Carregar apresentação
A apresentação está carregando. Por favor, espere

1
Identificação de elementos regulatórios usando Genômica Comparativa e Phylogenetic Footprinting
Raonne Barbosa Vargas

2
Introdução Motivação O ser humano possui uma sequência de DNA única, presente em todas as células de seu organismo. Nos últimos anos, após esta sequência de nucleotídeos ter sido completamente descoberta e os genes definidos nelas serem anotados, a comunidade que estuda a Biologia Molecular passou a enfrentar um novo desafio: como esta mesma sequência de genes pode definir todos os diferentes tipos de células que temos? A resposta está nos fatores que controlam a expressão desses genes, o estudo de um processo chamado de regulação gênica.

3
Introdução Proteínas chamadas de fatores de transcrição ligam-se à sequência de DNA em posições específicas chamadas de locais de amarração dos fatores de transcrição (TFBS’s), para regular a expressão de um determinado gene, ativando ou inibindo os mecanismos da transcrição. Os locais de amarração funcionais são por isso chamados de elementos regulatórios. A regulação gênica ainda é uma área de estudo muito complexa e seu completo entendimento ainda é considerado uma esperança distante, que irá requerer muitos esforços, inclusive com uma imprescindível ajuda da Computação, tanto pela capacidade de processamento de enormes quantidades de dados, mas também pela necessidade de avançados Algoritmos indispensáveis na solução de alguns problemas.
, para regular a expressão de um determinado gene, ativando ou inibindo os mecanismos da transcrição. Os locais de amarração funcionais são por isso chamados de elementos regulatórios. A regulação gênica ainda é uma área de estudo muito complexa e seu completo entendimento ainda é considerado uma esperança distante, que irá requerer muitos esforços, inclusive com uma imprescindível ajuda da Computação, tanto pela capacidade de processamento de enormes quantidades de dados, mas também pela necessidade de avançados Algoritmos indispensáveis na solução de alguns problemas.")
4
Figura 1 – Elemento Regulatório
Introdução Figura 1 – Elemento Regulatório

5
Objetivo O objetivo desta pesquisa é tentar identificar elementos regulatórios de genes humanos. Utilizando métodos computacionais podemos tentar predizer a localização exata de elementos regulatórios de genes humanos, o que representa um enorme avanço no entendimento da regulação gênica e facilita incrivelmente o trabalho de biólogos na anotação experimental dos elementos regulatórios. Os elementos regulatórios podem ser geralmente encontrados na região imediatamente anterior ao início de um gene, ou até nos primeiros pares de base do mesmo. A sequência de nucleotídeos nesta região será chamada de sequência promotora.

6
Objetivo Figura 2 – Definindo uma sequência promotora, onde serão procurados os elementos regulatórios.

7
Phylogenetic Footprinting
Para conseguir encontrar estes elementos regulatórios esta pesquisa baseia-se em uma teoria chamada de Phylogenetic Footprinting, cuja tradução seria “impressão de pegadas filogenéticas”. Esta teoria considera que mutações em regiões funcionais de genes se acumulariam mais lentamente do que em regiões não-funcionais, pois estariam sob pressão evolutiva. Desta forma, elementos regulatórios evoluem a uma taxa mais baixa do que as demais sequências não-funcionais ao seu redor. Por isso, é esperado que elementos regulatórios estejam mais conservados nas sequências de DNA de espécies consideradas próximas na árvore de evolução filogenética.

8
Phylogenetic Footprinting
Desta forma Phylogenetic Footprinting propõe um processo para se identificar possíveis elementos regulatórios, que baseia-se na comparação de sequências genômicas. Primeiro é necessário definir que genes ortólogos são genes similares em espécies distintas que descendem de um antecessor comum. Se um gene humano possui um gene ortólogo no chimpanzé, por exemplo, então é de se esperar que os elementos regulatórios destes genes estejam bem conservados em ambas as espécies. Assim podemos definir o processo em 2 etapas:

9
Phylogenetic Footprinting
No primeiro passo é necessário identificar se o gene a ser estudado possui ortólogos nas espécies sendo consideradas. Então obtém-se as sequências promotoras de cada gene ortólogo. No segundo passo as sequências promotoras devem ser analisadas em busca de pequenas sub-sequências que estejam bem conservadas em todas elas. Estas sub-sequências bem conservadas são chamadas de motifs. Esses motifs representarão excelentes candidatos a elementos regulatórios.

10
Genômica Comparativa Para analisar as sequências promotoras e extrair delas os motifs, utiliza-se um algoritmo de alinhamento múltiplo. Após a obtenção dos motifs, será utilizado também um algoritmo de agrupamento para agrupar motifs semelhantes, que podem ser variações de um mesmo elemento regulatório. Os grupos obtidos são finalmente comparados a TFBS’s anotados na base de dados TRANSFAC, na última etapa desta pesquisa.

11
Algoritmo Aqui procuramos resumir a solução proposta nesta pesquisa em um simples algoritmo que resume cada etapa do processo, que serão uma por uma analisadas em detalhes em seguida. Entrada: Lista de genes a serem analisados. Em todos os casos de estudo desta pesquisa teremos os genes humanos anotados no genoma humano no NCBI* e incluídos na base de dados HomoloGene*. Conjunto de espécies a serem consideradas na comparação genômica proposta por Phylogenetic Footprinting. * NCBI e HomoloGene serão apresentados em detalhes posteriormente.

12
Algoritmo ALGORITMO: Para cada gene na lista de entrada:
Pesquise em HomoloGene para identificar os genes ortólogos a este gene. Se este gene possui ortólogos para todas as espécies consideradas no conjunto de espécies da entrada: Para cada gene ortólogo: Pesquise em Entrez Gene para obter a localizaçãodo gene na sequência genômica de sua espécie. Pesquise em Entrez Nucleotide para obter a sequência promotora deste gene. Compute o Alinhamento Múltiplo das sequências promotoras. Extraia do alinhamento os motifs bem conservados. Compute o agrupamento dos motifs. Compare com a base de dados TRANSFAC.

13
Algoritmo Saída: Lista de motifs encontrados, especificando sua localização exata no cromossomo e o gene que ele regula. Lista dos Grupos, com os motifs de cada um deles. Lista de casamentos relevantes encontrados com TFBS’s anotados no TRANSFAC.

14
Casos de Estudo Humano / Chimpanzé / Camundongo / Rato
Humano / Chimpanzé / Camundongo / Rato / Cachorro Humano / Chimpanzé / Camundongo / Rato / Galinha Humano / Chimpanzé / Camundongo / Rato / Cachorro / Galinha Humano / Chimpanzé / Camundongo / Rato / Mosca

15
Dados Biológicos NCBI O National Center for Biotechnology Information (NCBI) é uma fonte de informação para biologia molecular que inclui a criação de bancos de dados públicos, condução de pesquisas em biologia computacional, desenvolvimento de ferramentas para analisar dados genômicos, e a disseminação de informações biomédicas. NCBI: Para manter a consistência de todas as informações e das relações entre elas, todos os dados biológicos requeridos para o desenvolvimento da solução desta pesquisa foram extraídos de bancos de dados do NCBI.
 é uma fonte de informação para biologia molecular que inclui a criação de bancos de dados públicos, condução de pesquisas em biologia computacional, desenvolvimento de ferramentas para analisar dados genômicos, e a disseminação de informações biomédicas. NCBI: Para manter a consistência de todas as informações e das relações entre elas, todos os dados biológicos requeridos para o desenvolvimento da solução desta pesquisa foram extraídos de bancos de dados do NCBI.")
16
Figura 3 - NCBI

17
Dados Biológicos HomoloGene – Genes Ortólogos
Para identificação de genes ortólogos esta pesquisa utiliza o banco de dados chamado HomoloGene, um sistema de detecção automática de homólogos entre genes anotados em diversos genomas eucarióticos completamente sequenciados. HomoloGene: Os conjuntos de espécies utilizados nesta pesquisa foram restringidos principalmente por essa base de dados, como pode ser visto na tabela na página inicial do HomoloGene (figura 4).
.")
18
Figura 4 - HomoloGene

19
Dados Biológicos Exemplo de pesquisa no HomoloGene:
Consideremos então o gene ING5, que tem a função de inibidor de crescimento, e possui um número de identificação no NCBI (id) igual a Se estivermos interessados em verificar se este gene possui ortólogos para por exemplo humano, chimpanzé, camundongo e rato, podemos pesquisá-lo no HomoloGene e obter essa infomação. Podemos verificar na Figura 5 que o ING5 possui sim ortólogos para as espécies consideradas nesse exemplo. Desta forma, obtemos do HomoloGene os id’s dos genes ortólogos e partimos para investigar cada um desses genes para obter suas sequências promotoras.
 igual a Se estivermos interessados em verificar se este gene possui ortólogos para por exemplo humano, chimpanzé, camundongo e rato, podemos pesquisá-lo no HomoloGene e obter essa infomação. Podemos verificar na Figura 5 que o ING5 possui sim ortólogos para as espécies consideradas nesse exemplo. Desta forma, obtemos do HomoloGene os id’s dos genes ortólogos e partimos para investigar cada um desses genes para obter suas sequências promotoras.")
20
Figura 5 – Pesquisa no HomoloGene

21
Dados Biológicos Entrez Gene – Informação sobre os genes
Entrez Gene é um banco de dados para busca de genes que contém diversas informações sobre eles, como tipo, nome, descrição, organismo, e muito mais. Entre Gene: Nesta pesquisa Entrez Gene será utilizado para identificação da localização de cada gene ortólogo, para que o posicionamento de sua sequência promotora seja estipulado.

22
Figura 6 – Entrez Gene

23
Dados Biológicos Continuando o exemplo com ING5, a figura 7 mostra o resultado da busca deste gene no Entrez Gene, com todas as informações deste gene. A localização do gene é exibida na seção “Genomic Regions”, contendo o id de seu cromosomo (NC_ ) e a sua localização no mesmo, tendo início na posição e terminando em
 e a sua localização no mesmo, tendo início na posição e terminando em")
24
Figura 7 – Pesquisa no Entrez Gene

25
Dados Biológicos Entrez Nucleotide – Sequências Promotoras
Como foi mostrado anteriormente, nesta pesquisa as sequências promotoras são definidas com sendo a partir de 1000 pares de base antes da posição de início do gene, até 200 pares de base após o início do gene. promoter_start = gene_start – 1000 promoter_end = gene_start + 200 Possuindo então o id do cromosomo e as posições de início e fim da sequência, basta realizar uma simples busca na base de dados Entrez Nucleotide para obter a sequência de nucleotídeos desejada.

26
Figura 8 - Entrez Nucleotide - contém sequências de nucleotídeos de diversos genomas.

27
Dados Biológicos Para exemplificar um busca no Entrez Nucleotide, vamos novamente considerar o gene ING5, o qual já sabemos está situado no cromosomo de id NC_ e possui posicição de início igual a Desta forma sabemos que a sequência promotora se inicia na posição e vai até A figura 9 mostra o resultado da busca dessa sequência no Entrez Nucleotide, no formato FASTA.

28
Figura 9 – Pesquisa no Entrez Nucleotide

29
Alinhamento Múltiplo Alinhamento Múltiplo de strings é um problema NP-Hard e por isso seu processamento pode demandar um quantidade de tempo a cima do aceitável. O algoritmo utilizado para realizar o alinhamento múltiplo consiste em uma extensão do alinhamento global dois a dois proposto por Needleman e Wunsch, que segue uma estratégia de programação dinâmica. Todos os pares de sequência são alinhados separadamente, uma matriz de distâncias é calculada e utilizada na montagem progressiva do alinhamento múltiplo.

30
Alinhamento Múltiplo Existem hoje diversas ferramentas computacionais para a computação de um alinhamento múltiplo, como por exemplo: CLUSTALW, MAVID, MLAGAN, DIALIGN, TBA e FootPrinter. A ferramenta escolhida para nos auxiliar nesta tarefa foi o CLUSTALW, por ser uma das mais famosas e mais comumente utilizadas. Além disso, CLUSTALW é uma versão de linha de comando de CLUSTALX para UNIX, e é totalmente integrada à biblioteca BioPython. Detalhes sobre programação virão posteriormente. CLUSTALW oferece uma alternativa para o alinhamento 2 a 2, permitindo que seja utilizada um heurística mais rápida porém menos precisa. Entretanto, nesta pesquisa esta alternativa não foi utilizada, sendo mantido o processo de programação dinâmica visando resultados de melhor qualidade.

31
Figura 10 – Exemplo de Alinhamento Múltiplo

32
Alinhamento Múltiplo Identificação de Motifs
Uma vez que foi processado o alinhamento múltiplo, é necessário extrair deles os motifs bem conservados. Seguindo várias referências na literatura científica, foi definido que procuraríamos motifs de tamanho 10. Requere-se então que uma sub-sequência de tamanho 10 possua um casamento perfeito entre todas as espécies em pelo menos 9 dos 10 nucleotídeos. Veja os exemplos a seguir.

33
Figura 11 – Motif com 10 casamentos perfeitos

34
Figura 12 – Motif com 9 casamentos perfeitos

35
Figura 13 – Sub-sequência com 9 casamentos perfeitos e 2 imperfeitos – não é um motif

36
Alinhamento Múltiplo Os motifs identificados são anotados e salvos em arquivo. As posições onde ocorre casamento imperfeito são completadas com gaps (-). A figura 14 mostra o arquivo contendo os motifs encontrados no estudo que incluia as espécies humano / chimpanzé / camundongo / rato / mosca. Para cada motif é indicado sua sequência, id do gene, espécie, id do cromosomo, posição de início do gene, posição de término do gene e posição de início do motif.
. A figura 14 mostra o arquivo contendo os motifs encontrados no estudo que incluia as espécies humano / chimpanzé / camundongo / rato / mosca. Para cada motif é indicado sua sequência, id do gene, espécie, id do cromosomo, posição de início do gene, posição de término do gene e posição de início do motif.")
37
Alinhamento Múltiplo Figura 14 – Motifs encontrados no estudo humano/chimpanzé/camundongo/rato/mosca

38
Agrupamento Introdução
Uma vez terminada a estratégia de Phylogenetic Footprinting e tendo sido encontrados os motifs que representam excelentes candidatos a elementos regulatórios, agora nós passamos a analisar esses motifs. O objetivo de agrupar os motifs é poder juntar aqueles motifs que possuem alto grau de similaridade, pois estes podem ser variações de um mesmo elemento regulatório, ou serem alvo de um mesmo fator de transcrição, ou compartilhar alguma outra similaridade funcional. O método de agrupamento utilizado foi bem restritivo, de forma a manter um alto grau de similaridade entre os motifs de um mesmo grupo, mesmo que obtendo um grande número de grupos com apenas 1 elemento. Posteriormente serão levados em consideração apenas os grupos com mais de 1 motif, e estes serão comparados com TRANSFAC.

39
Agrupamento Algoritmo K-Means
O algoritmo de agrupamento utilizado foi o K-Means, um dos mais populares algoritmos iterativos de agrupamento. Este algoritmo é aleatório e baseia-se na heurística de Loyd. O número de grupos (K) deve ser definido previamente. Os motifs são designados aleatoriamente para os K grupos. Um vetor de expressão média (ou centróide) de cada grupo é computado. Cada motif é movido para o grupo mais próximo (do qual mais se assemelha ao centróide) e os centróides são recalculados. O processo se repete até que nenhum motif possa ser movido para outro grupo.
 deve ser definido previamente. Os motifs são designados aleatoriamente para os K grupos. Um vetor de expressão média (ou centróide) de cada grupo é computado. Cada motif é movido para o grupo mais próximo (do qual mais se assemelha ao centróide) e os centróides são recalculados. O processo se repete até que nenhum motif possa ser movido para outro grupo.")
40
Agrupamento Algoritmo K-Means
Dependendo do posicionamento inicial que é aleatório, o K-Means pode converter para um mínimo local ou às vezes até não converter. Para evitar um loop infinito, a programação finaliza o processo quando detecta o mesmo agrupamento aparecendo novamente periodicamente. Além disso, para cada valor de K testado o algoritmo foi executado 3 vezes, com mudança na semente aleatória, e o melhor agrupamento foi escolhido, tentando assim fugir de mínimos locais. Na busca pelo melhor agrupamento, vários valores para o número de grupos K foram testados de acordo com a estratégia apresentada a seguir.

41
Agrupamento Número “K” de grupos
Para definir o número de grupos foram levadas em consideração duas ponderações. A primeira diz respeito ao fato de que estamos interessados em grupos com alta similaridade entre os seus elementos, mesmo que tenhamos muitos grupos unitários. Desta forma foi definido que seriam testados 100 valores diferentes de K entre 70% e 90% do número de motifs. Por exemplo, no estudo humano/chimpanzé/camundongo/rato/cachorro/galinha tínhamos 715 motifs. Testamos valores de K entre 500 e 642. No estudo incluindo humano/chimpanzé/camundongo/rato/mosca nós tínhamos apenas 13 motifs para agrupar, o que nos possibilitava testar todos os 13 diferentes valores de K sem problemas.

42
Agrupamento Número “K” de grupos
A segunda ponderação baseia-se num conceito estatístico que afirma o seguinte: O índice W que buscamos minimizar, no nosso caso a soma das distâncias dos elementos dentro dos grupos (within-cluster sum of distances), vai diminuindo ao passo que aumentamos o número de grupos K. Para um número de grupos igual ao número de motifs, teremos W=0 e um motif em cada grupo. Enquanto aumentamos o valor de K, a diminuição do valor de W torna-se cada vez mais lenta. Desta forma, o valor ideal de K pode ser determinado quando a variação do valor de W para valores diferentes de K se tornar menor que um determinado limite desejado. Veja o exemplo da tabela a seguir, com os valores de K e W computados para o estudo humano/chimpanzé/camundongo/rato/cachorro/galinha.
, vai diminuindo ao passo que aumentamos o número de grupos K. Para um número de grupos igual ao número de motifs, teremos W=0 e um motif em cada grupo. Enquanto aumentamos o valor de K, a diminuição do valor de W torna-se cada vez mais lenta. Desta forma, o valor ideal de K pode ser determinado quando a variação do valor de W para valores diferentes de K se tornar menor que um determinado limite desejado. Veja o exemplo da tabela a seguir, com os valores de K e W computados para o estudo humano/chimpanzé/camundongo/rato/cachorro/galinha.")
44
Agrupamento Número “K” de grupos
A estratégia adotada então foi verificar a variação do valor de W entre cada 5 agrupamentos consecutivos. Quando esta variação fosse menor que um determinado limite, o valor de K era escolhido. Este limite da variação era diferente de acordo com o número de motifs e grupos em cada estudo. Na tabela anterior o limite era de uma diferença de no máximo 100 unidades entre cada 5 agrupamentos. A tabela a seguir mostra a mesma análise para os 13 agrupamentos de humano/chimpanzé/camundongo/rato/mosca, porém neste caso o limite da variação de W foi imposto para cada 3 agrupamentos.

45
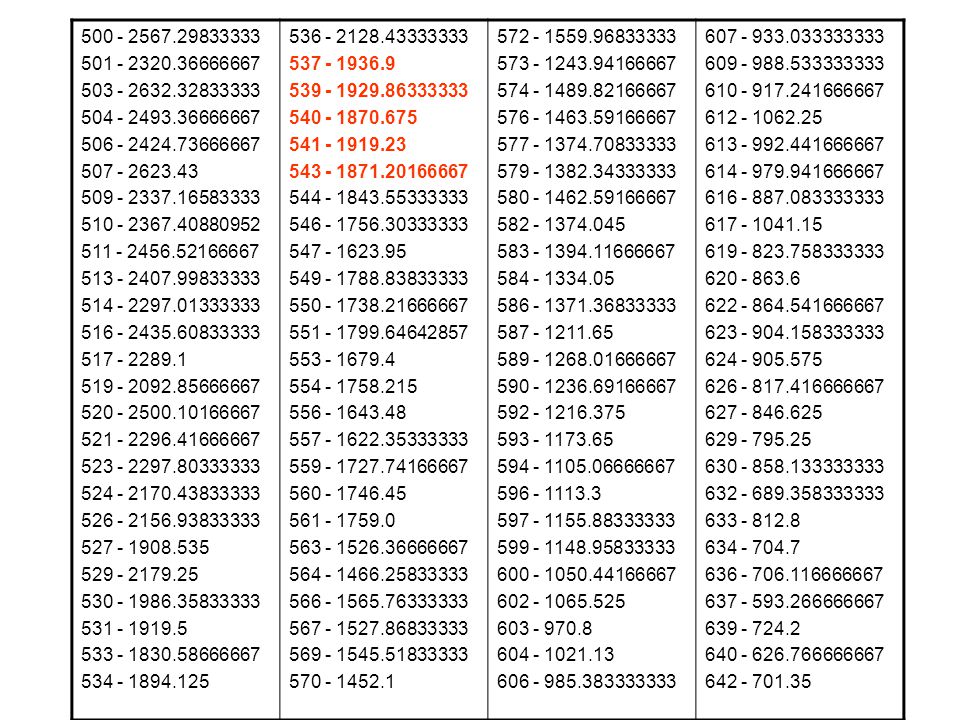
Agrupamento K W 1 2 3 4 5 6 7 8 9 10 11 12 13 417.9

46
Agrupamento Desta forma o agrupamento foi computado, e para cada caso de estudo foi gravado em arquivo, contendo os motifs de cada grupo com todas as informações de cada um: a sequência do motif, o id do gene, a espécie, o id do cromosomo, a posição de início e fim do gene e a posição de início do motif. A figura a seguir mostra parte do arquivo com o agrupamento para o estudo humano/chimpanzé/camundongo/rato/cachorro/galinha, com as informações de alguns dos grupos.

47
Figura 15 – Exemplo de Agrupamento

48
TRANSFAC Figura TRANSFAC

49
TRANSFAC Os TFBS’s anotados em TRANSFAC serão usados para que possamos identificar motifs descobertos que são elementos regulatórios já conhecidos, determinar outros motifs que possam ter semelhanças a algum elemento regulatório conhecido, e também isolar motifs encontrados que podem ser elementos regulatórios novos, ainda não descobertos. Desta forma calculamos a sequência de consenso para cada grupo, e comparamos cada uma a todos os 1388 elementos regulatórios de humanos anotados no TRANSFAC, em busca de casamentos (matches) relevantes.
 relevantes.")
50
TRANSFAC Sequência de Consenso de um Grupo
Alinhados os motifs de um grupo, para cada coluna é assinalado um nucleotídeo se este estivesse presente naquela coluna em mais de 50% dos motifs e aparecesse um número de vezes maior ou igual a duas vezes todos os outros nucleotídeos somados. Se nenhum nucleotídeo cumprisse esse pré-requisito a coluna era completada com um gap(-). Veja um exemplo de um grupo do estudo humano/chimpanzé/camundongo/rato: CLUSTER 13576: CCAGACACT H.sapiens NC_ AAAGAACAT H.sapiens NC_ AAAGACACT H.sapiens NC_ AAAGACACT => Sequência de Consenso do grupo 13576
. Veja um exemplo de um grupo do estudo humano/chimpanzé/camundongo/rato: CLUSTER 13576: CCAGACACT H.sapiens NC_ AAAGAACAT H.sapiens NC_ AAAGACACT H.sapiens NC_ AAAGACACT => Sequência de Consenso do grupo")
51
TRANSFAC Casamentos relevantes
Para determinar os casamentos relevantes entre grupos e motifs do TRANSFAC, a sequência de consenso de cada grupo era alinhada a cada motif deste banco de dados. Um casamento entre um grupo e um motif anotado era considerado se houvesse entre estes um alinhamento local sem gaps de tamanho pelo menos 5. Vamos seguir o exemplo de outro grupo do estudo humano / chimpanzé / camundongo / rato :

52
TRANSFAC CLUSTER 13534: ATCCCTCCTC 1956 H.sapiens NC_ CTCCCTCCTC H.sapiens NC_ - TCCCTCCTC => Sequência de Consenso do grupo 13534 Após a comparação com TRANSFAC, foi detectado um casamento relevante da sequência de consenso deste grupo com o motif anotado no TRANSFAC que possui número de identificação (accession number) R00377. -TCCCTCCTC (sequência de consenso do grupo 13534) ATCCCTCCTC (motif do transfac com id R00377) TCCCTCCTC (casamento)
 R TCCCTCCTC (sequência de consenso do grupo 13534) ATCCCTCCTC (motif do transfac com id R00377) TCCCTCCTC (casamento)")
53
Figura 17 – Elemento regulatório anotado no TRANSFAC (R00377)
")
54
Figura 18 – Gene do grupo 13534 (id 1956)
TRANSFAC Figura 18 – Gene do grupo (id 1956)
")
55
TRANSFAC Assim podemos perceber que o motif identificado pelo nosso sistema é exatamente o mesmo anotado no TRANSFAC. Exemplos como este mostram que a solução é capaz de alcançar seu objetivo, predizendo elementos regulatórios que já foram realmente comprovados experimentalmente. A seguir temos mais exemplos do estudo humano / chimpanzé / camundongo / rato.

56
GENE MOTIF EGFR (epidermal growth factor receptor); G000251
EGFR epidermal growth factor receptor (erythroblastic leukemia viral (v-erb-b) oncogene homolog, avian) (id 1956) LOC339287 - hypothetical protein LOC (id ) ATCCCTCCTC (R00377) ATCCCTCCTC (Cluster 13534) CTCCCTCCTC (Cluster 13534)
 oncogene homolog, avian) (id 1956) LOC hypothetical protein LOC (id ) ATCCCTCCTC (R00377) ATCCCTCCTC (Cluster 13534) CTCCCTCCTC (Cluster 13534)")
57
GENE MOTIF DBH (dopamine beta hydroxylase); G002007
DBH dopamine beta-hydroxylase (id 1621) OR52K2 olfactory receptor, family 52, subfamily K, member 2 (id ) GTCCATGTGT (R09521) GA-GTCCATG (Cluster 17159) GC-CTCCATG (Cluster 17159)
 OR52K2 olfactory receptor, family 52, subfamily K, member 2 (id ) GTCCATGTGT (R09521) GA-GTCCATG (Cluster 17159) GC-CTCCATG (Cluster 17159)")
58
GENE MOTIF G-CSF (granulocyte colony-stimulating factor); G000260
G-CSF (or CSF3) colony stimulating factor 3 (granulocyte) (id 1440) AMHR2 anti-Mullerian hormone receptor, type II (id 269) C9orf58 chromosome 9 open reading frame 58 (id 83543) GAGATTCCAC (R02683) TTCCCAGCTA (Cluster 21242) TTCCAAGGTC (Cluster 21242) TTCCAAGGTA (Cluster 21242)
 colony stimulating factor 3 (granulocyte) (id 1440) AMHR2 anti-Mullerian hormone receptor, type II (id 269) C9orf58 chromosome 9 open reading frame 58 (id 83543) GAGATTCCAC (R02683) TTCCCAGCTA (Cluster 21242) TTCCAAGGTC (Cluster 21242) TTCCAAGGTA (Cluster 21242)")
59
GENE MOTIF SI (sucrase-isomaltase); G000385
SI sucrase-isomaltase (alpha-glucosidase) (id 6476) CPA2 carboxypeptidase A2 (pancreatic) (id 1358) ITGB1BP2 integrin beta 1 binding protein (melusin) 2 (id 26548) GGTGCAATAAAACTTTATGAGTA (R04239) TTTATT-TCT (Cluster 22280) TTTGTT-TCT (Cluster 22280) TTTAGT-TAT (Cluster 22280)
 (id 6476) CPA2 carboxypeptidase A2 (pancreatic) (id 1358) ITGB1BP2 integrin beta 1 binding protein (melusin) 2 (id 26548) GGTGCAATAAAACTTTATGAGTA (R04239) TTTATT-TCT (Cluster 22280) TTTGTT-TCT (Cluster 22280) TTTAGT-TAT (Cluster 22280)")
60
GENE MOTIF H4 (histone 4 pHu4A gene); G000295
H4 (or HRH4) histamine receptor H4 (id 59340) NR1D1 nuclear receptor subfamily 1, group D, member 1 (id 9572) GGTTTTCAATCTGGTCCG(R00687) TGTTTTGAGT (Cluster 41063) TGTTTTGGGT (Cluster 41063)
 histamine receptor H4 (id 59340) NR1D1 nuclear receptor subfamily 1, group D, member 1 (id 9572) GGTTTTCAATCTGGTCCG(R00687) TGTTTTGAGT (Cluster 41063) TGTTTTGGGT (Cluster 41063)")
61
TRANSFAC Obervações Como dito anteriormente, os motifs diferentes do motif de TRANSFAC com o qual seu grupo se casa podem possuir semelhanças com o mesmo, como ser variação de um mesmo elemento regulatório, compartilhar um mesmo fator de transcrição ou alguma outra similaridade funcional. Isso vale tanto para grupos que continham o mesmo motif do TRANSFAC ao qual se casaram quanto para aqueles que não o contém. Identificar se o gene do motif descoberto é o mesmo gene do motif anotado no TRANSFAC é uma tarefa impossível de se automatizar, tendo em vista que além de id’s obviamente diferentes, os genes também muitas vezes possuem nomes e ‘alias’ diferentes nas duas bases de dados (TRANSFAC x NCBI).
.")
62
Resultados Humano / Chimpanzé / Camundongo / Rato
Número inicial de genes humanos: genes Número de genes com ortólogos nas 4 espécies: genes Número de motifs identificados: motifs Número de grupos: K = grupos Wmax – Wmin <= 400 Número de grupos com pelo menos 2 motifs: 8329 grupos Número de grupos com casamento relevante com TRANSFAC: 4498 grupos

63
Resultados Humano / Chimpanzé / Camundongo / Rato / Cachorro
Número inicial de genes humanos: genes Número de genes com ortólogos nas 4 espécies: 9494 genes Número de motifs identificados: motifs Número de grupos: K = 7921 grupos Wmax – Wmin <= 200 Número de grupos com pelo menos 2 motifs: 2329 grupos Número de grupos com casamento relevante com TRANSFAC: 867 grupos

64
Resultados Humano / Chimpanzé / Camundongo / Rato / Galinha
Número inicial de genes humanos: genes Número de genes com ortólogos nas 4 espécies: 6974 genes Número de motifs identificados: 1268 motifs Número de grupos: K = 968 grupos Wmax – Wmin <= 100 Número de grupos com pelo menos 2 motifs: 238 grupos Número de grupos com casamento relevante com TRANSFAC: 56 grupos

65
Resultados Humano / Chimpanzé / Camundongo / Rato / Cachorro / Galinha
Número inicial de genes humanos: genes Número de genes com ortólogos nas 4 espécies: 6382 genes Número de motifs identificados: 715 motifs Número de grupos: K = 537 grupos Wmax – Wmin <= 100 Número de grupos com pelo menos 2 motifs: 141 grupos Número de grupos com casamento relevante com TRANSFAC: 26 grupos

66
Resultados Humano / Chimpanzé / Camundongo / Rato / Mosca
Número inicial de genes humanos: genes Número de genes com ortólogos nas 4 espécies: 3444 genes Número de motifs identificados: 13 motifs Número de grupos: K = 8 grupos Wmax – Wmin <= 100 Número de grupos com pelo menos 2 motifs: 4 grupos Número de grupos com casamento relevante com TRANSFAC: 1 grupos

67
Resultados Humano / Chimpanzé / Camundongo / Rato / Mosca
Neste estudo, o grupo que possui um casamento relevante com TRANSFAC foi o grupo 0. CLUSTER 0: ATTTATT-TG 1506 H.sapiens NC_ GTGTGTG-GT 5459 H.sapiens NC_ GGTTATG-AA 8834 H.sapiens NC_ GTTTATG => Sequência de consenso A tabela a seguir lista os genes de cada um desses motifs e também o de alguns dos motifs do TRANSFAC com casamento relevante.

68
GENE MOTIF CTRL chymotrypsin-like (id 1506)
POU4F3 POU domain, class 4, transcription factor 3 (id 5459) TMEM11 transmembrane protein 11 (id 8834) B-ACT (beta-actin); G000214 TCR-delta (T-cell receptor delta); G apoB (apolipoprotein B); G000205 GCC (guanylyl cyclase C); G001742 ATTTATT-TG (Cluster 0) GTGTGTG-GT (Cluster 0) GGTTATG-AA (Cluster 0) CCTTTTATGG (R00040) AAATAAACAAGGAGATAGGGTGTTTATTT (R01429) GCATTTATGAGCTG (R04012) GTTTATAGCTCTGACCT (R08886)
 TMEM11 transmembrane protein 11 (id 8834) B-ACT (beta-actin); G TCR-delta (T-cell receptor delta); G apoB (apolipoprotein B); G GCC (guanylyl cyclase C); G ATTTATT-TG (Cluster 0) GTGTGTG-GT (Cluster 0) GGTTATG-AA (Cluster 0) CCTTTTATGG (R00040) AAATAAACAAGGAGATAGGGTGTTTATTT (R01429) GCATTTATGAGCTG (R04012) GTTTATAGCTCTGACCT (R08886)")
69
Conclusões Humano/Chimpanzé/ Camundongo/Rato
ESTUDO Genes com ortólogos Motifs Grupos Grupos com mais de 1 motif Grupos com casamento relevante no TRANSFAC Humano/Chimpanzé/ Camundongo/Rato 10738 66903 57536 8329 4498 Humano/Chimpanzé/ Camundongo/Rato/ Cachorro 9494 11002 7921 2329 867 Humano/Chimpanzé/ Camundongo/Rato/ Galinha 6974 1268 968 238 56 Humano/Chimpanzé/ Camundongo/Rato/ Cachorro/Galinha 6382 715 537 141 26 Humano/Chimpanzé/ Camundongo/Rato/Mosca 3444 13 8 4 1

70
Conclusões Nesta pesquisa desenvolveu-se uma solução que baseou-se em Phylogenetic Footprinting para identificar elementos regulatórios de genes humanos, considerando a conservação evolucionária dos mesmos e seus posicionamentos na região próxima ao início dos genes. Alguns motifs identificados representam elementos regulatórios já conhecidos, enquanto outros podem ser novos ainda não descobertos experimentalmente. Todos os resultados obtidos (lista de motifs, grupos e casamentos com Transfac) para cada um dos 5 estudos conduzidos nesta pesquisa estarão disponíveis na web.
 para cada um dos 5 estudos conduzidos nesta pesquisa estarão disponíveis na web.")
71
Conclusões Um aprimoramento no conhecimento de homologia entre genes, como por exemplo a inclusão de mais espécies na base de dados HomoloGene, permitirá um aperfeiçoamento na qualidade dos resultados de pesquisas como esta, aumentando as capacidades das técnicas de genômica comparativa. Futuramente esta pesquisa pode ser melhorada com a inclusão de um filtro deixando passar apenas os genes ortólogos que possuírem locais de início da transcrição também ortólogos. Outro contexto que pode ser explorado é o de que genes geralmente possuem vários elementos regulatórios em sua região promotora. Desta forma poderíamos analisar os motifs identificados e separar aqueles que aparecem em conjunto com outros para o mesmo gene, e eliminar aqueles que aparecem isolados para um determinado gene.

72
Apêndice I - Programação
A solução proposta nesta pesquisa foi inteiramente automatizada, sendo utilizada a linguagem de programação Python. A biblioteca BioPython foi utilizada para permitir ao sistema o acesso aos bancos de dados do NCBI. A ferramenta CLUSTALW, versão de linha de comando para UNIX do CLUSTALX, foi utilizada no processamento do alinhamento múltiplo. Esta ferramenta é totalmente integrada à biblioteca BioPython. A biblioteca “The C Clustering Library” foi utilizada para auxiliar o processamento dos agrupamentos se aproveitando da eficiência da linguagem C.

73
Esta apresentação foi parte do Projeto Final de Graduação de
Raonne Barbosa Vargas, para obtenção do grau de Bacharel em Ciência da Computação Departamento de Informática Universidade Federal do Espírito Santo

Apresentações semelhantes



>")















