Carregar apresentação
A apresentação está carregando. Por favor, espere

1
Paulo Abadie Guedes Eduardo Aranha
Data Mining Paulo Abadie Guedes Eduardo Aranha

2
Introdução Aplicação de processos de análise inteligentes visando manipulação automática de quantidades imensas de dados Larga aplicação nos mais variados ramos da indústria, comércio, medicina, governo, administração, etc.

3
Mineração de Dados: Exemplo 1
Fraldas e cervejas homens casados, entre 25 e 30 anos compravam fraldas e/ou cervejas às sextas-feiras à tarde no caminho do trabalho para casa Wal-Mart otimizou as gôndolas nos pontos de vendas, colocando as fraldas ao lado das cervejas Resultado: o consumo cresceu 30%

4
Mineração de Dados: Exemplo 2
Bank of America Selecionou entre seus 36 milhões de clientes Aqueles com menor risco de dar calotes Resultado: em três anos o banco lucrou 30 milhões de dólares com a carteira de empréstimos.

5
Motivação Quantidades imensas de dados
Necessidade de transformar dados em informação útil Análise de Mercado Sistemas de Suporte à Decisão Gerência Empresarial Análise de tendências, etc.

6
Knowledge Discovery Processo de filtragem de conhecimento útil
Necessidade de compreender e utilizar de forma efetiva os dados disponíveis para a tomada de decisões Integra várias técnicas e tecnologias, incluindo estatística, visualização de dados, IA, BD / OLAP / data warehouse, processamento de sinais e supercomputação

7
Data Mining: Definição
Processo de explicitar o conhecimento interessante de uma grande massa de dados Padrões e relações entre os dados Alterações e anomalias Estruturas significantes Fenômenos periódicos ou desconhecidos Apresentar de forma sucinta e compreensível o conhecimento obtido É parte do processo de descoberta de conhecimento

8
Análise de Dados X Data Mining
Orientado a suposições Formula-se uma hipótese Esta é validada contra os dados Data mining Orientada a descoberta Padrões são automaticamente extraídos Usa técnicas de IA para reconhecimento e análise do que é interessante ou não Requer muito poder computacional

9
Knowledge Discovery Process
Data cleaning Data integration Data selection Data transformation Data mining Pattern evaluation Knowledge presentation

10
Pré - processamento Data Cleaning Data Integration
Eliminaçao de “ruído”: Dados inválidos Dados incompletos Dados irrelevantes Data Integration Integração de dados de múltiplas fontes heterogêneas

11
Pré - processamento Data Selection Data transformation
Dados relevantes à análise são recuperados Data transformation Transformação e consolidação dos dados em um formato apropriado para a mineração Operações de agregação e resumo Processamento analítico (OLAP)
")
12
Data Mining (ML em BD) Algoritmos de aprendizagem de máquina (ID3, version space, Redes neurais, redes bayesianas, ...) são aplicados para extrair padrões dos dados pré-processados Reconhecimento de grupos, propriedades, relações, estruturas, anomalias, etc. Depende diretamente da tarefa desejada
 são aplicados para extrair padrões dos dados pré-processados. Reconhecimento de grupos, propriedades, relações, estruturas, anomalias, etc. Depende diretamente da tarefa desejada.")
13
Avaliação e Apresentação
Avaliação de Padrões Padrões realmente interessantes são identificados Representam o conhecimento desejado Processo baseado em medidas de interesse Apresentação do conhecimento obtido Técnicas de visualização e representação O conhecimento minerado é apresentado ao usuário de forma compreensível e concisa

14
Data Mining Tasks Class Description Exemplo Caracterização
Comparação ou discriminação Propriedades resumidas Quantidade, totais, médias e análise estatística Exemplo Comparar as vendas de uma empresa na Europa e na Ásia, identificando fatores discriminativos importantes e expondo uma visão global da situação

15
Data Mining Tasks Associação Exemplo
Descoberta de relacionamentos entre um conjunto de dados Expresso por regras atributo-valor de condições que ocorrem freqüentemente juntas x(A) y(A) se satisfaz x, tende a satisfazer y Exemplo cerveja(x) fraldas(x)
 y(A) se satisfaz x, tende a satisfazer y. Exemplo. cerveja(x) fraldas(x)")
16
Data Mining Tasks Classificação
Processa um conjunto de treinamento (classe) Constrói um modelo para cada classe Gera a árvore de decisão ou conjunto de regras Usada para compreender cada classe e classificação posterior de novos dados Estatística, BD, redes neurais, aprendizado, etc. Ex.: Análise de crédito, modelagem de empreendimentos, etc.
 Constrói um modelo para cada classe. Gera a árvore de decisão ou conjunto de regras. Usada para compreender cada classe e classificação posterior de novos dados. Estatística, BD, redes neurais, aprendizado, etc. Ex.: Análise de crédito, modelagem de empreendimentos, etc.")
17
Data Mining Tasks Previsão Ex.: Previsão de qualidade
Prevê os valores possíveis ou a distribuição destes a partir de certos atributos do BD Encontrar os atributos relevantes para o atributo de interesse Previsão baseada no conjunto de dados mais similar ao escolhido Análise de regressão, de correlação, árvores de decisão Algoritmos genéticos e redes neurais Data mining preditivo Ex.: Previsão de qualidade

18
Data Mining Tasks Agregação (Clustering)
Identifica grupos escondidos nos dados Grupo objetos similares Expressa por funções de distância Relação de similaridade conhecida a priori por especialistas ou usuários Alta similaridade no grupo, baixa entre grupos

19
Data Mining Tasks Análise de séries temporais Exemplo
Identifica regularidades e características temporais interessantes escondidas nos dados Analisa padrões seqüenciais, periódicos, tendências e desvios Busca seqüências similares ou subseqüências Exemplo Previsão da tendência de variação das quantidades em estoque de uma empresa, baseado no histórico do estoque, situação financeira, atuação da concorrência e situação do mercado

20
Mining Complex Data Dados espaciais Texto Multimídia Séries temporais
Dados complexos Dados heterogêneos Semi-estruturados ou desestruturados

21
Outras áreas de aplicação
Vendas e Marketing Identificar padrões de comportamento de consumidores Associar comportamentos à características demográficas de consumidores Campanhas de marketing direto (mailing campaigns) Identificar consumidores “leais”
 Identificar consumidores leais")
22
Áreas de aplicações potenciais
Bancos Identificar padrões de fraudes (cartões de crédito) Identificar características de correntistas Mercado Financeiro Minimizar prejuízos através de crédito a clientes de “confiança”
 Identificar características de correntistas. Mercado Financeiro. Minimizar prejuízos através de crédito a clientes de confiança")
23
Áreas de aplicações potenciais
Médica Comportamento de pacientes Identificar terapias de sucessos para diferentes tratamentos Fraudes em planos de saúdes Comportamento de usuários de planos de saúde Planos diferenciados por perfil

24
Empresas de software para Data mining:
Information Havesting - Red Brick Oracle Sybase Informix IBM

25
Conclusão - Diretrizes
Onde o processo de descoberta de conhecimento deve ser aplicado? Estudo de novos experimentos disponibilidade de dados suficientes com nível aceitável de ruído sem problemas de ordem jurídica especialistas disponíveis para: avaliação do grau de interesse das descobertas obtidas seleção de atributos descrição de conhecimento a priori em geral

26
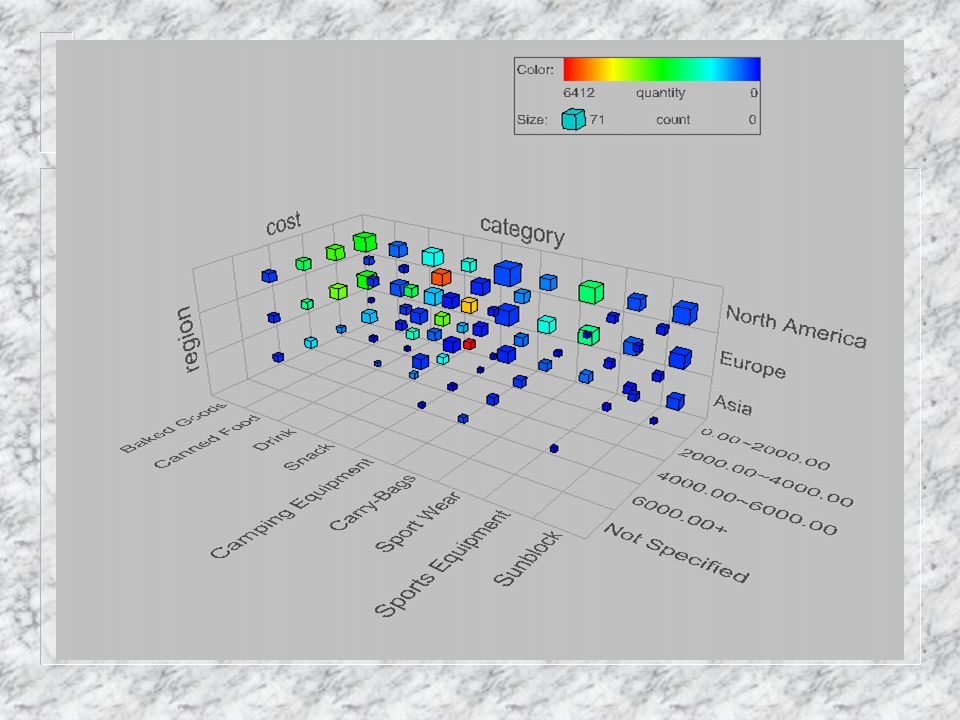
On-Line Analytical Processing (OLAP)
OLAP descreve uma classe de tecnologia que são designadas para livres acessos e análises ad hoc. OLAP tem sido considerado um sinônimo de visões multidimensionais de dados de negócio. Estas visões multidimensionais são suportadas por uma tecnologia multidimensional de bando de dados.

28
On-Line Analytical Processing (cont.)
Aplicações OLTP (On-Line Transaction Processing) caracterizadas por vários usuários criando, atualizando ou acessando registros individuais. Aplicações OLAP são usados por analistas e gerentes que frequentemente desejam uma visão agregada de alto nível dos dados, como total de vendas por produto, por região, etc.
 caracterizadas por vários usuários criando, atualizando ou acessando registros individuais. Aplicações OLAP são usados por analistas e gerentes que frequentemente desejam uma visão agregada de alto nível dos dados, como total de vendas por produto, por região, etc.")
29
On-Line Analytical Processing (cont.)
Aplicações OLAP usualmente atualizadas em batch, a partir de múltiplas fontes. Banco de dados relacionais são bons para retornar um pequeno número de registro rapidamente. Regiões de venda por produtos pode levar horas (segundos em um BD OLAP)
")
30
On-Line Analytical Processing (cont.)
")
31
On-Line Analytical Processing (cont.)
")
32
Referências KDNuggets Directory The Data Mine
The Data Mine Microsoft Decision Theory and Adaptive Systems DBMiner: demonstração

33
Referências http://www.pcc.qub.ac.uk/tec/courses/datamining

34
Referências Bigus, J. (1995). Data Mining with Neural Networks. McGraw-Hill. Fayyad, U.; Haussler, D.; Stolorz, P. (1996). "KDD for Science Data Analysis: Issues and Examples”. Proceedings of Second International Conference on Knowledge Discovery and Data Mining (KDD-96), AAAI Press. Disponível no endereço Fayyad, U. M.; Piatesky-Shapiro, G.; Smyth, P. (1995). “From Data Mining to Knowledge Discovery: An Overview”, em Advances in Knowledge Discovery and Data Mining. AAAI Press.
. KDD for Science Data Analysis: Issues and Examples . Proceedings of Second International Conference on Knowledge Discovery and Data Mining (KDD-96), AAAI Press. Disponível no endereço Fayyad, U. M.; Piatesky-Shapiro, G.; Smyth, P. (1995). From Data Mining to Knowledge Discovery: An Overview , em Advances in Knowledge Discovery and Data Mining. AAAI Press.")
35
Referências Imielinski, T; Mannila, H. (1996). “A Database Perspective on Knowledge Discovery”. Communications of the ACM, volume 39, número 11. Matheus, C.; Piateteky-Shapiro, G.; McNeill, D. (1995). ”Selecting and Reporting What is Interesting”. Em Advances in Knowledge Discovery and Data Mining. AAAI Press.
. Selecting and Reporting What is Interesting . Em Advances in Knowledge Discovery and Data Mining. AAAI Press.")
36
Referências Freitas, A. A. (1997). “On objective measures of rule surprisingness”. Em Proceedings of the 2nd European Symposium Principles of Data Mining and Knowledge Discovery. Disponível no endereço Spirtes, P.; Glymour, C; Scheines, R. (1993). Causation, Prediction and Search. Lecture Notes in Statistics, 83. Springer-Verlarg. Disponível no endereço philosophy/TETRAD.BOOK/book.html
. On objective measures of rule surprisingness . Em Proceedings of the 2nd European Symposium Principles of Data Mining and Knowledge Discovery. Disponível no endereço Spirtes, P.; Glymour, C; Scheines, R. (1993). Causation, Prediction and Search. Lecture Notes in Statistics, 83. Springer-Verlarg. Disponível no endereço philosophy/TETRAD.BOOK/book.html.")
Apresentações semelhantes