Carregar apresentação
A apresentação está carregando. Por favor, espere

1
Aprendizagem de Máquina - Agrupamento
Ricardo Prudêncio

2
Clustering (Agrupamento)
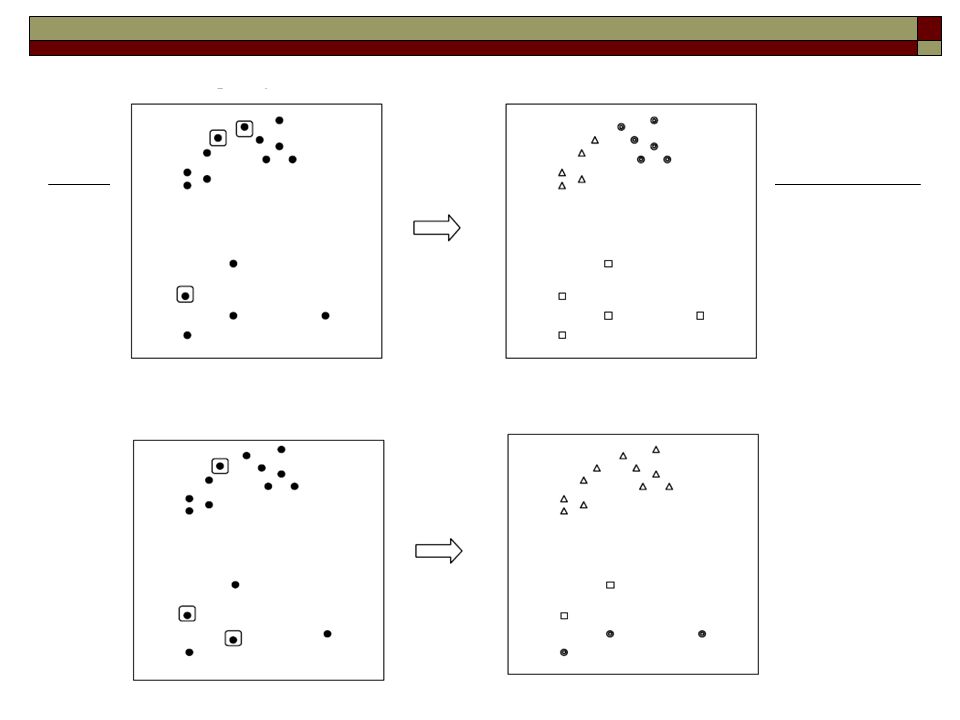
Particionar objetos em clusters de forma que: Objetos dentro de um cluster são similares Objetos de clusters diferentes são diferentes Descobrir novas categorias de objetos de uma maneira não-supervisionada Rótulos de classes não são fornecidos a priori

4
Clustering - Etapas Partição Objetos Redução da Representação
Padrões (Vetores) Redução da dimensionalidade Seleção ou extração de características Clustering Cluster A Cluster B Cluster C Objetos Similaridade Partição
 Redução da. dimensionalidade. Seleção ou extração. de características. Clustering. Cluster A. Cluster B. Cluster C. Objetos. Similaridade. Partição.")
5
Tipos de Clustering Algoritmos Flat (ou Particional)
Geram partição “plana”, i.e. não existe relação hierárquica entre os clusters Algoritmos Hierárquicos Geram uma hierarquia de clusters, i.e. cada cluster é associado a um cluster-pai mais genérico Vantagem: diferentes visões dos dados

6
Tipos de Clustering Hard Fuzzy
Cada objeto pertence exclusivamente a um único grupo na partição Fuzzy Cada objeto está associado a um cluster com certo grau de pertinência Partição Fuzzy pode ser convertida facilmente para uma partição hard

7
Tipos de Clustering Incremental Não-incremental
Partição é atualizada a cada novo objeto observado Em geral, apenas um número pequeno de clusters é modificado Não-incremental Partição é gerada de uma única vez usando todos os objetos disponíveis

8
Algoritmo K-Means

9
Algoritmo k-Means Algoritmo particional baseado em Otimização do Erro Quadrado centróide do cluster j Partição i-ésimo objeto do cluster j Conjunto de Objetos

10
Algoritmo k-Means Encontra de forma interativa os centróides dos clusters Centróide A Centróide A d1 d2

11
Algoritmo k-Means Clusters definidos com base nos centróides (centro de gravidade, ou o ponto médio dos cluster: Alocação dos objetos nos clusters feita com base na similaridade com o centróide até critério de parada

12
Algoritmo k-Means Passo 1: Defina k centróides iniciais, escolhendo k objetos aleatórios; Passo 2: Aloque cada objeto para o cluster correspondente ao centróide mais similar; Passo 3: Recalcule os centróides dos clusters. Passo 4: Repita passo 2 e 3 até atingir um critério de parada e.g. até um número máximo de iterações ou; até não ocorrer alterações nos centróides (i.e. convergência para um mínimo local da função de erro quadrado)
")
13
k-Means (Exemplo com K=2)
Inicializar centróides Alocar objetos Computar centróides x Realocar objetos x Computar centróides Realocar objetos Convergiu!

14
Algoritmo k-Means O k-Means tende a gerar clusters esféricos
Assim pode falhar para clusters naturais com formas mais complexas Exemplo -->

15
Algoritmo k-Means O k-Means é popular pela facilidade de implementação, e eficiência no tempo O(nK), onde n é o número de objetos e K é o número de clusters Comentários: Não adequado para atributos categóricos Sensível a outliers e ruído Converge para mínimos locais Desempenho do algoritmo é dependente da escolha dos centróides iniciais
, onde n é o número de objetos e K é o número de clusters. Comentários: Não adequado para atributos categóricos. Sensível a outliers e ruído. Converge para mínimos locais. Desempenho do algoritmo é dependente da escolha dos centróides iniciais.")
17
Algoritmo k-Medoid Similar ao k-Means mas cada cluster é representado por um objeto que realmente existe (medoid) Medoid é o objeto do grupo cuja similaridade média com os outros objetos possui o valor máximo Comentários: Tolerante a outliers e adequado para atributos categóricos Porém, custo mais alto

18
Algoritmos Hierárquicos

19
Algoritmos Hierárquicos
Geram uma partição onde os clusters são organizados em uma hierarquia Permite ao usuário ter diferentes visões dos objetos sendo agrupados

20
Dendrograma X2 F G D E B C A X1

21
Tipos de Algoritmos Hierárquicos
Algoritmos Hierárquicos Divisivos ou Particionais Assumem estratégia top-down Iniciam com cluster mais geral que é progressivamente dividido em sub-cluster Algoritmos Hierárquicos Aglomerativos Assumem estratégia bottom-up Iniciam com clusters específicos que são progressivamente unidos

22
Algoritmos Hierárquicos Divisivos
Passo 1: Inicie alocando todos os documentos em um cluster; Passo 2: A partir da estrutura existente de grupos, selecione um cluster para particionar; Em geral, o maior cluster, ou o cluster menos homogêneo Passo 3: Particione o grupo em dois ou mais subgrupos; Passo 4: Repita os passos 2 e 3 até que um critério de parada seja verificado e.g., até atingir um número desejado de grupos

23
Algoritmos Hierárquicos Divisivos
Bi-Secting k-Means Uso do algoritmo k-Means na etapa de divisão dos clusters Clusters são sucessivamente particionados em 2 sub-clusters Complexidade: O(n log(n))
)")
24
Algoritmos Hierárquicos Aglomerativos
Passo 1: Inicie alocando cada documento como um cluster diferente; Passo 2: Selecionar o par de clusters mais similares entre si e os agrupe em um cluster mais geral; Passo 3: Repita o passo 2 até a verificação de um critério de parada e.g., até que todos os documentos sejam agrupados em um único cluster Complexidade: O(n2 log(n))
)")
25
Algoritmos Hierárquicos Aglomerativos
Algoritmos variam conforme a maneira de medir similaridade entre dois clusters Single-Link: definida como a máxima similaridade entre os membros dos clusters Complete-Link: definida como a mínima similaridade entre os membros dos clusters Average-Link: definida como a média da similaridade entre os membros dos clusters

26
Single Link Similaridade entre clusters: Efeito:
Produz clusters mais alongados (efeito cadeia)
")
27
Single Link - Exemplo

28
Complete Link Similaridade entre clusters: Efeito:
Produz clusters mais coesos e compactos

29
Complete Link - Exemplo

30
Single Link X Complete Link
Single-Link conecta pontos de classes diferentes através de uma cadeia de pontos com ruído (*)
")
31
Single Link X Complete Link
1 1 1 1 1 2 2 1 2 1 2 2 2 1 1 1 1 1 Complete-Link não é capaz de identificar cluster de pontos (1)
")
32
Average-Link Similaridade entre clusters: Efeito:
Equilíbrio entre clusters coesos e flexíveis Em alguns contextos (e.g., clustering de texto) tem se mostrado mais eficaz
 tem se mostrado mais eficaz.")
33
Algoritmo Aglomerativo Baseado em Centróides
Similaridade entre clusters é definido como a similaridade entre seus centróides 1 2 x 3

34
Algoritmos Hierárquicos
Resumo: Os algoritmos hierárquicos divisivos são menos custosos que os aglomerativos Dentre os aglomerativos, o Average-Link funciona melhor em algumas aplicações Desempenho pode ser melhorado através da combinação de técnicas

35
Referências Jain, A. K., Murty, M. N., and Flynn, P. (1999). Data clustering: a review. ACM Computing Surveys, 3(31):264–323. Xu, R. and Wunsch II, D. (2005). Survey of Clustering Algorithms, IEEE Trans. on Neural Networks, 16(3): Jiang, D., T., Tang, and Zhang, A. (2004). Cluster Analysis for Gene Expression Data: A Survey, IEEE Trans. on Knowledge and Data Engineering, 16(11).
. Survey of Clustering Algorithms, IEEE Trans. on Neural Networks, 16(3): Jiang, D., T., Tang, and Zhang, A. (2004). Cluster Analysis for Gene Expression Data: A Survey, IEEE Trans. on Knowledge and Data Engineering, 16(11).")
Apresentações semelhantes





 Marcílio C. P. de Souto DIMAp/UFRN.>")


>")










 Programa.>")
