Carregar apresentação
A apresentação está carregando. Por favor, espere

1
1. I n t r o d u ç ã o Vários slides foram adaptados, traduzidos ou copiados de Pang-Ning Tan (ver Bibliografia)
 .")
2
Sumário Contexto Mineração de Dados Exemplo de Motivação
Modelos e Padrões Algoritmos de Mineração de Dados Métricas de Mineração de Dados Questões em Aberto Avaliação da Disciplina

3
Contexto Mineração de Dados Exemplo de Motivação Modelos e Padrões Algoritmos de Mineração de Dados Métricas de Mineração de Dados Questões em Aberto Avaliação da Disciplina

4
Por Que Minerar Dados? Ponto de vista comercial
Enormes volumes de dados estão sendo coletados e armazenados Web, e-commerce Supermercados, lojas de departamento Transações bancárias Os computadores têm se tornado mais baratos e poderosos A pressão competitiva é cada vez maior Tenho a informação que ninguém tem? A mineração pode ajudar Ponto de vista comercial

5
Ponto de vista científico
“Data streams” (GB/hora) Sensores em satélites Telescópios varrendo os céus “Microarrays” gerando dados de expressão de genes Simulações de tempo gerando terabytes de dados Mineração de Dados pode ajudar os cientistas A classificar e segmentar dados A formular hipóteses Ponto de vista científico
 Sensores em satélites. Telescópios varrendo os céus. Microarrays gerando dados de. expressão de genes. Simulações de tempo gerando. terabytes de dados. Mineração de Dados pode ajudar. os cientistas. A classificar e segmentar dados. A formular hipóteses. Ponto de vista científico.")
6
O Que É / Não É Mineração de Dados?
Achar um número de telefone em um catálogo Procurar numa máquina de busca informação sobre “Amazônia” O que é? Certos nomes são mais freqüentes em certas regiões do Brasil (Cacciola, Armani, Gutierrez… na Grande São Paulo) Agrupar documentos por similaridade de contexto (p.e. Amazônia)
 Agrupar documentos por similaridade de contexto (p.e. Amazônia)")
7
Origens da Expressão Mineração de Dados
Idéias mestras de “machine learning” / AI, “pattern recognition”, estatística e banco de dados Machine Learning / AI Estatística / Pattern Recognition Data Mining Banco de Dados

8
Sumário Contexto Mineração de Dados Exemplo de Motivação
Modelos e Padrões Algoritmos de Mineração de Dados Métricas de Mineração de Dados Questões em Aberto Avaliação da Disciplina

9
Mineração de Dados Mineração de Dados é uma tecnologia capaz de descobrir padrões de informação ‘escondidos’ em um BD Padrão Freqüência, Repetição BD desnormalizado Outras denominações Análise de Dados Exploratória Descoberta Dirigida a Dados Aprendizagem Indutiva Implementa o conceito de consulta aberta ou semi-aberta Consultas tradicionais são fechadas, ou completamente definidas

10
Consultas Abertas ou Semi-Abertas
Consulta: Pode não ser bem formada, ou formulada imprecisamente. O minerador pode nem mesmo saber exatamente o que ele quer ver Dados: Como se trata de descobrir padrões (repetições), dados normalizados (sem repetições) não facilitam a tarefa de mineração. A solução é gerar arquivos intermediários não normalizados do BD operacional normalizado Saída: Não é um subconjunto do BD. Em vez disso, é o resultado de alguma análise sobre o conteúdo do BD
, dados normalizados (sem repetições) não facilitam a tarefa de mineração. A solução é gerar arquivos intermediários não normalizados do BD operacional normalizado. Saída: Não é um subconjunto do BD. Em vez disso, é o resultado de alguma análise sobre o conteúdo do BD.")
11
Sumário Contexto Mineração de Dados Exemplo de Motivação
Modelos e Padrões Algoritmos de Mineração de Dados Métricas de Mineração de Dados Questões em Aberto Avaliação da Disciplina

12
Exemplo de Motivação Um robot que prescreve lentes de contato
Oftalmologista: quais as condições gerais – padrões – pelas quais eu sempre tenho receitado lentes de contato duras? ou gelatinosas? ou não tenho recomendo o uso de lentes? 4

13
Caracterização do Problema: Classificatório
categórico categórico categórico classe Conj. Teste Clasificador Induzido Modelo Conj. Treinamento

14
idade acuidade visual astigmatismo taxa de produção de lágrima tipo de lente jovem míope não reduzida nenhum normal gelatinosa sim dura hipermétrope

15
jovem hipermétrope sim reduzida nenhum normal dura maduro míope não gelatinosa

16
maduro hipermétrope não normal gelatinosa sim reduzida nenhum idoso míope dura

17
idoso hipermétrope não reduzida nenhum normal gelatinosa sim

18
se taxa_de_produção_de_lágrima = ‘reduzida’ então tipo_de_lente = ‘nenhum’
Padrão expressado em forma de regra se <condição> então <classe> Regra se ... então é um modelo de conhecimento Existem muitos modelos de conhecimento A regra se verifica em todos os casos em que a taxa de produção de lágrima é reduzida? Via de regra, não há certeza, apenas probabilidade Quantas e quais são as outras regras para não receitar lente de contato (somente da amostra, podemos extrair mais três regras – verifique)
")
19
Quão confiável é uma regra?
se idade = ‘maduro’ e acuidade_visual = ‘hipermétrope’ e astigmatismo = ‘sim’ e taxa_de_produção_de_lágrima = ‘normal’ então tipo_de_lente = ‘nenhum’ Ela se verifica em somente um caso da amostra Provavelmente, não tem validade estatística Qual a freqüência mínima estatisticamente aceitável?

20
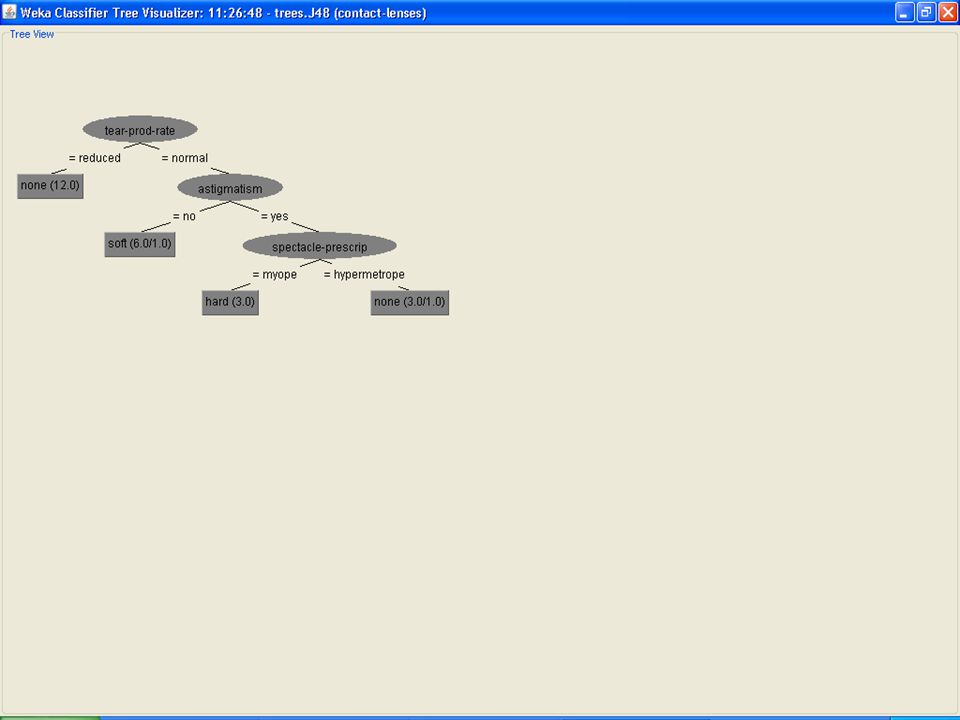
Regras expressas em forma de árvore de decisão (próximo slide)
Algoritmo WEKA, J48

22
Sumário Contexto Mineração de Dados Exemplo de Motivação
Modelos e Padrões Algoritmos de Mineração de Dados Métricas de Mineração de Dados Questões em Aberto Avaliação da Disciplina

23
Modelos e Padrões Outra definição de Mineração de Dados
Tecnologia que visa extrair automaticamente conhecimento útil, confiável e não trivial ‘minério’ de um banco de dados ‘mina’ O conhecimento deve ser apresentado segundo um modelo formal Modelo de regras de classificação: se <condição> então <classe> Instância do modelo: se taxa_de_produção_de_lágrima = ‘reduzida’ então tipo_de_lente = ‘nenhum’ Não faremos mais distinção entre modelo e instância Um modelo é confiável na medida em que ele possa ser considerado um padrão Padrão freqüência significativa no banco de dados

24
Modelos são induzidos (ou inferidos) por algoritmos de mineração
Existem muitos algoritmos de mineração Não existe o melhor algoritmo Que fazer? Diversos algoritmos poderiam implementar o nosso robô Experimentemos alguns deles Biblioteca WEKA

25
Tipos de modelo Preditivo Descritivo
Faz predição acerca de valores de dados usando resultados conhecidos de outros dados O exemplo de motivação é de predição Em geral, a modelagem é baseada em dados históricos, para fazer predição (ou previsão) sobre novos dados Descritivo Identifica padrões ou relacionamentos em dados, históricos ou não Importante para se conhecer os dados
 sobre novos dados. Descritivo. Identifica padrões ou relacionamentos em dados, históricos ou não. Importante para se conhecer os dados.")
26
Modelo Preditivo Descritivo Clustering Síntese Classificação Série Temporal Regressão Descoberta de Seqüências Regras de Associação

27
Sumário Contexto Mineração de Dados Exemplo de Motivação
Modelos e Padrões Algoritmos de Mineração de Dados Métricas de Mineração de Dados Questões em Aberto Avaliação da Disciplina

28
Algoritmos de Mineração de Dados
Os algoritmos diferem segundo os modelos de conhecimento que eles induzem (ou inferem) Classificação Supervisionada Classificação Não Supervisionada Regressão Síntese Associação Seqüência Detecção de Anomalias / Desvios Mineração de Texto / Dados Espaciais / Dados Espaço-Temporais / Dados Web / Dados Temporais 5
 Classificação Supervisionada. Classificação Não Supervisionada. Regressão. Síntese. Associação. Seqüência. Detecção de Anomalias / Desvios. Mineração de Texto / Dados Espaciais / Dados Espaço-Temporais / Dados Web / Dados Temporais. 5.")
29
Classificação Supervisionada
Mapeia entidades em classes, ou grupos pré-definidos Classes são valores de atributos, chamados de atributos de classificação Exemplo 1: Nosso problema do robot Classes: 1, 2 e 3 Diz-se que o conjunto-treinamento está anotado, ou rotulado (“labelled”), daí o adjetivo supervisionado
, daí o adjetivo supervisionado.")
30
Exemplo 2: Concessão de crédito bancário
Suponha que, com base em informações históricas sobre clientes de um banco, cada cliente é colocado em uma de quatro classes: (c1) OK, (c2) pedir mais informações, (c3) ñOK e (c4) chamar a polícia. Como todo algoritmo de classificação supervisionada, trabalha em duas fases: Fase 1: Induzir um modelo para as classes, de um conjunto-treinamento (corpus) anotado Fase 2: Aplicar o modelo a um novo cliente, para predição (oráculo) - Problema: se a base não fosse anotada?
 OK, (c2) pedir mais informações, (c3) ñOK e (c4) chamar a polícia. Como todo algoritmo de classificação supervisionada, trabalha em duas fases: Fase 1: Induzir um modelo para as classes, de um conjunto-treinamento (corpus) anotado. Fase 2: Aplicar o modelo a um novo cliente, para predição (oráculo) - Problema: se a base não fosse anotada")
31
Classificação Não Supervisionada
Agrupamento (“Clustering”) Os grupos (“clusters”) de um corpus são induzidos, por critérios abertos de similaridade Segmentação dos dados em grupos, não necessariamente disjuntos Dados similares são agrupados em um mesmo grupo A única restrição é o número de grupos “Clustering” é um modelo descritivo Uma espécie de anotação automática de um corpus O problema: as anotações não têm semântica (geralmente, cada grupo é identificado por um número)
 Os grupos ( clusters ) de um corpus são induzidos, por critérios abertos de similaridade. Segmentação dos dados em grupos, não necessariamente disjuntos. Dados similares são agrupados em um mesmo grupo. A única restrição é o número de grupos. Clustering é um modelo descritivo. Uma espécie de anotação automática de um corpus. O problema: as anotações não têm semântica (geralmente, cada grupo é identificado por um número)")
32
Como entender os grupos?
Indução de um modelo de classificação em que as classes são os grupos Corpus automaticamente anotado Um grupo é identificado pelas condições que levam ao número do grupo “ Clustering” é uma possível solução para o problema apontado no exemplo de concessão de crédito bancário

33
Exemplo (Mala Direta) Uma cadeia nacional de lojas deseja criar catálogos específicos, baseados em atributos tais como renda, localização, características físicas, etc. Para determinar o público-alvo dos catálogos, bem como identificar novos e desconhecidos grupos visando à criação de outros catálogos específicos, ou ainda catálogos mais específicos do que os inicialmente pensados, um algoritmo de “clustering” agrupa os clientes (potenciais) da cadeia de lojas, segundo certos atributos dos clientes. Desta forma, um eficiente sistema de mala direta pode ser construído
 da cadeia de lojas, segundo certos atributos dos clientes. Desta forma, um eficiente sistema de mala direta pode ser construído.")
34
Regressão Um problema estatístico clássico é experimentar determinar o relacionamento entre duas variáveis aleatórias, X e Y, por meio de uma curva qualquer, aproximada Y pode ser previsto de X, então trata-se de um modelo preditivo

35
Regressão Linear A curva é uma reta Y= a+bX+e
onde e é um resíduo e os coeficientes a and b are determinados de modo que o resíduo seja o menor possível

36
Rendimento de um Certo Investimento
x x x x x x x x x x x x Aplicação no Tempo

37
Regressão Não Linear Prediz um valor de uma dada variável contínua, baseado em valores de outras variáveis, segundo uma curva qualquer Muito estudada em estatística Exemplo Predizer velocidades de vento, como uma função de temperatura, umidade, pressão atmosférica, etc.

38
Série Temporal Uma série temporal é a variação, com o tempo, do valor de um certo atributo A freqüência das medições pode ser diária, semanal, horária, etc. Pelo exame de um conjunto de séries temporais, algoritmos podem Fazer predição Descobrir séries similares Descobrir outras propriedades de séries Modelo híbrido Predição Descrição

39
• Produto C é menos volátil do que produtos A e B
Nível de Estoque Produto B Produto A Produto C Tempo • Produto C é menos volátil do que produtos A e B • Mesma política de estoque para A e B • Com boa certeza, pode-se fazer predição para C

40
Síntese Uma síntese agrega dados, segundo critérios de agregação previamente escolhidos Também chamada de Caracterização ou Generalização De forma sucinta, caracteriza o conteúdo de um banco de dados Descritivo, essencialmente

41
Exemplo (Ranking de Universidades)
Um dos muitos critérios usados para comparar universidades por um certo instituto de pesquisa americano é o chamado escore ACT um modelo de síntese de universidades. Trata-se de uma síntese usada para estimar o tipo e o nível intelectual dos corpos estudantis Um modelo de síntese pode também ser pensado como um conjunto de métricas de alto nível de granularidade, relevantes a um contexto

42
Análise de Associação Regras de Associação
Uma regra de associação é um modelo descritivo que identifica tipos específicos de associação entre dados diferentes A associação entre certos nomes e regiões O clássico exemplo das cervejas e fraldas Quanto mais fralda comprada, mais cerveja comprada Formalmente, é uma extensão de regra de classificação, em que vários pares atributo-valor podem aparecer no conseqüente (isto é, o que vem depois do então) Atenção: regras de associação em geral não são comutativas!
 Atenção: regras de associação em geral não são comutativas!")
43
Exemplo (Gerência de Vendas)
O dono de um mercadinho está decidindo se coloca um produto X em promoção. A fim de determinar o impacto dessa decisão, o proprietário usa um algoritmo que infere regras de associação que mostram que outros produtos são freqüentemente comprados junto com o produto X. Baseado nesse conhecimento, ele toma algumas decisões: Aproximar, nas prateleiras, os produtos associados Não colocar em promoção, ao mesmo tempo, mais de um produto associado

44
Seqüência Os padrões são similares a associações, porém as associações são, em geral, temporais Exemplo 1: Padrões de compra ao longo do tempo Pessoas que compram CD-players, também compram CDs no espaço de uma semana O que não é trivial no exemplo é o espaço de uma semana Note que, para que este conhecimento seja válido, é preciso que seja um padrão (número de repetições acima de um valor mínimo aceitável) Isto vale para qualquer modelo
 Isto vale para qualquer modelo.")
45
Uma seqüência pode ser não temporal
Exemplo 2: Seqüência de disciplinas de um curso de ciência da computação {Algoritmos e Estruturas de Dados, Introdução a Sistemas Operacionais} {Banco de Dados, Arquitetura de Computadores} {Redes de Computadores, Engenharia de Software} {Computação Gráfica, Computação Paralela) Diz-se que a seqüência é composta de elementos (4) e eventos (8), e que os eventos são temporais Uma seqüência pode ser não temporal Ordenação espacial
 Diz-se que a seqüência é composta de elementos (4) e eventos (8), e que os eventos são temporais. Uma seqüência pode ser não temporal. Ordenação espacial.")
46
Exemplo 3: Padrões de navegação na Web
O webmaster de uma companhia X periodicamente usa um algoritmo que analisa os dados do log da Web, para saber como os usuários do site da empresa navegam nele – que seqüência de páginas são freqüentemente acessadas? Desta maneira, ele fica sabendo que 70% dos usuários da página A seguem um dos seguintes padrões de comportamento: <A,B,C> ou <A,D,B,C> ou <A,E,B,C>. Ele então determina criar um link diretamente da página A para a página C

47
Um Capítulo à Parte: Detecção de Anomalia ou Desvios
Detectam desvios significativos de comportamento padrão Aplicações: Fraude em cartões de crédito Intrusão em redes de computadores

48
Mineração de Dados Não Convencionais
Todas as técnicas e exemplos vistos até aqui referem-se a dados estruturados (descritos por meta dados) Como fazer para tratar com dados não estruturados (sem meta dados)? Textos, Dados Espaciais, Dados Espaço-Temporais A idéia central é a representação estruturada de dados não estruturados Redução de um problema desconhecido a um problema conhecido
 Como fazer para tratar com dados não estruturados (sem meta dados) Textos, Dados Espaciais, Dados Espaço-Temporais. A idéia central é a representação estruturada de dados não estruturados. Redução de um problema desconhecido a um problema conhecido.")
49
Sumário Contexto Mineração de Dados Exemplo de Motivação
Modelos e Padrões Algoritmos de Mineração de Dados Métricas de Mineração de Dados Questões em Aberto Avaliação da Disciplina

50
Métricas de Mineração de Dados
Dado um problema de mineração, há potencialmente uma grande quantidade de processos de MD que podem resolver o problema Um processo de MD é, simplificadamente, uma tripla <preparação de dados, execução de um algoritmo de mineração de dados, avaliação dos resultados> Quantidade de processos: No. de técnicas de preparação X no. de algoritmos de MD Qual o melhor processo de MD para o problema? A resposta depende das métricas de desempenho escolhidas

51
Métricas de Desempenho de Algoritmos
As tradicionais, como as de espaço e tempo, baseadas em análise de complexidade de algoritmos Para algoritmos de classificação supervisionada, a acurácia do conhecimento induzido Acurácia = No.de acertos treinamento (teste) / Tamanho do conjunto de treinamento (teste) Para algoritmos de mineração de dados não estruturados Precisão Cobertura (“Recall”) Veremos depois essas definições
 / Tamanho do conjunto de treinamento (teste) Para algoritmos de mineração de dados não estruturados. Precisão. Cobertura ( Recall ) Veremos depois essas definições.")
52
Sumário Contexto Mineração de Dados Exemplo de Motivação
Modelos e Padrões Algoritmos de Mineração de Dados Métricas de Mineração de Dados Questões em Aberto Avaliação da Disciplina

53
Desafios da Mineração de Dados
Mineração de Dados (MD) e SGBDs Modelos de Conhecimento Escala Dimensionalidade Dados complexos e heterogêneos Qualidade de dados Direitos autorais Privacidade “Streaming Data”
 e SGBDs. Modelos de Conhecimento. Escala. Dimensionalidade. Dados complexos e heterogêneos. Qualidade de dados. Direitos autorais. Privacidade. Streaming Data")
54
Agenda (Parcial) de Pesquisa em MD
Integração com SGBDs Os algoritmos de MD não lêem diretamente de SGBDs Dados são extraídos de um BD, via comandos SQL, e armazenados em um arquivo "flat", desnormalizado O arquivo "flat"é a entrada para os algoritmos de mineração Note que desnormalização (repetição) favorece a descoberta de padrões BDOR é desnormalizado implicações? Termos relacionais (<atributo1> <opcomp> <atributo2>) Os termos dos modelos de MD são da forma <atributo> <opcomp> valor Uma enorme simplificação Objetivo: produzir algoritmos de complexidade baixa Preço a pagar: limitação da expressividade dos modelos
 favorece a descoberta de padrões. BDOR é desnormalizado implicações Termos relacionais (<atributo1> <opcomp> <atributo2>) Os termos dos modelos de MD são da forma <atributo> <opcomp> valor. Uma enorme simplificação. Objetivo: produzir algoritmos de complexidade baixa. Preço a pagar: limitação da expressividade dos modelos.")
55
Minas de Dados são Impuras
Escala Algoritmos de MD sem escala são de limitada utilidade Otimização, principalmente de tempo, é um tema de pesquisa recorrente Minas de Dados são Impuras Dados do mundo real têm muita ‘sujeira’, e muito valor faltando (“null values”). Algoritmos de MD terão que ser capazes de trabalhar com minas impuras Dinâmica dos Dados Muitos algoritmos de MD trabalham com dados estáticos (comportamento invariável, ao longo do tempo). Isto pode não ser um modus operandi realista
. Algoritmos de MD terão que ser capazes de trabalhar com minas impuras. Dinâmica dos Dados. Muitos algoritmos de MD trabalham com dados estáticos (comportamento invariável, ao longo do tempo). Isto pode não ser um modus operandi realista.")
56
Facilidade de Assimilação
Embora alguns algoritmos possam trabalhar bem, eles podem induzir modelos muito complexos, de difícil assimilação mesmo por especialistas Conhecimento inútil misturado com conhecimento útil Padrões complexos Padrões não sintetizados Dimensionalidade O que fazer se as entidades têm muitos atributos (dimensões)? Os algoritmos de hoje trabalham mal com muitas dimensões? “Data streaming” Como minerar dados que fluem continuamente?
 Os algoritmos de hoje trabalham mal com muitas dimensões Data streaming Como minerar dados que fluem continuamente")
57
Atributos complexos ou estruturados Privacidade?
Os algoritmos de hoje só trabalham com atributos atômicos Privacidade? Google conhece todo-o-mundo!

58
Sumário Contexto Mineração de Dados Exemplo de Motivação
Modelos e Padrões Algoritmos de Mineração de Dados Métricas de Mineração de Dados Questões em Aberto Avaliação da Disciplina

59
Sistema de Avaliação Tarefas Laboratoriais Seminário (Tópico Avançado)
Caracterização de um problema de mineraçao Solução do problema Aplicação de processos de mineração ao problema Interpretação dos resultados dos processos Equipes de 2 Seminário (Tópico Avançado) Individual Ver os temas propostos
 Individual. Ver os temas propostos.")
Apresentações semelhantes















>")


>")
