Carregar apresentação
A apresentação está carregando. Por favor, espere

1
cURSO Engenharia Informática 1º Semestre
Desenho de Sistemas Informáticos Docente: Carlos Alberto Messani 2015

2
Apresentação O Docente
Carlos Alberto Messani Graduado em Ciência da Computação (IMES/BRASIL) Mestre em Gestão de Redes de Telecomunicações (PUC/BRASIL) Linha de pesquisa: Redes Ópticas (Criptografia em redes ópticas) Artigos publicados em revistas técnicas/Científicas Internacionais
 Mestre em Gestão de Redes de Telecomunicações (PUC/BRASIL) Linha de pesquisa: Redes Ópticas (Criptografia em redes ópticas) Artigos publicados em revistas técnicas/Científicas Internacionais.")
3
Apresentação O Docente
Artigos publicados em revistas técnicas/Científicas Internacionais Título: All-Optical Narrowband Spectral Slicing Encryption with Supergaussian Filter. Evento: ITS International Telecommunications Symposium (ITS) Título: All-Optical Phase and Delay Spectral Encoding of Signals with Advanced Modulation Formats. Evento: ICTON (15th International Conference on Transparent Optical Networks, 2014). Título: A New All-Optical Cryptography Technique Applied To Wdm-Compatible Dpsk Signals. Evento: ICTON (15th International Conference on Transparent Optical Networks, 2013).
 Título: All-Optical Phase and Delay Spectral Encoding of Signals with Advanced Modulation Formats. Evento: ICTON (15th International Conference on Transparent Optical Networks, 2014). Título: A New All-Optical Cryptography Technique Applied To Wdm-Compatible Dpsk Signals. Evento: ICTON (15th International Conference on Transparent Optical Networks, 2013).")
4
Apresentação O Docente
Título: Transmission of Encrypted Optical Signals in a metropolitan WDM compatible TON with Differential Phase-shift Keying Modulation. Evento: IMOC (International Microwave and Optoelectronics Conference, 2013, Rio de Janeiro. Evento conjunto do 15º SBMO Simpósio Brasileiro de Micro-ondas e Optoeletrônica e 10º CBMag Congresso Brasileiro de Eletromagnetismo, 2013.) Título: All-Optical Cryptography through Spectral Amplitude and Delay Encoding. Evento: JMO (Journal of Microwaves, Optoelectronics and Electromagnetic Applications, 2013.)
 Título: All-Optical Cryptography through Spectral Amplitude and Delay Encoding. Evento: JMO (Journal of Microwaves, Optoelectronics and Electromagnetic Applications, 2013.)")
5
Avaliação Prova Trabalhos Listas de exercícios Nota 70% Trabalhos 20%

6
Dúvidas? Senão, Boa Sorte!

7
DESENHO DE SISTEMAS INFORMÁTICOS
Introdução

8
Objectivos da disciplina
Capacitar o estudante para: Reconhecer os conceitos básicos de desenho de software Descrever problemas de desenho através de seus elementos fundamentais

9
Objectivos da disciplina
Identificar princípios de desenho de software e explicar seus benefícios Diferenciar desenho de baixo-nível (detalhado) de desenho de alto-nível (arquitetural) e saber quando aplicar cada um
 de desenho de alto-nível (arquitetural) e saber quando aplicar cada um.")
10
Extração, Transformação e Carga (Extract, Transform, Load – ETL)
Conceitos O processo de ETL (Extract, Transform and Load) destina-se à extração, transformação e carga dos dados de uma ou mais bases de dados de origem para uma ou mais bases de dados de destino (Data Warehouse). O ETL envolve: A extração de dados de fontes externas; A transformação dos mesmos para atender às necessidades de negócios e A carga dos mesmos no Armazém de Dados (Data Warehouse, DW).
 destina-se à extração, transformação e carga dos dados de uma ou mais bases de dados de origem para uma ou mais bases de dados de destino (Data Warehouse). O ETL envolve: A extração de dados de fontes externas; A transformação dos mesmos para atender às necessidades de negócios e. A carga dos mesmos no Armazém de Dados (Data Warehouse, DW).")
11
ETL- EXTRAÇÃO DOS DADOS
Conceitos A extração é a primeira tarefa que deve ser realizada durante o processo de ETL, é nela onde são extraídas as informações relevantes dos OLTPs (Online Transaction Processing ou Processamento de Transações em Tempo Real) para posteriormente serem transformadas e carregadas para o DW. { A conversão é necessária devido a heterogeneidade existe nas informações oriundas desses sistemas| “Tarefa mais simples e demorada no processo de ETL”}
 para posteriormente serem transformadas e carregadas para o DW. { A conversão é necessária devido a heterogeneidade existe nas informações oriundas desses sistemas| Tarefa mais simples e demorada no processo de ETL }")
12
ETL- EXTRAÇÃO DOS DADOS
Processo de ETL através de diferentes origens de dados

13
ETL- EXTRAÇÃO DOS DADOS
Conceitos Segundo (Lane, 2005), o método de extração dos dados pode ser Lógico ou Físico. A Extração Lógica; Total: A extração dos dados é feita de modo completo, ignorando as alterações dos dados nas fontes desde a última extração. Incremental: Este método extrai apenas as alterações ocorridas nos dados de origem desde a última coleta.
, o método de extração dos dados pode ser Lógico ou Físico. A Extração Lógica; Total: A extração dos dados é feita de modo completo, ignorando as alterações dos dados nas fontes desde a última extração. Incremental: Este método extrai apenas as alterações ocorridas nos dados de origem desde a última coleta.")
14
ETL- EXTRAÇÃO DOS DADOS
Conceitos A Extração Física: Os dados podem ser fisicamente extraídos por dois mecanismos. Extração Online: Os dados são extraídos diretamente da fonte para processamento na Staging Area, ou seja, os dados são extraídos diretamente do sistema fonte (Lane (2005) .
 .")
15
ETL- EXTRAÇÃO DOS DADOS
Conceitos Extração Offline: Os dados são obtidos a partir de uma área externa, que mantém a cópia dos dados de origem. Neste caso, não é necessário um sistema intermediário para fazer a coleta. Exemplos de fontes externas: Flat files; Dump files; Logs;

16
ETL- TRANSFORMAÇÃO DOS DADOS
Conceitos A Transformação dos dados é a fase subsequente à sua extração. Esta fase não só transforma os dados, mas também realiza a limpeza dos mesmos. A correção de erros de digitação, a descoberta de violações de integridade, a substituição de caracteres desconhecidos, a padronização de abreviações podem ser exemplos desta limpeza.

17
ETL- TRANSFORMAÇÃO DOS DADOS
No processo de transformação de dados, são aplicadas uma série de regras ou funções aos dados extraídos, afim de facilitar a manipulação de algumas fontes. Em alguns casos, as seguintes transformações podem ser necessárias: Seleccionar apenas determinadas colunas para carregar (ou nenhuma delas).
.")
18
ETL- TRANSFORMAÇÃO DOS DADOS
2 - Tradução de valores codificados (se o sistema de origem armazena 1 para sexo masculino e 2 para feminino, mas o data warehouse armazena M para masculino e F para feminino), também conhecido como limpeza de dados. 3 - Junção de dados provenientes de diversas fontes. 4 - Resumo de várias linhas de dados (total de vendas para cada loja e para cada região).
, também conhecido como limpeza de dados. 3 - Junção de dados provenientes de diversas fontes. 4 - Resumo de várias linhas de dados (total de vendas para cada loja e para cada região).")
19
ETL- TRANSFORMAÇÃO DOS DADOS
5 - Transposição ou rotação (transformando múltiplas colunas em múltiplas linhas ou vice-versa). 6 - Derivação de um novo valor calculado (montante_vendas = qtde * preço_unitário, por exemplo). ... Entre outros.
. 6 - Derivação de um novo valor calculado (montante_vendas = qtde * preço_unitário, por exemplo). ... Entre outros.")
20
ETL- TRANSFORMAÇÃO DOS DADOS
Produtos Angola USA Br C o n v e r s ã Peso (lb) Peso (kg) Peso (oz) Peso (gr) Data Warehouse
 Peso (kg) Peso (oz) Peso (gr) Data Warehouse.")
21
ETL- CARGA DOS DADOS O Processo de Carga ocorre posteriormente ao de transformação. É onde os dados são carregados para o DW. A duração deste processo depende da organização. Oracle Extrair Transformar Carregar Dados operacionais Dados externos Limpar Reconciliar Aprimorar Sumarizar Agregar Organizar Combinar várias fontes Popular sob demanda SQL Server Data Warehouse DB2 InterBase Arquivos

23
Ferramentas ETL Ferramentas ETL são aplicações de software cuja função, de modo geral, é extrair dados de diversas fontes, transformar esses dados para garantir a padronização e consistência das informações para posteriormente carregá-las para um ambiente de consulta e análise (Data Werehouse). Tarefa para casa Liste algumas ferramentas ETL, separando as open source das pagas. Descreva cada uma delas.
. Tarefa para casa. Liste algumas ferramentas ETL, separando as open source das pagas. Descreva cada uma delas.")
24
Para leitura e/ou pesquisarem
Alguns conceitos Para leitura e/ou pesquisarem

25
OLTP (Online Transaction Processing ou Processamento De Transações em Tempo Real)
Conceitos São sistemas que se encarregam de registrar todas as transações contidas em uma determinada operação organizacional. Por exemplo: sistema de transações bancárias que registra todas as operações efetuadas em um banco, caixas de multibanco, reservas de viagens ou hotel on-line, Cartões de Crédito.

26
OLTP (Online Transaction Processing ou Processamento De Transações em Tempo Real)
Processamento Operacional (OLTP) Funcionalidades do negócio Processamento de transações: inserção, atualização, consulta e deleção Reflete valor corrente, não-redundante e actualizável Altamente voláteis É o processamento realizado por sistemas computacionais que têm a finalidade de capturar as transações dos negócios do empreendimento e dar suporte as atividades diárias de uma empresa ou corporação. OLTP (On-Line Transaction Processing - Processamento de Transações On-Line) As transações realizadas normalmente afetam um único registro de cada vez. Como os registros são atualizados continuamente, os bancos de dados operacionais armazenam pouca quantidade de dados históricos. Em conseqüência, diz-se que os dados operacionais são altamente voláteis.
 Funcionalidades do negócio. Processamento de transações: inserção, atualização, consulta e deleção. Reflete valor corrente, não-redundante e actualizável. Altamente voláteis. É o processamento realizado por sistemas computacionais que têm a finalidade de capturar as transações dos negócios do empreendimento e dar suporte as atividades diárias de uma empresa. ou corporação. OLTP (On-Line Transaction Processing - Processamento de Transações On-Line) As transações realizadas normalmente afetam um único registro de cada vez. Como os registros são atualizados continuamente, os bancos de dados operacionais armazenam pouca quantidade de dados históricos. Em conseqüência, diz-se que os dados operacionais são altamente voláteis.")
27
Processamento Analítico (OLAP)
Conceitos OLAP é um conceito de interface com o usuário que proporciona a capacidade de ter ideias sobre os dados, permitindo analisá los profundamente em diversos ângulos. As funções básicas do OLAP são: Visualização multidimensional dos dados; Exploração; Rotação; Vários modos de visualização. É o processamento realizado para dar suporte à tomada de decisão. Processamento analítico, também chamado de informacional ou processamento de suporte à decisão, permite ao usuário analisar uma grande quantidade de dados, normalmente históricos, verificando problemas e situações, de modo a identificar perfis, tendências e padrões. Os sistemas analíticos não atualizam continuamente as informações, mas as mantêm como um registro específico do tempo, chamado também de instantâneos de dados (snapshot of data), acarretando, normalmente, o armazenamento de grande quantidade de dados históricos. Com isso, os dados analíticos adquirem a característica de não serem voláteis. Os bancos de dados correspondentes, ao nível de usuário, são ditos somente leitura (read-only), ou seja, somente é permitido ao usuário a realização de consultas sobre os dados e não a sua atualização [POE98], servindo basicamente para a geração de relatórios [KIM98b]. Dessa forma, dependendo do projeto e o nível de detalhes do banco de dados (dados históricos diários, semanais, mensais e anuais, dentre outros), é possível analisar uma grande massa de dados e obter informações que auxiliem a comunidade de gerentes, administradores e executivos na tomada de decisões. Os bancos de dados analíticos possuem, ainda, a grande vantagem de poderem se tornar integradores das informações provenientes dos diversos sistemas operacionais, possibilitando uma visão global de toda a organização.
, acarretando, normalmente, o armazenamento de grande quantidade de dados históricos. Com isso, os dados analíticos adquirem a característica de não serem voláteis. Os bancos de dados. correspondentes, ao nível de usuário, são ditos somente leitura (read-only), ou seja, somente é permitido ao usuário a realização de consultas sobre os dados e não a sua atualização [POE98], servindo basicamente para a geração de relatórios [KIM98b]. Dessa forma, dependendo do projeto e o nível de detalhes do banco de dados (dados históricos diários, semanais, mensais e anuais, dentre outros), é possível analisar uma grande massa de dados e obter informações que auxiliem a comunidade de gerentes, administradores e executivos na tomada de decisões. Os bancos de dados analíticos possuem, ainda, a grande vantagem de poderem se tornar integradores das informações provenientes dos diversos sistemas operacionais, possibilitando uma. visão global de toda a organização.")
28
Processamento Analítico (OLAP)
Conceitos Processamento Analítico (OLAP) Suporte à tomada de decisão Dados históricos, não voláteis, ready-only Integram informações de diversos sistemas operacionais Permitem identificações de perfis, tendências e padrões { usado para consultar dados em um DW} É o processamento realizado para dar suporte à tomada de decisão. Processamento analítico, também chamado de informacional ou processamento de suporte à decisão, permite ao usuário analisar uma grande quantidade de dados, normalmente históricos, verificando problemas e situações, de modo a identificar perfis, tendências e padrões. Os sistemas analíticos não atualizam continuamente as informações, mas as mantêm como um registro específico do tempo, chamado também de instantâneos de dados (snapshot of data), acarretando, normalmente, o armazenamento de grande quantidade de dados históricos. Com isso, os dados analíticos adquirem a característica de não serem voláteis. Os bancos de dados correspondentes, ao nível de usuário, são ditos somente leitura (read-only), ou seja, somente é permitido ao usuário a realização de consultas sobre os dados e não a sua atualização [POE98], servindo basicamente para a geração de relatórios [KIM98b]. Dessa forma, dependendo do projeto e o nível de detalhes do banco de dados (dados históricos diários, semanais, mensais e anuais, dentre outros), é possível analisar uma grande massa de dados e obter informações que auxiliem a comunidade de gerentes, administradores e executivos na tomada de decisões. Os bancos de dados analíticos possuem, ainda, a grande vantagem de poderem se tornar integradores das informações provenientes dos diversos sistemas operacionais, possibilitando uma visão global de toda a organização. Centro de Informática - UFPE
 Suporte à tomada de decisão. Dados históricos, não voláteis, ready-only. Integram informações de diversos sistemas operacionais. Permitem identificações de perfis, tendências e padrões. { usado para consultar dados em um DW} É o processamento realizado para dar suporte à tomada de decisão. Processamento analítico, também chamado de informacional ou processamento de suporte à decisão, permite ao usuário analisar uma grande quantidade de dados, normalmente históricos, verificando problemas e situações, de modo a identificar perfis, tendências e padrões. Os sistemas analíticos não atualizam continuamente as informações, mas as mantêm como um registro específico do tempo, chamado também de instantâneos de dados (snapshot of data), acarretando, normalmente, o armazenamento de grande quantidade de dados históricos. Com isso, os dados analíticos adquirem a característica de não serem voláteis. Os bancos de dados. correspondentes, ao nível de usuário, são ditos somente leitura (read-only), ou seja, somente é permitido ao usuário a realização de consultas sobre os dados e não a sua atualização [POE98], servindo basicamente para a geração de relatórios [KIM98b]. Dessa forma, dependendo do projeto e o nível de detalhes do banco de dados (dados históricos diários, semanais, mensais e anuais, dentre outros), é possível analisar uma grande massa de dados e obter informações que auxiliem a comunidade de gerentes, administradores e executivos na tomada de decisões. Os bancos de dados analíticos possuem, ainda, a grande vantagem de poderem se tornar integradores das informações provenientes dos diversos sistemas operacionais, possibilitando uma. visão global de toda a organização. Centro de Informática - UFPE.")
29
Processamento Analítico (OLAP)
Conceitos O OLAP e o Data Warehouse são destinados a trabalharem juntos, enquanto o DW armazena as informações de forma eficiente, o OLAP deve recuperál com a mesma eficiência,porém com muita rapidez. As duas te cnologias se complementam, ao ponto de que um Data Warehouse para ser bem sucedido, já na sua concepção, dev e levar em consideração o que se deseja apresentar na interface OLAP. É o processamento realizado para dar suporte à tomada de decisão. Processamento analítico, também chamado de informacional ou processamento de suporte à decisão, permite ao usuário analisar uma grande quantidade de dados, normalmente históricos, verificando problemas e situações, de modo a identificar perfis, tendências e padrões. Os sistemas analíticos não atualizam continuamente as informações, mas as mantêm como um registro específico do tempo, chamado também de instantâneos de dados (snapshot of data), acarretando, normalmente, o armazenamento de grande quantidade de dados históricos. Com isso, os dados analíticos adquirem a característica de não serem voláteis. Os bancos de dados correspondentes, ao nível de usuário, são ditos somente leitura (read-only), ou seja, somente é permitido ao usuário a realização de consultas sobre os dados e não a sua atualização [POE98], servindo basicamente para a geração de relatórios [KIM98b]. Dessa forma, dependendo do projeto e o nível de detalhes do banco de dados (dados históricos diários, semanais, mensais e anuais, dentre outros), é possível analisar uma grande massa de dados e obter informações que auxiliem a comunidade de gerentes, administradores e executivos na tomada de decisões. Os bancos de dados analíticos possuem, ainda, a grande vantagem de poderem se tornar integradores das informações provenientes dos diversos sistemas operacionais, possibilitando uma visão global de toda a organização.
, acarretando, normalmente, o armazenamento de grande quantidade de dados históricos. Com isso, os dados analíticos adquirem a característica de não serem voláteis. Os bancos de dados. correspondentes, ao nível de usuário, são ditos somente leitura (read-only), ou seja, somente é permitido ao usuário a realização de consultas sobre os dados e não a sua atualização [POE98], servindo basicamente para a geração de relatórios [KIM98b]. Dessa forma, dependendo do projeto e o nível de detalhes do banco de dados (dados históricos diários, semanais, mensais e anuais, dentre outros), é possível analisar uma grande massa de dados e obter informações que auxiliem a comunidade de gerentes, administradores e executivos na tomada de decisões. Os bancos de dados analíticos possuem, ainda, a grande vantagem de poderem se tornar integradores das informações provenientes dos diversos sistemas operacionais, possibilitando uma. visão global de toda a organização.")
30
Processamento Analítico (OLAP)
Conceitos A aplicação OLAP tem como função a análise e consolidação de dados, pois é o processamento analítico online dos dados. Tem capacidade de visualizações das informações a partir de perspectivas diferentes, enquanto mantém uma estrutura de dados adequada e eficiente. A visualização é realizada em dados agregados, e não em dados operacionais porque a aplicação OLAP tem por finalidade apoiar os usuários finais a tomar decisões estratégicas. É o processamento realizado para dar suporte à tomada de decisão. Processamento analítico, também chamado de informacional ou processamento de suporte à decisão, permite ao usuário analisar uma grande quantidade de dados, normalmente históricos, verificando problemas e situações, de modo a identificar perfis, tendências e padrões. Os sistemas analíticos não atualizam continuamente as informações, mas as mantêm como um registro específico do tempo, chamado também de instantâneos de dados (snapshot of data), acarretando, normalmente, o armazenamento de grande quantidade de dados históricos. Com isso, os dados analíticos adquirem a característica de não serem voláteis. Os bancos de dados correspondentes, ao nível de usuário, são ditos somente leitura (read-only), ou seja, somente é permitido ao usuário a realização de consultas sobre os dados e não a sua atualização [POE98], servindo basicamente para a geração de relatórios [KIM98b]. Dessa forma, dependendo do projeto e o nível de detalhes do banco de dados (dados históricos diários, semanais, mensais e anuais, dentre outros), é possível analisar uma grande massa de dados e obter informações que auxiliem a comunidade de gerentes, administradores e executivos na tomada de decisões. Os bancos de dados analíticos possuem, ainda, a grande vantagem de poderem se tornar integradores das informações provenientes dos diversos sistemas operacionais, possibilitando uma visão global de toda a organização.
, acarretando, normalmente, o armazenamento de grande quantidade de dados históricos. Com isso, os dados analíticos adquirem a característica de não serem voláteis. Os bancos de dados. correspondentes, ao nível de usuário, são ditos somente leitura (read-only), ou seja, somente é permitido ao usuário a realização de consultas sobre os dados e não a sua atualização [POE98], servindo basicamente para a geração de relatórios [KIM98b]. Dessa forma, dependendo do projeto e o nível de detalhes do banco de dados (dados históricos diários, semanais, mensais e anuais, dentre outros), é possível analisar uma grande massa de dados e obter informações que auxiliem a comunidade de gerentes, administradores e executivos na tomada de decisões. Os bancos de dados analíticos possuem, ainda, a grande vantagem de poderem se tornar integradores das informações provenientes dos diversos sistemas operacionais, possibilitando uma. visão global de toda a organização.")
31
Processamento Analítico (OLAP)
Conceitos O OLAP é uma interface com o usuário e não uma forma de armazenamento de dados, porém, utiliza- se do armazenamento para poder apresentar as informações. Os métodos de armazenamento são: ROLAP (OLAP Relacional): Os dados são armazenados de forma relacional. MOLAP (OLAP Multidimensional): Os dados são armazenados de forma multidimensional. É o processamento realizado para dar suporte à tomada de decisão. Processamento analítico, também chamado de informacional ou processamento de suporte à decisão, permite ao usuário analisar uma grande quantidade de dados, normalmente históricos, verificando problemas e situações, de modo a identificar perfis, tendências e padrões. Os sistemas analíticos não atualizam continuamente as informações, mas as mantêm como um registro específico do tempo, chamado também de instantâneos de dados (snapshot of data), acarretando, normalmente, o armazenamento de grande quantidade de dados históricos. Com isso, os dados analíticos adquirem a característica de não serem voláteis. Os bancos de dados correspondentes, ao nível de usuário, são ditos somente leitura (read-only), ou seja, somente é permitido ao usuário a realização de consultas sobre os dados e não a sua atualização [POE98], servindo basicamente para a geração de relatórios [KIM98b]. Dessa forma, dependendo do projeto e o nível de detalhes do banco de dados (dados históricos diários, semanais, mensais e anuais, dentre outros), é possível analisar uma grande massa de dados e obter informações que auxiliem a comunidade de gerentes, administradores e executivos na tomada de decisões. Os bancos de dados analíticos possuem, ainda, a grande vantagem de poderem se tornar integradores das informações provenientes dos diversos sistemas operacionais, possibilitando uma visão global de toda a organização.
: Os dados são armazenados de forma relacional. MOLAP (OLAP Multidimensional): Os dados são armazenados de forma multidimensional. É o processamento realizado para dar suporte à tomada de decisão. Processamento analítico, também chamado de informacional ou processamento de suporte à decisão, permite ao usuário analisar uma grande quantidade de dados, normalmente históricos, verificando problemas e situações, de modo a identificar perfis, tendências e padrões. Os sistemas analíticos não atualizam continuamente as informações, mas as mantêm como um registro específico do tempo, chamado também de instantâneos de dados (snapshot of data), acarretando, normalmente, o armazenamento de grande quantidade de dados históricos. Com isso, os dados analíticos adquirem a característica de não serem voláteis. Os bancos de dados. correspondentes, ao nível de usuário, são ditos somente leitura (read-only), ou seja, somente é permitido ao usuário a realização de consultas sobre os dados e não a sua atualização [POE98], servindo basicamente para a geração de relatórios [KIM98b]. Dessa forma, dependendo do projeto e o nível de detalhes do banco de dados (dados históricos diários, semanais, mensais e anuais, dentre outros), é possível analisar uma grande massa de dados e obter informações que auxiliem a comunidade de gerentes, administradores e executivos na tomada de decisões. Os bancos de dados analíticos possuem, ainda, a grande vantagem de poderem se tornar integradores das informações provenientes dos diversos sistemas operacionais, possibilitando uma. visão global de toda a organização.")
32
Processamento Analítico (OLAP)
Conceitos HOLAP (OLAP Híbrido): Uma combinação dos métodos ROLAP e MOLAP DOLAP (OLAP Desktop): conjunto de dados multidimensionais deve ser criado no servidor e transferido para o desktop. Permite portabilidade aos usuários OLAP que não possuem acesso direto ao servidor É o processamento realizado para dar suporte à tomada de decisão. Processamento analítico, também chamado de informacional ou processamento de suporte à decisão, permite ao usuário analisar uma grande quantidade de dados, normalmente históricos, verificando problemas e situações, de modo a identificar perfis, tendências e padrões. Os sistemas analíticos não atualizam continuamente as informações, mas as mantêm como um registro específico do tempo, chamado também de instantâneos de dados (snapshot of data), acarretando, normalmente, o armazenamento de grande quantidade de dados históricos. Com isso, os dados analíticos adquirem a característica de não serem voláteis. Os bancos de dados correspondentes, ao nível de usuário, são ditos somente leitura (read-only), ou seja, somente é permitido ao usuário a realização de consultas sobre os dados e não a sua atualização [POE98], servindo basicamente para a geração de relatórios [KIM98b]. Dessa forma, dependendo do projeto e o nível de detalhes do banco de dados (dados históricos diários, semanais, mensais e anuais, dentre outros), é possível analisar uma grande massa de dados e obter informações que auxiliem a comunidade de gerentes, administradores e executivos na tomada de decisões. Os bancos de dados analíticos possuem, ainda, a grande vantagem de poderem se tornar integradores das informações provenientes dos diversos sistemas operacionais, possibilitando uma visão global de toda a organização.
: Uma combinação dos métodos ROLAP e MOLAP. DOLAP (OLAP Desktop): conjunto de dados multidimensionais deve ser criado no servidor e transferido para o desktop. Permite portabilidade aos usuários OLAP que não possuem acesso direto ao. servidor. É o processamento realizado para dar suporte à tomada de decisão. Processamento analítico, também chamado de informacional ou processamento de suporte à decisão, permite ao usuário analisar uma grande quantidade de dados, normalmente históricos, verificando problemas e situações, de modo a identificar perfis, tendências e padrões. Os sistemas analíticos não atualizam continuamente as informações, mas as mantêm como um registro específico do tempo, chamado também de instantâneos de dados (snapshot of data), acarretando, normalmente, o armazenamento de grande quantidade de dados históricos. Com isso, os dados analíticos adquirem a característica de não serem voláteis. Os bancos de dados. correspondentes, ao nível de usuário, são ditos somente leitura (read-only), ou seja, somente é permitido ao usuário a realização de consultas sobre os dados e não a sua atualização [POE98], servindo basicamente para a geração de relatórios [KIM98b]. Dessa forma, dependendo do projeto e o nível de detalhes do banco de dados (dados históricos diários, semanais, mensais e anuais, dentre outros), é possível analisar uma grande massa de dados e obter informações que auxiliem a comunidade de gerentes, administradores e executivos na tomada de decisões. Os bancos de dados analíticos possuem, ainda, a grande vantagem de poderem se tornar integradores das informações provenientes dos diversos sistemas operacionais, possibilitando uma. visão global de toda a organização.")
33
Processamento Analítico (OLAP)
Conceitos Os métodos mais comuns de armazenamento de dados utilizados pelos sistema s OLAP são: ROLAP e MOLAP, a única diferença entre eles é a tecnologia de banco de dad os. O ROLAP usa a tecnologia RDBMS (Relational DataBase Management System), na qual o s dados são armazenados em uma série de tabelas e colunas. Enquanto o MOLAP usa a tec nologia MDDB (MultiDimensional Database), onde os dados são armazenados em arrays multidimensionais. É o processamento realizado para dar suporte à tomada de decisão. Processamento analítico, também chamado de informacional ou processamento de suporte à decisão, permite ao usuário analisar uma grande quantidade de dados, normalmente históricos, verificando problemas e situações, de modo a identificar perfis, tendências e padrões. Os sistemas analíticos não atualizam continuamente as informações, mas as mantêm como um registro específico do tempo, chamado também de instantâneos de dados (snapshot of data), acarretando, normalmente, o armazenamento de grande quantidade de dados históricos. Com isso, os dados analíticos adquirem a característica de não serem voláteis. Os bancos de dados correspondentes, ao nível de usuário, são ditos somente leitura (read-only), ou seja, somente é permitido ao usuário a realização de consultas sobre os dados e não a sua atualização [POE98], servindo basicamente para a geração de relatórios [KIM98b]. Dessa forma, dependendo do projeto e o nível de detalhes do banco de dados (dados históricos diários, semanais, mensais e anuais, dentre outros), é possível analisar uma grande massa de dados e obter informações que auxiliem a comunidade de gerentes, administradores e executivos na tomada de decisões. Os bancos de dados analíticos possuem, ainda, a grande vantagem de poderem se tornar integradores das informações provenientes dos diversos sistemas operacionais, possibilitando uma visão global de toda a organização.
, na qual o s dados são. armazenados em uma série de tabelas e colunas. Enquanto o MOLAP usa a tec nologia MDDB. (MultiDimensional Database), onde os dados são armazenados em arrays. multidimensionais. É o processamento realizado para dar suporte à tomada de decisão. Processamento analítico, também chamado de informacional ou processamento de suporte à decisão, permite ao usuário analisar uma grande quantidade de dados, normalmente históricos, verificando problemas e situações, de modo a identificar perfis, tendências e padrões. Os sistemas analíticos não atualizam continuamente as informações, mas as mantêm como um registro específico do tempo, chamado também de instantâneos de dados (snapshot of data), acarretando, normalmente, o armazenamento de grande quantidade de dados históricos. Com isso, os dados analíticos adquirem a característica de não serem voláteis. Os bancos de dados. correspondentes, ao nível de usuário, são ditos somente leitura (read-only), ou seja, somente é permitido ao usuário a realização de consultas sobre os dados e não a sua atualização [POE98], servindo basicamente para a geração de relatórios [KIM98b]. Dessa forma, dependendo do projeto e o nível de detalhes do banco de dados (dados históricos diários, semanais, mensais e anuais, dentre outros), é possível analisar uma grande massa de dados e obter informações que auxiliem a comunidade de gerentes, administradores e executivos na tomada de decisões. Os bancos de dados analíticos possuem, ainda, a grande vantagem de poderem se tornar integradores das informações provenientes dos diversos sistemas operacionais, possibilitando uma. visão global de toda a organização.")
34
Processamento Analítico (OLAP)
Conceitos Os dois fornecem uma base sólida para análise e apresentam tanto vantagens quanto desvantagens. Para se escolher entre os dois métodos deve se levar em consideração os requisitos e a abrangência do aplicativo a ser desenvolvido. ROLAP é mais indicado para DATA WAREHOUSE pelo grande volum e de dados, a necessidade de um maior número de funções e diversas regras de ne gócio a serem aplicadas. É o processamento realizado para dar suporte à tomada de decisão. Processamento analítico, também chamado de informacional ou processamento de suporte à decisão, permite ao usuário analisar uma grande quantidade de dados, normalmente históricos, verificando problemas e situações, de modo a identificar perfis, tendências e padrões. Os sistemas analíticos não atualizam continuamente as informações, mas as mantêm como um registro específico do tempo, chamado também de instantâneos de dados (snapshot of data), acarretando, normalmente, o armazenamento de grande quantidade de dados históricos. Com isso, os dados analíticos adquirem a característica de não serem voláteis. Os bancos de dados correspondentes, ao nível de usuário, são ditos somente leitura (read-only), ou seja, somente é permitido ao usuário a realização de consultas sobre os dados e não a sua atualização [POE98], servindo basicamente para a geração de relatórios [KIM98b]. Dessa forma, dependendo do projeto e o nível de detalhes do banco de dados (dados históricos diários, semanais, mensais e anuais, dentre outros), é possível analisar uma grande massa de dados e obter informações que auxiliem a comunidade de gerentes, administradores e executivos na tomada de decisões. Os bancos de dados analíticos possuem, ainda, a grande vantagem de poderem se tornar integradores das informações provenientes dos diversos sistemas operacionais, possibilitando uma visão global de toda a organização.
, acarretando, normalmente, o armazenamento de grande quantidade de dados históricos. Com isso, os dados analíticos adquirem a característica de não serem voláteis. Os bancos de dados. correspondentes, ao nível de usuário, são ditos somente leitura (read-only), ou seja, somente é permitido ao usuário a realização de consultas sobre os dados e não a sua atualização [POE98], servindo basicamente para a geração de relatórios [KIM98b]. Dessa forma, dependendo do projeto e o nível de detalhes do banco de dados (dados históricos diários, semanais, mensais e anuais, dentre outros), é possível analisar uma grande massa de dados e obter informações que auxiliem a comunidade de gerentes, administradores e executivos na tomada de decisões. Os bancos de dados analíticos possuem, ainda, a grande vantagem de poderem se tornar integradores das informações provenientes dos diversos sistemas operacionais, possibilitando uma. visão global de toda a organização.")
35
Processamento Analítico (OLAP)
Conceitos MOLAP é mais indidado para DATA MARTS, onde os dados são mais específicos e o aplicativo será direcionado na análise com dimensionalidade limitad a e pouco detalhamento das informações. Para se fazer uma comparação básica entre os dois métodos, as regr as mais importantes são desempenho da consulta e desempenho do carregamento. É o processamento realizado para dar suporte à tomada de decisão. Processamento analítico, também chamado de informacional ou processamento de suporte à decisão, permite ao usuário analisar uma grande quantidade de dados, normalmente históricos, verificando problemas e situações, de modo a identificar perfis, tendências e padrões. Os sistemas analíticos não atualizam continuamente as informações, mas as mantêm como um registro específico do tempo, chamado também de instantâneos de dados (snapshot of data), acarretando, normalmente, o armazenamento de grande quantidade de dados históricos. Com isso, os dados analíticos adquirem a característica de não serem voláteis. Os bancos de dados correspondentes, ao nível de usuário, são ditos somente leitura (read-only), ou seja, somente é permitido ao usuário a realização de consultas sobre os dados e não a sua atualização [POE98], servindo basicamente para a geração de relatórios [KIM98b]. Dessa forma, dependendo do projeto e o nível de detalhes do banco de dados (dados históricos diários, semanais, mensais e anuais, dentre outros), é possível analisar uma grande massa de dados e obter informações que auxiliem a comunidade de gerentes, administradores e executivos na tomada de decisões. Os bancos de dados analíticos possuem, ainda, a grande vantagem de poderem se tornar integradores das informações provenientes dos diversos sistemas operacionais, possibilitando uma visão global de toda a organização.
, acarretando, normalmente, o armazenamento de grande quantidade de dados históricos. Com isso, os dados analíticos adquirem a característica de não serem voláteis. Os bancos de dados. correspondentes, ao nível de usuário, são ditos somente leitura (read-only), ou seja, somente é permitido ao usuário a realização de consultas sobre os dados e não a sua atualização [POE98], servindo basicamente para a geração de relatórios [KIM98b]. Dessa forma, dependendo do projeto e o nível de detalhes do banco de dados (dados históricos diários, semanais, mensais e anuais, dentre outros), é possível analisar uma grande massa de dados e obter informações que auxiliem a comunidade de gerentes, administradores e executivos na tomada de decisões. Os bancos de dados analíticos possuem, ainda, a grande vantagem de poderem se tornar integradores das informações provenientes dos diversos sistemas operacionais, possibilitando uma. visão global de toda a organização.")
36
Processamento Analítico (OLAP)
OLTP X OLAP É o processamento realizado para dar suporte à tomada de decisão. Processamento analítico, também chamado de informacional ou processamento de suporte à decisão, permite ao usuário analisar uma grande quantidade de dados, normalmente históricos, verificando problemas e situações, de modo a identificar perfis, tendências e padrões. Os sistemas analíticos não atualizam continuamente as informações, mas as mantêm como um registro específico do tempo, chamado também de instantâneos de dados (snapshot of data), acarretando, normalmente, o armazenamento de grande quantidade de dados históricos. Com isso, os dados analíticos adquirem a característica de não serem voláteis. Os bancos de dados correspondentes, ao nível de usuário, são ditos somente leitura (read-only), ou seja, somente é permitido ao usuário a realização de consultas sobre os dados e não a sua atualização [POE98], servindo basicamente para a geração de relatórios [KIM98b]. Dessa forma, dependendo do projeto e o nível de detalhes do banco de dados (dados históricos diários, semanais, mensais e anuais, dentre outros), é possível analisar uma grande massa de dados e obter informações que auxiliem a comunidade de gerentes, administradores e executivos na tomada de decisões. Os bancos de dados analíticos possuem, ainda, a grande vantagem de poderem se tornar integradores das informações provenientes dos diversos sistemas operacionais, possibilitando uma visão global de toda a organização. Centro de Informática - UFPE
, acarretando, normalmente, o armazenamento de grande quantidade de dados históricos. Com isso, os dados analíticos adquirem a característica de não serem voláteis. Os bancos de dados. correspondentes, ao nível de usuário, são ditos somente leitura (read-only), ou seja, somente é permitido ao usuário a realização de consultas sobre os dados e não a sua atualização [POE98], servindo basicamente para a geração de relatórios [KIM98b]. Dessa forma, dependendo do projeto e o nível de detalhes do banco de dados (dados históricos diários, semanais, mensais e anuais, dentre outros), é possível analisar uma grande massa de dados e obter informações que auxiliem a comunidade de gerentes, administradores e executivos na tomada de decisões. Os bancos de dados analíticos possuem, ainda, a grande vantagem de poderem se tornar integradores das informações provenientes dos diversos sistemas operacionais, possibilitando uma. visão global de toda a organização. Centro de Informática - UFPE.")
37
Processamento Analítico (OLAP)
OLTP X OLAP É o processamento realizado para dar suporte à tomada de decisão. Processamento analítico, também chamado de informacional ou processamento de suporte à decisão, permite ao usuário analisar uma grande quantidade de dados, normalmente históricos, verificando problemas e situações, de modo a identificar perfis, tendências e padrões. Os sistemas analíticos não atualizam continuamente as informações, mas as mantêm como um registro específico do tempo, chamado também de instantâneos de dados (snapshot of data), acarretando, normalmente, o armazenamento de grande quantidade de dados históricos. Com isso, os dados analíticos adquirem a característica de não serem voláteis. Os bancos de dados correspondentes, ao nível de usuário, são ditos somente leitura (read-only), ou seja, somente é permitido ao usuário a realização de consultas sobre os dados e não a sua atualização [POE98], servindo basicamente para a geração de relatórios [KIM98b]. Dessa forma, dependendo do projeto e o nível de detalhes do banco de dados (dados históricos diários, semanais, mensais e anuais, dentre outros), é possível analisar uma grande massa de dados e obter informações que auxiliem a comunidade de gerentes, administradores e executivos na tomada de decisões. Os bancos de dados analíticos possuem, ainda, a grande vantagem de poderem se tornar integradores das informações provenientes dos diversos sistemas operacionais, possibilitando uma visão global de toda a organização.
, acarretando, normalmente, o armazenamento de grande quantidade de dados históricos. Com isso, os dados analíticos adquirem a característica de não serem voláteis. Os bancos de dados. correspondentes, ao nível de usuário, são ditos somente leitura (read-only), ou seja, somente é permitido ao usuário a realização de consultas sobre os dados e não a sua atualização [POE98], servindo basicamente para a geração de relatórios [KIM98b]. Dessa forma, dependendo do projeto e o nível de detalhes do banco de dados (dados históricos diários, semanais, mensais e anuais, dentre outros), é possível analisar uma grande massa de dados e obter informações que auxiliem a comunidade de gerentes, administradores e executivos na tomada de decisões. Os bancos de dados analíticos possuem, ainda, a grande vantagem de poderem se tornar integradores das informações provenientes dos diversos sistemas operacionais, possibilitando uma. visão global de toda a organização.")
38
Data Warehouse Definição I:
“ É uma coleção de dados orientados por assuntos, integrados, variáveis no tempo e não voláteis, para dar suporte ao processo gerencial de tomada de decisão ” [ Inmon ]

39
Data Warehouse Definição II:
“ É um processo em andamento que aglutina dados de fontes heterogêneas, incluindo dados históricos e dados externos para atender às necessidades de consultas estruturadas, relatórios analíticos e de suporte a decisão ” [Harjinder ]

40
Data Warehouse Definição III:
“ É uma coleção de técnicas e tecnologias que juntas disponibilizam um enfoque pragmático e sistemático para tratar com o problema do usuário final de acessar informações que estão distribuídas em vários sistemas da organização ” [ Barquini ]

41
Dados operacionais vs. Data Warehouse

42
Dados operacionais vs. Data Warehouse

43
Componente de um Data Warehouse
Data Warehouse não é o fim, ele é um meio que as empresas dispõem para analisar informações podendo utilizá-las para a melhoria dos processos atuais e futuros Dados Operacionais Dados Externos Qualquer fonte Data Warehouse Qualquer Dado Qualquer acesso Ferramentas de OLAP Aplicativos Ferramentas de consultas (relatórios)
")
44
Data Warehouse- Características
Orientação por assunto Integração Variação no tempo Não volatilidade Localização Credibilidade dos dados Granularidade Metadados

45
Data Warehouse- Características
Orientação por assunto Integração Variação no tempo Não volatilidade Localização Credibilidade dos dados Granularidade Metadados

46
Data Warehouse Características
Orientação por assunto Um DW sempre armazena dados importantes sobre temas específicos da empresa e conforme o interesse das pessoas que irão utilizá-lo. Exemplo: Uma empresa pode trabalhar com vendas de produtos alimentícios no varejo e o seu maior interesse ser o perfil de seus compradores, então o DW será voltado para as pessoas que compram seus produtos e não para os produtos que ela vende.

47
Data Warehouse- Características
Orientação por assunto Integração Variação no tempo Não volatilidade Localização Credibilidade dos dados Granularidade Metadados

48
Data Warehouse Características
Integração Incompatibilidade: mesmo elemento, nomes diferentes Incoerência: diferentes elementos, mesmo nome Aplicação A Aplicação B Aplicação C

49
Data Warehouse Características
Integração de dados DATA WAREHOUSE OPERACIONAL - Maria Silva - Feminino - 01/12/68 - Maria Silva - Duas internações em 2000 - Equipe médica - Duração média das internações - Maria Silva - Exames requeridos - Resultados Plano de Saúde Clínica Laboratório de Exames - Maria Silva - Feminino - Nascida em 01/12/68 - Duas internações em Equipe médica - Duração média das internações - Exames requeridos - Resultados dos exames - Casada - 2 filhos

50
Data Warehouse-Características
Integração de dados OPERACIONAL DATA WAREHOUSE Aplicação A: m,f Aplicação B: 1,0 Aplicação C: masculino, feminino Aplicação A: caminho - centímetros Aplicação B: caminho - pés Aplicação C: caminho - jardas Aplicação A: descrição Aplicação B: descrição Aplicação C: descrição Aplicação A: chave char(10) Aplicação B: chave dec fixed(9,2) Aplicação C: chave char(12) sexo: m, f caminho: centímetros Chave char(12) ? descrição
 Aplicação B: chave dec fixed(9,2) Aplicação C: chave char(12) sexo: m, f. caminho: centímetros. Chave char(12) descrição.")
51
Data Warehouse- Características
Orientação por assunto Integração Variação no tempo Não volatilidade Localização Credibilidade dos dados Granularidade Metadados

52
Data Warehouse Características
Variante no Tempo Os DW armazenam dados por um período de tempo de 5 a 10 anos Refere-se a algum momento específico não é atualizável No DW haverá sempre uma tabela dimensão ou fato, cuja estrutura registrará o elemento tempo

53
Data Warehouse Características
Variante no Tempo Atômico Departamental Individual Maria Silva Rua 24 horas, 12 Medicação: X, Z Entrada: 01/03/98 Alta: 10/03/98 Operacional Janeiro 4101 Fevereiro 4209 Março 4175 Abril 4215 Pacientes desde 1980 tomando o medicamento X e com período de internação superior à 5 dias Maria Silva Rua XV, 02 Medicação: X, Y Entrada: 05/11/00 Alta: 10/11/00 Maria Silva Rua XV, 02 Medicação: X, Y Entrada: 10/11/00 Alta: 10/11/00 Quais são os riscos (tendências) em relação aos pacientes que foram vitimas de infeção hospitalar? Estamos atendendo mais ou menos pacientes ao longo do tempo? Ex: Quais são medicamentos ministrados à Maria Silva neste momento? Quais foram os medicamentos ministrados à Maria Silva nos últimos 5 anos?
 em relação aos pacientes que foram. vitimas de infeção. hospitalar Estamos. atendendo mais. ou menos. pacientes ao. longo do tempo Ex: Quais são medicamentos ministrados à Maria Silva neste momento Quais foram os. medicamentos. ministrados à. Maria Silva nos. últimos 5 anos")
54
Data Warehouse- Características
Orientação por assunto Integração Variação no tempo Não volatilidade Localização Credibilidade dos dados Granularidade Metadados

55
Data Warehouse Características
Não volátil Permite o "load-and-access” Os dados após serem extraídos, transformados e transportados para o DW estão disponíveis aos usuários somente para consulta

56
Data Warehouse Características
Não volátil OPERACIONAL DATA WAREHOUSE alterar incluir acessar excluir carregar acessar

57
Data Warehouse- Características
Orientação por assunto Integração Variação no tempo Não volatilidade Localização Credibilidade dos dados Granularidade Metadados

58
Data Warehouse Características
Localização Dados altamente resumidos Formas de armazenamento: único local (centralizado) por área de interesse (distribuído) por nível de detalhes Dados levemente resumidos Dados detalhados atuais Dados detalhados antigos
 por área de interesse (distribuído) por nível de detalhes. Dados levemente resumidos. Dados detalhados atuais. Dados detalhados antigos.")
59
Data Warehouse- Características
Orientação por assunto Integração Variação no tempo Não volatilidade Localização Credibilidade dos dados Granularidade Metadados

60
Data Warehouse - Características
Credibilidade dos dados É o mais importante para o sucesso de qualquer projeto Discrepâncias simples de todo tipo podem causar sérios problemas quando se quer extrair dados para suportar decisões estratégicas para o negócio das empresas; Dados não dignos de confiança podem resultar em relatórios inúteis, que não tem importância alguma por exemplo, uma lista de pacientes do sexo masculino e grávidos;

61
Data Warehouse- Características
Orientação por assunto Integração Variação no tempo Não volatilidade Localização Credibilidade dos dados Granularidade Metadados

62
Data Warehouse-Características
Granularidade Baixa é possível responder a praticamente qualquer consulta porém, grande quantidade de recursos computacionais é necessária para responder perguntas específicas Alta ocorre uma significativa redução da possibilidade de utilização dos dados para atender consultas detalhadas porém, reduz-se muito o espaço em disco e o número de índices necessários

63
Data Warehouse Características
Exemplo de níveis de granularidade Baixa Alta Prod. Data Qtda. Valor A1 13/9/ ,00 B1 14/9/ ,00 A1 16/9/ ,00 A1 16/9/ ,00 mês/ano Prod. Qtda. Valor 09/00 A ,00 09/00 B ,00

64
Data Warehouse- Características
Orientação por assunto Integração Variação no tempo Não volatilidade Localização Credibilidade dos dados Granularidade Metadados

65
Data Warehouse- Características
Metadados Três diferentes camadas: Operacionais, Centrais do Data Warehouse, nível do usuário Três diferentes componentes: Mapeamento: descrevem como os dados de sistemas operacionais são transformados antes de entrarem no DW Histórico: descrevem as regras corretas a serem aplicadas nos dados corretos quando as regras de negócio mudam Algoritmos de sumarização: mostram a relação entre os diferentes níveis de detalhes dos dados, indicando inclusive que nível de sumarização é mais adequado para um dado objetivo.

66
Data Warehouse- Características
Metadados O conceito metadado é considerado como sendo os "dados sobre dados", isto é, os dados sobre os sistemas que operam com estes dados. Um repositório de metadados é uma ferramenta essencial para o gerenciamento de um Data Warehouse no momento de converter dados em informações para o negócio. Entre outras coisas, um repositório de metadados bem construído deve conter informações sobre a origem dos dados, regras de transformação, nomes e alias, formatos de dados, etc. Ou seja, esse "dicionário" deve conter muito mais do que as descrições de colunas e tabelas: deve conter informações que adicionem valor aos dados.

67
Data Warehouse- Características
Metadados Data marts DATA MARTS são pontos específicos de acesso a subconjuntos do data warehouse. Os data marts são construídos para responder prováveis perguntas de um tipo específico de usuário. Por exemplo: um data mart financeiro poderia armazenar informações consolidadas dia a dia para um usuário gerencial e em periodicidades maiores (semana, mês, ano) para um usuário no nível da diretoria. Um data mart pode ser composto por um ou mais cubos de dados.
 para um usuário no nível da diretoria. Um data mart pode ser composto por um ou mais cubos de dados.")
68
Padrão Arquitetura em Camadas
Estimula a organização da arquitetura do sistema em um conjunto de camadas coesas com fraco acoplamento entre elas. Cada camada possui um propósito bem definido. A camada superior conhece apenas a camada imediatamente inferior (que fornece seus serviços através de uma interface)
")
69
Padrão Arquitetura em Camadas
Cada camada é formada por um conjunto de classes com um determinado propósito.

70
Propósito de Cada Camada
Padrão Arquitetura em Camadas Propósito de Cada Camada UI: agrega as classes do sistema com as quais os usuários interagem. Negócio: mantém as classes do sistema responsáveis pelos serviços e regras do negócio. Dados: camada responsável pelo armazenamento e recuperação dos dados persistentes do sistema. Comunicação: responsável pela distribuição do sistema em várias máquinas.

71
Vantagens e Desvantagem
Padrão Arquitetura em Camadas Vantagens e Desvantagem Vantagens: Separação de código relativo a interface com o usuário (UI), comunicação, negócio e dados. Permite a mudança de implementação de uma camada sem afetar a outra, desde que a interface entre as mesmas seja mantida. Possibilita que uma camada trabalhe com diferentes versões de outra camada. Desvantagens Aumento no número de classes existentes no sistema
, comunicação, negócio e dados. Permite a mudança de implementação de uma camada sem afetar a outra, desde que a interface entre as mesmas seja mantida. Possibilita que uma camada trabalhe com diferentes versões de outra camada. Desvantagens. Aumento no número de classes existentes no sistema.")
72
Padrão Arquitetura em Camadas
Exemplos de diferentes configurações do padrão arquitetura em camadas usando tecnologias Java.

73
Padrão Arquitetura em Camadas
Possui as camadas: UI, Regras de Negócio e Acesso a Dados A camada de UI: agrega as classes de fronteira Exemplo: GUIAluno A camada de Regras de Negócio: agrega as classes de controle e entidade Exemplos: ControladorAluno e Aluno A camada de Acesso a Dados: agrega as classes de persistência dos dados Exemplo: RepositorioAluno

74
Padrão Arquitetura em Camadas
Entre as camadas UI e Negócio haverá sempre uma interface Java que uma classe Fachada do sistema implementará. A classe Fachada é utilizada para oferecer um caminho único para acesso aos serviços da camada de regras de negócio. As classes da UI, portanto, comunicam-se apenas com a classe Fachada, que por sua vez colabora com as outras classes internas da camada de regras de negócio para oferecer os serviços

75
Padrão Arquitetura em Camadas
O Controlador pode conter regras de controle do sistema e delega ações da fachada para a camada de acesso a dados. Entre as camadas Negócio e Dados haverá sempre uma interface Java que uma classe Repositório implementará. O Repositório armazena os objetos persistentes do sistema em algum meio de armazenamento físico (banco de dados, arquivo, etc.).
.")
76
Padrão Arquitetura em Camadas
Arquitetura em 3 camadas - Visão Arquitetural

77
Model-view-controller (MVC)
Model-view-controller (MVC) é um padrão de arquitetura que divide a aplicação em Controladores que tratam as entradas dos usuários, no Modelo que prove as funcionalidades principais, e nas Visões que mostram as informações para os usuários.
 é um padrão de arquitetura que divide a aplicação em Controladores que tratam as entradas dos usuários, no Modelo que prove as funcionalidades principais, e nas Visões que mostram as informações para os usuários.")
78
Model-view-controller (MVC)
Modelo (MODEL): Lógica de negócio; Visão (VIEW): Camada de interface com o usuário. Nesta camada o usuário vê o estado do modelo e pode manipular a interface, para ativar a lógica do negócio; Controlador (CONTROLLER): Transforma eventos gerados pela interface em ações de negócio, alterando o modelo.
: Lógica de negócio; Visão (VIEW): Camada de interface com o usuário. Nesta camada o usuário vê o estado do modelo e pode manipular a interface, para ativar a lógica do negócio; Controlador (CONTROLLER): Transforma eventos gerados pela interface em ações de negócio, alterando o modelo.")
79
Model-view-controller (MVC)
(continuação): Controller (Controle): utilizado para que haja comunicação entre a camada de View do Utilizador e a camada de Modelo do Servidor, por exemplo: Caso o Utilizador A tenha permissão para visualizar as informações da Entidade B, buscar no Modelo a Entidade B e seus atributos. View (Visualização) camada apresentável para o usuário contendo componentes como listas, botões, menus, etc. Utiliza a camada de Controle para se comunicar com o Modelo.
: Controller (Controle): utilizado para que haja comunicação entre a camada de View do Utilizador e a camada de Modelo do Servidor, por exemplo: Caso o Utilizador A tenha permissão para visualizar as informações da Entidade B, buscar no Modelo a Entidade B e seus atributos. View (Visualização) camada apresentável para o usuário contendo componentes como listas, botões, menus, etc. Utiliza a camada de Controle para se comunicar com o Modelo.")
80
Model-view-controller (MVC)
")
81
Presentation-Abstraction-Control (PAC)
Presentation-Abstraction-Control (PAC): define uma estrutura para o sistemas na forma de uma hierarquia de agentes cooperativos. Adequado para sistemas interativos, onde cada agente é responsável por um aspecto específico da funcionalidade da aplicação e é composto por três componentes: apresentação, abstração e controle.
: define uma estrutura para o sistemas na forma de uma hierarquia de agentes cooperativos. Adequado para sistemas interativos, onde cada agente é responsável por um aspecto específico da funcionalidade da aplicação e é composto por três componentes: apresentação, abstração e controle.")
82
Presentation-Abstraction-Control (PAC)
A parte Apresentação de um agente define sua imagem na tela por meio de um objecto interactivo da toolkit. Esse objecto é escolhido pela aplicação de regras ergonômicas, que são deduzidas de recomendações ergonômicas estudadas pela ergonomia cognitiva. Um agente pode ter várias apresentações. Ergonomia Cognitiva: também conhecida engenharia psicológica, refere-se aos processos mentais, tais como percepção, atenção, cognição, controle motor e armazenamento e recuperação de memória, como eles afetam as interações entre seres humanos e outros elementos de um sistema. Tópicos relevantes incluem carga mental de trabalho, vigilância, tomada de decisão, desempenho de habilidades, erro humano, interação humano-computador e treinamento. Fonte:

83
Presentation-Abstraction-Control (PAC)
A parte abstração de um agente corresponde a um dado ou tarefa da aplicação. Se um agente precisa trocar dados com a aplicação, é definido na sua parte abstração um mecanismo que permite esta troca.

84
Presentation-Abstraction-Control (PAC)
A parte do Controle é responsável por manter a coerência entre os dados mostrados na tela (objectos interactivos) e os dados da aplicação e por efetuar o tratamento dos eventos do usuário sobre esses objectos.
 e os dados da aplicação e por efetuar o tratamento dos eventos do usuário sobre esses objectos.")
85
Arquitectura Pipe and filter
O Padrão arquitectural Pipes and Filters oferece uma estrutura para processamento de stream de dados. Cada passo do processamento é encapsulado em um componente filtro. Os dados são transportados por meio de tubos (pipes) que estão entre filtros. Stream pode ser definido como um fluxo de dados em um sistema computacional
 que estão entre filtros. Stream pode ser definido como um fluxo de dados em um sistema computacional.")
86
Padrão Pipes e Filtros Estrutura
Filtro: Obtém dados de entrada, Executa uma função sobre os dados de entrada, Fornece dados de saída. Pipe: Transfere dados, Bufferiza dados, Sincroniza componentes vizinhos ativos. Filtros Pipes Asd sdf dsf fasdfjn df g poenig dfaf kondfg ia oi rwei wi Qqq sdfgds bfdg dfgsdf gvb thrt rtw ewerty yery wert dfghs. Fonte de dados Receptor de dados Buffer (ciência da computação) - Uma região de memória temporária utilizada para escrita e leitura de dados
 - Uma região de memória temporária utilizada para escrita e leitura de dados.")
87
Padrão Pipes e Filtros Estrutura (cont.) Fonte de dados
Fornece entrada para processamento no pipeline. Receptor de dados Consome saída.

88
1.17-Arquitectura Invocacao Inplicita(Implicit invocation) 1.19-Arquitectura Blackboard system 1.20-Arquitectura Ponto a Ponto(Peer-to-peer ) 1.21-Arquitectura orientanda a servico (Service-oriented architecture)
 1.21-Arquitectura orientanda a servico (Service-oriented architecture)")
89
DESENHO DETALHADO Desenho de Software Objectivos Problemas
Qualidades Técnicas

90
DESENHO DETALHADO Desenho de Software Objectivos
Desenho é o processo da passagem do espaço do problema para o espaço da solução. À descrição da solução também se chama desenho. O desenho descreve uma solução para o problema que satisfaz os seus requisitos note-se que muitas outras soluções satisfazendo os mesmo requisitos são possíveis

91
DESENHO DETALHADO Arquitectura e Desenho
O processo de desenho deve considerar dois aspectos: Descrever para os clientes o que o sistema faz- Arquitectura de Software Descreve as funções do sistema Está relacionado com os documentos de requisitos Descrever para a equipa de desenvolvimento como o sistema faz – Desenho de Programa Uma descrição dos principais algoritmos As estruturas e os fluxos de dados

92
DESENHO DETALHADO Qualidades Qualidades do desenho Coesão Ligação
Implicações

93
DESENHO DETALHADO Qualidades dos “Bons” desenhos
Intelegibilidade (understandability) Qualidade que determina o esforço necessário para compreender o desenho (a finalidade de cada componente e as suas interacções). Robustez (robustness) Até que ponto as alterações aos componentes são estanques (isto é, não impactam outros).
 Qualidade que determina o esforço necessário para compreender o desenho (a finalidade de cada componente e as suas interacções). Robustez (robustness) Até que ponto as alterações aos componentes são estanques (isto é, não impactam outros).")
94
DESENHO DETALHADO Qualidades dos “Bons” desenhos
Flexibilidade (flexibility) Mede até que ponto se pode alterar o software com um custo baixo. Reutilizabilidade (reusability) Mede até que ponto um os componentes do desenho podem ser utilizados para outras finalidades.
 Mede até que ponto se pode alterar o software com um custo baixo. Reutilizabilidade (reusability) Mede até que ponto um os componentes do desenho podem ser utilizados para outras finalidades.")
95
DESENHO DETALHADO Qualidades dos “Maus” desenhos Mau
Incompreensível (incomprehensible) A finalidade dos componentes não é compreensível Frágil (fragile) Alterar um componente tem implicações imprevisíveis noutros pontos do desenho.
 A finalidade dos componentes não é compreensível. Frágil (fragile) Alterar um componente tem implicações imprevisíveis noutros pontos do desenho.")
96
DESENHO DETALHADO Qualidades dos “Maus” desenhos Mau Rígido (rigid)
Qualquer alteração implica um número muito grande de ajustes Imóvel (immutable) A reutilização é impedida pela impossibilidade de desacoplar um componente do resto do sistema
 A reutilização é impedida pela impossibilidade de desacoplar um componente do resto do sistema.")
97
DESENHO DETALHADO Independência
Qualidade que determina a capacidade de reutilização (reusability); A independência entre componentes é uma qualidade do desenho que permite ainda Entendimento Concretização código Concretização de testes Adaptações Rastreabilidade dos requisitos
; A independência entre componentes é uma qualidade do desenho que permite ainda. Entendimento. Concretização código. Concretização de testes. Adaptações. Rastreabilidade dos requisitos.")
98
DESENHO DETALHADO Independência
Para aferir a independência entre componentes usam-se duas medidas: Coesão intra-componente Ligação inter-componentes

99
DESENHO DETALHADO Coesão
Medida de proximidade de componentes com determinada finalidade Coesão Funcional Coesão Comunicacional Coesão de Objecto

100
DESENHO DETALHADO Coesão
Medida de proximidade de componentes com determinada finalidade Coesão Funcional Coesão Comunicacional Coesão de Objecto

101
DESENHO DETALHADO Coesão Intra-Componente
Um componente é coeso se todos os seus elementos estão envolvidos na satisfação dos objectivos do componente. Quando não existe coesão, ao modificar uma determinada função é necessário procurar em todos os componentes as partes relativas à função

102
DESENHO DETALHADO Coesão Intra-Componente
A coesão determina a localidade das alterações

103
DESENHO DETALHADO Coesão de Objecto
Coesão = cada método e atributo é essencial para cumprir a responsabilidade do objecto. O Desenho com objectos promove a coesão.

104
DESENHO DETALHADO Ligação
Ligação forte quando existe uma grande dependência entre componentes; Ligação fraca quando existe uma fraca dependência; Desligados quando são completamente independentes;

105
DESENHO DETALHADO Ligação Inter-Componentes
A ligação entre componentes depende de: As referências entre componentes Os dados passados entre componentes O controlo entre componentes O nível de complexidade da interface entre componentes

106
DESENHO DETALHADO Ligação Inter-Componentes Níveis de ligação
Ligação de conteúdo Ligação de Partilha Ligação de Controlo Ligação de Estrutura Ligação de Dados Sem ligação

107
COMPLEXIDADE DE SOFTWARE
A colecção de requisições é crucial para o sucesso no desenvolvimento de sistemas. E para realizá-los com qualidade, é essencial que seu desenvolvimento seja de forma sistemática e compreensível; pois ele deverá ter o que o usuário necessita e se não o faz, provavelmente não se ajustará às suas especificações; podendo levar à crise do software. Esta crise se manifesta através do custo acima do planejado; da insatisfação do usuário final com o produto; do software com defeitos e da falta de confiabilidade no mesmo.

108
COMPLEXIDADE DE SOFTWARE
É importante que se entenda as medidas de complexidade na teoria, para aplicá-las na prática, principalmente porque as pessoas lidam com complexidade abstraindo detalhes desnecessários.

109
COMPLEXIDADE DE SOFTWARE
As razões que levam à complexidade do software são: Tamanho, número de variáveis e funções; restrições de tempo; gerenciamento de memória, concorrência e interface orientada a eventos. Assim, Booch [BOOCH90] identificou algumas características comuns a todos os sistemas complexos: Existe alguma hierarquia ; Os componentes são mais acoplados internamente que externamente; Existem padrões comuns que usam componentes simples, capazes de representar componentes complexos; Geralmente sistemas complexos são construídos a partir de sistemas básicos.

110
COMPLEXIDADE DE SOFTWARE
Complexidade de Modelos Baseados em Processos O processo de desenvolvimento pode ser dividido em: análise, projecto e implementação; onde a análise objectivas entender o problema como preparação para o projecto; seguido pela modelagem do sistema com conceitos do mundo real de uma forma que possa ser entendido. Daí o analista interage intensamente com o requisitante, a fim de esclarecer ambiguidades e mal entendidos.

111
COMPLEXIDADE DE SOFTWARE
Complexidade de Modelos Baseados em Processos O PROJECTO é, essencialmente, um processo de refinamento e acréscimo de detalhes, onde o projectista irá: combinar os três modelos de análise, obter as operações sobre as classes, projectar algoritmos para implementar tais operações, optimizar o caminho de acesso aos dados, implementar controles para as interações externas, ajustar a estrutura de classes para aumentar a herança, projetar associações adequadas, determinar a representação dos objectos, e empacotar classes e associações em módulos

112
Princípios e técnicas de desenho de software
Principio de Divisão e conquista Divisão e Conquista consiste em dividir o problema a ser resolvido em partes menores, encontrar soluções para as partes, e então combinar as soluções obtidas em uma solução global. O uso do paradigma para resolver problemas nos quais os subproblemas são versões menores do problema original geralmente leva a soluções eficientes e elegantes, especialmente quando é utilizado recursivamente” (ZIVIANI, 2007) A Divisão e Conquista emprega modularização de programas e frequentemente conduz a um algoritmo simples e eficiente. Esta técnica é bastante utilizada em desenvolvimento de algoritmos paralelos, onde os subproblemas são tipicamente independentes um dos outros, podendo assim serem resolvidos separadamente.
 A Divisão e Conquista emprega modularização de programas e frequentemente conduz a um algoritmo simples e eficiente. Esta técnica é bastante utilizada em desenvolvimento de algoritmos paralelos, onde os subproblemas são tipicamente independentes um dos outros, podendo assim serem resolvidos separadamente.")
113
Princípios e técnicas de desenho de software
Principio de Divisão e conquista A técnica de Divisão e Conquista consistem em 3 passos: • Divisão: dividir a instância do problema original em duas ou mais instâncias menores, considerando-as como subproblemas. • Conquista: resolver cada subproblema recursivamente. • Combinação: combinar as soluções encontradas em cada subproblema, compondo uma solução para o problema original.

114
Princípios e técnicas de desenho de software
Principio de Divisão e conquista Vantagens • Indicado para aplicações que tem restrição de tempo. • É de fácil implementação. • Simplifica problemas complexos. Desvantagens • Necessidade de memória auxiliar. • Repetição de Subproblemas. • Tamanho da pilha (número de chamadas recursivas e/ou armazenadas pode causar estouro de memória).
.")
115
Princípios e técnicas de desenho de software
Principio de Divisão e conquista Algumas aplicações • Multiplicação de inteiros longos. • Menor distância entre pontos. • Ordenação rápida (quicksort) e por intercalação (mergesort). • Pesquisa em árvore binária.
 e por intercalação (mergesort). • Pesquisa em árvore binária.")
116
Princípios e técnicas de desenho de software
Principio de Divisão e conquista Um exemplo para ilustrar o uso dessa técnica é o algoritmo de ordenação de um vetor por intercalação (MergeSort). Sua representação pode ser feita através de uma árvore binária.
. Sua representação pode ser feita através de uma árvore binária.")
117
abstração ABSTRAÇÃO é o princípio de ignorar os aspectos de um assunto não relevantes para o propósito em questão, tornando possível uma concentração maior nos assuntos principais; selecção que um analista faz de alguns aspectos, ignorando outros. Tipos de abstração Abstração de procedimentos Abstração de dados

118
abstração A abstração de procedimentos é uma forma de abstração usada por analistas de requisitos, projectistas e programadores e é caracterizada como uma abstração função/subfunção; é o princípio de que qualquer operação com efeito bem definido poderá ser tratada como entidade única, mesmo que a operação seja realmente conseguida através de alguma sequência de operações de nível mais baixo.

119
abstração A abstração de dados consiste na definição de um tipo de dado conforme as operações aplicáveis aos objetos deste tipo; assim, os objetos podem ser modificados e observados através destas operações. Este tipo de abstração é mais poderoso que a abstração de procedimentos e pode ser usado como base para a organização do pensamento e a especificação das responsabilidades de um sistema. Ao se aplicar uma abstração de dados, um analista define os atributos e os serviços que manipulam exclusivamente estes atributos que podem ser tratados como um todo intrínseco.

120
abstração O programador pode usar abstração para notar que duas funções tem tarefas comuns e podem ser combinadas em uma simples função. É uma técnica importante em Engenharia de Software, sendo relatada com outra técnica conhecida como encapsulamento, que será discutida a seguir. Assim, o programador poderá focar-se em novos objetos, sem se preocupar com a ocultação dos detalhes.

121
Encapsulamento Encapsulamento é o agrupamento de idéias relacionadas em uma unidade; uma técnica poderosa de programação que reduz a complexidade e previne contra mudanças intencionais ou não de partes do programa; agrupamento de procedimentos em torno de ideias. Já o encapsulamento orientado a objecto é o agrupamento de procedimentos em torno dos dados, revelando informações e escondendo a implementação. Então, pode–se concluir que o encapsulamento pode ser uma poderosa técnica para domesticar a complexidade do sistema.

122
Encapsulamento Algumas vantagens do encapsulamento podem ser descritas como a diminuição de trabalho no desenvolvimento de um novo sistema; o agrupamento de aspectos relacionados; a minimização do fluxo entre as diferentes partes do trabalho e a separação de certos requisitos específicos que outras partes da especificação podem usar.

123
Modularização do Projecto
A modularidade contribui muito para a manutenabilidade, sendo, então, um fator importante na prevenção de manutenção corretiva e aperfeiçoamento do código. Sendo que sua meta é fazer cada rotina como uma caixa preta que tem uma interface simples e uma funcionalidade bem definida. Porém, o objectivo da perfeita modularidade é difícil de se realizar com rotinas individuais, pois elas não especificam perfeitamente o porque particionam os dados com outras rotinas.

124
Acoplamento Método para medir a qualidade de um projeto , ou seja, o grau de interdependência entre os módulos. Assim, é importante minimizar o acoplamento, indicando um sistema bem particionado. Um baixo acoplamento entre os módulos pode ser obtido eliminando relações desnecessárias , reduzindo o número de relações necessárias e enfraquecendo a dependência das relações necessárias. Existem cinco tipos de acoplamento que são: Acoplamento de dados, Acoplamento de Imagem, Acoplamento de Controle, Acoplamento Comum, Acoplamento de Conteúdo, Acoplamento patológico .

125
Acoplamento Acoplamento de dados onde os módulos se comunicam por parâmetros . É a comunicação de dados necessária entre os módulos. Acoplamento de Imagem onde os módulos são ligados por imagem se eles se referem à mesma estrutura de dados. Tende a expor o módulo a mais dados do que realmente necessita, com possíveis consequências ruins. Acoplamento de Controle onde um módulo passa para o outro um grupo de dados que controle a lógica interna do outro. O módulo subordinado não é uma caixa preta . O Acoplamento de Controle às vezes está disfarçado em uma forma denominada Acoplamento Híbrido, que pode causar problemas desastrosos na manutenção, pois resulta na indicação de vários significados para várias partes do domínio de um grupo de dados.

126
Acoplamento Acoplamento Comum onde dois módulos se referem à mesma área de dados. Não é aconselhável pois o excesso de uso de dados comuns degrada a ideia de modularidade ao deixar os dados abandonarem os limites escritos de um módulo. Acoplamento de Conteúdo (ou Patológico)onde um módulo faz referencia ao interior do outro. Assim, um módulo sabe o conteúdo e implementação do outro, assim, a maioria das linguagens de alto nível não permitem este tipo de acoplamento. Dois módulos podem estar acoplados em mais de uma maneira, sendo então, definidos pelo pior tipo de acoplamento que representem. Por exemplo, se dois módulos são ligados por acoplamento de imagem e comum, a característica deles será o acoplamento comum.
onde um módulo faz referencia ao interior do outro. Assim, um módulo sabe o conteúdo e implementação do outro, assim, a maioria das linguagens de alto nível não permitem este tipo de acoplamento. Dois módulos podem estar acoplados em mais de uma maneira, sendo então, definidos pelo pior tipo de acoplamento que representem. Por exemplo, se dois módulos são ligados por acoplamento de imagem e comum, a característica deles será o acoplamento comum.")
127
TPC Principio de Separação de políticas da execução de algoritmos
Principio de Separação de interfaces de suas implementações Principio de localidade.

128
QUALIDADE DE SOFTWARE O factor qualidade é um dos aspectos importantes que deve ser levado em conta quando do desenvolvimento do software. Para isto, é necessário que se tenha uma definição precisa do que é um software de qualidade ou, pelo menos, quais são as propriedades que devem caracterizar um software desenvolvido segundo os princípios da Engenharia de Software.

129
QUALIDADE DE SOFTWARE Primeiramente, é importante discutir o conceito de software de qualidade. Segundo a Associação Francesa de Normalização, AFNOR, a qualidade é definida como "a capacidade de um produto ou serviço de satisfazer às necessidades dos seus usuários". Esta definição, de certa forma, é coerente com as metas da Engenharia de Software, particularmente quando algumas definições são apresentadas. É o caso das definições de Verificação e Validação introduzidas por Boehm, que associa a estas definições as seguintes questões:

130
QUALIDADE DE SOFTWARE • Verificação: "Será que o produto foi construído corretamente?" • Validação: "Será que este é o produto que o cliente solicitou?" O problema que surge quando se reflete em termos de qualidade é a dificuldade em se quantificar este factor.

131
Fatores de Qualidade Externos e Internos
QUALIDADE DE SOFTWARE Fatores de Qualidade Externos e Internos Algumas das propriedades que poderíamos apontar de imediato são a correção, a facilidade de uso, o desempenho, a legibilidade, etc... Na verdade, analisando estas propriedades, é possível organizá-las em dois grupos importantes de fatores, que vamos denominar fatores externos e internos.

132
Fatores de Qualidade Externos
QUALIDADE DE SOFTWARE Fatores de Qualidade Externos Os fatores de qualidade externos, são aqueles que podem ser detectados principalmente pelo cliente ou eventuais usuários. A partir da observação destes fatores, o cliente pode concluir sobre a qualidade do software, do seu ponto de vista. Enquadram-se nesta classe fatores tais como: o desempenho, a facilidade de uso, a correção, a confiabilidade, a extensibilidade, etc...

133
Factores de Qualidade Interno
QUALIDADE DE SOFTWARE Factores de Qualidade Interno Os fatores de qualidade internos são aqueles que estão mais relacionados à visão de um programador, particularmente aquele que vai assumir as tarefas de manutenção do software. Nesta classe, encontram-se fatores como: modularidade, legibilidade, portabilidade, etc... Não é difícil verificar que, normalmente, os fatores mais considerados quando do desenvolvimento do software são os externos. Isto porque, uma vez que o objetivo do desenvolvimento do software é satisfazer ao cliente, são estes fatores que vão assumir um papel importante na avaliação do produto (da parte do cliente, é claro!!!). No entanto, também não é difícil concluir que são os fatores internos que vão garantir o alcance dos fatores externos.
. No entanto, também não é difícil concluir que são os fatores internos que vão garantir o alcance dos fatores externos.")
134
QUALIDADE DE SOFTWARE Factores de Qualidade Correção Robustez
Extensibilidade Reusabilidade Compatibilidade Eficiência Portabilidade Facilidade de uso

135
QUALIDADE DE SOFTWARE Factores de Qualidade Correção
É a capacidade dos produtos de software de realizarem suas tarefas de forma precisa, conforme definido nos requisitos e na especificação. É um factor de suma importância em qualquer categoria de software. Nenhum outro factor poderá compensar a ausência de correção. Não é interessante produzir um software extremamente desenvolvido do ponto de vista da interface homem- máquina, por exemplo, se as suas funções são executadas de forma incorreta.

136
QUALIDADE DE SOFTWARE Factores de Qualidade Correção
É preciso dizer, porém, que a correção é um factor mais facilmente afirmado do que alcançado. O alcance de um nível satisfatório de correção vai depender, principalmente, da formalização dos requisitos do software e do uso de métodos de desenvolvimento que explorem esta formalização.

137
QUALIDADE DE SOFTWARE Factores de Qualidade Robustez
A robustez é a capacidade do sistema funcionar mesmo em condições anormais. É um fator diferente da correção. Um sistema pode ser correto sem ser robusto, ou seja, o seu funcionamento vai ocorrer somente em determinadas condições. O aspecto mais importante relacionado à robustez é a obtenção de um nível de funcionamento do sistema que suporte mesmo situações que não foram previstas na especificação dos requisitos.

138
QUALIDADE DE SOFTWARE Factores de Qualidade Robustez
Na pior das hipóteses, é importante garantir que o software não vai provocar consequências catastróficas em situações anormais. Resultados esperados são que, em tais situações, o software apresente comportamentos tais como: a sinalização da situação anormal, a terminação "ordenada", a continuidade do funcionamento "correto" mesmo de maneira degradada, etc... Na literatura, estas características podem ser associadas também ao conceito de confiabilidade.

139
QUALIDADE DE SOFTWARE Factores de Qualidade Extensibilidade
É a facilidade com a qual se pode introduzir modificações nos produtos de software. Todo software é considerado, em princípio, "flexível" e, portanto, passível de modificações. No entanto, este factor nem sempre é muito bem entendido, principalmente quando se trata de pequenos programas.

140
QUALIDADE DE SOFTWARE Factores de Qualidade Extensibilidade
Por outro lado, para softwares de grande porte, este fator atinge uma importância considerável, e pode ser atingido a partir de dois critérios importantes: A simplicidade de projeto, ou seja, quanto mais simples e clara a arquitetura do software, mais facilmente as modificações poderão ser realizadas; A descentralização, que implica na maior autonomia dos diferentes componentes de software, de modo que a modificação ou a retirada de um componente não implique numa reação em cadeia que altere todo o comportamento do sistema, podendo inclusive introduzir erros antes inexistentes.

141
QUALIDADE DE SOFTWARE Factores de Qualidade Reusabilidade
É a capacidade dos produtos de software serem reutilizados, totalmente ou em parte, para novas aplicações. A necessidade vem da constatação de que muitos componentes de software obedecem a um padrão comum, o que permite então que estas similaridades possam ser exploradas para a obtenção de soluções para outras classes de problemas.

142
QUALIDADE DE SOFTWARE Factores de Qualidade Reusabilidade
Este fator permite, principalmente, atingir uma grande economia e um nível de qualidade satisfatórios na produção de novos softwares, dado que menos programa precisa ser escrito, o que significa menos esforço e menor risco de ocorrência de erros. Isto significa de fato que a reusabilidade pode influir em outros fatores de qualidade importantes, tais como a correção e a robustez.

143
QUALIDADE DE SOFTWARE Factores de Qualidade Compatibilidade
A compatibilidade corresponde à facilidade com a qual produtos de software podem ser combinados com outros. Este é um fator relativamente importante, dado que um produto de software é construído (e adquirido) para trabalhar convivendo com outros softwares. A impossibilidade de interação com outros produtos pode ser, sem dúvida, uma característica que resultará na não escolha do software ou no abandono de sua utilização.
 para trabalhar convivendo com outros softwares. A impossibilidade de interação com outros produtos pode ser, sem dúvida, uma característica que resultará na não escolha do software ou no abandono de sua utilização.")
144
QUALIDADE DE SOFTWARE Factores de Qualidade Compatibilidade
Os contraexemplos de compatibilidade, infelizmente, são maiores que os exemplos, mas podemos citar, nesta classe, principalmente, a definição de formatos de arquivos padronizados (ASCII, PostScript, ...), a padronização de estruturas de dados, a padronização de interfaces homem-máquina (sistema do Macintosh, ambiente Windows, ...), etc...
, a padronização de estruturas de dados, a padronização de interfaces homem-máquina (sistema do Macintosh, ambiente Windows, ...), etc...")
145
QUALIDADE DE SOFTWARE Factores de Qualidade Eficiência
A eficiência está relacionada com a utilização racional dos recursos de hardware e de sistema operacional da plataforma onde o software será instalado. Recursos tais como memória, processador e co-processador, memória cache, recursos gráficos, bibliotecas (por exemplo, primitivas de sistema operacional) devem ser explorados de forma adequada em espaço e tempo
 devem ser explorados de forma adequada em espaço e tempo.")
146
QUALIDADE DE SOFTWARE Factores de Qualidade Portabilidade
A portabilidade consiste na capacidade de um software em ser instalado para diversos ambientes de software e hardware. Esta nem sempre é uma característica facilmente atingida, devido principalmente às diversidades existentes nas diferentes plataformas em termos de processador, composição dos periféricos, sistema operacional, etc…

147
QUALIDADE DE SOFTWARE Factores de Qualidade Eficiência
Alguns softwares, por outro lado, são construídos em diversas versões, cada uma delas orientada para execução num ambiente particular. Exemplos disto são alguns programas da Microsoft, como por exemplo o pacote Microsoft Office, que existe para plataformas Macintosh e microcomputadores compatíveis IBM

148
QUALIDADE DE SOFTWARE Factores de Qualidade Facilidade de uso
Este fator é certamente um dos mais fortemente detectados pelos usuários do software. Atualmente, com o grande desenvolvimento dos ambientes gráficos como Windows, X- Windows e o Sistema Macintosh, a obtenção de softwares de fácil utilização tornou-se mais frequente. A adoção de procedimentos de auxílio em linha (help on line) é, sem dúvida, uma grande contribuição neste sentido.
 é, sem dúvida, uma grande contribuição neste sentido.")
149
A Metrologia da Qualidade do Software
QUALIDADE DE SOFTWARE A Metrologia da Qualidade do Software Apresentados alguns factores de qualidade de software, a dificuldade que se apresenta é como medir a qualidade do software. Ao contrário de outras disciplinas de engenharia, onde os produtos gerados apresentam características físicas como o peso, a altura, tensão de entrada, tolerância a erros, etc..., a medida da qualidade do software é algo relativamente novo e alguns dos critérios utilizados são questionáveis.

150
A Metrologia da Qualidade do Software
QUALIDADE DE SOFTWARE A Metrologia da Qualidade do Software A possibilidade de estabelecer uma medida da qualidade é um aspecto importante para a garantia de um produto de software com algumas das características definidas anteriormente. A Metrologia do Software corresponde ao conjunto de teorias e práticas relacionadas com as medidas, a qual permite estimar o desempenho e o custo do software, a comparação de projetos e a fixação dos critérios de qualidade a atingir.

151
A Metrologia da Qualidade do Software
QUALIDADE DE SOFTWARE A Metrologia da Qualidade do Software As medidas de um software podem ser as mais variadas, a escolha da medida devendo obedecer a determinados critérios: a pertinência da medida (interpretabilidade); o custo da medida (percentual reduzido do custo do software); utilidade (possibilidade de comparação de medidas).
; o custo da medida (percentual reduzido do custo do software); utilidade (possibilidade de comparação de medidas).")
152
A Metrologia da Qualidade do Software
QUALIDADE DE SOFTWARE A Metrologia da Qualidade do Software As medidas de um software podem ser organizadas segundo duas grandes categorias: Medidas dinâmicas Medidas estáticas

153
A Metrologia da Qualidade do Software
QUALIDADE DE SOFTWARE A Metrologia da Qualidade do Software Medidas dinâmicas São as medidas obtidas mediante a execução do software, como, por exemplo, os testes, as medidas de desempenho em velocidade e ocupação de memória, os traços, etc... Estas medidas podem assumir um interesse relativamente grande pois elas permitem quantificar fatores que podem implicar em retorno econômico ou que representem informações sobre a correção do programa; por outro lado, estas medidas só podem ser obtidas num momento relativamente tardio do ciclo de desenvolvimento de um software, ou seja, a partir da etapa de testes.

154
A Metrologia da Qualidade do Software
QUALIDADE DE SOFTWARE A Metrologia da Qualidade do Software Medidas estáticas São aquelas obtidas a partir do documento fonte do software, sem a necessidade de execução do software. Dentre as medidas estáticas, podemos destacar: • As medidas de complexidade textual, a qual é baseada na computação do número de operadores e do número de operandos contidos no texto do software; • A complexidade estrutural, a qual se baseia na análise dos grafos de controle associadas a cada componente do software; • As medidas baseadas no texto, como o tamanho do programa, a taxa de linhas de comentários, etc...

155
Processos de Desenvolvimento de Software
O processo de software é visto por uma sequência de atividades que produzem uma variedade de documentos, resultando em um programa satisfatório e executável. Os níveis e arquitectura do processo de software é formada por: Nível Universal: possa utilizar em qualquer projeto; Nível Mundial: Específico para um determinado projeto; Nível Atômico: Sequência algorítmica do projeto, específico para as tarefas do processo.

156
Processos de Desenvolvimento de Software
O desenvolvimento de software tem-se caracterizado por uma sobreposição de atividades necessárias para especificar, projectar e testar retorno dos resultados do software que está sendo criado. O feedback dessa atividade nos ajuda a compreender o que é necessário para criar um produto. A partir do feedback obtido em experiências com protótipos, podemos efetuar mudanças na forma e na construção conceitual Modelos de Processos 5 do software. O feedback possui quatro formas básicas: Medições da entidade do software: número derivado de resultados produzidos por processos executores; Corretiva: erros, faltas e falhas cometidas no software; Mudança: Modificar o software para eliminar defeitos; Aprimoramento: Aperfeiçoar o software.

157
Modelos de Processo de Software
Existem vários modelos de processo de software (ou paradigmas de engenharia de Modelos de Processos 6 software). Cada um representa uma tentativa de colocar ordem em uma atividade inerentemente caótica.
. Cada um representa uma tentativa de colocar ordem em uma atividade inerentemente caótica.")
158
Modelos de Processo de Software
O Modelo Sequencial Linear Também chamado Modelo Cascata O Modelo de Prototipação O Modelo RAD (Rapid Application Development) Modelos Evolutivos de Processo de Software Modelos de Processos 7 O Modelo Incremental O Modelo Espiral O Modelo de Montagem de Componentes Técnicas de Quarta Geração
 Modelos Evolutivos de Processo de Software. Modelos de Processos 7. O Modelo Incremental. O Modelo Espiral. O Modelo de Montagem de Componentes. Técnicas de Quarta Geração.")
159
Modelos de Processo de Software
O Modelo Sequencial Linear também chamado Modelo Cascata

160
Modelos de Processo de Software
O Modelo Cascata Modelo mais antigo e o mais amplamente usado da engenharia de software Modelado em função do ciclo da engenharia convencional Requer uma abordagem sistemática, sequencial ao desenvolvimento de software O resultado de uma fase se constitui na entrada da outra

161
Modelos de Processo de Software
O Modelo Cascata

162
Modelos de Processo de Software
O Modelo Cascata Exploração de Conceitos / Informação e Modelagem Envolve a elicitação de requisitos do sistema, com uma pequena quantidade de projeto e análise de alto nível; Preocupa-se com aquilo que conhecemos como engenharia progressiva de produto de software; Iniciar com um modelo conceitual de alto nível para um sistema e prosseguir com o projeto, implementação e teste do modelo físico do sistema.

163
Modelos de Processo de Software
O Modelo Cascata Análise de Requisitos de Software O processo de elicitação dos requisitos é intensificado e concentrado especificamente no Software. Deve-se compreender o domínio da informação, a função, desempenho e interfaces exigidos. Os requisitos (para o sistema e para o software) são documentados e revistos com o cliente
 são documentados e revistos com o cliente.")
164
Modelos de Processo de Software
O Modelo Cascata Análise de Requisitos de Software O processo de elicitação dos requisitos é intensificado e concentrado especificamente no Software. Deve-se compreender o domínio da informação, a função, desempenho e interfaces exigidos. Os requisitos (para o sistema e para o software) são documentados e revistos com o cliente
 são documentados e revistos com o cliente.")
165
Modelos de Processo de Software
O Modelo Cascata Projecto tradução dos requisitos do software para um conjunto de representações que podem ser avaliadas quanto à qualidade, antes que a codificação inicie.

166
Modelos de Processo de Software
O Modelo Cascata Implementação Tradução das representações do projeto para uma linguagem “artificial” resultando em instruções executáveis pelo computador e implementado num ambiente de trabalho.

167
Modelos de Processo de Software
O Modelo Cascata Testes Concentra-se: nos aspectos lógicos internos do software, garantindo que todas as instruções tenham sido testadas; nos aspectos funcionais externos, para descobrir erros e garantir que a entrada definida produza resultados que concordem com os esperados.

168
Modelos de Processo de Software
O Modelo Cascata Manutenção Provavelmente o software deverá sofrer mudanças depois que for entregue ao cliente, causas das mudanças: erros, adaptação do software para acomodar mudanças em seu ambiente externo e exigência do cliente para acréscimos funcionais e de desempenho.

169
Modelos de Processo de Software
Problemas com o Modelo Cascata Projetos reais raramente seguem o fluxo sequencial que o modelo propõe; Logo no início é difícil estabelecer explicitamente todos os requisitos. No começo dos projetos sempre existe uma incerteza natural; O cliente deve ter paciência. Uma versão executável do software só fica disponível numa etapa avançada do desenvolvimento (na instalação); Difícil identificação de sistemas legados (não acomoda a engenharia reversa).
; Difícil identificação de sistemas legados (não acomoda a engenharia reversa).")
170
Modelos de Processo de Software
Problemas com o Modelo Cascata

171
Modelos de Processo de Software
O Modelo Cascata O Modelo de processo em Cascata trouxe contribuições importantes para o processo de desenvolvimento de software: Imposição de disciplina, planeamento e gerenciamento, a implementação do produto deve ser postergada até que os objetivos tenham sido completamente entendidos; Permite gerência do baseline, que identifica um conjunto fixo de documentos produzidos ao longo do processo de desenvolvimento;

172
Baseline: É um conceito de gerenciamento de configuração que nos ajuda a controlar as mudanças realizadas nos itens de configuração de uma empresa. Ao aprovarmos uma determinada configuração, seja de hardware ou de software, estaremos criando uma baseline. Toda vez que houver uma alteração em um item de configuração, uma nova baseline é gerada, para fins de comparação com a anterior e consequente aprovação (ou não) das mudanças
 das mudanças.")
Apresentações semelhantes
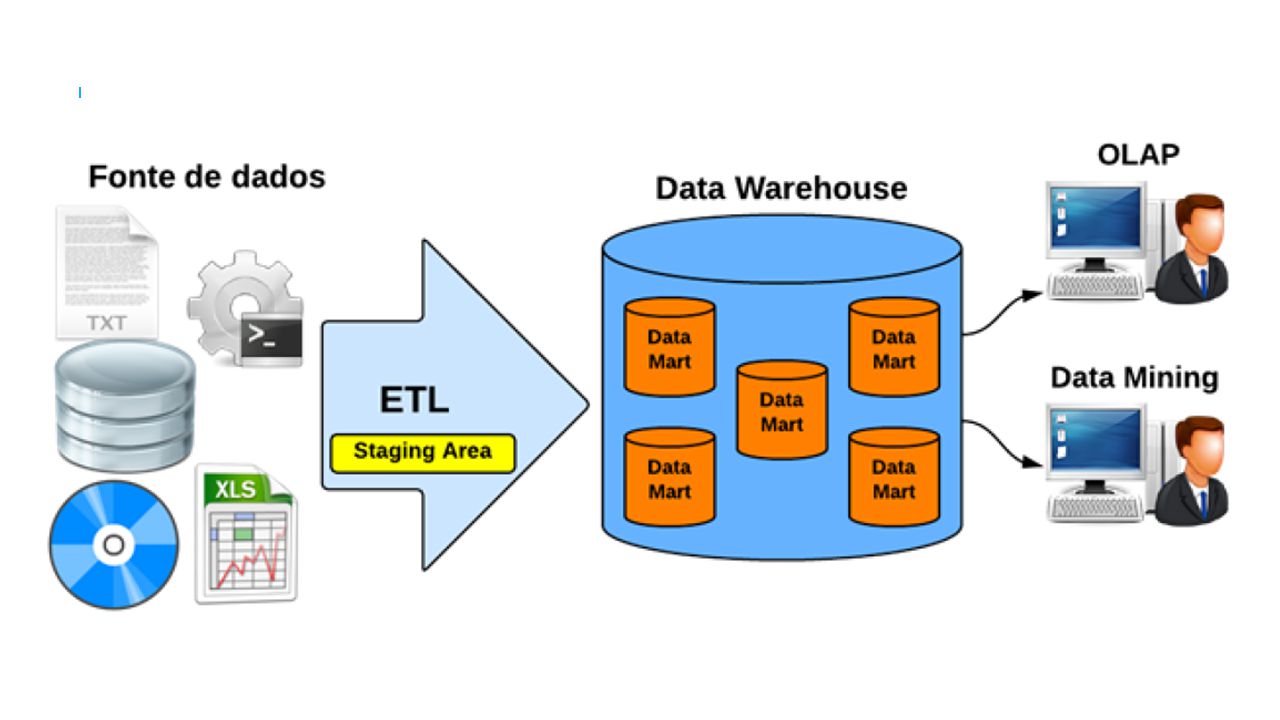













 Requisitos Adélia Barros (adelia_nassau@yahoo.com.br)>")

>")



