Carregar apresentação
A apresentação está carregando. Por favor, espere

1
Descrição Bivariada Comparando Duas Distribuições
Eng. de Minas João Felipe C.L. Costa Prof. Dr. do DEMIN/PPGEM, UFRGS Eng. de Minas Luis Eduardo de Souza Doutorando do PPGEM, UFRGS

2
Estrutura da Apresentação
Introdução Gráficos q-q plot Scatterplots Histogramas Correlação Regressão Distribuição condicional

3
Introdução Na análise de bancos de dados, freqüentemente se torna necessário comparar duas distribuições, de maneira a medir seu grau de associação. A apresentação dos histogramas com seus respectivos sumários estatísticos vai revelar apenas a existência de diferenças mais evidentes. Infelizmente, se as duas distribuições são muito parecidas, este método de comparação não será útil na descoberta de diferenças mais sutis entre as distribuições. Dessa forma, o propósito básico dessa apresentação é apresentar ferramentas que permitam entender melhor o comportamento de dois conjuntos de valores e tornar possível fazer algum tipo de predição, usando uma variável para conhecer a outra.

4
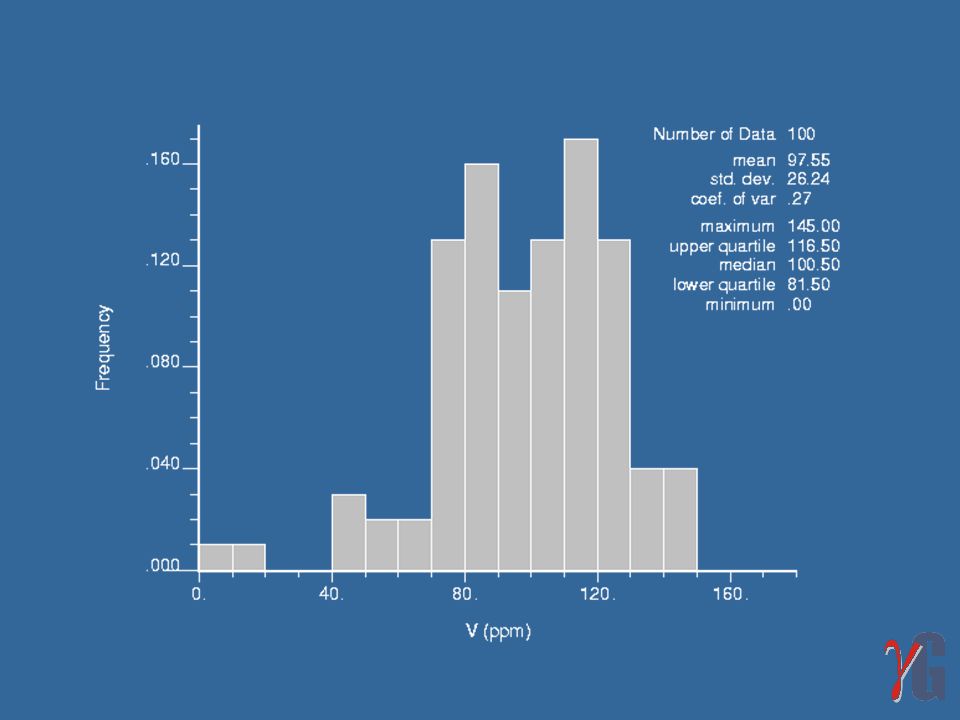
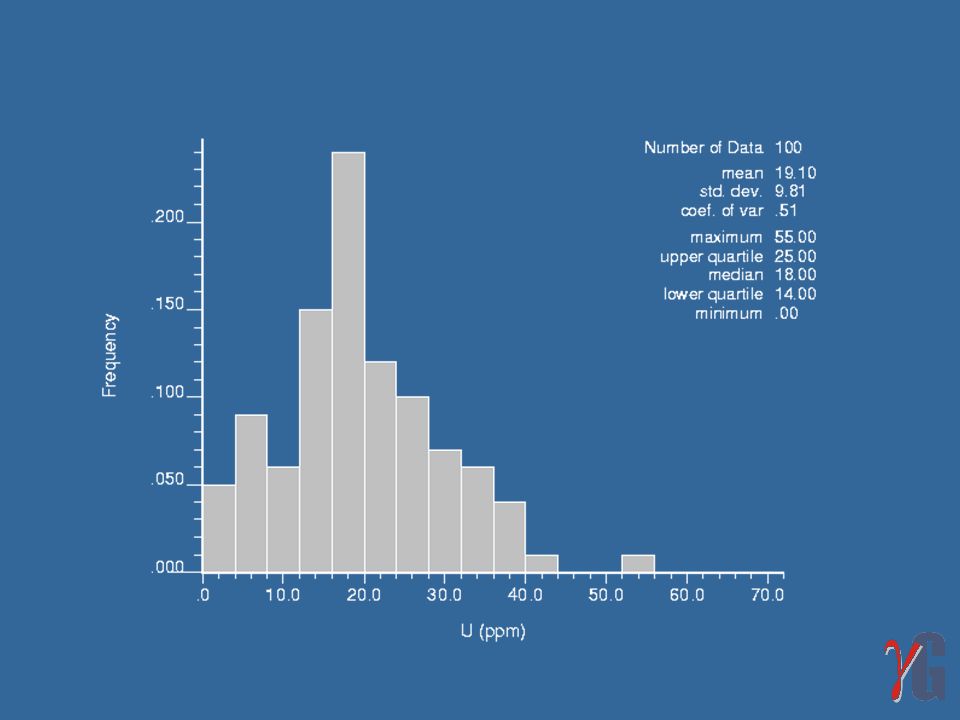
Mapa de localização de 100 amostras extraídas do banco de dados Walker Lake, com valores de V e U, acima e abaixo do símbolo, respectivamente.

7
Os histogramas e os sumários estatísticos dos valores de V e U apresentam apenas as principais diferenças entre as distribuições das duas variáveis: a distribuição de U apresenta assimetria positiva, enquanto V tem assimetria negativa; os valores de V são geralmente maiores que os de U, com um valor médio cinco vezes maior do que o de U; a mediana e o desvio padrão de V são também maiores do que os de U.

8
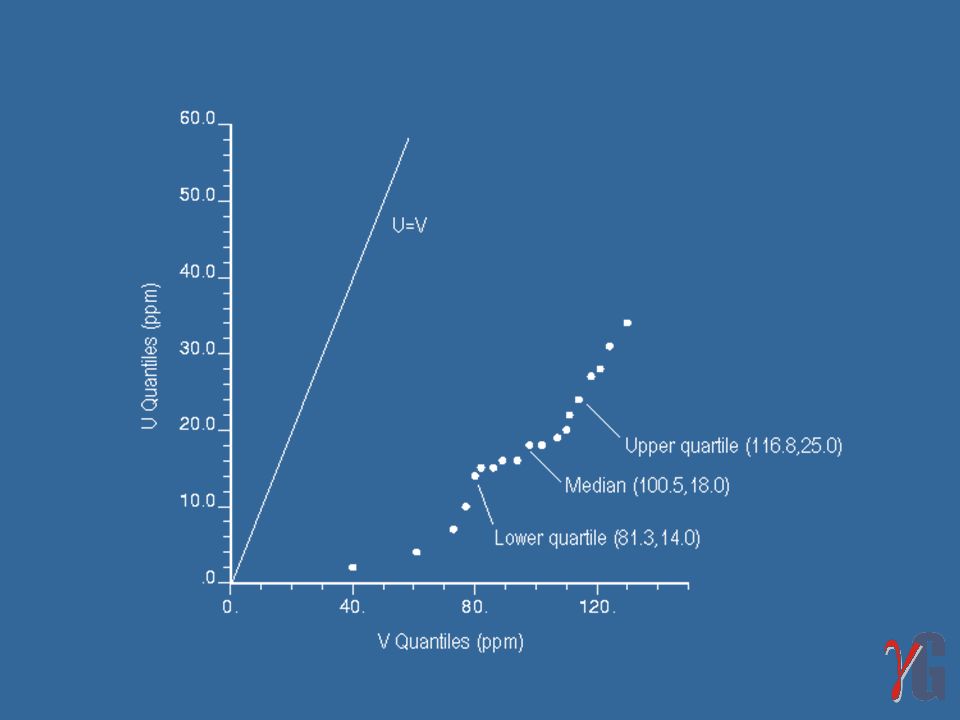
Gráficos q-q plot Uma comparação mais completa pode ser obtida pela análise dos quantis de diversas freqüências acumuladas. Para uma boa comparação visual das duas distribuições, faz-se uso de um gráfico chamado q-q plot, onde os quantis de uma distribuição são plotados contra os quantis da outra. Freqüência Quantil Acumulada V U

10
Um q-q plot de duas distribuições idênticas deve ser plotado como uma reta do tipo x = y;
Para distribuições muito similares, os desvios da reta x = y mostram onde as distribuições são diferentes; Se o q-q plot de duas distribuições puder ser aproximado por uma reta diferente de x = y, as duas distribuições tem a mesma forma mas suas localizações e espalhamento podem diferir; A similaridade de uma distribuição observada para um modelo de distribuição teórico também pode ser analisada utilizando um gráfico do tipo q-q plot. Por exemplo, plotando os quantis de V contra os quantis de uma distribuição normal ou lognormal padrão.

11
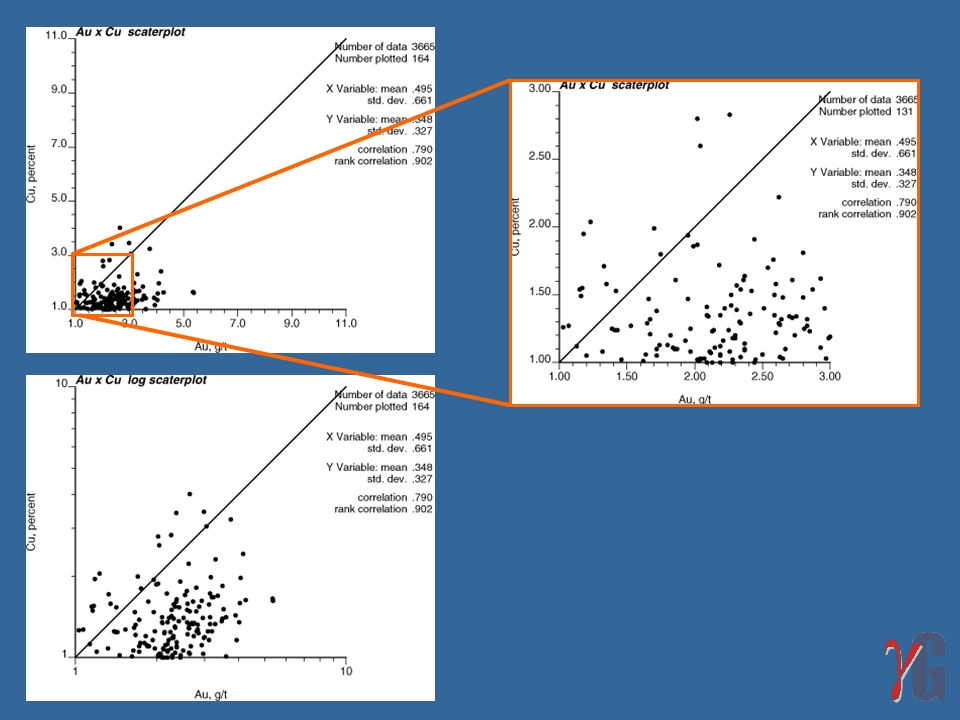
Scatterplots A forma mais comum de apresentar dados bivariados é no gráfico de dispersão ou scatterplot, um gráfico do tipo x-y no qual o eixo x corresponde aos valores de uma variável e a coordenada y aos valores da outra variável.

12
Apesar de haver um espalhamento na nuvem de pontos, os valores altos de V tendem a estar associados com valores altos de U da mesma forma que os valores baixos de V estão associados com os valores baixos de U; Além de fornecer uma idéia qualitativa de como as duas distribuições estão relacionadas, o scatterplot é útil para chamar atenção sobre dados discrepantes; Em caso de distribuições altamente assimétricas, recomenda-se o uso de dois scatterplots, um mostrando detalhes perto da origem e outro a relação geral; O uso de escala logarítmica nos dois eixos permite mostrar adequadamente toda a distribuição em um único gráfico.

14
Histogramas As informações de um scatterplot podem ser sumarizadas contando o número de pares de amostras que caem em uma certa classe, definida pelos limites das duas variáveis.

15
Em um histograma bivariado as distribuições univariadas de cada variável podem ser calculadas somando o número de ocorrências ao longo de colunas e linhas. Histogramas marginais.

16
Correlação De forma simplificada, há três padrões que podem ser observados entre as variáveis em um scatterplot: correlação positiva; correlação negativa; ausência de correlação. O coeficiente de correlação () é o parâmetro estatístico mais freqüentemente utilizado para sumarizar a relação entre duas variáveis e é calculado por:
 é o parâmetro estatístico mais freqüentemente utilizado para sumarizar a relação entre duas variáveis e é calculado por:")
17
O numerador da equação do coeficiente de correlação () é chamado de covariância:
A covariância entre duas variáveis depende da magnitude dos valores dos dados. Se todos os pares de dados V-U forem multiplicados por 10, enquanto o scatterplot vai permanecer com o mesmo aspecto (apenas com os eixos re-escalonados), a covariância será 100 vezes maior.
, a covariância será 100 vezes maior.")
18
Alta covariância positiva:
Covariância próxima de zero: Grande covariância negativa:

19
Dividindo a covariância pelo desvio padrão das duas variáveis, garante-se que o coeficiente de correlação estará sempre entre -1 e +1, fornecendo um índice que é independente da magnitude dos valores dos dados.

20
Freqüentemente chamado na literatura estatística de coeficiente de correlação de Pearson, o coeficiente de correlação () apresenta algumas deficiências: é uma medida de dependência linear entre duas variáveis; é sensível a pontos que plotem afastados da nuvem principal de pontos.

21
Utilizado para complementar a informação fornecida pelo coeficiente de correlação linear, o coeficiente de correlação de rank (R) ou coeficiente de correlação de Spearman é calculado por: x y rank de x rank de y = rank = 0.904

22
Existe correlação (monotônica), porém não necessariamente linear;
Alguns poucos pares de valores extremos podem arruinar uma possível boa correlação; Alguns poucos pares de valores extremos podem levar a uma falsa idéia de existir uma boa correlação.

23
Regressão Como foi salientado anteriormente, uma forte relação entre duas variáveis pode ajudar-nos a inferir uma variável desde que a outra seja conhecida. A forma mais simples para executar esse tipo de previsão é a regressão linear, na qual assumimos que a dependência de uma variável em função da outra pode ser descrita pela equação da reta do tipo: Os coeficientes a e b são obtidos pelo método dos Mínimos Quadrados (a reta ajustada aos pontos do mapa de dispersão (x versus y) visa minimizar a soma dos quadrados dos erros, sendo erro a diferença entre o valor real e a estimativa de Y). x e y = valores dos atributos X e Y. Por exemplo, teor de cobre (X) e teor de ouro (Y)
 visa minimizar a soma dos quadrados dos erros, sendo erro a diferença entre o valor real e a estimativa de Y). x e y = valores dos atributos X e Y. Por exemplo, teor de cobre (X) e teor de ouro (Y)")
24
O ângulo de inclinação, a, e a constante, b, são dados por:
ou n – número de dados usados na regressão mx – média de x my – média de y r – coeficiente de correlação

25
Se usarmos os 100 pares de valores de V-U para calcular a equação de regressão linear para prever os valores de V a partir de U, teremos:

26
Intervalo de Confiança Para o Valor de Y
Anteriormente, foi obtida a estimativa (y’) do atributo Y, considerando o valor do atributo X, em um mesmo local. Considerando a estimativa y’ e o possível erro associado à essa estimativa, pode-se determinar o intervalo que contém o verdadeiro valor de Y. A seguinte equação define o intervalo que contém o valor real de Y, com uma confiança de 100(1-)% x = valor de X utilizado na regressão t = distribuição t-student onde: S2y/x é a variância do erro da regressão Suposição: Para um dado valor x, a distribuição dos possíveis valores de Y é normal
 do atributo Y, considerando o valor do atributo X, em um mesmo local. Considerando a estimativa y’ e o possível erro associado à essa estimativa, pode-se determinar o intervalo que contém o verdadeiro valor de Y. A seguinte equação define o intervalo que contém o valor real de Y, com uma confiança de 100(1-)% x = valor de X utilizado na regressão. t = distribuição t-student. onde: S2y/x é a variância do erro da regressão. Suposição: Para um dado valor x, a distribuição dos possíveis valores de Y é normal.")
27
Mesmo exemplo usando 100 pares de U e V
No exemplo: Confiança de 95% A largura do intervalo de confiança varia com o x utilizado na regressão. Essa largura é mínima quando o x é igual à média de X

28
Continuando com a teoria sobre regressão...
Quando utiliza-se regressões para sumarizar a relação de duas variáveis, deve-se atentar se a curva da função ajustada descreve adequadamente a relação em faixas de valores que nos interesse.

29
Embora saiba-se que um polinômio de ordem elevada sempre proverá um melhor ajuste no sentido puramente matemático, deve-se atentar se a curva da função ajustada descreve adequadamente a relação física esperada entre as duas variáveis. Algumas vezes pode-se estar somente representando peculiaridades dos dados disponíveis sem nenhum sentido prático/físico

30
Distribuição condicional

31
Em caso de termos que analisar um número grande de histogramas condicionais, todos com o sumário estatístico completo, faz-se útil uma ferramenta de análise mais concisa, usar gráficos mostrando como as estatísticas condicionais mudam em função dos dados condicionantes.

32
Gráficos de estatísticas condicionais podem ser sumarizados ajustando uma função a ele.
Embora a regressão seja comumente utilizada para sumarizar as variações da média de uma das variáveis, na medida que um segundo atributo varia, outras estatísticas também podem ser calculadas usando o mesmo procedimento (desvio padrão, por exemplo).
.")
Apresentações semelhantes