Carregar apresentação
A apresentação está carregando. Por favor, espere

1
Análise de Sobrevivência Professor: Dani Gamerman
IM - UFRJ Professor: Dani Gamerman

2
1. CONCEITOS ESTATÍSTICOS EM SOBREVIVÊNCIA
1.1 Introdução Análise de Sobrevivência é o estudo de indivíduos (itens observados) onde um evento bem definido (falha) ocorre depois de algum tempo (tempo de falha). Exemplos: (i) tempo de falha de equipamentos industriais (engenharia) (ii) tempo de sobrevida de um paciente (medicina) (iii) tempo de duração do período de desemprego ou greve (economia) Definindo algumas características: (i) as variáveis de resposta são não-negativas (ii) principalmente univariados e contínuos (iii) presença comum de censura Primeiramente, é importante ter uma definição precisa de tempo de falha. Isto requer especificações sobre: origem do tempo de falha unidade de medida do tempo (calendários, tempo de operação, milhagem, número de ciclos) falha (mais fácil na medicina: morte, não tão fácil na engenharia).
 onde um evento bem definido (falha) ocorre depois de algum tempo (tempo de falha). Exemplos: (i) tempo de falha de equipamentos industriais (engenharia) (ii) tempo de sobrevida de um paciente (medicina) (iii) tempo de duração do período de desemprego ou greve (economia) Definindo algumas características: (i) as variáveis de resposta são não-negativas. (ii) principalmente univariados e contínuos. (iii) presença comum de censura. Primeiramente, é importante ter uma definição precisa de tempo de falha. Isto requer especificações sobre: origem do tempo de falha. unidade de medida do tempo (calendários, tempo de operação, milhagem, número de ciclos) falha (mais fácil na medicina: morte, não tão fácil na engenharia).")
3
1.2 Resultados em Sobrevivência
Exemplo: tempo de falha de um carro Questões a serem feitas: Quando começar a contar o tempo? Como medir o tempo de falha? O que é falha? Nós devemos estudar melhor todas essas especificações. 1.2 Resultados em Sobrevivência 1) Descritiva vs Inferência Estatística Em algumas aplicações, características descritivas simples como média simples, função de sobrevivência e gráficos de probabilidades são suficientes. Em outras aplicações, intervalos de confiança ou taxa de influência de determinadas variáveis são exigidas. 2) Censura Um sistema pode falhar mesmo antes que todos os itens tenham falhado em um determinado tempo. Este fato tem determinadas razões. Os itens são normalmente censurados à direita. Mas podem ainda ser censurados à esquerda ou podemos determinar um intervalo de censura(mais difícil de analisar) 3) Paramétrico ou Não-Paramétrico Ambos serão vistos no curso. E ainda os Semi-Paramétricos serão apresentados.
 Descritiva vs Inferência Estatística. Em algumas aplicações, características descritivas simples como média simples, função de sobrevivência e gráficos de probabilidades são suficientes. Em outras aplicações, intervalos de confiança ou taxa de influência de determinadas variáveis são exigidas. 2) Censura. Um sistema pode falhar mesmo antes que todos os itens tenham falhado em um determinado tempo. Este fato tem determinadas razões. Os itens são normalmente censurados à direita. Mas podem ainda ser censurados à esquerda ou podemos determinar um intervalo de censura(mais difícil de analisar) 3) Paramétrico ou Não-Paramétrico. Ambos serão vistos no curso. E ainda os Semi-Paramétricos serão apresentados.")
4
4) Amostras Simples vs Modelos de Regressão
Se os itens pertencem à mesma população (são similares), então uma análise de amostras simples deve ser utilizada. Se os itens não são da mesma população e se suas diferenças podem ser contadas (máquinas submetidas a pressões distintas), então estas diferenças devem ser consideradas na Análise. Variáveis para medir tais diferenças (pressão) são denominadas variáveis explanatórias ou covariáveis. Ambos serão vistos no decorrer do curso. 5) Clássica vs Bayesiana Ambas serão rapidamente revisadas e vistas neste curso. Modelos Bayesianos tiveram no passado a desvantagem de que sua Análise através de Modelos de Regressão requeriam muito esforço computacional . Isto, com o tempo, foi se tornando cada vez menos importante. Métodos bayesianos são importantes em estudos de sobrevivência porque freqüentemente temos informações de experiências anteriores que podem usualmente serem combinadas com os dados e incorporadas à análise.
, então uma análise de amostras simples deve ser utilizada. Se os itens não são da mesma população e se suas diferenças podem ser contadas (máquinas submetidas a pressões distintas), então estas diferenças devem ser consideradas na Análise. Variáveis para medir tais diferenças (pressão) são denominadas variáveis explanatórias ou covariáveis. Ambos serão vistos no decorrer do curso. 5) Clássica vs Bayesiana. Ambas serão rapidamente revisadas e vistas neste curso. Modelos Bayesianos tiveram no passado a desvantagem de que sua Análise através de Modelos de Regressão requeriam muito esforço computacional . Isto, com o tempo, foi se tornando cada vez menos importante. Métodos bayesianos são importantes em estudos de sobrevivência porque freqüentemente temos informações de experiências anteriores que podem usualmente serem combinadas com os dados e incorporadas à análise.")
5
1.3 Sistema Reparáveis e Não-Reparáveis
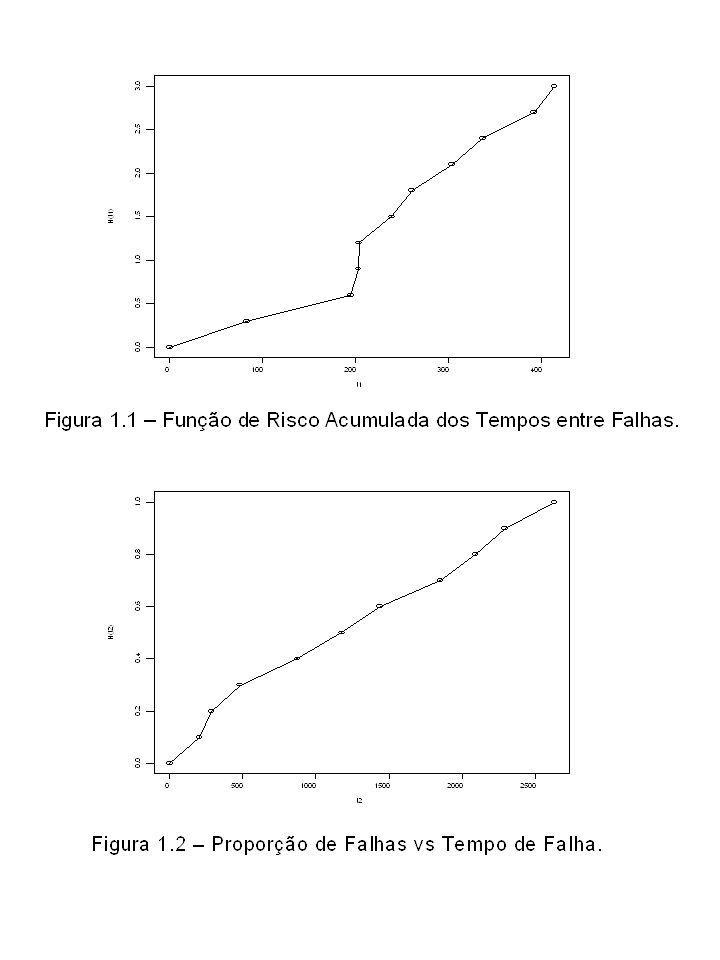
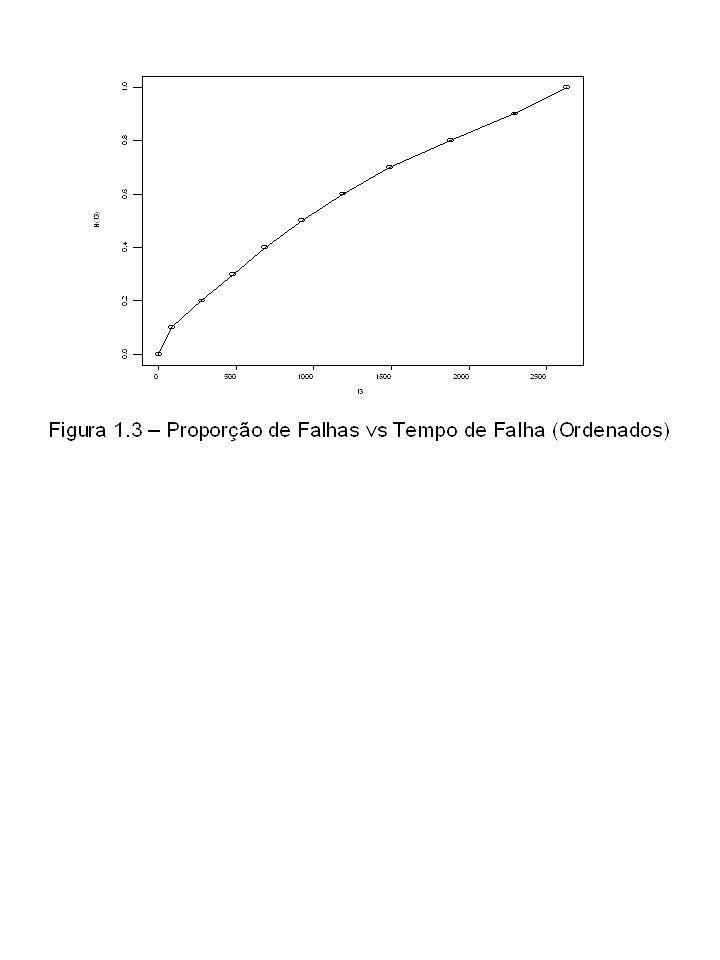
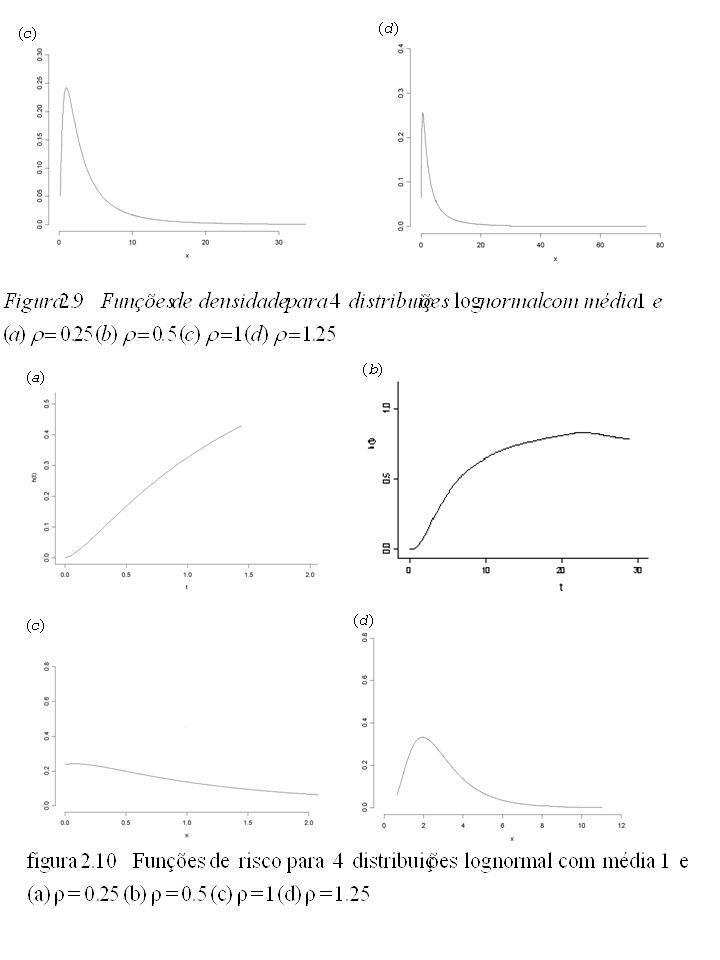
Outra importante definição, embora somente depois será vista neste curso. Considere o experimento com um sistema reparável e os seguintes tempos de falha cumulativos: 203, 286, 481, 873, 1177, 1438, 1852, 2091, 2295, 2632. Vejamos alguns itens interessantes sobre se a taxa de falha aumenta ou diminui com o tempo. Se o sistema é tomado como não reparável, então o tempo entre falhas é considerado. Um exemplo de análise simples na Figura 1.1 indica o aumento da taxa de falha. Conforme o tempo passa, é mais provável que uma máquina deste tipo venha a falhar. Para sistemas reparáveis o exemplo da análise simples na Figura 1.2 indica taxa de falha constante em relação ao tempo. Se os tempos entre falhas são ordenados e o sistema é reparável, a Figura 1.3 indica que a taxa de falha é decrescente. Sistemas reparáveis com processo de tempo de falha ideais não serão vistos neste curso.

8
1.4 Componentes e Sistemas Reparáveis
Neste curso, trataremos de componentes reparáveis sem referência aos sistemas que podem conter tais componentes. Porém, é importante afirmar que Sistemas Reparáveis também são uma importante área de estudo. Os sistemas mais simples são: Sistemas em Série: o sistema só funciona se todas as componentes funcionarem. Sistemas Paralelos: o sistema só falha se todas as componentes falharem Sistemas k out of n : o sistema só funciona se pelo menos k das n componentes funcionarem(se k=1 paralelo e se k=n série). Esses sistemas formam grande parte dos grupos de sistemas chamados Sistemas Coerentes. Para entender o conceito de sistemas coerentes é útil definir o indicador de funcionamento xi para a componente i e a função de estrutura das n componentes do sistema: 1, se o sistema funciona. (x1,x2,...,xn) = 0, caso contrário.
. Esses sistemas formam grande parte dos grupos de sistemas chamados Sistemas Coerentes. Para entender o conceito de sistemas coerentes é útil definir o indicador de funcionamento xi para a componente i e a função de estrutura das n componentes do sistema: 1, se o sistema funciona. (x1,x2,...,xn) = 0, caso contrário.")
9
1.5 Distribuições Binomial e Hipergeométrica
Sistemas coerentes têm função de estrutura que satisfaz: (i) (1,1,..., 1)=1 (ii) (0, 0,..., 0)=0 (iii) é não-decrescente nesses argumentos. Outros sistemas são: Sistemas multi-estados: onde as componentes podem estar em vários estados (não só funcionando ou falhando) Sistemas load-sharing: onde a carga do sistema é distribuída entre as componentes que funcionam. 1.5 Distribuições Binomial e Hipergeométrica Análises estatísticas simples são obtidas se os tempos de falha são dicotomizados: funcionar até certo tempo (digamos tempo de falha): defeituoso. funcionar além deste tempo: não-defeituoso. Distribuições Binomial e Geométrica são para um número X de itens defeituosos em uma amostra de tamanho n e probabilidade p do item ser defeituoso. Se uma amostra com reposição (ou que não seja de uma população muito grande), a distribuição Binomial é obtida como:
 (1,1,..., 1)=1. (ii) (0, 0,..., 0)=0. (iii) é não-decrescente nesses argumentos. Outros sistemas são: Sistemas multi-estados: onde as componentes podem estar em vários estados (não só funcionando ou falhando) Sistemas load-sharing: onde a carga do sistema é distribuída entre as componentes que funcionam. 1.5 Distribuições Binomial e Hipergeométrica. Análises estatísticas simples são obtidas se os tempos de falha são dicotomizados: funcionar até certo tempo (digamos tempo de falha): defeituoso. funcionar além deste tempo: não-defeituoso. Distribuições Binomial e Geométrica são para um número X de itens defeituosos em uma amostra de tamanho n e probabilidade p do item ser defeituoso. Se uma amostra com reposição (ou que não seja de uma população muito grande), a distribuição Binomial é obtida como:")
10
P(X=k) = n pk(1-p)n-k onde 0 k n
E(X)=np e Var(X)=np(1-p) Quando p é desconhecido, podemos estimá-lo como: P = X/n e Var(X) = np(1-p) Para n grande, np5 e n(1-p)5, a Binomial é aproximada pela distribuição Normal com momentos conforme os descritos anteriormente. Para uma aproximação ao nível de significância 100(1-)%, o intervalo de confiança para p é dado por: (X/n - z/2 (X(n-X)/n3)1/2, X/n + z/2 (X(n-X)/n3)1/2) onde z/2 é o quartil(1-/2) da distribuição N(0,1). Outra aproximação para n grande e =np (p pequeno) é a distribuição de Poisson com média . Equivalentemente testando a independência e constância de p. Se as amostras são sem reposição e de uma população finita, a distribuição Hipergeométrica é obtida como: n N-n P(X=k)= k K-k k=0,1,..,K N K
=np e Var(X)=np(1-p) Quando p é desconhecido, podemos estimá-lo como: P = X/n e Var(X) = np(1-p) Para n grande, np5 e n(1-p)5, a Binomial é aproximada pela distribuição Normal com momentos conforme os descritos anteriormente. Para uma aproximação ao nível de significância 100(1-)%, o intervalo de confiança para p é dado por: (X/n - z/2 (X(n-X)/n3)1/2, X/n + z/2 (X(n-X)/n3)1/2) onde z/2 é o quartil(1-/2) da distribuição N(0,1). Outra aproximação para n grande e =np (p pequeno) é a distribuição de Poisson com média . Equivalentemente testando a independência e constância de p. Se as amostras são sem reposição e de uma população finita, a distribuição Hipergeométrica é obtida como: n N-n. P(X=k)= k K-k k=0,1,..,K. N. K.")
11
onde N é o tamanho da população e K é a população de itens defeituosos.
E(X)=np e Var(X)=np(1-p)N-n para p=K/N N-1 1.6 Processos de Poisson Usado particularmente para sistemas reparáveis. Assume-se primeiramente que é observada uma série de ocorrências em linha. (As ocorrências devem ser falhas sucessivas do sistema e a linha representa o tempo real). Assume-se que: (i) as falhas ocorrem em intervalos disjuntos e independentes (ii) ocorrência = falha (iii) a taxa de falha é uma constante . Então se X é o número de falhas num intervalo de tamanho s, X tem distribuição de Poisson com média s. Também, os tempos entre falhas são independentes e exponencialmente distribuídos com MTFB -1. Isto indica que a exponencial com linha base (solo) é a distribuição para o tempo de falha. Isto pode ser generalizado para permitir taxas de falha não constantes. Processo de Poisson não-homogêneo.
=np e Var(X)=np(1-p)N-n para p=K/N. N Processos de Poisson. Usado particularmente para sistemas reparáveis. Assume-se primeiramente que é observada uma série de ocorrências em linha. (As ocorrências devem ser falhas sucessivas do sistema e a linha representa o tempo real). Assume-se que: (i) as falhas ocorrem em intervalos disjuntos e independentes. (ii) ocorrência = falha. (iii) a taxa de falha é uma constante . Então se X é o número de falhas num intervalo de tamanho s, X tem distribuição de Poisson com média s. Também, os tempos entre falhas são independentes e exponencialmente distribuídos com MTFB -1. Isto indica que a exponencial com linha base (solo) é a distribuição para o tempo de falha. Isto pode ser generalizado para permitir taxas de falha não constantes. Processo de Poisson não-homogêneo.")
12
2. DISTRIBUIÇÕES DE PROBABILIDADE 2.1 Introdução
Em muitas áreas de aplicação da estatística, o ponto inicial para avaliação da variável de interesse é a distribuição Normal. Isto pode resultar de uma consideração pragmática pura ou da argumentação baseada no Teoria do Limite central, que diz que se uma variável aleatória é a soma de um grande número de pequenos efeitos , então a distribuição é aproximadamente Normal. No contexto de sobrevivência, o caso da normalidade é muito menos usado. Para que possamos entender, tempos de vida e resistência são quantidades positivas. Do ponto de vista do modelo, é natural começar a pensar no processo de Poisson, idéias já discutidas na sessão 1.6, baseado na distribuição Exponencial. Contudo esta distribuição tem uma limitada aplicabilidade na prática, generalizações da Exponencial como a Gamma e a Weibull já provarão ter maior valor prático em modelos de sobrevivência. Estas e outras distribuições de probabilidade comumente encontradas em estudos de sobrevivência são discutidas nas sessões 2.3 à 2.7. Outros aspectos centrais da discussão sobre análise de sobrevivência são as funções de sobrevivência e de risco, e a natural ocorrência de dados censurados. Estes assuntos são discutidos nas sessões 2.2 e 2.8.

13
2.2 Conceitos Iniciais para a Distribuição de Sobrevivência
Finalmente neste capítulo colocamos os resultados probabilísticos em contexto de análise de dados. Contudo métodos gerais para ajustar distribuições de probabilidades são desenvolvidos no Capítulo 3, algumas técnicas básicas são apresentadas na sessão 2.9 à 2.11. 2.2 Conceitos Iniciais para a Distribuição de Sobrevivência Chamaremos de T a variável aleatória que representará o tempo de falha dentro do nosso estudo. Aqui a noção de tempo é usada de maneira genérica. Ele pode ser realmente tempo ou qualquer outra variável não negativa, desde que haja um número qualquer de falhas ou quebras associado a variável. Denotamos : sendo a distribuição de T e denotamos : sendo a Função de Sobrevivência de T. Note que alguns autores definem F(t) e S(t) por Pr(T<=t) e Pr(T>t) respectivamente. Na prática isto não faz diferença para os resultados que se seguem quando T é uma variável continua, este caso será considerado a partir de agora. Nós iremos assumir que T tem a função de densidade :
 e S(t) por Pr(T<=t) e Pr(T>t) respectivamente. Na prática isto não faz diferença para os resultados que se seguem quando T é uma variável continua, este caso será considerado a partir de agora. Nós iremos assumir que T tem a função de densidade :")
14
tal que a probabilidade da unidade falhar em um curto espaço de tempo [t , t+t) é :
Considere a probalidade condicional do item falhar naquele instante [t , t+t) e não ter falhado até o tempo t : Podemos pensar como a probabilidade do item iminentemente falhar em t. A função h(t) é dada por : esta é a função de risco, de taxa de falha, ou hazard e é um indicador natural da propensão a falha após uma unidade de tempo ter transcorrido. A função de taxa de falha acumulada é dada por : e concluímos que : 2.1
 e não ter falhado até o tempo t : Podemos pensar como a probabilidade do item iminentemente falhar em t. A função h(t) é dada por : esta é a função de risco, de taxa de falha, ou hazard e é um indicador natural da propensão a falha após uma unidade de tempo ter transcorrido. A função de taxa de falha acumulada é dada por : e concluímos que : 2.1.")
15
Note que f, F, S, h e H são funções tais que o conhecimento de uma delas nos permite o cálculo de todas as outras. Alguns casos típicos são discutidos aqui : Se h(t)= é constante então H(t)= t e S(t)=exp(-t ) é a distribuição de sobrevivência exponencial com parâmetro . A densidade correspondente é f(t)= exp(-t). Se h(t) é uma função crescente de t , então T é dito ter uma taxa de falha crescente (IFR). Isto á apropriado quando a unidade medida tem relação com fadiga ou danos cumulativos. Se h(t) é uma função decrescente de t, então T é dito ter um taxa de falha decrescente (DFR). Isto pode ocorrer, por exemplo, quando o processo diminui a quantidade produzida ao longo do tempo diminuindo o risco de falha. Isto é comum em alguns ambientes de produção de componentes eletrônicos. Outro caso comum mencionado é o “bat-tub harzard” onde a função de taxa de falha é decrescente inicialmente e depois torna-se crescente. Isto costuma acontecer em linha de produção onde os componentes iniciais tem uma qualidade melhor que os finais provocando este tipo de oscilação na taxa de falha.
= é constante então H(t)= t e S(t)=exp(-t ) é a distribuição de sobrevivência exponencial com parâmetro . A densidade correspondente é f(t)= exp(-t). Se h(t) é uma função crescente de t , então T é dito ter uma taxa de falha crescente (IFR). Isto á apropriado quando a unidade medida tem relação com fadiga ou danos cumulativos. Se h(t) é uma função decrescente de t, então T é dito ter um taxa de falha decrescente (DFR). Isto pode ocorrer, por exemplo, quando o processo diminui a quantidade produzida ao longo do tempo diminuindo o risco de falha. Isto é comum em alguns ambientes de produção de componentes eletrônicos. Outro caso comum mencionado é o bat-tub harzard onde a função de taxa de falha é decrescente inicialmente e depois torna-se crescente. Isto costuma acontecer em linha de produção onde os componentes iniciais tem uma qualidade melhor que os finais provocando este tipo de oscilação na taxa de falha.")
16
2.3 A Distribuição Exponencial
Como mencionado na sessão 1.6, a distribuição exponencial é o ponto natural de início para uma distribuição de sobrevivência. Relembrando temos que a Distribuição de Sobrevivência, hazard e função de densidade tem a seguinte forma: onde é um parâmetro positivo, freqüentemente chamado de taxa, e onde t>0. Note também que a distribuição exponencial tem média 1/ e variância 1/ 2. A forma da densidade é a mesma para todos os , e 1/ age como um parâmetro de escala. Então, por exemplo, se o tempo de sobrevivência, T, de um certo tipo de componente é medido em minutos e ele é distribuído exponencialmente com taxa igual , então T*=T/60 medido em horas é distribuído exponencialmente com taxa 60 . Uma outra formulação comum é termos a parametrização = 1/ no lugar de . A Figura 2.1 mostra duas densidades da distribuição exponencial com diferentes taxas. 2.2

17
As funções hazard correspondentes são apresentadas na Figura 2. 2
As funções hazard correspondentes são apresentadas na Figura 2.2. Nós iremos mostrar que a Distribuição Exponencial é um caso especial das Famílias de Distribuições Weibull e Gamma.

18
2.4 Distribuições Weibull e Gumbel
Uma variável aleatória Weibull (W. Weibull (1939,1951)) possui a seguinte função de sobrevivência: para t>0 e onde e são parâmetros positivos, sendo um parâmetro de escala e um parâmetro de forma. Note que quando =1, obtemos uma Distribuição Exponencial com parâmetro =1/ . 2.3
) possui a seguinte função de sobrevivência: para t>0 e onde e são parâmetros positivos, sendo um parâmetro de escala e um parâmetro de forma. Note que quando =1, obtemos uma Distribuição Exponencial com parâmetro =1/ ")
19
A função de falha (hazard) da Weibull é :
Então temos DFR para <1, constante para =1 e IFR para >1. Em particular, para 1<<2 a função de falha se aproxima de uma função linear e para =2 a função é linear; para >2 a função cresce rapidamente acima de uma função linear. A função de taxa de falha (hazard) da Weibull para diferentes valores dos parâmetros é mostrada na Figura 2.3. A função de densidade da Weibull é para t > 0. 2.4
 da Weibull para diferentes valores dos parâmetros é mostrada na Figura 2.3. A função de densidade da Weibull é. para t >")
20
A média e a variância são dadas por :
2.5

21
veja , por exemplo, Abramowitz and Stegun (1972, CAPITULO 6)
veja , por exemplo, Abramowitz and Stegun (1972, CAPITULO 6). Um programa em fortran para calcular a equação 2.5 é dado em Griffiths and Hill (1985, pp ), que é baseado em um programa anterior de Pike e Hill (1966). Quando é grande (>5), a média e a variância são aproximadamente e 1.642/ respectivamente. A forma da densidade depende de . Na Figura 2.4 são mostradas algumas funções de densidade da Weibull para diferentes valores de .
. Um programa em fortran para calcular a equação 2.5 é dado em Griffiths and Hill (1985, pp ), que é baseado em um programa anterior de Pike e Hill (1966). Quando é grande (>5), a média e a variância são aproximadamente e 1.642/ respectivamente. A forma da densidade depende de . Na Figura 2.4 são mostradas algumas funções de densidade da Weibull para diferentes valores de .")
22
A Distribuição de Gumbel tem a seguinte função de sobrevivência :
A Distribuição Weibull é provavelmente a mais utilizada das distribuições em análise de sobrevivência. Uma possível explicação para isto se deve ao seu comportamento nos extremos da distribuição, à possibilidade de variarmos o seu formato e em particular a possibilidade de utilizá-la como uma generalização da Exponencial. A Distribuição de Gumbel tem a seguinte função de sobrevivência : para , onde é o parâmetro de locação e é o parâmetro de escala. Esta distribuição também começa com limite de distribuição mínimo, veja Galambos (1978), e tem uma taxa de falha exponencial crescente. Em alguns casos permite valores negativos com probabilidades positivas. Mais comumente a distribuição de Gumbel é gerada através de Log(t) quando T tem uma distribuição Weibull. A relação entre os parâmetros da Gumbel e da Weibull é a seguinte : A função de densidade da Gumbel é a seguinte : 2.6
, e tem uma taxa de falha exponencial crescente. Em alguns casos permite valores negativos com probabilidades positivas. Mais comumente a distribuição de Gumbel é gerada através de Log(t) quando T tem uma distribuição Weibull. A relação entre os parâmetros da Gumbel e da Weibull é a seguinte : A função de densidade da Gumbel é a seguinte : 2.6.")
23
para , e tem a mesma forma para todos os parâmetros.
Note que a média e a variância da Gumbel são - e (2/6)2, respectivamente, onde = é a constante de Euler, e a distribuição é negativamente inclinada. A densidade e a taxa de falha (harzard) para a distribuição de Gumbel com =0 e =1 é mostrada nas Figuras 2.5 e 2.6 respectivamente.
2, respectivamente, onde = é a constante de Euler, e a distribuição é negativamente inclinada. A densidade e a taxa de falha (harzard) para a distribuição de Gumbel com =0 e =1 é mostrada nas Figuras 2.5 e 2.6 respectivamente.")
24
2.5 Distribuições Normal e Lognormal
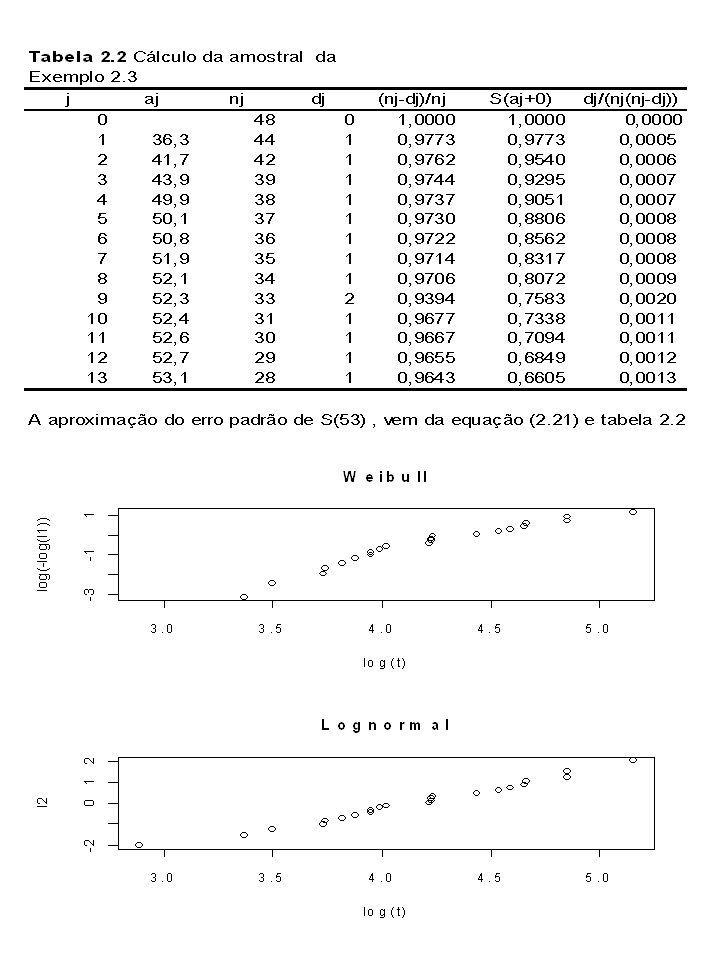
A distribuição Normal é a distribuição mais comumente utilizada em Estatística. Em confiabilidade é geralmente usada como um modelo para log T. A função de densidade da distribuição lognormal é descrita pela equação abaixo: As funções de Sobrevivência e de Risco podem ser escritas somente em termos de integrais. Algumas densidades e funções de risco são plotadas na figura 2.9 e A função de Risco é crescente para valores de t próximos de zero e eventualmente decrescente quando

26
2. 6 Distribuições Gama e Gama Generalizada
2.6 Distribuições Gama e Gama Generalizada A distribuição Gama é descrita pela equação abaixo: Densidades são positivas (ver figura 2.11) mas tendem para normal quando é grande. As funções de Sobrevivência e risco podem ser escritas somente em termos de integrais. A função de risco é decrescente para , constante para (exponencial) e crescente para (ver figura 2.12). A Gama é obtida como a distribuição do -ésimo tempo de falha em um processo de Poisson .
 mas tendem para normal quando é grande. As funções de Sobrevivência e risco podem ser escritas somente em termos de integrais. A função de risco é decrescente para , constante para (exponencial) e crescente para. (ver figura 2.12). A Gama é obtida como a distribuição do -ésimo tempo de falha em um processo de Poisson .")
28
A distribuição gama generalizada é descrita pela equação abaixo:
A distribuição gama generalizada inclui os seguintes casos especiais:

29
2.7 Distribuição Exponencial por Partes
Uma generalização da distribuição exponencial Temos abaixo a função de Risco: Vantagem: Pode-se aproximar qualquer função de Risco desejada. Desvantagem: Grande número de parâmetros (“não-paramétrica”)
")
30
2.8 Censura Observações incompletas freqüentemente ocorrem nos estudos de sobrevivência e confiabilidade. Nos testes de confiabilidade é comum aguardar até todos os itens falharem. Nos estudos de sobrevivência, pacientes abandonam o tratamento ou continuam vivos depois do final dos estudos. Isso resulta em algumas observações incompletas, ditas censuradas. Tipos comuns de censura a direita: Tipo I: Observações são acompanhadas até um tempo c fixado inicialmente. Tipo II: Observações são acompanhadas até obter-se um número pré-determinado de falhas. Tipo III: Aleatória à direita: Associado aos tempos de falha existem onde observa-se apenas e onde é o tempo de falha observado, e independentes

31
2.9 Métodos dos Momentos para Dados Simples: Sem Censura
Métodos informais (métodos formais serão apresentados no próximo capítulo) Baseado nos momentos e estimativas simples Suponha que t1,...,tn sejam tempos de falha observados. Exemplo 2.1: T – número de milhões de revoluções de rolimã até a falha. Dados: 17.88, 28.92, 33.00, 41.52, 42.12, 45.60, 48.40, 51.84, 51.96, 54.12, 55.56, 67.80, 68.64, 68.64, 68.88, 84.12, 93.12, 98.64, , , , , (ordenados por conveniência) Média amostral: = e desvio padrão amostral (s.d.): st = 37.49 Recai segundo §2.3 que a média e o s.d. coincidem no modelo exponencial. Neste caso, /st se aproxima de 2, logo o modelo exponencial não é apropriado. Para ajustar Weibull e lognormal, é mais fácil trabalhar com xi = log ti. Novamente, média amostral: = e s.d. amostral: sx =
 Baseado nos momentos e estimativas simples. Suponha que t1,...,tn sejam tempos de falha observados. Exemplo 2.1: T – número de milhões de revoluções de rolimã até a falha. Dados: 17.88, 28.92, 33.00, 41.52, 42.12, 45.60, 48.40, 51.84, 51.96, 54.12, 55.56, 67.80, 68.64, 68.64, 68.88, 84.12, 93.12, 98.64, , , , , (ordenados por conveniência) Média amostral: = e desvio padrão amostral (s.d.): st = Recai segundo §2.3 que a média e o s.d. coincidem no modelo exponencial. Neste caso, /st se aproxima de 2, logo o modelo exponencial não é apropriado. Para ajustar Weibull e lognormal, é mais fácil trabalhar com xi = log ti. Novamente, média amostral: = e s.d. amostral: sx =")
32
Estes cálculos valem para a média μ –γσ e s. d
Estes cálculos valem para a média μ –γσ e s.d. πσ/√6 da Gumbel, trazendo assim os momentos estimados = e = Em termos dos parâmetros da Weibull, temos: = exp( ) = 80.64 e = 1/ =2.40, diferente do 1. De forma similar, os parâmetros estimados da lognormal são = e = Outra aproximação é baseada na função de sobrevivência empírica dada por é um estimador não paramétrico de S(t) n possui distribuição binomial com média S(t) e , segundo §1.15, um IC a 100%(1-α) para S(t) dado por De forma similar, a função de taxa de falha acumulada empírica é dada por Onde o s.d. é dado por
 = e = 1/ =2.40, diferente do 1. De forma similar, os parâmetros estimados da lognormal são = e = Outra aproximação é baseada na função de sobrevivência empírica dada por. é um estimador não paramétrico de S(t) n possui distribuição binomial com média S(t) e , segundo §1.15, um IC a 100%(1-α) para S(t) dado por. De forma similar, a função de taxa de falha acumulada empírica é dada por. Onde o s.d. é dado por.")
33
Os gráficos destas funções empíricas podem ser usados para checar a adequação das hipóteses dos parâmetros. Assuma os tempos ordenados t(1) < ... < t(n) . Salto de 1 / n tempo t(i). Realocado por 1- (i – 0.5) / n . (Outra forma possível) Modelo Weibull: S(t) = exp {- (t / α)} Log S(t) = - (t / α) log{-log S(t)}= log t – log α Se o modelo Weibull é apropriado, então o gráfico de é aproximadamente uma linha reta. Inicialmente os parâmetros estimados serão obtidos a partir de : - log α = intercepto = coeficiente angular Modelo lognormal: , – função de distribuição de N(0,1). Se o modelo lognormal for apropriado, então o gráfico de (log t(i), -1{(i-0.5)/n}) será uma linha reta.
 < ... < t(n) . Salto de 1 / n tempo t(i). Realocado por 1- (i – 0.5) / n . (Outra forma possível) Modelo Weibull: S(t) = exp {- (t / α)} Log S(t) = - (t / α) log{-log S(t)}= log t – log α. Se o modelo Weibull é apropriado, então o gráfico de. é aproximadamente uma linha reta. Inicialmente os parâmetros estimados serão obtidos a partir de : - log α = intercepto. = coeficiente angular. Modelo lognormal: , – função de distribuição de N(0,1). Se o modelo lognormal for apropriado, então o gráfico de (log t(i), -1{(i-0.5)/n}) será uma linha reta.")
34
2.10 Estimador do Produto-Limite
Inicialmente os parâmetros estimados serão dados por : -μ / σ= intercepto 1 / σ = coeficiente angular Estes gráficos são dados nas figuras 2.13 e 2.14 do exemplo 2.1. Inicialmente os parâmetros estimados são (entre parênteses por momentos): Weibull: =2.3(2.4) e α = 77.3(80.6) Lognormal: μ = 4.2(4.15) e σ = 0.56(0.53) Diferentemente do baseado pelo método dos momentos, o gráfico das probabilidades pode ser usado com censura. Eles são definidos por t < t (r ), para r tempos de falha (não censurados). 2.10 Estimador do Produto-Limite O estimador do produto-limite (PL) ou de Kaplan-Meyer é um estimador não paramétrico da função de sobrevivência. Ele coincide com a função empírica de sobrevivência quando não há censura.
: Weibull: =2.3(2.4) e α = 77.3(80.6) Lognormal: μ = 4.2(4.15) e σ = 0.56(0.53) Diferentemente do baseado pelo método dos momentos, o gráfico das probabilidades pode ser usado com censura. Eles são definidos por t < t (r ), para r tempos de falha (não censurados) Estimador do Produto-Limite. O estimador do produto-limite (PL) ou de Kaplan-Meyer é um estimador não paramétrico da função de sobrevivência. Ele coincide com a função empírica de sobrevivência quando não há censura.")
35
a1 < ... < ak – k tempos de falha distintos (a0 = 0)
d1, ...dk – número de falhas em cada tempo de falha (d0=0) n1 < ... < nk – número de itens em risco em cada tempo de falha (nk = 0) O estimador do PL é: Esta é uma função escada começando do 1 para t = 0 e alterando-se a cada ak. É como se a distribuição de falhas se concentrasse nos pontos a1, ... , ak. De acordo com a teoria assintótica , média e variância de são dados por S(t) e H(t) pode ser estimado de forma similar por De forma mais simples e intuitiva, podemos estimar H(t) usando que é relacionado ao estimador Pode-se utilizar análise gráfica do estimador do PL para avaliação da adequação de modelos Weibul e log-normal.
 n1 < ... < nk – número de itens em risco em cada tempo de falha (nk = 0) O estimador do PL é: Esta é uma função escada começando do 1 para t = 0 e alterando-se a cada ak. É como se a distribuição de falhas se concentrasse nos pontos a1, ... , ak. De acordo com a teoria assintótica , média e variância de são dados por. S(t) e. H(t) pode ser estimado de forma similar por. De forma mais simples e intuitiva, podemos estimar H(t) usando. que é relacionado ao estimador . Pode-se utilizar análise gráfica do estimador do PL para avaliação da adequação de modelos Weibul e log-normal.")
36
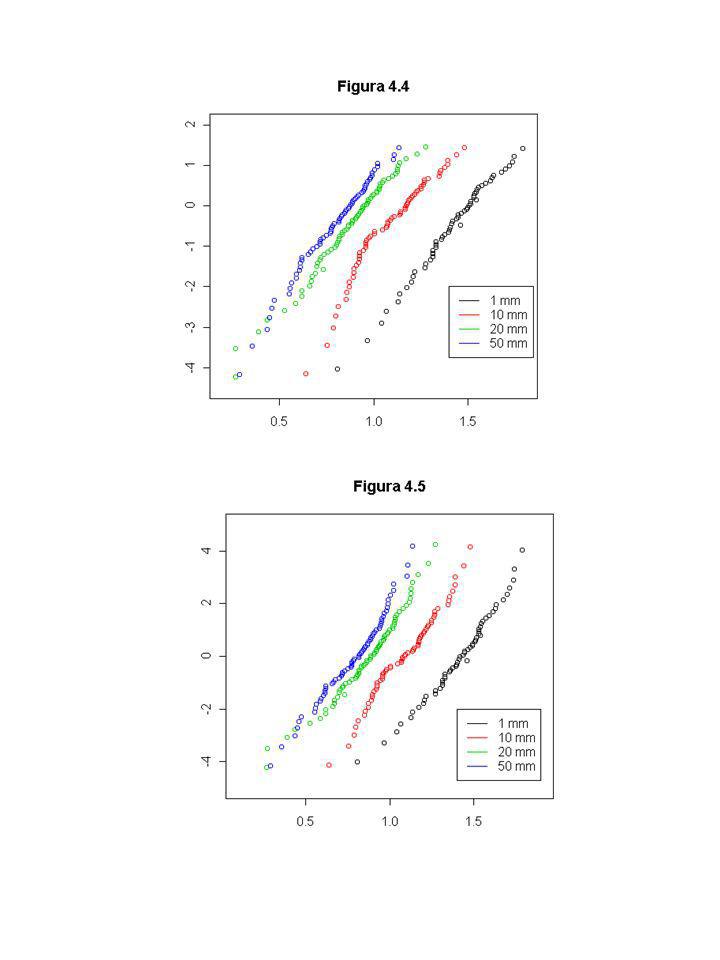
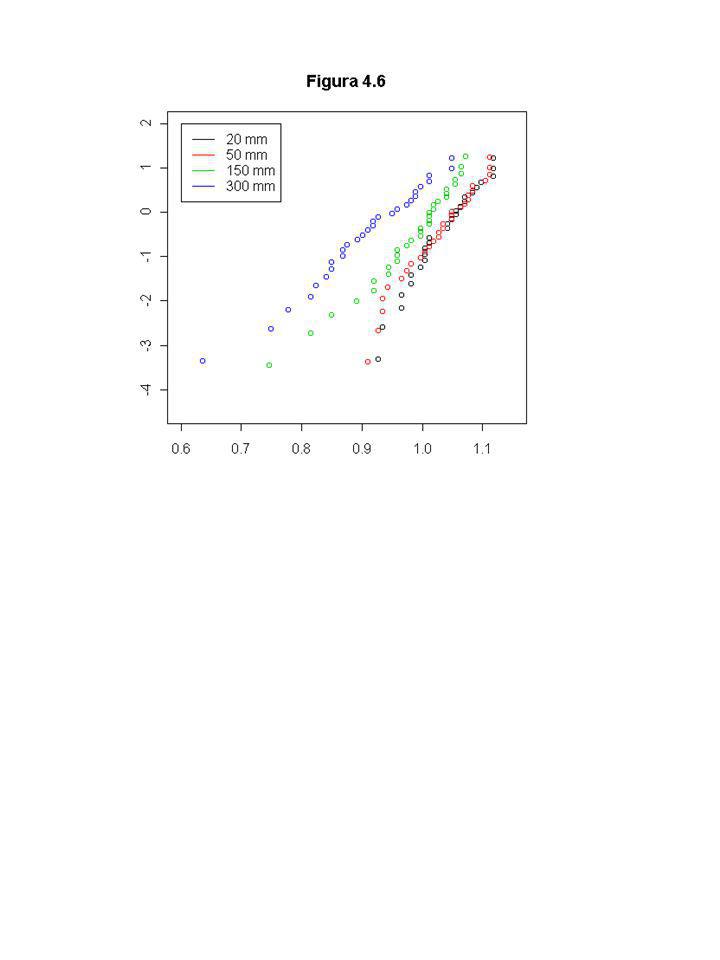
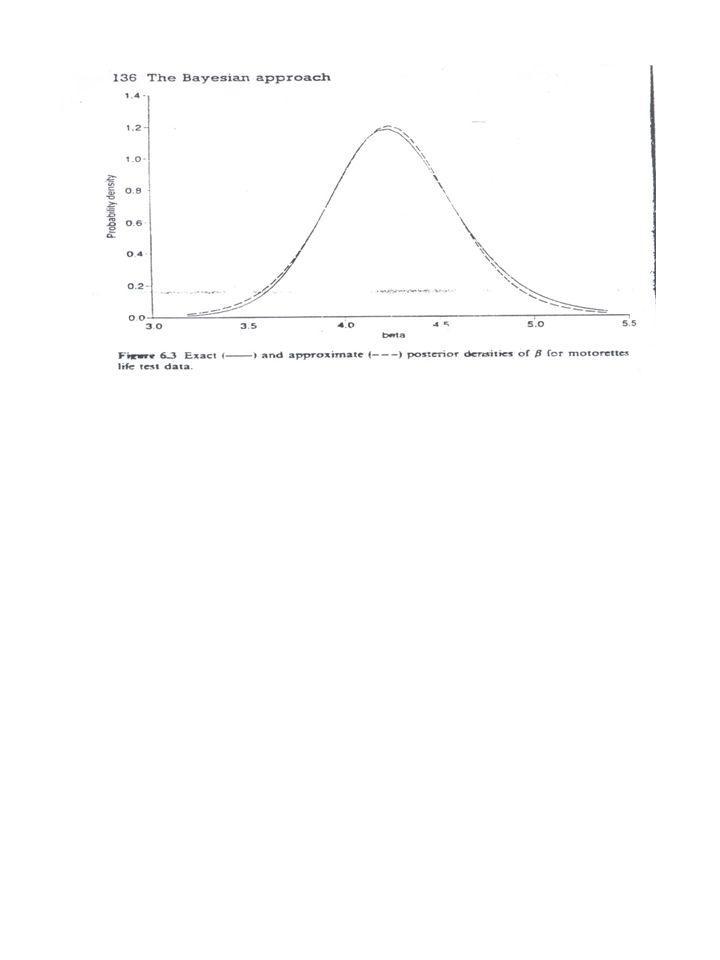
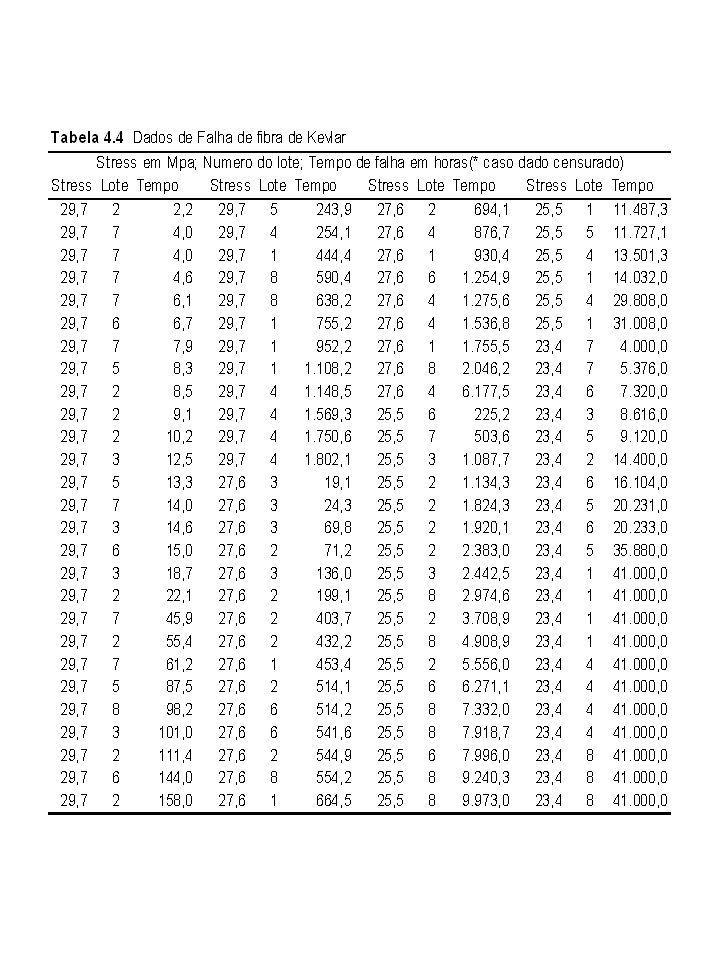
Exemplo 2.3: Resistência de corda a uma certa tensão (em unidades codificadas).
Principais interesses: Qual a confiabilidade de uma corda após 53 unidades de tensão ? O modelo de distribuição Weibull é apropriado ? Da tabela 2.2 , e Um IC de 95% para S(53) é dado por ( x0.0725, x0.0725)=(0.54,0.83) Fora 3 pontos isolados a figura 2.17 parece com uma linha reta. Investigação similar com modelo lognormal apresenta os mesmos resultados.
 é dado por. ( x0.0725, x0.0725)=(0.54,0.83) Fora 3 pontos isolados a figura 2.17 parece com uma linha reta. Investigação similar com modelo lognormal apresenta os mesmos resultados.")
38
3. MÉTODOS ESTATÍSTICOS PARA AMOSTRAS SIMPLES
3.1 Introdução Final do último capítulo: métodos estatísticos simples. Este capítulo: métodos mais formais, máxima verossimilhança, inferência bayesiana dinâmica. 3.2 Estimação por Máxima Verossimilhança: Generalidades Suponha uma amostra de tempos de vidas de uma certa população. Todos os possuem densidade , onde Caso as observações não sejam censuradas então, a função de verossimilhança é para observações censuradas (a direita): A contribuição para a verossimilhança é a probabilidade de sobrevivência após o tempo de censura. Separando os dados em conjuntos disjuntos: C - itens censurados e U - para itens não censurados.
: A contribuição para a verossimilhança é a probabilidade de sobrevivência após o tempo de censura. Separando os dados em conjuntos disjuntos: C - itens censurados e U - para itens não censurados.")
39
Estimativa da máxima verossimilhança (EMV) de
Para outras formas de censura existem outras expressões. É mais conveniente trabalhar com Estimativa da máxima verossimilhança (EMV) de Normalmente são obtidos resolvendo Assumindo que q(p;θ) como o quantil 1-p de T, ou seja, Pr(T≥ q(p;θ) = S(q(p;θ)) = p
 de. Normalmente são obtidos resolvendo. Assumindo que q(p;θ) como o quantil 1-p de T, ou seja, Pr(T≥ q(p;θ) = S(q(p;θ)) = p.")
40
3.3 Máxima Verossimilhança (MV) estimação : ilustrações
J é a informação observada da matriz Em particular, O EMV possui muitas vantagens sobre todos os outros métodos clássicos de estimação: Ele é universal; Ele é invariante; Ele possui boas propriedades assintóticas: Consistência, normalidade assintótica e eficiência; Distribuição assintótica é facilmente encontrada. 3.3 Máxima Verossimilhança (MV) estimação : ilustrações
 estimação : ilustrações.")
43
Figura Log-Verossimilhança para o tempo de vida de um componente de um avião com distribuição Exponencial. A reta no gráfico foi feita para mostrar o intervalo de confiança 95% para lambda, baseado em W. Note a grande diferença na calda

44
3.4 Intervalos de Confianças e Testes
q = (q1,...,qn) está divida dentro (q(A), q(B)) das dimensões ma e mb. Nós interessa testar a Hipótese H: q(A)= q0(A) ( , ) é um EMV de (q(A),q(B)) (A0) é um EMV de q(B) de H. Estão disponíveis dois procedimentos: 1) Onde temos para H , que: W(q0(A)) = 2{i ( , ) - i[q0(A), (A0)]} ~ c2( ma), é aproximadamente. Grandes valores de W Þ grandes diferenças em comum com log – máxima verossimilhança Þ grande suporte contra H. O teste da relação da MV rejeita H se W(q0(A)) > ca2( (ma) onde ca2( (ma) é 1 - a quantil de ca2(ma). As regiões de confiança para são dadas por: { :W(q(A),ca2( ma)} 2) Seja VA a variância assintótica de Então:W*( ) = ( q0(A))TVA-1( q0(A)), distribuição aproximada c2( ma) de H. As regiões de confianças e os testes são obtidos a partir das informações acima com W* substituindo W.
 está divida dentro (q(A), q(B)) das dimensões ma e mb. Nós interessa testar a Hipótese H: q(A)= q0(A) ( , ) é um EMV de (q(A),q(B)) (A0) é um EMV de q(B) de H. Estão disponíveis dois procedimentos: 1) Onde temos para H , que: W(q0(A)) = 2{i ( , ) - i[q0(A), (A0)]} ~ c2( ma), é aproximadamente. Grandes valores de W Þ grandes diferenças em comum com log – máxima verossimilhança Þ grande suporte contra H. O teste da relação da MV rejeita H se W(q0(A)) > ca2( (ma) onde ca2( (ma) é 1 - a quantil de ca2(ma). As regiões de confiança para são dadas por: { :W(q(A),ca2( ma)} 2) Seja VA a variância assintótica de . Então:W*( ) = ( - q0(A))TVA-1( - q0(A)), distribuição aproximada c2( ma) de H. As regiões de confianças e os testes são obtidos a partir das informações acima com W* substituindo W.")
45
Em particular, para θ(A) escalar, a região de confiança torna-se:
[ z a/2 VA ½, z a/2 VA ½] ( um intervalo) onde é usado o fato de c2( 1) = [N(0,1)]. Embora W e W* sejam assintoticamente equivalentes e geralmente similares, preferimos W pela re-parametrização acima e por ser invariante. Exemplo 3.1 (cont.): Temos o modelo exponencial, onde θ(A) = l, ma = 1 é W*(l ) = 2{ log l l} O intervalo de confiança (IC = 95%) baseado em W* é dado por: {l:W(l)£ 3.84}=[.22,.76] e como 3.84 = c0.52(1). (Figura 3.1) Então o intervalo de confiança (IC = 95%) baseado em W*é: [.434 – 1.96 x .137, x .137] = [0.17,0.70](simétrico) O intervalo de confiança (IC=95%) é dado por: [0.21,0.74] baseado em 2rl/ ~ c2(2r). Exemplo 3.2 (cont.): Desejamos testar a hipótese H de exponencialidade. Usando o modelo Gumbel temos: q(A) = s, q(B) = m, ma = 1 e H é s = 1 W*(1) = >> 3.84 Þ H0 rejeitado. Logo, W(1) = confirma a rejeição de H como esperado.
 onde é usado o fato de c2( 1) = [N(0,1)]. Embora W e W* sejam assintoticamente equivalentes e geralmente similares, preferimos W pela re-parametrização acima e por ser invariante. Exemplo 3.1 (cont.): Temos o modelo exponencial, onde θ(A) = l, ma = 1 é W*(l ) = 2{ log l l} O intervalo de confiança (IC = 95%) baseado em W* é dado por: {l:W(l)£ 3.84}=[.22,.76] e como 3.84 = c0.52(1). (Figura 3.1) Então o intervalo de confiança (IC = 95%) baseado em W*é: [.434 – 1.96 x .137, x .137] = [0.17,0.70](simétrico) O intervalo de confiança (IC=95%) é dado por: [0.21,0.74] baseado em 2rl/ ~ c2(2r). Exemplo 3.2 (cont.): Desejamos testar a hipótese H de exponencialidade. Usando o modelo Gumbel temos: q(A) = s, q(B) = m, ma = 1 e H é s = 1. W*(1) = >> 3.84 Þ H0 rejeitado. Logo, W(1) = confirma a rejeição de H como esperado.")
46
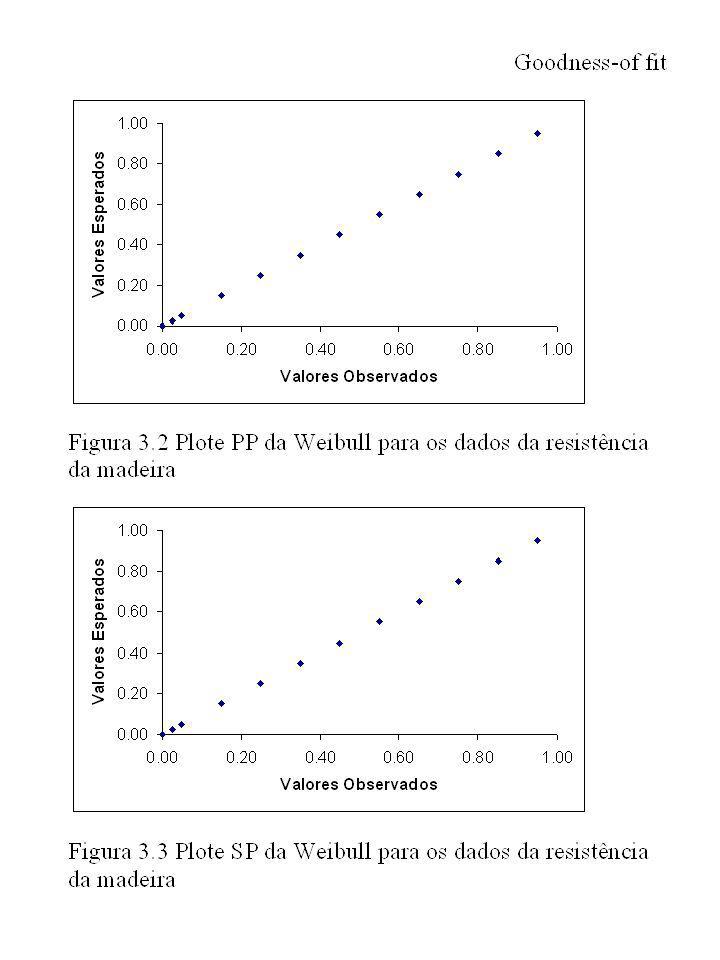
O Exemplo 3.2 considera a hipótese de recursividade: onde a Exponencial é um caso especial da Gumbel. São mais difíceis de considerar a hipótese de não – recursividade para o tratamento clássico estatístico. 3.5 Bondade do Ajuste Enfoque formal: Encaixar o modelo dentro de uma classe de modelos ( Exemplo 3.2) ou usar a forma excelente. Técnicas Gráficas Plote o gráfico de QQ: Seja m e s, parâmetros de locação e escala, (onde é estimador do PL) e F0 é a função de distribuição para m = 0 e s = 1. O plote dos pontos [aj , F0 -1(pj)] deveria ser linear. Plote PP: junte os pontos (pj , F( aj , )). (esta linha deveria ser y = x) Pode ser usado fora do modelo de locação de escala. Plote SP: Para estabilizar a variabilidade de PP, plote a transformação y = (2/p)sin-1x em ambos os eixos. As figuras 3.2 e 3.3 mostra os dados do exemplo 2.3 plotado em PP e SP.
 ou usar a forma excelente. Técnicas Gráficas. Plote o gráfico de QQ: Seja m e s, parâmetros de locação e escala, (onde é estimador do PL) e F0 é a função de distribuição para m = 0 e s = 1. O plote dos pontos [aj , F0 -1(pj)] deveria ser linear. Plote PP: junte os pontos (pj , F( aj , )). (esta linha deveria ser y = x) Pode ser usado fora do modelo de locação de escala. Plote SP: Para estabilizar a variabilidade de PP, plote a transformação y = (2/p)sin-1x em ambos os eixos. As figuras 3.2 e 3.3 mostra os dados do exemplo 2.3 plotado em PP e SP.")
48
3.6 Elementos de Estatística Bayesiana
Incorpora informação subjetiva sobre o problema (experiência anterior). É feita através da especificação de uma distribuição a priori P(q). Informação a priori vaga: a análise é guiada pela informação dos dados. Assuma, como antes, uma amostra t = ( t1, , tn ) com densidade f (t ;q). Isto é combinado com a priori e leva a Fórmula de Bayes Válido para q e t discreto e contínuo. P(q | t) é a densidade a posteriori (dado os dados t). Como t é constante, A fórmula de Bayes pode ser simplificada em A constante removida P(t) pode ser recuperada por Estimativas a posteriori para q são obtidas através de medidas de locação de P(q | t). Exemplo: Considere os dados do exemplo 2.2 com modelo exponencial
. É feita através da especificação de uma distribuição a priori P(q). Informação a priori vaga: a análise é guiada pela informação dos dados. Assuma, como antes, uma amostra t = ( t1, , tn ) com densidade f (t ;q). Isto é combinado com a priori e leva a. Fórmula de Bayes. Válido para q e t discreto e contínuo. P(q | t) é a densidade a posteriori (dado os dados t). Como t é constante, A fórmula de Bayes pode ser simplificada em. A constante removida P(t) pode ser recuperada por. Estimativas a posteriori para q são obtidas através de medidas de locação de P(q | t). Exemplo: Considere os dados do exemplo 2.2 com modelo exponencial.")
49
É conveniente atribuir a priori (distribuição gama).
Combinada com a verossimilhança de forma simples (priori conjugada). Para especificar os valores de a e b assuma que acredita-se que l está próximo de 0.5 e que é pouco provável que ele seja menor que 0.2. Então, tome a moda da priori igual a 0.5 e P(l < 0.2) 0.05 a = 3 e b = 4. A posteriori é l | t ~ Gamma (13, 27.05) com moda e média (figura 6.1). O desvio padrão a posteriori (priori) é (0.175).
. Para especificar os valores de a e b assuma que acredita-se que l está próximo de 0.5 e que é pouco provável que ele seja menor que 0.2. Então, tome a moda da priori igual a 0.5 e P(l < 0.2) a = 3 e b = 4. A posteriori é l | t ~ Gamma (13, 27.05) com moda e média (figura 6.1). O desvio padrão a posteriori (priori) é (0.175).")
50
Regiões de confiança são facilmente obtidas da posteriori
Regiões de confiança são facilmente obtidas da posteriori Particularmente úteis são as regiões de maior densidade a posteriori (HPD). Por exemplo, o intervalo HPD de 95% para todo l é [0.231, 0.758]. Interpretação da região HPD é simples diferentemente das regiões de confiança clássicas. Inferência sobre funções paramétricas são obtidas de maneira similar. Assuma interesse na confiabilidade em um certo tempo t0 . Para o modelo exponencial isto é S ( t0 ; l) = e-lt0, uma função de l. A posteriori completa de S ( t0 ; l) pode ser obtida. Como exemplo, 0.01 = Pr (l < | t) = Pr (S ( t0 ; l) > e t0 | t) a probabilidade a posteriori de que S (t0; l) exceda e t0 é 0.01. Predição: assuma que se está interessado no tempo de vida S de um novo item. Inferência deve ser baseada na distribuição de S | ( t1, ... ,tn ). (S independente de t dado l) Por exemplo, a densidade do tempo de vida de um novo item é
. Por exemplo, o intervalo HPD de 95% para todo l é [0.231, 0.758]. Interpretação da região HPD é simples diferentemente das regiões de confiança clássicas. Inferência sobre funções paramétricas são obtidas de maneira similar. Assuma interesse na confiabilidade em um certo tempo t0 . Para o modelo exponencial isto é S ( t0 ; l) = e-lt0, uma função de l. A posteriori completa de S ( t0 ; l) pode ser obtida. Como exemplo, 0.01 = Pr (l < | t) = Pr (S ( t0 ; l) > e t0 | t) a probabilidade a posteriori de que S (t0; l) exceda e t0 é Predição: assuma que se está interessado no tempo de vida S de um novo item. Inferência deve ser baseada na distribuição de S | ( t1, ... ,tn ). (S independente de t dado l) Por exemplo, a densidade do tempo de vida de um novo item é.")
51
(a constante de proporcionalidade é 0.481).
Informação a priori vaga é usualmente representada por adequados valores pequenos dos parâmetros da priori conjugada. No exemplo, pequenos valores de a e b, como 0.5. O intervalo de 95% de confiança a priori é [0.001, 5.024]. (muito grande) A posteriori é Gama (10.5, 23.55) com média e desvio padrão O limite de uma distribuição a priori vaga é uma priori não informativa. No exemplo, isso é obtido fazendo a, b 0 => p(l) l-1 (priori imprópria). A posteriori é Gama (10, 23.05) com média e desvio padrão (similar aos resultados da inferência por máxima verossimilhança). A priori não informativa é um meio para obtenção da posteriori na ausência de informação a priori.
 A posteriori é Gama (10.5, 23.55) com média e desvio padrão O limite de uma distribuição a priori vaga é uma priori não informativa. No exemplo, isso é obtido fazendo a, b 0 => p(l) l-1 (priori imprópria). A posteriori é Gama (10, 23.05) com média e desvio padrão (similar aos resultados da inferência por máxima verossimilhança). A priori não informativa é um meio para obtenção da posteriori na ausência de informação a priori.")
52
3.7 Outros Tópicos em Inferência Bayesiana (§6.4 do livro texto)
Especificação de prioris Não é necessário que a especificação seja muito precisa. Próxima seção: análise Bayesiana com especificação a priori parcial. Verificação de inconsistências: análise pré-posteriori. Análise conjugada é conveniente mas nem sempre apropriada. Prioris não informativas devem ser usadas com cuidado: pode levar a absurdos. Parâmetros de distúrbio Suponha que os parâmetros são divididos em (y, f) onde y é de interesse f é somente necessário (distúrbio) e pode ser eliminado facilmente via Densidade marginal Exemplo: tempos de falha Weibull com S(t) = e-ltg A verossimilhança é com
 onde y é de interesse. f é somente necessário (distúrbio) e pode ser eliminado facilmente via. Densidade marginal. Exemplo: tempos de falha Weibull com S(t) = e-ltg. A verossimilhança é. com.")
53
Assuma que a priori é Integrando com relação a l temos Entre chaves: p(t | g) - verossimilhança marginal (ou integrada) de g. Fator de Bayes Considere um teste Bayesiano de uma dada hipótese H. Se H é uma região então Pr(H | t) reflete a crença em H a posteriori. Para o exemplo em §3.6 e H : l < 0.25, temos Pr(H | t) = Pr( l < 0.25 | t) = 0.2 => H é rejeitada Similarmente, pode-se usar a razão de chances a posteriori dada por A primeira razão do lado direito é a razão de chances a priori e o segunda é o fator de Bayes. Isso representa a razão relativa de verossimilhanças entre as duas hipóteses H e . Maiores valores do fator de Bayes maior apoio dos dados em H. O fator de Bayes é útil quando deseja-se testar hipóteses nulas bilaterais H : q = q0
 reflete a crença em H a posteriori. Para o exemplo em §3.6 e H : l < 0.25, temos Pr(H | t) = Pr( l < 0.25 | t) = 0.2 => H é rejeitada. Similarmente, pode-se usar a razão de chances a posteriori dada por. A primeira razão do lado direito é a razão de chances a priori e o segunda é o fator de Bayes. Isso representa a razão relativa de verossimilhanças entre as duas hipóteses H e . Maiores valores do fator de Bayes maior apoio dos dados em H. O fator de Bayes é útil quando deseja-se testar hipóteses nulas bilaterais H : q = q0.")
54
3.8 Modelos Bayesianos Dinâmicos
Note que Pr(H | t) será sempre 0. Há alguma controvérsia a respeito de quão adequado é testar hipóteses nulas bilaterais. No exemplo, o fator de Bayes para H : l = 0.25 é 0.81 a crença no valor 0.25 é reduzida pelos dados. 3.8 Modelos Bayesianos Dinâmicos Baseado em uma distribuição exponencial por partes para os tempos de falência com suposição explícita de conexão entre intervalos. Distribuição E. P. (Exponencial por Partes): o risco é constante nos intervalos. É geralmente razoável assumir funções de risco contínuas algumas conexão entre valores de risco em intervalos sucessivos. Forma matemática adotada para simplicidade: passeio aleatório na escala log wi - termo de perturbação permitindo o aumento da incerteza como um movimento direto do intervalo. Conseqüências deste modelo: (1) Preserva a posição: (2) Aumento da incerteza :
 será sempre 0. Há alguma controvérsia a respeito de quão adequado é testar hipóteses nulas bilaterais. No exemplo, o fator de Bayes para H : l = 0.25 é a crença no valor 0.25 é reduzida pelos dados. 3.8 Modelos Bayesianos Dinâmicos. Baseado em uma distribuição exponencial por partes para os tempos de falência com suposição explícita de conexão entre intervalos. Distribuição E. P. (Exponencial por Partes): o risco é constante nos intervalos. É geralmente razoável assumir funções de risco contínuas algumas conexão entre valores de risco em intervalos sucessivos. Forma matemática adotada para simplicidade: passeio aleatório na escala log. wi - termo de perturbação permitindo o aumento da incerteza como um movimento direto do intervalo. Conseqüências deste modelo: (1) Preserva a posição: (2) Aumento da incerteza :")
55
Um artifício útil para determinar valores para Wi´s: fatores de desconto controlam a quantidade de informação (medida de precisão) passando direto dos intervalos. Fator de desconto é um número entre 0 e 1(geralmente fechado para 1). 1) se o desconto é fechado para 0 – nenhuma informação passa direto do intervalo. Estimação M.V. (máxima verossimilhança) com distribuição E.P. (exponencial por partes), estimador P.L. (produto-limite ou Kaplan Meyer). 2) se o desconto é 1 – toda informação passa direto do intervalo Parâmetros são os mesmos tempo de falência exponencial. Função de verossimilhança De §2.7, a verossimilhança para um dado indivíduo é onde Xi é o indicador da falência no intervalo Ii bi é o tempo observado em Ii, para este indivíduo. Para uma amostra de tamanho n, a verossimilhança é
. 1) se o desconto é fechado para 0 – nenhuma informação passa direto do intervalo. Estimação M.V. (máxima verossimilhança) com distribuição E.P. (exponencial por partes), estimador P.L. (produto-limite ou Kaplan Meyer). 2) se o desconto é 1 – toda informação passa direto do intervalo. Parâmetros são os mesmos tempo de falência exponencial. Função de verossimilhança. De §2.7, a verossimilhança para um dado indivíduo é. onde Xi é o indicador da falência no intervalo Ii. bi é o tempo observado em Ii, para este indivíduo. Para uma amostra de tamanho n, a verossimilhança é.")
56
onde di é o número de indivíduos observados até a falha em Ii
onde di é o número de indivíduos observados até a falha em Ii ai é o tempo total observado em Ii para a amostra Li é a verossimilhança para λi baseado nos eventos observados em Ii dado Di-1, a informação do intervalo anterior (ver final de §2.7). De fato, o produto das verossimilhanças vai de i = 1 a i = N onde N é o indexador do último intervalo com tempo de falência observado (censurado ou não censurado). Análise Seqüencial e Distribuições a Priori Assuma que A Priori assumida para Conseqüentemente: aumento da incerteza Atualização da distribuição de λi feita direta da fórmula de Bayes.
. De fato, o produto das verossimilhanças vai de i = 1 a i = N onde N é o indexador do último intervalo com tempo de falência observado (censurado ou não censurado). Análise Seqüencial e Distribuições a Priori. Assuma que. A Priori assumida para. Conseqüentemente: aumento da incerteza. Atualização da distribuição de λi feita direta da fórmula de Bayes.")
57
e (análise conjugada) As análises procedem do aumento de i para i+1 como antes dito. Inicia em i = 0 indo para i = N, o último intervalo com informação de dados. {ci} controla a suavidade da função risco: ci → 0: sem passagem de informação ci = 0: passagem total de informação Especificação dos ci´s Dado que Usando o método Delta Da relação entre sucessivos λ´s: Usando novamente o método Delta dado

58
Geralmente, Wi é selecionado proporcional ao tamanho de Ii.
De onde um obtém Geralmente, Wi é selecionado proporcional ao tamanho de Ii. Quanto maior o intervalo, mais informação é perdida. A proporcionalidade constante é W, a variância da perturbação supera uma unidade de tempo. Fatores de desconto são associados diretamente com W: tem que ser especificado só a primeira vez para um modelo dado. Inferência Inferência é baseada na distribuição predita de um novo tempo de falência S baseado em DN, o (total) de informação do dado. Interesse particular: sobrevivência predita e risco predito Estes são obtidos após a integração fora dos λ´s com respeito a sua distribuição suavizada (ou filtrada) Estas distribuições são obtidas via um algoritmo recursivo. Modelo de Seleção Um modelo é especificado pela escolha de : 1) Priori para 2) fator de desconto 3) grade de intervalos
 de informação do dado. Interesse particular: sobrevivência predita e. risco predito. Estes são obtidos após a integração fora dos λ´s com respeito a sua distribuição suavizada (ou filtrada) Estas distribuições são obtidas via um algoritmo recursivo. Modelo de Seleção. Um modelo é especificado pela escolha de : 1) Priori para. 2) fator de desconto. 3) grade de intervalos.")
59
Modelos M1 e M2 podem ser comparados via seus fatores de Bayes
Cada verossimilhança marginal é obtida após a integração fora dos parâmetros como segue facilmente obtido.

62
3.9 O Estimador Atuarial Utilizado em tabelas de mortalidade onde muitas vezes dados estão agrupados. Assume-se que a distribuição é contínua e divide-se o tempo em intervalos geralmente iguais onde a taxa de falha é constante. Ex: Em tabela de mortalidade, divide-se tempo (tempo de vida de população) em intervalos 0 – 1, 1 – 5 (ou 0 – 5), 5 – 10, 10 – 15, ... anos. Raramente faz-se divisão ano a ano. Suponha que a população tem n indivíduos morrendo em um ano com idades y1, ..., yn. (Não há censura) Se o indivíduo morre no intervalo i , sua contribuição à verossimilhança é: A verossimilhança total é dada pelo produto das contribuições individuais
 em intervalos 0 – 1, 1 – 5 (ou 0 – 5), 5 – 10, 10 – 15, ... anos. Raramente faz-se divisão ano a ano. Suponha que a população tem n indivíduos morrendo em um ano com idades y1, ..., yn. (Não há censura) Se o indivíduo morre no intervalo i , sua contribuição à verossimilhança é: A verossimilhança total é dada pelo produto das contribuições individuais.")
63
verossimilhança fatora em i
onde di = # de mortes no intervalo i indivíduo k morre antes do intervalo i) (indivíduo k morre no intervalo i) (indivíduo k morre depois do intervalo i) é o tempo total em risco no intervalo i Por analogia, na estimação do modelo exponencial, o EMV de i é: Se todos os indivíduos morrem no final dos intervalos,
 (indivíduo k morre no intervalo i) (indivíduo k morre depois do intervalo i) é o tempo total em risco no intervalo i. Por analogia, na estimação do modelo exponencial, o EMV de i é: Se todos os indivíduos morrem no final dos intervalos,")
64
onde ri = # de indivíduos observados no intervalo i.
Se também há censura, fórmulas não se alteram (apenas ri será diferente). Vamos supor agora que a censura também está sujeita a um mecanismo: · Aleatório cuja taxa é constante ao longo dos mesmos intervalos · Independente do mecanismo de falha (mortalidade) Inferência acima não é alterada pela independência. Normalmente, em tabelas de mortalidade, dados são fornecidos em forma grupada, isto é, só são fornecidos: di = # de mortes no intervalo i mi = # de censuras no intervalo i Temos 3 grupos de indivíduos em cada intervalo: i) ri – di – mi - sobrevivem ao intervalo i ii) di morrem no intervalo i iii) mi são censurados no intervalo i Vamos supor que taxa de censura é i no intervalo i
. Vamos supor agora que a censura também está sujeita a um mecanismo: · Aleatório cuja taxa é constante ao longo dos mesmos intervalos. · Independente do mecanismo de falha (mortalidade) Inferência acima não é alterada pela independência. Normalmente, em tabelas de mortalidade, dados são fornecidos em forma grupada, isto é, só são fornecidos: di = # de mortes no intervalo i. mi = # de censuras no intervalo i. Temos 3 grupos de indivíduos em cada intervalo: i) ri – di – mi - sobrevivem ao intervalo i. ii) di - morrem no intervalo i. iii) mi - são censurados no intervalo i. Vamos supor que taxa de censura é i no intervalo i.")
65
Já vimos que verossimilhança fatora em verossimilhanças condicionais à história passada.
A contribuição dada à verossimilhança do intervalo i de cada um dos 3 grupos acima dada sobrevivência até o início do intervalo é dada por: (i) Pr (Y > ti , C > ti | Y > ti-1 , C > ti-1) (ii) Pr (Y ti , C > Y | Y > ti-1 , C > ti-1) (iii) Pr (Y > C , C ti | Y > ti-1 , C > ti-1) falha (iii) (i) ti (ii) ti censura De fundo bi = ti – ti-1 temos: (i) Pr(Y>ti | Y>ti-1).Pr(C>ti | C>ti-1) = exp{-bii}exp{-bii} = exp{-bi(i+i)}
 Pr (Y > ti , C > ti | Y > ti-1 , C > ti-1) (ii) Pr (Y ti , C > Y | Y > ti-1 , C > ti-1) (iii) Pr (Y > C , C ti | Y > ti-1 , C > ti-1) falha. (iii) (i) ti. (ii) ti-1 censura. De fundo bi = ti – ti-1 temos: (i) Pr(Y>ti | Y>ti-1).Pr(C>ti | C>ti-1) = exp{-bii}exp{-bii} = exp{-bi(i+i)}")
66
(ii) (iii) , por analogia a (ii) Logo, a verossimilhança do intervalo i é dada por Nenhum outro fator de verossimilhança depende de i e i EMV de i e i podem ser obtidos a partir da verossimilhança acima dando e

67
Normalmente, é pequeno Fazendo aproximação temos Equivale a assumir que mortes e censuras se distribuem uniformemente nos intervalos. A probabilidade de sobrevivência a um intervalo é e pode ser estimada por No caso específico de uma tabela de mortalidade, n é bastante grande e a única informação é d1, d2, ..., ou seja, número de mortos em cada intervalo. Podemos calcular ri pois , mas xik não são fornecidos. Os problemáticos são os indivíduos que morrem (ou são censurados) no intervalo. Suposição: Dada a massa de indivíduos, é razoável supor que indivíduos morrem (ou são censurados) aleatoriamente no intervalo.
 no intervalo. Suposição: Dada a massa de indivíduos, é razoável supor que indivíduos morrem (ou são censurados) aleatoriamente no intervalo.")
68
Logo, para esses indivíduos é tomada como
se não há censura Como ri = ri+1 + di temos onde Di = { indivíduos que morrem no intervalo i} Si = {indivíduos que morrem após intervalo i} A suposição acima é razoável: da é falha apenas no intervalo 0-1 ano onde a tendência à falha é nitidamente maior perto de 0.

69
Logo, i é usualmente estimada por
A probabilidade de sobrevivência a um intervalo é e pode ser estimada por Muitas vezes é pequeno. Fazendo a expansão de Taylor em torno de 0, obtemos que é denotado por ou e substituindo esses valores em temos o estimador atuarial Observe que o estimador atuarial difere do estimador PL pela troca de ri por quanto t = ti , i = 1, 2, ... Nos outros pontos ele é contínuo e o PL é tipo escada 1

70
3.10 O Estimador Bayesiano Quando não se assume nenhuma distribuição específica para os tempos de falha a própria Fd F ou a f.s. S torna-se o parâmetro da distribuição. Convenciona-se dizer que o problema é não paramétrico pois a dimensão do parâmetro é infinita. Temos que construir priori sobre F(t) ( ou S(t) ), t [0;) Ferguson (1973): Seja uma medida finita R+, isto é, ( [a,b] ) = c > 0, ( [a,b]A ) c e ( [0,) ) < Ex: ( [0,) ) = 1 < A distribuição P é um processo de Dirichlet se qualquer partição B1, ..., Bk de R+, Pr(B1), ..., Pr(Bk) tem distribuição Dirichlet com parâmetro ((B1), ..., (Bk) )
 ( ou S(t) ), t [0;) Ferguson (1973): Seja uma medida finita R+, isto é, ( [a,b] ) = c > 0, ( [a,b]A ) c e ( [0,) ) < Ex: ( [0,) ) = 1 < A distribuição P é um processo de Dirichlet se qualquer partição B1, ..., Bk de R+, Pr(B1), ..., Pr(Bk) tem distribuição Dirichlet com parâmetro ((B1), ..., (Bk) )")
71
onde 1 = (A1), ..., k = (Ak) e, portanto, é uma amostra aleatória de um processo de Dirichlet se: Pr(X1A1, ..., XnAn | P(A1), ..., P(An) ) = Pode se mostrar que O processo de Dirichlet funciona como a priori para a distribuição amostral. Assim, por exemplo, Logo tem densidade e corresponde ao valor esperado a priori para F.
, ..., P(An) ) = Pode se mostrar que. O processo de Dirichlet funciona como a priori para a distribuição amostral. Assim, por exemplo, Logo tem densidade. e. corresponde ao valor esperado a priori para F.")
72
y1, ..., yk são as observações não-censuradas
Se não há censura na amostra, a distribuição é conjugada e a posteriori de P também é um processo de Dirichlet com parâmetro onde: , se é contínuo, não é mais. Se há censura, a distribuição não é conjugada e a forma da posteriori complica. Pode-se obter a esperança a posteriori de F(t) ou S(t), t > 0 Usando essa esperança como estimador temos yl < t yl+1 c = k, ..., m onde y1, ..., yk são as observações não-censuradas yk+1, ..., ym são os diferentes valores das observações censuradas ck+1, ..., cm são o número de observações censuradas = yk+1, ..., ym r(t) = # de observações à vista em t Se não há censura, yi-1 t yi , i = 1, ..., n
 ou S(t), t > 0. Usando essa esperança como estimador temos. yl < t yl+1. c = k, ..., m onde. y1, ..., yk são as observações não-censuradas. yk+1, ..., ym são os diferentes valores das observações censuradas. ck+1, ..., cm são o número de observações censuradas = yk+1, ..., ym. r(t) = # de observações à vista em t. Se não há censura, yi-1 t yi , i = 1, ..., n.")
73
No caso geral, se 0, estimador PL
Quando se > 0, comporta-se da seguinte forma A(n) Abordagem completamente não paramétrica sugerida por Hill (1968) baseada na hipótese A(n): Sejam X1, ..., Xn+1 permutáveis com distribuição P. Suponha que observa-se X1 = x1, ..., Xn = xn onde x1 < x2 < ... < xn (possível pela permutabilidade) Sejam I(0), ..., I(n) intervalos dados por I(i) = (xi, xi+1) onde x0 = 0 e xn+1 =
 Abordagem completamente não paramétrica sugerida por Hill (1968) baseada na hipótese A(n): Sejam X1, ..., Xn+1 permutáveis com distribuição P. Suponha que observa-se X1 = x1, ..., Xn = xn onde x1 < x2 < ... < xn (possível pela permutabilidade) Sejam I(0), ..., I(n) intervalos dados por I(i) = (xi, xi+1) onde x0 = 0 e xn+1 = ")
74
Então a distribuição preditiva de Xn+1 dado X1 = x1, ...,
Xn = xn dá Eventuais empates nos xi’s podem ser separados acrescentando pequeno a um deles No caso de censura a situação complica pois não conhecemos todos os xi’s. Resolve-se também de uma forma não paramétrica. Suponha x4 e x5 são tempos de censura. O objetivo é calcular as probabilidades preditivas para I(0), I(1), I(2), I(3). Isso é feito considerando todos os possíveis valores (não censurados) de x4 e x5.
, I(1), I(2), I(3). Isso é feito considerando todos os possíveis valores (não censurados) de x4 e x5.")
75
Supondo que x4 I(1) e x5 I(2) temos sob a hipótese A(5) que a probabilidade
de I(0) é , de I(1) é , de I(2) é e de I(3) é Se supomos, por exemplo,
 é , de I(1) é , de I(2) é e de I(3) é. Se supomos, por exemplo,")
76
Implícito nos cálculos acima:
Falha dos censurados poderia ocorrer em qualquer ponto no intervalo de censura, ou seja, o ponto de censura é trazido de volta até o início do intervalo. Ex.: x4 poderia ocorrer em qualquer ponto de I(1) O cálculo é portanto uma aproximação (que fornece cota superior). Defina Z1, ..., ZN – tempos de falha a ser observados Z – tempos de falha a ser previsto n < N – número de falhas observadas – valores observados de falha yn+1, ..., yN – valores observados de censura IEC = {Zj > yj, j = n+1, ..., N} Info. Exata de Censura IPC = { Zj > Uj, j = n+1, ..., N} Info. Parcial de Censura onde Ui é o maior xi | xi < yi Ex.: No exemplo, temos x1 < y4 < x2 < y5 < x3 U4 = x1 e U5 = x2 Ao invés de calcularmos Qi = Pr( Z I(i) | IEC, ), i = 0, 1, ..., n calcularemos
 O cálculo é portanto uma aproximação (que fornece cota superior). Defina Z1, ..., ZN – tempos de falha a ser observados. Z – tempos de falha a ser previsto. n < N – número de falhas observadas. – valores observados de falha. yn+1, ..., yN – valores observados de censura. IEC = {Zj > yj, j = n+1, ..., N} Info. Exata de Censura. IPC = { Zj > Uj, j = n+1, ..., N} Info. Parcial de Censura. onde Ui é o maior xi | xi < yi. Ex.: No exemplo, temos x1 < y4 < x2 < y5 < x3 U4 = x1 e U5 = x2. Ao invés de calcularmos Qi = Pr( Z I(i) | IEC, ), i = 0, 1, ..., n calcularemos.")
77
Como IEC IPC, Qi = Pr( Z I(i) | IEC, IPC, ) =
Pi = Pr( Z I(i) | IPC, Como IEC IPC, Qi = Pr( Z I(i) | IEC, IPC, ) = Como, dado IPC, pouca informação adicional sobre IEC é fonecida por [Z I(i)] principalmente em amostras moderadas ou grandes, Qi Pi. Para o cálculo dos Pi, define-se ci - # de observações censuradas em I(i) , i = 0, 1, ..., n i = 1 / (N - (i - 1) - Ci) Então P0 = 0 e , i = 0, 1, ..., n-1
 | IPC, Como IEC IPC, Qi = Pr( Z I(i) | IEC, IPC, ) = Como, dado IPC, pouca informação adicional sobre IEC é fonecida por [Z I(i)] principalmente em amostras moderadas ou grandes, Qi Pi. Para o cálculo dos Pi, define-se ci - # de observações censuradas em I(i) , i = 0, 1, ..., n. i = 1 / (N - (i - 1) - Ci) Então P0 = 0 e , i = 0, 1, ..., n-1.")
78
Prova: (i = 0): Se c0 = 0, C0 = 0 e A(N) P0 = 1 / (N+1)
Se c0 0, sob IPC, essas c0 observações são colocadas no início de I(0) e portanto não trazem nenhuma info. Podemos considerar apenas N-c0 = N-C0 observações restantes. A(N-C0) P0 = 1 / (N-C0+1) Sob IPC, c1 observações são colocadas no início de I(1) e para o cálculo da parcela acima (condicional a Z > x1) não trazem nenhuma info. assim como x1. Podemos então sob A(N – 1 – c0 – c1) = A(N – 1 – C1) obter Pr( Z I(1) | Z > x1 , IPC, ) = 1
 e portanto não trazem nenhuma info. Podemos considerar apenas N-c0 = N-C0 observações restantes. A(N-C0) P0 = 1 / (N-C0+1) Sob IPC, c1 observações são colocadas no início de I(1) e para o cálculo da parcela acima (condicional a Z > x1) não trazem nenhuma info. assim como x1. Podemos então sob A(N – 1 – c0 – c1) = A(N – 1 – C1) obter Pr( Z I(1) | Z > x1 , IPC, ) = 1.")
79
Logo, O mesmo raciocínio pode ser seguido e usando indução mostra-se o resultado. A substituição de IEC por IPC faz com que i = Pr( Z I(i) | Z > xi , IPC, ) produzam cotas superiores para Pr( Z I(i) | Z > xi , IEC, ) Observe que Cotas inferiores podem ser obtidas se censuras são trazidas para cima. IPCI = {Zj > Uj , j = n+1, ..., N} Info. Parcial de Censura Inferior onde Uj é o menor xi | xi > yj Nesse caso Q0 Pr( Z I(0) | IPCI, ) , por A(N)
 | Z > xi , IPC, ) produzam cotas superiores para Pr( Z I(i) | Z > xi , IEC, ) Observe que. Cotas inferiores podem ser obtidas se censuras são trazidas para cima. IPCI = {Zj > Uj , j = n+1, ..., N} Info. Parcial de Censura Inferior onde Uj é o menor xi | xi > yj. Nesse caso Q0 Pr( Z I(0) | IPCI, ) , por A(N)")
80
Podemos definir Pr( Z I(i) | Z > xi , IPCI, )
Assim como Podemos definir Pr( Z I(i) | Z > xi , IPCI, ) Por analogia com temos que , i = 0, 1, ..., n com C-1 = 0 Definindo então Pi = , = Pr( Z I(i) | IPCI, ) temos Além disso, = Pr( Z I(1) | Z > x1 , IPCI, ) Pr( Z I(1) | Z > x1 , IEC, ) Multiplicando as duas inequações tem-se
 | Z > xi , IPCI, ) Por analogia com temos que , i = 0, 1, ..., n. com C-1 = 0. Definindo então Pi = , = Pr( Z I(i) | IPCI, ) temos. Além disso, = Pr( Z I(1) | Z > x1 , IPCI, ) Pr( Z I(1) | Z > x1 , IEC, ) Multiplicando as duas inequações tem-se.")
81
Em geral

82
4. MODELOS DE REGRESSÃO PARA DADOS DE CONFIABILIDADE
4.1 Introdução Até agora, itens pertencem a mesma população. Às vezes, outras variáveis afetam os tempos de falha. Exemplos: tensão, pressão, temperatura (confiabilida-de), idade, tratamento, sexo (análise de sobrevivência). Estas variáveis são chamadas covariáveis, e devem ser incorporadas ao modelo. Elas podem ser contínuas (tensão, pressão, temperatura, idade) ou discretas (tratamento, sexo). De agora em diante, analisaremos dados de falha com covariáveis (regressão). Em confiabilidade, a maioria dos modelos são baseados na distribuição Weibull. Outra opção é a lognormal: após a transformação log nos tempos de falha, podemos fazer uso da teoria normal e da regressão padrão. Em geral, prefere-se a distribuição Weibull devido a facilidade do seu uso com dados censurados e devido a forma da função taxa de falha. Propósito do estudo: determinar o quanto T é afetado por x (covariáveis). Exemplo: x – tensão; T pode decrescer com x. § 4.2 a 4.6 descrevem diferentes modelos.
, idade, tratamento, sexo (análise de sobrevivência). Estas variáveis são chamadas covariáveis, e devem ser incorporadas ao modelo. Elas podem ser contínuas (tensão, pressão, temperatura, idade) ou discretas (tratamento, sexo). De agora em diante, analisaremos dados de falha com covariáveis (regressão). Em confiabilidade, a maioria dos modelos são baseados na distribuição Weibull. Outra opção é a lognormal: após a transformação log nos tempos de falha, podemos fazer uso da teoria normal e da regressão padrão. Em geral, prefere-se a distribuição Weibull devido a facilidade do seu uso com dados censurados e devido a forma da função taxa de falha. Propósito do estudo: determinar o quanto T é afetado por x (covariáveis). Exemplo: x – tensão; T pode decrescer com x. § 4.2 a 4.6 descrevem diferentes modelos.")
83
4.2 Modelos de Tempo de Vida Acelerado (ALM)
§ 4.7 a 4.9 lidamos com modelos baseados na distribuição Weibull. Capítulo 5 lida com modelos de taxa de falha proporcional. Capítulo 6 lida com modelos Bayesianos dinâmicos. 4.2 Modelos de Tempo de Vida Acelerado (ALM) Suponhamos tempos de falha sujeitos a uma carga. ALM: tempo de falha é o produto de uma função da carga e do tempo de falha padrão. Tempo de falha padrão: tempo de falha para um nível padrão de carga Pr (T t x) = S (t; x) = S0 (t yx ) aonde S0 é a sobrevivência básica (padrão) e yx é uma função positiva de x. Quando x está no nível básico: yx = 1. Para outros valores de x, tempo de falha é acelerado (multiplicado) por yx. Exemplo: S0 é exponencial unidade (S0 (t) = e t ) e yx = x b S (t; x) = S0 (t x b ) = exp {t x b } No ALM: Tyx tem distribuição básica ou log T = log yx + log W, aonde W ~ P (não depende de x).
 Suponhamos tempos de falha sujeitos a uma carga. ALM: tempo de falha é o produto de uma função da carga e do tempo de falha padrão. Tempo de falha padrão: tempo de falha para um nível padrão de carga. Pr (T t x) = S (t; x) = S0 (t yx ) aonde S0 é a sobrevivência básica (padrão) e yx é uma função positiva de x. Quando x está no nível básico: yx = 1. Para outros valores de x, tempo de falha é acelerado (multiplicado) por yx. Exemplo: S0 é exponencial unidade (S0 (t) = e t ) e yx = x b. S (t; x) = S0 (t x b ) = exp {t x b } No ALM: Tyx tem distribuição básica ou log T = log yx + log W, aonde W ~ P (não depende de x).")
84
Sj (t) = S0 (t yx) = S0 {exp (log t + log yj )} = s0 (log t + log yj )
Uma especificação comum é log yx = xTb (similar aos modelos lineares normais). A função taxa de falha h (t; x) é A adequação do ALM pode ser preliminarmente avaliada pelos seguintes gráficos: 1) Sendo log T = log yx + “termo de erro”, o gráfico de log T versus x deve fornecer uma indicação da forma de y. 2) Se os dados podem ser agrupados em k grupos homogêneos, os gráficos das estimativas das funções de sobrevivência versus log t devem ser cópias horizontais deslocadas de S0 quando Sj (t) = S0 (t yx) = S0 {exp (log t + log yj )} = s0 (log t + log yj ) 3) Também no ALM com k grupos, os quantis são proporcionais. Isto é, se qj (p) é o p-ésimo quantil do grupo j então qj (p) yj = qk (p) yk porque S0 (qj (p) yj) = Sj (qj (p)) = p, j. Os quantis 0.1, 0.2, ..., 0.9 para todos os grupos podem ser estimados de
. A função taxa de falha h (t; x) é. A adequação do ALM pode ser preliminarmente avaliada pelos seguintes gráficos: 1) Sendo log T = log yx + termo de erro , o gráfico de log T versus x deve fornecer uma indicação da forma de y. 2) Se os dados podem ser agrupados em k grupos homogêneos, os gráficos das estimativas das funções de sobrevivência versus log t devem ser cópias horizontais deslocadas de S0 quando. Sj (t) = S0 (t yx) = S0 {exp (log t + log yj )} = s0 (log t + log yj ) 3) Também no ALM com k grupos, os quantis são proporcionais. Isto é, se qj (p) é o p-ésimo quantil do grupo j então qj (p) yj = qk (p) yk porque S0 (qj (p) yj) = Sj (qj (p)) = p, j. Os quantis 0.1, 0.2, ..., 0.9 para todos os grupos podem ser estimados de .")
85
4.3 Modelos de Taxas de Falha Proporcionais (PHM)
Podemos fazer o gráfico dos quantis estimados para o grupo j, j = 2, ..., k versus os do grupo 1. Os gráficos devem ser aproximadamente lineares com inclinação y1 /yj . Equivalentemente, os gráficos dos log-quantis devem ser linhas paralelas. Os gráficos também poderão ser feitos versus a média dos quantis (ao invés de versus os quantis do grupo 1). 4.3 Modelos de Taxas de Falha Proporcionais (PHM) PHM: a taxa de falha é acelerada, isto é, h (t; x) = h0 (t) yx aonde h0 é a função taxa de falha básica (padrão) e yx é uma função positiva de x. Quando x está no nível básico: yx = 1. Este nome vem do fato (não depende de t). Uma especificação comum é log yx = xTb. Assim, h (t; x) = h0 (t) exp{xTb}. A função de sobrevivência é
. 4.3 Modelos de Taxas de Falha Proporcionais (PHM) PHM: a taxa de falha é acelerada, isto é, h (t; x) = h0 (t) yx aonde h0 é a função taxa de falha básica (padrão) e yx é uma função positiva de x. Quando x está no nível básico: yx = 1. Este nome vem do fato (não depende de t). Uma especificação comum é log yx = xTb. Assim, h (t; x) = h0 (t) exp{xTb}. A função de sobrevivência é.")
86
4.4 Modelos de Razão de Chances Proporcionais (POM)
Se S (t; x) é um ALM e um PHM então S (t; x) = Sa 0 (t y ax) = e a única solução possível é a sobrevivência da Weibull Sa 0 (t) = Sp 0 (t) = exp {t h } com Gráficos preliminares podem novamente serem feitos depois da separação dos dados em k grupos. Assim, temos que log Sj (t) = y j log S0 (t) ou log {log S j (t)} = log y j + log {log S0 (t)} e os gráficos de devem ser múltiplos mutuamente na escala log ou devem ser cópias verticais deslocadas de cada um na escala log-log. 4.4 Modelos de Razão de Chances Proporcionais (POM) POM: a função taxa de falha satisfaz Após diferenciar em relação a t, A razão taxa de falha é yx quando t = 0 e tende a 1 quando t .
 é um ALM e um PHM então. S (t; x) = Sa 0 (t y ax) = e a única solução possível é a sobrevivência da Weibull Sa 0 (t) = Sp 0 (t) = exp {t h } com . Gráficos preliminares podem novamente serem feitos depois da separação dos dados em k grupos. Assim, temos que. log Sj (t) = y j log S0 (t) ou log {log S j (t)} = log y j + log {log S0 (t)} e os gráficos de devem ser múltiplos mutuamente na escala log ou devem ser cópias verticais deslocadas de cada um na escala log-log. 4.4 Modelos de Razão de Chances Proporcionais (POM) POM: a função taxa de falha satisfaz. Após diferenciar em relação a t, A razão taxa de falha é yx quando t = 0 e tende a 1 quando t .")
87
f 1 {log S j (t)} = g 1 (y j ) + f 1 {log S0 (t)}.
ocorre diminuição do efeito de x na taxa de falha a medida que o tempo cresce. Avaliações preliminares podem ser feitas baseadas nos gráficos 4.5 Generalizações A relação PHM log {log S j (t)} = log y j + log {log S0 (t)} pode ser generalizada como f 1 {log S j (t)} = g 1 (y j ) + f 1 {log S0 (t)}. Isto inclui o POM como o caso especial: f 1 (u) = log {(1 u) / u}. A relação ALM log q j = log q 0 log (y j / y 0) pode ser generalizada como f 2 (q j ) = f 2 (q 0) g 2 (y j / y 0). Outras generalizações são: 1) ALM generalizado aonde y x também depende de t. 2) PHM generalizado aonde aonde s (l ) é a família Box-Cox de transformações em s. 3) Modelo de deslocamento no tempo: h (t; x) = h0 (t + yx) – taxa de falha de ação atrasada. 4) Modelo de taxa de falha polinomial: h (t; x) = y 0x + y 1x t y qx t q. 5) Modelo de taxa de falha por partes: h (t; x) = h i (t; x), para t I i, i = 1, ..., N.
} = log y j + log {log S0 (t)} pode ser generalizada como. f 1 {log S j (t)} = g 1 (y j ) + f 1 {log S0 (t)}. Isto inclui o POM como o caso especial: f 1 (u) = log {(1 u) / u}. A relação ALM log q j = log q 0 log (y j / y 0) pode ser generalizada como f 2 (q j ) = f 2 (q 0) g 2 (y j / y 0). Outras generalizações são: 1) ALM generalizado aonde y x também depende de t. 2) PHM generalizado aonde aonde s (l ) é a família Box-Cox de transformações em s. 3) Modelo de deslocamento no tempo: h (t; x) = h0 (t + yx) – taxa de falha de ação atrasada. 4) Modelo de taxa de falha polinomial: h (t; x) = y 0x + y 1x t y qx t q. 5) Modelo de taxa de falha por partes: h (t; x) = h i (t; x), para t I i, i = 1, ..., N.")
88
b i = G i b i1 + w i aonde E(w i) = 0 e Var (w i) = Wi.
6) Covariáveis dependentes do tempo: x pode depender do tempo em alguns casos. 4.6 Modelos Bayesianos dinâmicos (DMB) (cf Gamerman, 1991) DMB combina modelos de taxas de falha proporcionais (PHM) com distribuição exponencial por partes (similar ao modelo de taxa de falha por partes). Do PHM, temos que h (t; x) = h0 (t) y x. Assuma que h0 (t) = exp {b i, 0}, t I i. Também, generalize y x para y i, x, para que dependa de t. Uma especificação comum é y i, x = exp {xTb i}. O modelo pode ser escrito como h (t; x) = exp {xTb i}, aonde b i agora inclui uma primeira componente b i, 0 e xT agora inclui uma primeira componente 1. O modelo é completado com a relação entre os parâmetros em intervalos sucessivos, como em § 3.8. b i = G i b i1 + w i aonde E(w i) = 0 e Var (w i) = Wi. A matriz evolução G i fixa a parte determinística da evolução e o termo de erro w i controla o aumento na incerteza a medida que o tempo passa. Exemplos: 1) G i = I, é a matriz identidade (passeio aleatório simples);
 Covariáveis dependentes do tempo: x pode depender do tempo em alguns casos. 4.6 Modelos Bayesianos dinâmicos (DMB) (cf Gamerman, 1991) DMB combina modelos de taxas de falha proporcionais (PHM) com distribuição exponencial por partes (similar ao modelo de taxa de falha por partes). Do PHM, temos que h (t; x) = h0 (t) y x. Assuma que h0 (t) = exp {b i, 0}, t I i. Também, generalize y x para y i, x, para que dependa de t. Uma especificação comum é y i, x = exp {xTb i}. O modelo pode ser escrito como h (t; x) = exp {xTb i}, aonde b i agora inclui uma primeira componente b i, 0 e xT agora inclui uma primeira componente 1. O modelo é completado com a relação entre os parâmetros em intervalos sucessivos, como em § 3.8. b i = G i b i1 + w i aonde E(w i) = 0 e Var (w i) = Wi. A matriz evolução G i fixa a parte determinística da evolução e o termo de erro w i controla o aumento na incerteza a medida que o tempo passa. Exemplos: 1) G i = I, é a matriz identidade (passeio aleatório simples);")
89
2) G i = diag (1, G i 1) aonde (modelo de crescimento generalizado). A variância pode novamente ser especificada através dos fatores de desconto. Pode ter uma para cada parâmetro mas o mais comum é ter uma para o parâmetro de base b i, 0 e uma para os coeficientes de regressão. Geralmente, esta última é próxima a 1 (se 1, o modelo se torna PHM). Se não há presença de covariáveis, o modelo se torna o mesmo de § 3.8.
. Se não há presença de covariáveis, o modelo se torna o mesmo de § 3.8.")
90
4.7 Modelos Baseados na Distribuição Weibull
O Modelo de Regressão Weibull pode ser escrito como: Pode, também, ser escrito como: onde ALM onde onde PHM

91
Estimação e Testes Plot de Resíduos onde:
Sabemos que W ~ Gumbel e ainda que h é somente um fator escala, mas também pode ser dependente de x. Estimação e Testes Regressão Linear Simples: Estimador de Mínimos Quadrados pode ser usado. Procedimento similar pode ser usado para regressões múltiplas. Mais formalmente, o Estimador de Máxima Verossimilhança pode ser calculado como no capítulo 3: parâmetros são estimados, variâncias assintóticas obtidas e testes de hipóteses calculados via Teste da Razão de Máxima Verossimilhança. Esses cálculos podem ser manuseados por GLIM. Plot de Resíduos PPplot pode ser usado como em 3.5 Os dados transformados convergem para uma amostra de variáveis aleatórias U(0,1). Os ui’s são chamados resíduos generalizados. Também, zi = log(-log ui) tem distribuição Gumbel. Um plot de probabilidade pode ser construído como segue: onde:
. Os ui’s são chamados resíduos generalizados. Também, zi = log(-log ui) tem distribuição Gumbel. Um plot de probabilidade pode ser construído como segue: onde:")
92
Ordene os zi’s em zi:n, ..., zn:n
Faça o gráfico zi:n contra log{- log(1-pi:n)} onde pi:n é: Dados não censurados Checar se o gráfico é da forma y=x Resíduos generalizados são também proveitosos quando plotados contra covariáveis (ver 4.8) Dados censurados
} onde pi:n é: Dados não censurados. Checar se o gráfico é da forma y=x. Resíduos generalizados são também proveitosos quando plotados contra covariáveis (ver 4.8) Dados censurados.")
93
4.8 Um Exemplo: Resistências de Fibras de Carbono e Pacotes
Dados das tabelas 4.1 e 4.2 são analisados.

95
Sob ALM, a distribuição de logT:
1) Variam em locação de um pro outro. 2) Tem a mesma variância. Variância amostral dos dados da tabela 4.1são: 0.042, 0.040, e => estaticamente equivalentes figura 4.1 é o gráfico 2 da seção 4.2: variação horizontal. Figuras 4.2e 4.3: linear (particularmente na figura 4.3). Gráficos de contra log t deve ser: Cópias verticais da mesma curva, sob PHM; Linhas paralelas, sob modelo de regressão Weibull (ver seção 4.7) figura 4.4 mostra gráfico de contra log t para dados da tabela 4.1com linhas Weibull (ajuste por Máxima Verossimilhança separadamente em cada amostra). Figura 4.6 mostra o mesmo gráfico para os dados da tabela 4.2 Sob POM, devem ser cópias verticais uma da outra (ver figura 4.5)
 Variam em locação de um pro outro. 2) Tem a mesma variância. Variância amostral dos dados da tabela 4.1são: 0.042, 0.040, e => estaticamente equivalentes. figura 4.1 é o gráfico 2 da seção 4.2: variação horizontal. Figuras 4.2e 4.3: linear (particularmente na figura 4.3). Gráficos de contra log t deve ser: Cópias verticais da mesma curva, sob PHM; Linhas paralelas, sob modelo de regressão Weibull (ver seção 4.7) figura 4.4 mostra gráfico de contra log t para dados da tabela 4.1com linhas. Weibull (ajuste por Máxima Verossimilhança separadamente em cada amostra). Figura 4.6 mostra o mesmo gráfico para os dados da tabela 4.2. Sob POM, devem ser cópias verticais uma da outra (ver figura 4.5)")
96
onde Sr é a função de sobrevivência para fibra de comprimento r.
Agora, nesta Seção, vamos nos concentrar em Weakest Link Hypotesis: onde Sr é a função de sobrevivência para fibra de comprimento r. WLH pode ser implementada nos seguintes modelos Weibull: M1 – como em M0 mas com M2 – como em M1 mas com (modelo log-linear no parâmetro escala da distribuição Gumbel); M3 – distribuição Weibull separada para cada comprimento. onde
; M3 – distribuição Weibull separada para cada comprimento. onde.")
97
Os valores maximizados da função log-verossimilhaça são:
A função de verossimilhança pode ser obtida para cada modelo e na maioria dos casos, maximizá-la não é difícil. Os valores maximizados da função log-verossimilhaça são: l0 = (2 parâmetros) l1 = (3 parâmetros) l2 = (4 parâmetros) l3 = (8 parâmetros) Teste de hipótese H1: e=1 é calculado via estatística de razão de verossimilhança: é aceita. (O Estimador de Máxima Verossimilhança sob M1 é 0.90) Dados da tabela 4.2: valores maximizados da log-verossimilhança são:
 l1 = (3 parâmetros) l2 = (4 parâmetros) l3 = (8 parâmetros) Teste de hipótese H1: e=1 é calculado via estatística de razão de verossimilhança: é aceita. (O Estimador de Máxima Verossimilhança sob M1 é 0.90) Dados da tabela 4.2: valores maximizados da log-verossimilhança são:")
98
l0 = 21.8 (2 parâmetros) l1 = 29.6 (3 parâmetros) l2 = 31.5 (4 parâmetros) l3 = 35.8 (8 parâmetros) Teste de H1 agora tem W1 = 15.6 > 3.84 => M0 rejeitado O Estimador de Máxima Verossimilhança de e sob M1 é 0.58 WLH não necessariamente implica modelo Weibull PHM também é possível.

102
4.9 Análise Bayesiana de Dados de Confiança
Como mencionado anteriormente, as análises de grande amostra de máximo verossimilhança oferecem resultados similares à análise bayesiana com vaga informação a priori. Exemplo: A estimativa de máximo verossimilhança 0,58 de ξ para os dados da tabela 4.2 é uma aproximação da média da posteriori de ξ. Os testes de níveis de significância não possuem complemento bayesiano. O teste de hipótese bayesiano pode ser feito da seguinte maneira: 1) Constrói-se a região de máxima densidade a posteriori 100(1-α)% do parâmetro de interesse (ξ, no exemplo anteriormente citado); 2) Observa-se se esta região contém o valor do parâmetro especificado por H (1, no exemplo anterior); 3) Aceita-se H se este for o caso ou rejeita-se H, caso contrário. Também, para grandes amostras, a razão de máxima posteriori pode ser aproximada pela razão de máxima verossimilhança, se a priori for vaga. Exemplo: Considere os dados da tabela 6.1 do modelo Weibull. onde W ~ Gumbel
 Constrói-se a região de máxima densidade a posteriori 100(1-α)% do parâmetro de interesse (ξ, no exemplo anteriormente citado); 2) Observa-se se esta região contém o valor do parâmetro especificado por H (1, no exemplo anterior); 3) Aceita-se H se este for o caso ou rejeita-se H, caso contrário. Também, para grandes amostras, a razão de máxima posteriori pode ser aproximada pela razão de máxima verossimilhança, se a priori for vaga. Exemplo: Considere os dados da tabela 6.1 do modelo Weibull. onde W ~ Gumbel.")
104
5. TAXA DE FALHA PROPORCIONAL
5.1 Introdução Baseada no documento de Cox (1972). Concentrada em análise de sobrevivência em vez de confiança. O modelo linear de taxa de falha proporcional assume que Cada variável x afeta a taxa de falha, oscilando para cima e para baixo. A análise depende das pressuposições dos parâmetros feitos em h0. Se a taxa de falha de base acumulada , então: onde y=logG(t).
. Concentrada em análise de sobrevivência em vez de confiança. O modelo linear de taxa de falha proporcional assume que. Cada variável x afeta a taxa de falha, oscilando para cima e para baixo. A análise depende das pressuposições dos parâmetros feitos em h0. Se a taxa de falha de base acumulada , então: onde y=logG(t).")
105
5.2 Análise do Modelo Semiparamétrico de Taxa de Falha Proporcional
Segue que z = ηy + log α + xT β ~ Gumbel e y = -η-1 log α – xT(-η-1 β) + η-1z sendo que esta é a fórmula do modelo log-linear de regressão da Weibull. Pode-se usar outras fórmulas para h0 e a que possuir o melhor ajuste, pode então, ser utilizada. 5.2 Análise do Modelo Semiparamétrico de Taxa de Falha Proporcional De agora em diante, h0 não será especificado. Assume-se n itens, r tempos de falha distintos e Ri é o conjunto de risco, ou seja, o grupo de itens que tem chances de falhar um pouco antes de t(i). β é estimado pela função de verossimilhança:
 + η-1z. sendo que esta é a fórmula do modelo log-linear de regressão da Weibull. Pode-se usar outras fórmulas para h0 e a que possuir o melhor ajuste, pode então, ser utilizada. 5.2 Análise do Modelo Semiparamétrico de Taxa de Falha Proporcional. De agora em diante, h0 não será especificado. Assume-se n itens, r tempos de falha distintos e Ri é o conjunto de risco, ou seja, o grupo de itens que tem chances de falhar um pouco antes de t(i). β é estimado pela função de verossimilhança:")
106
Há muitas justificativas para a verossimilhança acima:
1) Cox (1972) originalmente considerou análises condicionais dos tempos de falha . A probabilidade condicional do item (i) falhar dado que conhecemos as falhas anteriores é: A verossimilhança é formada pelo produto das probabilidades condicionais. (Basicamente, usa-se ) 2) Também, é obtida por Kalbfleisch & Prentice (1973) como a verossimilhança marginal de β baseada nos postos das observações. Se L(β ) é tratado como a verossimilhança, então a teoria da máximo verossimilhança pode ser aplicada: i) O estimador de máximo verossimilhança é obtido maximizando L(β ); ii) Sua variância assintótica é obtida pela 2ª derivada de l(β). Computacionalmente: Primeiro, calcula-se ;
 Cox (1972) originalmente considerou análises condicionais dos tempos de falha . A probabilidade condicional do item (i) falhar dado que conhecemos as falhas anteriores é: A verossimilhança é formada pelo produto das probabilidades condicionais. (Basicamente, usa-se ) 2) Também, é obtida por Kalbfleisch & Prentice (1973) como a verossimilhança. marginal de β baseada nos postos das observações. Se L(β ) é tratado como a verossimilhança, então a teoria da máximo verossimilhança pode ser aplicada: i) O estimador de máximo verossimilhança é obtido maximizando L(β ); ii) Sua variância assintótica é obtida pela 2ª derivada de l(β). Computacionalmente: Primeiro, calcula-se ;")
107
L(β ) é formado pelo produto dos termos λ(i)/ci.
Então, acumula-se o decréscimo dos tempos de falha pra obter , i = 1,...r. L(β ) é formado pelo produto dos termos λ(i)/ci. O log de verossimilhança e suas derivadas são: Onde e A maximização numérica é usada para obter Há pacotes computacionais que podem nos auxiliar, por exemplo, o R. Observações Empatadas: Dados empatados complicam os cálculos da verossimilhança.
 é formado pelo produto dos termos λ(i)/ci. O log de verossimilhança e suas derivadas são: Onde. e. A maximização numérica é usada para obter . Há pacotes computacionais que podem nos auxiliar, por exemplo, o R. Observações Empatadas: Dados empatados complicam os cálculos da verossimilhança.")
108
5.3 Estimação de Sobrevivência e Função de Taxa de Falha
Uma aproximação razoável neste caso é: Onde di é o número de tempos que falham em t(i) e s(i) é a soma das covariâncias que dependem destes tempos. A aproximação é boa se di /n(i) for pequeno. As covariâncias que dependem dos tempos são substituídas de x(l) por x(l) (t(i)). 5.3 Estimação de Sobrevivência e Função de Taxa de Falha A taxa de sobrevivência de base é obtida por um método não paramétrico junto com o estimador do produto limite, como: onde Também, o estimador de H0 é dado por Os métodos do capítulo 3 podem ser aplicados aqui para verificar as formas paramétricas para S0 .
 e s(i) é a soma das covariâncias que dependem destes tempos. A aproximação é boa se di /n(i) for pequeno. As covariâncias que dependem dos tempos são substituídas de x(l) por x(l) (t(i)). 5.3 Estimação de Sobrevivência e Função de Taxa de Falha. A taxa de sobrevivência de base é obtida por um método não paramétrico junto com o estimador do produto limite, como: onde. Também, o estimador de H0 é dado por . Os métodos do capítulo 3 podem ser aplicados aqui para verificar as formas paramétricas para S0 .")
109
5.4 Métodos de Verificação
As suposições da taxa de falha proporcional podem ser verificadas pelos dados e modelos de ajuste: Depois do ajuste, o gráfico do log vs. t deve ter paralelas verticais. O resíduo pode ser definido por um item não censurado como: e por um item censurado, e deve ser somado por 1. Se os resíduos se comportam como amostras de uma distribuição exponencial de média 1, o ajuste é adequado. Deve-se ter cautela, pois os resíduos podem estar adequados mesmo quando a taxa de falha proporcional não estiver. Também, o gráfico dos resíduos vs. as variáveis pode não se encaixar no modelo.

110
5.5 Exemplos Numéricos Tabela 4.3 contem dados de falha sob stress
Tabela 4.3 contem dados de falha sob stress Figura 4.7 indica a influencia da taxa de stress na falha h(t;x) = h0(t)em(x) para alguma função m de x caso m(x)= -β log x , temos que β^ =0,2069 com erro padrão assintótico = 0,0457 => forte efeito da taxa de stress Figura 5.1 mostra um gráfico de log^H0(t) vs log t indicando Weibull A checagem da hipótese de modelo de taxas proporcionais é feita segundo estratificação sugerida em §5.4 Isto leva ao gráfico na Figura 5.2 (paralelismo vertical= OK) Checagem da linearidade em log x é feita através de um estimador não paramétrico dos efeitos de x onde zj(x) é um indicador de que x está no nível j. Este modelo não é estimável (uma constante pode sempre ser adicionada ao αj)
 = h0(t)em(x) para alguma função m de x. caso m(x)= -β log x , temos que β^ =0,2069 com erro padrão assintótico = 0,0457 => forte efeito da taxa de stress. Figura 5.1 mostra um gráfico de log^H0(t) vs log t indicando Weibull. A checagem da hipótese de modelo de taxas proporcionais é feita segundo estratificação sugerida em §5.4. Isto leva ao gráfico na Figura 5.2 (paralelismo vertical= OK) Checagem da linearidade em log x é feita através de um estimador não paramétrico dos efeitos de x. onde zj(x) é um indicador de que x está no nível j. Este modelo não é estimável (uma constante pode sempre ser adicionada ao αj)")
111
Mas se torna estimável ao se impor uma restrição (Σαj =0 ou αk =0, para algum k)
O valor maximizado de l é –177,00 em oposição a-178,19 sob o modelo linear. W = 2 (-177,00+178,19) = 2,38 < 7,81 = χ20,05(4-1) => modelo linear aceito Tabela 4.4 contem dados de tempo de falha de fibras Figura 4.8 contem PH plots para diferentes níveis de stress. Dando indicação de que o efeito dos lotes nos tempos de falha do modelo proposto é onde S é o nível de stress e zj é o indicador do lote j , j = 1,..,7
 = 2,38 < 7,81 = χ20,05(4-1) => modelo linear aceito. Tabela 4.4 contem dados de tempo de falha de fibras. Figura 4.8 contem PH plots para diferentes níveis de stress. Dando indicação de que o efeito dos lotes nos tempos de falha do modelo proposto é. onde S é o nível de stress e zj é o indicador do lote j , j = 1,..,7.")
112
Figura 4.7 Plot da Weibull para dados de tungestênio, com linhas ajustadas pela Weibull

113
Figura 5.2 Procedimentos iterativos funcionarão melhor caso iniciem com bons valores iniciais. Estes podem ser obtidos através da MV com Weibull ou por mínimos quadrados. γ^ =32,586 com erro padrão assintótico igual a 3,097 => forte efeito da taxa de stress. O teste para efeito do lote é baseado na Razão de MV entre M0: não há efeito do lote e M1: existe efeito do lote A maximização das log verossimilhanças são –320,119 e –261,775 que nos trazem W =2(-261, )=116,69 >> χ2α(7)=> o efeito do lote é significante.
=116,69 >> χ2α(7)=> o efeito do lote é significante.")
114
A figura 5.3 mostra o gráfico do log^Hj aproximado por PH
A hipótese de modelo de taxas proporcionais é testada pela estratificação dos dados através dos lotes. A figura 5.3 mostra o gráfico do log^Hj aproximado por PH A figura 5.4 mostra o gráfico do log^H0 vs log t , onde linearidade indica Weibull Também é possível investigar a interação entre o stress e os lotes. Isto é feito através da inclusão de 7 covariáveis zj log S no modelo A maximização da log-verossimilhança é –259,241 com W=5,07 (não significante) Ajustando uma linha reta na figura 5.4 teremos log^H0(t)= -11,19 + 1,533logt E H^j(T)=15,296T1,533S32,586eα^j , j = 1,...,8 (α8 = 0) Exemplo : o tempo médio de falha previsto para S= 23,4 e j = 4 é T = 7,4 anos.
 Ajustando uma linha reta na figura 5.4 teremos. log^H0(t)= -11,19 + 1,533logt. E. H^j(T)=15,296T1,533S32,586eα^j , j = 1,...,8 (α8 = 0) Exemplo : o tempo médio de falha previsto para S= 23,4 e j = 4 é T = 7,4 anos.")
116
Figura 4.8 plot da Weibull para dados de fibra de Kevlar sob pressão , com linhas ajustadas pela Weibull Figura 5.3 Log da função de taxa de falha acumulada para dados da fibra de Kevlar: modelo estratificado . Lotes 1-8

117
Figura 5.4 Log da Log da função de taxa de falha acumulada para dados da fibra de Kevlar
Em geral: i = 0, 1, ..., n-2

118
6. MODELOS BAYESIANOS DINÂMICOS
6.1 Introdução Os modelos PH (Proportional Harzard Model) são razoáveis em alguns casos, porem muitas as vezes modelos mais genéricos são requeridos. Os enfoques utilizados são : 1 - Parametrização das mudanças entre as faixas de estimação. Exemplo : 2 - Estimação independente por partes em cada intervalo. O primeiro enfoque exige uma suposição forte em torno dos dados enquanto o segundo não exige nada ,porem as informações contidas nos intervalos anteriores são desconsideradas. Modelos dinâmicos permite mapearmos as mudanças entre as diferentes faixas sem a necessidade de fortes suposições e permitindo que os dados orientem a direção do modelo.
 são razoáveis em alguns casos, porem muitas as vezes modelos mais genéricos são requeridos. Os enfoques utilizados são : 1 - Parametrização das mudanças entre as faixas de estimação. Exemplo : 2 - Estimação independente por partes em cada intervalo. O primeiro enfoque exige uma suposição forte em torno dos dados enquanto o segundo não exige nada ,porem as informações contidas nos intervalos anteriores são desconsideradas. Modelos dinâmicos permite mapearmos as mudanças entre as diferentes faixas sem a necessidade de fortes suposições e permitindo que os dados orientem a direção do modelo.")
119
6.2 Elementos do Modelo Distribuição Exponencial por Partes
Modelos dinâmicos provem uma abordagem para os modelos de PHM. 6.2 Elementos do Modelo Distribuição Exponencial por Partes A Distribuição Exponencial por Partes é usada para tempo de falha baseada na função de densidade Harzard : , onde o primeiro componente (baseline) e o primeiro componente Fatorização Temporal da verossimilhança Os dados podem ser divididos ao longo do mesmo intervalo Ii . Cada intervalo prove a verossimilhança baseado na condicional das informações obtidos do intervalo anterior.
 e o primeiro componente . Fatorização Temporal da verossimilhança. Os dados podem ser divididos ao longo do mesmo intervalo Ii . Cada intervalo prove a verossimilhança baseado na condicional das informações obtidos do intervalo anterior.")
120
6.3 Desenvolvendo a Análise
Esta é a verossimilhança do intervalo Ii condicionado em Di-1, F(Ii) é o conjunto de itens que falharam no intervalo Ii , R(Ii) é o conjunto de itens que estavam em risco antes Ii mais não falharam em Ii e L é o conjunto de parâmetros 6.3 Desenvolvendo a Análise Evolução Paramétrica Como descrito em 4.6, parâmetros sucessivos podem ser calculados via
 é o conjunto de itens que falharam no intervalo Ii , R(Ii) é o conjunto de itens que estavam em risco antes Ii mais não falharam em Ii e. L é o conjunto de parâmetros. 6.3 Desenvolvendo a Análise. Evolução Paramétrica. Como descrito em 4.6, parâmetros sucessivos podem ser calculados via.")
121
W Þ 0 conduz ao um modelo estático.
O valor de W indica o potencial de mudança dos b´s por unidade de tempo. W Þ 0 conduz ao um modelo estático. W-1 Þ 0 grande potencial de mudança conduzindo a modelos independentes. Assume-se que : (especificação parcial) A priori para o intervalo Ii é onde Novamente, o valor de Wi (ou W) podem ser definidos como fatores de desconto. Verossimilhança e Atualização A verossimilhança Li pode ser escrita como :
 A priori para o intervalo Ii é onde. Novamente, o valor de Wi (ou W) podem ser definidos como fatores de desconto. Verossimilhança e Atualização. A verossimilhança Li pode ser escrita como :")
122
dij é o indicador de falha para o item em j ,
Onde Onde é o valor constante da hazard para o item s em Ii , ri é o numero do item em Ii dij é o indicador de falha para o item em j , tij é o tempo de sobrevivência do indivíduo j em Ii . Uma analise baysiana completa envolve a especificação da prior para até a integração numérica de cada intervalo Ii , alternativamente, especificações parciais podem ser utilizadas. A atualização é efetuada em ciclos através dos intervalos e dentro de cada intervalo através de seus itens. O calculo envolvendo esta analise esta especificado abaixo: LINEAR BAYES MEDIA SAIDA

123
Passo 1 : Dado obtemos : Passo 2 : Aproximar por uma Gamma utilizando os dados do Passo 1. Parâmetros e ; Passo 3 : Atualizar, usando a informação do Lij para ; Passo 4 : Use os métodos lineares de bayes e a relação entre e para obter Passo 5 : Defina ai,j+1 = mij e Pi,j+1=Cij e repita os passo anteriores; Passo 6 : Quando j=rij , todos os itens Li tem sido processado. Evolui para o próximo intervalo.

124
O procedimento acima tem como resultado a especificação parcial da distribuição :
Este procedimento continua ate In , o ultimo intervalo com informações. Smoothing É mais conveniente trabalhar com a distribuição de Ela gera resultados mais precisos e é utilizada na predição.Existem distribuições Smoothing obtidas via algoritmos recursivos. Com valores iniciais

125
6.4 Predição de Ocorrências Futuras
Dois casos devem ser considerados : 1) Predição dos itens que sobraram e ainda não falharam 2) Predição de novos itens. Para o caso 2, a distribuição de sobrevivência predita é S(W\DN) onde , O fato acima pode ser obtido da seguinte forma : Obtido de Aproximados pela distribuição de
 Predição dos itens que sobraram e ainda não falharam. 2) Predição de novos itens. Para o caso 2, a distribuição de sobrevivência predita é S(W\DN) onde , O fato acima pode ser obtido da seguinte forma : Obtido de. Aproximados pela distribuição de .")
126
Se então, Cálculos parecidos são utilizados para a distribuição preditora a posteriori Devemos verificar se a especificação da priori e razoável. 6.5 Ilustrações Exemplo 1 : Dados de 90 pacientes com câncer gástrico divididos em dois grupos de tratamento : Quimioterapia e Radioterapia / somente quimioterapia. PHM ajustado com 2 covariáveis : x1 - Indicador de tratamento e x2=x1*t. Isto é equivalente a assumir um modelo de regressão com os coeficientes Os estimadores MLE são :

127
Os estimadores MLE são :
Analises dinâmicas foram feitas com : 1 - Priori Vaga 2 - dados obtidos pelos tempos observados de falha. 3 - evolução do erro da variância , dado por : Para a variação foi utilizado um crescimento linear com em 4.6 . Figura 1 mostra as estimativas do coeficiente de regressão.

128
Figura 2 mostra a curva de sobrevivência predita.

129
Figura 3 mostra estimativas para as taxas de mudança de
. Exemplo 2 : Dados de 300 desempregados que foram acompanhados durante um ano na Inglaterra. Esta é uma amostra de um grande estudo feito por Germerman e West (1987). As covariáveis selecionadas são x1 ~ idade e x2 ~ faixa de renda. Analises dinâmicas foram feitas com : 1 - Priori 2 - Intervalos Semanais; 3 - Evolução do erro da variância Wi=7*diag(10-2,10-5,10-3).
. As covariáveis selecionadas são x1 ~ idade e x2 ~ faixa de renda. Analises dinâmicas foram feitas com : 1 - Priori. 2 - Intervalos Semanais; 3 - Evolução do erro da variância Wi=7*diag(10-2,10-5,10-3).")
130
Figura 4 mostra preposteriori par 4 hipotéticos indivíduos.
Figura 5 mostra estimativas paramétricas(priori estava muito forte).
.")
131
Figura 6 mostra predição para os mesmos 4 indivíduos.

Apresentações semelhantes