Carregar apresentação
A apresentação está carregando. Por favor, espere

1
Sistemas Distribuídos
Silvia Cristina Sardela Bianchi

2
Agenda Publish-Subscribe Peer-to-Peer Computação em Grade
Computação em Nuvem 2

3
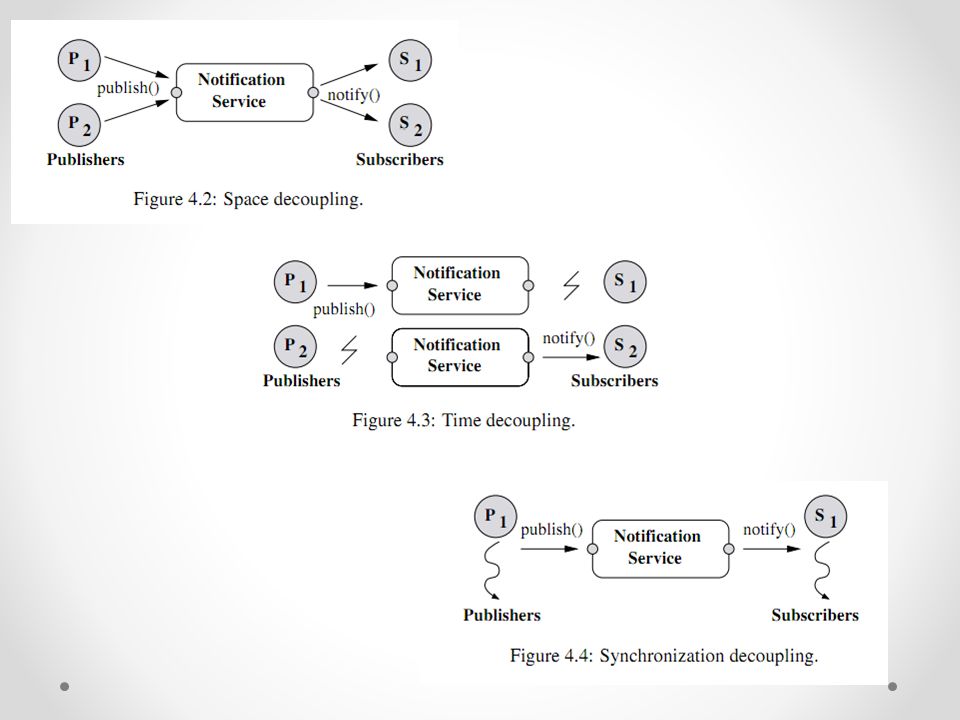
Publish-Subscribe Os modelos de comunicação indireta como os sistemas Publicação-Subscrição têm emergido como uma alternativa ao modelo de comunicação direta, ou seja, Pedido-Resposta. A principal vantagem do paradigma de comunicação indireta consiste no desacoplamento entre participantes, que não necessitam de ter conhecimento quer da localização, quer do número de elementos existentes no sistema.

4
Publish-Subscribe

6
Topic-based Publish-Subscribe

7
Content-based Publish-Subscribe

8
RSS Feeds A tecnologia do RSS permite aos usuários da internet se inscreverem em sites que fornecem "feeds" RSS. Estes são tipicamente sites que mudam ou atualizam o seu conteúdo regularmente. Para isso, são utilizados Feeds RSS que recebem estas atualizações, desta maneira o utilizador pode permanecer informado de diversas atualizações em diversos sites sem precisar visitá-los um a um. Os feeds RSS oferecem conteúdo Web ou resumos de conteúdo juntamente com os links para as versões completas deste conteúdo e outros metadados. Esta informação é entregue como um arquivo XML chamado "RSS feed", "webfeed", "Atom" ou ainda canal RSS.

9
Sistemas P2P Não-Estruturados
Quem tem este artigo? Eu tenho Grafo aleatório Cada nó indexa apenas o conteúdo que compartilha Cada nó mantém a lista dos vizinhos Simplicidade A rede é inundada com a busca Não garante a busca do conteúdo pesquisado. Any new peer that joins the network contacts an existing peer and copies its neighbor’s list. For resource discovering in the network, these systems support different search mechanisms. The straightforward mechanism is to flood the request in the network, as shown in Figure 2.1. The peer forwards the request to all its neighbors, which each of them will forward to its neighbors and so on. If the requested resource is not found, the forwarding procedure will be interrupted after a limited number of retransmissions. Normally, the number of steps can be determined by the Time-To-Live (TTL), as used in Gnutella [50], or Hops-To-Live (HTL), as used in Freenet [32]. The choice of an appropriate value of TTL or HTL affects the message overhead during the search. A high value generates unnecessary traffic and a low value may result on unsuccessful search even if the resource is available in the network. Therefore, the TTL should be high enough to guarantee that the search is successful. This generates a high amount of traffic [73]. In case of a highly connected graph in which nodes have a high degree, i.e., nodes have many communication links, the average number of hops necessary for the search decreases [107]. This allows minimizing the TTL, but it may generate an excessive number of duplicate messages thus increasing even more the overhead. In order to ensure that a search is successful, all the nodes should be addressed, generating O(N) messages, where N is the total number of nodes in the system. In order to cope with the message overhead, different mechanisms have been proposed to improve the search strategy. These include random walks (see Figure 2.2) [49, 73], percolation-based search [94] and bloom filters-based search [69]. Most of them try to reduce the search time from O(N) to O(log(N)). In random walks (see Figure 2.2), the nodes forward the request to a randomly chosen node. However, this routing approach still requires a mechanism to terminate the request. As in flooding, a TTL is used to limit the number of messages forwarded, and, in addition to that, it may use a check mechanism [73]. The check mechanism tries to reduce even more the traffic by performing periodically checks to the requesting node, by the forwarding nodes, before forwarding the request. While random walks usually generate fewer messages during the search, flooding provides a better response time. For any of these approaches, resources available at several nodes are more likely to be found, but if the object is stored in only few peers, there is a high probability that the search will be unsuccessful. Since such systems give no control over resource placement, the peers have no knowledge about other peers’ contents. Thus, if a search was not successful, it does not mean that the resource is not available in the network. On the other hand, the fact that these systems give no control over nodes’ placements, i.e., the communication links are established arbitrary, they can be easily built and maintained. INPE 14 de abril 2011 9 9
, as used in Gnutella [50], or Hops-To-Live (HTL), as used in Freenet [32]. The choice of an appropriate value of. TTL or HTL affects the message overhead during the search. A high value generates unnecessary. traffic and a low value may result on unsuccessful search even if the resource. is available in the network. Therefore, the TTL should be high enough to guarantee that. the search is successful. This generates a high amount of traffic [73]. In case of a highly. connected graph in which nodes have a high degree, i.e., nodes have many communication. links, the average number of hops necessary for the search decreases [107]. This allows. minimizing the TTL, but it may generate an excessive number of duplicate messages thus. increasing even more the overhead. In order to ensure that a search is successful, all the. nodes should be addressed, generating O(N) messages, where N is the total number of. nodes in the system. In order to cope with the message overhead, different mechanisms have been proposed. to improve the search strategy. These include random walks (see Figure 2.2) [49, 73], percolation-based search [94] and bloom filters-based search [69]. Most of them try to. reduce the search time from O(N) to O(log(N)). In random walks (see Figure 2.2), the nodes forward the request to a randomly chosen. node. However, this routing approach still requires a mechanism to terminate the request. As in flooding, a TTL is used to limit the number of messages forwarded, and, in addition. to that, it may use a check mechanism [73]. The check mechanism tries to reduce. even more the traffic by performing periodically checks to the requesting node, by the forwarding. nodes, before forwarding the request. While random walks usually generate fewer. messages during the search, flooding provides a better response time. For any of these approaches, resources available at several nodes are more likely to be. found, but if the object is stored in only few peers, there is a high probability that the search. will be unsuccessful. Since such systems give no control over resource placement, the peers. have no knowledge about other peers’ contents. Thus, if a search was not successful, it does. not mean that the resource is not available in the network. On the other hand, the fact that. these systems give no control over nodes’ placements, i.e., the communication links are. established arbitrary, they can be easily built and maintained. INPE. 14 de abril")
10
Sistemas P2P Estruturados
Idéia Atribuir aos nós participantes os conteúdos (ou index) Quando um nó procura por um conteúdo, direciona a procura ao nó que contém o objeto Desafios Evitar gargalhos: distribuir de forma uniforme as responsabilidades entre os nós participantes Adaptação quando nós entram e saem do sistema Atribuir responsabilidades aos nós que entram Redistribuir responsabilidades dos nós que partem INPE 14 de abril 2011 10
 Quando um nó procura por um conteúdo, direciona a procura ao nó que contém o objeto. Desafios. Evitar gargalhos: distribuir de forma uniforme as responsabilidades entre os nós participantes. Adaptação quando nós entram e saem do sistema. Atribuir responsabilidades aos nós que entram. Redistribuir responsabilidades dos nós que partem. INPE. 14 de abril")
11
Sistemas P2P Estruturados: Distributed Hash Tables
P2P for dummies Learn English in 1 Step Any new peer that joins the network contacts an existing peer and copies its neighbor’s list. For resource discovering in the network, these systems support different search mechanisms. The straightforward mechanism is to flood the request in the network, as shown in Figure 2.1. The peer forwards the request to all its neighbors, which each of them will forward to its neighbors and so on. If the requested resource is not found, the forwarding procedure will be interrupted after a limited number of retransmissions. Normally, the number of steps can be determined by the Time-To-Live (TTL), as used in Gnutella [50], or Hops-To-Live (HTL), as used in Freenet [32]. The choice of an appropriate value of TTL or HTL affects the message overhead during the search. A high value generates unnecessary traffic and a low value may result on unsuccessful search even if the resource is available in the network. Therefore, the TTL should be high enough to guarantee that the search is successful. This generates a high amount of traffic [73]. In case of a highly connected graph in which nodes have a high degree, i.e., nodes have many communication links, the average number of hops necessary for the search decreases [107]. This allows minimizing the TTL, but it may generate an excessive number of duplicate messages thus increasing even more the overhead. In order to ensure that a search is successful, all the nodes should be addressed, generating O(N) messages, where N is the total number of nodes in the system. In order to cope with the message overhead, different mechanisms have been proposed to improve the search strategy. These include random walks (see Figure 2.2) [49, 73], percolation-based search [94] and bloom filters-based search [69]. Most of them try to reduce the search time from O(N) to O(log(N)). In random walks (see Figure 2.2), the nodes forward the request to a randomly chosen node. However, this routing approach still requires a mechanism to terminate the request. As in flooding, a TTL is used to limit the number of messages forwarded, and, in addition to that, it may use a check mechanism [73]. The check mechanism tries to reduce even more the traffic by performing periodically checks to the requesting node, by the forwarding nodes, before forwarding the request. While random walks usually generate fewer messages during the search, flooding provides a better response time. For any of these approaches, resources available at several nodes are more likely to be found, but if the object is stored in only few peers, there is a high probability that the search will be unsuccessful. Since such systems give no control over resource placement, the peers have no knowledge about other peers’ contents. Thus, if a search was not successful, it does not mean that the resource is not available in the network. On the other hand, the fact that these systems give no control over nodes’ placements, i.e., the communication links are established arbitrary, they can be easily built and maintained. How I Met Your Mother Grey’s Anatomy INPE 14 de abril 2011 11 11
, as used in Gnutella [50], or Hops-To-Live (HTL), as used in Freenet [32]. The choice of an appropriate value of. TTL or HTL affects the message overhead during the search. A high value generates unnecessary. traffic and a low value may result on unsuccessful search even if the resource. is available in the network. Therefore, the TTL should be high enough to guarantee that. the search is successful. This generates a high amount of traffic [73]. In case of a highly. connected graph in which nodes have a high degree, i.e., nodes have many communication. links, the average number of hops necessary for the search decreases [107]. This allows. minimizing the TTL, but it may generate an excessive number of duplicate messages thus. increasing even more the overhead. In order to ensure that a search is successful, all the. nodes should be addressed, generating O(N) messages, where N is the total number of. nodes in the system. In order to cope with the message overhead, different mechanisms have been proposed. to improve the search strategy. These include random walks (see Figure 2.2) [49, 73], percolation-based search [94] and bloom filters-based search [69]. Most of them try to. reduce the search time from O(N) to O(log(N)). In random walks (see Figure 2.2), the nodes forward the request to a randomly chosen. node. However, this routing approach still requires a mechanism to terminate the request. As in flooding, a TTL is used to limit the number of messages forwarded, and, in addition. to that, it may use a check mechanism [73]. The check mechanism tries to reduce. even more the traffic by performing periodically checks to the requesting node, by the forwarding. nodes, before forwarding the request. While random walks usually generate fewer. messages during the search, flooding provides a better response time. For any of these approaches, resources available at several nodes are more likely to be. found, but if the object is stored in only few peers, there is a high probability that the search. will be unsuccessful. Since such systems give no control over resource placement, the peers. have no knowledge about other peers’ contents. Thus, if a search was not successful, it does. not mean that the resource is not available in the network. On the other hand, the fact that. these systems give no control over nodes’ placements, i.e., the communication links are. established arbitrary, they can be easily built and maintained. How I Met Your Mother. Grey’s Anatomy. INPE. 14 de abril")
12
Sistemas P2P Estruturados: Distributed Hash Tables
Quem tem “How I Met Your Mother”? P2P for dummies Grey’s Anatomy Eu tenho Any new peer that joins the network contacts an existing peer and copies its neighbor’s list. For resource discovering in the network, these systems support different search mechanisms. The straightforward mechanism is to flood the request in the network, as shown in Figure 2.1. The peer forwards the request to all its neighbors, which each of them will forward to its neighbors and so on. If the requested resource is not found, the forwarding procedure will be interrupted after a limited number of retransmissions. Normally, the number of steps can be determined by the Time-To-Live (TTL), as used in Gnutella [50], or Hops-To-Live (HTL), as used in Freenet [32]. The choice of an appropriate value of TTL or HTL affects the message overhead during the search. A high value generates unnecessary traffic and a low value may result on unsuccessful search even if the resource is available in the network. Therefore, the TTL should be high enough to guarantee that the search is successful. This generates a high amount of traffic [73]. In case of a highly connected graph in which nodes have a high degree, i.e., nodes have many communication links, the average number of hops necessary for the search decreases [107]. This allows minimizing the TTL, but it may generate an excessive number of duplicate messages thus increasing even more the overhead. In order to ensure that a search is successful, all the nodes should be addressed, generating O(N) messages, where N is the total number of nodes in the system. In order to cope with the message overhead, different mechanisms have been proposed to improve the search strategy. These include random walks (see Figure 2.2) [49, 73], percolation-based search [94] and bloom filters-based search [69]. Most of them try to reduce the search time from O(N) to O(log(N)). In random walks (see Figure 2.2), the nodes forward the request to a randomly chosen node. However, this routing approach still requires a mechanism to terminate the request. As in flooding, a TTL is used to limit the number of messages forwarded, and, in addition to that, it may use a check mechanism [73]. The check mechanism tries to reduce even more the traffic by performing periodically checks to the requesting node, by the forwarding nodes, before forwarding the request. While random walks usually generate fewer messages during the search, flooding provides a better response time. For any of these approaches, resources available at several nodes are more likely to be found, but if the object is stored in only few peers, there is a high probability that the search will be unsuccessful. Since such systems give no control over resource placement, the peers have no knowledge about other peers’ contents. Thus, if a search was not successful, it does not mean that the resource is not available in the network. On the other hand, the fact that these systems give no control over nodes’ placements, i.e., the communication links are established arbitrary, they can be easily built and maintained. How I Met Your Mother Learn English in 1 Step INPE 14 de abril 2011 12 12
, as used in Gnutella [50], or Hops-To-Live (HTL), as used in Freenet [32]. The choice of an appropriate value of. TTL or HTL affects the message overhead during the search. A high value generates unnecessary. traffic and a low value may result on unsuccessful search even if the resource. is available in the network. Therefore, the TTL should be high enough to guarantee that. the search is successful. This generates a high amount of traffic [73]. In case of a highly. connected graph in which nodes have a high degree, i.e., nodes have many communication. links, the average number of hops necessary for the search decreases [107]. This allows. minimizing the TTL, but it may generate an excessive number of duplicate messages thus. increasing even more the overhead. In order to ensure that a search is successful, all the. nodes should be addressed, generating O(N) messages, where N is the total number of. nodes in the system. In order to cope with the message overhead, different mechanisms have been proposed. to improve the search strategy. These include random walks (see Figure 2.2) [49, 73], percolation-based search [94] and bloom filters-based search [69]. Most of them try to. reduce the search time from O(N) to O(log(N)). In random walks (see Figure 2.2), the nodes forward the request to a randomly chosen. node. However, this routing approach still requires a mechanism to terminate the request. As in flooding, a TTL is used to limit the number of messages forwarded, and, in addition. to that, it may use a check mechanism [73]. The check mechanism tries to reduce. even more the traffic by performing periodically checks to the requesting node, by the forwarding. nodes, before forwarding the request. While random walks usually generate fewer. messages during the search, flooding provides a better response time. For any of these approaches, resources available at several nodes are more likely to be. found, but if the object is stored in only few peers, there is a high probability that the search. will be unsuccessful. Since such systems give no control over resource placement, the peers. have no knowledge about other peers’ contents. Thus, if a search was not successful, it does. not mean that the resource is not available in the network. On the other hand, the fact that. these systems give no control over nodes’ placements, i.e., the communication links are. established arbitrary, they can be easily built and maintained. How I Met Your Mother. Learn English in 1 Step. INPE. 14 de abril")
13
Aplicações P2P Compartilhamento de arquivos: BitTorrent, eMule, Gnutella, Kazaa, Napster… Video Streaming: Zattoo, Joost,… ... Comunicação via Internet: Skype, MSN, ICQ ... Multiplayer games: Unreal Tournament, DOOM Computação distribuída: Intel® Philanthropic Peer-to-Peer Program Intel® Philanthropic Peer-to-Peer Program [ -- "Intel’s Philanthropic peer-to-peer program links millions of PCs to create a computing resource for researchers in a wide-variety of fields. For example, Leland Stanford Junior University is focusing on protein folding and related diseases such as Alzheimer’s, ALS and Parkinson’s." [ -- "The project links and uses donated computer processing capacity to analyze data collected from a radio telescope located in Puerto Rico." Worldwide Lexicon Project [ -- "The worldwide lexicon project is an open source initiative to create a multilingual dictionary service for the Internet, and to create a simple, standardized protocol for talking to dictionary, encyclopedia and translation servers throughout the web. Similar to the project. While taps the idle CPUs of millions of personal computers, the worldwide lexicon enlists the help of internet users who are logged in, but not busy. Think of this as distributed human computation." Educational Applications INPE 14 de abril 2011 13 13

14
Grid-Computing São ambientes em rede que propiciam uma infra-estrutura de serviços que suportam a criação de recursos compartilhados (computadores,memória, aplicações) em uma comunidade distribuída (Ian Forster). Surgiu da necessidade de pesquisadores em física de partículas compartilharem e processarem volumes de informações da ordem de petabytes (1015 bytes). Em geral são utilizados por comunidades com interesses comuns (pesquisadores em física, biólogia) que possuem alto volume de dados para serem compartilhados. Exemplo: International Virtual Data Grid Laboratory (iVDGL) que reúne projetos internacionais tais como os projetos Grid Physics Network e Particle Physics Data Grid. existentes no sistema.
 em uma comunidade distribuída (Ian Forster). Surgiu da necessidade de pesquisadores em física de partículas compartilharem e processarem volumes de informações da ordem de petabytes (1015 bytes). Em geral são utilizados por comunidades com interesses comuns (pesquisadores em física, biólogia) que possuem alto volume de dados para serem compartilhados. Exemplo: International Virtual Data Grid Laboratory (iVDGL) que reúne projetos internacionais tais como os projetos Grid Physics Network e Particle Physics Data Grid. existentes no sistema.")
15
Grid-Computing

16
Cloud-Computing “ A Nuvem é um grande reservatório de recursos virtualizados facilmente utilizáveis e acessíveis (como hardware, plataformas de desenvolvimento e/ou serviços). Esses recursos podem ser dinamicamente reconfigurados para ajustar a carga (escala) variável do sistema, permitindo também um uso ótimo dos recursos. Esse reservatório de recursos é geralmente explorado por um modelo pay-per-use (pagar para usar) no qual as garantias são oferecidas por um Provedor de Infraestrutura por meio de SLAs (Service Level Agreement - Acordo de Nível de Serviço) " Retirado de: Vaquero, L.M. and Rodero-Merino, L. and Caceres, J. and Lindner, M. "A break in the clouds: towards a cloud definition" em ACM SIGCOMM Computer Communication Review, 2008
. Esses recursos podem ser dinamicamente reconfigurados para ajustar a carga (escala) variável do sistema, permitindo também um uso ótimo dos recursos. Esse reservatório de recursos é geralmente explorado por um modelo pay-per-use (pagar para usar) no qual as garantias são oferecidas por um Provedor de Infraestrutura por meio de SLAs (Service Level Agreement - Acordo de Nível de Serviço) Retirado de: Vaquero, L.M. and Rodero-Merino, L. and Caceres, J. and Lindner, M. A break in the clouds: towards a cloud definition em ACM SIGCOMM Computer Communication Review,")
17
Cloud-Computing

18
Características Acesso Remoto: o acesso a programas, serviços e arquivos é remoto. O uso desse modelo (ambiente) é mais viável do que o uso de unidades físicas Baseado em serviço: o recurso é oferecido em forma de serviço. Escalável e elástico: os recursos de infraestrutura e software podem ser ampliados ou reduzidos conforme a necessidade. Compartilhamento: a infraestrututra, software ou plataforma são compartilhadas entre os consumidores. Isso permite que recursos não utilizados possam atender diversas necessidades para vários consumidores ao mesmo tempo.
 é mais viável do que o uso de unidades físicas. Baseado em serviço: o recurso é oferecido em forma de serviço. Escalável e elástico: os recursos de infraestrutura e software podem ser ampliados ou reduzidos conforme a necessidade. Compartilhamento: a infraestrututra, software ou plataforma são compartilhadas entre os consumidores. Isso permite que recursos não utilizados possam atender diversas necessidades para vários consumidores ao mesmo tempo.")
19
Características Pagamento por uso: o pagamento é baseado no consumo, não no custo do equipamento. Ele baseia-se na quantidade do serviço utilizado pelos consumidores, que pode ser em termos de hora ou na transferência de dados, por exemplo. Usa tecnologias da internet: o serviço é oferecido usando identificadores, formatos e protocolos da internet como URLs, HTTP e IP.

20
Categorias Infraestrutura como Serviço (IaaS ):
Sistema Operacional completo Plataforma como Serviço (PaaS ): Ambiente de desenvolvimento Software como Serviço (SaaS): Editores de texto
: Ambiente de desenvolvimento. Software como Serviço (SaaS): Editores de texto.")
21
Categorias: outras Armazenamento como serviço
Banco de dados como serviço Informação como serviço Processo como serviço Integração como serviço Segurança como serviço Gestão/governança como serviço Teste como serviço Infraestrutura como serviço

22
Sistemas Comerciais SaaS PaaS IaaS

Apresentações semelhantes

















, que.>")

