Carregar apresentação
A apresentação está carregando. Por favor, espere

1
Operações sobre o Texto
Eveline Alonso Veloso PUC-MINAS

2
Referências BAEZA-YATES, Ricardo e RIBEIRO-NETO, Berthier. Modern Information Retrieval. 1ª edição, New York: ACM Press, 1999, capítulo 7.

3
Motivação Nem todas as palavras são igualmente significantes;
para representar a semântica de um documento. Substantivos são as palavras mais representativas do conteúdo de um documento; “carregam” mais significado. O pré-processamento dos documentos da coleção é realizado; com o objetivo de determinar os termos que serão utilizados como termos de indexação.

4
Indexação do Texto Completo dos Documentos
Representar documentos utilizando como termos de indexação todos os seus termos; promove uma representação imprecisa da semântica dos documentos da coleção. Há termos que não possuem um significado muito forte; não sendo muito representativos do conteúdo do documento; artigos, preposições, conjunções, etc. A utilização então de todas as palavras da coleção para indexar seus documentos; gera muito “ruído” na tarefa de recuperar informação.

5
Pré-processamento dos Documentos da Coleção
Maneira de reduzir esse “ruído”: reduzir o conjunto de palavras que podem ser utilizadas para indexar os documentos da coleção. Pré-processamento dos documentos da coleção; pode ser visto como um processo para controlar e selecionar o vocabulário utilizado para indexar os documentos.

6
Potencial Prejuízo do Pré-processamento dos Documentos
Normalmente não é do conhecimento dos usuários dos sistemas de recuperação de informação; a realização desse pré-processamento nos documentos da coleção. Como resultado, um usuário pode ficar surpreso com alguns dos documentos retornados; e com a ausência de outros que ele esperava.

7
Conclusão As transformações realizadas sobre o texto original dos documentos; potencialmente podem melhorar o processo de recuperação de informação; mas podem também tornar mais difícil para o usuário interpretar a tarefa de recuperação. Por causa disso, algumas máquinas de busca estão optando por indexar o texto completo de seus documentos; apesar do índice ter mais “ruído”; a tarefa de recuperação de informação é mais simples e intuitiva para o usuário.

8
Transformações Análise léxica do texto; Eliminação de stopwords;
com o objetivo de identificar candidatos a termos de indexação; tratando dígitos, hífens, sinais de pontuação, acentuação, caracteres especiais e letras maiúsculas e minúsculas. Eliminação de stopwords; com o objetivo de retirar palavras que possuem um baixo valor de discriminação para o processo de recuperação de informação.

9
Transformações Radicalização; Seleção de termos de indexação;
com o objetivo de remover sufixos e prefixos; e permitir a recuperação de documentos contendo variações sintáticas dos termos da consulta. Seleção de termos de indexação; determinando quais palavras poderão ser utilizadas para indexar os documentos da coleção. Essa escolha está relacionada com a natureza sintática da palavra; substantivos geralmente “carregam” mais semântica do que adjetivos e advérbios.

10
Análise Léxica do Texto
Identificação das palavras candidatas a termos de indexação; tratando dígitos, hífens, sinais de pontuação, acentuação, caracteres especiais e letras maiúsculas e minúsculas.

11
Conversão de Letras Maiúsculas em Minúsculas ou Vice-versa
Considerar se a palavra está escrita em letras maiúsculas ou minúsculas; não é importante para a identificação dos termos de indexação; nem para aspectos de recuperação de informação. Normalmente, durante a análise léxica, todas as palavras identificadas; são convertidas para letras maiúsculas ou minúsculas.

13
Eliminação de Sinais de Pontuação
Em geral, os sinais de pontuação são totalmente removidos; durante a análise léxica do texto dos documentos da coleção.

15
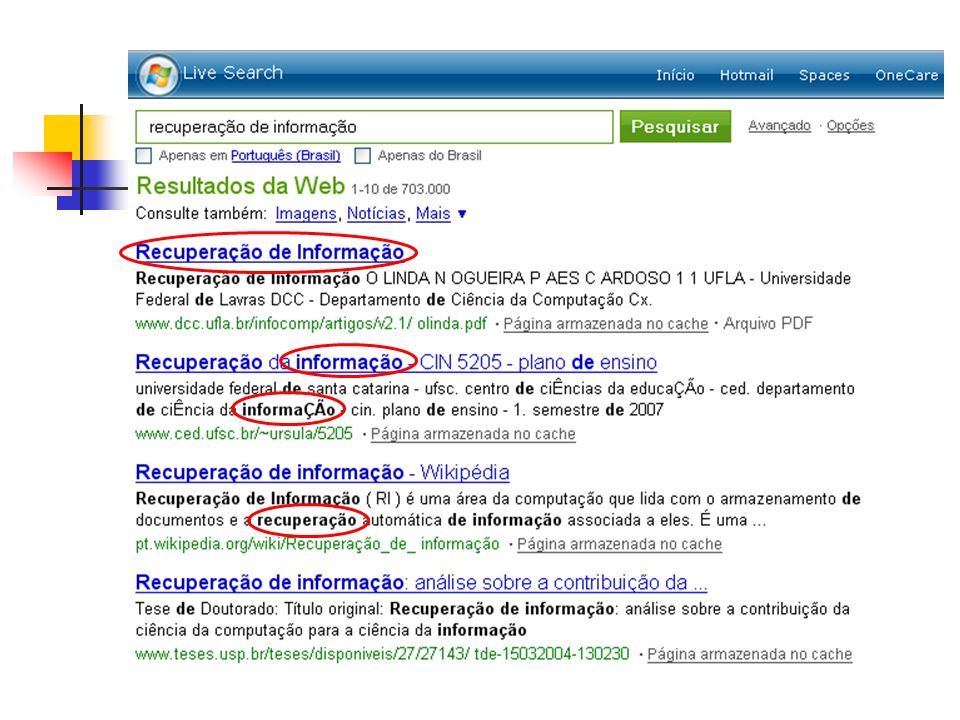
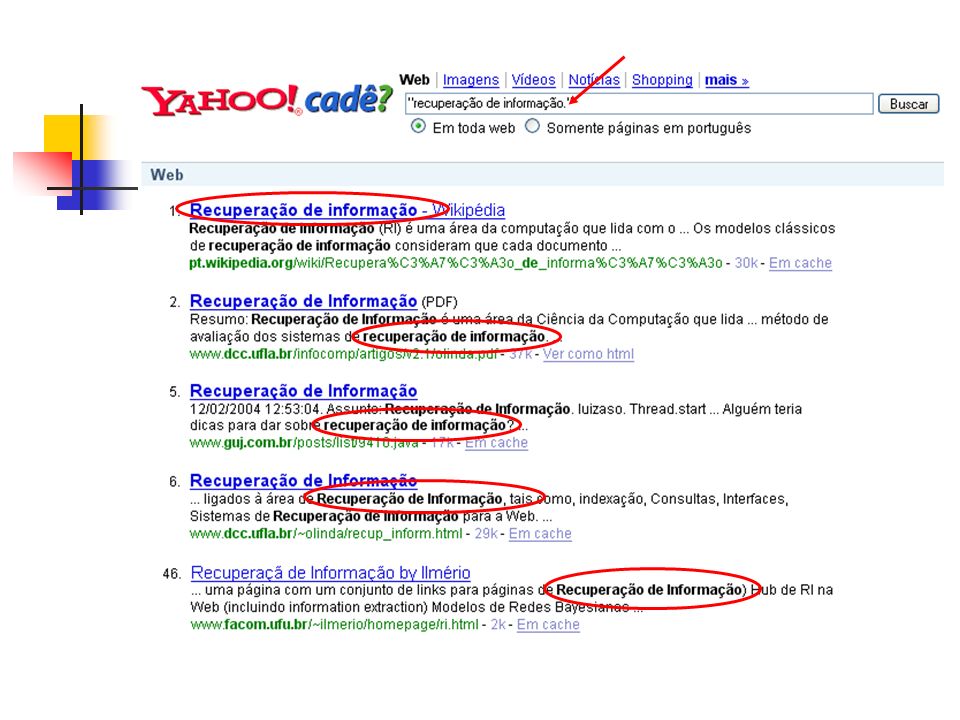
Eliminação de Sinais de Pontuação
No entanto, há contextos em que esses sinais podem ser importantes. Exemplo: sistema de recuperação de informação para a área médica; códigos CID como J30.2

16
Eliminação de Caracteres Especiais
Em geral, também são eliminados durante a análise léxica do texto dos documentos da coleção; e desconsiderados caso apareçam na consulta do usuário.

18
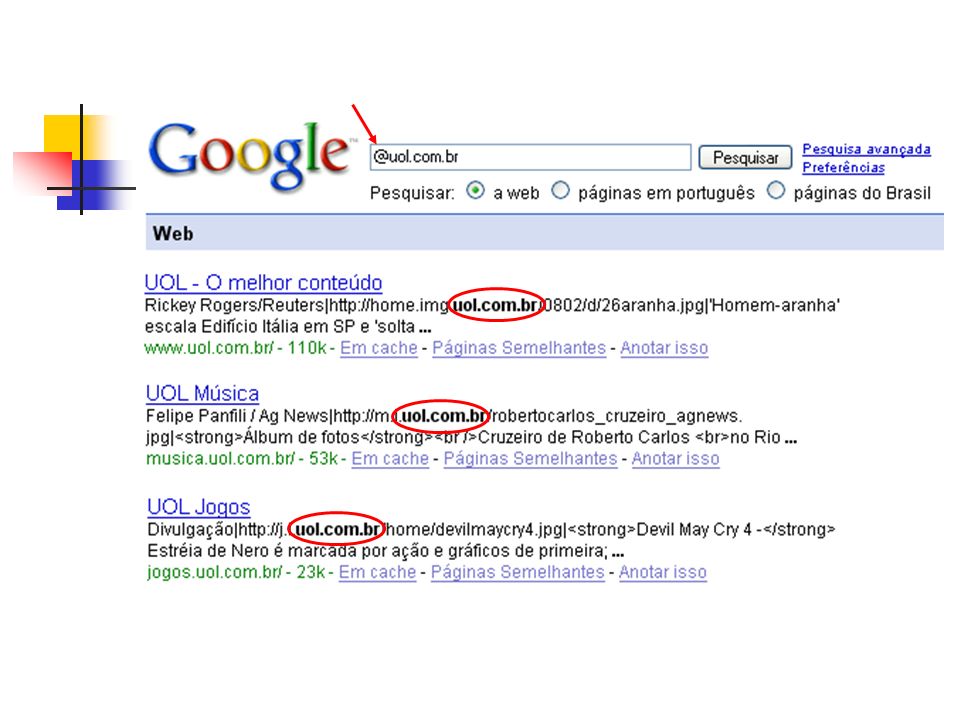
Eliminação de Caracteres Especiais
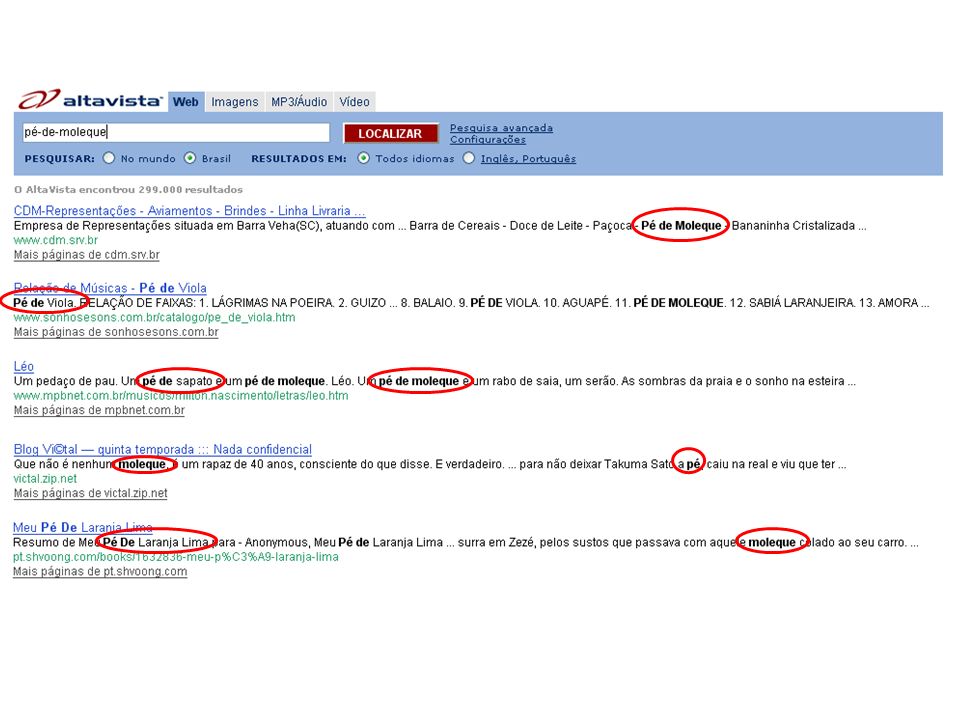
No entanto, há contextos em que os caracteres especiais podem ser importantes. Exemplo: s. Assim, muitos sistemas de recuperação de informação estão optando por dar um tratamento diferente dependendo do caracter especial; e do local onde ele aparece; no termo identificado; e na consulta do usuário.

21
Eliminação de Hífens Eliminar os hífens, separando os termos das palavras que foram escritas utilizando-os; considerando então mais de um termo de indexação; pode ser útil devido a inconsistências de uso; a mesma palavra escrita com e sem hífen em documentos diferentes. No entanto, existem palavras que são realmente escritas com hífen e sua separação em mais de um termo de indexação pode prejudicar o processo de recuperação de informação; interpretando incorretamente a necessidade de informação do usuário.

23
Eliminação de Hífens Uma solução parece ser:
separar os termos das palavras que foram escritas utilizando-se hífens; considerando então mais de um termo de indexação; durante a indexação do documento. caso o usuário especifique sua consulta utilizando hífens; os hífens são desconsiderados; permitindo recuperar tanto documentos onde a palavra aparece com hífen quanto documentos em que ela aparece sem hífen. mas a consulta é processada como uma consulta por frase exata; recuperando apenas documentos onde os termos especificados aparecem próximos e na ordem indicada.

25
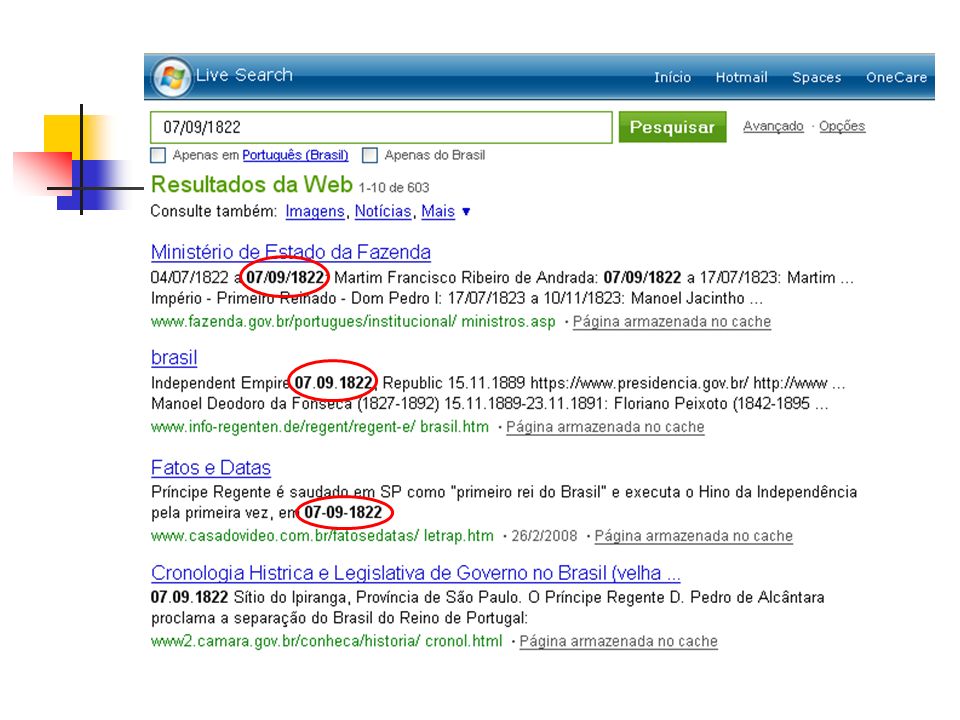
Eliminação de Dígitos Dígitos não são geralmente bons termos de indexação; porque sem estarem inseridos e associados a um contexto bem-definido; são muito vagos. Por isso, muitas vezes, opta-se por eliminar dígitos do conjunto de termos de indexação. No entanto, associados a palavras, ou seja, inseridos em um determinado contexto, podem ser muito importantes. Exemplo: datas como 7 de setembro de 1822.

26
Eliminação de Acentuação
Eliminar os acentos; pode ser útil devido a inconsistências de uso; a mesma palavra escrita com e sem acento em documentos diferentes. No entanto, na língua portuguesa, existem palavras com significados completamente diferentes; mas que são escritas com as mesmas letras; diferenciando-se apenas pela presença ou ausência do acento. Nesse caso, a eliminação da acentuação pode causar uma interpretação incorreta da necessidade de informação do usuário.

28
Eliminação de Stopwords
Palavras que são muito freqüentes em muitos dos documentos da coleção; não são bons discriminadores dos documentos relevantes para uma consulta. Por isso, são pouco úteis para objetivos de recuperação de informação. Essas palavras são conhecidas como stopwords: artigos, preposições, conjunções. Verbos e advérbios muito comuns também podem ser incluídos na lista de stopwords: são, está, é, etc.

29
Eliminação de Stopwords
Em geral, as stopwords são eliminadas durante o processo de indexação dos documentos. Benefícios da eliminação de stopwords: redução do tamanho do índice da coleção; aumento da velocidade de processamento da consulta. No entanto, esse procedimento pode prejudicar o processo de recuperação de informação; especialmente para consultas por frase exata.

30
Eliminação de Stopwords

31
Eliminação de Stopwords
Uma solução para esse problema tem sido: desconsiderar as stopwords em consultas que não são por frase exata; o que diminui o número de termos de indexação e de ocorrências a serem considerados; diminuindo também o tempo de processamento da consulta. mas considerá-las em consultas por frase exata; cerca de apenas 10% das consultas submetidas às máquinas de busca disponíveis na Web.

34
Radicalização – Stemming
Freqüentemente, o usuário especifica uma palavra em uma consulta; mas apenas uma variação sintática dessa palavra está presente em um documento relevante. Esse problema pode ser resolvido com a substituição de palavras pelos seus respectivos radicais; a porção de uma palavra que resta; após a remoção de prefixos e sufixos.

35
Radicalização – Stemming
A radicalização é útil para melhorar o processo de recuperação de informação porque reduz variantes que apresentam a mesma raiz; e são relacionadas a um conceito comum. Exemplo: a palavra no singular, no plural, na forma do verbo correspondente, o verbo no gerúndio ou em algum tempo verbal são reduzidos ao mesmo radical. A literatura da área ainda é controversa em relação aos benefícios da radicalização.

38
Seleção de Termos de Indexação
Pode-se utilizar todas as palavras de um texto; para representá-lo. Pode-se também utilizar uma estratégia mais abstrata; em que nem todas as palavras são usadas como termos de indexação. Isso significa que o conjunto de termos de indexação deve ser controlado e selecionado; essa seleção pode ser feita por um especialista ou automaticamente.

39
Seleção de Termos de Indexação
Substantivos “carregam” mais semântica do que verbos, adjetivos e advérbios. Uma estratégia para selecionar automaticamente os termos de indexação; é selecionar apenas os substantivos que aparecem na coleção. Além disso, como é comum combinarmos dois ou mais substantivos para denotar um único conceito; como sistemas de informação; podemos também agrupar substantivos que aparecem próximos no texto em um único termo de indexação; que representa um único conceito.

Apresentações semelhantes