Carregar apresentação
A apresentação está carregando. Por favor, espere

1
Verossimilhança

2
Construção de modelos:
1 estimativa dos parâmetros que melhor ajustam os modelos aos dados, 2 selecionar aqueles modelos que tem o melhor ajuste Métrica usada para avaliar o ajuste Verossimilhança: probabilidade de ocorrência dos dados dado um modelo.

3
Modelo Parte determinística: Expectativa da média da distribuição de erros. Y= Normal(ax+b, σ) Y=Poisson(ax+b)
 Y=Poisson(ax+b) .")
4
As distribuições de erros pertencem à famílias de funções exponenciais e podem ser descritas por:
Onde θi e φ são parâmetros de localização e escala, respectivamente. Ex. Poisson:

5
Binomial Normal

6
Estimativas de parâmetros: uma única distribuição
Conjunto de dados independentes vindos todos da mesma distribuição. Ex: Predação de frutos em experimento de remoção – binomial; Densidade de árvores com distribuição aleatória em parcelas – Poisson. Estimo os parâmetros da distribuição.

7
Máxima verossimilhança
Maximizar a verossimilhança entre os dados e o modelo Estimativa dos parâmetros de conjunto independente de dados: verossimilhança conjunta é o produto das estimativas individuais a partir de cada dado. Se a distribuição é única (dados vindos da mesma distribuição) temos o produto de termos similares
 temos o produto de termos similares.")
8
Por convenção, usa-se: - log do valor de verossimilhança e procuramos minimizar o soma das mesmas.

9
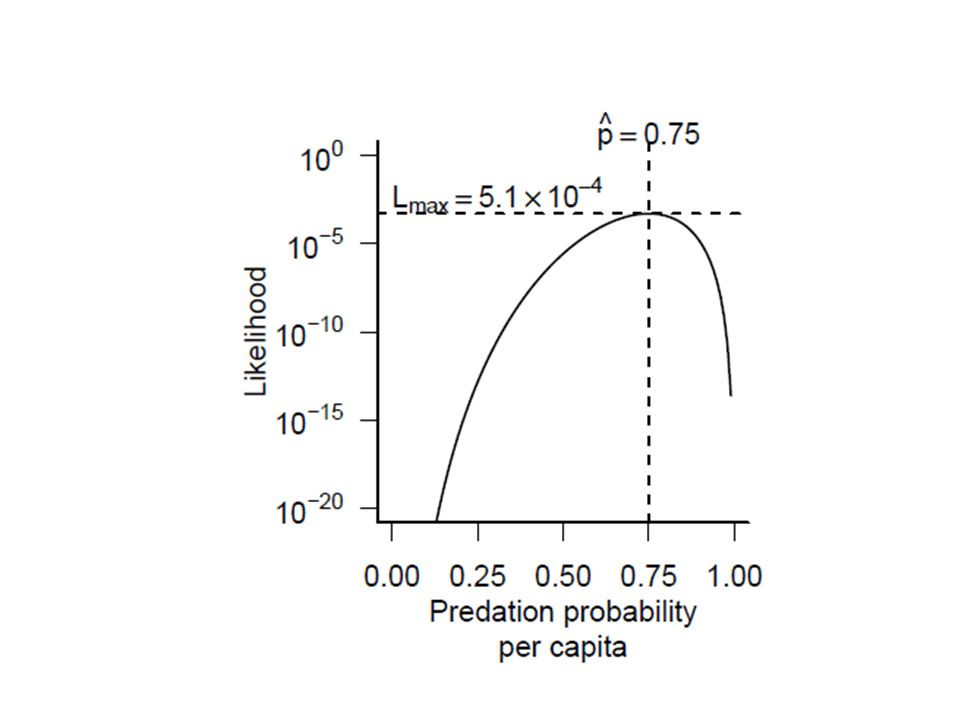
Exemplo: uma única observação: k sucessos em N possibilidades, dado uma probabilidade individual p de sucessos Em n tentativas, cada uma com N possibilidades, e o numero de sucessos da iésima tentativa é ki

11
Melhor valor para p Analiticamente: derivada do L em relação a p. Máximo – derivada é zero. Numero de sucessos Numero de tentativas

12
Para Poisson, o melhor estimador de lambda é a média.
Para a normal o melhor estimador da média e desvio são estes parâmetros calculados à partir dos dados. Para algumas distribuições, entretanto, não há solução analítica: solução numérica

13
Solução numérica no R. P1=rbinom(20, size =6, p=0.7)
#Crio a função de densidade acumulada (verossimilhança bionomial) para um dado p e conjunto de dados x: binomL=function(p,k,N){-sum(dbinom(k, prob=p, size=N, log=TRUE))} #usando a função optimize. Otimiza o parêmtro escolhido, a partir de uma estimativa inicial, usando alguns métodos O1=optim(fn=binomL,par=c(p=0.5),N=6,k=P1, method= “BFGS”)
 para um dado p e conjunto de dados x: binomL=function(p,k,N){-sum(dbinom(k, prob=p, size=N, log=TRUE))} #usando a função optimize. Otimiza o parêmtro escolhido, a partir de uma estimativa inicial, usando alguns métodos. O1=optim(fn=binomL,par=c(p=0.5),N=6,k=P1, method= BFGS )")
14
library(bbmle) Função mle() já usa o negativo da verossimilhança.
M1=mle2(minuslog=binomL,start=list(p=0.5),data=list(N=6, k=P1))
,data=list(N=6, k=P1))")
15
Modelos mais complexos
Ex. p=f(x) Y ~ binomial(p,N). Ajuste de uma reta ou uma curva logística usando 3 parametros: y= a/exp((b-x)/c) my=c(5,6,11,20,27,33,57,43,47,31) co=c(5,15,20,25,30,35,40,45,55,60)
 Y ~ binomial(p,N). Ajuste de uma reta ou uma curva logística usando 3 parametros: y= a/exp((b-x)/c) my=c(5,6,11,20,27,33,57,43,47,31) co=c(5,15,20,25,30,35,40,45,55,60)")
16
Reta com desvios normais
#primeiro crio a função de densidade acumulada que combina a parte determinística e a estocástica ren=function(p,mean,sd,x){ a=p[1] b=p[2] myp=a*co+b sd1=((sum((my-myp)^2))/(length(my)-1)^0.5 -sum(dnorm(x,mean=myp,sd=sd1, log=TRUE)) }
{ a=p[1] b=p[2] myp=a*co+b. sd1=((sum((my-myp)^2))/(length(my)-1)^0.5. -sum(dnorm(x,mean=myp,sd=sd1, log=TRUE)) }")
17
Agora uso a função de otimização:
O2=optim(fn=ren,x=my,p=c(0.5,5), method=“BFGS”). Como faria se quisesse comparar isto com uma curva construída com distribuição de posson?
, method= BFGS ). Como faria se quisesse comparar isto com uma curva construída com distribuição de posson")
18
rpo=function(p,lambda,x){
a=p[1] b=p[2] myp=a*cob+b -sum(dpois(x,lambda=myp, log=TRUE)) }
) }")
19
logip=function(p,lambda,x){ a=p[1] b=p[2] c=p[3]
Agora tente fazer um ajuste a função logística: y= a/exp((b-x)/c). Com desvios normais e depois com Poisson logip=function(p,lambda,x){ a=p[1] b=p[2] c=p[3] myp = a/(1+exp((b-co)/c)) -sum(dpois(x,lambda=myp, log=TRUE)) }
![logip=function(p,lambda,x){ a=p[1] b=p[2] c=p[3]](http://slideplayer.com.br/slide/1233444/3/images/19/logip%3Dfunction%28p%2Clambda%2Cx%29%7B+a%3Dp%5B1%5D+b%3Dp%5B2%5D+c%3Dp%5B3%5D.jpg "Agora tente fazer um ajuste a função logística: y= a/exp((b-x)/c). Com desvios normais e depois com Poisson. logip=function(p,lambda,x){ a=p[1] b=p[2] c=p[3] myp = a/(1+exp((b-co)/c)) -sum(dpois(x,lambda=myp, log=TRUE)) }")
20
login=function(p,mean,sd,x){
a=p[1] b=p[2] c=p[3] myp = a/(1+exp((b-co)/c)) sd1=(sum((my-myp)^2))^0.5 -sum(dnorm(x,mean=myp,sd=sd1, log=TRUE)) }
/c)) sd1=(sum((my-myp)^2))^0.5. -sum(dnorm(x,mean=myp,sd=sd1, log=TRUE)) }")
Apresentações semelhantes


 de variáveis aleatórias X1, X2, ..., Xn, cuja distribuição conjunta é desconhecida, inferir propriedades desta distribuição.>")







>")








