Carregar apresentação
A apresentação está carregando. Por favor, espere

1
LCM: na efficient algorithm for enumerating frequent closed item sets T. Uno, T. Asai, H. Arimura Apresentação: Luiz Henrique Longhi Rossi

2
Apresentação Serão apresentados três algorítmos: Serão apresentados três algorítmos: LCM-freqLCM-freq Todos conjuntos frequentes Todos conjuntos frequentes LCMLCM Conjuntos fechados frequentes Conjuntos fechados frequentes LCMmaxLCMmax Conjuntos frequentes máximos Conjuntos frequentes máximos

3
Definições E é o universo de todos os itens; E é o universo de todos os itens; X é um subconjunto de E. X é um subconjunto de E. R é o conjunto de transações sobre E R é o conjunto de transações sobre E R(X) = {t R | X t} será o conjunto de transações incluindo X; R(X) = {t R | X t} será o conjunto de transações incluindo X; α é uma constante, α > 0; α é uma constante, α > 0; Um conjunto X é chamado de freqüente se |R(X)| > α; Um conjunto X é chamado de freqüente se |R(X)| > α;
 = {t R | X t} será o conjunto de transações incluindo X; R(X) = {t R | X t} será o conjunto de transações incluindo X; α é uma constante, α > 0; α é uma constante, α > 0; Um conjunto X é chamado de freqüente se |R(X)| > α; Um conjunto X é chamado de freqüente se |R(X)| > α;.")
4
Definições Se um conjunto freqüente está contido em outro, este é dito maximal Se um conjunto freqüente está contido em outro, este é dito maximal Se um conjunto de transações S R, tomamos I(S) = TS T. Se um conjunto de transações S R, tomamos I(S) = TS T. Se X satisfaz I(R(X)) = X, então é um conjunto fechado. Se X satisfaz I(R(X)) = X, então é um conjunto fechado. F será o conjunto de todos conjuntos freqüentes F será o conjunto de todos conjuntos freqüentes C será o conjunto de todos conjuntos freqüentes fechados C será o conjunto de todos conjuntos freqüentes fechados
 = TS T. Se X satisfaz I(R(X)) = X, então é um conjunto fechado. Se X satisfaz I(R(X)) = X, então é um conjunto fechado. F será o conjunto de todos conjuntos freqüentes F será o conjunto de todos conjuntos freqüentes C será o conjunto de todos conjuntos freqüentes fechados C será o conjunto de todos conjuntos freqüentes fechados.")
5
Característica Algoritmo híbrido Algoritmo híbrido Em um momento das iterações opta, baseado em estimativas, por um ou por outra técnica para utilizar algoritmos para dados esparsos ou densos;Em um momento das iterações opta, baseado em estimativas, por um ou por outra técnica para utilizar algoritmos para dados esparsos ou densos;

6
Enumerando Conjuntos Fechados Freqüentes É construída uma arvore TRIE É construída uma arvore TRIE É feita uma busca em profundidade, enumera-se assim todos os conjuntos fechados freqüentes É feita uma busca em profundidade, enumera-se assim todos os conjuntos fechados freqüentes

7
Algoritmo LCM Para todos conjuntos maiores que o conjunto i (anterior) Para todos conjuntos maiores que o conjunto i (anterior) Se o conjunto for freqüente E igual a intersecção de todas as transações envolvendo ele se chama recursivamente o LCMSe o conjunto for freqüente E igual a intersecção de todas as transações envolvendo ele se chama recursivamente o LCM For each i > i(X) For each i > i(X) If X[i] is frequent and X[i] = I(T(X[i]) then If X[i] is frequent and X[i] = I(T(X[i]) then Call LCM (X[i])Call LCM (X[i]) End for End for
![Algoritmo LCM Para todos conjuntos maiores que o conjunto i (anterior) Para todos conjuntos maiores que o conjunto i (anterior) Se o conjunto for freqüente E igual a intersecção de todas as transações envolvendo ele se chama recursivamente o LCMSe o conjunto for freqüente E igual a intersecção de todas as transações envolvendo ele se chama recursivamente o LCM For each i > i(X) For each i > i(X) If X[i] is frequent and X[i] = I(T(X[i]) then If X[i] is frequent and X[i] = I(T(X[i]) then Call LCM (X[i])Call LCM (X[i]) End for End for](http://images.slideplayer.com.br/2/359198/slides/slide_7.jpg "Algoritmo LCM Para todos conjuntos maiores que o conjunto i (anterior) Para todos conjuntos maiores que o conjunto i (anterior) Se o conjunto for freqüente E igual a intersecção de todas as transações envolvendo ele se chama recursivamente o LCMSe o conjunto for freqüente E igual a intersecção de todas as transações envolvendo ele se chama recursivamente o LCM For each i > i(X) For each i > i(X) If X[i] is frequent and X[i] = I(T(X[i]) then If X[i] is frequent and X[i] = I(T(X[i]) then Call LCM (X[i])Call LCM (X[i]) End for End for")
8
Algorítmo LCM X[i] são todos os conjuntos que contém X e contém i, logo X não necessariamente é um prefixo de X[i]. X[i] são todos os conjuntos que contém X e contém i, logo X não necessariamente é um prefixo de X[i].
![Algorítmo LCM X[i] são todos os conjuntos que contém X e contém i, logo X não necessariamente é um prefixo de X[i].](http://images.slideplayer.com.br/2/359198/slides/slide_8.jpg "X[i] são todos os conjuntos que contém X e contém i, logo X não necessariamente é um prefixo de X[i]..")
9
Exemplo, sup = 3 A: 1,2,3,8,5 A: 1,2,3,8,5 B: 1,2,4,5 B: 1,2,4,5 C: 1,2,3,8,9 C: 1,2,3,8,9 D: 1,2,3,8,10 D: 1,2,3,8,10 E: 1,2,4,9 E: 1,2,4,9 F: 1,2,5,8 F: 1,2,5,8 1; 1; 1,2 é freqüente? 1,2 é freqüente? Sim T({1,2}) = {A, B, C, D, E, F} T({1,2}) = {A, B, C, D, E, F} I(T({1,2})) = 1,2 I(T({1,2})) = 1,2 É igual? É igual? Sim, então chama recursivamente
 = {A, B, C, D, E, F} T({1,2}) = {A, B, C, D, E, F} I(T({1,2})) = 1,2 I(T({1,2})) = 1,2 É igual. É igual. Sim, então chama recursivamente.")
10
Exemplo, sup = 3 A: 1,2,3,8,5 A: 1,2,3,8,5 B: 1,2,4,5 B: 1,2,4,5 C: 1,2,3,8,9 C: 1,2,3,8,9 D: 1,2,3,8,10 D: 1,2,3,8,10 E: 1,2,4,9 E: 1,2,4,9 F: 1,2,5,8 F: 1,2,5,8 1,2; 1,2; 1,2,3 é frequente? 1,2,3 é frequente? Sim T({1,2,3}) = {A, C, D} T({1,2,3}) = {A, C, D} I(T({1,2,3}) = 1,2,3,8 I(T({1,2,3}) = 1,2,3,8 É igual? É igual? Não, então não chama recursivamente
 = {A, C, D} T({1,2,3}) = {A, C, D} I(T({1,2,3}) = 1,2,3,8 I(T({1,2,3}) = 1,2,3,8 É igual. É igual. Não, então não chama recursivamente.")
11
Exemplo Então como que ele identificará que o conjunto 1,2,3,8 será fechado freqüente? Então como que ele identificará que o conjunto 1,2,3,8 será fechado freqüente? Por causa do iterador! A verificação é feita como se os dados estivessem em uma trie, logo, ele vai varrer aumentando o índice i, que compreende todos os subconjuntos (percorre em profundidade)Por causa do iterador! A verificação é feita como se os dados estivessem em uma trie, logo, ele vai varrer aumentando o índice i, que compreende todos os subconjuntos (percorre em profundidade) Percorre toda a árvore em tempo linear Percorre toda a árvore em tempo linear Para realizar a operação I(X) não teria que percorrer as transações envolvendo X?Para realizar a operação I(X) não teria que percorrer as transações envolvendo X?
Por causa do iterador. A verificação é feita como se os dados estivessem em uma trie, logo, ele vai varrer aumentando o índice i, que compreende todos os subconjuntos (percorre em profundidade) Percorre toda a árvore em tempo linear Percorre toda a árvore em tempo linear Para realizar a operação I(X) não teria que percorrer as transações envolvendo X Para realizar a operação I(X) não teria que percorrer as transações envolvendo X .")
12
Vantagens Outros algoritmos ao gerarem a árvore adicionam todos os conjuntos freqüentes, adicionando assim, muitos que serão podados, como o LCM só adiciona conjuntos fechados na árvore, poupa processamento; Outros algoritmos ao gerarem a árvore adicionam todos os conjuntos freqüentes, adicionando assim, muitos que serão podados, como o LCM só adiciona conjuntos fechados na árvore, poupa processamento; Afirma também que cada iteração tem menos processamento. Afirma também que cada iteração tem menos processamento.

13
Vantagens Além do algoritmo base, apresenta algumas otimizações Além do algoritmo base, apresenta algumas otimizações Ocurrence Deliver:Ocurrence Deliver: Reduz o tempo para construir T(X[i]) Reduz o tempo para construir T(X[i]) Normalmente é obtido a partir de T(X) percorrendo todas transações que não envolvem i Normalmente é obtido a partir de T(X) percorrendo todas transações que não envolvem i Ao invés disso, em quanto se obtém T(X) simultaneamente é feita a lista J[i] = T(X[i]) Ao invés disso, em quanto se obtém T(X) simultaneamente é feita a lista J[i] = T(X[i]) Além disso não precisam ser feitas chamadas recursivas se J[i] for vazio Além disso não precisam ser feitas chamadas recursivas se J[i] for vazio
![Vantagens Além do algoritmo base, apresenta algumas otimizações Além do algoritmo base, apresenta algumas otimizações Ocurrence Deliver:Ocurrence Deliver: Reduz o tempo para construir T(X[i]) Reduz o tempo para construir T(X[i]) Normalmente é obtido a partir de T(X) percorrendo todas transações que não envolvem i Normalmente é obtido a partir de T(X) percorrendo todas transações que não envolvem i Ao invés disso, em quanto se obtém T(X) simultaneamente é feita a lista J[i] = T(X[i]) Ao invés disso, em quanto se obtém T(X) simultaneamente é feita a lista J[i] = T(X[i]) Além disso não precisam ser feitas chamadas recursivas se J[i] for vazio Além disso não precisam ser feitas chamadas recursivas se J[i] for vazio](http://images.slideplayer.com.br/2/359198/slides/slide_13.jpg "Vantagens Além do algoritmo base, apresenta algumas otimizações Além do algoritmo base, apresenta algumas otimizações Ocurrence Deliver:Ocurrence Deliver: Reduz o tempo para construir T(X[i]) Reduz o tempo para construir T(X[i]) Normalmente é obtido a partir de T(X) percorrendo todas transações que não envolvem i Normalmente é obtido a partir de T(X) percorrendo todas transações que não envolvem i Ao invés disso, em quanto se obtém T(X) simultaneamente é feita a lista J[i] = T(X[i]) Ao invés disso, em quanto se obtém T(X) simultaneamente é feita a lista J[i] = T(X[i]) Além disso não precisam ser feitas chamadas recursivas se J[i] for vazio Além disso não precisam ser feitas chamadas recursivas se J[i] for vazio")
14
Vantagens Ocurrence Deliver Ocurrence Deliver Otimiza em casos que T(X[i]) é bem menor que T(X);Otimiza em casos que T(X[i]) é bem menor que T(X); Pode levar até 1/10 do tempo em alguns casos.Pode levar até 1/10 do tempo em alguns casos. Right-First Sweep Right-First Sweep Como cada chamada recursiva vai ter um tamanho menor ou igual que a chamada anterior pode-se alocar a memória no tamanho total de J de uma vez só como variável global.Como cada chamada recursiva vai ter um tamanho menor ou igual que a chamada anterior pode-se alocar a memória no tamanho total de J de uma vez só como variável global.
![Vantagens Ocurrence Deliver Ocurrence Deliver Otimiza em casos que T(X[i]) é bem menor que T(X);Otimiza em casos que T(X[i]) é bem menor que T(X); Pode levar até 1/10 do tempo em alguns casos.Pode levar até 1/10 do tempo em alguns casos.](http://images.slideplayer.com.br/2/359198/slides/slide_14.jpg "Right-First Sweep Right-First Sweep Como cada chamada recursiva vai ter um tamanho menor ou igual que a chamada anterior pode-se alocar a memória no tamanho total de J de uma vez só como variável global.Como cada chamada recursiva vai ter um tamanho menor ou igual que a chamada anterior pode-se alocar a memória no tamanho total de J de uma vez só como variável global..")
15
Vantagens Diffsets Diffsets No caso do |T(X[i])| ser parecido com |T(X)| é usada essa técnicaNo caso do |T(X[i])| ser parecido com |T(X)| é usada essa técnica Está definida em uma artigo completo nas referênciasEstá definida em uma artigo completo nas referências Diz-se que reduz em até 1/100 em algumas base de dadosDiz-se que reduz em até 1/100 em algumas base de dados
![Vantagens Diffsets Diffsets No caso do |T(X[i])| ser parecido com |T(X)| é usada essa técnicaNo caso do |T(X[i])| ser parecido com |T(X)| é usada essa técnica Está definida em uma artigo completo nas referênciasEstá definida em uma artigo completo nas referências Diz-se que reduz em até 1/100 em algumas base de dadosDiz-se que reduz em até 1/100 em algumas base de dados](http://images.slideplayer.com.br/2/359198/slides/slide_15.jpg "Vantagens Diffsets Diffsets No caso do |T(X[i])| ser parecido com |T(X)| é usada essa técnicaNo caso do |T(X[i])| ser parecido com |T(X)| é usada essa técnica Está definida em uma artigo completo nas referênciasEstá definida em uma artigo completo nas referências Diz-se que reduz em até 1/100 em algumas base de dadosDiz-se que reduz em até 1/100 em algumas base de dados")
16
Vantagens Computação hibrida Computação hibrida Usar Ocurrence Deliver em casos em que |T(X[i])| é bem menor que |T(X)|;Usar Ocurrence Deliver em casos em que |T(X[i])| é bem menor que |T(X)|; Usar Diffsets em casos em que |T(X[i])| é bem próximo a |T(X)|Usar Diffsets em casos em que |T(X[i])| é bem próximo a |T(X)| Como decidir?Como decidir? Estatística Estatística
![Vantagens Computação hibrida Computação hibrida Usar Ocurrence Deliver em casos em que |T(X[i])| é bem menor que |T(X)|;Usar Ocurrence Deliver em casos em que |T(X[i])| é bem menor que |T(X)|; Usar Diffsets em casos em que |T(X[i])| é bem próximo a |T(X)|Usar Diffsets em casos em que |T(X[i])| é bem próximo a |T(X)| Como decidir Como decidir.](http://images.slideplayer.com.br/2/359198/slides/slide_16.jpg "Estatística Estatística.")
17
Vantagens A(X) = Σ i |T (X {i})| A(X) = Σ i |T (X {i})| Tamanho total dos filhos de XTamanho total dos filhos de X B(X) = Σ i:X {i} F (|T (X)| |T (X {i})|) B(X) = Σ i:X {i} F (|T (X)| |T (X {i})|) Tamanho de X menos o tamanho dos filhosTamanho de X menos o tamanho dos filhos Para uma constante c usa-se o Ocurrence deliver se A(X) < c.B(X) Para uma constante c usa-se o Ocurrence deliver se A(X) < c.B(X) A decisão é feita apenas para os filhos imediatos da raiz desde que não tome muito tempo A decisão é feita apenas para os filhos imediatos da raiz desde que não tome muito tempo
 = Σ i |T (X {i})| A(X) = Σ i |T (X {i})| Tamanho total dos filhos de XTamanho total dos filhos de X B(X) = Σ i:X {i} F (|T (X)| |T (X {i})|) B(X) = Σ i:X {i} F (|T (X)| |T (X {i})|) Tamanho de X menos o tamanho dos filhosTamanho de X menos o tamanho dos filhos Para uma constante c usa-se o Ocurrence deliver se A(X) < c.B(X) Para uma constante c usa-se o Ocurrence deliver se A(X) < c.B(X) A decisão é feita apenas para os filhos imediatos da raiz desde que não tome muito tempo A decisão é feita apenas para os filhos imediatos da raiz desde que não tome muito tempo")
18
Vantagens A computação hibrida, reduz o tempo em até 1/3A computação hibrida, reduz o tempo em até 1/3 Verificação de fechabilidade (no ocurrence deliver) Verificação de fechabilidade (no ocurrence deliver) Por definição um conjunto candidato não vai ser fechado sse existir um valor que ocorre em todas transações que outro valorPor definição um conjunto candidato não vai ser fechado sse existir um valor que ocorre em todas transações que outro valor Então, é testado durante o algoritmo se a existe um j que pertence a todas as transaçõesEntão, é testado durante o algoritmo se a existe um j que pertence a todas as transações Não é feito no diffset porque o conjunto seria muito grandeNão é feito no diffset porque o conjunto seria muito grande
 Verificação de fechabilidade (no ocurrence deliver) Por definição um conjunto candidato não vai ser fechado sse existir um valor que ocorre em todas transações que outro valorPor definição um conjunto candidato não vai ser fechado sse existir um valor que ocorre em todas transações que outro valor Então, é testado durante o algoritmo se a existe um j que pertence a todas as transaçõesEntão, é testado durante o algoritmo se a existe um j que pertence a todas as transações Não é feito no diffset porque o conjunto seria muito grandeNão é feito no diffset porque o conjunto seria muito grande")
19
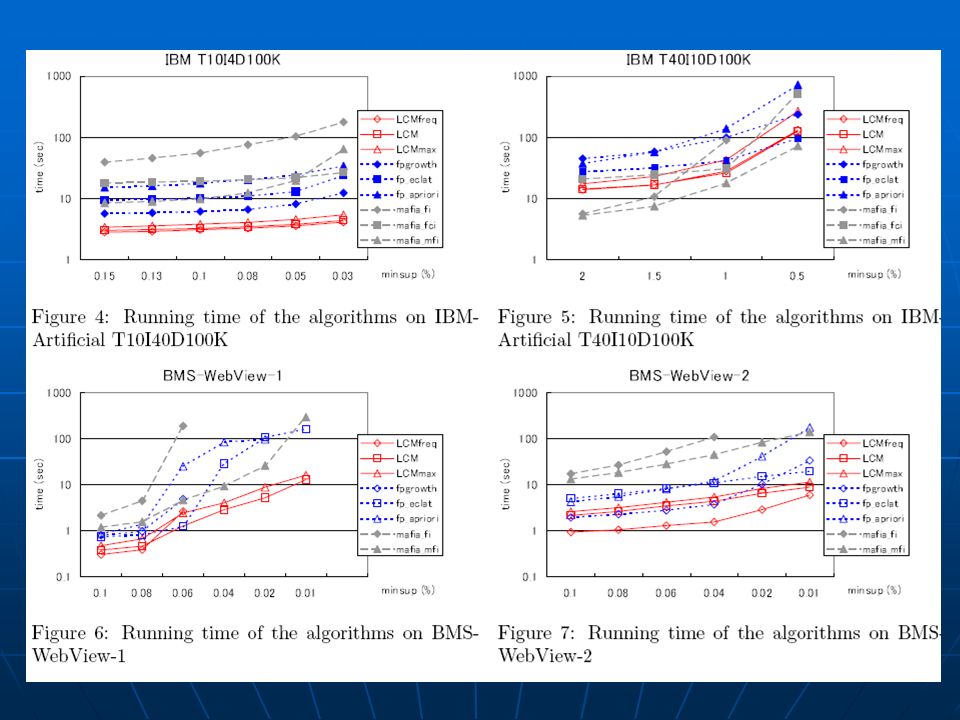
Resultados Bases de dados Bases de dados Dataset#items#Trans Minsup (%) BMS-Web-View1BMS-Web-View2BMS-POST10I4D100KT40I10D100Kpumsb pumsb star mushroomconnectchess4973,3401,6571,0001,0007,1177,1171201307659,60277,512517,255100,000100,00049,04649,0468,12467,57731960.1–0.010.1–0.010.1–0.010.15–0.0252–0.595–6050–1020–0.195–4090–30
 BMS-Web-View1BMS-Web-View2BMS-POST10I4D100KT40I10D100Kpumsb pumsb star mushroomconnectchess4973,3401,6571,0001,0007,1177, ,60277,512517,255100,000100,00049,04649,0468,12467, – – – –0.0252–0.595–6050–1020–0.195–4090–30")
20
Resultados LCMfreq, LCM, LCMmax, FPgrowth, eclat, apriori, mafia-mfi LCMfreq, LCM, LCMmax, FPgrowth, eclat, apriori, mafia-mfi Em todas as 9 base de dados diferentesEm todas as 9 base de dados diferentes

Apresentações semelhantes









1Database System Concepts result := {R}; done := false; calcular F+; while (not done) do if (há um esquema.>")










