Carregar apresentação
A apresentação está carregando. Por favor, espere

1
Análise Exploratória de Dados
R – 03 de junho de 2008

2
Objetivos Análise bivariada: uma variável qualitativa e
uma quantitativa: representar graficamente as duas variáveis combinadas; definir e calcular uma medida de associação entre as variáveis.

3
Exemplo 1 Os dados referem-se ao exemplo 2.1 do livro-texto (Bussab e Morettin, pag. 11) Arquivo: ciaMB.txt Conteúdo: informações sobre estado civil, grau de instrução, número de filhos, salário (expresso como fração do salário mínimo), idade (medida em anos e meses) e procedência de 36 empregados da seção de orçamentos da Companhia MB.
, idade (medida em anos e meses) e procedência de 36 empregados da seção de orçamentos da Companhia MB.")
4
Exemplo 1: nomes das variáveis no arquivo
ecivil: variável nominal cujos níveis são solteiro ou casado. instrucao: variável ordinal cujos níveis são F(Ensino Fundamental), M(Ensino Médio) e S(Ensino Superior). nfilhos: número de filhos (apenas para os funcionários casados), entre os solteiros a informação está como NA.
, M(Ensino Médio) e S(Ensino Superior). nfilhos: número de filhos (apenas para os funcionários casados), entre os solteiros a informação está como NA.")
5
Exemplo 1: nomes das variáveis no arquivo
sal: salário expresso como fração do salário mínimo idadea: idade em anos completos idadem: meses rp: região de procedência (interior, capital e outros).
.")
6
Exemplo 1:salário versus nível de instrução
Suponha que estejamos interessados em analisar o comportamento dos salários dentro de cada nível de instrução, ou seja, investigar o comportamento conjunto das variáveis sal e instrucao. Para facilitar, vamos primeiro ordenar os dados numa nova base (dadosord) pela variável instrução.
 pela variável instrução.")
7
Ordenando por instrução
dados=read.table(“ indice=order(dados$instrucao) dadosord=dados[indice,] table(dados$instrucao) F M S Logo, em dadosord as observações de 1 a 12 são de empregados com Ensino Fundamental, de 13 a 30 com Ensino Médio e de 31 a 36 com Ensino Superior.
 indice=order(dados$instrucao) dadosord=dados[indice,] table(dados$instrucao) F M S Logo, em dadosord as observações de 1 a 12 são de. empregados com Ensino Fundamental, de 13 a 30 com. Ensino Médio e de 31 a 36 com Ensino Superior.")
8
dadosord ecivil instrucao filhos sal idadea idadem rp
1 solteiro F NA interior 2 casado F capital 3 casado F capital 5 solteiro F NA outra 6 casado F interior 7 solteiro F NA interior 8 solteiro F NA capital 12 solteiro F NA capital 14 casado F outra 18 casado F outra 23 solteiro F NA outra 27 solteiro F NA outra 4 solteiro M NA outra 9 casado M capital 10 solteiro M NA outra 11 casado M interior 13 solteiro M NA outra 15 casado M interior 16 solteiro M NA outra 17 casado M capital 20 solteiro M NA interior 21 casado M outra 22 solteiro M NA capital 25 casado M interior 26 casado M outra 28 casado M interior 29 casado M interior 30 casado M capital 32 casado M interior 35 casado M capital 19 solteiro S NA interior 24 casado S outra 31 solteiro S NA outra 33 casado S capital 34 solteiro S NA capital 36 casado S interior observações de 1 a 12 em dadosord dadosord observações de 13 a 30 em dadosord observações de 31 a 36 em dadosord

9
Medidas resumo por nível de instrução
Vamos começar descrevendo o comportamento dos salários por nível de instrução, a partir das estatísticas resumo dentro de cada nível. sink(“a:\\relatorio1.txt”) #gera um relatório no disquete “Comportamento de salários para Ensino Fundamental” summary(dadosord$sal[1:12]) “Desvio-padrão:” sd(dados$sal[1:12]) “Comportamento de salários para Ensino Médio” summary(dadosordsal[13:30]) sd(dadosord$sal[13:30]) “Comportamento de salários para Ensino Superior” summary(dadosord$sal[31:36]) sd(dadosord$sal[31:36]) sink() #fecha o relatório
 #gera um relatório no disquete. Comportamento de salários para Ensino Fundamental summary(dadosord$sal[1:12]) Desvio-padrão: sd(dados$sal[1:12]) Comportamento de salários para Ensino Médio summary(dadosordsal[13:30]) sd(dadosord$sal[13:30]) Comportamento de salários para Ensino Superior summary(dadosord$sal[31:36]) sd(dadosord$sal[31:36]) sink() #fecha o relatório.")
10
Lista de comandos source(“ O conteúdo será gravado no arquivo relatorio1.txt no disquete no drive A Se você preferir, edite o arquivo instrusal.txt e na primeira linha altere o endereço e/ou o nome do arquivo que conterá os resultados.

11
[1] "Comportamento de salários para Ensino Fundamental"
Min. 1st Qu. Median Mean 3rd Qu. Max. desvio-padrão: [1] "Comportamento de salários para Ensino Médio" Min. 1st Qu. Median Mean 3rd Qu. Max. desvio-padrão: [1] "Comportamento de salários para Ensino Superior" Min. 1st Qu. Median Mean 3rd Qu. Max. desvio-padrão:
![[1] Comportamento de salários para Ensino Fundamental](http://slideplayer.com.br/slide/1600594/5/images/11/%5B1%5D+Comportamento+de+sal%C3%A1rios+para+Ensino+Fundamental.jpg "Min. 1st Qu. Median Mean 3rd Qu. Max desvio-padrão: [1] Comportamento de salários para Ensino Médio Min. 1st Qu. Median Mean 3rd Qu. Max desvio-padrão: [1] Comportamento de salários para Ensino Superior Min. 1st Qu. Median Mean 3rd Qu. Max desvio-padrão:")
12
Resumindo Resumindo nível fundamental médio superior
mínimo ,00 5,73 10,53 Q ,01 8,84 13,65 Q ,12 10,91 16,74 Q ,16 14,42 18,38 máximo 13,85 19,40 23,30 média ,84 11,53 16,47 desvio padrão 2,96 3,72 4,50 Percebe-se claramente que as medidas de posição crescem conforme aumenta o nível de instrução.

13
Gráfico de salário versus nível de instrução
Quando se dispõe de um par de variáveis, para o qual uma é qualitativa e outra é quantitativa, é comum representar o comportamento conjunto delas usando-se boxplots das distribuições das variáveis quantitativas, segundo as respostas da variável qualitativa. No R podemos usar a função já conhecida plot indicando primeiro o vetor que contém a variável qualitativa.

14
Gráfico de salário versus nível de instrução (1)
plot(dados$instrucao,dados$sal,main="Box-plots de salário segundo o nível de instrução")
")
15
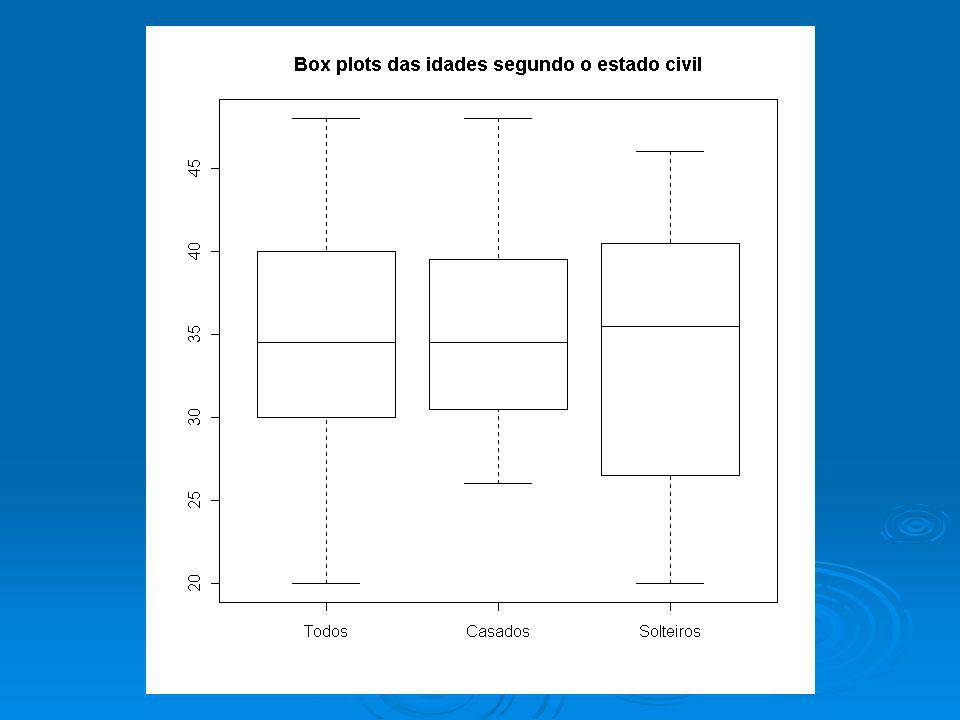
Comportamento dos salários sem discriminar por nível de instrução (todos)
summary(dadosord$sal) Min. 1st Qu. Median Mean 3rd Qu. Max. sd(dados$sal) [1] nível todos fundamental médio superior mínimo , ,00 5,73 10,53 Q , ,01 8,84 13,65 Q , ,12 10,91 16,74 Q , ,16 14,42 18,38 máximo , ,85 19,40 23,30 média , ,84 11,53 16,47 desvio padrão , ,96 3,72 4,50 Ver tabela 2
 Min. 1st Qu. Median Mean 3rd Qu. Max sd(dados$sal) [1] nível todos fundamental médio superior. mínimo 4,00 4,00 5,73 10,53. Q1 7,55 6,01 8,84 13,65. Q2 10,16 7,12 10,91 16,74. Q3 14,06 9,16 14,42 18,38. máximo 23,30 13,85 19,40 23,30. média 11,12 7,84 11,53 16,47. desvio padrão 4,59 2,96 3,72 4,50. Ver tabela 2.")
16
boxplot(dados$sal,dadosord$sal[1:12],dadosord$sal[13:30], dadosord$sal[31:36],names=c("Todos","F","M","S"))
![boxplot(dados$sal,dadosord$sal[1:12],dadosord$sal[13:30], dadosord$sal[31:36],names=c( Todos , F , M , S ))](http://slideplayer.com.br/slide/1600594/5/images/16/boxplot%28dados%24sal%2Cdadosord%24sal%5B1%3A12%5D%2Cdadosord%24sal%5B13%3A30%5D%2C+dadosord%24sal%5B31%3A36%5D%2Cnames%3Dc%28+Todos+%2C+F+%2C+M+%2C+S+%29%29.jpg "boxplot(dados$sal,dadosord$sal[1:12],dadosord$sal[13:30], dadosord$sal[31:36],names=c( Todos , F , M , S ))")
17
Comentário É possível perceber, a partir destes dados e gráficos, uma dependência entre salário e nível de instrução: o salário tende a ser maior conforme é maior a escolaridade do empregado.

18
Exemplo 2: salário versus região de procedência
Vamos agora analisar o comportamento dos salários dentro de cada região de procedência, ou seja, investigar o comportamento conjunto das variáveis cujos nomes na base de dados são sal e rp. Para facilitar, vamos primeiro ordenar os dados numa nova base (dadosrp) pela variável rp.
 pela variável rp.")
19
Ordenando por Região de Procedência
indice=order(dados$rp) dadosrp=dados[indice,] table(dados$rp) capital interior outra Logo, em dadosrp as observações de 1 a 11 são de empregados cuja procedência é a capital, de 12 a 23 é o interior e de 24 a 36 são outras regiões.
 dadosrp=dados[indice,] table(dados$rp) capital interior outra Logo, em dadosrp as observações de 1 a 11 são de. empregados cuja procedência é a capital, de 12 a 23. é o interior e de 24 a 36 são outras regiões.")
20
Medidas resumo por região de procedência
sink(“a:\\relatoriorp.txt”) #abre arquivo que conterá os resultados “Comportamento de salários para Capital” summary(dadosrp$sal[1:11]) ‘’Desvio-padrão:’’ sd(dadosrp$sal[1:11]) “Comportamento de salários para Interior” summary(dadosrp$sal[12:23]) sd(dadosrp$sal[12:23]) “Comportamento de salários para Outras” summary(dadosrp$sal[24:36]) sd(dadosrp$sal[24:36]) sink() # fecha arquivo
 #abre arquivo que conterá os resultados. Comportamento de salários para Capital summary(dadosrp$sal[1:11]) ‘’Desvio-padrão:’’ sd(dadosrp$sal[1:11]) Comportamento de salários para Interior summary(dadosrp$sal[12:23]) sd(dadosrp$sal[12:23]) Comportamento de salários para Outras summary(dadosrp$sal[24:36]) sd(dadosrp$sal[24:36]) sink() # fecha arquivo.")
21
Lista de comandos source(“ O conteúdo será gravado no arquivo relatoriorp.txt no disquete no drive A Se você preferir, edite o arquivo rpsal.txt e na primeira linha altere o endereço e/ou o nome do arquivo que conterá os resultados.

22
[1] "Comportamento de salários para Capital"
Min. 1st Qu. Median Mean 3rd Qu. Max. desvio-padrão: [1] "Comportamento de salários para Interior" Min. 1st Qu. Median Mean 3rd Qu. Max. desvio-padrão: [1] "Comportamento de salários para Outras" Min. 1st Qu. Median Mean 3rd Qu. Max. desvio-padrão:
![[1] Comportamento de salários para Capital](http://slideplayer.com.br/slide/1600594/5/images/22/%5B1%5D+Comportamento+de+sal%C3%A1rios+para+Capital.jpg "Min. 1st Qu. Median Mean 3rd Qu. Max desvio-padrão: [1] Comportamento de salários para Interior Min. 1st Qu. Median Mean 3rd Qu. Max desvio-padrão: [1] Comportamento de salários para Outras Min. 1st Qu. Median Mean 3rd Qu. Max desvio-padrão:")
23
Resumindo: salário versus região de procedência
todos Capital Interior Outros mínimo 4,00 4,56 4,00 5,73 Q1 7,55 7,49 7,81 8,74 Q2 10,16 9,77 10,65 9,80 Q3 14,06 16,63 14,70 12,79 máximo 23,30 19,40 23,30 16,22 média 11,12 11,46 11,55 10,45 desvio-padrão 4,59 5,48 5,30 3,14 Volta

24
Gráfico de salário versus região de procedência
plot(dados$rp,dados$sal,main="Box-plots de salário segundo a região de procedência")
")
25
Comportamento dos salários sem discriminar por nível de instrução (todos)
boxplot(dados$sal,dadosrp$sal[1:11],dadosrp$sal[12:23], dadosrp$sal[24:36],names=c("Todos",”Capital",”Interior”, ”Outras"))
)")
26
Comentário É possível perceber, a partir destes dados e gráficos que não há uma relação bem definida entre salário e região de procedência. Os salários parecem estar mais relacionados com o nível de instrução do que com a região de procedência.

27
Problema Como quantificar a dependência entre estas variáveis?
No caso de duas variáveis quantitativas usa-se a correlação. No caso de duas variáveis qualitativas usa-se o qui-quadrado. O que usar no caso de uma variável qualitativa e uma quantitiativa?

28
Medida de dependência: uma variável qualitativa e uma quantitativa
Vamos usar as variâncias dentro de cada categoria de resposta da variável qualitativa e a variância global, para definir uma medida de associação entre uma variável qualitativa e uma quantitativa.

29
Medida de dependência: uma variável qualitativa e uma quantitativa (1)
Se a variância dentro de cada categoria de resposta for pequena e menor do que a global, significa que a variável qualitativa melhora a capacidade de previsão da variável quantitativa e, portanto, existe uma relação entre as duas variáveis. Ver tabela 1

30
Instrução versus salário
Região de procedência versus salário Parece haver uma melhora na capacidade de previsão de salário, segundo o nível de instrução. Não parece haver melhora na capacidade de previsão de salário, segundo a região de procedência.

31
Medida de dependência: uma variável qualitativa e uma quantitativa (2)
Observe que para as variáveis salário e instrução, as variâncias dentro de cada nível são menores do que a variância global: var(dados$sal) # variância global de salários var(dadosord$sal[1:12]) #var. de salários para Ens. Fund. var(dadosord$sal[13:30]) #var. de salários para Ens. Médio var(dadosord$sal[31:36]) #var. de salários para Ens. Sup.
 # variância global de salários var(dadosord$sal[1:12]) #var. de salários para Ens. Fund var(dadosord$sal[13:30]) #var. de salários para Ens. Médio var(dadosord$sal[31:36]) #var. de salários para Ens. Sup")
32
Medida de dependência: uma variável qualitativa e uma quantitativa (3)
Para as variáveis sal e rp, vemos que as variâncias dentro de cada região de procedência não são menores do que a global: var(dados$sal) # variância global de salários var(dadosrp$sal[1:11]) #var. de salários para capital var(dadosrp$sal[12:23]) #var. de salários para interior var(dadosrp$sal[24:36]) #var. de salários para outra
 # variância global de salários var(dadosrp$sal[1:11]) #var. de salários para capital var(dadosrp$sal[12:23]) #var. de salários para interior var(dadosrp$sal[24:36]) #var. de salários para outra")
33
Medida de dependência: uma variável qualitativa e uma quantitativa (4)
Utiliza-se a média das variâncias, porém ponderada pelo número de observações em cada categoria, ou seja, Essa variância média será comparada à variância global.

34
Medida de dependência: uma variável qualitativa e uma quantitativa (5)
número de categorias de resposta da variável qualitativa número de observações na i-ésima categoria de resposta =n (total de observações. variância dentro da i-ésima categoria de resposta, i=1,...,k. Nos dois exemplos trabalhados k foi igual a 3: instrução (F,M,S) e região de procedência (capital,interior,outra).
 e região de procedência. (capital,interior,outra).")
35
Variância dentro de cada grupo
Se xij representa o salário do j-ésimo indivíduo da i-ésima categoria de instrução, i=1,2,3 e j=1,...,ni com ni representando o total de indivíduos com escolaridade de nível i, a variância dentro do i-ésimo nível de scolaridade Vari(S) é dada por representando a média de salário para o nível de escolaridade i. com
 é dada por. representando a média. de salário para o. nível de escolaridade i. com.")
36
Continuação Fórmula para o cálculo de

37
Variância Global é o número total de observações
representa a média global.

38
Medida de dependência: uma variável qualitativa e uma quantitativa (5)
com Var(S) representando a variância global e representando a média ponderada das variâncias dentro de cada categoria da variável qualitativa.
 representando a variância global e. representando a média ponderada das variâncias dentro de cada categoria da variável qualitativa.")
39
é igual a zero

40
soma dos desvios da média em cada
grupo.

41
Portanto, tal que

42
Medida de dependência: uma variável qualitativa e uma quantitativa (6)
O grau de associação entre as duas variáveis é definido como o ganho relativo na variância, obtido pela introdução da variável qualitativa. A medida é baseada na decomposição de somas de quadrados vista anteriormente.

43
Medida de dependência: uma variável qualitativa e uma quantitativa (7)
Se a média das variâncias for muito parecida com a variância global, o ganho relativo na variância será pequeno. Já se a média das variâncias for bem menor do que a variância global, o ganho relativo na variância será grande.

44
Medida de dependência: uma variável qualitativa e uma quantitativa (7)
Observe que 0R2 1. O símbolo R2 é usual em análise de variância e regressão, tópicos que vão ser abordados nas disciplinas Análise de Regressão e Planejamento de Experimentos. Quanto mais próximo de 1 for o valor de R2, maior será a associação.

45
Cálculo de R2 R2 0.4133 Dizemos que 41,33% da variação total
Calcule o R2 para o par salário e instrução. s=35*var(dados$sal)/36 #variância global de salários com denominador n s1=11*var(dadosord$sal[1:12])/12 #var. sal. Ens. Fund. s2=17*var(dadosord$sal[13:30])/18 #var. sal. Ens. Médio s3=5*var(dadosord$sal[31:36])/6 #var.sal. Ens. Superior sbarra=(12*s1+18*s2+6*s3)/36 #média pond. variâncias R2=(s-sbarra)/s #cálculo de R2 R2 Dizemos que 41,33% da variação total do salário é explicada pela variável instrução.
/36 #variância global de salários com denominador n. s1=11*var(dadosord$sal[1:12])/12 #var. sal. Ens. Fund. s2=17*var(dadosord$sal[13:30])/18 #var. sal. Ens. Médio. s3=5*var(dadosord$sal[31:36])/6 #var.sal. Ens. Superior. sbarra=(12*s1+18*s2+6*s3)/36 #média pond. variâncias. R2=(s-sbarra)/s #cálculo de R2. R2 Dizemos que 41,33% da variação total. do salário é explicada pela variável. instrução.")
46
Tabela para o cálculo de R2
Nível F M S total soma simples 94.04 207.51 98.85 400.40 soma de quadrados simples 833.11 ni 12 18 6 36 média 7.84 11.53 16.48 11.12 soma de quadrados corrigida pela média 96.15 234.64 101.36 736.57 432.15 Variação residual Variação total

47
Cálculo de R2 (continuação)
")
48
Cálculo de R2 R2 0.0127 Dizemos que apenas 1,27%
Calcule o R2 para o par salário e região de procedência. s=35*var(dados$sal)/36 #variância global de salários com denominador n s1=10*var(dadosrp$sal[1:11])/11#capital s2=11*var(dadosrp$sal[12:23])/12#interior s3=12*var(dadosrp$sal[24:36])/13#outra sbarra=(11*s1+12*s2+13*s3)/36 R2=(s-sbarra)/s R2 Dizemos que apenas 1,27% da variabilidade dos salários é explicada pela região de procedência.
/36 #variância global de salários com denominador n. s1=10*var(dadosrp$sal[1:11])/11#capital. s2=11*var(dadosrp$sal[12:23])/12#interior. s3=12*var(dadosrp$sal[24:36])/13#outra. sbarra=(11*s1+12*s2+13*s3)/36. R2=(s-sbarra)/s. R2 Dizemos que apenas 1,27% da variabilidade dos salários. é explicada pela região de procedência.")
49
Tabela para o cálculo de R2
Região capital interior outra total soma simples 126.01 138.60 135.79 400.40 soma de quadrados simples ni 11 12 13 36 média 11.46 11.55 10.45 11.12 soma de quadrados corrigida 299.94 308.53 118.73 736.57 727.19

50
Cálculo de R2 (continuação)
")
51
Observação A comparação dos valores de R2 em cada exemplo confirma comentário anterior de que há uma relação entre salário e instrução e, que entre salário e região de procedência, não há relação.

52
Usando funções do R para calcular o R2
No R, o comando aov(dados$sal~dados$instrucao), gerará a seguinte tabela: Terms: dados$instrucao Residuals Sum of Squares Deg. of Freedom é a variação residual é a variação devido aos grupos – numerador de R2 Logo,
, gerará a seguinte tabela: Terms: dados$instrucao Residuals. Sum of Squares Deg. of Freedom é a variação. residual. é a variação devido aos grupos – numerador de R2. Logo,")
53
Salário versus região de procedência
aov(dados$sal~dados$rp) Terms: dados$rp Residuals Sum of Squares Deg. of Freedom Logo,
 Terms: dados$rp Residuals. Sum of Squares Deg. of Freedom Logo,")
54
Revendo as fórmulas Decomposição da variação total – soma de quadrados total - SQ variação devida aos grupos – SQExp variação total - SQTot variação residual - SQRes

56
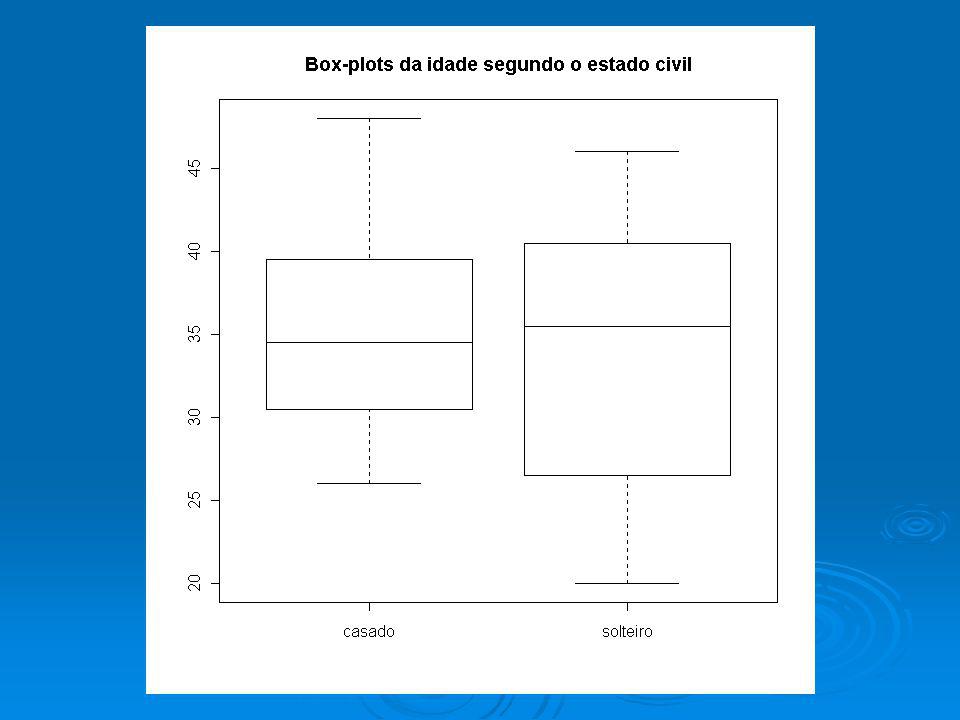
Exercício 1 Calcule o grau de associação entre as variáveis estado civil e idade (em anos completos) nos dados da companhia MB. > indice=order(dados$ecivil) > dadosec=dados[indice,] > table(dados$ecivil) casado solteiro > s=35*var(dados$idadea)/36 > s1=19*var(dadosec$idadea[1:20])/20 > s2=15*var(dadosec$idadea[21:36])/16 > sbarra=(20*s1+16*s2)/36 > R2=(s-sbarra)/s > R2 [1] Sugestão: R.: O estado civil explica apenas 0,9% da variabilidade total da idade.
 > dadosec=dados[indice,] > table(dados$ecivil) casado solteiro > s=35*var(dados$idadea)/36. > s1=19*var(dadosec$idadea[1:20])/20. > s2=15*var(dadosec$idadea[21:36])/16. > sbarra=(20*s1+16*s2)/36. > R2=(s-sbarra)/s. > R2. [1] Sugestão: R.: O estado civil explica apenas 0,9% da variabilidade total da idade.")
57
Exercício 1 (cont.) Alternativamente, aov(dados$idadea~dados$sal)
Terms: dados$ecivil Residuals Sum of Squares Deg. of Freedom R2=14.45/( ) > R2 [1]
 > R2. [1]")
60
Exercício 2 Voltando aos dados da pesquisa de telemarketing (telemark.TXT), investigue possíveis dependências entre os seguintes pares de variáveis: cia e uso renda e uso instrucao e uso idade e uso.

62
aov(tel$uso~tel$cia)
Call: aov(formula = tel$uso ~ tel$cia) Terms: tel$cia Residuals Sum of Squares Deg. of Freedom R2= /( ) > R2 [1] R.: A Companhia explica apenas cerca de 3% da variabilidade total da variável uso.
 Terms: tel$cia Residuals. Sum of Squares Deg. of Freedom R2= /( ) > R2. [1] R.: A Companhia explica apenas cerca de 3% da variabilidade. total da variável uso.")
63
Renda versus uso

64
Renda versus uso Call: aov(formula = tel$uso ~ tel$renda) Terms:
tel$renda Residuals Sum of Squares Deg. of Freedom > R2= /( ) > R2 [1] R.: A faixa de renda explica apenas cerca de 4,7% da variabilidade total da variável uso.
 > R2. [1] R.: A faixa de renda explica apenas cerca de 4,7% da. variabilidade total da variável uso.")
65
Instrução e uso

66
Instrução e uso > aov(tel$uso~tel$instrucao) Call:
aov(formula = tel$uso ~ tel$instrucao) Terms: tel$instrucao Residuals Sum of Squares Deg. of Freedom > R2= /( ) > R2 [1] R.: A escolaridade explica apenas cerca de 4,4% da variabilidade total da variável uso.
 Terms: tel$instrucao Residuals. Sum of Squares Deg. of Freedom > R2= /( ) > R2. [1] R.: A escolaridade explica apenas cerca de 4,4% da. variabilidade total da variável uso.")
67
Idade e uso

68
Idade e uso Call: aov(formula = tel$uso ~ tel$idade) Terms:
tel$idade Residuals Sum of Squares Deg. of Freedom R2= /( ) > R2 [1] R.: A idade explica apenas cerca de 3,2% da variabilidade total da variável uso.
 > R2. [1] R.: A idade explica apenas cerca de 3,2% da variabilidade. total da variável uso.")
69
Conclusão Pelas análises feitas, não percebe-se nenhuma dependência entre a variável intensidade de uso do telefone e as variáveis cia, renda, idade e escolaridade.

70
Funções do R usadas na aula de hoje:
read.table order sink summary sd var plot boxplot aov (analysis of variance)
")
Apresentações semelhantes


 – Lápides 1, 2, 3» «nomes gravados, 21 de Agosto de 2008» «Ultramar.TerraWeb»>")






. Nenhuns direitos reservados, excepto para fins comerciais. Por favor, não coloque.>")



 2.Comparação.>")







>")