Carregar apresentação
A apresentação está carregando. Por favor, espere

1
Oracle Text 11G: Uma Introdução
Cláudio de Souza Baptista Agosto/2007

2
Roteiro Introdução: Características básicas Arquitetura Índices
Operadores Serviços de documentos Classificação Exemplo de uma aplicação Conclusão

3
Oracle Text - Características
Integrado ao SGBD: usa SQL reusa os serviços providos pelo SGBD Pode indexar documentos armazenados no SGBD, file system ou Web Pode realizar análise linguística, faz busca por: keywords, contexto, operações booleanas, temáticas, casamento de padrões, HTML e XML

4
Oracle Text - Características
Usa vários formatos: Word, PDF, Excel, HTML, XML, etc Multilíngue

5
Arquitetura

6
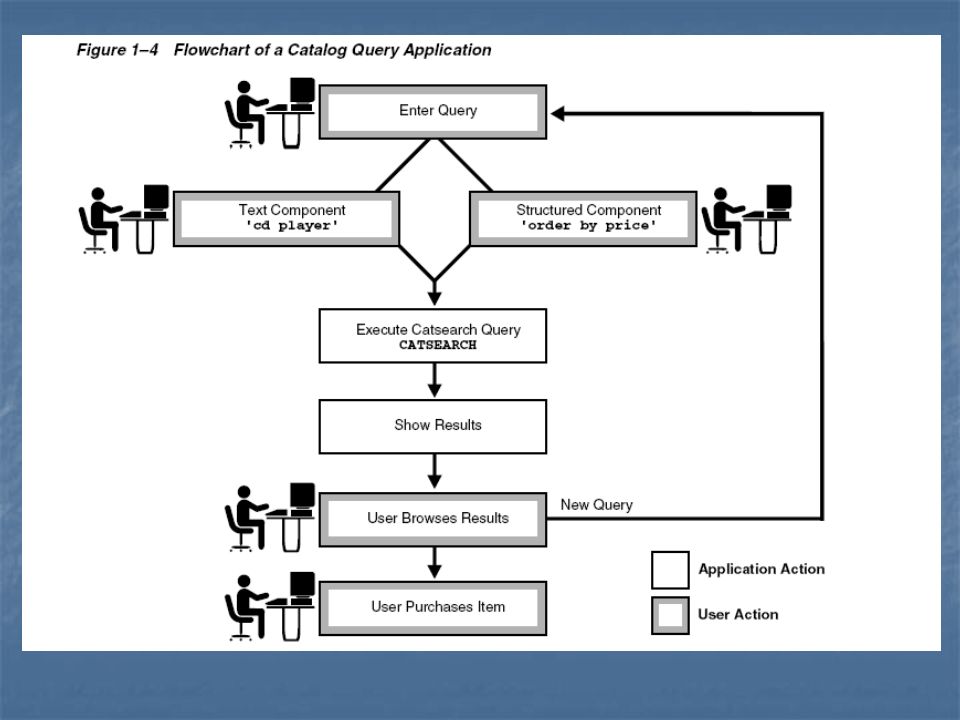
Tipos de Índices Há três tipos:
Standard index type (CONTEXT): usado para coleção de documentos coesos. Operador: CONTAINS Catalog index type (CTXCAT): usado para indexar pequenos trechos de texto em colunas. Operador: CATSEARCH Classification index type (CTXRULE): permite criar uma aplicação de classificação de documentos. Operador MATCHES
: usado para coleção de documentos coesos. Operador: CONTAINS. Catalog index type (CTXCAT): usado para indexar pequenos trechos de texto em colunas. Operador: CATSEARCH. Classification index type (CTXRULE): permite criar uma aplicação de classificação de documentos. Operador MATCHES.")
7
Tipos de Índices

11
Score “To calculate a relevance score for a returned document in a word query, Oracle uses an inverse frequency algorithm based on Salton's formula. Inverse frequency scoring assumes that frequently occurring terms in a document set are noise terms, and so these terms are scored lower. For a document to score high, the query term must occur frequently in the document but infrequently in the document set as a whole.” Oracle Text Reference, Release 9.0.1

12
Query Operators ABOUT: aumenta o número de documentos relevantes à consulta usando temas ACCUMulate: procura por documentos que contêm pelo menos um dos termos da consulta AND, OR e NOT Broader Term, Narrower Term, Preferred Term, Related Term, SYNonym, Top Term EQUIvalence Fuzzy

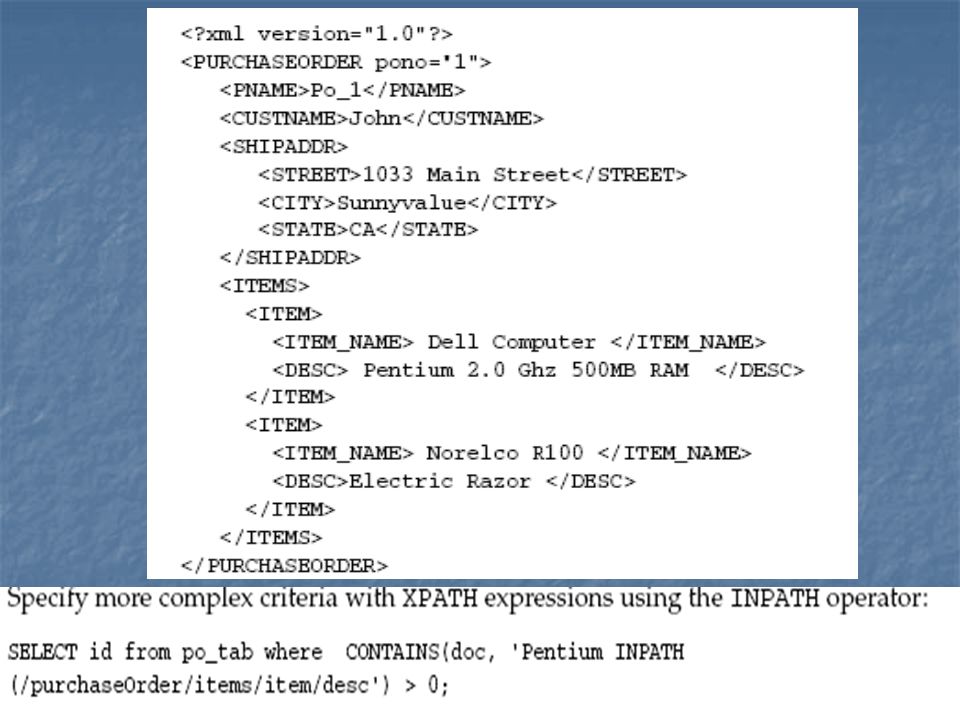
13
Query Operators HasPath InPath MDATA MINUS NEAR SOUNDEX STEM WITHIN

14
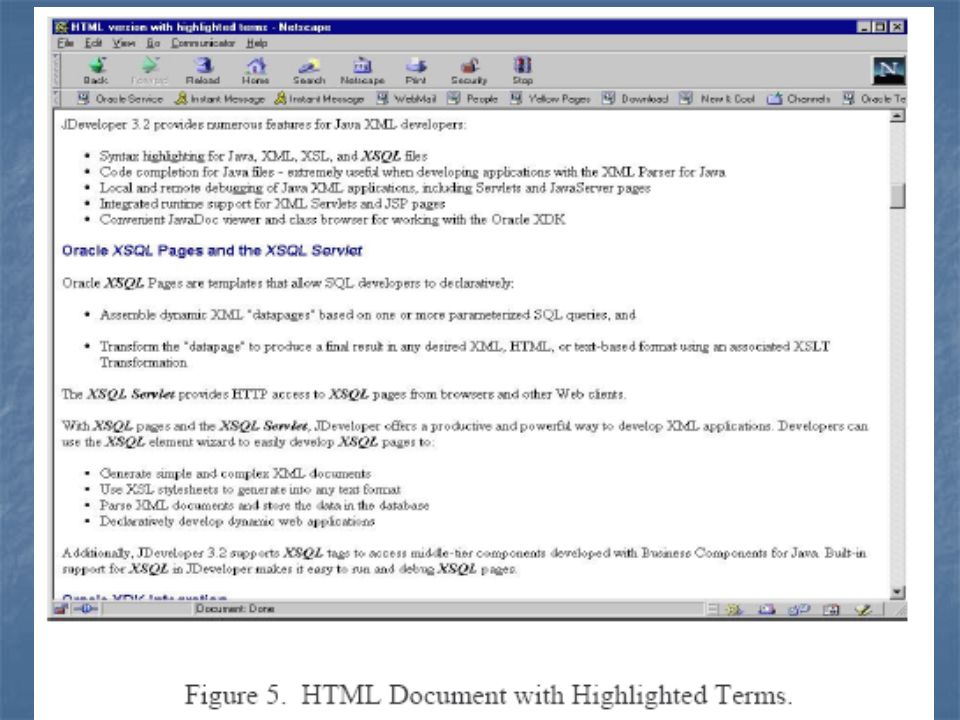
Document services Highlighting Markup Snnipet Theme extraction Gist

16
Exemplo Snnipet

17
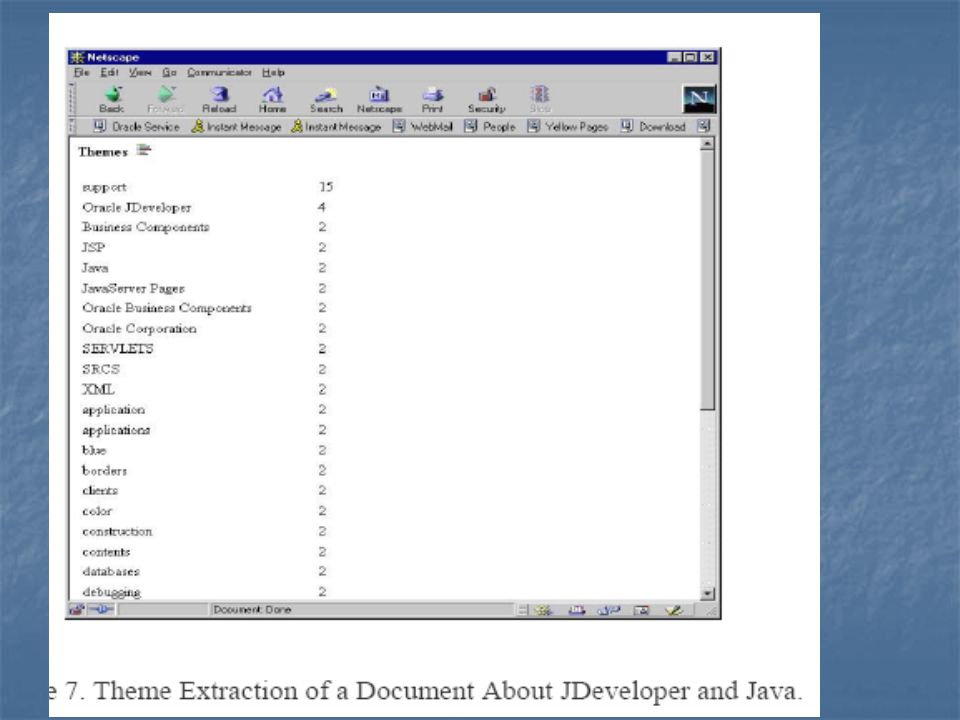
Temas Um tema é um snapshot que descreve sobre o que o documento trata. Ao invés de se buscar por palavras ou frases, pode-se buscar por um certo assunto, mesmo se este não esteja explicitamente contido no documento.

19
Gist Gist significa idéia central ou essência
gist é um sumário consistindo de parágrafos do documento que melhor o representam. Uma espécie de resumo do texto.

20
Base de Conhecimento É uma árvore com conceitos e categorias
O Oracle vem com uma base em inglês e francês com conceitos de: Ciência e Tecnologia, Business e economia, geografia, governo e militarismo, ambiente social, idéias abstratas e conceitos É implementado como um thesaurus Pode-se aumentar a acurácia da extração de temas através da criação de um thesaurus para CHESF

21
Alguns Exemplos Exemplo ACCUMulate

23
Ex. SDATA (Section Data)
Procure por livros da Categoria Fiction que contém a palavra summer

24
Ex. WITHIN

27
Ex. Múltiplos Scores SELECT title, body, SCORE(10), SCORE(20)
FROM news WHERE CONTAINS (news.title, 'Oracle', 10) > 0 OR CONTAINS (news.body, 'java', 20) > 0 ORDER BY SCORE(10), SCORE(20);
 > 0 OR. CONTAINS (news.body, java , 20) > 0. ORDER BY SCORE(10), SCORE(20);")
28
Ex. ABOUT 'about(soccer rules in international competition)‘
returns all documents that have themes of soccer, rules, or international competition. In terms of scoring, documents which have all three themes will generally score higher than documents that have only one or two of the themes.

29
Exemplo ACCUM You can assign different weights to different terms. For example, in a query of the form soccer, Brazil*3 the term Brazil is weighted three times as heavily as soccer. Therefore, the document people play soccer because soccer is challenging and fun will score lower than Brazil is the largest nation in South America but both documents will rank below soccer is the national sport of Brazil

30
Ex. Equivalence The following example returns all documents that contain either the phrase alsatians are big dogs or labradors are big dogs: 'labradors=alsatians are big dogs'

31
Ex. Fuzzy Consider the CONTAINS query:
...CONTAINS(TEXT, 'fuzzy(government, 70, 6, weight)', 1) > 0; This query expands to the first six fuzzy variations of government in the index that have a similarity score over 70.
 , 1) > 0; This query expands to the first six fuzzy variations of government in the index that have a similarity score over 70.")
32
Ex. MDATA Suppose you want to query for books written by the writer Nigella Lawson that contain the word summer. Assuming that an MDATA section called AUTHOR has been declared,you can query as follows: SELECT id FROM idx_docs WHERE CONTAINS(text, 'summer AND MDATA(author, Nigella Lawson)')>0 This query will only be successful if an AUTHOR tag has the exact value Nigella Lawson (after simplified tokenization). Nigella or Ms. Nigella Lawson will not work.
 )>0. This query will only be successful if an AUTHOR tag has the exact value Nigella Lawson (after simplified tokenization). Nigella or Ms. Nigella Lawson will not work.")
33
Ex. Minus Suppose a query on the term cars always returned high scoring documents about Ford cars. You can lower the scoring of the Ford documents by using the expression: 'cars - Ford' In essence, this expression returns documents that contain the term cars and possibly Ford. However, the score for a returned document is the score of cars minus the score of Ford.

34
Ex. Near to find all documents that contain the terms tiger, lion, and cheetah where the terms lion and tiger are within 10 words of each other, enter the following query: ‘near((lion, tiger), 10) AND cheetah'
, 10) AND cheetah")
35
Not (~) to obtain the documents that contain the term transportation but not automobiles or trains, use the following expression: 'transportation not (automobiles or trains)'
")
36
Ex. STEM Input Expands To $scream scream screaming screamed
$distinguish distinguish distinguished distinguishes $guitars guitars guitar $commit commit committed $cat cat cats $sing sang sung sing

37
Thesaurus Example 2 (Hierarchical) animal NT1 mammal cat SYN feline
NT2 cat NT3 domestic cat NT4 Persian cat NT4 Siamese cat NT3 wild cat NT4 tiger NT5 Bengal tiger NT2 dog NT3 domestic dog NT4 German Shepard NT3 wild dog NT4 Dingo cat SYN feline Dog SYN canine

38
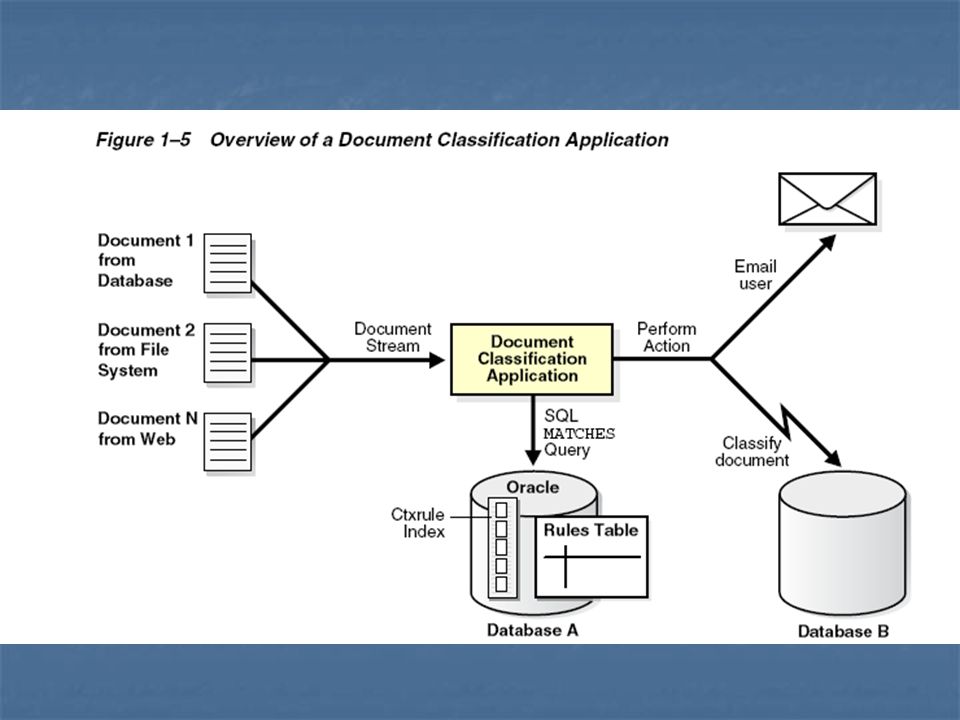
Classificação Classificação pode ser feita de 3 formas:
Rule-based: escreve-se as regras para formar as categorias dos documentos Supervised: as regras são escritas automaticamente, mas requer um conjunto treinamento previamente classificado (usa Decision tree ou SVM (Support Vector Machine) Clustering: é não supervisionada, as regras e classificação são feitas automaticamente.
 Clustering: é não supervisionada, as regras e classificação são feitas automaticamente.")
39
Ex. Rule-based

40
Ex. Rule-based

41
Exemplo de Aplicação Exemplo YAPA

Apresentações semelhantes





 tem tom.>")
















