Carregar apresentação
A apresentação está carregando. Por favor, espere

1
Aprendizagem Simbólica
Árvores de Decisão

2
Esquema da apresentação
Representação de árvores de decisão Problemas apropriados para árvores de decisão Algoritmo de Aprendizagem Básico - ID3 Entropia Ganho de Informação Busca no espaço de estado Bias indutivo Problemas do algoritmo ID3 -> C4.5 Exemplos práticos

3
Árvore de Decisão para PlayTennis
<Outlook, Temperature, Humidity, Wind, PlayTenis>

4
Árvore para prever risco de cesariana
Aprendida a partir do registro médico de 1000 mulheres Exemplos Negativos são cesarianas [833+,167-] Fetal_Presentation = 1: [822+,116-] | Previous_Csection = 0: [767+,81-] | | Primiparous = 0: [399+,13-] | | Primiparous = 1: [368+,68-] | | | Fetal_Distress = 0: [334+,47-] | | | | Birth_Weight < 3349: [201+,10.6-] | | | | Birth_Weight >= 3349: [133+,36.4-] | | | Fetal_Distress = 1: [34+,21-] | Previous_Csection = 1: [55+,35-] Fetal_Presentation = 2: [3+,29-] Fetal_Presentation = 3: [8+,22-]

5
Árvores de Decisão Representação de árvores de decisão
Cada nó interno testa um atributo Cada ramo corresponde a um valor do atributo Cada folha atribui uma classificação Como representaríamos: , , XOR (A B) (C D E) M de N
 (C D E) M de N.")
6
Quando usar árvores de decisão?
Instâncias (exemplos) são representadas por pares atributo-valor Função objetivo assume apenas valores discretos Hipóteses disjuntivas podem ser necessárias Conjunto de treinamento possivelmente corrompido por ruído Exemplos: Diagnóstico médico, diagnóstico de equipamentos, análise de crédito
 são representadas por pares atributo-valor. Função objetivo assume apenas valores discretos. Hipóteses disjuntivas podem ser necessárias. Conjunto de treinamento possivelmente corrompido por ruído. Exemplos: Diagnóstico médico, diagnóstico de equipamentos, análise de crédito.")
7
Indução top-down de árvores de decisão (1/2)
Loop principal: 1. A o “melhor” atributo de decisão para o próximo nó 2. Atribua A como atributo de decisão para nó 3. Para cada valor de A, crie um novo descendente para nó 4. Classifique os exemplos de treinamento nos nós folha 5. Se os exemplos de treinamento estão classificados perfeitamente, então PARE, senão comece novamente a partir dos novos nós folha

8
ID3: Algoritmo de aprendizagem
function APRENDIZAGEM_ID3(exemplos,atributos,default) : árvore de decisão if (exemplos é vazio) then return default; else if (todos os exemplos têm a mesma classificação) then return (a classificação); elseif (atributos é vazio) then return maioria(exemplos); else melhor <- ESCOLHA_MELHOR_ATRIBUTO(atributos,exemplos); árvore <- nova árvore com raiz “melhor”; para cada valor vi de melhor faça exemplosi <- exemplos onde melhor = vi; subárvore <- APRENDIZAGEM_DA_ID3(exemplosi, atributos-{melhor}, maioria(exemplos)); adicione subárvore como um ramo à árvore com rótulo vi; return arvore;
 : árvore de decisão. if (exemplos é vazio) then return default; else if (todos os exemplos têm a mesma classificação) then return (a classificação); elseif (atributos é vazio) then return maioria(exemplos); else. melhor <- ESCOLHA_MELHOR_ATRIBUTO(atributos,exemplos); árvore <- nova árvore com raiz melhor ; para cada valor vi de melhor faça. exemplosi <- exemplos onde melhor = vi; subárvore <- APRENDIZAGEM_DA_ID3(exemplosi, atributos-{melhor}, maioria(exemplos)); adicione subárvore como um ramo à árvore com. rótulo vi; return arvore;")
9
Indução top-down de árvores de decisão (2/2)
Qual é o melhor atributo? [29+ , 35-] [21+, 5-] [8+, 30-] A2=? [18+ , 33-] [11+ , 2-] A1=?

10
Entropia (1/3) S é uma amostra dos exemplos de treinamento
p é a proporção de exemplos positivos em S p é a proporção de exemplos negativos em S Entropia mede a “impureza” de S: Entropia(S)=- p log2 p - p log2 p
=- p log2 p - p log2 p")
11
Entropia (2/3) Entropia(S)=especifica o nr. mínimo de bits de informação necessário para codificar uma classificação de um membro arbitrário de S. Por quê? Teoria da Informação: códigos de comprimento ótimo atribui -log2p bits para mensagens que possuem probabilidade p

12
Entropia (3/3) Portanto, o nr. de bits esperados para codificar ou de elementos aleatórios de S: p (-log2 p) + p (-log2 p) Entropia(S)=- p log2 p - p log2 p
 + p (-log2 p) Entropia(S)=- p log2 p - p log2 p")
13
Entropia - Exemplo I Se p é 1, o destinatário sabe que o exemplo selecionado será positivo Nenhuma mensagem precisa ser enviada Entropia é 0 (mínima) Se p é 0.5, um bit é necessário para indicar se o exemplo selecionado é ou Entropia é 1 (máxima) Se p é 0.8, então um coleção de mensagens podem ser codificadas usando-se - em média menos de um bit - códigos mais curtos para e mais longos para
 Se p é 0.5, um bit é necessário para indicar se o exemplo selecionado é ou Entropia é 1 (máxima) Se p é 0.8, então um coleção de mensagens podem ser codificadas usando-se - em média menos de um bit - códigos mais curtos para e mais longos para ")
14
Entropia - Gráfico

15
Entropia - Exemplo I Suponha que S é uma coleção de 14 exemplos, incluindo 9 positivos e 5 negativos Notação: [9+,5-] A entropia de S em relação a esta classificação booleana é dada por:

16
Critério de ganho (1/2) Gain(S,A)=redução esperada da entropia devido a “classificação” de acordo com A
 Gain(S,A)=redução esperada da entropia devido a classificação de acordo com A.")
17
Critério de ganho (2/2) Usar o critério de ganho para decidir!
[29+ , 35-] [21+, 5-] [8+, 30-] A2=? [18+ , 33-] [11+ , 2-] A1=?

18
Critério de ganho - Exemplo (1/2)
Suponha que S é uma coleção de exemplos de treinamento ([9+,5-]) descritos por atributos incluindo Wind, que pode ter os valores Weak and Strong.
 descritos por atributos incluindo Wind, que pode ter os valores Weak and Strong.")
19
Critério de ganho - Exemplo (2/2)
")
20
Exemplos de treinamento (1/3)
Considere a tarefa de aprendizagem representada pelos exemplos de treinamento na tabela abaixo, onde o objetivo é prever o atributo PlayTenis baseando-se nos outros atributos

21
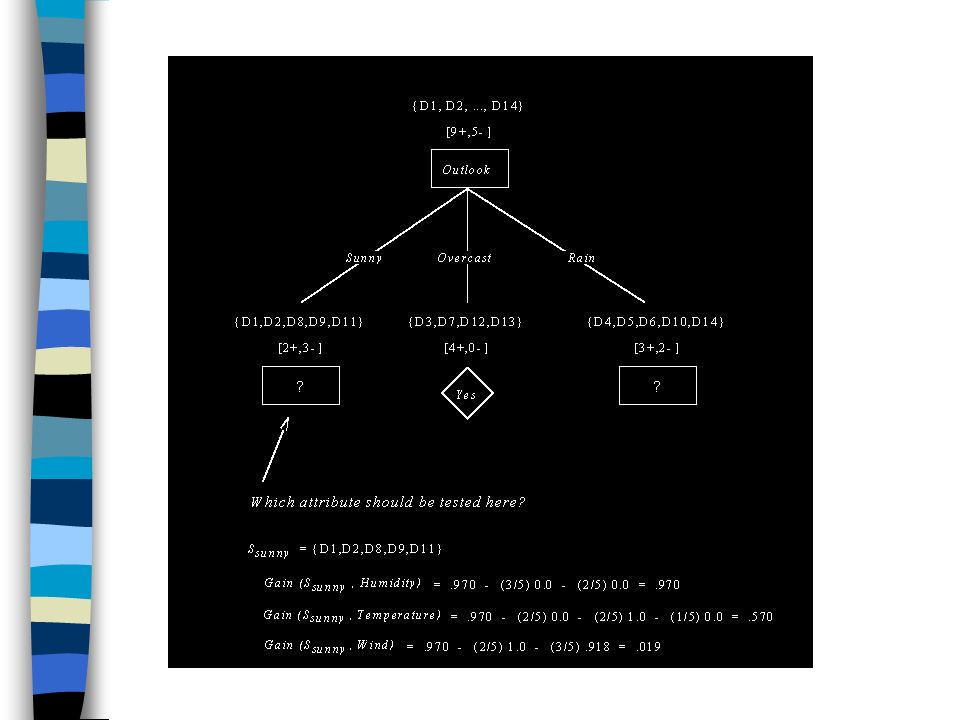
Exemplos de treinamento (1/3)
Que atributo deve ser selecionado para ser a raiz da árvore? Gain(S,Outlook) = 0.246 Gain(S,Humidity) = 0.151 Gain(S,Wind) = 0.048 Gain(S,Temperature) = 0.029 onde S denota a coleção de exemplos na tabela anterior
 = Gain(S,Humidity) = Gain(S,Wind) = Gain(S,Temperature) = onde S denota a coleção de exemplos na tabela anterior.")
23
Busca no espaço de hipóteses - ID3

24
Busca no espaço de hipóteses por ID3
Espaço de hipóteses completo A função objetivo com certeza está contido nele Tem como saída uma única hipótese (qual?) Não pode lidar com várias perguntas.... Não há backtracking Mínimo local Escolhas para busca baseadas em estatística Robusto contra dados com ruído Inductive bias: aprox “prefere a menor árvore”
 Não pode lidar com várias perguntas.... Não há backtracking. Mínimo local. Escolhas para busca baseadas em estatística. Robusto contra dados com ruído. Inductive bias: aprox prefere a menor árvore")
25
Inductive bias em ID3 Note que H é conjunto das partes de instâncias X
Não tendencioso? Não exatamente... Preferência por árvores curtas, e por aquelas com atributos com alto ganho de informação próximos à raiz Bias é uma preferência por algumas hipótese, ao invés de uma restrição do espaço de hipóteses H Occam´s razor: preferir a hipótese mais simples que se ajuste aos dados

26
Occam´s razor (1/2) Heurística de Occam´s Razor: preferir a hipótese mais simples que que se ajuste aos dados Por quê preferir hipóteses mais simples a mais complexas? Raciocínio comum: Há muito menos hipóteses mais simples, portanto é menos provável que seja uma coincidência se uma dessas hipótese se ajustar aos dados

27
Occam´s razor (2/2) Argumentos contra:
Porém existem vários conjuntos pequenos de hipóteses sem sentindo! e.g., todas as árvores com um número primo de nós que usam o atributo começando por “Z” Então, o que há de tão especial sobre conjuntos pequenos baseados no tamanho (complexidade) das hipóteses? A complexidade de uma hipótese depende da representação usada durante a aprendizagem
 das hipóteses A complexidade de uma hipótese depende da representação usada durante a aprendizagem.")
28
Overfitting em árvores de decisão
Suponha que adicionamos um exemplo de treinamento com ruído #15: Sunny, Hot, Normal, Strong, PlayTennis=No Qual seria seu efeito na árvore anterior:

29
Overfitting Considere o erro da hipótese h sobre
dados do treinamento: errotrain(h) distribuição completa D dos dados: erroD(h) Uma hipótese h H “overfits” o conjunto de dados se há uma hipótese alternativa h´ H tal que errotrain(h) < errotrain(h´) e erroD(h) > erroD(h´)
 distribuição completa D dos dados: erroD(h) Uma hipótese h H overfits o conjunto de dados se há uma hipótese alternativa h´ H tal que. errotrain(h) < errotrain(h´) e. erroD(h) > erroD(h´)")
30
Overfitting na aprendizagem de árvores de decisão (1/2)
")
31
Overfitting na aprendizagem de árvores de decisão (2/2)
Como evitar overfitting? Parar o crescimento da árvore quando a divisão dos dados não é estatisticamente significativa Deixar a árvore crescer completamente para, então, poda-la (post-prune) Como escolher a “melhor” árvore: Medir a performance sobre o cj. de dados treinamento Medir a performance sobre um cj. de dados (separado) de validação MDL: minimizar - size(tree)+size(misclassification(tree))
 Como escolher a melhor árvore: Medir a performance sobre o cj. de dados treinamento. Medir a performance sobre um cj. de dados (separado) de validação. MDL: minimizar - size(tree)+size(misclassification(tree))")
32
Reduzindo o erro através da poda
Divida os dados em cj. de treinamento e validação Faça até que uma poda adicional seja prejudicial: 1. Avalie o impacto sobre o cj. de validação de podar cada nó possível (e seus descendentes) 2. Gulosamente remova aquele que melhora mais a performance no cj. de validação Produz a menor versão da sub-árvore mais precisa E se os dados são limitados?
 2. Gulosamente remova aquele que melhora mais a performance no cj. de validação. Produz a menor versão da sub-árvore mais precisa. E se os dados são limitados")
33
Efeito do uso da técnica de poda

34
Podando as regras 1. Converta a árvore para um conjunto equivalente de regras 2. Pode cada regra independentemente umas das outras 3. Ordene as regras finais em uma seqüência deseja para uso Estes é um dos métodos mais utilizados (e.g., C4.5)
")
35
Convertendo uma árvore em regras

36
Convertendo uma árvore em regras
IF (Outlook = Sunny) (Humidity = High) THEN PlayTennis = No IF (Outlook = Sunny) (Humidity = Normal) THEN PlayTennis = YES
 (Humidity = High) THEN PlayTennis = No. IF (Outlook = Sunny) (Humidity = Normal) THEN PlayTennis = YES")
37
Atributos com valores contínuos
Crie um atributo discreto para testar um que seja contínuo Temperature = 82.5 (Temperature > 72.3) = t,f Temperature: PlayTennis: NO NO YES YES YES NO
 = t,f. Temperature: PlayTennis: NO NO YES YES YES NO.")
38
Atributos com vários valores (1/2)
Problema: Se o atributo tem vários valores, Gain o selecionará Suponha o uso de Date = 3/06/00 como atributo Um abordagem: use GainRatio

39
Atributos com vários valores (2/2)
Onde Si é um subconjunto de S para o qual A tem valor vi

40
Atributos com custo Considere
Diagnóstico médico, BloodTest tem custo R$500 Robótica, Width_from_1ft tem custo 23 sec. Como aprender uma árvore consistente com um valor de custo esperado baixo? Uma abordagem: substitua Gain por:

41
Atributos com custo (2/2)
Tan e Schlimmer (1990) Nunez (1988) Onde w [0,1] determinar a importância do custo
 Nunez (1988) Onde w [0,1] determinar a importância do custo.")
42
Valores de atributo desconhecidos (1/2)
E se valores do atributo A estão faltando para alguns exemplos? Mesmo assim use os exemplos de treinamento, e organize a árvore como segue: Se um nó n testa A, atribua um valor para A que seja o mais comum entre os outros exemplos classificados nó n Atribua para A um valor que seja o mais comum entre os outros exemplos com o mesmo valor objetivo (target value)
")
43
Valores de atributo desconhecidos (2/2)
Atribua uma probabilidade pi para cada valor possível vi de A atribua uma fração pi de exemplos para cada descendente da árvore Classifique exemplos novos da mesma maneira

44
Exemplos Práticos GASOIL
Sistema de separação de gás-óleo em plataformas de petróleo Sistema de 10 pessoas-ano se baseado em regras Desenvolvido em 100 pessoas-dia Piloto automático de um Cessna Treinado por três pilotos Obteve um desempenho melhor que os três Mineração de dados Recuperação de Informação

45
Redes Neurais X Árvores de Decisão
Algoritmo TREPAN Representa uma rede neural através de uma árvore de decisão Algoritmo geral de extração de conhecimento de redes neurais

Apresentações semelhantes










>")





>")


