice requer a lista de arestas incidentes (processo de relaxamento) 25 de março de")
85
Objetos deformáveis 25 de março de 2017

86
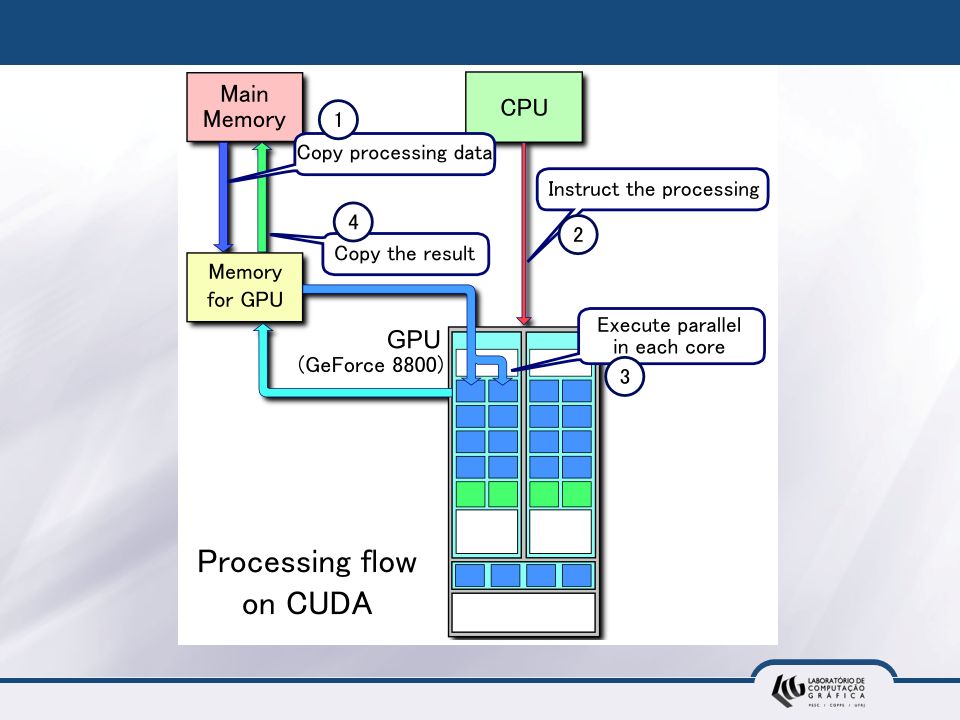
Introdução à API CUDA 25 de março de 2017

87
GeForce 6 Architecture

88
GeForce 8800 GPU Unidades programáveis Shader unificado

89
GPU Architecture

90
CUDA–C Sem limitações dos shaders!
Aplicações integradas host + device C program Partes serial e paralelo no código C host Partes totalmente em paralelo no código C device kernel C Código Serial (host) . . . Kernel Paralelo (device) KernelA<<< nBlk, nTid >>>(args); Código Serial (host) . . . Kernel Paralelo (device) KernelB<<< nBlk, nTid >>>(args);
 Kernel Paralelo (device) KernelA<<< nBlk, nTid >>>(args); Código Serial (host) Kernel Paralelo (device) KernelB<<< nBlk, nTid >>>(args);")
92
IDs de Blocos e IDs de Threads
Cada thread usa IDs para decidir os dados com os que deve trabalhar Block ID: 1D ou 2D Thread ID: 1D, 2D, ou 3D Memoria simplificada Endereçamento Dados multidimensionais

93
Visão geral do Modelo de Memória do CUDA
Memória Global Permite a comunicação de dados R/W entre host e device Visível a todos os threads Access não é rápido Memória Constante Memória compartilhada Registradores locais Grid Block (0, 0) Block (1, 0) Shared Memory Shared Memory Registers Registers Registers Registers Thread (0, 0) Thread (1, 0) Thread (0, 0) Thread (1, 0) Host Global Memory
 Block (1, 0) Shared Memory. Shared Memory. Registers. Registers. Registers. Registers. Thread (0, 0) Thread (1, 0) Thread (0, 0) Thread (1, 0) Host. Global Memory.")
94
CUDA Exemplo: Multiplicação de matrizes – Versão Host simples em C
void MatrixMulOnHost(float* M, float* N, float* P, int Width){ for (int i = 0; i < Width; ++i) for (int j = 0; j < Width; ++j) { double sum = 0; for (int k = 0; k < Width; ++k) { double a = M[i * width + k]; double b = N[k * width + j]; sum += a * b; } P[i * Width + j] = sum; N k j WIDTH M P i WIDTH k WIDTH WIDTH
{ for (int i = 0; i < Width; ++i) for (int j = 0; j < Width; ++j) { double sum = 0; for (int k = 0; k < Width; ++k) { double a = M[i * width + k]; double b = N[k * width + j]; sum += a * b; } P[i * Width + j] = sum; N. k. j. WIDTH. M. P. i. WIDTH. k. WIDTH. WIDTH.")
95
CUDA Exemplo: Multiplicação de matrizes – Versão GPU
void MatrixMulOnDevice(float* M, float* N, float* P, int Width){ int size = Width * Width * sizeof(float); float* Md, Nd, Pd; // Allocate and Load M, N to device memory cudaMalloc(&Md, size); cudaMemcpy(Md, M, size, cudaMemcpyHostToDevice); cudaMalloc(&Nd, size); cudaMemcpy(Nd, N, size, cudaMemcpyHostToDevice); // Allocate P on the device cudaMalloc(&Pd, size); dim3 dimGrid(1, 1); dim3 dimBlock(Width, Width); // Launch the device computation threads! MatrixMulKernel<<<dimGrid, dimBlock>>>(Md, Nd, Pd, Width); cudaMemcpy(P, Pd, size, cudaMemcpyDeviceToHost); // Read P from device cudaFree(Md); cudaFree(Nd); cudaFree (Pd); }
{ int size = Width * Width * sizeof(float); float* Md, Nd, Pd; // Allocate and Load M, N to device memory. cudaMalloc(&Md, size); cudaMemcpy(Md, M, size, cudaMemcpyHostToDevice); cudaMalloc(&Nd, size); cudaMemcpy(Nd, N, size, cudaMemcpyHostToDevice); // Allocate P on the device. cudaMalloc(&Pd, size); dim3 dimGrid(1, 1); dim3 dimBlock(Width, Width); // Launch the device computation threads! MatrixMulKernel<<<dimGrid, dimBlock>>>(Md, Nd, Pd, Width); cudaMemcpy(P, Pd, size, cudaMemcpyDeviceToHost); // Read P from device. cudaFree(Md); cudaFree(Nd); cudaFree (Pd); }")
96
CUDA Exemplo: Multiplicação de matrizes – Versão GPU
void MatrixMulOnDevice(float* M, float* N, float* P, int Width) { int size = Width * Width * sizeof(float); float* Md, Nd, Pd; // Allocate and Load M, N to device memory cudaMalloc(&Md, size); cudaMemcpy(Md, M, size, cudaMemcpyHostToDevice); cudaMalloc(&Nd, size); cudaMemcpy(Nd, N, size, cudaMemcpyHostToDevice); // Allocate P on the device cudaMalloc(&Pd, size); dim3 dimGrid(1, 1); dim3 dimBlock(Width, Width); // Launch the device computation threads! MatrixMulKernel<<<dimGrid, dimBlock>>>(Md, Nd, Pd, Width); cudaMemcpy(P, Pd, size, cudaMemcpyDeviceToHost); // Read P from device cudaFree(Md); cudaFree(Nd); cudaFree (Pd); } Allocate memory on device
 { int size = Width * Width * sizeof(float); float* Md, Nd, Pd; // Allocate and Load M, N to device memory. cudaMalloc(&Md, size); cudaMemcpy(Md, M, size, cudaMemcpyHostToDevice); cudaMalloc(&Nd, size); cudaMemcpy(Nd, N, size, cudaMemcpyHostToDevice); // Allocate P on the device. cudaMalloc(&Pd, size); dim3 dimGrid(1, 1); dim3 dimBlock(Width, Width); // Launch the device computation threads! MatrixMulKernel<<<dimGrid, dimBlock>>>(Md, Nd, Pd, Width); cudaMemcpy(P, Pd, size, cudaMemcpyDeviceToHost); // Read P from device. cudaFree(Md); cudaFree(Nd); cudaFree (Pd); } Allocate memory on device.")
97
CUDA Exemplo: Multiplicação de matrizes – Versão GPU
void MatrixMulOnDevice(float* M, float* N, float* P, int Width) { int size = Width * Width * sizeof(float); float* Md, Nd, Pd; // Allocate and Load M, N to device memory cudaMalloc(&Md, size); cudaMemcpy(Md, M, size, cudaMemcpyHostToDevice); cudaMalloc(&Nd, size); cudaMemcpy(Nd, N, size, cudaMemcpyHostToDevice); // Allocate P on the device cudaMalloc(&Pd, size); dim3 dimGrid(1, 1); dim3 dimBlock(Width, Width); // Launch the device computation threads! MatrixMulKernel<<<dimGrid, dimBlock>>>(Md, Nd, Pd, Width); cudaMemcpy(P, Pd, size, cudaMemcpyDeviceToHost); // Read P from device cudaFree(Md); cudaFree(Nd); cudaFree (Pd); } Do Matrix multiplication on device
 { int size = Width * Width * sizeof(float); float* Md, Nd, Pd; // Allocate and Load M, N to device memory. cudaMalloc(&Md, size); cudaMemcpy(Md, M, size, cudaMemcpyHostToDevice); cudaMalloc(&Nd, size); cudaMemcpy(Nd, N, size, cudaMemcpyHostToDevice); // Allocate P on the device. cudaMalloc(&Pd, size); dim3 dimGrid(1, 1); dim3 dimBlock(Width, Width); // Launch the device computation threads! MatrixMulKernel<<<dimGrid, dimBlock>>>(Md, Nd, Pd, Width); cudaMemcpy(P, Pd, size, cudaMemcpyDeviceToHost); // Read P from device. cudaFree(Md); cudaFree(Nd); cudaFree (Pd); } Do Matrix multiplication on device.")
98
CUDA Exemplo: Multiplicação de matrizes – Versão GPU
void MatrixMulOnDevice(float* M, float* N, float* P, int Width) { int size = Width * Width * sizeof(float); float* Md, Nd, Pd; // Allocate and Load M, N to device memory cudaMalloc(&Md, size); cudaMemcpy(Md, M, size, cudaMemcpyHostToDevice); cudaMalloc(&Nd, size); cudaMemcpy(Nd, N, size, cudaMemcpyHostToDevice); // Allocate P on the device cudaMalloc(&Pd, size); dim3 dimGrid(1, 1); dim3 dimBlock(Width, Width); // Launch the device computation threads! MatrixMulKernel<<<dimGrid, dimBlock>>>(Md, Nd, Pd, Width); cudaMemcpy(P, Pd, size, cudaMemcpyDeviceToHost); // Read P from device cudaFree(Md); cudaFree(Nd); cudaFree (Pd); } Free device memory
 { int size = Width * Width * sizeof(float); float* Md, Nd, Pd; // Allocate and Load M, N to device memory. cudaMalloc(&Md, size); cudaMemcpy(Md, M, size, cudaMemcpyHostToDevice); cudaMalloc(&Nd, size); cudaMemcpy(Nd, N, size, cudaMemcpyHostToDevice); // Allocate P on the device. cudaMalloc(&Pd, size); dim3 dimGrid(1, 1); dim3 dimBlock(Width, Width); // Launch the device computation threads! MatrixMulKernel<<<dimGrid, dimBlock>>>(Md, Nd, Pd, Width); cudaMemcpy(P, Pd, size, cudaMemcpyDeviceToHost); // Read P from device. cudaFree(Md); cudaFree(Nd); cudaFree (Pd); } Free device memory.")
99
CUDA Exemplo: Multiplicação de matrizes – Versão GPU
// Matrix multiplication kernel – per thread code __global__ void MatrixMulKernel(float* Md, float* Nd, float* Pd, int Width) { // Pvalue is used to store the element of the matrix // that is computed by the thread float Pval = 0; for (int k = 0; k < Width; ++k) { float Melement = Md[threadIdx.y*Width+k]; float Nelement = Nd[k*Width+threadIdx.x]; Pval += Melement * Nelement; } Pd[threadIdx.y*Width+threadIdx.x] = Pval; Nd k WIDTH tx This should be emphasized! Maybe another slide on “This is the first thing” Md Pd ty ty WIDTH tx k WIDTH WIDTH
 { // Pvalue is used to store the element of the matrix. // that is computed by the thread. float Pval = 0; for (int k = 0; k < Width; ++k) { float Melement = Md[threadIdx.y*Width+k]; float Nelement = Nd[k*Width+threadIdx.x]; Pval += Melement * Nelement; } Pd[threadIdx.y*Width+threadIdx.x] = Pval; Nd. k. WIDTH. tx. This should be emphasized! Maybe another slide on This is the first thing Md. Pd. ty. ty. WIDTH. tx. k. WIDTH. WIDTH.")
100
Exemplos

101
Referências http://www.mathematik.uni-dortmund.de/~goeddeke/gpgpu
25 de março de 2017

Apresentações semelhantes











.>")







