Carregar apresentação
A apresentação está carregando. Por favor, espere

1
A P2P-Based Self-Healing Service for Network Maintenance
Serviço de auto-correção baseado em P2P para manutenção de redes Pedro Arthur Pinheiro Rosa Duarte, Jeferson Campos Nobre, Lisandro Zambenedetti Granville, Liane Margarida Rockenbach Tarouco Federal University of Rio Grande do Sul 12th IFIP/IEEE International Symposium on Integrated Network Management 2011 Apresentado por Bruno Barcarollo Gauer

2
Roteiro Objetivo Introdução Trabalhos Relacionados Proposta
Implementação Estudo de caso / Avaliação Conclusões Críticas

3
Propor um mecanismo de auto-correção que funcione sobre um sistema de gerência de redes baseado em P2P Objetivo

4
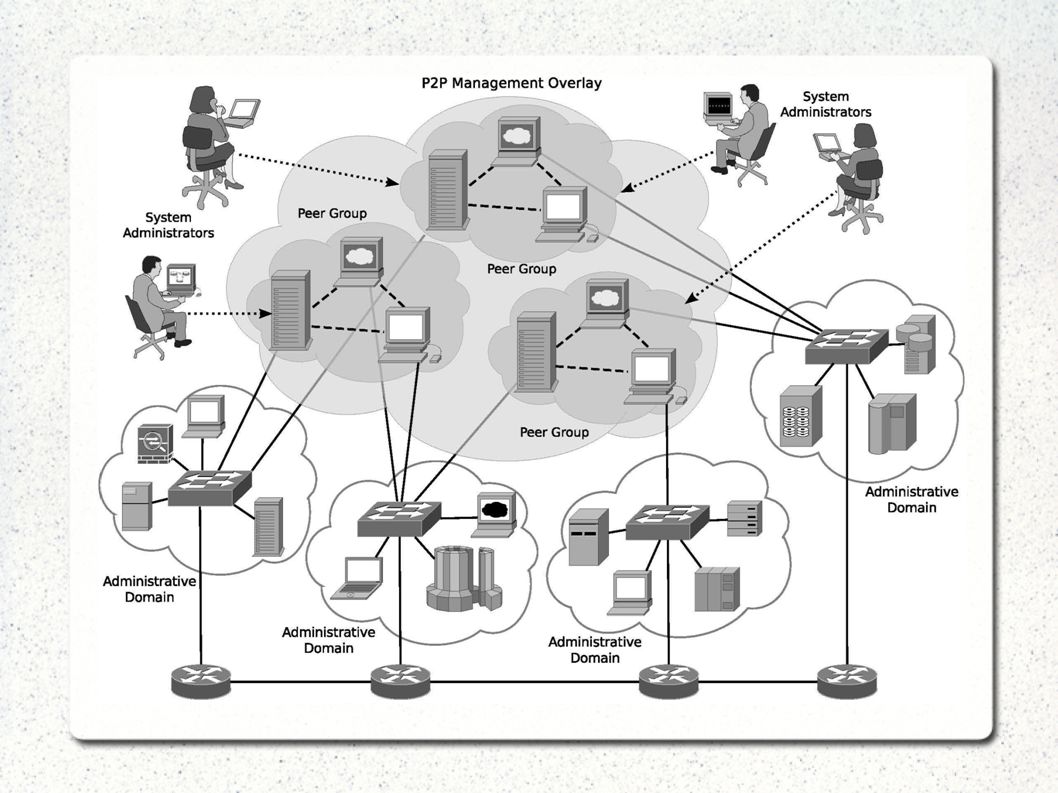
Introdução Recentemente as redes têm aumentado em tamanho, complexidade e heterogeneidade Introdução de tecnologias distribuídas na gerência de redes (P2PBNM) trouxe melhorias comparado ao sistema tradicional centralizado P2P Based Management Overlays Gerência colaborativa Conectividade mais robusta entre entidades Melhoria na distribuição das tarefas Boa escalabilidade
 trouxe melhorias comparado ao sistema tradicional centralizado. P2P Based Management Overlays. Gerência colaborativa. Conectividade mais robusta entre entidades. Melhoria na distribuição das tarefas. Boa escalabilidade.")
5
Introdução Uso de propriedades self-* do Autonomic Computing
Autonomic Computing: paradigma que define composição e características de sistemas autônomos Propriedades self-*: Self Awareness, Self Configuring, Self Optimizing, Self-Healing, Self Protecting Foco em Self-Healing (auto-correção): Habilidade de detectar e corrigir problemas, além de manter o sistema funcionando corretamente de maneira transparente
: Habilidade de detectar e corrigir problemas, além de manter o sistema funcionando corretamente de maneira transparente.")
6
Introdução Self Healing: Automatizar tarefas de gerência
Reduzir custos de manutenção de infraestrutura 50% do custo é relativo a prevenção de erros, diagnósticos e correção Facilitar a vida dos administradores Objetivos da proposta: Abstrair monitoramento e correção dos sistemas Tratar a heterogeneidade das redes usando ”workplans” (descrições de alto nível de como os sistemas devem ser gerenciados) Alta disponibilidade dos serviços Avaliar o serviço em um sistema distribuído de detecção de intrusões
 Alta disponibilidade dos serviços. Avaliar o serviço em um sistema distribuído de detecção de intrusões.")
7
Trabalhos Relacionados
Abordagens Auto-Correção (Self-Healing) PANACEA: framework para desenvolvimento de sistemas com auto-correção Inserção de elementos de auto-correção ao sistema na fase de design e codificação Elementos posteriormente são utilizados para correções e testes em tempo de execução Desvantagem: é embutido na aplicação
 PANACEA: framework para desenvolvimento de sistemas com auto-correção. Inserção de elementos de auto-correção ao sistema na fase de design e codificação. Elementos posteriormente são utilizados para correções e testes em tempo de execução. Desvantagem: é embutido na aplicação.")
8
Trabalhos Relacionados
Abordagem: Model Based Adaptation Apenas para aplicações com configurações em tempo real

9
Trabalho relacionados de gerência P2P
Madeira Management System Adaptive Management Components (AMC): containers que rodam em um elemento e fazem a sua gerência e se comunicam com outros AMCs ManP2P Management by Delegation: Gerentes podem delegar tarefas uns aos outros Orientado a serviços (peers se organizam de acordo com tarefas que podem realizar) Suporte a propriedades self-* através de módulos autônomos de peers
: containers que rodam em um elemento e fazem a sua gerência e se comunicam com outros AMCs. ManP2P. Management by Delegation: Gerentes podem delegar tarefas uns aos outros. Orientado a serviços (peers se organizam de acordo com tarefas que podem realizar) Suporte a propriedades self-* através de módulos autônomos de peers.")
10
Proposta Peers executam tarefas através de serviços de gerência
Cada serviço tem um identificador único e vários componentes responsáveis pelas tarefas Componentes comunicam a rede seus serviços e fazem sincronia entre si Peers são agrupados de acordo com os serviços que oferecem Podem participar de mais de um grupo

12
Proposta Fornecer propriedade de auto-correção (self-healing) para sistemas P2PBNM Dividido em 2 serviços: monitoramento e correção Monitoramento Verifica periodicamente estados dos componentes e identifica falhas Reporta ao serviço de correção Correção Aguarda por falhas a serem corrigidas

13
Proposta Auto-correção é atrelada ao elemento a ser gerenciado em tempo de execução em 3 passos: Monitoring service identifier: identificador global de requisição de serviço em um grupo de monitoramento

14
Serviço de Monitoramento
Requisição de serviço é uma tupla: (target, workplan, period) Target: elemento a ser monitorado e informações específicas (protocolo da camada de transporte, portas, etc.) Workplan: descrição em alto-nível de como o elemento deve ser monitorado e os parâmetros que identificam seu estado normal e anômalo Period: frequência com que o serviço deve ser monitorado
 Target: elemento a ser monitorado e informações específicas (protocolo da camada de transporte, portas, etc.) Workplan: descrição em alto-nível de como o elemento deve ser monitorado e os parâmetros que identificam seu estado normal e anômalo. Period: frequência com que o serviço deve ser monitorado.")
15
Serviço de Monitoramento
Workplan distribuído entre log2 n peers Peers são então organizados em um anel lógico

16
Serviço de Correção Requisição de serviço é uma tupla:
(target, workplan) Target: especificação do elemento gerenciado a ser corrigido Workplan: descrição em alto nível de como o elemento deve ter suas anomalias tratadas Workplan é replicado entre log2 n peers Caso peer sem workplan necessário seja requisitado este é responsável por encontrar e repassar para um peer que o tenha
 Target: especificação do elemento gerenciado a ser corrigido. Workplan: descrição em alto nível de como o elemento deve ter suas anomalias tratadas. Workplan é replicado entre log2 n peers. Caso peer sem workplan necessário seja requisitado este é responsável por encontrar e repassar para um peer que o tenha.")
17
Interação dos Serviços

18
Interação dos Serviços
Após executar o workplan de correção envia notificação de sucesso ou falha Sucesso → Continua monitoramento Falha → Interrompe monitoramento Caso de substituição do elemento monitorado: Grupo de monitoramento não aborta workplan Grupo de correção recebe notificação e retorna sucesso para monitoramento enviando informações sobre como monitorar novo elemento

19
Implementação Construído sobre o sistema protótipo de gerência P2P: ManP2P-ng Possui mecanismos de auto-organização e manutenção para topologias planas P2P (modelo descentralizado) Descoberta de recursos por inundação Fornece uma API que desenvolvedores de componentes de gerência devem utilizar para integra-los aos peers
 Descoberta de recursos por inundação. Fornece uma API que desenvolvedores de componentes de gerência devem utilizar para integra-los aos peers.")
20
Implementação API: base para mecanismo de auto-correção
Permite instanciação, inicialização e operação dos componentes de gerência Componentes são descritos em XML Fornece noção de grupos (de serviços neste caso)
")
21
Workplan de monitoramento
No evento da recepção da mensagem é checado se há alguma falha, caso positivo o serviço de correção é informado

22
Workplan de Correção Após receber mensagem de detecção de problema executa correção, no exemplo o script healingActivities

23
Estudo de Caso Auto-correção para auxílio de um HIDS (Host-based Instrusion Detection System) HIDS: Monitora e analiza hosts para verificar se estão sendo atacados ou comprometidos Composto por sensores (agentes) que coletam dados sobre hosts onde estão rodando e enviam para gerente Cenários de falha: Sensor falha → sistema deve continuar funcionando normalmente, administrador pode ser notificado Gerente falha → notifica administrador e para sensores
 que coletam dados sobre hosts onde estão rodando e enviam para gerente. Cenários de falha: Sensor falha → sistema deve continuar funcionando normalmente, administrador pode ser notificado. Gerente falha → notifica administrador e para sensores.")
24
Estudo de Caso Problemas:
Parada de parte ou todo serviço Brechas de segurança Necessidade de intervenção manual (inviável para sistemas grandes) Falhas frequentes ou comuns podem ser corrigidas automaticamente
 Falhas frequentes ou comuns podem ser corrigidas automaticamente.")
25
Avaliação Testado em 2 experimentos em uma overlay com 32 peers e nº variável de sensores Avaliado: Tráfego total da gerência da auto-correção Tempo médio de duração Primeiro cenário: workplan de correção executado completamente pelo peer que recebeu notificação do grupo de monitoramento Segundo cenário: workplan executado de modo cooperativo por vários peers

26
1º Experimento – Tráfego

27
2º Experimento – Tempo Médio

28
Conclusão Os resultados mostram a relação de troca entre Trafego x Tempo Plano de correção independente demanda menos recursos Plano de correção cooperativo melhor em situações onde o tempo é crítico

29
Críticas Necessário avaliar proposta em cenários mais complexos e heterogêneos Questões de segurança não foram tratadas Faltaram mais detalhes sobre possíveis erros no sistema de monitoramento/correção

Apresentações semelhantes












>")






