Carregar apresentação
A apresentação está carregando. Por favor, espere

1
GENÉTICA GEOGRÁFICA: Estatistica Espacial em Genética de Populações e da Paisagem
JOSÉ ALEXANDRE FELIZOLA DINIZ FILHO LABORATORIO DE ECOLOGIA TEÓRICA & SÍNTESE Departamento de Ecologia, ICB, Universidade Federal de Goiás, Brasil

2
ESPACIALMENTE IMPLICITAS ESPACIALMENTE EXPLICITAS
ABORDAGENS ESPACIAIS ESPACIALMENTE IMPLICITAS Ecologia & Genética ESPACIALMENTE EXPLICITAS

3
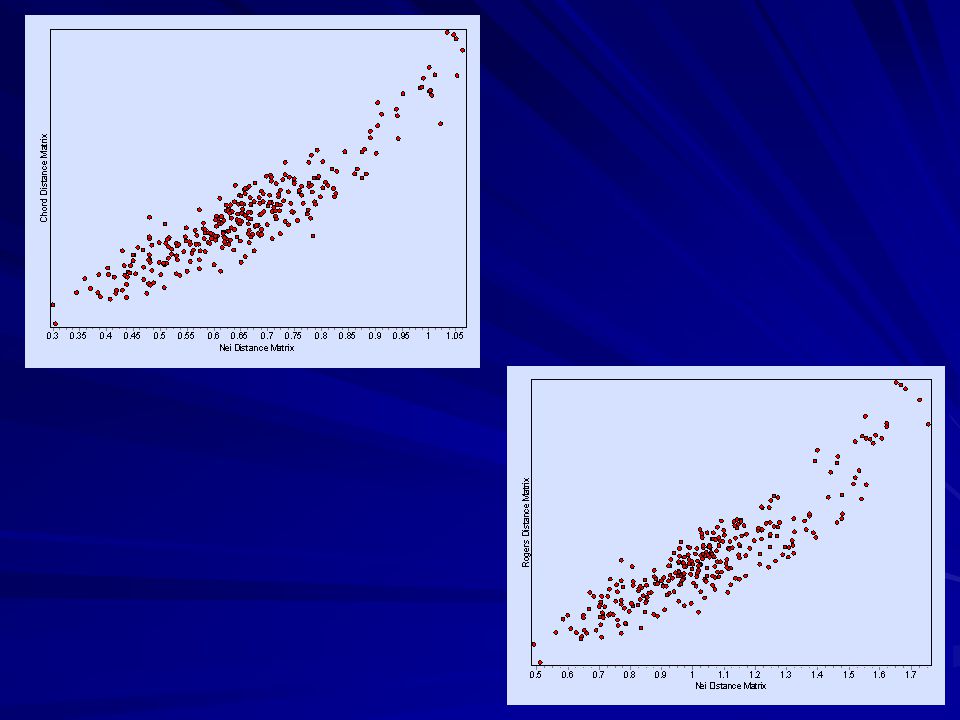
Matriz quadrada (n * n), simétrica e com zero na diagonal principal
Relação genética entre as populações FST (e estatísticas relacionadas) par-a-par Distâncias genéticas Outras matrizes de similaridade
 par-a-par. Distâncias genéticas. Outras matrizes de similaridade.")
4
D = -ln (I) I = Σxiyi / (Σxi2 Σyi2)0.5 Nei’s genetic distances Where
A identidade de Nei é, portanto, a correlação de Pearson entre as populações “ao longo” das frequencias alélicas... Masatoshi Nei

5
Valores “par-a-par” (n * n, simétrica)
Wright’s FST Análise de Variância de Frequencias Alélicas (P) AMOVA RST Holsinger’s Bayesian ST GST QST (fenótipo) Valores “par-a-par” (n * n, simétrica)
 AMOVA RST. Holsinger’s Bayesian ST. GST. QST (fenótipo) Valores par-a-par (n * n, simétrica)")
6
Distância Euclidiana (ca. distância de Rogers 1972)
")
7
j i dij Xj2 Alelo X2 Xi2 Xi1 Xj1 Alelo X1
Quando existem apenas dois descritores, essa equação resulta no valor da hipotenusa: j Xj2 população Alelo X2 dij i Xi2 população Xi1 Xj1 Alelo X1

8
A distância Euclidiana não apresenta um limite superior, ou seja, o valor aumenta indefinidamente com o aumento do número de descritores. Assim, podemos calcular a distância Euclidiana média: A distância de Rogers usa p = 2

9
Cavalli-Sforza’s & Edward (1967) chord distance
Populations are conceptualised as existing as points in a m-dimensional Euclidean space which are specified by m allele frequencies (i.e. m equals the total number of alleles in both populations).
.")
11
Coeficientes de SIMILARIDADE para dados binários
Transformar frequencias alélicas em dados 0/1 (ou seja, presença ou ausência do alelo ou haplótipo) Tabela de Freqüência 2 X 2 População 2 População 1
 Tabela de Freqüência 2 X 2. População 2. População 1.")
12
Uma maneira simples de calcular a similaridade entre os dois objetos envolve a contagem dos números de descritores que codificam estes objetos do mesmo modo e a posterior divisão pelo número total de descritores p (a+b+c+d): S1 = Coincidência simples (“simple matching”)
")
13
(0 = baixa similaridade e 1 = alta similaridade)
")
14
Coeficientes de similaridade para dados binários: modo Q (Coeficientes assimétricos)
Jaccard Sørensen

15
A idéia é desdobrar a (dis)similaridade em diferentes componentes, incluindo turnover e riqueza de alelos
similaridade em diferentes componentes, incluindo turnover e riqueza de alelos")
16
“Turnover” (substituição)
Riqueza alélica Para o Baru, o componente de turnover representa 69% da similaridade, mas o interessante é que apenas o componente de riqueza possui padrão espacial

17
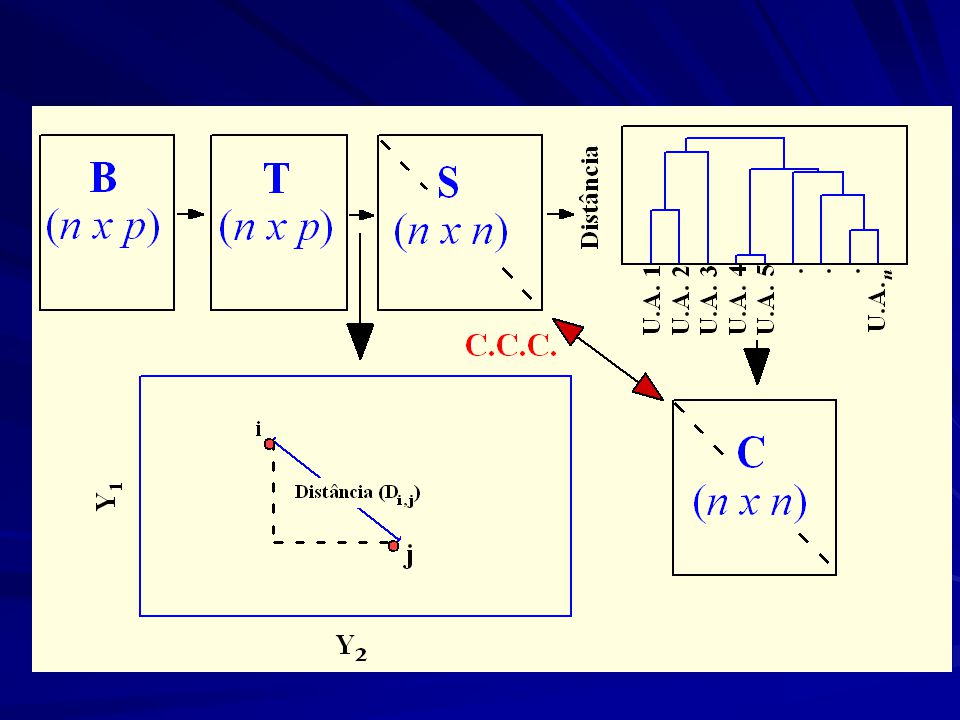
E agora, José? Com n objetos (unidades amostrais) vamos ter uma matriz com: [n (n – 1)/2] valores (e.g. se n = 25 300 valores) Como podemos representar eficientemente o padrão de similaridade entre esses objetos? As relações entre as n populações estão definidas em um espaço p-dimensional (onde p é o numero de alelos)
![E agora, José Com n objetos (unidades amostrais) vamos ter uma matriz com: [n (n – 1)/2] valores.](http://slideplayer.com.br/slide/1710349/6/images/17/E+agora%2C+Jos%C3%A9+Com+n+objetos+%28unidades+amostrais%29+vamos+ter+uma+matriz+com%3A+%5Bn+%EF%82%B4+%28n+%E2%80%93+1%29%2F2%5D+valores..jpg "(e.g. se n = 25 300 valores) Como podemos representar eficientemente o padrão de similaridade entre esses objetos As relações entre as n populações estão definidas em um espaço p-dimensional (onde p é o numero de alelos)")
18
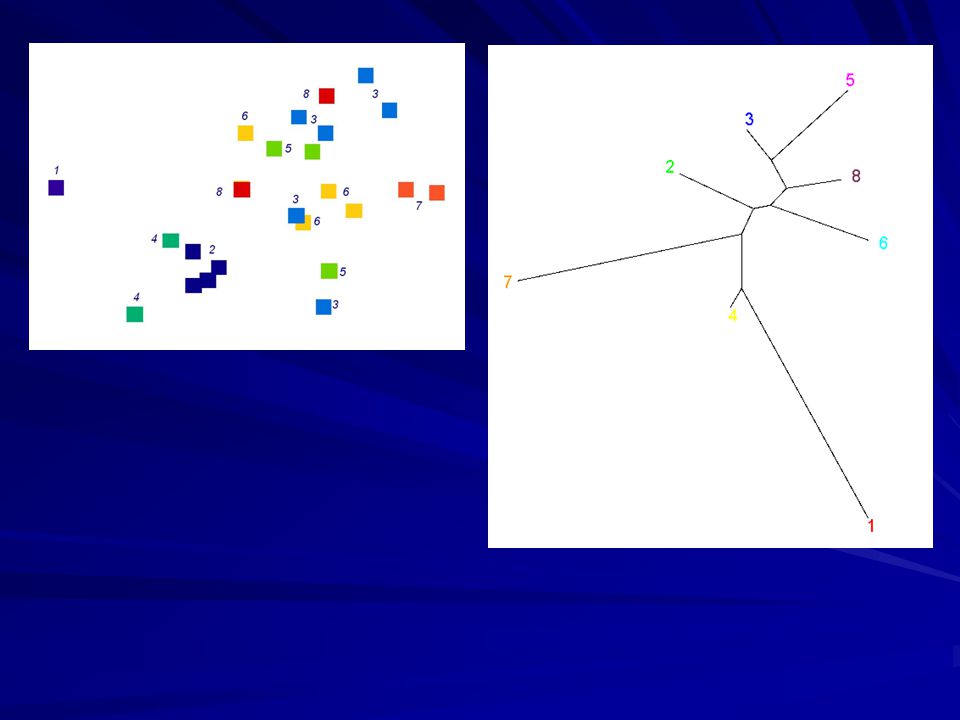
e.g., Quais as relações entre os 6 objetos a partir dessa matriz de distancias?

19
Agrupamento & Ordenações

20
Classificação das técnicas de agrupamentos
Algumas propriedades das técnicas: Aglomerativos: Os grupos são formados, sucessivamente, até reunir todos os objetos em um único grande grupo, ou; Divisivos: Subdivide os grupos até o isolamento de cada objeto (e.g. chaves de taxonomia); Hierárquicos: elementos de um determinado grupo são agrupados dentro de grupos em níveis maiores, ou; Não-hierárquicos: Produzem uma única divisão que maximiza a homogeneidade dentro de grupos;
; Hierárquicos: elementos de um determinado grupo são agrupados dentro de grupos em níveis maiores, ou; Não-hierárquicos: Produzem uma única divisão que maximiza a homogeneidade dentro de grupos;")
21
Análise de Classificação
Análise de Agrupamentos (SAHN)
")
22
Vários métodos de agrupamento:

23
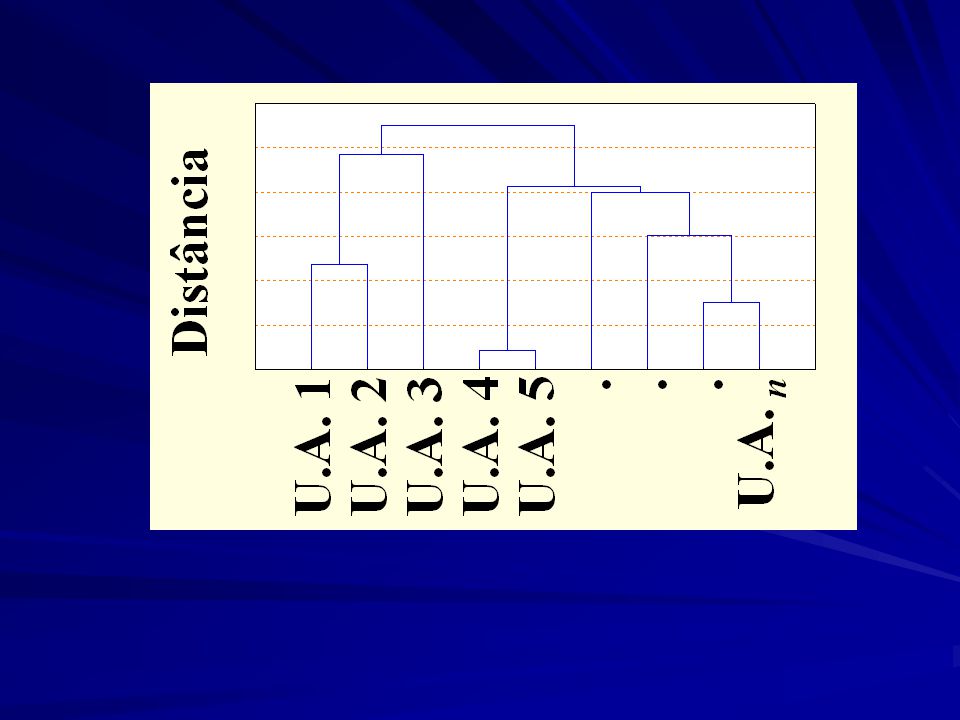
Aplicação da técnica de agrupamento: Construção do dendrograma
(método médias das distâncias, UPGMA)
")
24
Primeiro passo: Unir D e F (0,37) Distância de ligação 0,37 D F
 Distância de ligação 0,37 D F")
25
Calcular as distância em relação ao novo grupo
Segundo passo: Calcular as distância em relação ao novo grupo Neste ponto, vamos verificar qual o par com menor distância (2,12+2,49)/2 E assim, sucessivamente, para esta linha
/2. E assim, sucessivamente, para esta linha.")
26
Terceiro passo: Unir A e B (0,67) Distância de ligação A B D F
 Distância de ligação A B D F")
27
Calcular as distância em relação ao novo grupo
Quarto passo: Calcular as distância em relação ao novo grupo Vamos agrupar: (E) com (AB)
 com (AB)")
28
Quinto passo: Unir E e AB (0,73) Distância de ligação A B E D F
 Distância de ligação A B E D F")
29
Calcular as distância em relação ao novo grupo
Demais passos: Calcular as distância em relação ao novo grupo Agrupar (CDF) com (ABE) A B E C D F
 com (ABE) A. B. E. C. D. F.")
30
Resultado do NTSYS

31
Para os dados das 25 populações de Baru (UPGMA), a partir do FST par-a-par...
?

32
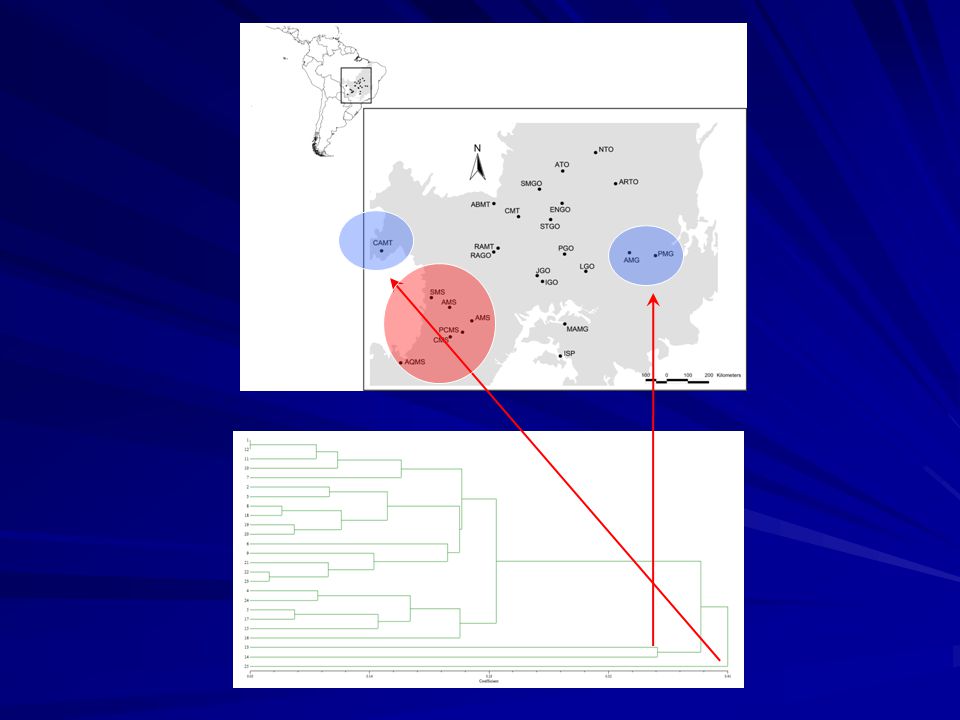
Subp. Local de coleta 1 Cocalinho-MT 2 Água Boa-MT 3 Pirenópolis-GO 4 Sonora-MS 5 Alcinópolis-MS 6 Alvorada-TO 7 São Miguel do Araguaia-GO 8 Luziânia-GO 9 Icém-SP 10 Monte Alegre de Minas-MG 11 Estrela do Norte-GO 12 Santa Terezinha-GO 13 Arinos-MG 14 Pintópolis-MG 15 Paraíso-MS (Chapadão do Sul) 16 Paraíso/Camapuã-MS (Camapuã) 17 Camapuã-MS 18 Indiara-GO 19 Araguaia-MT (Barra do Garça) 20 Araguaia-GO (Aragarças) 21 Jandaia-GO 22 Natividade-TO 23 Arraias-TO 24 Aquidauana- MS 25 Cáceres- MT
 16. Paraíso/Camapuã-MS (Camapuã) 17. Camapuã-MS. 18. Indiara-GO. 19. Araguaia-MT (Barra do Garça) 20. Araguaia-GO (Aragarças) 21. Jandaia-GO. 22. Natividade-TO. 23. Arraias-TO. 24. Aquidauana- MS. 25. Cáceres- MT.")
33
Subp. Local de coleta 1 Cocalinho-MT 2 Água Boa-MT 3 Pirenópolis-GO 4 Sonora-MS 5 Alcinópolis-MS 6 Alvorada-TO 7 São Miguel do Araguaia-GO 8 Luziânia-GO 9 Icém-SP 10 Monte Alegre de Minas-MG 11 Estrela do Norte-GO 12 Santa Terezinha-GO 13 Arinos-MG 14 Pintópolis-MG 15 Paraíso-MS (Chapadão do Sul) 16 Paraíso/Camapuã-MS (Camapuã) 17 Camapuã-MS 18 Indiara-GO 19 Araguaia-MT (Barra do Garça) 20 Araguaia-GO (Aragarças) 21 Jandaia-GO 22 Natividade-TO 23 Arraias-TO 24 Aquidauana- MS 25 Cáceres- MT
 16. Paraíso/Camapuã-MS (Camapuã) 17. Camapuã-MS. 18. Indiara-GO. 19. Araguaia-MT (Barra do Garça) 20. Araguaia-GO (Aragarças) 21. Jandaia-GO. 22. Natividade-TO. 23. Arraias-TO. 24. Aquidauana- MS. 25. Cáceres- MT.")
34
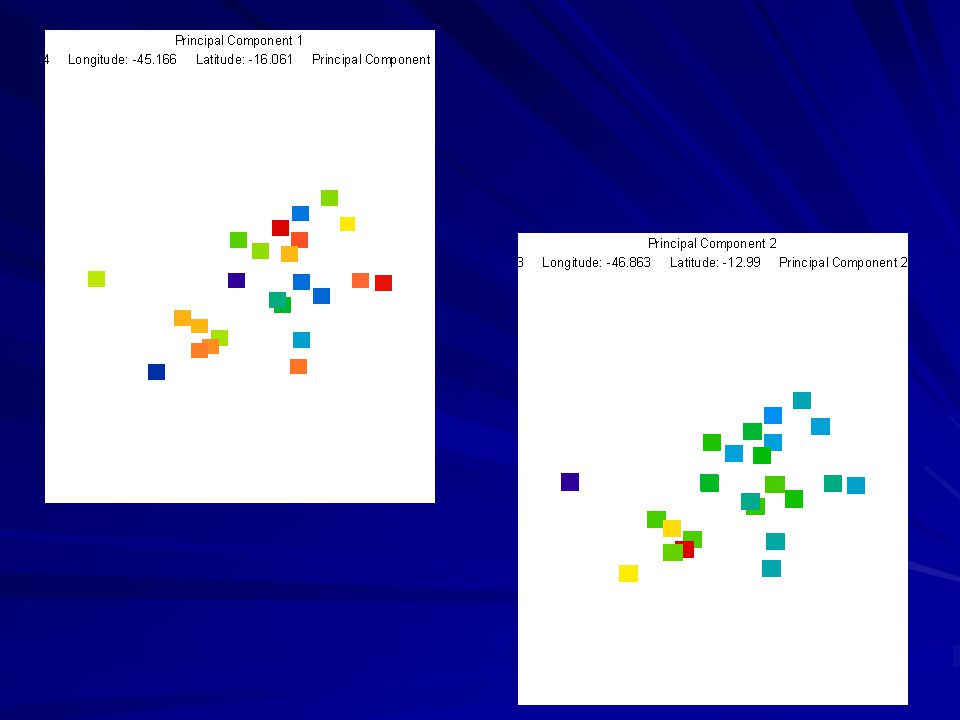
VISUALIZANDO OS PADRÕES NO ESPAÇO...

36
O dendrograma representa adequadamente a matriz de distância original?
Matriz Cofenética Matriz Original Coeficiente de Correlação Cofenética CCC) CCC=0,75 Bom ou Ruim?
 CCC=0,75. Bom ou Ruim")
37
Diagrama de Shepard: diagrama de dispersão que relaciona distâncias em um espaço com dimensão reduzida com a distâncias originais (mais adequado para técnicas de ordenação): No caso do Baru, o CCC foi igual a 0.845

38
Problemas com a Análise de Agrupamentos
(i) Resultados são dependentes dos protocolos utilizados; (ii) discretizar um processo que pode ser, na verdade, contínuo, de modo que; (iv) Dificuldade de interpretação (iii) O número de grupos é dependente do nível de corte;
 Resultados são dependentes dos protocolos utilizados; (ii) discretizar um processo que pode ser, na verdade, contínuo, de modo que; (iv) Dificuldade de interpretação. (iii) O número de grupos é dependente do nível de corte;")
40
Métodos para determinação do nível de corte
Maximizar diferenças entre grupos Minimizar diferenças dentro de grupos

41
Zero para quando u.a. estão em grupos iguais definidos pelo nível de corte
1 para quando u.a. estão em diferentes grupos definidos pelo nível de corte Nível 1 Nível 2 Bini, L. M. & Diniz Filho, J. A. F. (1995) Spectral Decomposition in cluster analysis with applications to limnological data. Acta Limnologica Brasiliensia, 7:
 Spectral Decomposition in cluster analysis with applications to limnological data. Acta Limnologica Brasiliensia, 7:")
42
Matriz Modelo (Nível de corte 1) Matriz Modelo (Nível de corte 2) Matriz de distância Original CCC Nível de Corte

43
(v) Mesmo com um conjunto aleatório de dados é possível encontrar “grupos”.
 Mesmo com um conjunto aleatório de dados é possível encontrar grupos .")
44
“Model-based” Clustering: STRUCTURE
Pressupostos (H-W, equilibrio de ligação) Maximizar a probabilidade de individuos pertencerem a grupos (que são desconhecidos) Vários dados (marcadores) e modelos de evolução Associar com outras caracteristicas dos individuos (inclusive “espaço”) Abordagem Bayesiana (MCMC)
 Maximizar a probabilidade de individuos pertencerem a grupos (que são desconhecidos) Vários dados (marcadores) e modelos de evolução. Associar com outras caracteristicas dos individuos (inclusive espaço ) Abordagem Bayesiana (MCMC)")
45
--------------------------------------------
Estimated Ln Prob of Data = Mean value of ln likelihood = Variance of ln likelihood = 820.8 Mean value of alpha =

47
Subp. Local de coleta 1 Cocalinho-MT 2 Água Boa-MT 3 Pirenópolis-GO 4 Sonora-MS 5 Alcinópolis-MS 6 Alvorada-TO 7 São Miguel do Araguaia-GO 8 Luziânia-GO 9 Icém-SP 10 Monte Alegre de Minas-MG 11 Estrela do Norte-GO 12 Santa Terezinha-GO 13 Arinos-MG 14 Pintópolis-MG 15 Paraíso-MS (Chapadão do Sul) 16 Paraíso/Camapuã-MS (Camapuã) 17 Camapuã-MS 18 Indiara-GO 19 Araguaia-MT (Barra do Garça) 20 Araguaia-GO (Aragarças) 21 Jandaia-GO 22 Natividade-TO 23 Arraias-TO 24 Aquidauana- MS 25 Cáceres- MT CLUSTERS 1 2 3 4 5 6 7 8 n BEST p2 0.026 0.01 0.078 0.012 0.753 0.03 0.073 0.017 32 0.581 0.007 0.095 0.086 0.013 0.167 0.525 0.092 0.014 0.329 0.056 0.31 0.547 0.032 0.018 0.400 0.12 0.145 0.53 0.054 0.103 31 0.331 0.069 0.692 0.081 0.023 0.05 0.497 0.009 0.128 0.061 0.089 0.016 0.094 0.589 0.384 0.011 0.583 0.301 0.015 0.044 0.433 0.347 0.124 0.045 0.398 0.299 0.232 0.59 0.034 0.024 0.051 0.029 0.408 0.022 0.021 0.028 0.509 0.036 0.335 0.376 0.02 0.436 0.323 0.077 0.068 12 0.308 0.041 0.038 0.516 0.122 0.211 0.008 0.058 0.854 0.734 0.006 0.811 0.668 0.096 0.5 0.137 0.066 0.085 13 0.296 0.027 0.043 0.067 0.665 0.807 0.063 0.660 0.005 0.035 0.676 0.485 0.157 0.173 0.183 0.348 0.048 27 0.215 0.285 0.09 0.129 0.025 0.356 37 0.239 0.389 0.104 0.049 0.81 0.019 0.666 0.667 0.142 0.1 15 0.477 0.033 0.171 0.484 0.139 0.047 0.292 0.94 30 0.884
 16. Paraíso/Camapuã-MS (Camapuã) 17. Camapuã-MS. 18. Indiara-GO. 19. Araguaia-MT (Barra do Garça) 20. Araguaia-GO (Aragarças) 21. Jandaia-GO. 22. Natividade-TO. 23. Arraias-TO. 24. Aquidauana- MS. 25. Cáceres- MT. CLUSTERS n. BEST. p")
48
Subp. Local de coleta 1 Cocalinho-MT 2 Água Boa-MT 3 Pirenópolis-GO 4 Sonora-MS 5 Alcinópolis-MS 6 Alvorada-TO 7 São Miguel do Araguaia-GO 8 Luziânia-GO 9 Icém-SP 10 Monte Alegre de Minas-MG 11 Estrela do Norte-GO 12 Santa Terezinha-GO 13 Arinos-MG 14 Pintópolis-MG 15 Paraíso-MS (Chapadão do Sul) 16 Paraíso/Camapuã-MS (Camapuã) 17 Camapuã-MS 18 Indiara-GO 19 Araguaia-MT (Barra do Garça) 20 Araguaia-GO (Aragarças) 21 Jandaia-GO 22 Natividade-TO 23 Arraias-TO 24 Aquidauana- MS 25 Cáceres- MT
 16. Paraíso/Camapuã-MS (Camapuã) 17. Camapuã-MS. 18. Indiara-GO. 19. Araguaia-MT (Barra do Garça) 20. Araguaia-GO (Aragarças) 21. Jandaia-GO. 22. Natividade-TO. 23. Arraias-TO. 24. Aquidauana- MS. 25. Cáceres- MT.")
50
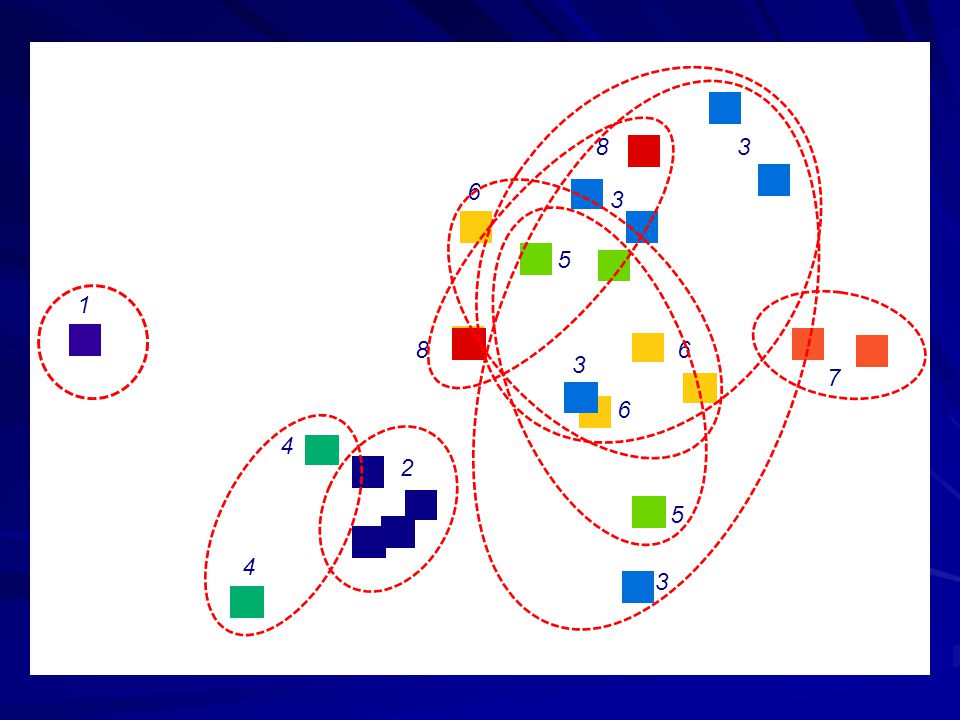
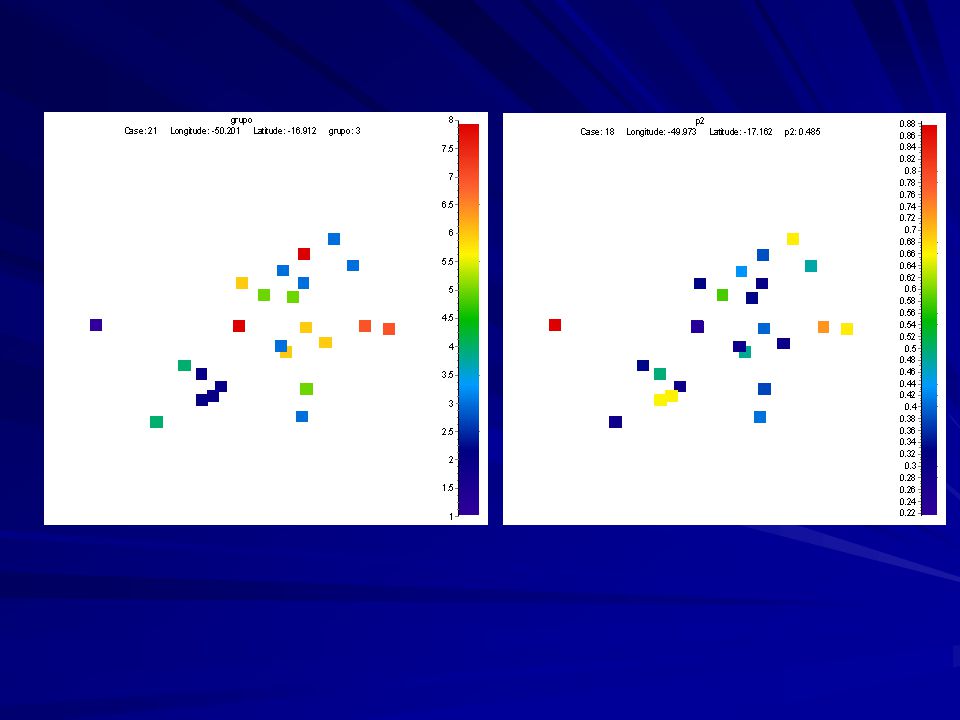
Os 8 grupos do STRUCTURE no espaço geográfico
3 6 3 5 1 8 6 3 7 6 4 2 5 4 3

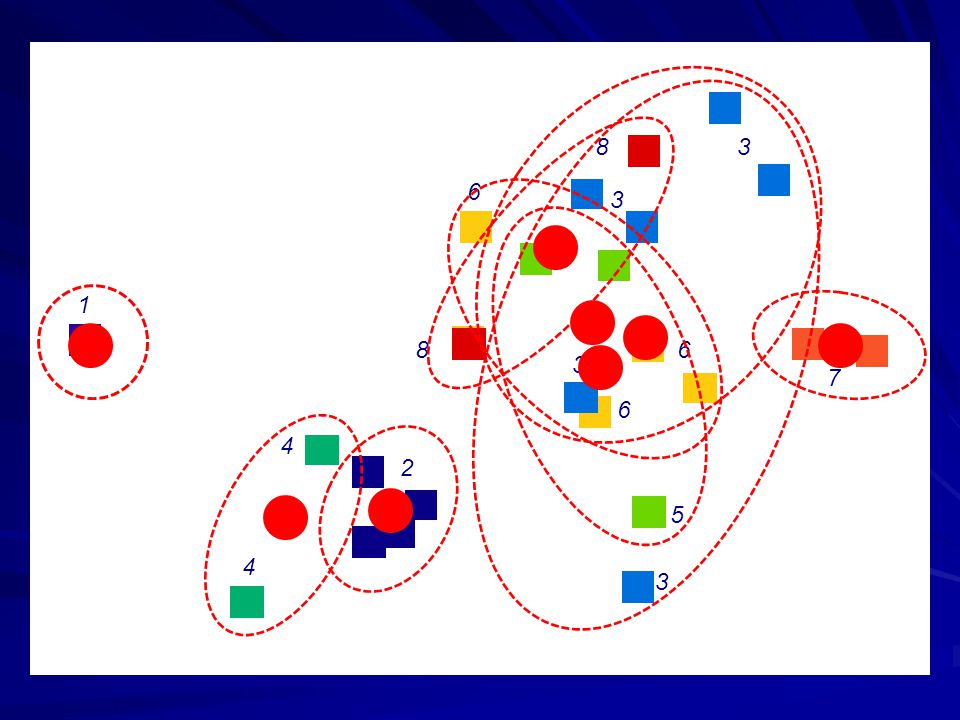
53
8 3 6 3 5 1 8 6 3 7 6 4 2 5 4 3
54
8 3 6 3 5 1 8 6 3 7 6 4 2 5 4 3
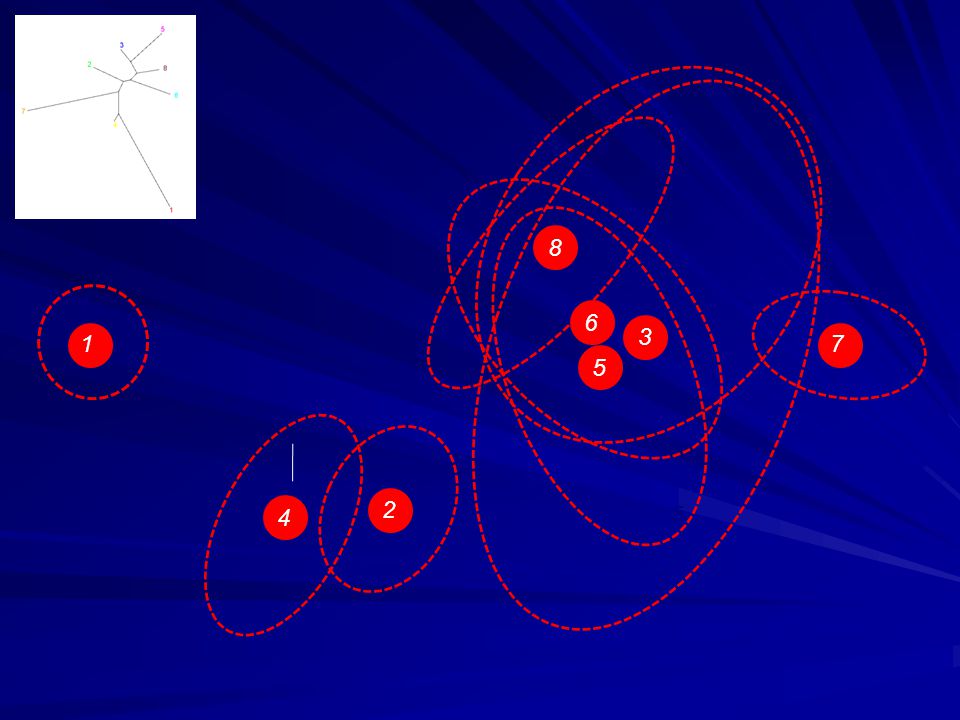
55
8 3 6 3 8 5 1 6 3 1 7 8 6 3 5 7 6 2 2 4 5 4 3
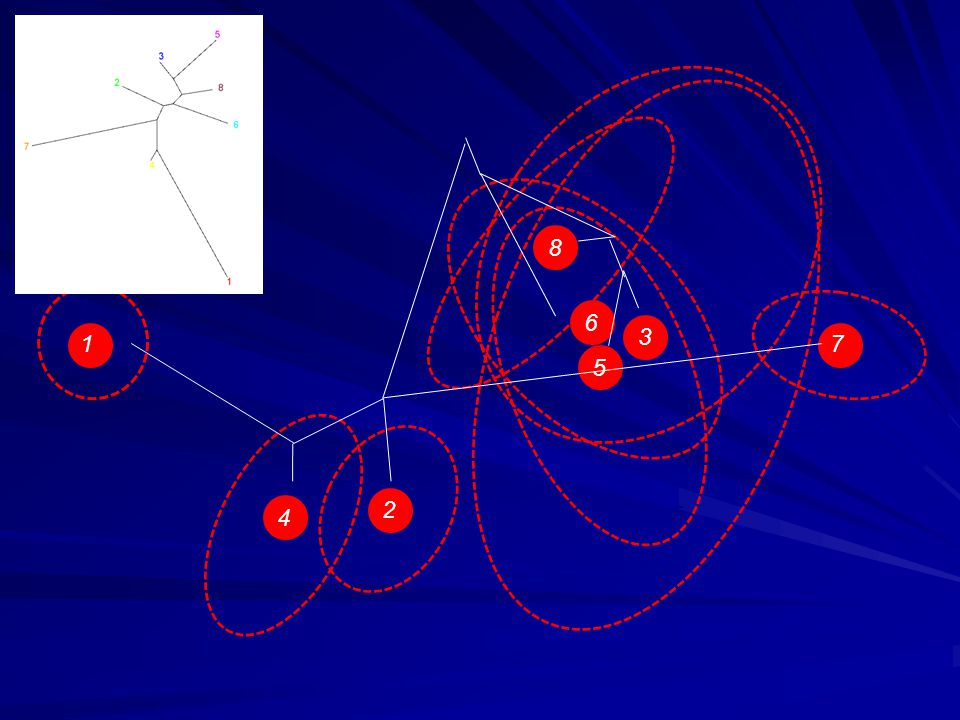
56
8 3 6 3 8 5 1 6 3 1 7 8 6 3 5 7 6 4 2 2 4 5 4 3
57
TÈCNICAS DE ORDENAÇÃO Representar a variação p-dimensional em um espaço (eixos) contínuo que “compacte” essa variação variação em um numero com m > p de dimensões (normalmente 1, 2 ou 3)
 contínuo que compacte essa variação variação em um numero com m > p de dimensões (normalmente 1, 2 ou 3)")
58
MAPAS SINTÉTICOS baseados em Análise de Componentes Principais (ACP)
Eliminar estrutura de correlação entre variáveis transformando-as em eixos ortogonais (os componentes principais); Interpretar os eixos principais como conseqüência de processos microevolutivos. Hotteling, H Analysis of a complex of statistical variables into principal componentes. Journal of Educational Psychology. v. 24, p
; Interpretar os eixos principais como conseqüência de processos microevolutivos. Hotteling, H Analysis of a complex of statistical variables into principal componentes. Journal of Educational Psychology. v. 24, p")
59
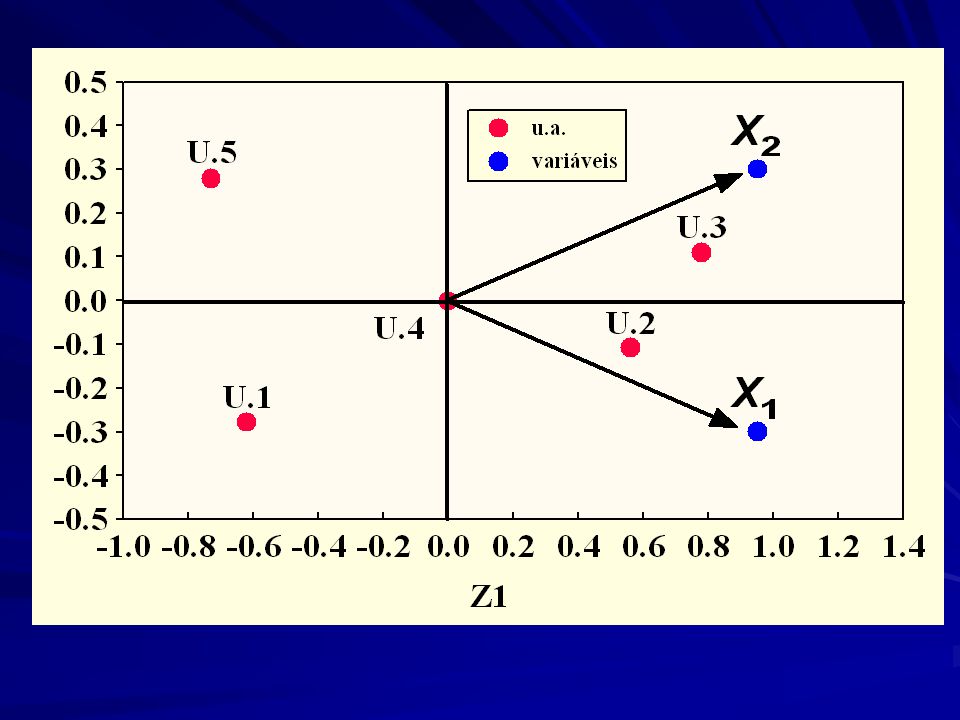
Em resumo, na ACP três matrizes são importantes
Autovalores – importância de cada eixo; Autovetores – coeficientes das variáveis nos eixos; Escores – componentes principais (eixo)
")
60
Análise de Componentes Principais (PCA) (Principal Component Analysis)
Pearson, K On lines and planes of closest fit to a system of points in space. Phylosophical magazine. v. 2, p Hotteling, H Analysis of a complex of statistical variables into principal componentes. Journal of Educational Psychology. v. 24, p Etapas: -Interpretação geométrica; -Procedimentos matemáticos; -Interpretação de dados reais; -Aplicações

61
Matematicamente, o objetivo da PCA é encontrar uma combinação linear de variáveis de tal forma que a variância entre os indivíduos seja a maior possível (1o componente principal): Os coeficientes a são os autovetores. São obtidos de tal forma a maximizar a variância de Z1 (var(Z1)), com a seguinte condição: Esta condição garante que a var(Z1) não aumente com a simples adição de qualquer um dos valores de a1j .
), com a seguinte condição: Esta condição garante que a var(Z1) não aumente com a simples adição de qualquer um dos valores de a1j .")
62
O segundo componente principal:
É calculado de tal forma que a var(Z2) seja a maior possível (a segunda principal direção da variância). A mesma condição anterior é requerida: Além disso, estes autovetores são calculados de tal maneira que Z2 não seja correlacionado com Z1 (componentes independentes).
 seja a maior possível (a segunda principal direção da variância). A mesma condição anterior é requerida: Além disso, estes autovetores são calculados de tal maneira que Z2 não seja correlacionado com Z1 (componentes independentes).")
63
Eixos independentes ou ortogonais:

64
O terceiro componente principal:
É calculado de tal forma que a var(Z3) seja a maior possível. A mesma condição anterior é requerida: Além disso, estes autovetores são calculados de tal maneira que Z3 não seja correlacionado com Z2 e Z1 (componentes independentes).
 seja a maior possível. A mesma condição anterior é requerida: Além disso, estes autovetores são calculados de tal maneira que Z3 não seja correlacionado com Z2 e Z1 (componentes independentes).")
65
Por exemplo, se temos 5 variáveis podemos extrair 5 componentes principais, tal como definido anteriormente. De forma mais geral, o número possível de componente é igual a p (variáveis). No entanto, como foi demonstrado, sucessivos componentes principais apresentam uma variância cada vez menor. Esse resultado será útil para a redução da dimensionalidade dos dados.
. No entanto, como foi demonstrado, sucessivos componentes principais apresentam uma variância cada vez menor. Esse resultado será útil para a redução da dimensionalidade dos dados.")
66
As variâncias dos componentes principais são os autovalores () de uma matriz de covariância ou correlação (com dados previamente estandardizados). Os autovetores (a) são os coeficientes das combinações lineares e informam quais as variáveis que apresentam o maior poder de discriminação das u.a. (maximizam a dispersão das unidades amostrais ao longo do espaço).
 são os coeficientes das combinações lineares e informam quais as variáveis que apresentam o maior poder de discriminação das u.a. (maximizam a dispersão das unidades amostrais ao longo do espaço).")
67
CP 1 X1 CP3 CP 2 X3 X2

68
Autovalores e Autovetores
C = Ca = a

69
Autovalores e Autovetores
Ra = a

70
Exemplo numérico Matriz de correlação entre variáveis:

71
(R-I)a=0 Cuja equação característica: |R- I|=0
a=0 Cuja equação característica: |R- I|=0")
73
Determinante de uma matriz 2 x 2:
o primeiro termo ao quadrado, menos duas vezes o produto dos dois termos mais o quadrado do segundo)
")
74
a b c (Ignore o sinal) (Ignore o sinal)
 (Ignore o sinal)")
75
% de explicação do CP 1 = I/ = 1,82/2 = 91 % % de explicação do CP 2 = II/ = 0,18/2 = 9 % Total = 100 %

76
Autovetores: Ra = a O autovetor associado com I=1,82 é:

77
Arranjando: Para resolver essa equação, o valor a1,I é, arbitrariamente, fixado como 1 e o resultado de a2,I é encontrado:

78
Para resolver essa equação, 0 valor a1,I é, arbitrariamente, fixado como 1 e o resultado de a2,I é encontrado: Assim, a2,1= 1 Assim, o autovetor associado com o 1 é:

79
Similarmente, para 2 :

80
Para que a condição : seja atendida, o autovetor deve ser normalizado através de um fator, dado por: Posteriormente, cado autovetor é multiplicado pelo seu respectivo fator:

81
Note que:

82
De posse dos autovetores podemos criar as combinações lineares e, deste modo, encontrar os escores das unidades amostrais através da substituição das variáveis originais nestas combinações lineares:

83
Para as demais unidades amostrais

84
Escores = posição das novas u.a. nas novas variáveis denominadas CPs

85
A correlação (“loading”, coeficiente de estrutura) das variáveis originais com os componentes é dada pela correlação linear de Pearson entre as variáveis originais e os escores ou:
 das variáveis originais com os componentes é dada pela correlação linear de Pearson entre as variáveis originais e os escores ou:")
87
Para a realização da PCA, em conjuntos reais de dados, p deve ser sempre maior que 3, para fins de ordenação e redução da dimensionalidade dos dados (com 3 dimensões basta fazer um diagrama tridimensional). Deste modo, quando p >>> 3, por exemplo, p = 10, é possível obter 10 combinações lineares. Assim, é necessário um critério de parada. Em outras palavras, precisamos de um critério para verificar quais são os componentes principais interpretáveis. Se interpretamos um número muito grande de componente voltamos para o problema da análise univariada e não conseguimos o objetivo principal: redução da dimensionalidade do problema.

88
Critérios de Parada -Critério de Kaiser-Guttman ( > 1);
Jackson, D. A Stopping rules in principal components analysis: a comparison of heuristical and statistical approaches. Ecology 74: -Critério de Kaiser-Guttman ( > 1); -Proporção da variância total (e.g. 95%); -”Scree plot”; -Teste de esferecidade de Bartlett; -Modelo de Broken-Stick;
; -Proporção da variância total (e.g. 95%); - Scree plot ; -Teste de esferecidade de Bartlett; -Modelo de Broken-Stick;")
89
Regras de Parada: Scree plot
Assim, neste exemplo, somente o 1o CP seria interpretável. Os componentes “residuais” tendem a estar em uma linha reta.

90
Regras de Parada: Esferidade de Bartlett
CP 1 X1 CP3 CP 2 X3 X2

91
Regras de Parada: Broken Stick
Observado Broken-Stick

92
Um exemplo clássico... Considerem os dados obtidos por Bumpus (1898):
49 pardais (21 vivos e 29 mortos, após uma tempestade); 5 medidas morfométricas (landmarks); Passer domesticus
; 5 medidas morfométricas. (landmarks); Passer domesticus.")
93
---------------------------------------------------------------
***** PRINCIPAL COMPONENTS ANALYSIS -- pardais in medidas space ********** PC-ORD, Version 3.0 VARIANCE EXTRACTED, FIRST 5 AXES Broken-stick AXIS Eigenvalue % of Variance Cum.% of Var. Eigenvalue ***** PRINCIPAL COMPONENTS ANALYSIS -- pardais in medidas space ********** PC-ORD, Version 3.0 VARIANCE EXTRACTED, FIRST 5 AXES Broken-stick AXIS Eigenvalue % of Variance Cum.% of Var. Eigenvalue

94
Latent Vectors (Eigenvectors)
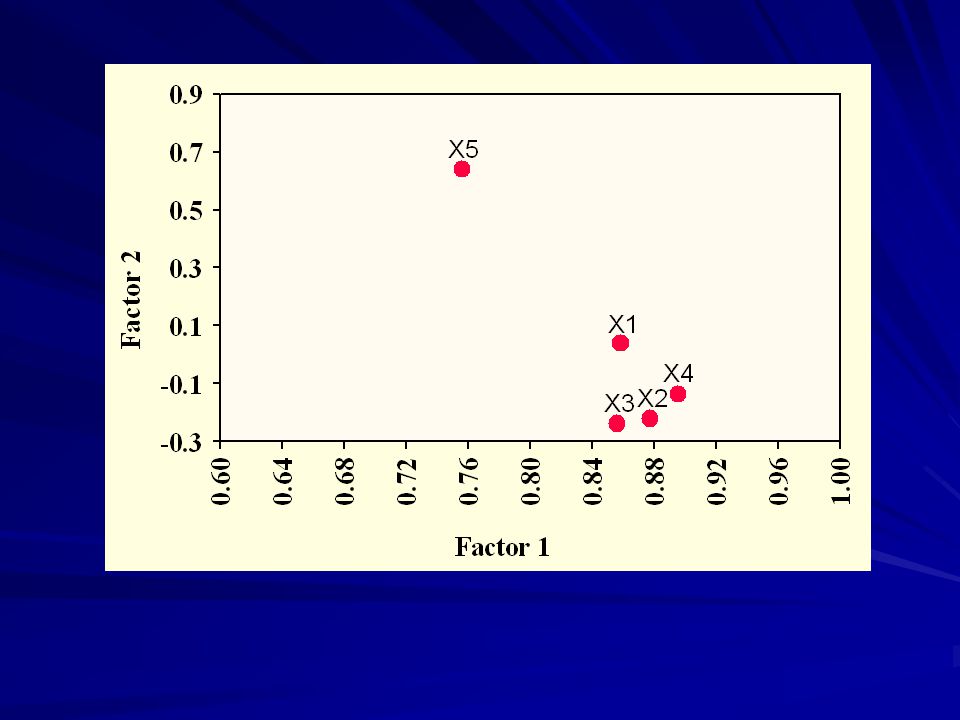
X X X X X

96
Seleção estabilizadora?
Eixo de tamanho (72,3 %)
")
101
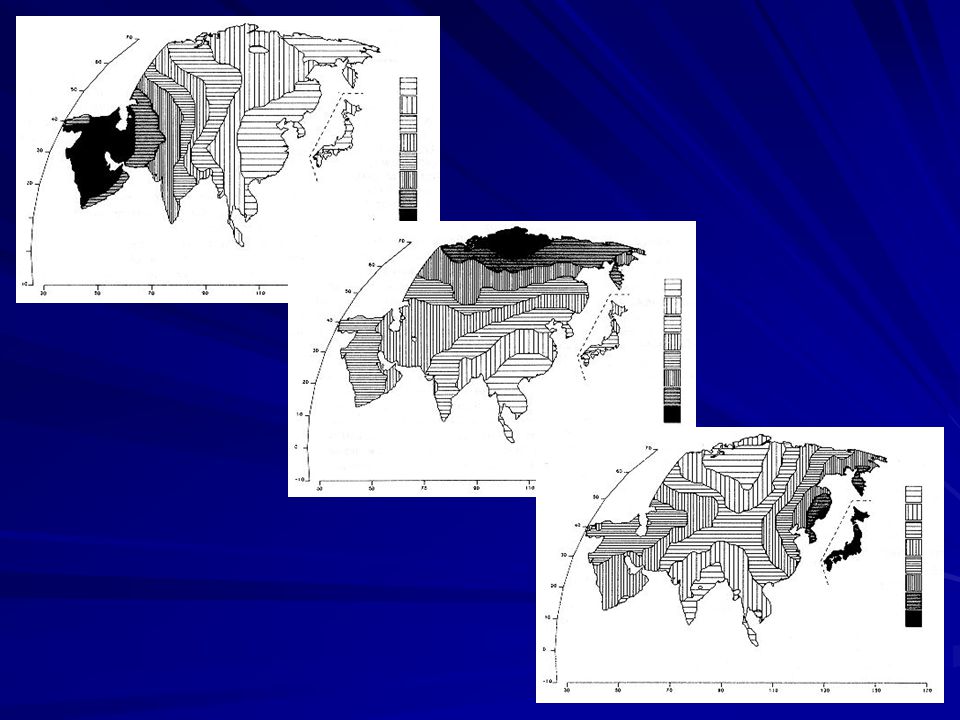
Nature Genetics 35: , 2003

104
Dados do Baru (1 locus – DA20)
")
107
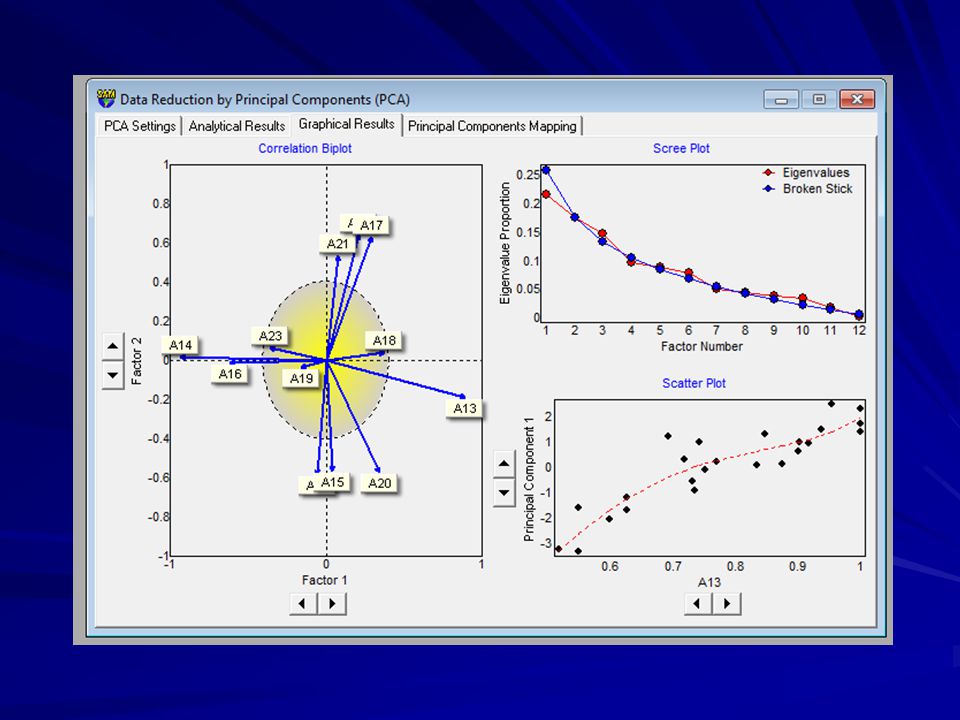
OUTRAS TÉCNICAS DE ORDENAÇÃO
ANALISE DE COORDENADAS PRINCIPAIS (PCOA) resolve o problema do PCA de poucas populações, pois extrai os autovetores de uma matriz de distâncias (transformada) Pode utilizar qualquer métrica de distância (incluindo distancias de Nei, FST, etc) ESCALONAMENTO MULTIDIMENSIONAL NÃO-MÉTRICO (NMDS) Técnica de otimização não-linear para espaço com m dimensões (medida de “stress”) Pode iniciar com a PCOA e melhorar a configuração
 resolve o problema do PCA de poucas populações, pois extrai os autovetores de uma matriz de distâncias (transformada) Pode utilizar qualquer métrica de distância (incluindo distancias de Nei, FST, etc) ESCALONAMENTO MULTIDIMENSIONAL NÃO-MÉTRICO (NMDS) Técnica de otimização não-linear para espaço com m dimensões (medida de stress ) Pode iniciar com a PCOA e melhorar a configuração.")
108
PCOA CCC = 0.907 NMDS Final STRESS1 = CCC = 0.968

110
PCOA CCC = 0.907 NMDS Final STRESS1 = CCC = 0.968

Apresentações semelhantes





















>")
 Programa de Pós-Graduação em Ciência.>")
 Análise dos Componentes Principais David Menotti, Ph.D. www.decom.ufop.br/menotti Universidade.>")
