Carregar apresentação
A apresentação está carregando. Por favor, espere

1
REVISÃO 1º Bimestre http://chaiene.yolasite.com/

2
Considerações gerais para administração de recursos de dados

3
Administração de Bancos de Dados Uma importante função de gerenciamento de recursos de dados responsável pelo uso adequado da tecnologia de gerenciamento de bancos de dados.

4
Considerações gerais para administração de recursos de dados Administração de Bancos de Dados Isto inclui responsabilidade pelo: Desenvolvimento e manutenção do dicionário de dados da organização Projeto e monitoração do desempenho dos bancos de dados Aplicação de padrões para uso e segurança dos bancos de dados.

5
Considerações gerais para administração de recursos de dados Planejamento de Dados É uma função de planejamento e análise empresarial que se concentra no gerenciamento de recursos de dados.

6
Considerações gerais para administração de recursos de dados Planejamento de Dados Ela inclui a responsabilidade pelo: Desenvolvimento de uma arquitetura global para os recursos de dados da empresa vinculada à sua missão, planos estratégicos e aos objetivos e processos de suas unidades de negócios. É um componente importante do processo de planejamento estratégico de uma organização.

7
Considerações gerais para administração de recursos de dados Administração de Dados Envolve: O estabelecimento e execução de políticas e procedimentos para gerenciamento de dados como um recurso estratégico das empresas. A administração da coleta, armazenamento e disseminação de todos os tipos de dados.

8
Considerações gerais para administração de recursos de dados Benefícios e Limitações do Gerenciamento de Bancos de Dados Benefícios importantes: Redução da duplicação de dados Integração dos dados de forma que possam ser acessados por múltiplos programas e usuários.

9
Considerações gerais para administração de recursos de dados A integridade e segurança dos dados armazenados em bancos de dados podem ser aumentadas, já que o acesso aos dados e a modificação dos bancos de dados são controlados pelo software de sistema de gerenciamento de bancos de dados, um dicionário de dados e uma função de administração de bancos de dados.

10
Considerações gerais para administração de recursos de dados Benefícios e Limitações do Gerenciamento de Bancos de Dados As limitações decorrem de: Sua maior complexidade tecnológica. Poder ser difícil e dispendioso desenvolver grandes bancos de dados de tipos complexos e instalar um SGBD. Maior capacidade de hardware é exigida, já que são maiores os requisitos de armazenamento para os dados da organização, os dados de controle das despesas e os programas SGBD.

11
Considerações gerais para administração de recursos de dados Tempos mais longos de processamento podem resultar de aplicações de processamento de transações de alto volume uma vez que existe uma camada extra de software (o SGBD) entre os programas de aplicativos e o sistema operacional. Se a organização utiliza bancos de dados centralizados, sua vulnerabilidade a erros, fraude e falhas é aumentada. Se a organização utiliza bancos de dados distribuídos, problemas de inconsistência de dados podem surgir.

12
Arquivos

13
O banco de dados SQL Server possui três tipos de arquivos, são eles de dados (primário e secundário) e de log de transação. Os arquivos de dados são responsáveis por armazenar os dados do banco de dados. O arquivo de log de transação é responsável por armazenar todas as transações ocorridas dentro de um banco de dados.

14
Arquivos Primário O arquivo de dados primário contém as informações de inicialização do banco de dados e aponta para os outros arquivos no banco de dados. Dados do usuário e objetos podem ser armazenados neste arquivo ou em arquivos de dados secundários. Todo banco de dados possui um arquivo de dados primário. A extensão de nome de arquivo indicada para arquivos de dados primários é.mdf (no caso do SQL Server).
..")
15
Arquivos Secundário Os arquivos de dados secundários são opcionais, definidos pelo usuário, e armazenam dados do usuário. Arquivos secundários podem ser usados para distribuir os dados entre os diversos discos, colocando cada arquivo em uma unidade de disco diferente. Além disso, caso um banco de dados exceda o tamanho máximo em um único arquivo Windows, será possível usar arquivos de dados secundários, assim, o banco de dados continuará a crescer. A extensão de nome de arquivo recomendada para arquivos de dados secundários é. Ndf (No caso do SQL Server)
.")
16
Arquivos Log de transações Os arquivos de log de transações armazenam as informações de log usadas para recuperar o banco de dados. Deve haver, no mínimo, um arquivo de log para cada banco de dados. A extensão de nome de arquivo indicada para arquivos de transação é.ldf (No caso do SQL Server).
..")
17
Arquivos SQL Server... Existem três tipo de extensões:.mdf,.ndf e o.ldf. O.mdf e o.ndf armazena os dados. Todo banco de dados tem um arquivo com a extensão.mdf, pois ele é considerado o arquivo primário. Normalmente armazena-se dados de sistema dentro do arquivo primário, e os outros dados são armazenados em arquivos com a extensão.ndf. O.ldf armazena os dados de log de transação. (Dica: coloque o arquivo de log separado dos arquivos de dados, assim não ocorrerão problemas de concorrência entre dados e log)
.")
18
Arquivos Por padrão, os dados e logs de transação são colocados na mesma unidade e caminho. Isto é feito para controlar os sistemas de um único disco. Porém, isto não é o ideal para ambientes de produção. Recomenda-se que coloque os dados e arquivos de log em discos separados.

19
Grupos de Arquivos Todo banco de dados possui um grupo de arquivo primário. Este grupo de arquivo contém o arquivo de dados primário e qualquer um dos arquivos secundários que não foram colocados em outros grupos de arquivos. Grupos de arquivos definidos pelo usuário podem ser criados para agrupar os arquivos de dados para fins administrativos, de alocação de dados e de posicionamento.

20
Arquivos Oracle... Data files (arquivos de dados) O banco de dados Oracle possui um ou mais data files, mas o que é isso ? Esse arquivo é o responsável por guardar os dados do banco de dados. Os dados das estruturas das tablespaces (estrutura lógica) são fisicamente armazenados nos data files.
 O banco de dados Oracle possui um ou mais data files, mas o que é isso . Esse arquivo é o responsável por guardar os dados do banco de dados. Os dados das estruturas das tablespaces (estrutura lógica) são fisicamente armazenados nos data files..")
21
Arquivos Oracle... Control file (arquivo de controle) É um pequeno binário que faz parte de um banco de dados Oracle. O control file é usado para rastrear o status do banco de dados e a estrutura física. Cada banco Oracle deve ter pelo menos um arquivo de controle. É recomendado criar mais de um control file, e utilizar a multiplexação (separar os arquivos em diferentes discos/partição). Outra recomendação é deixar o redo online também em diferentes discos. Desta maneira, você minimiza o risco em caso de falha de disco.
 É um pequeno binário que faz parte de um banco de dados Oracle. O control file é usado para rastrear o status do banco de dados e a estrutura física. Cada banco Oracle deve ter pelo menos um arquivo de controle. É recomendado criar mais de um control file, e utilizar a multiplexação (separar os arquivos em diferentes discos/partição). Outra recomendação é deixar o redo online também em diferentes discos. Desta maneira, você minimiza o risco em caso de falha de disco..")
22
Arquivos Oracle... Online Redo Log files Permite uma recuperação de instância do banco de dados. Se o banco de dados travar e não perder arquivo de dados algum, a instância poderá recuperá-lo com as informações desses arquivos. A estrutura do redo online é física no banco de dados Oracle e é o responsável por tornar possível refazer (redo) uma transação que possa ter dado alguma indisponibilidade. Ele armazena informações de transações tanto as antigas e as novas.
 uma transação que possa ter dado alguma indisponibilidade. Ele armazena informações de transações tanto as antigas e as novas..")
23
Serviços Um serviço é um tipo de aplicativo executado em segundo plano no sistema. Os bancos de dados são executados nos sistemas operacionais como um serviço.

24
Serviços Os serviços normalmente fornecem recursos essenciais de sistema operacional, como fornecimento de Web, registro de eventos ou fornecimento de arquivos. Serviços podem ser executados sem exibir uma interface de usuário na área de trabalho do computador.

25
Serviços Exemplo: O Mecanismo de Banco de Dados do SQL Server, SQL Server Agent e diversos outros componentes SQL Server são executados como serviços.

26
Performance Devido à utilização cada vez maior de sistemas nas organizações, é necessário que estes sejam rápidos e seguros para atender à demanda de seus usuários. Consequentemente, o interesse em otimização de performance (tuning) destes sistemas cresce e os conhecimentos para “tuná-los” torna-se um requisito de grande importância para contratação de profissionais de TI.
 destes sistemas cresce e os conhecimentos para tuná-los torna-se um requisito de grande importância para contratação de profissionais de TI..")
27
Performance O termo tuning ainda pode parecer um enigma para muitas pessoas, mas aos poucos ele vem sendo desvendado e explorado cada vez mais pelos profissionais de TI. Quando aplicado em Tecnologia da Informação (TI), este termo refere-se basicamente ao conceito de propor mudanças e aplicar ideias para otimizar o desempenho na recuperação ou atualização de dados.
, este termo refere-se basicamente ao conceito de propor mudanças e aplicar ideias para otimizar o desempenho na recuperação ou atualização de dados..")
28
Performance O processo de tuning é algo que só deve ser realizado quando houver uma real necessidade, pois envolve uma grande quantidade de processos tanto do SGBD como do sistema operacional. Tuning não é só configuração do SGBD, algumas vezes requer configuração no sistema operacional ou otimizar as consultas realizadas nos bancos, e algumas configurações podem acarretar em problemas futuros ou até mesmo mau funcionamento do SGBD.

29
Performance A técnica de tuning de desempenho é uma prática feita em todos os SGBDs importantes com técnicas diferentes. É uma necessidade de toda grande empresa, e requer um grande nível de conhecimento e experiência sobre os processos e suas técnicas, pois nem sempre o problema será resolvido com uma ou duas alterações, às vezes é necessário uma mudança nas queries.

30
Performance Para aumentar a segurança e a performance dos sistemas, deve-se considerar, dentre os principais itens: a arquitetura do sistema, a rede, o hardware e o banco de dados em que ele armazena as suas informações.

31
Performance Crie rotinas de indexação periódicas. Rotinas de indexação são fundamentais para garantia de performance. Não se esqueça delas. Índices devem ser criados para agilizar a performance do sistema como um todo.

32
Performance Índices na Otimização de Consultas Criar índice eficiente não é uma tarefa simples; requer conhecimento das consultas (queries) em execução e dos diferentes tipos de índices disponíveis.
 em execução e dos diferentes tipos de índices disponíveis.")
33
Performance Portanto, uma estratégia fundamental para ganho de performance consiste na reestruturação periódica dos índices. O banco de dados utilizado, o comportamento da aplicação, as regras de negócio, a tecnologia de rede e o hardware onde o banco de dados está instalado são alguns dos fatores externos que devem ser levados em consideração e que podem ser decisivos para solução do problema de performance.

34
Performance Análise do plano de execução de uma query Paralelismo: indica que a query está sendo executada em mais de um processador. Em máquinas multi-processadas, o otimizador poderá quebrar queries complexas e executá-las em paralelo, normalmente ganhando performance.

35
Performance Sort: presente quando a query utiliza order by ou quando o input precisa ser ordenado para resolução do join. No segundo caso, a perda de performance pode ser evitada criando-se um índice adequado.

36
Performance Normalmente só pensamos em otimização quando nos deparamos com situações críticas de performance. Otimização é um processo contínuo que deve ser observado em todas as etapas de um projeto: Inicia-se na modelagem, garantindo estruturas de dados normalizadas e índices bem definidos, continua na escrita dos batchs e stored procedures e prossegue no dia-a-dia do DBA.

37
Performance Através de: Criteriosas análises do servidor de banco de dados; Rastreamento de queries com longo tempo de duração; Checagem de ocorrências de deadlocks e Implementação de rotinas de reindexação. O administrador pode garantir que o banco de dados esteja sempre correspondendo com as necessidades de tempo de resposta da aplicação.

38
Performance Os sistemas normalmente não nascem lentos, mas tendem a ficar mais lentos com o tempo. Aumento do número de usuários; Existência de mais processos concorrentes; Crescimento do volume de informações armazenadas; Falta (ou excesso) de índices e Por fim, a má qualidade do código SQL. São atores que ocasionam o aparecimento de gargalos e, consequentemente queda de performance.
 de índices e Por fim, a má qualidade do código SQL. São atores que ocasionam o aparecimento de gargalos e, consequentemente queda de performance..")
39
Performance Portanto, antes de mais nada aprenda a modelar bem e conheça as minúcias do SQL do seu SGDB. Depois aprenda a analisar com profundidade os planos de execução e reescreva consultas complexas a partir deste tipo de análise.

40
Performance A forma como a sua aplicação utiliza o seu SGDB é de suma importância para o DBA. Sendo assim identificar o tipo de carga que a aplicação projeta sobre o banco de dados é muito importante. Como por exemplo...

41
Performance OLTP (On Line Trasactional Processing ou Processamento de Transações em Tempo Real) consiste na maior parte da carga das aplicações corporativas atuais. É caracterizado por um grande volume de pequenas transações concorrentes e alto volume de gravações. As cargas OLTP são as que tem o desempenho de disco mais crítico.

42
Performance Exemplos de OLTP Sistema de transações bancárias que registram todas as operações efetuadas em um banco; Caixas multibancos; Reservas de viagens ou hotel on-line; Cartões de Crédito.

43
Performance BI ou Business Inteligence consiste num universo paralelo com diversas tecnologias como Data Mining, OLAP, Data Warehouse, Data Mart, Balanced Scored Card, etc. A questão é que quando falamos em BI, o banco de dados sempre acaba de um jeito ou de outro, tendo que suportar consultas enormes, com grande quantidade de dados e cálculos complexos. As cargas de BI exigem muita velocidade em leitura de disco, memória para ordenações e uso intenso do processador.

44
Performance Tecnologias BI fornecem histórico, atual e previsíveis visões das operações de negócios. As habituais funções do BI são: Relatórios; Processos de análise online; Análises; Mineração de dados; Processamento de eventos complexos; Gerenciamento de desempenho dos negócios; Benchmarking; Mineração de texto; Análises previsíveis e análises prescritivas.

45
Performance O BI pode ser usado para ajudar na decisão de uma grande variedade de negócios variando do operacional ao estratégico.

46
Performance Sites Web Dinâmicos: os sites dinâmicos são aqueles que armazenam o seu conteúdo num banco de dados. Desta forma um único acesso numa página web pode representar uma dúzia de pequenas leituras no banco de dados. As cargas de sites web são caracterizadas por um enorme número de conexões simultâneas realizando pequenas leituras.

47
Performance Operações em lote ou bath são cargas de trabalho intensas no banco de dados que podem durar várias horas para se completar e tem um grande impacto na performance. São comuns tanto em aplicações OLTP (cálculo de uma folha de pagamento, fechamento de ano fiscal, etc), como em BI (carga de grandes tabelas vindas de fontes externas). As cargas em lote sempre são alvos de estudos cuidadosos tem o potencial de crescer rapidamente em tempo de execução até inviabilizar os negócios da empresa.
, como em BI (carga de grandes tabelas vindas de fontes externas). As cargas em lote sempre são alvos de estudos cuidadosos tem o potencial de crescer rapidamente em tempo de execução até inviabilizar os negócios da empresa..")
48
Performance Em resumo... Performance de banco de dados pode ser definida como a otimização de uso de recursos para aumentar a throughput e minizar a contenção, possibilitando o maior workload possível ser processado.

49
Segurança A segurança do banco de dados herda as mesmas dificuldades que a segurança da informação enfrenta, que é garantir a: Integridade, Disponibilidade, Confidencialidade.

50
Segurança Os bancos de dados SQL implementam mecanismos que restringem ou permitem acessos aos dados de acordo com papéis ou roles fornecidos pelo administrador.

51
Segurança O comando GRANT concede privilégios específicos para um objeto (tabela, visão, sequência, banco de dados, função, linguagem procedural, esquema ou espaço de tabelas) para um ou mais usuários ou grupos de usuários. O comando REVOKE remove a permissão GRANT.

52
Segurança A preocupação com a criação e manutenção de ambientes seguros se tornou a ocupação principal de administradores de redes, de sistemas operacionais e de bancos de dados.

53
Segurança Pesquisas mostram que a maioria dos ataques, roubos de informações e acessos não-autorizados são feitos por pessoas que pertencentes à organização alvo.

54
Segurança Por esse motivo, esses profissionais se esforçam tanto para criar e usar artifícios com a finalidade de eliminar os acessos não-autorizados ou diminuir as chances de sucesso das tentativas de invasão (internas ou externas).
.")
55
Segurança Os controles de acesso em sistemas de informação devem certificar que todos os acessos diretos ao sistema ocorram exclusivamente de acordo com as modalidades e as regras pré-estabelecidas, e observadas por políticas de proteção.

56
Segurança Os mecanismos de segurança referem-se às regras impostas pelo subsistema de segurança do SGBD, que verifica todas as solicitações de acesso, comparando-as com as restrições de segurança armazenadas no catálogo do sistema.

57
Segurança Entretanto existem brechas no sistema e ameaças externas que podem resultar em um servidor de banco de dados comprometido ou na possibilidade de destruição ou no roubo de dados confidenciais.

58
Segurança As ameaças aos bancos de dados podem resultar na perda ou degradação de alguns ou de todos os objetivos de segurança aceitos, são eles: integridade, disponibilidade, confidencialidade.

59
Segurança A integridade do banco de dados se refere ao requisito de que a informação seja protegida contra modificação imprópria.

60
Segurança A disponibilidade do banco de dados refere-se a tornar os objetos disponíveis a um usuário ou a um programa ao qual eles têm um direito legítimo.

61
Segurança A confidencialidade do banco de dados se refere à proteção dos dados contra a exposição não autorizada

62
Segurança O impacto da exposição não autorizada de informações confidenciais pode resultar em perda de confiança pública, constrangimento ou ação legal contra a organização.

63
Controle de Acesso É todo controle feito quanto ao acesso ao BD, impondo regras de restrição, através das contas dos usuários. O Administrador do BD (DBA) é o responsável superior por declarar as regras dentro do SGBD. Ele é o responsável por conceder ou remover privilégios, criar ou excluir usuários, e atribuição de um nível de segurança aos usuários do sistema, de acordo com a política da empresa.
 é o responsável superior por declarar as regras dentro do SGBD. Ele é o responsável por conceder ou remover privilégios, criar ou excluir usuários, e atribuição de um nível de segurança aos usuários do sistema, de acordo com a política da empresa..")
64
Controle de Inferência É um mecanismo de segurança para banco de dados estatísticos que atua protegendo informações estatísticas de um individuo ou de um grupo. Bancos de dados estatísticos são usados principalmente para produzir estatísticas sobre várias populações. Por exemplo: IBGE

65
Controle de Inferência O banco de dados pode conter informações confidenciais sobre indivíduos. Os usuários têm permissão apenas para recuperar informações estatísticas sobre populações e não para recuperar dados individuais, como, por exemplo, a renda de uma pessoa específica.

66
Controle de Fluxo É um mecanismo que previne que as informações fluam por canais secretos e violem a política de segurança ao alcançarem usuários não autorizados. Ele regula a distribuição ou fluxo de informação entre objetos acessíveis. Um fluxo entre o objeto A e o objeto B ocorre quando um programa lê valores de A e escreve valores em B.

67
Controle de Fluxo Os controles de fluxo têm a finalidade de verificar se informações contidas em alguns objetos não fluem explicita ou implicitamente para objetos de menor proteção. Dessa maneira, um usuário não pode obter indiretamente em B aquilo que ele ou ela não puder obter diretamente de A.

68
Criptografia de dados É uma medida de controle final, utilizada para proteger dados sigilosos que são transmitidos por meio de algum tipo de rede de comunicação. Ela também pode ser usada para oferecer proteção adicional para que partes confidenciais de um banco de dados não sejam acessadas por usuários não autorizados.

69
Criptografia de dados Para isso, os dados são codificados através da utilização de algum algoritmo de codificação. Assim, um usuário não autorizado terá dificuldade para decifrá-los, mas os usuários autorizados receberão chaves para decifrar esses dados. A criptografia permite o disfarçada mensagem para que, mesmo com o desvio da transmissão, a mensagem não seja revelada.

70
Criptografia de dados Os dados originais (não criptografados) são chamados de texto comum. O texto comum é criptografado quando é submetido a um algoritmo de criptografia, cujas as entradas são o texto comum e uma chave de criptografia. A saída desse algoritmo (a forma criptografada de um texto comum) é chamada texto cifrado.
 é chamada texto cifrado..")
71
Criptografia de dados O texto cifrado, que deve ser ininteligível para qualquer pessoa que não possua a chave de criptografia, é o que fica armazenado no banco de dados ou é transmitido pela linha de comunicações.

72
Login O que é Login? É um objeto que dá acesso a instância do SQL Server, ou seja, o Login é único e exclusivo da instância. Logins podem ser criados através do SSMS (SQL Server Management Studio) ou Transact-SQL. Existem dois tipos de Logins: Windows e SQL Server.
 ou Transact-SQL. Existem dois tipos de Logins: Windows e SQL Server..")
73
Usuário O que Usuário? É um objeto que dá acesso ao banco de dados. Usuários também são criados através do SSMS (SQL Server Management Studio) ou Transact-SQL.
 ou Transact-SQL..")
74
Login e Usuário Obs: o Login e o Usuário podem ou não serem vinculados, isso vai depender de qual forma você quer trabalhar, ou seja um usuário sempre vai ter vinculo com um Login por isso um Usuário é uma vinculação entre um Login e um banco de dados. Um ponto importante e que não deve esquecer que, quando se trabalha com Logins e Usuário deve-se realmente ter a atenção com relação a segurança, principalmente com relação aos dados e a instância.

75
Privilégios O gerenciamento de usuários e seus respectivos privilégios aos objetos do banco de dados, dependendo do número de objetos e usuários, pode ser tornar uma tarefa árdua para o administrador do banco de dados.

76
Privilégios Quando este número ultrapassa 10 usuários a DBA já deve começar a tomar cuidado para não se passar ao conceder os Grants (permissões) para os objetos do banco em nível de usuário, ou seja, um a um. Uma forma muito simples de minimizar este trabalho é a utilização de Roles (papéis).
..")
77
Privilégios O que é uma role? Uma Role pode ser definida como um “pacote” de privilégios que podem ser associados de forma muito fácil aos usuários do banco de dados.

78
Privilégios Por exemplo, podemos criar uma role com privilégio total a todos os objetos de nosso banco de dados, ou seja, privilégio de administrador. Sendo assim, todos os usuários com papel de administradores do banco de dados deverão ser associados a esta role.

79
Privilégios Desta forma, fica muito fácil o gerenciamento de privilégios para um grupo de usuários, pois se antes era necessário realizarmos Grant de todas as tabelas, views, functions e procedures para todos os usuários com permissão de administradores, agora, com a Role, necessitamos apenas associar estes usuários a ela.

80
Privilégios A utilização de Roles pode facilitar a vida de um DBA na hora de gerenciar os níveis de permissão de acesso a diversos grupos de usuários.

81
Controle de Acesso Controle discriminatório; Controle mandatário

82
Controle de Acesso Controle discriminatório Determinado usuário terá privilégios diferentes sobre objetos diferentes; Há poucas limitações inerentes a respeito de quais usuários podem ter quais direitos sobre quais objetos; Esquemas discriminatórios são muito flexíveis.

83
Controle de Acesso Controle discriminatório Por exemplo: O usuário U1 pode ser capaz de ver A, mas não B, enquanto o usuário U2 pode ser capaz de ver B, mas não A.

84
Controle de Acesso Controle mandatário Cada objeto de dados é assinalado com um certo nível de classificação, e cada usuário recebe um certo nível de liberação; O acesso a determinado objeto de dados só pode ser feito por usuário com a liberação apropriada; Os esquemas mandatários tendem a ser hierárquicos por natureza, portanto mais rígidos.

85
Controle de Acesso Controle mandatário Por exemplo: O usuário U1 pode ser capaz de ver A, mas não B, então a classificação de B deve ser maior que a de A, e então nenhum usuário U2 poderá ver B sem poder ver A.

86
Restrições de Segurança Restrições de segurança são aplicáveis a uma determinada requisição de acesso; O sistema precisa ser capaz de reconhecer a origem dessa requisição, isto é, precisa ser capaz de reconhecer o usuário solicitante.

87
Restrições de Segurança Quando os usuário se conectam ao sistema, em geral, eles são obrigados a fornecer não apenas sua ID de usuário, mas também uma senha; A senha é conhecida apenas pelo sistema e por usuário legítimos da ID de usuário em questão. O processo de verificação de senha, ou seja, o processo de verificação se os usuário realmente são quem dizem ser, é chamada de autenticação.

88
Restrições de Segurança Autenticação - Diferentes técnicas de autenticação: Leitoras de impressões digitais; Scaners de retina; verificadores de imagem da geometria das mãos; Verificadores de voz; Dispositivos de reconhecimentos de assinaturas; Etc.

89
Restrições de Segurança Autenticação Características pessoais que ninguém pode roubar.

90
Replicação de dados “A replicação é um conjunto de tecnologias utilizadas para copiar e distribuir objetos e dados de um banco de dados para um outro banco de dados, sincronizando estes dados com a finalidade de se manter a consistência.”

91
Replicação de dados Destes bancos de dados, a replicação pode ser feita entre servidores ou entre servidores e clientes.

92
Replicação de dados Replicação de dados entre servidores: Suporte na melhoria na escalabilidade e disponibilidade; Armazenamento de dados e geração de relatórios; Integração de dados de diversos sites.

93
Replicação de dados Replicação de dados entre servidores e clientes: Suporte a troca de dados com usuários móveis; Utilizado a aplicativos de ponto de vendas para o consumidor; Integração de dados em diversos sites.

94
Replicação de dados Componentes de topologia de replicação: Publicador; Distribuidor; Assinantes; Publicações; Artigos; Assinaturas.

95
Replicação de dados Para entender melhor o conceito da replicação e sua topologia, normalmente usamos uma metáfora para exemplificar. No caso a metáfora é de uma editora de revista (ou jornal, se preferir), onde a própria editora é o “publicador”, o assinante é aquele que recebe seu exemplar da revista, o distribuidor é aquele que faz a entrega e assim por diante.
, onde a própria editora é o publicador , o assinante é aquele que recebe seu exemplar da revista, o distribuidor é aquele que faz a entrega e assim por diante..")
96
Replicação de dados O único detalhe em que esta metáfora não se enquadra quando relacionamos o caso da editora de revistas com a replicação em si é que na replicação de dados, o assinante pode efetuar atualizações (bilateral) e o publicador(editora) pode enviar alterações incrementais nos artigos.
 e o publicador(editora) pode enviar alterações incrementais nos artigos.")
97
Replicação de dados Em outras palavras, o que muda é que no caso de uma editora, você apenas recebe a informação, não atualiza e sempre a editora manda uma edição da revista na versão “final”.

98
Replicação de dados O tipo de replicação que você escolhe para um aplicativo, depende de muitos fatores, incluindo o ambiente físico da replicação, o tipo e a quantidade de dados a serem replicados e se os dados serão ou não atualizados no Assinante.

99
Replicação de dados O ambiente físico inclui o número e local dos computadores envolvidos na replicação e se esses computadores são clientes (estações de trabalho, laptops ou dispositivos portáteis) ou servidores.
 ou servidores.")
100
Replicação de dados Cada tipo de replicação começa normalmente com uma sincronização inicial dos objetos publicados entre o Publicador e os Assinantes.

101
Replicação de dados Esta sincronização inicial pode ser executada por replicação com um instantâneo, que é uma cópia de todos os objetos e dados especificados por uma publicação. Depois que o instantâneo é criado, ele é distribuído aos Assinantes.

102
Replicação de dados Para alguns aplicativos, a replicação de instantâneo é tudo o que é necessário. Para outros tipos de aplicativos, é importante que as alterações de dados subsequentes fluam para o Assinante de forma incremental com o passar do tempo.

103
Replicação de dados Alguns aplicativos também exigem que as alterações fluam do Assinante de volta para o Publicador. A replicação transacional e a replicação de mesclagem fornecem opções para estes tipos de aplicativos.

104
Replicação de dados As alterações de dados não são rastreadas para a replicação de instantâneo. Sempre que um instantâneo é aplicado, ele sobrescreve por completo os dados existentes. A replicação transacional rastreia as alterações pelo log de transação do SQL Server e a replicação de mesclagem rastreia as alterações pelos gatilhos e tabelas de metadados.

105
Replicação de dados Tipos de Replicação (Publicações): Replicação de Instantâneo (snapshot Publication) Replicação de Transacional (Transactional Publication) Replicação de Mesclagem (Merge Publication)
: Replicação de Instantâneo (snapshot Publication) Replicação de Transacional (Transactional Publication) Replicação de Mesclagem (Merge Publication)")
106
Replicação de instantâneo A replicação de instantâneo distribui os dados exatamente como eles aparecem em um momento específico no tempo e não monitora para as atualizações dos dados. Quando a sincronização ocorre, todo o instantâneo é gerado e enviado aos Assinantes.

107
Replicação de instantâneo A replicação de instantâneo pode ser usada por si só, mas o processo de instantâneo (o que cria uma cópia de todos os objetos e dados especificados por uma publicação) também é usado regularmente para fornecer o ajuste inicial dos dados e dos objetos do banco de dados para publicações de mesclagem e transacionais.
 também é usado regularmente para fornecer o ajuste inicial dos dados e dos objetos do banco de dados para publicações de mesclagem e transacionais.")
108
Replicação de instantâneo O uso da replicação de instantâneo por si só é mais apropriado quando um ou mais dos itens a seguir for verdadeiro: As alterações de dados ocorrerem raramente. É aceitável ter cópias de dados desatualizadas em relação ao Publicador por um período de tempo. Replicação de pequenos volumes de dados. Um volume grande de alterações ocorre por um curto período de tempo.

109
Replicação de instantâneo A replicação de Instantâneo é mais apropriada quando as alterações de dados forem significativas, mas pouco frequentes.

110
Replicação de instantâneo Por exemplo, se uma empresa de vendas mantiver uma lista de preços de produtos e os preços forem todos atualizados ao mesmo tempo uma ou duas vezes por ano, é recomendada a replicação de todo o instantâneo de dados após ele ter sido alterado.

111
Replicação de instantâneo A replicação de instantâneo tem uma sobrecarga contínua no Publicador inferior à replicação transacional, porque as alterações incrementais não são rastreadas. No entanto, se o ajuste do conjunto de dados que estiver sendo replicado for muito grande, ele exigirá recursos substanciais para gerar e aplicar o instantâneo.

112
Replicação de instantâneo Considere a dimensão de todo o conjunto de dados e a frequência de alterações nos dados ao avaliar a possibilidade de utilizar a replicação de instantâneo.

113
Replicação transacional A replicação transacional normalmente inicia com um instantâneo dos objetos e dados do banco de dados de publicação. Assim que o instantâneo inicial é tirado, as alterações subsequentes nos dados e as modificações no esquema efetuadas no Publicador geralmente são distribuídas para o Assinante assim que ocorrem (quase em tempo real).
..")
114
Replicação transacional As alterações nos dados são aplicadas ao Assinante na mesma ordem e dentro dos mesmos limites de transação conforme ocorreram no Publicador; por isso, dentro de uma publicação, a consistência transacional é assegurada.

115
Replicação transacional A replicação transacional é normalmente usada em ambientes do tipo servidor para servidor e é apropriada em cada um dos seguintes casos: Você quer que as alterações com incremento sejam propagadas para os Assinantes à medida que ocorrem; O aplicativo requer baixa latência entre as mudanças de hora feitas no Publicador, assim as mudanças chegarão ao Assinante;

116
Replicação transacional O aplicativo requer acesso aos estados de dados intermediários; Por exemplo, se uma linha muda cinco vezes, a replicação transacional permite que um aplicativo responda a cada mudança (como acionar um gatilho), e não simplesmente uma mudança de dados da rede na linha;
, e não simplesmente uma mudança de dados da rede na linha;")
117
Replicação transacional O Publicador tem um volume muito alto de atividade de inserção, atualização e exclusão; O Publicador ou Assinante é um banco de dados que não é do tipo SQL Server, como Oracle.

118
Replicação transacional Por padrão, os Assinantes de publicações transacionais devem ser tratados como somente leitura, porque as alterações não são propagadas de volta para o Publicador. Porém, replicação transacional oferece opções que permitem atualizações ao Assinante.

119
Replicação transacional O Publicador tem um volume muito alto de atividade de inserção, atualização e exclusão; O Publicador ou Assinante é um banco de dados que não é do tipo SQL Server, como Oracle.

120
Replicação de mesclagem A replicação de mesclagem, como a replicação transacional, normalmente inicia com um instantâneo dos objetos e dos dados do banco de dados de publicação.

121
Replicação de mesclagem As alterações dos dados subsequentes e as modificações de esquema feitas no Publicador e nos Assinantes são rastreadas com gatilhos. O Assinante sincroniza com o Publicador quando está conectado à rede e permuta todas as linhas que foram alteradas entre o Publicador e o Assinante desde a última vez que a sincronização ocorreu.

122
Replicação de mesclagem A replicação de mesclagem é usada normalmente em ambientes do tipo servidor para clientes. A replicação de mesclagem é apropriada em quaisquer das seguintes situações: Diversos Assinantes podem atualizar os mesmos dados diversas vezes e propagar essas alterações para o Publicador e outros Assinantes;

123
Replicação de mesclagem Os Assinantes precisam receber dados, fazer alterações offline e sincronizar posteriormente as alterações com o Publicador e outros Assinantes; Cada Assinante requer uma partição diferente de dados; Conflitos podem ocorrer e, quando isto acontecer, você precisará do recurso para detectá-los e encontrar a solução;

124
Replicação de mesclagem O aplicativo requer a alteração nos dados da rede no lugar do acesso aos estados de dados intermediários. Por exemplo, se uma linha for alterada cinco vezes em um Assinante antes de ele sincronizar com um Publicador, a linha será alterada somente uma vez no Publicador pra refletir a alteração dos dados na rede (ou seja, o quinto valor);
;.")
125
Replicação de mesclagem A replicação de mesclagem permite que diversos sites operem de forma autônoma e que as atualizações posteriores de mesclagem obtenham um único resultado uniforme. Como as atualizações são feitas em mais de um nó, os mesmos dados podem ter sido atualizados pelo Publicador e por mais de um Assinante.

126
Replicação de mesclagem Portanto, os conflitos podem ocorrer quando as atualizações forem mescladas e a replicação de mesclagem fornecer várias maneiras para controlar os conflitos.

127
Replicação de mesclagem Para rastrear as alterações, a replicação de mesclagem (e a replicação transacional, com assinaturas de atualização em fila) deve poder identificar exclusivamente cada linha em cada tabela publicada.
 deve poder identificar exclusivamente cada linha em cada tabela publicada.")
128
Banco de dados distribuídos O que é um banco de dados distribuído?

129
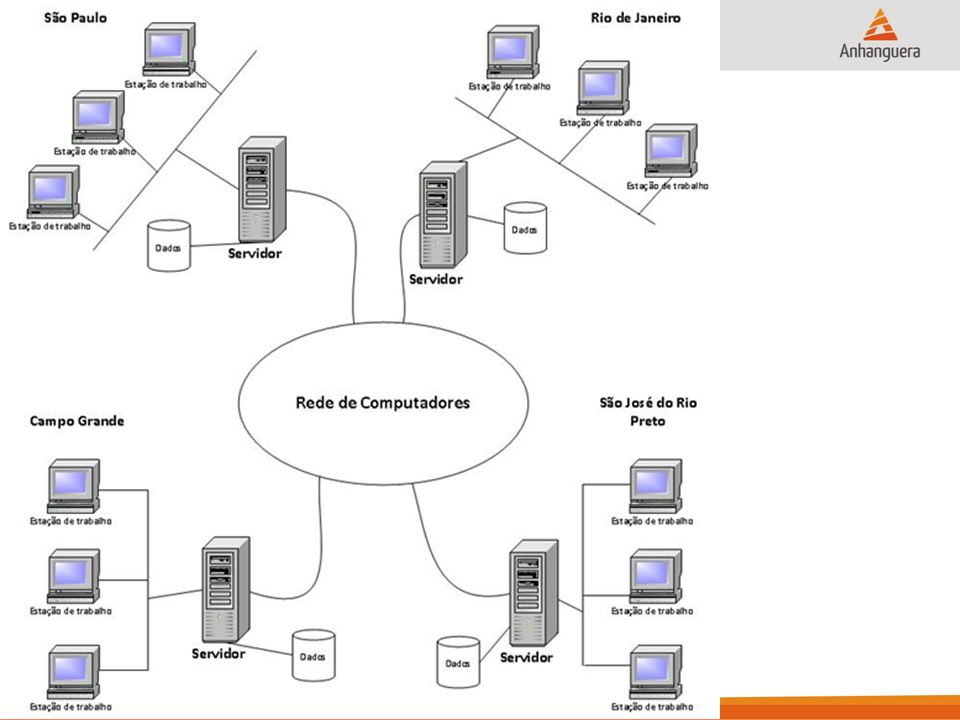
Banco de dados distribuídos Imagine uma instituição financeira na qual o banco de dados está distribuído em três grandes cidades brasileiras – São Paulo, Brasília e Rio de Janeiro, e transações distribuídas entre esses servidores são executadas o dia todo para armazenar informações e movimentações de seus clientes.

131
Banco de dados distribuídos Agora imagine a situação em que o cliente José sacou R$ 1.000,00 de sua conta corrente, e essa movimentação deve ser replicada para todos os servidores envolvidos na transação; caso contrario, o saldo de José ficará inconsistente, gerando informações diferentes em determinado servidor.

132
Banco de dados distribuídos Isso pode causar grandes transtornos, pois teoricamente o usuário acessa os dados em servidores de acordo com a localidade, diminuindo assim a latência e retornando o resultado com mais rapidez, ou seja, se o usuário está acessando sua conta em São Paulo, o sistema busca os dados nos servidores de São Paulo, e assim por diante.

133
Banco de dados distribuídos Como no exemplo José sacou R$ 1.000,00 de sua conta, imagine se ele estivesse em São Paulo e essa informação não fosse replicada para o servidor de Brasília? No servidor de São Paulo, ele estaria com determinado saldo e em Brasília com R$ 1.000,00 a mais em sua conta.

134
Banco de dados distribuídos Agora imagine o estoque de um produto que foi vendido porém não foi executada baixa em todos os servidores envolvidos na transação, gerando informações falsas sobre a quantidade em estoque desse produto. Um exemplo simples para demonstrar a consistência dos dados.

135
Banco de dados distribuídos Um sistema de banco de dados distribuído (BDD) consiste em uma relação de nós, cada qual podendo participar na execução de transações que acessam dados em um ou mais nós. Em um sistema de banco de dados distribuído, o banco de dados é armazenado em diversos computadores (nós).
..")
136
Banco de dados distribuídos Os computadores, em um sistema distribuído, comunicam-se uns com os outros por intermédio de vários meios de comunicação, tais como: Redes de alta velocidade, Redes sem fio ou Linhas telefônicas, Obs.: Eles não compartilham a memória principal e o relógio.

137
Banco de dados distribuídos A diferença principal entre sistemas de banco de dados centralizados e distribuídos é que no primeiro os dados estão localizados em um único lugar, enquanto que no outro os dados residem em diversos locais.

138
Banco de dados distribuídos A arquitetura de BDD é totalmente transparente para os usuários que utilizam aplicações nessa arquitetura distribuída, ou seja, para o usuário, os dados estão centralizados em um único servidor, mas na verdade eles podem estar “espalhados”, distribuídos em vários locais fisicamente separados.

139
Banco de dados distribuídos

140
Os processadores em um sistema distribuído podem variar em tamanho e função, podendo incluir microcomputadores, estações de trabalho, minicomputadores e sistemas de computadores de uso em geral. Estes processadores são geralmente chamados de nós, dependendo do contexto no qual eles estejam mencionados. Usa-se principalmente o termo nó (lugar, posição), a fim de enfatizar a distribuição física destes sistemas.
, a fim de enfatizar a distribuição física destes sistemas..")
141
Banco de dados distribuídos

142
Os processadores em um sistema distribuído podem variar em tamanho e função, podendo incluir microcomputadores, estações de trabalho, minicomputadores e sistemas de computadores de uso em geral. Estes processadores são geralmente chamados de nós, dependendo do contexto no qual eles estejam mencionados. Usa-se principalmente o termo nó (lugar, posição), a fim de enfatizar a distribuição física destes sistemas.
, a fim de enfatizar a distribuição física destes sistemas..")
143
Banco de dados distribuídos Uma tabela possui diversos enfoques para o armazenamento em um banco de dados distribuído (BDD): Replicação: o sistema mantém réplicas idênticas da relação, onde cada réplica é armazenada em sites diferentes, resultando na replicação dos dados; Fragmentação: a relação é particionada em vários fragmentos, onde cada fragmento é armazenado em um site diferente; Replicação e fragmentação: a relação é particionada em vários segmentos, e o sistema mantém diversas réplicas de cada fragmento.
: Replicação: o sistema mantém réplicas idênticas da relação, onde cada réplica é armazenada em sites diferentes, resultando na replicação dos dados; Fragmentação: a relação é particionada em vários fragmentos, onde cada fragmento é armazenado em um site diferente; Replicação e fragmentação: a relação é particionada em vários segmentos, e o sistema mantém diversas réplicas de cada fragmento.")
144
Banco de dados distribuídos Replicação de dados A replicação de dados significa que um determinado objeto de dados lógico pode possuir diversos representantes armazenados, em nós. O grau de suporte para a replicação é um pré-requisito para atingir o verdadeiro potencial de um sistema distribuído.

145
Banco de dados distribuídos Fragmentação de dados Uma relação é dividida em fragmentos, onde cada fragmento contem informação suficiente para permitir a reconstrução da relação original. Existem duas formas de fazer a fragmentação: Fragmentação Horizontal: divide a relação separando as tuplas de r em dois ou mais fragmentos. Fragmentação Vertical: divide a relação pela decomposição do esquema R da relação r.

146
Banco de dados distribuídos Processamento de consultas distribuídas A transparência para leitura é mais fácil de se conseguir e manter do que a transparência para atualização. O maior problema para a atualização é garantir que todas as réplicas e fragmentos sejam atualizados, após uma atualização em uma das réplicas ou fragmentos. A atualização deve ser prolongada para todas as cópias (réplicas e fragmentos) existentes no sistema.
 existentes no sistema..")
147
Banco de dados distribuídos Processamento de consultas distribuídas Um dos fatores mais importantes no desempenho de uma consulta, em uma base centralizada, é a quantidade de acesso a disco necessária para atingir o resultado. Em um banco distribuído os problemas aumentam, pois existe também a preocupação com a transmissão de dados na rede. Um fator interessante para a consulta realizada em uma base distribuída é que os diversos sites podem processar partes da consulta em paralelo.

148
Banco de dados distribuídos Processamento de consultas distribuídas Na realização de uma consulta simples (trivial), como consultar todas as tuplas da relação CONTA, pode caracterizar um processamento não tão trivial, pois CONTA pode estar fragmentada, replicada ou ambas.
, como consultar todas as tuplas da relação CONTA, pode caracterizar um processamento não tão trivial, pois CONTA pode estar fragmentada, replicada ou ambas.")
149
Banco de dados distribuídos Transações O acesso a diversos itens de dados em um sistema distribuído é normalmente acompanhado de transações que têm de preservar as propriedades ACID: A: Atomicidade C: Consistência I: Isolamento D: Durabilidade

150
Banco de dados distribuídos Atomicidade: Indica que a transação deve ter todas as suas ações concluídas ou não. Caso todas as ações da transação sejam terminadas com sucesso, então é executado oCommit na transação inteira; caso contrário, a transação inteira deve ser revertida, Rollback.

151
Banco de dados distribuídos Consistência: A execução de uma transação isolada preserva a consistência do banco de dados. Isolamento: Cada transação não toma conhecimento de outras transações concorrentes. Durabilidade: Depois da transação completar-se com sucesso (Commit), as mudanças que ela faz no banco de dados persistem.
, as mudanças que ela faz no banco de dados persistem..")
152
Banco de dados distribuídos Tipos de transações Locais: mantem acesso e atualizam somente a base de dados local. Globais: mantem acesso e atualizam diversas bases de dados locais.

153
Banco de dados distribuídos Protocolos de efetivação Os protocolos de efetivação garantem integridade de transação distribuída que atinge mais de um servidor, fazendo com que a transação só seja efetuada (Commit) ou abortada (Rollback) quando todos os servidores entram em um acordo.
 ou abortada (Rollback) quando todos os servidores entram em um acordo.")
154
Banco de dados distribuídos Protocolos de efetivação Two-Phase Commit O protocolo de efetivação Two-Phase Commit é composto por duas fases, em que todos os servidores envolvidos na transação T entram em acordo se efetivaram (Commit) ou abortaram (Rollback) a transação.
 ou abortaram (Rollback) a transação.")
155
Banco de dados distribuídos Protocolos de efetivação Three-Phase Commit O protocolo Three-Phase Commit é uma continuação do protocolo de duas fases em que é adicionada uma terceira fase que busca a diminuição de falhas do coordenador. Com a implementação da terceira fase, a troca de dados entre coordenador e gerenciadores de transação aumenta o grau de complexidade e proporciona um maior trafego na rede (overhead).
..")
156
Banco de dados distribuídos Coordenador Um dos nós participantes, por exemplo o nó de origem da transação, é estabelecido, "a priori", como o coordenador da operação. Este coordenador é conhecido dos demais nós e também dispõe da identidade de todos os nós participantes. Isto não é difícil de ser conseguido durante a fase em que a transação migra de um nó para outro e dados são enviados de volta aos nós requisitantes.

157
Banco de dados distribuídos Funções Adicionais Rastreamente de dados. Processamento de consultas distribuídas. Gerenciamento de transações distribuídas. Gerenciamento de dados replicados. Recuperação de banco de dados distribuído. Segurança. Gerenciamento do diretório distribuído

158
Banco de dados distribuídos Vantagens Gerenciamento de dados distribuído com níveis diferentes de transparência. Transparência de distribuição ou de rede. Transparência de replicação. Transparência de fragmentação. Melhoria da confiabilidade e na disponibilidade. Melhoria no desempenho. Expansão mais fácil.

159
Banco de dados distribuídos

160
Falhas Em um sistema de banco de dados distribuído pode sofrer os mesmos tipos de falhas que ocorrem em um sistema centralizado, porem existem falhas adicionais que podem ocorrer em um (BDD), tais como: falha de comunicação entre eles, perda de mensagens e o particionamento da rede; Cada um desses problemas devem ser considerados no projeto de recuperação de um BDD. Para um sistema ser robusto, ele precisa detectar qualquer uma dessas falhas, reconfigurar-se enquanto a falha é recuperada.

161
Banco de dados distribuídos Desvantagens A complexidade dos problemas é uma desvantagem, porque os problemas são mais complexos do que em bancos de dados centralizados, pois além de haver os problemas que são comuns em banco de dados centralizados, que normalmente ocorrem nos servidores locais, haverá os problemas que surgem com a comunicação entre esses servidores locais.

162
Banco de dados distribuídos Desvantagens Implantação mais cara – o aumento da complexidade e uma infraestrutura mais extensa significam custo extra de trabalho. Falta de padrões – ainda não há metodologias e ferramentas para ajudar usuários a converterem um SGBD centralizado para um SGBD distribuído.

Apresentações semelhantes



 Alguém explorou uma conta privilegiada e através dela.>")





 é um sistema de gerenciamento de nomes hierárquicos.>")

 GERENCIAMENTO DE CONFIGURAÇÃO E SOLICITAÇÃO DE MUDANÇAS Análise de Sistema ll Prof° Andrea Padovan Ademir Kaique Claudio.>")

 Profª Cynara Carvalho.>")

 querem o poder e a flexibilidade de gerir.>")



