Carregar apresentação
A apresentação está carregando. Por favor, espere

1
Estatística 4.1 Dirceu da Silva Jomar Barros Filho

2
DETERMINAÇÃO DA FORÇA DA RELAÇÃO ENTRE DUAS VARIÁVEIS Idéia básica em análise de dados estatísticos nas Ciências Humanas, Sociais e da Saúde é a busca de relações entre duas variáveis de uma mesma população. O procedimento mais usado é a correlação expressa por um coeficiente. Este, é zero quando duas variáveis são absolutamente independentes entre si, ou seja, não existe nenhuma relação entre elas. Pode assumir um valor máximo de + 1,00, quando a associação for positiva e o mais “forte” possível. Pode, também assumir um valor máximo de -1,00, quando a associação for negativa e o menos forte possível.

3
Como exemplo, podemos citar a correlação fortemente positiva da relação entre idade e estatura de uma criança; quanto maior a idade maior a estatura. Um exemplo de forte correlação negativa é a relação entre a temperatura e o consumo de cobertores; quando maior a temperatura, menor o consumo de cobertores. Um exemplo da inexistência de correlação é a relação entre o número do calçado de um adulto e o seu nível intelectual. Ou ainda, a paixão pelo Timão em função do número de vitórias ou derrotas!

4
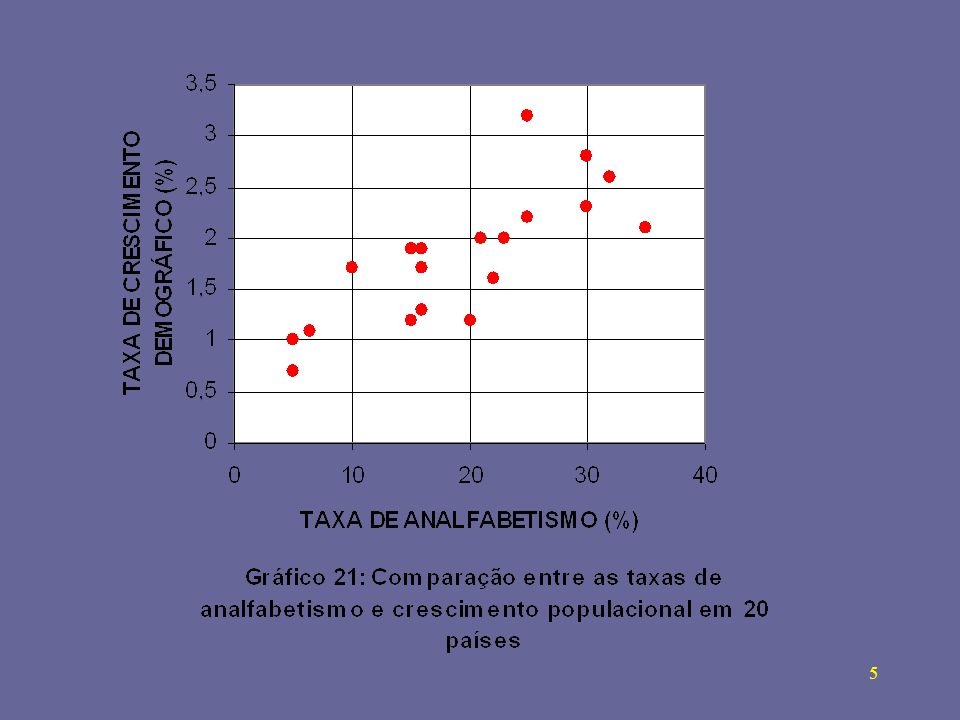
EXEMPLO: Taxas de analfabetismo (X) e de crescimento demográfico (Y) em 20 países (dados UNESCO/1991).
 e de crescimento demográfico (Y) em 20 países (dados UNESCO/1991).")
6
Análise estatística mais usada, para obtenção da correlação entre variáveis é o coeficiente de (Karl) PEARSON (r), para dados paramétricos. No Microsoft Excel: =PEARSON($A$2:$A$21;$B$2:$B$21)
")
7
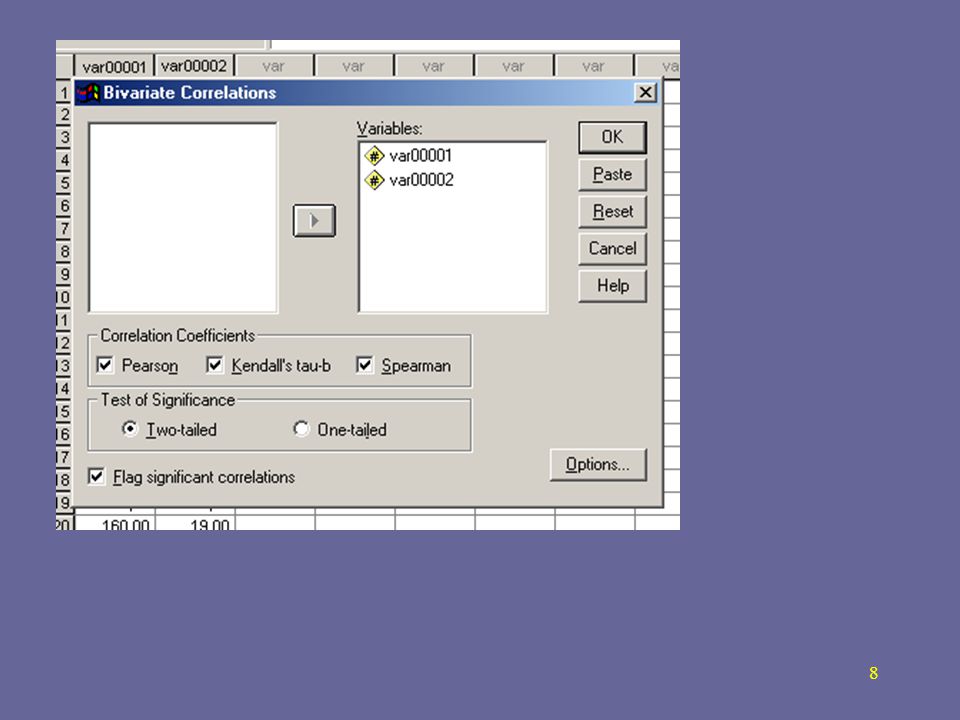
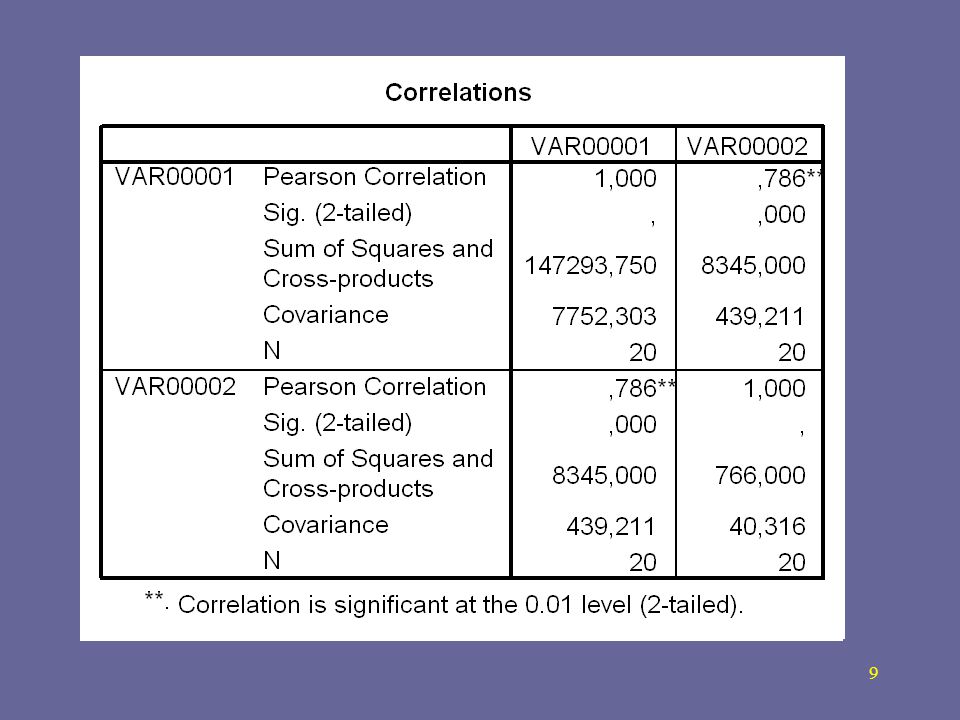
No SPSS:

11
Para dados não-paramétricos (ordinais)
recomenda-se usar o coeficiente de correlação de Spearman (). Idem para o de Kendall
. Idem para o de Kendall.")
12
Para dados não-paramétricos (nominais) recomenda-se usar o coeficiente de correlação de Contingência(C). Ou, V de Cramér

14
O nível de significância (ou p-value) é a probabilidade de obter-se resultados fora da região de possibilidades de conclusão. Se o p-value é pequeno (<0,50) a correlação é significativa e as duas variáveis são linearmente dependentes ou relacionadas e vice-versa. Como detalhe pode-se usar os coeficientes de correlação de Spearman e Kendall para dados intervalares ou métricos, sabendo-se que as suas eficiências são de aproximadamente 91% do coeficiente de Pearson.
 a correlação é significativa e as duas variáveis são linearmente dependentes ou relacionadas e vice-versa. Como detalhe pode-se usar os coeficientes de correlação de Spearman e Kendall para dados intervalares ou métricos, sabendo-se que as suas eficiências são de aproximadamente 91% do coeficiente de Pearson.")
15
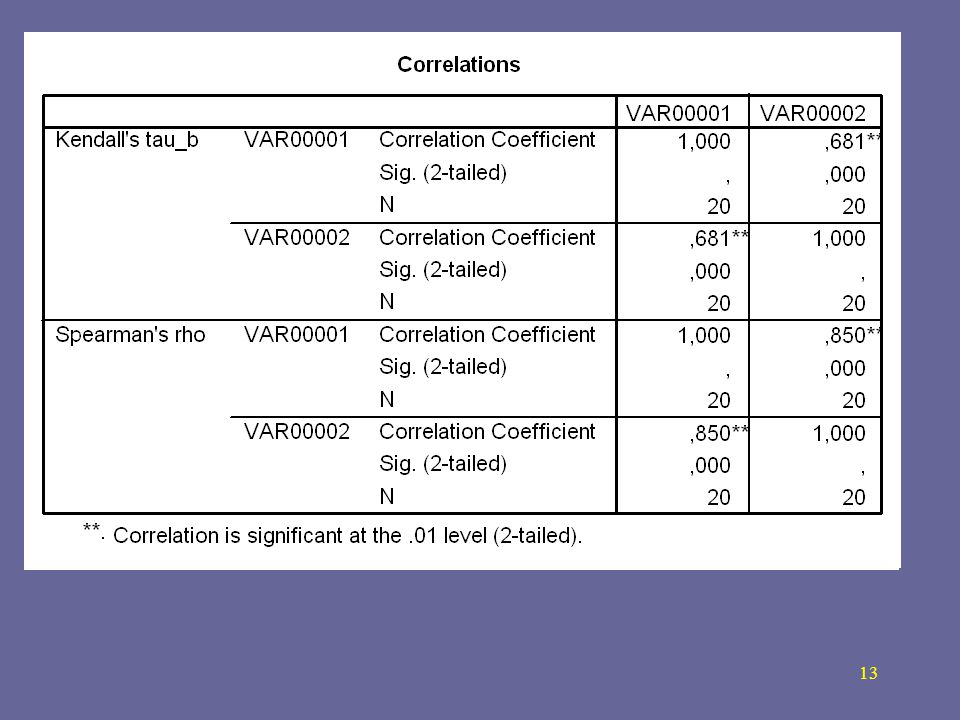
Pelos três testes obteve-se:
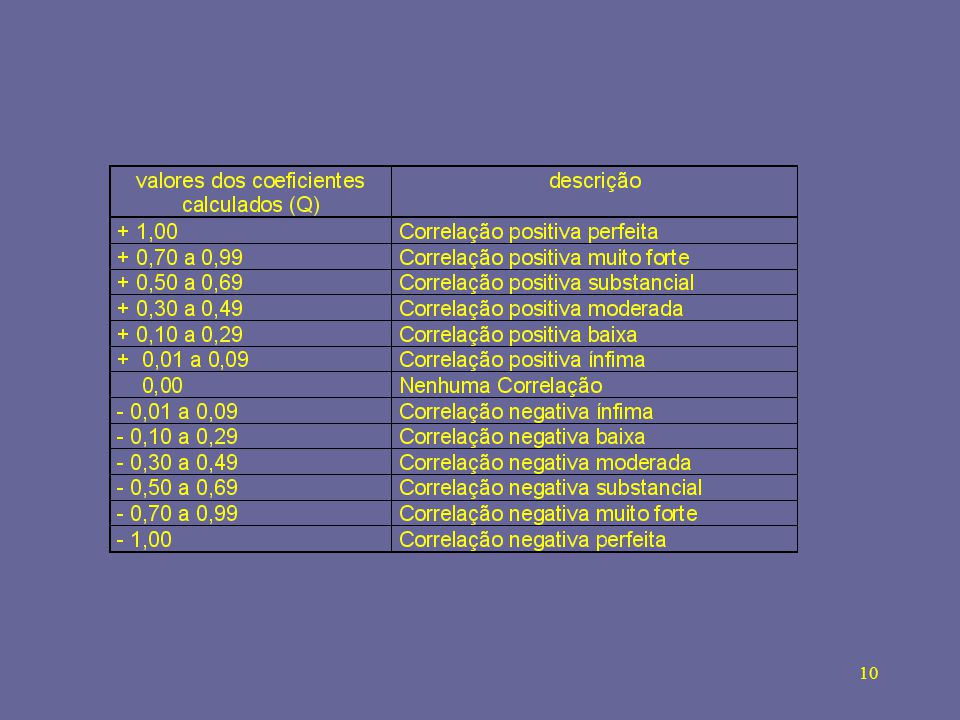
= 0,850 = 0,681 Nota-se que a correlação é positiva muito forte. Como interpretar os resultados?

16
REGRESSÃO LINEAR: Muitas pesquisas necessitam fazer previsões específicas. O procedimento mais usado é a análise de regressão à estimar valores não conhecidos de uma variável, a partir de uma série de valores conhecidos. à dada uma série de pontos (x,y), procura-se descobrir a equação. y b x
, procura-se descobrir a equação. y. b. x.")
17
Exemplo: Um pesquisador está querendo analisar a relação que existe entre o investimento em equipamentos informatizados e o desempenho escolar de alunos. Tomado um período de 10 meses O objetivo é ter uma equação matemática que permita fazer projeções e estimativas de qualidade do ensino a partir do investimento novos equipamentos . Variável dependente = quantidade de alunos aprovados(y) Variável independente = investimento em equipamentos (x)
 Variável independente = investimento em equipamentos (x)")
19
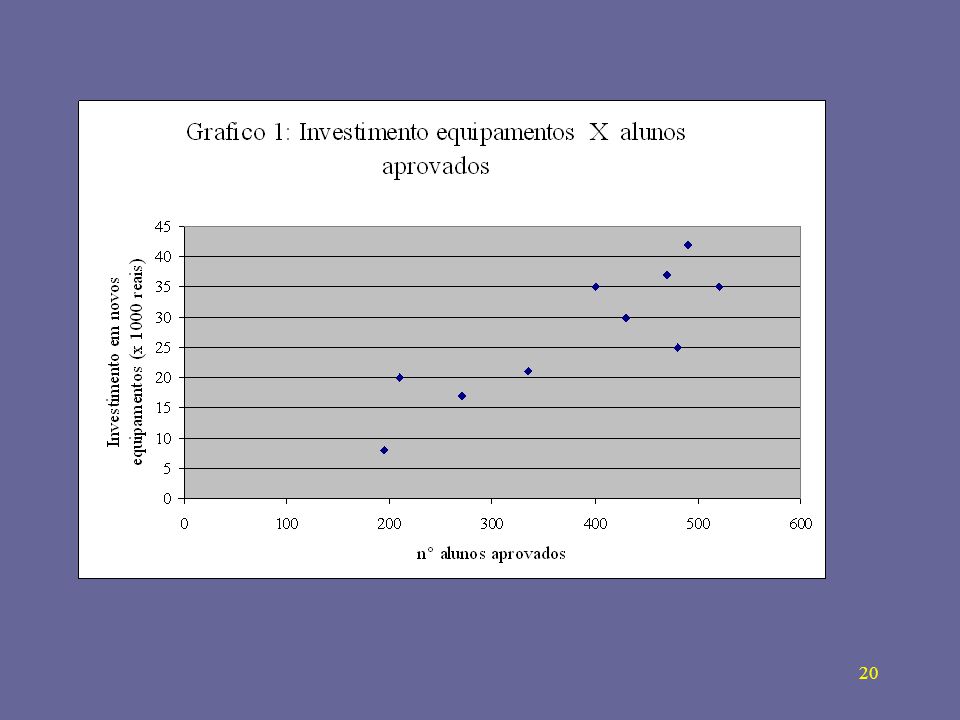
Analisando os dados da tabela 1, deve-se manter os investimento em novos equipamentos?

21
Correlação positiva muito forte
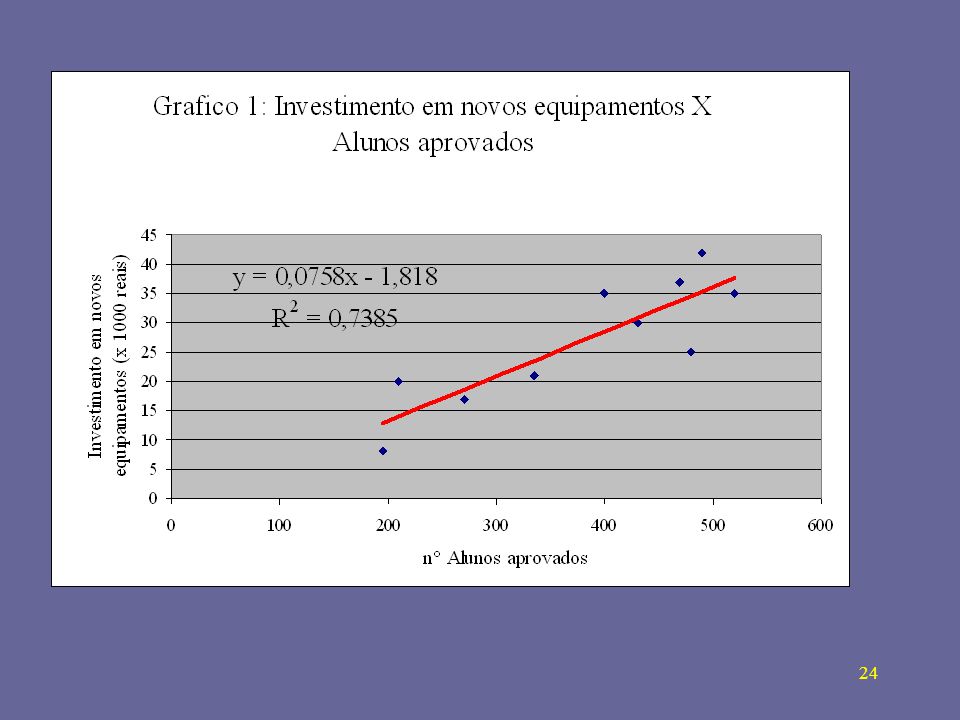
Teste de Pearson = 0,859 Correlação positiva muito forte Vê-se através do gráfico que há uma dependência entre o crescimento do número de alunos aprovados e o investimento em novos equipamentos. Para obtermos a RETA DE REGRESSÃO: USANDO O EXCEL: Há três funções (de biblioteca) no excel para o cálculo da regressão linear:
 no excel para o cálculo da regressão linear:")
22
Interceptação: calcula o coeficiente b
=INTERCEPÇÃO(A2:A11;B2:B11) inclinação: calcula o coeficiente m =INCLINAÇÃO(A2:A11;B2:B11) previsão: calculo de um valor de X que você queira: =PREVISÃO(20;A2:A11;B2:B11)
 inclinação: calcula o coeficiente m =INCLINAÇÃO(A2:A11;B2:B11) previsão: calculo de um valor de X que você queira: =PREVISÃO(20;A2:A11;B2:B11)")
23
INTERCEPTAÇÃO. b = 117,0702 INCLINAÇÃO. m = 9,7381. PREVISÃO X = 20
INTERCEPTAÇÃO b = 117,0702 INCLINAÇÃO m = 9, PREVISÃO X = 20 y = 311,8330 PREVISÃO X = 30 y = 406,6744 PREVISÃO X = 45 y = 551,5763 ERRO PADRÃO DE ESTIMATIVA: 65,1734 TESTE DE PEARSON r = 0, COEFICIENTE DE DETERMINAÇÃO r2 = 0, Pode-se usar também a ferramenta [ferramentas] [análise de dados] [regressão] do excel para a obtenção da ANOVA

25
há dois parâmetros que podem ajudar a analisar os dados obtidos:
ERRO PADRÃO DA ESTIMATIVA: calcula o maior erro padrão da estimativa, para a faixa de 95% da amostra (dois graus de liberdade) Mede a variabilidade em torno da linha ajustada de regressão (em unidades da variável dependente Y) COEFICIENTE DE DETERMINAÇÃO r2 (mede o modo de associação de duas variáveis) parcela de y que é explicada por x!
 Mede a variabilidade em torno da linha ajustada de regressão (em unidades da variável dependente Y) COEFICIENTE DE DETERMINAÇÃO r2 (mede o modo de associação de duas variáveis) parcela de y que é explicada por x!")
26
NO EXEMPLO O VALOR de r2 é 0,7385. Isto significa que 73,85% das variações dos de alunos aprovados (y) são “explicadas” pelo investimento em Novos equipamentos, ficando 26,15% sem explicação.
 são explicadas pelo investimento em Novos equipamentos, ficando 26,15% sem explicação.")
27
Ainda resta saber se a correlação positiva forte é devida aos dois parâmetros X e Y ou se a diminuição de problemas estão relacionadas com outros parâmetros (não considerados aqui). Aplicando o Teste completo de Fisher (F) ou teste de hipótese F testa a hipótese de que nenhum dos coeficientes de regressão tenha significado.
 ou teste de hipótese F. testa a hipótese de que nenhum dos coeficientes de regressão tenha significado.")
28
Então: onde: k = graus de liberdade (gl) (95% 2 graus de liberdade)
n = Nº. de elementos da amostra r2 coeficiente de determinação Então:

29
Valor crítico de F (caudas inferior e superior da distribuição):
significância de 0,01, para k=2 k-1= 2-1 = 1 no numerador e n-K = 10-2 = 8 no denominador Usando o Excel: =INVF (0,01;1;8) Fcrit. = 11,258 (< 22,59) Portanto: é menor que o valor de F A regressão deve ser aceita!
 Fcrit. = 11,258 (< 22,59) Portanto: é menor que o valor de F A regressão deve ser aceita!")
Apresentações semelhantes