Carregar apresentação
A apresentação está carregando. Por favor, espere

1
Fundamentos do Método Probabilístico

2
Relacioamento de Registros Método Determinístico Método Probabilístico Utilização conjunta de campos comuns presentes em ambos os bancos de dados com o objetivo de identificar o quanto é provável que um par de registros se refira a um mesmo indivíduo.

3
Padronização

4
Formação de Links- Blocagem

5
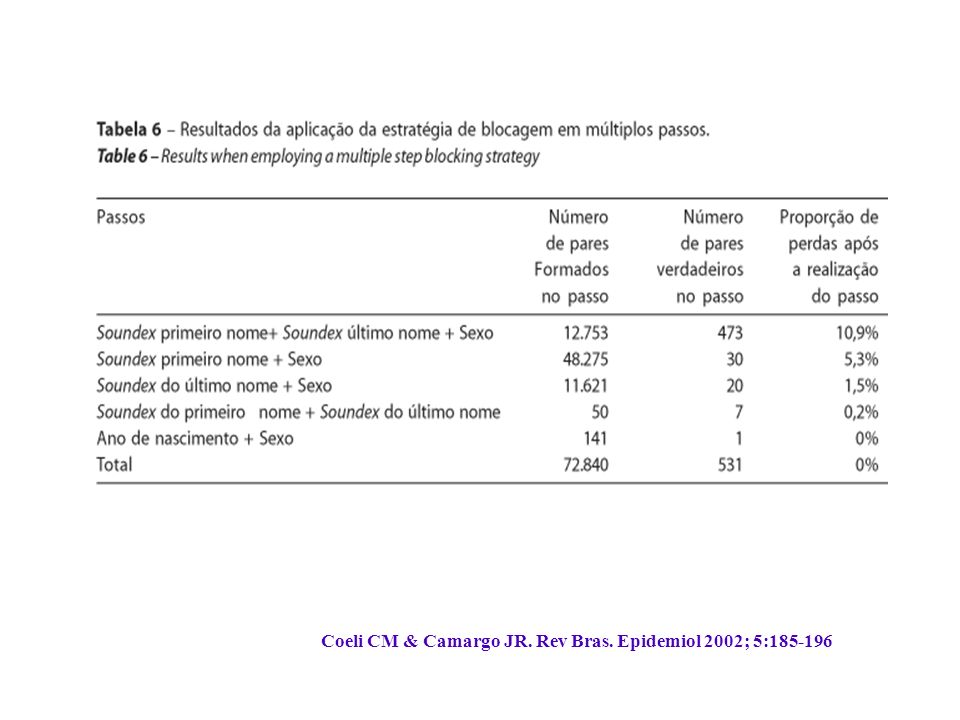
Blocagem Consiste na criação de blocos lógicos de registros dentro dos arquivos a serem relacionados, permitindo que a comparação entre registros se faça de uma forma mais otimizada; O número de pares possíveis com a combinação de duas bases de dados é igual ao produto entre o número de registros na primeira base e o número de registros na segunda base. Por exemplo, o relacionamento de duas bases de dados com 10.000 registros cada implicaria na necessidade de comparação de 100.000.000 de pares de registros, o que demandaria um alto custo para o processamento das comparações.

6
Blocagem A blocagem permite que as bases de dados sejam logicamente divididas em blocos mutuamente exclusivos, sendo as comparações limitadas aos registros pertencentes a um mesmo bloco. Os blocos são constituídos de forma a aumentar a probabilidade de que os registros neles contidos representem pares verdadeiros. O processo consiste na indexação dos arquivos a serem relacionados segundo uma chave formada por um campo ou pela combinação de mais de um campo. Os registros de um determinado bloco apresentam o mesmo valor para a chave escolhida.

7
Blocagem A chave para a blocagem deve apresentar um grande número de valores que se distribuem de modo relativamente uniforme, buscando, desta maneira, alcançar a divisão do arquivo em um número grande blocos com tamanho reduzido (poucos registros por bloco) Adicionalmente, os campos que formam a chave devem apresentar baixa probabilidade de ocorrência de erros 8-9. Estes últimos fazem com que os registros relativos a um mesmo indivíduo sejam alocados em blocos diferentes impossibilitando a comparação dos registros, e levando a classificação dos mesmos como falsos não pares.

8
Blocagem Em resumo, deve-se buscar a utilização estratégias de blocagem que minimizem simultaneamente o custo com o processamento e a perda de pares verdadeiros. O emprego de códigos fonéticos de partes do nome (primeiro e/ou último nome) representa uma alternativa usualmente utilizada, já que as chaves apresentam múltiplos valores com uma ocorrência de erros bem menor do que a seria esperada com o emprego direto do primeiro e/ou do último nome. O soundex é um dos códigos frequentemente usados para este fim.
 representa uma alternativa usualmente utilizada, já que as chaves apresentam múltiplos valores com uma ocorrência de erros bem menor do que a seria esperada com o emprego direto do primeiro e/ou do último nome. O soundex é um dos códigos frequentemente usados para este fim..")
9
Blocagem O código soundex é formado por 4 dígitos sendo o primeiro representado pela primeira letra da palavra a ser codificada enquanto os demais são dígitos numéricos codificados segundo as seguintes regras: 1 As letras A, E, I, O, U, H, W e Y são ignoradas. 2 Para as demais letras empregam-se os seguintes códigos numéricos: B, F,P,V – 1; C, G, J, K, Q, S, X, Z - 2; D, T- 3; L - 4; M,N - 5; R-6. 3 Se duas letras contíguas na palavra apresentarem o mesmo código, este só é computado uma única vez. 4 Uma vez que os três dígitos numéricos tenham sido completados as demais letras da palavra são ignoradas. 5 Todos os códigos devem ter 4 dígitos. Sendo assim, para as palavras onde o código inicialmente formado seja constituído por menos do que 3 dígitos numéricos, completa-se os dígitos restantes com zeros.

10
Blocagem Por exemplo, o código soundex da palavra soundex é S532 e o do nome João é J000. O algoritmo para o soundex encontra-se implementado em alguns gerenciadores de banco de dados, como por exemplo o Visual dBASE (Borland). Newcombe 11 (1967) verificou que o código soundex funciona adequadamente para nomes de diferentes origens, com a exceção de nomes de origem oriental, já que o código ignora vogais e estas representam uma parte importante do poder de discriminação destes nomes.
. Newcombe 11 (1967) verificou que o código soundex funciona adequadamente para nomes de diferentes origens, com a exceção de nomes de origem oriental, já que o código ignora vogais e estas representam uma parte importante do poder de discriminação destes nomes..")
11
Blocagem Trabalhando com bases de dados nacionais encontramos, entretanto, um problema de inadequação do código soundex para alguns nomes brasileiros que apresentam variações de grafia da primeira sílaba para um mesmo som (por exemplo, Helena x Elena; Jorge x George). Estes nomes são mais sujeitos a erros de registro. Como o código soundex retém a primeira letra do nome, as diferentes grafias recebem códigos diferentes, sendo consequentemente alocadas em blocos diferentes, o que aumenta a probabilidade da perda de pares verdadeiros.

12
Blocagem - Primeira letra W e segunda A -> Primeira letra passa a V - Primeira letra H -> Deleta primeira letra - Primeira letra K e segunda A, O ou U -> Primeira letra passa a C - Primeira letra Y -> Primeira letra passa a I - Primeira letra C e segunda E ou I -> Primeira letra passa a S - Primeira letra G e segunda E ou I -> Primeira letra passa a J Rotina de Padronização Campos: PBLOCO e UBLOCO

13
Últimos nomes mais frequentes na base de óbitos. Município do Rio de Janeiro, 1998. Coeli CM & Camargo JR. Rev Bras. Epidemiol 2002; 5:185-196

15
Algoritmos de Comparação O algoritmo de Levenshtein identifica o número de operações necessárias (ex. inserções, deleções, trocas) para transformar uma cadeia de caracter na outra que se encontra em comparação. Retorna um resultado que pode variar de zero (concordância total) até o valor máximo, que é igual ao número de caracteres da cadeia com maior tamanho (discordância total).
 para transformar uma cadeia de caracter na outra que se encontra em comparação. Retorna um resultado que pode variar de zero (concordância total) até o valor máximo, que é igual ao número de caracteres da cadeia com maior tamanho (discordância total)..")
16
Algoritmos de Comparação Manoel vs. Manuel C= (6-1)/6= 5/6=0.833 ou 83,3% Manoel vs. Manuel Claudia Medina Coeli vs. Maria Claudia Coeli C= (20-9)/20= 11/20=0.55 ou 55,5%
/20= 11/20=0.55 ou 55,5%.")
17
Cálculo Escore Sim Não Algoritmo Padrão Ouro Verdadeiro Falso Verdadeiro Positivo VPi Falso Negativo FNi Falso Positivo FPi Verdadeiro Negativo VNi

18
Cálculo Escore Carlos Sllatery Mansa vs Carlos Sllatery Mansa 19700702 vs 19611221 Concordância Discordância

19
Cálculo Escore Carlos Sllatery Mansa vs Carlos Sllatery Mansa 19700702 vs 19611221 Nome VPi= 0.92 FPi=0.01 Data Nascimento VNi=0.95 FNi=0.10 log2 (0.92/0.01) + log2(0.10/0.95)= 6.523+(-3.247)=3.275
 + log2(0.10/0.95)= (-3.247)=3.275")
20
Linkage - Seleção de Pares

Apresentações semelhantes