Carregar apresentação
A apresentação está carregando. Por favor, espere

1
Extração da Informação Cirdes Borges, Flávio Dantas, Rafael Barbosa, Samuel Arcoverde, Tiago Rocha Modificado por Flávia Barros

2
Índice Motivação Introdução Processo de extração da informação Abordagens para um sistema de EI Desafios Conclusão

3
Motivação Problema: Vasta quantidade de documentos textuais na Web Como apresentar ao usuário apenas o que interessa? Como transmitir os dados entre Web services e bases de dados existentes? Necessário definir templates

4
Motivação O que se quer? Respostas relevantes para o usuário Não apenas links para documentos Gerar resumos/sumários de textos Minerar dados Preencher Base de dados e Bases de conhecimento

5
Introdução Sistemas de Extração de informação (EI) visam Localizar e extrair,informações relevantes em um documento ou uma coleção de documentos De forma automática A fim de preencher um template de saída.
 visam Localizar e extrair,informações relevantes em um documento ou uma coleção de documentos De forma automática A fim de preencher um template de saída.")
6
Extração de informação Trata o problema de extração de dados relevantes a partir de uma coleção de documentos. Os dados a serem extraídos são previamente definidos em um template (formulário) Criação Dos slots Documento com tags Tabelas com campos pré- definidos ou templates
 Criação Dos slots Documento com tags Tabelas com campos pré- definidos ou templates.")
7
Extração de informação Sistema de Extração de Informação

8
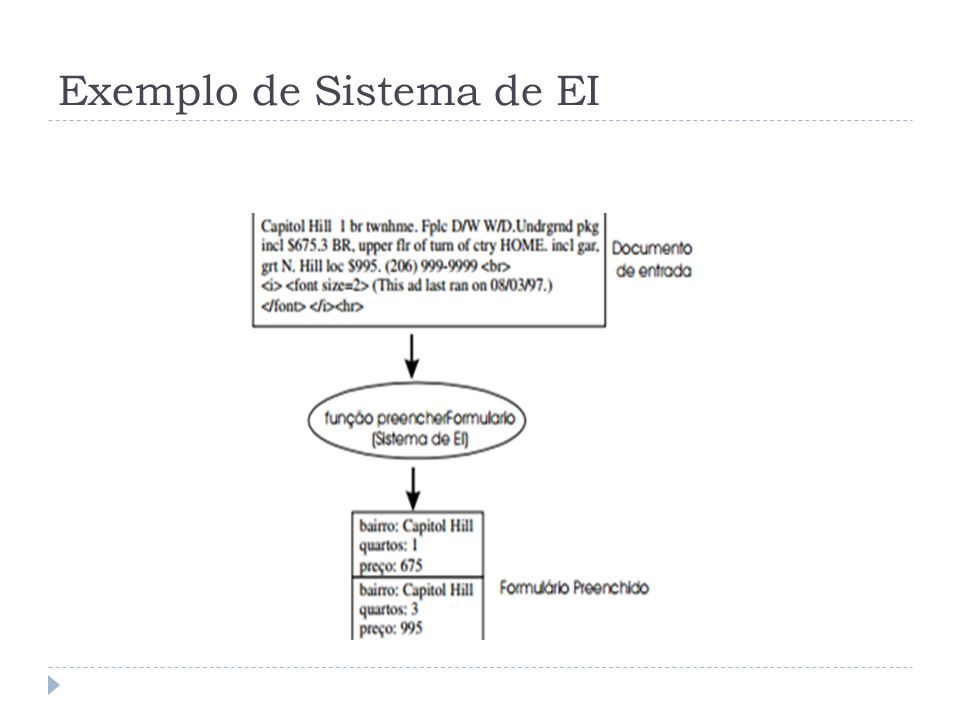
Exemplo de Sistema de EI

10
RI x EI Recuperação de Informação Recupera documentos relevantes baseando-se em cálculos estatísticos sobre os termos que ocorrem no documento. Visualiza o documento apenas como um conjunto de palavras. Extração de Informação Extrai informações relevantes baseando-se no domínio de conhecimento do documento Filtra o resultado de uma tarefa de RI graças a restrição do domínio Busca derivar conhecimento dos documentos recuperados segundo a estruturada do documento.

11
Breve História JASPER (1980s) Sistema para finanças MUC-Message Understanding Conference [final da década de 80] Internet/Web [década de 90]
![Breve História JASPER (1980s) Sistema para finanças MUC-Message Understanding Conference [final da década de 80] Internet/Web [década de 90]](http://images.slideplayer.com.br/27/9252718/slides/slide_11.jpg "Breve História JASPER (1980s) Sistema para finanças MUC-Message Understanding Conference [final da década de 80] Internet/Web [década de 90]")
12
Abordagens para Sistema de EI Observamos nos sistemas de Extração de Informação a distinção entre duas abordagens: Engenharia de conhecimento Aprendizagem de Máquina As abordagens são diferenciadas pela forma com que as regras são definidas

13
Engenharia de conhecimento Construção de regras é feita manualmente. Requer que um especialista em sistemas de Extração de Informação participe efetivamente da criação das regras. Construção baseada no conhecimento que o engenheiro possui do cenário e domínio com o qual vai trabalhar. Precisão nos resultados é maior. O tempo de desenvolvimento é maior Possibilita reuso de regras e extensibilidade Para lidar com pequenas mudanças no template Alana Brito – Fernando Rodrigues – Josias Barbosa 05/05/2010

14
Aprendizagem de Máquina Utiliza algoritmos de Inteligência Artificial Algoritmos de treinamento automático Para indução de regras de extração Um corpus de documentos etiquetados é usado para treinamento e vallidação das regras induzidas Tempo menor de desenvolvimento Boa precisão nos resultados Difícil adaptação a novos domínios/problemas (reuso) Requer novo processo de treinamento
 Requer novo processo de treinamento")
15
Tipos de texto e Técnicas para EI A técnica mais adequada para construir o sistema de EI depende do tipo do texto a ser tratado Processamento de Linguagem Natural – PLN Textos livres Wrappers Textos estruturados com formato predefinido e rígido Textos semi estruturados permitem a ocorrência de variações na ordem e no formato dos dados E.g., notícias de classificados de jornal

16
Processamento de Linguagem Natural – PLN Utilizado no tratamento de documentos com pouco ou nenhum grau de estruturação Caracteriza-se pela análise e manipulação ou codificação de informações expressas em língua natural

17
PLN – Níveis de Análise Nível Morfológico Estuda a constituição das palavras em seus elementos básicos; Nível Sintático Determina a relação entre as palavras em uma sentença (papel) Nível Semântico Determina o significado e inter-relacionamento semântico das palavras Nível Discursivo Estuda as relações entre sentenças Nível Pragmático Estuda o objetivo do uso da língua
 Nível Semântico Determina o significado e inter-relacionamento semântico das palavras Nível Discursivo Estuda as relações entre sentenças Nível Pragmático Estuda o objetivo do uso da língua")
18
Nível Morfológico A análise Morfológica determina: O radical + sufixo da palavra, e geralmente constrói um dicionário adicionando informações relacionadas como: Classe da palavra Conjugação Pessoa A análise morfológica pode ser implementada através de algorítmos baseados em regras eats eat + s verbo, singular, 3rd pers dog dog nome, singular

19
Nível Sintático A análise sintática faz uso do dicionário gerado pela análise morfológica procurando mostrar relacionamento entre palavras. As palavras que apresentam apenas um sentido possível podem ser substituídas pela sua representação semântica Tem como saída a representação da sentença que representa as dependências entre palavras As sentenças de exemplo apenas diferem na sintáxi e apresentam significados diferentes ‘The dog chased the cat.’ ‘The cat chased the dog.’

20
Nível Semântico Não é apenas neste nível que o significado é determinado, todos os níveis contribuem para a determinação do significado O nível semântico determina o possível significado de uma sentença, focando nas interações entre os significados das palavras na sentença Desambigüidade semântica A cabeça une-se ao tronco pelo pescoço Ele é o cabeça da rebelião Sabrina tem boa cabeça

21
Nível Discursivo Analisa textos maiores que sentenças Foca nas propriedades do texto como um todo, determinando significado através das conexões de sentenças Resolução de Anáfora: Substituição de pronomes pelas entidades que eles referenciam Reconhecimento de Estrutura de Texto: Em um jornal temos; Artigos de capa, opniões, eventos passados, anúcios

22
Nível Pragmático Foca no significado que vai além do contexto do texto Requer um conhecimento global Os exemplos seguintes utilizam anáforas mas as resoluções necessitam de um conhecimento global Os vereadores recusaram receber os manifestantes, porque eles temiam o confronto Os vereadores recusaram receber os manifestantes, porque eles defendiam a revolução.

23
Processo de extração de informação Documento Analisador sintático/semântico Integração e preenchimento de templates Templates preenchidos Processador léxico Analisador do discurso Reconhecimento de nomes Padrões de extração

24
Processo de extração de informação EI Microsoft Corporation CEO Bill Gates Microsoft Gates Microsoft Bill Veghte Microsoft VP Richard Stallman founder Free Software Foundation Microsoft Corporation CEO Bill Gates Microsoft Gates Microsoft Bill Veghte Microsoft VP Richard Stallman founder Free Software Foundation Cluster A Cluster B Cluster C

25
Problemas com sistemas de PLN Maior desenvolvimento da WEB nos anos 90... Necessidade de sistemas mais eficientes Sistemas baseados em PLN são computacionalmente caros Baixa precisão nos resultados Devido à imprecisão e à flexibilidade das línguas naturais

26
Wrappers Extraem informação de documentos A fim de preencher templates Relembrando... Textos estruturados com formato predefinido e rígido Textos semi estruturados permitem a ocorrência de variações na ordem e no formato dos dados Utilizam dados sobre a formatação do texto, marcadores, freqüência estatística das palavras, etc.

27
Wrappers - Técnicas de Extração Autômatos finitos Casamento de padrões Classificadores de texto Modelos de Markov escondidos (HMM)
")
28
Autômatos Finitos Regras de extração na forma de autômatos finitos Bons para textos estruturados e semi estruturados Definidos manualmente ou aprendidos automaticamente. Definidos por: Estados que “aceitam” os símbolos do texto que preenchem algum campo do fórmulario de saída Os estados que apenas consomem os símbolos irrelevantes encontrados no texto Os símbolos que provocam as transições de estado

29
Autômatos Finitos

30
Casamento de Padrões Padrões descritos através de expressões regulares (ER) que “casam” com o texto para extrair as informações. ER mais intuitivas do que autômatos. Exemplo:

31
Classificadores de Texto Textos semi-estruturados Documento é dividido em fragmentos podendo utilizar várias características de cada segmento para a classificação tamanho, posição, formatação, presença de palavras Desvantagem: realiza classificação local independente para cada fragmento, erdendo informações estruturais importantes do documento

32
Classificadores de Texto Classificam fragmentos do documento para determinar que campo do fórmulario eles devem preencher

33
Classificadores de Texto

34
Modelos de Markov Escondidos (HMM) Textos livres e semi-estruturados. Verifica a ocorrência de padrões em sequência no texto de entrada. Maximiza a probabilidade de acerto para o conjunto todo de padrões.

35
Modelos de Markov Escondidos (HMM) É um autômato finito probabilístico que consiste em: Um conjunto de estados ocultos Uma probabilidade de transição entre os estados ocultos Um conjunto de símbolos emitidos pelos estados ocultos Uma distribuição de probabilidade de emissão de cada símbolo que pertence ao conjunto de símbolos para cada estado oculto Processo de classificação Algoritmo de Viterbi Retorna a sequência de estados ocultos com maior probabilidade de ter emitido cada sequência de símbolos de entrada.
 É um autômato finito probabilístico que consiste em: Um conjunto de estados ocultos Uma probabilidade de transição entre os estados ocultos Um conjunto de símbolos emitidos pelos estados ocultos Uma distribuição de probabilidade de emissão de cada símbolo que pertence ao conjunto de símbolos para cada estado oculto Processo de classificação Algoritmo de Viterbi Retorna a sequência de estados ocultos com maior probabilidade de ter emitido cada sequência de símbolos de entrada.")
36
Modelos de Markov Escondidos (HMM)
")
37
Vantagens Classificação ótima para a sequência de entrada Desvantagens Não é capaz de fazer uso de múltiplas características de Tokens por exemplo, formatação, tamanho e posição

38
Construção de Wrappers Automática Define regras de extração com um corpus de treinamento com de técnicas de aprendizagem de máquina. Semi-automática Auxiliado por ferramentas, o usuário especifica a estrutura e o contexto dos dados a serem extraídos. Manual Mais demorada e trabalhosa, porém com maior precisão nos dados extraídos.

39
PLN x Wrappers

40
Desafios Técnicas de Extração “Dividir pra Conquistar” Linguagem natural Idiomas Métricas de avaliação Classificar stop words Apredizagem de Máquina

41
Desafios Ontologias Acesso do Usuário Conteúdo preciso, claro Padrões de Ontologia

42
Aplicações de EI Filtragem de Fóruns Controle de Conteúdo Assunto do Dialogo Monitoramento da WEB Buscar por Hackers Busca por Terroristas

43
Aplicações de EI Extração de Informações Estratégicas Inteligência de Negócios Análise de mercado Análise de Arquivos de LOG Análise de LOGs de erro Análise de LOGs de acesso

44
Conclusões Extrair Informação é preciso Web é um pandemônio de informações Precisamos de soluções inteligentes

45
Dúvidas

46
Referências MANFREDINI, V. H.; Proposta de uma Técnica de Extração de Informação de Arquivos de Log de Servidores Proxy Silva, E. F. A.; Barros, F. A.; Prudencio, R. B. C.; Uma Abordagem de Aprendizagem Híbrida para Extração de Informação em Textos Semi-Estruturados http://en.wikipedia.org/wiki/Information_extraction http://en.wikipedia.org/wiki/Information_extraction Liddy, E. D. In Encyclopedia of Library and Information Science, 2nd Ed. Marcel Decker, Inc http://www.cnlp.org/publications/03NLP.LIS.Encyclopedia. pdf http://www.cnlp.org/publications/03NLP.LIS.Encyclopedia. pdf

47
Referências Schneider O. M., Rosa, L.J., Processamento de Linguagem Natural (PLN), http://moschneider.tripod.com/pln.pdfhttp://moschneider.tripod.com/pln.pdf Aranha C., Passos E. A Tecnologia de Mineração de Textos, PUC-RIO Bulegon H., Moro M. C. C., Text Mining and Natural Language Processing in Discharge Summaries, PPGTS,PUCPR http://143.54.31.10/reic/edicoes/2003e2/tutoriais/Minerac aoNaWeb.pdf
, Aranha C., Passos E. A Tecnologia de Mineração de Textos, PUC-RIO Bulegon H., Moro M. C. C., Text Mining and Natural Language Processing in Discharge Summaries, PPGTS,PUCPR aoNaWeb.pdf.")
48
Referências www.cin.ufpe.br/~if796/2006-1/ExtracaoInformacao.ppt www.cin.ufpe.br/~if796/2006-1/ExtracaoInformacao.ppt http://sare.unianhanguera.edu.br/index.php/rcext/article/vi ewFile/413/409 MELO, Taciana. Um Sistema Especialista para Extração e Classificação de Receitas Culinárias em Páginas Eletrônicas. Trabalho de Conclusão de Curso. UFPE, CIn. 2000. - www.cin.ufpe.br/~tg/2000-2/tmlm.docwww.cin.ufpe.br/~tg/2000-2/tmlm.doc

Apresentações semelhantes