Carregar apresentação
1
Adriano Melo Amora Albuquerque Anália Lima Eduardo Pires Ivan França
Sistemas de RI na Web Adriano Melo Amora Albuquerque Anália Lima Eduardo Pires Ivan França

2
Roteiro Introdução Objetivos Entendendo a Web Arquiteturas Técnicas
Estratégia de Busca Crawlers Browsing Metabuscas Conclusão

3
A Web Pode ser vista como uma grande base de dados não estruturada e ubíqua Surge a necessidade de ferramentas para gerenciar, buscar e filtrar informações

4
Formas de busca na Web Engenhos de busca Diretórios de sites
Exploração de hyperlinks

6
+1.000.000.000 de buscas são realizadas por dia
Google data, September 2010

7
+1.000.000.000 de pessoas usam o google a cada semana
Google data, September 2010

8
feitas nos últimos 90 dias nunca tinham sido feitas antes
20% das buscas feitas nos últimos 90 dias nunca tinham sido feitas antes Google Internal Data, April 2010

9
de pageviews são realizados por mês no reino unido*
> 4 bilhões de pageviews são realizados por mês no reino unido* * dados de abril de 2010

10
estão indexadas no Google Images*
10 bilhões de imagens estão indexadas no Google Images* (eram 250 milhões em 2001) * TechCrunch, July 2010
 * TechCrunch, July")
12
filmes é a equivalência do total de uploads de vídeos feitos no YouTube por mês

13
de execuções de vídeos foram realizadas no YouTube em 2010
700 bilhões de execuções de vídeos foram realizadas no YouTube em 2010

14
são gastas por mês vendo os vídeos do YouTube
2.9 bilhões de horas são gastas por mês vendo os vídeos do YouTube

15
quem tem acesso a esse conteúdo?
todo mundo! (exceto os vídeos do YouTube)
")
17
estão cadastradas no facebook*
600 milhões de pessoas estão cadastradas no facebook* (250 milhões entraram em 2010) * Fim de 2010
 * Fim de")
18
são gastas por mês nas páginas do site
9.3 bilhões de horas são gastas por mês nas páginas do site

19
como links e notícias são compartilhados a cada mês no facebook
30 bilhões de documentos como links e notícias são compartilhados a cada mês no facebook

20
Quem tem acesso a esse conteúdo?
bind e os usuários do facebook

21
Desafios Grande quantidade de dados Dados voláteis (mudam muito rápido) Acesso ao conteúdo produzido em redes sociais Conteúdo heterogêneo (multimídia, linguagem) Informações redundantes e não estruturadas
 Acesso ao conteúdo produzido em redes sociais Conteúdo heterogêneo (multimídia, linguagem) Informações redundantes e não estruturadas")
22
Entendendo a Web

23
Caracterização da WEB Mensurando a WEB Organização atual da WEB
Arquiteturas

24
Mensurando a WEB Qual o número de computadores conectados a internet?
Qual o número de websites na internet? Mensurar a WEB de maneira precisa é uma tarefa difícil devido a sua natureza altamente dinâmica. Hoje, há mais de 500 milhões de computadores conectados a internet, em mais de 200 países.

25
Mensurando a WEB Qual o número de computadores conectados a internet?
500 milhões de hosts, em mais de 200 países.

26
Mensurando a WEB

27
Mensurando a WEB

28
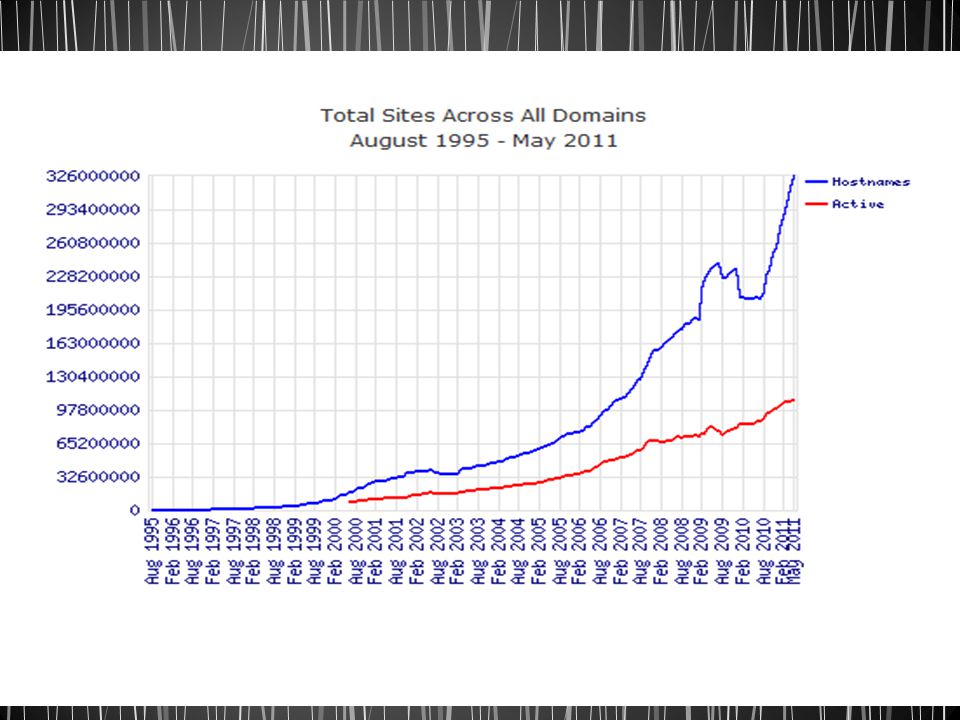
Mensurando a WEB Qual o número de websites na internet?
O Netcraft roda desde agosto de 1995 Em maio de 2011 foram recebidas respostas de mais de 324 milhões websites.

30
Organização atual da WEB
WEB é uma coleção não controlada de documentos. Inserção de documentos Formato dos documentos Engenhos de busca Recuperar informações na WEB Permitir a consulta por usuários Ao contrário de uma biblioteca, a Web é uma coleção não controlada de documentos, ou seja, a todo instante, documentos estão sendo inseridos e modificados por diferentes pessoas, sendo o conteúdo e formato desses documentos os mais variados possíveis. Para poder lidar com as características da Web, surgiu uma nova geração de SRIs, os Mecanismos de Busca, ou Engenhos de Busca, ou ainda Máquinas de Busca.

31
Engenhos de Busca Arquitetura Centralizada Distribuída
Usa crawlers(rastreadores) Distribuída A busca é realizada utilizando um esforço de coordenação entre vários gatherers e brokers
 Distribuída. A busca é realizada utilizando um esforço de coordenação entre vários gatherers e brokers.")
32
Arquitetura Centralizada

33
Arquitetura Centralizada
Crawlers (robots, spiders, wanderers) Buscam páginas na WEB Enviam para um servidor principal Roda em um sistema local Envia requisições servidores web remotos Quanto às arquiteturas, a maioria das engines de busca utilizam uma arquitetura centralizada baseada em crawlers (ratreadores). Crawlers são programas que buscam na web por novas páginas ou atualizações nas páginas e eviam tais páginas para um servidor principal onde tais páginas serão indexadas. Crawlers são também chamados de robots, spiders, wanderers, walkers, and knowbots. Um crawler não se move e nem roda em máquinas remotas, em vez disso um crawler roda em um sistema local e envia requisições para servidores web remotos.
 Buscam páginas na WEB. Enviam para um servidor principal. Roda em um sistema local. Envia requisições servidores web remotos. Quanto às arquiteturas, a maioria das engines de busca utilizam uma arquitetura centralizada baseada em crawlers (ratreadores). Crawlers são programas que buscam na web por novas páginas ou atualizações nas páginas e eviam tais páginas para um servidor principal onde tais páginas serão indexadas. Crawlers são também chamados de robots, spiders, wanderers, walkers, and knowbots. Um crawler não se move e nem roda em máquinas remotas, em vez disso um crawler roda em um sistema local e envia requisições para servidores web remotos.")
34
Arquitetura Centralizada
Indexer Cada página baixada é processada localmente A informação indexada é salva e a página é descartada Exceção: alguns sites de busca mantêm um cachê local algumas cópias das páginas mais populares

35
Arquitetura Centralizada
Principais dificuldades Recolha dos dados Natureza dinâmica da WEB Volume de dados Sobrecarga nos servidores web Requisições de diferentes crawlers Tráfego na WEB Objetos recolhidos pelos crawlers Informações recolhidas independentemente Sem coordenação

36
Arquitetura Distribuída
Novos elementos Gatheres (recolhedores) Brokers
 Brokers.")
37
Arquitetura Distribuída
Gatherers (recolhedores) Coletar e extrair informações de um ou mais servidores WEB Tempos de coletas são periódicos definidos pelo sistema
 Coletar e extrair informações de um ou mais servidores WEB. Tempos de coletas são periódicos. definidos pelo sistema.")
38
Arquitetura Distribuída
Brokers Obtém informações extraídas pelo Gatherer Recuperam informações de Brokers Mecanismo de indexação Atualizando índices Interface de consulta

39
Arquitetura Distribuída
Vantagens Redução na carga dos servidores web Gatherers podem rodar em um servidor web sem gerar tráfego externo Redução no tráfego da rede Arquitetura centralizada retém todo os documentos, enquanto que a arquitetura distribuída move apenas o que é extraído pelos Gatherers Evita trabalho redundante Um gatherer envia informações para vários brokers, reduzindo repetição do trabalho

40
Ranking na Web

41
Base dos algoritmos mais utilizados
Considerar a relevância de web pages por meio dos links Incomming links Outgoing Links

42
Conceitos Básicos Uma página da web valiosa e informativa é geralmente apontado por um grande número de hiperlinks, ou seja, ele tem um grande indegree (“grau de entrada”) . Essa página é chamada um “authority” Uma página da Web que aponta para muitas páginas “authority” é um recurso útil e é chamado de “hub”. Um “hub” tem geralmente uma grande outdegree (“grau de saída”). LINK ANALYSIS: HUBS AND AUTHORITIES ON THE WORLD WIDE WEB [CHRIS H.Q. DING, HONGYUAN ZHA , XIAOFENG HE , PARRY HUSBANDS , ANDHORST D. SIMON]
 . Essa página é chamada um authority Uma página da Web que aponta. para muitas páginas authority é um recurso útil e é chamado de hub . Um hub tem geralmente uma grande outdegree ( grau de saída ). LINK ANALYSIS: HUBS AND AUTHORITIES ON THE WORLD WIDE WEB. [CHRIS H.Q. DING, HONGYUAN ZHA , XIAOFENG HE , PARRY HUSBANDS , ANDHORST D. SIMON]")
43
Hypertext Induced Topic Selection (HITS)
O algoritmo foi criado por Jon Kleinberg Precursor do Page Rank, utilizado pelo Google. O algoritmo atribui pontuações de importância para os hubs e authorities seguindo este conceito: Uma boa authority deve ser apontada por vários bons hubs e um bom hub deve apontar para várias boas authorities.

44
Hypertext Induced Topic Selection (HITS)
Determinar subgrafo (S) composto pelo conjunto de páginas retornadas em uma busca e páginas que apontam e são apontadas por páginas deste conjunto. Realizar várias iterações para determinar um “valor hub” e um “valor authority” para cada página do subgrafo. Esses valores são normalizados. O algoritmo aplica iterações até que pesos de hub e authority cheguem a convergir, isto é, até que estes pesos não variem acima de um valor pré-determinado.
 composto pelo conjunto de páginas retornadas em uma busca e páginas que apontam e são apontadas por páginas deste conjunto. Realizar várias iterações para determinar um valor hub e um valor authority para cada página do subgrafo. Esses valores são normalizados. O algoritmo aplica iterações até que pesos de hub e authority cheguem a convergir, isto é, até que estes pesos não variem acima de um valor pré-determinado.")
45
Hypertext Induced Topic Selection (HITS)
Todo este processamento, que leva cerca de alguns minutos, é realizado no momento da consulta. Por esta razão o HITS não atende ao requisito de tempo imposto pelos engenhos de busca comerciais, que é de poucos segundos. Algumas extensões do algoritmo HITS que adicionaram análise de conteúdo à análise puramente estrutural foram desenvolvidas pelo projeto CLEVER da IBM. Combinando Informações Textuais e Estruturais na Recuperação de Documentos Web. [Roberta de Souza Coelho, Marcelo Nery dos Santos,Silvio Romero Lemos Meira]

46
PageRank PageRank™ é uma família de algoritmos de análise de rede que dá pesos numéricos a cada elemento de uma coleção de documentos hiperligados, como as páginas da Internet, com o propósito de medir a sua importância nesse grupo por meio de um motor de busca. O processo do PageRank™ foi patenteado pela Universidade de Stanford. Somente o nome PageRank™ é uma marca registrada do Google.

47
PageRank e Google O sistema PageRank é usado pelo motor de busca Google para ajudar a determinar a relevância ou importância de uma página. O Google mantém uma lista de bilhões de páginas em ordem de importância, isto é, cada página tem sua importância na Internet como um todo. A importância se dá pelo número de votos que uma página recebe. Um voto é um link em qualquer lugar da Internet para aquela página. Os votos de páginas de alta popularidade na Web contam mais do que os votos de sites de baixa popularidade. Quanto mais links uma página de Web oferece, mais diluído seu poder de votação. Uma boa unidade de medida para definir o PageRank™ de uma página pode ser a percentagem (%) de páginas que ela é mais importante. Por exemplo, se uma página tem PageRank™ de 33% significa que ela é mais importante que um terço de toda a Internet. Se o seu PageRank™ é 99% significa que ela é superior a quase todas as páginas da Internet.
 de páginas que ela é mais importante. Por exemplo, se uma página tem PageRank™ de 33% significa que ela é mais importante que um terço de toda a Internet. Se o seu PageRank™ é 99% significa que ela é superior a quase todas as páginas da Internet.")
48
PageRank e Google O PageRank faz uma avaliação objetiva da importância de páginas da web, resolvendo uma equação de mais de 500 milhões de variáveis e 2 bilhões de termos. O mecanismo de pesquisa do Google também analisa o conteúdo completo de uma página e os fatores em fontes, subdivisões e a localização exata de cada palavra.

49
Quais os sites com maior PageRank?
O website Search Engine Genie atualizou sua lista dos websites com maior PageRank e tornou a informação pública no dia 20 de janeiro de 2011.

50
Google Caffeine Exibe taxa maior de resultados mais recentes devido sua atualização mais constante. Ocupa cerca de 100 milhões de gigabytes de armazenamento em um banco de dados e adiciona novas informações auma taxa de centenas de milhares de gigabytes por dia.

51
Google Vídeo – Como Google funciona
É possível manipular o PageRank™ atribuindo links descontextualizados com o objetivo da página, modificando a ordenação de resultados na pesquisa pelo Google e induzindo a resultados pouco relevantes ou tendenciosos. Googlebombing failure ou miserable failure: retornava biografia oficial da Casa Branca para o presidente dos EUA, George W. Bush e em sequência a página de Michael Moore, inimigo declarado do presidente dos EUA. NÃO MOSTRAR O VÍDEO!!

52
SEO - Search Engine Optimization
Hoje em dia cerca de 85% do tráfego na Internet inicia-se com uma pesquisa num motor de busca como o Google, o Yahoo ou o Bing Conjunto de técnicas que otimizam os web sites, tornando-os mais aptos a estarem bem colocados nas pesquisas efetuadas pelos potenciais visitantes. São baseados naquilo que os buscadores levam em conta no momento da busca.

53
SEO – Exemplos de fatores considerados
Tempo de registro do domínio (Idade do domínio) Freqüência do conteúdo: regularidade com a qual novo conteúdo é adicionado Originalidade do conteúdo Quantidade de links externos Relevância do site que linka para o seu website Citações e fontes de pesquisa (indica que o conteúdo é de qualidade para pesquisa) Links "quebrados“ Conteúdo inseguro ou ilegal Qualidade da codificação HTML, presença de erros no código
 Freqüência do conteúdo: regularidade com a qual novo conteúdo é adicionado. Originalidade do conteúdo. Quantidade de links externos. Relevância do site que linka para o seu website. Citações e fontes de pesquisa (indica que o conteúdo. é de qualidade para pesquisa) Links quebrados Conteúdo inseguro ou ilegal. Qualidade da codificação HTML, presença de erros no código.")
54
Crawlers SPIDERS, BOTS, etc.

55
Crawlers Coleta automática e sistemática de documentos da Web a serem indexados e consultados pela máquina de busca

56
Crawlers Como funcionam?

57
Crawlers Estratégias de busca:
Em Profundidade - Resulta em uma coleta “focada”, pois o crawler caminha por todo um determinado site antes de ir para o próximo. Pode-se limitar o número de níveis.

58
Crawlers Estratégias de busca:
Em Largura com sufixo de URL - Exemplo: *.terra.com.br. Garante cobertura balanceada entre sites. Técnica bastante utilizada.

59
Crawlers Estratégias baseadas em conectividade
Referências (Backlink count) - Quanto mais links apontando para uma página maior a "importância" dela. Variações recursivas - Links vindos de páginas com maior "importância" tem maior peso. Esta é a técnica usada pelo algoritmo PageRank™.
 - Quanto mais links apontando para uma página maior a importância dela. Variações recursivas - Links vindos de páginas com maior importância tem maior peso. Esta é a técnica usada pelo algoritmo PageRank™.")
60
Crawlers

61
Arquitetura

62
Crawlers

63
Componentes

64
Crawlers Coletores Responsáveis pela requisição de páginas aos servidores HTTP Extraem os links das páginas recebidas e enviam ao escalonador Requisitam do escalonador uma ou mais URLs a serem coletadas Podem realizar um escalonamento local (short term scheduling)
")
65
Crawlers Servidor de Nomes Atendem requisições DNS dos coletores
Mantêm um cache de identificadores DNS (nomes) resolvidos Crucial para evitar que cada coletor faça requisições DNS remotas
 resolvidos. Crucial para evitar que cada coletor faça requisições DNS remotas.")
66
Crawlers Servidor de Armazenamento
Recebem as páginas ou outros objetos coletados e armazenam em uma base local Fazem a extração (parsing) de texto Podem tratar vários formatos: Postscript, PDF, Word, Powerpoint, etc.
 de texto. Podem tratar vários formatos: Postscript, PDF, Word, Powerpoint, etc.")
67
Crawlers Escalonador Responsável por decidir qual a próxima URL a ser coletada Coordena as ações dos coletores Estratégias de busca (LIFO, FIFO, PageRank) Deve garantir: Protocolo de exclusão Robots.txt Retardo mínimo entre requisições a um mesmo servidor HTTP. Não haverão coletas repetidas
 Deve garantir: Protocolo de exclusão. Robots.txt. Retardo mínimo entre requisições a um mesmo servidor HTTP. Não haverão coletas repetidas.")
68
Crawlers Qual a melhor estratégia de escalonamento?
Coletar k páginas com vários tipos de escalonamento (Randômico, FIFO, backlink e PageRank) Critérios de avaliação: Freqüência de termos, Backlink, PageRank, tipo de URLs Resultado: páginas do domínio stanford.edu Estratégia baseada em PageRank é a melhor Estratégia baseada em FIFO é boa
 Critérios de avaliação: Freqüência de termos, Backlink, PageRank, tipo de URLs. Resultado: páginas do domínio stanford.edu. Estratégia baseada em PageRank é a melhor. Estratégia baseada em FIFO é boa.")
69
Crawlers Qual a melhor estratégia de escalonamento?
Usando somente PageRank como métrica Resultado Estratégia FIFO descobre páginas com alto PageRank primeiro Conclusão Máquinas com ranking baseado em conectividade devem coletar em FIFO

70
Restrições

71
Crawlers Protocolo de exclusão Recomendação informal
Restrições de acesso Delay mínimo entre requisições a um mesmo servidor

72
Crawlers Robots.txt Regras de restrição para navegação automática
Está sempre na URL raiz e deve ser consultado antes Obediência não é obrigatória User-agent: * Disallow: /cgi-bin/ Disallow: /tmp/ Disallow: /junk/ Robots.txt

73
Recomendações

74
Crawlers Respeitar retardo mínimo entre requisições em um mesmo servidor HTTP Usar header “User-Agent” Nome do robô, , responsável, instituição, etc Evitar horários de tráfego intenso Limitar o número de páginas coletadas em sites grandes

75
Crawlers Não coletar tipos de dados não-indexáveis JPG, EXE, …
Cuidado com links relativos <a href=“../../../material/”>Clique aqui</a> Cuidado com Buracos Negros (Spider Traps) Páginas que “prendem” o crawler num loop infinito Links como: Páginas dinâmicas que geram número infinito de páginas (Ex: calendários)
 Páginas que prendem o crawler num loop infinito. Links como: Páginas dinâmicas que geram número infinito de páginas (Ex: calendários)")
76
Browsing

77
Recapitulando... Termos de Busca Termos do sistema Estratégia de Busca
Em RI, a estratégia de busca é geralmente descrita como um subsistema, com o objetivo de traçar estratégias de combinação de termos de busca com os termos do sistema, propiciando a recuperação. Browsing é uma modalidade de busca dentro do subsistema.

78
“A arte de não saber o que se quer até que se encontre”
Browsing “A arte de não saber o que se quer até que se encontre” Contraste da busca direta

79
Browsing Níveis de atenção: - Ao acaso - Quase ao acaso
Atividade não orientada, não programada, não sistemática, informal e casual Níveis de atenção: - Ao acaso Atividade não orientada, não programada, informal, não sistemática, casual que justifica a dificuldade de defini-lo precisamente. Tipo de busca com critérios e objetivos não definidos previamente. Levine (1969), aponta três diferentes níveis de atenção ao se fazer browsing: (1) ao acaso, com uma coleção desconhecida; (2) quase ao acaso, por meio de uma área de um edifício ou coleção previamente exploradas e (3) semideterminado em uma área física limitada ou área intelectual direcionada. - Quase ao acaso - Semideterminado
, aponta três diferentes níveis de atenção ao se fazer browsing: (1) ao acaso, com uma coleção desconhecida; (2) quase ao acaso, por meio de uma área de um edifício ou coleção previamente exploradas e (3) semideterminado em uma área física limitada ou área intelectual direcionada. - Quase ao acaso. - Semideterminado.")
80
Browsing Essencialmente visual Acesso direto, sem mediador
Atividade não orientada, não programada, não sistemática, informal e casual Essencialmente visual o browsing é essencialmente visual e, só se torna possível, através do “acesso direto”, é o que Naves denomina de “livre acesso”. Para o usuário é ter pleno acesso à coleção de uma biblioteca ou ao conteúdo total de um site, sem a ajuda de um mediador, é ter a chance de encontrar, ao acaso, um item que lhe seja interessante Na estratégia de recuperação por browsing, em oposição à querying, o usuário explora visual e espacialmente o conjunto documental, sem necessidade de ter que expressar de forma prévia quais são suas necessidades de informação. Ou seja, o usuário prefere navegar [n]o conjunto documental, e reconhecer visualmente [o] que está buscando, ao invés de especificar suas necessidades mediante a linguagem de consulta. Afinal quando um usuário visita uma página na internet, se adentra nas funcionalidades de um software ou navega em um hiperdocumento, seus movimentos visuais estão em plena atividade, colhendo flashes e analisando pequenos trechos ou conteúdos do objeto. Acesso direto, sem mediador

81
Browsing Navegação Browsing Contexto físico Ponto de destino
Chamamos a atenção aqui para tratar destes dois conceitos – browsing e navegação – que ora se aproximam ora se afastam. Assim fizemos algumas considerações sobre os termos nos diferentes contextos: No contexto físico a expressão “browsing” parece ser mais aceita para definir a ação de explorar um ambiente, como em uma biblioteca, por exemplo. • No contexto virtual as palavras “navegação” e “browsing” são tratadas como sinônimos. Um bom exemplo seriam as palavras “navegador” e “browser” para definir softwares utilizados para acesso ao conteúdo Web. • Na navegação o ponto de destino é definido no início do processo – ainda que, necessariamente, não seja cumprido, já no browsing parece que não existe um ponto de chegada. Mas no contexto virtual, significam a mesma coisa

82
Diretórios Web Ferramentas baseadas em browsing
Classifica o conhecimento humano Pesquisas retornadas são relevantes Diretorios web: ferramentas web que são baseadas em browsing. Pesquisas retornadas são normalmente relevantes apesar da cobertura relativamente pequena (1% das páginas web). Técnica de classifica o conhecimento humano; Cobertura relativamente pequena
. Técnica de classifica o conhecimento humano; Cobertura relativamente pequena.")
83
Meta Buscadores Nem todas as páginas da web estão em todos os engenhos de busca Podem diferir um do outro em como as respostas vão ser rankeadas no resultado final. (em alguns casos o rankeamento não é feito); e em como eles traduzem uma dada query do usuário em uma query para os engenhos de busca e diretórios.
; e em como eles traduzem uma dada query do usuário em uma query para os engenhos de busca e diretórios.")
84
Meta Buscadores Combinação de resultados de diversas fontes
Ordenação por diferentes atributos Navegação mais simples Principais vantagens: Habilidade em combinar os resultados de diversas fontes em apenas uma interface. Podem ser ordenadas por diferentes atributos, que podem ser mais informativos que as respostas de apenas um engenho de busca. Navegação das respostas mais simples. Desvantagem: Diminuição da precisão Diminuição da precisão

85
Busca usando hyperlinks
Inclui: Linguagens de consulta web Busca dinâmica Diminui a performance Linguagens de consulta web: . Não é amplamente usado por diversas razões, incluindo limitação de performance e falta de produtos comerciais. Linguagens de consulta web: até agora as consultas são feitas baseadas no conteúdo de cada página. No entanto, as pesquisas podem incluir também um link entre as páginas web. O modelo de grafos é o mais utilizado para essa representação. Páginas web : nós Hyperlink entre as páginas: arestas. Modelo de semi-estrutura é usado para representar o conteúdo das páginas. A pesquisa pode incluir link entre as páginas O modelo de grafos é o mais utilizado para essa representação

86
Busca usando hyperlinks
Linguagens de consulta web: Nós: Páginas web Arestas: Hyperlink Modelo de semi-estrutura: Conteúdo Por que usar esse tipo de busca? Exemplo: Buscar todas as páginas web que contem pelo menos uma imagem e são acessíveis a partir de um dado site seguindo mais de três links. Pra responder a esse tipo de query, diferentes modelos de dados podem ser utilizados. Os mais importantes são os que rotulam um modelo de grafos para representar as páginas web (nós) e hyperlinks entra as páginas (arestas) , e um modelo de semi estrutura pra representar o conteudo das páginas. Por que usar esse tipo de busca? Combinar estrutura com conteúdo Tem sido estendido para extrair e integrar informações de páginas web, e construir e restruturar estes sites. Combinação de estrutura com conteúdo; É possível extrair e integrar o conteúdo das páginas; Construir e restruturar sites.
 e hyperlinks entra as páginas (arestas) , e um modelo de semi estrutura pra representar o conteudo das páginas. Por que usar esse tipo de busca Combinar estrutura com conteúdo. Tem sido estendido para extrair e integrar informações de páginas web, e construir e restruturar estes sites. Combinação de estrutura com conteúdo; É possível extrair e integrar o conteúdo das páginas; Construir e restruturar sites.")
87
Busca usando hyperlink
Busca dinâmica: Busca online para descobrir informações relevantes dentre os links que foram retornados na busca. Abordagem lenta pra toda web, mas prática pra um subconjunto específico Busca dinâmica: equivalente ao texto de busca sequencial. A idéia é usar uma busca online para descobrir informações relevantes pelos seguintes links. Abordagem lenta pra toda a web, mas pode ser usado em subconjuntos da web. Se baisea na heuristica de que documentos relevantes geralmente tem vizinhos que são também relevantes Heurística: Documentos relevantes geralmente têm vizinhos que também são relevantes

88
Busca usando hyperlinks
Busca dinâmica: Algoritmo Dada uma query, para cada passo: Analisar a página com mais alta prioridade; Se a página for relevante, a heurística decide seguir ou não os links dessa página; Se decidir que sim, novas páginas serão adicionadas à lista. Algoritmo: Dada uma query, para cada passo, analisar a página com mais alta prioridade. Se a página for considerada relevante, a heuristica decide seguir ou não os links desta página. Se decidir que sim, novas páginas serão adicionadas à lista de prioridade, nas posições adequadas.

89
Tendências e Questões de Pesquisa
Modelagem: Adaptação às necessidades da Web; Melhores paradigmas e melhores filtros de informação Consulta: Melhorar a combinação entre estrutura e conteúdo; Processamento de linguagem natural Arquiteturas Distribuídas: elagem: Os modelod de RI precisam ser adaptados as necessidades da web. Nós buscaremos a informação Ou a informação chegará até nós? Em ambos os casos nós precisamos de melhores paradigmas de pesquisa e melhores filtros de informação. Consulta: É necessário trabalhar mais na combinação entre estrutura e conteúdo na consultas bem como em um novo visual para posicionar essas consultas e visualizar as respostas. Futuras linguagens de consulta podem incluir conceitos baseados em pesquisa e processamento de linguagem natural. novos sistemas de distribuição para percorrer e pesquisar na web deve ser concebido para lidar com o crescimento. Isto terá impacto nas atuais técnicas de rastreamento e indexação Lidar com o crescimento da quantidade de informação na web; Qual será o gargalo no futuro? Capacidade dos servidores ou largura de banda?

90
Tendências e Questões de Pesquisa
Ranking: Melhores esquemas de ranking; Exploração tanto no conteúdo como na estrutura; The search engine persuasion problem Indexação: Ranking: melhor esquemas de ranking são necessários, exploração tanto no conteúdo como na estrutura (internos à pagina e hyperlinks); Um problema é que o engenho de busca pode rankear algumas paginas como de alta prioridade deviso a razoes que não são baseadas numa real relevância da página (the search engine persuasin problem). Indexação: Qual é a melhor visão lógica para o texto? O que deve ser indexado? Como explorar melhor os esquemas de compreensao de texto ara alcançar buscas mais rápidas? Qual a melhor visão lógica para um texto? O que deve ser indexado?
; Um problema é que o engenho de busca pode rankear algumas paginas como de alta prioridade deviso a razoes que não são baseadas numa real relevância da página (the search engine persuasin problem). Indexação: Qual é a melhor visão lógica para o texto O que deve ser indexado Como explorar melhor os esquemas de compreensao de texto ara alcançar buscas mais rápidas Qual a melhor visão lógica para um texto O que deve ser indexado")
91
Desafios Mapear e indexar toda a Web SEO: Search Engine Optimization
Rastrear e indexar aplicações Web 2.0 Making AJAX Applications Crawlable

92
SEO - Search Engine Optimization
Hoje em dia cerca de 85% do tráfego na Internet inicia-se com uma pesquisa num motor de busca como o Google, o Yahoo ou o Bing Conjunto de técnicas que otimizam os web sites, tornando-os mais aptos a estarem bem colocados nas pesquisas efetuadas pelos potenciais visitantes. São baseados naquilo que os buscadores levam em conta no momento da busca.

93
SEO – Exemplos de fatores considerados
Tempo de registro do domínio (Idade do domínio) Freqüência do conteúdo: regularidade com a qual novo conteúdo é adicionado Originalidade do conteúdo Quantidade de links externos Relevância do site que linka para o seu website Citações e fontes de pesquisa (indica que o conteúdo é de qualidade para pesquisa) Links "quebrados“ Conteúdo inseguro ou ilegal Qualidade da codificação HTML, presença de erros no código
 Freqüência do conteúdo: regularidade com a qual novo conteúdo é adicionado. Originalidade do conteúdo. Quantidade de links externos. Relevância do site que linka para o seu website. Citações e fontes de pesquisa (indica que o conteúdo. é de qualidade para pesquisa) Links quebrados Conteúdo inseguro ou ilegal. Qualidade da codificação HTML, presença de erros no código.")
94
Dúvidas

95
Referências [1] [2] [3]








 Curso: Publicidade e Propaganda FACHA – Faculdades Hélio Alonso Setembro 2011 LUIZ AGNER MÍDIAS.>")












 é a parte multimídia da Internet, portanto possiblita a exibição de páginas de hipertexto,>")


