Carregar apresentação
A apresentação está carregando. Por favor, espere

1
Prof. Alexandre Monteiro Recife
Árvore de Decisão Prof. Alexandre Monteiro Recife

2
Contatos Prof. Guilherme Alexandre Monteiro Reinaldo
Apelido: Alexandre Cordel /gtalk: Site: Celular: (81)
")
3
Árvores de Decisão – ADs (1/4)
Forma mais simples: Lista de perguntas respostas “sim” ou “não” Hierarquicamente arranjadas Levam a uma decisão Estrutura da árvore determinada por meio de aprendizado Baseia-se em conhecimento a priori

4
ADs – treinamento (1/10) Treinamento AD encontra regras que recursivamente bifurcam (baseadas nos valores dos atributos) o conjunto de dados Sub-conjuntos homogêneos intra sub-conjuntos e Sub-conjuntos heterogêneos inter sub-conjuntos Conteúdo dos sub-conjuntos pode ser descrito por um conjunto de regras

5
ADs – treinamento (2/10) Base de Dados “Tempo”
 Base de Dados Tempo")
6
ADs – treinamento (3/10) Outlook? Sunny Rain Overcast
 Outlook Sunny Rain Overcast")
7
ADs – treinamento (4/10)
")
8
ADs – treinamento (5/10) Outlook? YES Humidity ? Sunny Rain Overcast
Normal High Inst Outlook Temp Hum Wind Play D9 sunny cool normal weak yes D11 mild strong Inst Outlook Temp Hum Wind Play D1 sunny hot high weak no D2 strong D8 mild

9
ADs – treinamento (6/10)
")
10
ADs – treinamento (7/10) Outlook? Humidity ? YES NO Wind? Sunny
Overcast Rain Humidity ? Normal High YES NO Wind? Weak Strong

11
ADs – treinamento (8/10) Outlook? Humidity ? YES NO Wind? NO YES Sunny
Overcast Rain Humidity ? Normal High YES NO Wind? Weak Strong NO YES

12
ADs – treinamento (9/10)
")
13
ADs – treinamento (10/10) Outlook? YES Humidity ? Wind? YES NO NO YES
Como classificar <rain,hot,high,normal,strong>? Outlook? Sunny Rain Overcast YES Humidity ? Wind? Normal High Weak Strong YES NO NO YES

14
Indução top-down de árvores de decisão
Qual é o melhor atributo? Dados de tempo [29+ , 35-] [21+, 5-] [8+, 30-] A2=? [18+ , 33-] [11+ , 2-] A1=?

15
Entropia (1/3) S é uma amostra dos exemplos de treinamento
p é a proporção de exemplos positivos em S p é a proporção de exemplos negativos em S Entropia mede a “impureza” de S: Entropia(S)=- p log2 p - p log2 p Para mais de duas (n) classes
=- p log2 p - p log2 p Para mais de duas (n) classes.")
16
Entropia (2/3) Entropia(S) = especifica o nr. mínimo de bits de informação necessário para codificar uma classificação de um membro arbitrário de S.

17
Entropia (3/3) Portanto, o nr. de bits esperados para codificar ou de elementos aleatórios de S: p (-log2 p) + p (-log2 p) Entropia(S)=- p log2 p - p log2 p
 + p (-log2 p) Entropia(S)=- p log2 p - p log2 p")
18
Entropia - Exemplo I Se p é 1, o destinatário sabe que o exemplo selecionado será positivo Nenhuma mensagem precisa ser enviada Entropia é 0 (mínima) Se p é 0.5, um bit é necessário para indicar se o exemplo selecionado é ou Entropia é 1 (máxima) Se p é 0.8, então uma coleção de mensagens podem ser codificadas usando-se - em média menos de um bit - códigos mais curtos para e mais longos para
 Se p é 0.5, um bit é necessário para indicar se o exemplo selecionado é ou Entropia é 1 (máxima) Se p é 0.8, então uma coleção de mensagens podem ser codificadas usando-se - em média menos de um bit - códigos mais curtos para e mais longos para ")
19
Entropia - Gráfico

20
Entropia - Exemplo I Suponha que S é uma coleção de 14 exemplos, incluindo 9 positivos e 5 negativos (o exemplo da base de dados “Tempo”) Notação: [9+,5-] A entropia de S em relação a esta classificação booleana é dada por:

21
Ganho de Informação No contexto das árvores de decisão a entropia é usada para estimar a aleatoriedade da variável a prever (classe). Dado um conjunto de exemplos, que atributo escolher para teste? Os valores de um atributo definem partições do conjunto de exemplos. O ganho de informação mede a redução da entropia causada pela partição dos exemplos de acordo com os valores do atributo A construção de uma árvore de decisão é guiada pelo objetivo de diminuir a entropia, ou seja, a aleatoriedade (dificuldade de previsão) da variável que define as classes.
 da variável que define as classes.")
22
Critério de ganho (1/2) Gain(S, A) = redução esperada da entropia devido a “classificação” de acordo com A
 Gain(S, A) = redução esperada da entropia devido a classificação de acordo com A.")
23
Critério de ganho (2/2) Usar o critério de ganho para decidir!
[29+ , 35-] [21+, 5-] [8+, 30-] A2=? [18+ , 33-] [11+ , 2-] A1=?

24
Exemplo de Critério de Ganho

25
Exemplo Critério de Ganho

26
Critério de ganho - Exemplo (1/2)
Suponha que S é uma coleção de exemplos de treinamento ([9+,5-]) descritos por atributos incluindo Wind, que pode ter os valores Weak and Strong (base de dados “Tempo”).
 descritos por atributos incluindo Wind, que pode ter os valores Weak and Strong (base de dados Tempo ).")
27
Critério de ganho - Exemplo (2/2)
")
28
Exemplos de treinamento (1/3)
")
29
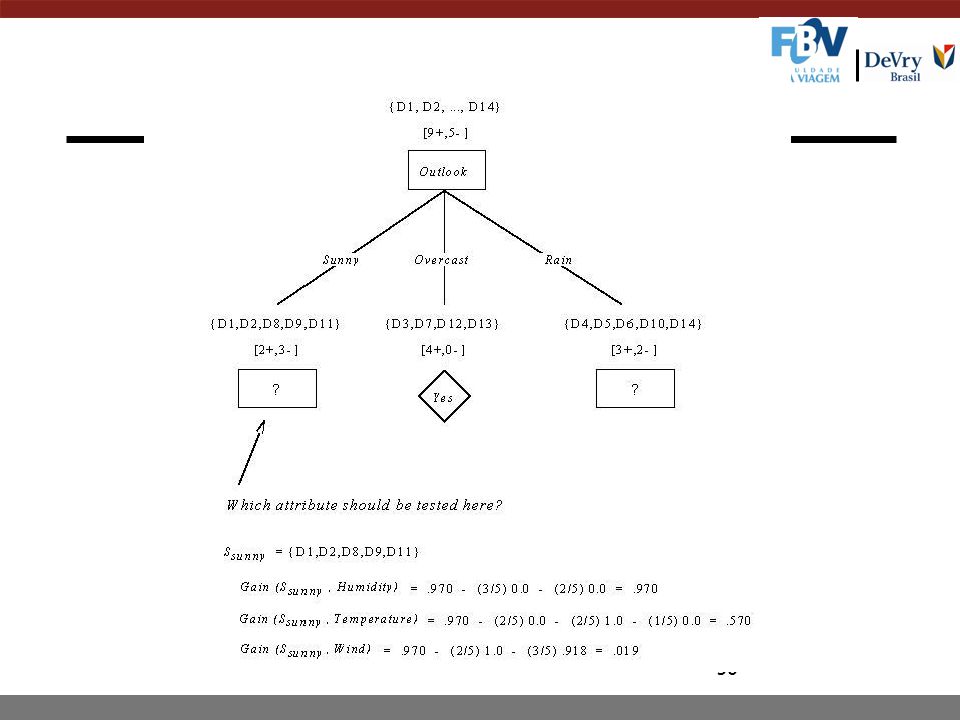
Exemplos de treinamento (2/3)
Que atributo deve ser selecionado para ser a raiz da árvore? Gain(S,Outlook) = 0.246 Gain(S,Humidity) = 0.151 Gain(S,Wind) = 0.048 Gain(S,Temperature) = 0.029 em que S denota a coleção de exemplos na tabela anterior
 = Gain(S,Humidity) = Gain(S,Wind) = Gain(S,Temperature) = em que S denota a coleção de exemplos na tabela anterior.")
31
Overfitting em árvores de decisão
Suponha que adicionamos um exemplo de treinamento com ruído #15: Sunny, Hot, Normal, Strong, PlayTennis=No Qual seria seu efeito na árvore anterior:

32
Overfitting Considere o erro da hipótese h sobre
dados do treinamento: errotrain(h) distribuição completa D dos dados: erroD(h) Uma hipótese h H “overfits” (se super ajusta) o conjunto de dados se há uma hipótese alternativa h´ H tal que errotrain(h) < errotrain(h´) e erroD(h) > erroD(h´)
 distribuição completa D dos dados: erroD(h) Uma hipótese h H overfits (se super ajusta) o conjunto de dados se há uma hipótese alternativa h´ H tal que. errotrain(h) < errotrain(h´) e. erroD(h) > erroD(h´)")
33
Overfitting na aprendizagem de árvores de decisão (1/2)
")
34
Overfitting na aprendizagem de árvores de decisão (2/2)
Como evitar overfitting? Parar o crescimento da árvore quando a divisão dos dados não é estatisticamente significativa (pre-prune) Deixar a árvore crescer completamente para, então, poda-la (post-prune) Como escolher a “melhor” árvore: Medir a performance sobre o cj. de dados treinamento Medir a performance sobre um cj. de dados (separado) de validação MDL: minimizar - size(tree)+size(misclassification(tree))
 Deixar a árvore crescer completamente para, então, poda-la (post-prune) Como escolher a melhor árvore: Medir a performance sobre o cj. de dados treinamento. Medir a performance sobre um cj. de dados (separado) de validação. MDL: minimizar - size(tree)+size(misclassification(tree))")
35
Reduzindo o erro através da poda
Divida os dados em cj. de treinamento e validação Faça até que uma poda adicional seja prejudicial: 1. Avalie o impacto sobre o cj. de validação de podar cada nó possível (e seus descendentes) 2. Gulosamente remova aquele que melhora mais a performance no cj. de validação
 2. Gulosamente remova aquele que melhora mais a performance no cj. de validação.")
36
Efeito do uso da técnica de poda

37
Podando as regras Este é um dos métodos mais utilizados
1. Converta a árvore para um conjunto equivalente de regras 2. Pode cada regra independentemente umas das outras 3. Ordene as regras finais em uma seqüência desejada para uso Este é um dos métodos mais utilizados

38
Atributos com valores contínuos
Crie um atributo discreto para testar um que seja contínuo Temperature = 82.5 (Temperature > 72.3) = t,f Temperature: PlayTennis: NO NO YES YES YES NO
 = t,f. Temperature: PlayTennis: NO NO YES YES YES NO.")
39
Atributos Numéricos: Exemplo

40
Atributos Numéricos: Exemplo

41
Atributos Numéricos: Exemplo

42
Atributos Numéricos: Exemplo

43
Atributos Numéricos: Exemplo
Sensor_1? > 83,46 <= 83,46

44
Atributos Numéricos: Exemplo

45
Atributos Numéricos: Exemplo
Sensor_1? > 83,46 <= 83,46

46
Atributos Numéricos: Exemplo
Sensor_1? > 83,46 <= 83,46 Sensor_2? > 12,84 <= 12,84

47
Atributos Numéricos: Exemplo

48
Atributos Numéricos: Exemplo (Ruído)
")
49
Atributos Numéricos: Exemplo (Ruído)
Sensor_1? > 83,46 <= 83,46 Sensor_2? > 12,74 <= 12,74

50
Atributos Numéricos: Exemplo (Ruído)
Sensor_1? > 83,46 <= 83,46 Sensor_2? > 12,74 <= 12,74 >13,30 Sensor_2? <=13,30 Overfitting!

51
Atributos com vários valores (1/2)
Problema: Se o atributo tem vários valores, Gain o selecionará Suponha o uso de Date = 3/06/00 como atributo Um abordagem: use GainRatio

52
Atributos com vários valores (2/2)
Onde Si é um subconjunto de S para o qual A tem valor vi

53
Atributos com custo Considere
Diagnóstico médico, BloodTest tem custo R$500 Robótica, Width_from_1ft tem custo 23 sec. Como aprender uma árvore consistente com um valor de custo esperado baixo? Uma abordagem: substitua Gain por:

54
Atributos com custo (2/2)
Tan e Schlimmer (1990) Nunez (1988) Onde w [0,1] determinar a importância do custo
 Nunez (1988) Onde w [0,1] determinar a importância do custo.")
55
Valores de atributo desconhecidos (1/2)
E se valores do atributo A estão faltando para alguns exemplos? Mesmo assim use os exemplos de treinamento, e organize a árvore como segue: Se um nó n testa A, atribua um valor para A que seja o mais comum entre os outros exemplos classificados nó n Atribua para A um valor que seja o mais comum entre os outros exemplos com o mesmo valor objetivo (target value)
")
56
Valores de atributo desconhecidos (2/2)
Atribua uma probabilidade pi para cada valor possível vi de A atribua uma fração pi de exemplos para cada descendente da árvore Classifique exemplos novos da mesma maneira

57
ADs - conclusão Vantagens: Estrutura de fácil manipulação
Produzem modelos que podem ser facilmente interpretados por humanos Desvantagens: Pouca robustez a dados de grande dimensão Acurácia afetada por atributos pouco relevantes Dificuldade em lidar com dados contínuos

58
Referências Machine Learning. Tom Mitchell. McGraw-Hill.1997.

Apresentações semelhantes








 Universidade do Minho.>")










