Carregar apresentação
A apresentação está carregando. Por favor, espere

1
Web Mining Aplicação de técnicas de Mineração de Dados para descoberta de padrões na Web Motivações: Encontrar informação relevante Gerar conhecimento a partir da informação disponível na Web Personalizar a informação Aprender sobre consumidores ou usuários individuais

2
Abordagens de Web Mining
Mineração de conteúdo (Web content mining) Extração de conhecimento do conteúdo de páginas e suas descrições Mineração de estrutura (Web structure mining) Obtenção de conhecimento a partir da organização da web e da referência cruzada de ligações. Mineração de uso (Web usage mining) Geração de padrões interessantes com o uso dos registros de acesso da web
 Extração de conhecimento do conteúdo de páginas e suas descrições. Mineração de estrutura (Web structure mining) Obtenção de conhecimento a partir da organização da web e da referência cruzada de ligações. Mineração de uso (Web usage mining) Geração de padrões interessantes com o uso dos registros de acesso da web.")
3
Mineração de conteúdo (Web content mining)
Extração de conhecimento do conteúdo de páginas e suas descrições Inclui a Mineração de texto (text mining) Aplicações Classificação de textos Detecção e acompanhamento de evento Extração de regras
 Aplicações. Classificação de textos. Detecção e acompanhamento de evento. Extração de regras.")
4
Documentos não estruturados
Texto livre Representação: bag of words Palavras do texto são atributos Booleano Baseado em frequência Ignora a sequência em que palavras aparecem Usa estatísticas sobre palavras isoladas

5
Outras formas de seleção:
Remover pontuação, palavras pouco frequentes, palavras muito frequentes Stemming – extrair o radical das palavras Outras formas de representação: Posição da palavra no documento N-grams (sequências de palavras de tamanho até n)
")
6
Documentos semi-estruturados
Tem informação estrutural adicional (HTML e hiperlinks) no documento de hipertexto Aplicações: Classificação de hipertextos Agrupamento Aprendizado de relações entre documentos web Extração de Padrões ou regras
 no documento de hipertexto. Aplicações: Classificação de hipertextos. Agrupamento. Aprendizado de relações entre documentos web. Extração de Padrões ou regras.")
7
Mineração de estrutura (Web structure mining)
Tenta descobrir o modelo por trás da estrutura de links na web. Informação extraída: Links apontando para um documento podem indicar sua popularidade Links saindo de um documento podem indicar a riqueza ou variedade de tópicos tratados pelo documento

8
Estrutura típica Páginas = nós, hyperlinks = arcos conectando páginas
Hyperlinks tem duas finalidades: Permitir navegação Apontar para páginas com “autoridade” no mesmo tópico da página contendo o link

9
Estruturas interessantes

10
Informações a serem extraídas:
Qualidade da página web Autoridade de uma página Ranking de páginas Estruturas interessantes co-citação, escolha social, etc

11
Mineração de uso (Web usage mining)
Aplicação das técnicas de mineração de dados para descobrir padrões de uso a partir de registros de acesso à web Tendências: extração de padrão geral de acesso personalização

12
Tendências - Definidas pelo tipo de aplicação:
Extração de padrão geral de acesso Analisa dados do web log file e outras fontes para descobrir padrões e tendências de acesso Pode ser usado para: Reestruturação dos sites em grupos mais eficientes Localizar pontos para propaganda mais efetiva Direcionar campanhas específicas para usuários específicos

13
Uso personalizado Analisa tendências de usuários individuais
Pode ser utilizado para: Personalizar dinamicamente a cada usuário, com base no padrão de acesso ao longo do tempo a informação apresentada, a profundidade do site e o formato dos recursos

14
Fontes de dados Dados do servidor Web Web server log Cookies
Dados de consultas

15
Dados do cliente Agente remoto (Javascripts ou Java applets)
Modificação do código fonte de um browser Requer a cooperação do usuário

16
Dados do proxy Web proxy atua como um nível intermediário entre browsers de clientes e servidores web Pode ser usado para reduzir o tempo de carregar uma página web Desempenho depende da habilidade de prever acessos futuros Dados podem revelar requisição de múltiplos usuários a múltiplos servidores web

17
Web server log Tipos de logs Formatos Error Segurança Referência
Browser (Agente) Accesso Formatos Common Log Extended log formats
 Accesso. Formatos. Common Log. Extended log formats.")
18
Exemplo: Web log #Software: Microsoft Internet Information Server 4.0
#Version: 1.0 #Date: :00:21 #Fields: date time c-ip cs-username cs-method cs-uri-stem cs-uri-query sc-status sc-bytes cs(User-Agent) cs(Cookie) cs(Referer) :00: GET /issue1/jobs/Default.asp :03: GET /statistics/ExpIntHits1.asp :26: GET /robots.txt :32: GET /issue2/default.asp :49: GET /resources/images/main/bg.gif Mozilla/2.0+(compatible;+MSIE+3.02;+AK;+Windows+NT) ASPSESSIONIDGQQGQGAD=IIHCBIFDIECKPAPGICDEOJII;+SITESERVER=ID=22e0a17296b8c2ed1f77460cde75c27f :49: GET /issue1/webtechs/Default.asp Mozilla/2.0+(compatible;+MSIE+3.02;+AK;+Windows+NT) - :49: GET /resources/images/main/global_home_h.gif Mozilla/2.0+(compatible;+MSIE+3.02;+AK;+Windows+NT) ASPSESSIONIDGQQGQGAD=IIHCBIFDIECKPAPGICDEOJII;+SITESERVER=ID=22e0a17296b8c2ed1f77460cde75c27f :49: GET /resources/images/main/global_search.gif Mozilla/2.0+(compatible;+MSIE+3.02;+AK;+Windows+NT) ASPSESSIONIDGQQGQGAD=IIHCBIFDIECKPAPGICDEOJII;+SITESERVER=ID=22e0a17296b8c2ed1f77460cde75c27f :49: GET /resources/images/main/local_home01.gif Mozilla/2.0+(compatible;+MSIE+3.02;+AK;+Windows+NT) ASPSESSIONIDGQQGQGAD=IIHCBIFDIECKPAPGICDEOJII;+SITESERVER=ID=22e0a17296b8c2ed1f77460cde75c27f
 cs(Cookie) cs(Referer) :00: GET /issue1/jobs/Default.asp :03: GET /statistics/ExpIntHits1.asp :26: GET /robots.txt :32: GET /issue2/default.asp :49: GET /resources/images/main/bg.gif Mozilla/2.0+(compatible;+MSIE+3.02;+AK;+Windows+NT) ASPSESSIONIDGQQGQGAD=IIHCBIFDIECKPAPGICDEOJII;+SITESERVER=ID=22e0a17296b8c2ed1f77460cde75c27f :49: GET /issue1/webtechs/Default.asp Mozilla/2.0+(compatible;+MSIE+3.02;+AK;+Windows+NT) :49: GET /resources/images/main/global_home_h.gif Mozilla/2.0+(compatible;+MSIE+3.02;+AK;+Windows+NT) ASPSESSIONIDGQQGQGAD=IIHCBIFDIECKPAPGICDEOJII;+SITESERVER=ID=22e0a17296b8c2ed1f77460cde75c27f :49: GET /resources/images/main/global_search.gif Mozilla/2.0+(compatible;+MSIE+3.02;+AK;+Windows+NT) ASPSESSIONIDGQQGQGAD=IIHCBIFDIECKPAPGICDEOJII;+SITESERVER=ID=22e0a17296b8c2ed1f77460cde75c27f :49: GET /resources/images/main/local_home01.gif Mozilla/2.0+(compatible;+MSIE+3.02;+AK;+Windows+NT) ASPSESSIONIDGQQGQGAD=IIHCBIFDIECKPAPGICDEOJII;+SITESERVER=ID=22e0a17296b8c2ed1f77460cde75c27f")
19
Este arquivo de log mostra visitas ao web site Exploit Interactive de 00:00:00 em 25 de Dezembro de 1999: A visit from an AltaVista robot in UK, downloading several text files A visit from a FAST-Crawler robot in Norway A visit from a PC (WinNT) user of an IE browser who followed a link at < techs.html> and downloaded a HTML page and several images
 user of an IE browser who followed a link at < techs.html> and downloaded a HTML page and several images.")
20
Web Server Log – Exemplo
Conteúdo da Página KDnuggets.com Server Web server log [16/Nov/2005:16:32: ] "GET … HTTP/1.1" 200 [16/Nov/2005:16:32: ] "GET /gps.html HTTP/1.1" 200 [16/Nov/2005:16:32: ] "GET /jobs/ HTTP/1.1" 200 …

21
Web (Server) Log Uma linha (exemplo) do log 152.152.98.11 - -
[16/Nov/2005:16:32: ] "GET /jobs/ HTTP/1.1" " "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR )“ - - [16/Nov/2005:16:32: ] "GET /jobs/ HTTP/1.1" 200 15140 " =en&lr=&start=10&sa=N" "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR )"
 [16/Nov/2005:16:32: ] GET /jobs/ HTTP/ q=salary+for+data+mining&hl =en&lr=&start=10&sa=N Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR )")
22
Web log: IP IP address – pode ser convertido para o nome do host, por exemplo: xyz.example.com

23
Top-Level Domains (TLD)
A última parte do domínio é o TLD TLD Generico .com (comercial) – geralmente mas não necessariamente USA .net (ISP, network providers) .edu – US educacional, e.g. conncoll.edu Outros: .gov (governo), .org (organizações sem fins lucrativos), …
 – geralmente mas não necessariamente USA. .net (ISP, network providers) .edu – US educacional, e.g. conncoll.edu. Outros: .gov (governo), .org (organizações sem fins lucrativos), …")
24
Top-Level Domains – código do país (ccTLD)
Alguns dos mais comuns

25
Web log: Name, Login - Name: - Login:
nome do usuário remoto (normalmente omitido e trocado por um traço “-”) - Login: Login do usuário remoto (também é normalmente omitido e trocado por um traço “-”)
 - Login: Login do usuário remoto (também é normalmente omitido e trocado por um traço - )")
26
Web log: Date/Time/TZ [16/Nov/2005:16:32:50 -0500] Date: Time:
HH:MM:SS Time Zone: (+|-)HH00 relativo ao GMT Date: DD/MM/AAAA
![Web log: Date/Time/TZ [16/Nov/2005:16:32: ] Date: Time:](http://slideplayer.com.br/slide/335767/1/images/26/Web+log%3A+Date%2FTime%2FTZ+%5B16%2FNov%2F2005%3A16%3A32%3A+%5D+Date%3A+Time%3A.jpg "HH:MM:SS. Time Zone: (+|-)HH00. relativo ao GMT. Date: DD/MM/AAAA.")
27
Web log: Request "GET /jobs/ HTTP/1.1" GET HEAD POST OPTIONS …
Method: GET HEAD POST OPTIONS … Protocolo HTTP: e.g. HTTP/1.0 or HTTP/1.1 URL: Relativo ao domínio Nota: a requisição é armazenada como é enviada, assim, pode conter erros, falhas, e qualquer tipo de coisa estranha.

28
Web log: Status code 200 Status (Response) code. Os mais importantes são: 200 – OK (é o mais frequente, ainda bem!) 206 – acesso parcial 301 – redirecionamento permanente 302 – redirecionamento temporário 304 – não modificado 404 – não encontrado …

29
Web log: Object size 15140 O tamanho do objeto retornado ao cliente (em bytes) Pode ser “-” se o código de status for 304
 Pode ser - se o código de status for 304.")
30
Web log: Referrer or+data+mining&hl=en&lr=&start=10&sa =N URL que da qual o visitante veio (neste exemplo é uma query do Google: “salary for data mining”, 2a. Página de resutados– começando de 10) Também pode ser uma página estática, interna, externa ou “-” no caso de uma requisição direta (bookmark, por exemplo) Esta é uma informação valiosa
 Também pode ser uma página estática, interna, externa ou - no caso. de uma requisição direta (bookmark, por exemplo) Esta é uma informação valiosa.")
31
Web log: User agent "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR )" User agent (browser) Por razões históricas, quase todos os browsers começam com Mozilla Em muitos casos pode-se ter informações adicionais: Browser type, version : MSIE Internet Explorer 6.0 OS: Windows NT 5.1 (XP SP2) with .NET Framework 1.1 installed
 Por razões históricas, quase todos os browsers começam com Mozilla. Em muitos casos pode-se ter informações adicionais: Browser type, version : MSIE Internet Explorer 6.0. OS: Windows NT 5.1 (XP SP2) with .NET Framework 1.1 installed.")
32
Programas para análise de Web Log
Free Analog, awstats, webalizer Google analytics (ver Comerciais WebTrends, WebSideStory, …

33
Programas para análise de Web Log
Podem fazer análises e emitir relatórios como por exemplo: lista de IPs conectados a um website “pie chart” detalhando quais arquivos foram acessados com mais frequência, e muitos outros

34
Itens identificados a partir dos dados coletados
Usuário Click-streams – seqüência de requisições de acessos a páginas. Os dados disponíveis pelo servidor nem sempre fornece informação para reconstruir um click-stream completo para um site Visões de páginas – uma única ação do usuário e pode consistir de vários arquivos: frames, gráficos, scripts. O usuário requer uma “web-page” e não cada um dos componentes.

35
Sessões – click-stream de páginas para um único usuário por toda a web
Sessões – click-stream de páginas para um único usuário por toda a web. Tipicamente, apenas a parte de cada sessão de usuário acessando um site específico pode ser usada para análise, pois informações de acesso não são públicas.

36
Visita ou sessão do servidor – conjunto de acessos a páginas em uma sessão de usuário para um web site em particular. Um conjunto de visitas é a entrada necessária para qualquer ferramenta de análise de uso ou de mineração de dados. Episódios – subconjunto de uma sessão de usuário ou de servidor que tem significado semântico.

37
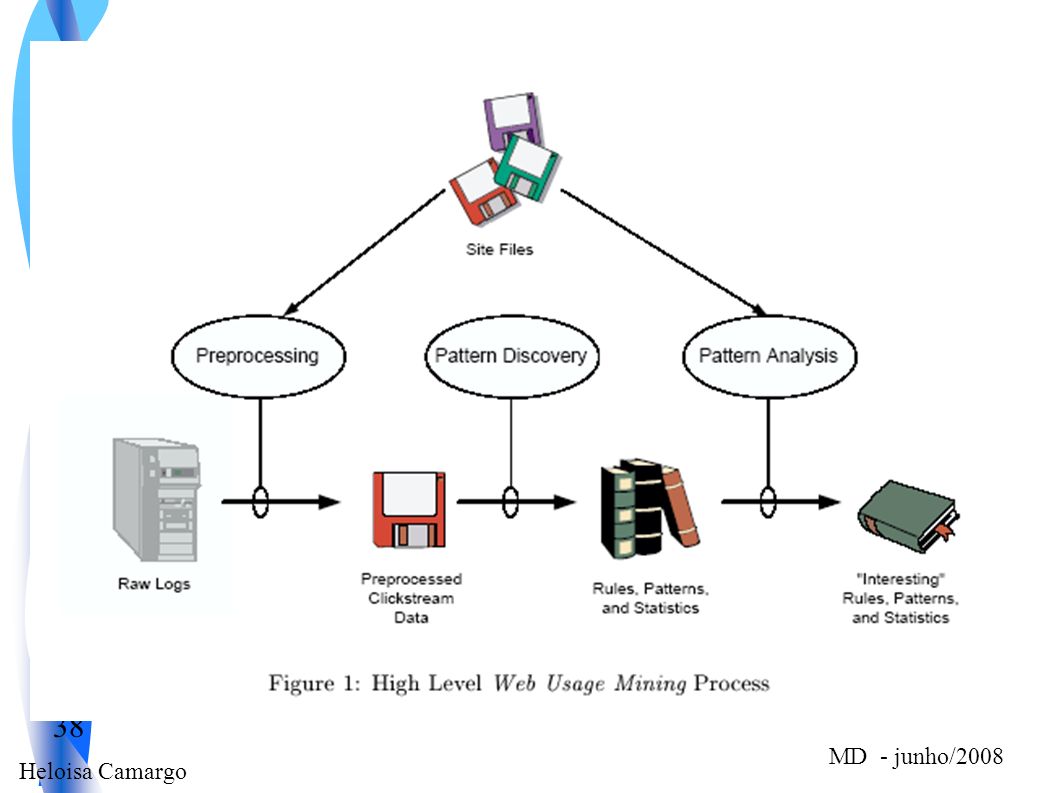
Processo de Web usage mining
Pré-processamento Descoberta de Padrões Análise de Padrões

39
Processo de Web Usage Mining
Pré-processamento Consiste em converter os dados disponíveis nas várias fontes de dados identificando itens necessários para a descoberta de padrões. Considerada a etapa mais difícil em Web usage mining devido aos dados disponíveis não serem completos

40
Pré-processamento Identificar: Usando: Usuários Sessões do servidor
Endereço de IP Agente Cadeia de requisições (click-streams)
")
41
Identificação de usuários
Problemas: IP único / Múltiplas sessões de servidor Um proxy pode ter vários usuários acessando um Web site, no mesmo período de tempo – registros do usuário não serão sequenciais nem no tempo correto. Múltiplos IPs / Sessão de servidor única por motivo de segurança, o provedor pode atribuir aleatoriamente um entre vários endereços de IP a cada requisição de um usuário.

42
Múltiplos IP / Usuário único
um usuário que acessa a Web de máquinas diferentes terá IPs diferentes a cada sessão, dificultando registro de visitas repetidas do mesmo usuário. Múltiplos agentes / Usuário único o usuário pode usar diferentes browsers, de uma mesma máquina, pode parecer mais de um usuário.

43
Exemplo- web server log

44
Identificação de usuários
Soluções: usar Cookies logins IP/agentes/caminhos

45
Identificação de sessões
(depois de identificados cada usuário) Dividir o click-stream de cada usuário em sessões Dificuldades: saber quando um usuário saiu de um website Requisições de outros websites não estão disponíveis Usar intervalo de tempo
 Dividir o click-stream de cada usuário em sessões. Dificuldades: saber quando um usuário saiu de um website. Requisições de outros websites não estão disponíveis. Usar intervalo de tempo.")
46
Inferir referências a páginas em cache
Exige monitoramento de uso do lado do cliente O campo de referência pode ser usado para detectar quando paginas em cache foram vistas

47
Referência a páginas com cópias locais

48
A-B-F-O-F-B-G L-R A-B-A-C-J
Exemplo IP é responsável por 3 sessões IPs e são responsáveis por uma sessão. Usando informações de referência e agente, linhas 1 a 11 podem ser divididas em: A-B-F-O-G L-R A-B-C-J Complementando os caminhos seriam adicionadas páginas: A-B-F-O-F-B-G L-R A-B-A-C-J

49
Registros de tempos de acesso errados no servidor
Tempo de acesso real

50
Visitas a páginas não registradas no sevidor

51
Detecção de robots e filtragem
Web robots são programas que percorrem automaticamente a estrutura de hyperlinks para localizar e recuperar informações. Porque distinguir: Recuperam informação não autorizada Sobrecarga de tráfego Dificultam o acompanhamento de clik-streams

52
Identificação de transações
Depois de identificadas as sessões, transações devem ser inferidas Possível critério: transação é um caminho dentro de uma sessão, terminando em uma página de conteúdo Páginas devem estar classificadas em : navegação e conteúdo

53
Descoberta de padrões Algoritmos e métodos de mineração de dados são aplicados aos dados obtidos da web Análises estatísticas Método mais comum Análises estatísticas descritivas: média, frequência, mediana..) Variáveis: visões de páginas, tempo de permanência, comprimento do caminho de navegação. Utilidade: melhorar desempenho do sistema, melhorar a segurança, facilitar tarefas de modificação do site, apoiar decisões de mercado
 Variáveis: visões de páginas, tempo de permanência, comprimento do caminho de navegação. Utilidade: melhorar desempenho do sistema, melhorar a segurança, facilitar tarefas de modificação do site, apoiar decisões de mercado.")
54
Regras de Associação Características:
Pode relacionar páginas que são acessadas com mais frequência em uma mesma sessão. Podem não estar relacionadas por um link Exemplo: relação entre usuários que visitaram uma página de produtos eletrônicos e aqueles que visitaram uma página de equipamentos esportivos

55
Regras de Associação Utilidade: Aplicações de negócios e comércio
Reestruturação de web sites Pré-recuperação de documentos para reduzir a latência percebida pelo usuário para carregar página de um site remoto

56
Exemplos 60% dos clientes que acessaram /products também acessaram /products/software/webminer.htm 30% dos clientes que acessaram /special- offer.htm submeteram um pedido on-line para /products/software

57
Agrupamento Características Utilidade:
Grupos de usuários: identifica grupos de usuários com padrões de navegação semelhantes Grupos de páginas: identifica grupos de páginas tendo conteúdo semelhante Utilidade: Inferir dados demográficos para segmentação de mercado em e-commerce Personalização Sites de busca Provedores de assistência na web

58
Agrupamento Páginas podem ser criadas para sugerir hyperlinks para o usuário de acordo com as consultas do usuário ou históricos de necessidades de informação

59
Classificação Características: Utilidade:
Identifica atributos que melhor descrevem as características de uma dada classe Exemplo: 30% dos usuários que compraram alguma coisa no setor Produto/Musica estão na faixa de anos e moram na região sudeste. Utilidade: Permite define perfis de usuários que pertencem a uma classe ou categoria

60
Exemplos – agrupamento e classificação
Clientes que frequentemente acessam /products/software.webminer.htm tendem a ser de instituições de ensino Clientes que fizeram pedido on-line para software tendem a ser estudantes na faixa etária de e moram nos EUA 75% dos clientes que fizeram download de softwares de products/software/demos visitam entre 7 e 11 pm nos finais de semana

61
Análise de Padrões Filtra as regras ou padrões que não tem utilidade

Apresentações semelhantes




. Nenhuns direitos reservados, excepto para fins comerciais. Por favor, não coloque.>")








 2.Comparação.>")


 BREVE HISTÓRICO CARACTERÍSTICAS CONCEITOS DE PROGRAMAÇÃO ORIENTADA A OBJETOS MODELAGEM DE ANÁLISE E DE.>")


 –>")
