Carregar apresentação
A apresentação está carregando. Por favor, espere

1
AGREGADOR AUTÔNOMO DE CONTEÚDO WEB
Rafael Marchioli Bernardes Wagner Ferreira dos Santos Júnior Wilson Massashiro Yonezawa

2
Objetivo Desenvolver um sistema computacional capaz de agregar informações de ofertas de compras coletivas através apenas da analise do código HTML/Javascript/CSS padrão web, agrupando-as de acordo com as caracteristicas da oferta apresentada.

3
Classificador Scraper BD

4
Crawler

5
Arquitetura do crawler

6
crawlers Crawler sequencial Seeds é qualquer lista de URLs
A ordem das paginas visitadas é definida pela arquitetura do frontier Criterio de parada pode ser qualquer.

7
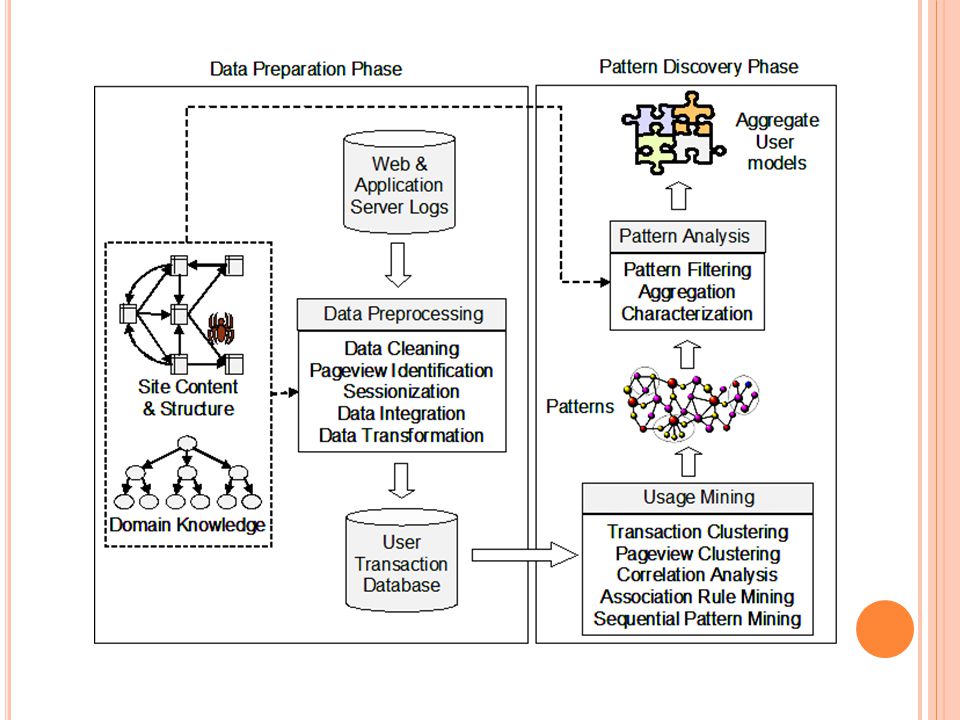
Data cleaning Data cleaning
Remove referências irrelevantes e campos nos logs. Remove referências criada pela navegação do crawler Remove referências erradas Adiciona referências perdidas devido a sessionization.

9
Classificador Integração XML. Criação de template manual.
Modelo de extração autonomo.

10
<?xml version="1.0" encoding="UTF-8"?>
<ofertas> <oferta> <id>ID da oferta</id> <cidade>Rio de Janeiro</cidade> <endereco>Endereço da oferta</endereco> <titulo>Título da oferta</titulo> <preco-real>Preço Real</preco-real> <preco-final>Preço Final</preco-final> <desconto>Desconto Porcentagem</desconto> <url-imagem>URL da imagem</url-imagem> <site>Nome do site da oferta</site> <link>URL da oferta</link> <data-inicio>Data de início da oferta</data-inicio> <data-fim>Data do término da oferta</data-fim> <categoria>Categoria da oferta</categoria> <numero-vendas>Número de ofertas vendidas</numero-vendas> </oferta> <id>...</id> <cidade>...</cidade>... ... </ofertas>

11
Manual Extensão Chrome.
Capaz de navegar o DOM e estrair um template da info selecionada. Armazena o template. Requesita o dado baseado no template.

12
Extração Autonoma Cada extração é feita utilizando-se 2 regras,
uma start rule e uma end rule. As regras de extração são baseadas em landmarks. Cada landmark é uma sequência tokens consecutivos. Landmarks são usados para localizar o inicio e o fim de cada item. Regras usam landmarks The start rule identifies the beginning of the node and the end rule identifies the end of the node. This strategy is applicable to both leaf nodes (which represent data items) and list nodes. For a list node, list iteration rules are needed to break the list into individual data records (tuple instances).
 and list nodes. For a list node, list iteration rules are needed to break the list into individual data records (tuple instances).")
13
Exemplo: “Good Noodles”. A regra R1 pode identificar o início:
R1: SkipTo(<b>) // start rule Com essa regra o sistema varre a pagina do início até encontrar a tag <b>, que é um landmark. Para identifcar o fim: R2: SkipTo(</b>) // end rule Let us try to extract the restaurant name “Good Noodles”. Rule R1 can to identify the beginning : R1: SkipTo(<b>) // start rule This rule means that the system should start from the beginning of the page and skip all the tokens until it sees the first <b> tag. <b> is a landmark. Similarly, to identify the end of the restaurant name, we use: R2: SkipTo(</b>)
 // start rule. Com essa regra o sistema varre a pagina do início até encontrar a tag <b>, que é um landmark. Para identifcar o fim: R2: SkipTo(</b>) // end rule. Let us try to extract the restaurant name Good Noodles . Rule R1 can to identify the beginning : R1: SkipTo(<b>) // start rule. This rule means that the system should start from the beginning of the page and skip all the tokens until it sees the first <b> tag. <b> is a landmark. Similarly, to identify the end of the restaurant name, we use: R2: SkipTo(</b>)")
14
Regras não são únicas Por exemplo, outras regras podem ser usadas para encontrar o início da palavra: R3: SkiptTo(Name _Punctuation_ _HtmlTag_) ou R4: SkiptTo(Name) SkipTo(<b>) R3 pula-ra tudo ate encontrar “Name” seguido por uma pontuação e uma tag HTML. Name _Punctuaion_ e _HtmlTag juntos formam um landmark.
 ou R4: SkiptTo(Name) SkipTo(<b>) R3 pula-ra tudo ate encontrar Name seguido por uma pontuação e uma tag HTML. Name _Punctuaion_ e _HtmlTag juntos formam um landmark.")
15
Regras de extração Como o Stalker(Modulo que compara os dados e cria os templates) aprende as regras para encontrar um item. Em cada iteração ele aprende uma regra que cobre o maior número de exemplos positivos sem ter nenhum exemplo negativo. Uma vez que um exemplo positivo é coberto por uma regra, este exemplo é removido. O algoritmo termina quando todos os exemplos positivos foram removidos e o resultado é uma lista com todas as regras aprendidas.

16
Parsing HTML tem uma estrutura de árvore DOM (Document Object Model)
HTML geralmente possui erros Crawlers, assim como browsers, devem ser robustos Mas existem ferramentas para ajudar E.g. tidy.sourceforge.net Cuidado com os diversos outros formatos Flash, SVG, RSS, AJAX…

17
FrontEnd

20
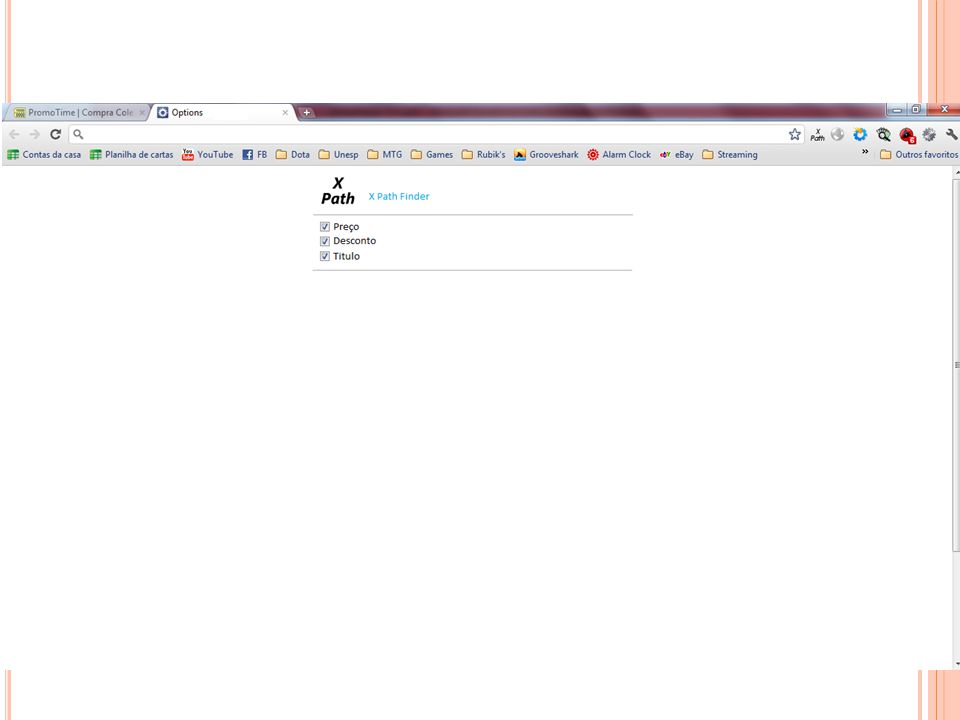
Aplicativo Chrome Possível seleção dos parâmetros a serem selecionados. Usuário seleciona na tela qual será a informação a ser gravada e em seguida seleciona na extensão onde grava-la Ao final exporta-se um arquivo contendo os caminhos que foram selecionados, tornando possível coleta-los automaticamente da próxima vez.

23
Bibliografia: YU, Liyang. A Developer’s guide to the Semantic Web. Springer 1st Edition., 2011 Web Semântica. Disponível em: < > Acesso em : 16 março 2011. SYCARA, Katia; PAOLUCCI, Massimo; ANKOLEKAR, Anupriya; SRINIVASAN, Naveen. Automated discovery, interaction and composition of Semantic Web services. Carnegie Mellon University, 18 julho 2003 BERNERS-LEE, Tim; HENDLER, James; LASSILA, Ora. The Semantic Web: A new form of Web content that is meaningful to computers will unleash a revolution of new possibilities, 17 Maio 2001 LIU, Bing. Web Data Mining Exploring Hyperlinks, Contests, and Usage Data. Springler-Verlag Berlin Heidelberg, 2007 WITTEN, Ian H.; FRANK, Eibe; HALL, Mark A..Data Mining:Practical Machine Learning tools and techniques, 2011

24
Fim

Apresentações semelhantes
















 Prof. Ismael H F Santos.>")




