Carregar apresentação
1
Prof. Edilson Ferneda (eferneda@pos.ucb.br) ERIN’2010

2
Agenda CONTEXTUALIZAÇÃO METODOLOGIAS FERRAMENTAS APLICAÇÕES
Inteligência Organizacional METODOLOGIAS CRISP-DM Modelagem do conhecimento FERRAMENTAS WEKA APLICAÇÕES xxx

3
Inteligência Organizacional
Aprendizagem Organizacional Habilidade de uma empresa aprender e rapidamente traduzir em ações o conhecimento como um meio eficaz de atingir vantagem competitiva O que uma empresa conhece, como usa o que conhece e com que rapidez pode assimilar algo novo Um dos objetivos da Inteligência Organizacional: Melhorar a qualidade da tomada de decisão em todos os níveis da organização, através do aumento do acesso às informações e da redução do problema de sobrecarga de informações.

4
Inteligência Organizacional
Ciclo do conhecimento Decisão COMPREENSÃO, ANÁLISE, SÍNTESE Técnicas de visualização, ... Conhecimento AÇÃO DESCOBERTA DE CONHECIMENTO Projeto de busca de padões, Data Mining, Estatística, ... Informação Potencial de apoio a decisões estratégicas ORGANIZAÇÃO/TRANSFORMAÇÃO/ANÁLISE Data Warehouse, Data Mart, OLAP, consultas, relatórios, ... Dado COLETA Papel, arquivos, bases de dados operacionais, ... Realidade

5
Inteligência Organizacional
Contexto de organizações no mundo competitivo (O modelo das 5 forças de Porter)
")
6
Inteligência Organizacional Tecnologia da Informação
Definição “Conjunto de conceitos e metodologias que, fazendo uso de acontecimentos (fatos) e sistemas baseados nesses acontecimentos, apóia a tomada de decisões em negócios” Elementos técnico-organizacionais Database Marketing CRM Balanced Scorecard Data warehousing “BI” DCBD Gestão Negócio Inteligência Organizacional Tecnologia da Informação 6
 e sistemas baseados nesses acontecimentos, apóia a tomada de decisões em negócios Elementos técnico-organizacionais. Database Marketing. CRM. Balanced Scorecard. Data warehousing. BI DCBD. Gestão. Negócio. Inteligência Organizacional. Tecnologia da Informação. 6.")
7
Inteligência Organizacional
Para que sistemas de IO? Database Marketing (“Marketing de precisão”) Ajuda a melhorar os contatos futuros e assegura um planejamento mais realista do marketing Usa canais e meios de comunicação de marketing para: Ampliar a ajuda na busca do público-alvo da empresa Estimular a demanda de seu público Estar perto do público, registrando e mantendo uma memória eletrônica sobre clientes, clientes potenciais, todos os contatos comerciais e de comunicação
 Ajuda a melhorar os contatos futuros e assegura um planejamento mais realista do marketing. Usa canais e meios de comunicação de marketing para: Ampliar a ajuda na busca do público-alvo da empresa. Estimular a demanda de seu público. Estar perto do público, registrando e mantendo uma memória eletrônica sobre clientes, clientes potenciais, todos os contatos comerciais e de comunicação.")
8
Inteligência Organizacional
Para que sistemas de IO? CRM (Customer Relationship Management) Estratégia de negócio voltada ao atendimento e à antecipação das necessidades dos clientes atuais e potenciais Envolve ... ... a captura dos dados dos clientes ao longo de toda a empresa ... a consolidação em um banco de dados central ... a análise e distribuição dos resultados da análise para todos os pontos de contato, utilizando as informações ao interagir com os clientes por meio de qualquer ponto de contato com a empresa Engloba ... ... conceitos, métricas, processos, soluções, gestão de canais e estratégias ... ferramentas das áreas de marketing, vendas e serviços
 Estratégia de negócio voltada ao atendimento e à antecipação das necessidades dos clientes atuais e potenciais. Envolve a captura dos dados dos clientes ao longo de toda a empresa. ... a consolidação em um banco de dados central. ... a análise e distribuição dos resultados da análise para todos os pontos de contato, utilizando as informações ao interagir com os clientes por meio de qualquer ponto de contato com a empresa. Engloba conceitos, métricas, processos, soluções, gestão de canais e estratégias. ... ferramentas das áreas de marketing, vendas e serviços.")
9
Inteligência Organizacional
Para que sistemas de IO? Balanced Scorecard Sistema de gestão da estratégia a longo prazo Busca traduzir a missão e a estratégia das organizações num conjunto abrangente de desempenho como base para um sistema de medição e gestão estratégica Empresas podem adotar esta metodologia para ... Esclarecer e obter consenso em relação à estratégia Comunicar a estratégia a toda a organização Alinhar as metas departamentais e pessoais à estratégia corporativa Associar objetivos estratégicos metas de longo prazo orçamentos anuais Identificar e alinhar as iniciativas estratégicas Realizar revisões estratégicas periódicas e sistemáticas Obter feedback p/aprofundar o conhecimento da estratégia e aperfeiçoá-la

10
Sistemas de Suporte à Decisão
Inteligência Organizacional Sistemas de Suporte à Decisão Problema: Explosão de dados Ferramentas automáticas de coleta de dados e tecnologia madura de armazenamento acarretam o surgimento de grandes bancos de dados e outros repositórios de informação “Estamos nos afogando em dados, mas carentes de conhecimento!” Excesso de dados nas Organizações Disseminação de sistemas de informação (aplicações) Eficiência para coletar e armazenar grandes volumes de dados Sistemas de Suporte à Decisão Dificuldade de se extrair informações táticas e estratégicas e se obter conhecimento dos negócios
 Eficiência para coletar e armazenar grandes volumes de dados. Sistemas de Suporte à Decisão. Dificuldade de se extrair informações táticas e estratégicas e se obter conhecimento dos negócios.")
11
Inteligência Organizacional
Sistemas de Suporte à Decisão ... necessitam de informação / conhecimento (Análises, Diagnósticos, Recomendações, Ações realizadas / em curso, ...) Devem extrair e integrar dados de múltiplas fontes Servem-se da experiência para analisar dados contextualizados Trabalham com hipóteses (criação de cenários) Procuram relações de causa/efeito Transformam os registros obtidos em informação útil para o conhecimento empresarial
 Devem extrair e integrar dados de múltiplas fontes. Servem-se da experiência para analisar dados contextualizados. Trabalham com hipóteses (criação de cenários) Procuram relações de causa/efeito. Transformam os registros obtidos em informação útil para o conhecimento empresarial.")
12
Inteligência Organizacional
Onde está o conhecimento das Organizações? Conhecimento refere-se à habilidade de criar um modelo mental que descreva objetos e indique ações a realizar Conhecimento tácito, segundo a gestão do conhecimento, Está nas pessoas (Experiências, casos, rotinas, observações, requisitos, códigos, especificações, mensagens, ...) Não permite representação Difícil de explicar e se elicitar Se torna dados e informação quando assume forma explícita Conhecimento explícito (“informação”) Bases de Dados, documentos, correspondências, arquivos, livros, filmes, textos, planilhas, ..
 Não permite representação. Difícil de explicar e se elicitar. Se torna dados e informação quando assume forma explícita. Conhecimento explícito ( informação ) Bases de Dados, documentos, correspondências, arquivos, livros, filmes, textos, planilhas, ..")
13
Inteligência Organizacional
Onde está o conhecimento das Organizações? Conhecimento na IA IA busca viabilizar a transferência desses processos para sistemas capazes de simular o processo de decisão do ser humano Representação do conhecimento Simbólica (Frames, Redes Semânticas, Ontologias, Regras de Produção, Árvores de Decisão, ...) Conexionista (Redes Neurais Artificiais) Métodos de aprendizagem Agrupamento - Clustering (Não supervisionados) Classificação (Supervisionados) Associação ... if ... then ...
 Conexionista (Redes Neurais Artificiais) Métodos de aprendizagem. Agrupamento - Clustering (Não supervisionados) Classificação (Supervisionados) Associação. ... if ... then ...")
14
Inteligência Organizacional
Explicitação do conhecimento “Processo de articulação do conhecimento tácito em conceitos explícitos. O tácito se torna explícito expresso na forma de metáforas, analogias, conceitos, hipóteses ou modelos.” (Nonaka & Takeuchi) Engenharia do conhecimento CommonKADS Descoberta de conhecimento (Reconhecimento de padrões) Fayyad CRISP-DM Elicitação de “conhecimento”
 Engenharia do conhecimento. CommonKADS. Descoberta de conhecimento (Reconhecimento de padrões) Fayyad. CRISP-DM. Elicitação de conhecimento")
15
CRISP-DM Introdução CRISP-DM = Cross Industry Standard Process for Data Mining Projeto que padroniza conceitos e técnicas na busca de informações em banco de dados Surgiu a partir da experiência de três empresas pioneiras no setor (1996): DaimlerChrysler - Aplica análises de data mining em seus negócios NCR - Provê soluções de datawarehouse SPSS - Disponibiliza soluções baseadas no processo de mineração de dados Padroniza os passos do processo de descoberta de conhecimento e sua aplicação em diferentes mercados, independente do segmento Agiliza grandes projetos de DCBD, com mais eficiência e com menor custo Pode ser usada por qualquer analista de informações, tendo como base qualquer software de DM Manual disponível em
: DaimlerChrysler - Aplica análises de data mining em seus negócios. NCR - Provê soluções de datawarehouse. SPSS - Disponibiliza soluções baseadas no processo de mineração de dados. Padroniza os passos do processo de descoberta de conhecimento e sua aplicação em diferentes mercados, independente do segmento. Agiliza grandes projetos de DCBD, com mais eficiência e com menor custo. Pode ser usada por qualquer analista de informações, tendo como base qualquer software de DM. Manual disponível em")
16
CRISP-DM Fases Compreensão do problema Compreensão dos dados
Preparação dos dados Modelagem Avaliação Aplicação (Deployment)
")
17
CRISP-DM Compreensão do problema 1.1 - Objetivos do negócio
Plano de fundo Objetivos do negócio Critério de sucesso do negócio 1.2 - Avaliação da situação Inventário de recursos Exigências, suposições e limitações Riscos e contingências Terminologia Custos e benefícios 1.3 - Objetivos do data mining (DCBD) Objetivos do data mining Critério do sucesso do data mining 1.4 - Plano de projeto Plano de projeto Avaliação inicial de ferramentas e técnicas
 Objetivos do data mining. Critério do sucesso do data mining Plano de projeto. Plano de projeto. Avaliação inicial de ferramentas e técnicas.")
18
CRISP-DM Entendimento dos dados 2.1 - Coleta inicial dos dados
Relatório da coleta inicial dos dados 2.2 - Descrição dos dados Relatório da descrição dos dados 2.3 - Exploração de dados Relatos da exploração de dados 2.4 - Verificação da qualidade dos dados Relatório de qualidade dos dados

19
CRISP-DM Preparação dos dados 3.1 - Seleção dos dados
Racionalização para inclusão/exclusão 3.2 - Limpeza dos dados Relatório da limpeza de dados 3.3 -Construção dos dados Atributos derivados Registros gerados 3.4 - Integração dos dados Dados combinados 3.5 - Formatação dos dados Dados reformatados

20
CRISP-DM Modelagem 4.1 - Seleção da técnica de modelagem
4.2 - Geração do design de teste Design de teste 4.3 - Construção do modelo Ajustes de parâmetros Modelos Descrição dos modelos 4.4 - Avaliação do modelo (Acurácia e generalidade do modelo) Avaliação do modelo (Validação cruzada, taxas de erro, etc) Avaliação do modelo revisado
 Avaliação do modelo (Validação cruzada, taxas de erro, etc) Avaliação do modelo revisado.")
21
CRISP-DM Avaliação do modelo 5.1 - Avaliar resultados
Avaliação dos resultados do data mining a respeito dos critérios do sucesso do negócio Modelos aprovados 5.2 - Processo de revisão Revisão do processo 5.3 - Determinação dos próximos passos Lista das ações possíveis Decisão

22
CRISP-DM Aplicação (Deployment) 6.1 - Planejamento da implantação
Plano de implantação 6.2 - Planejamento do monitoramento e manutenção Plano de monitoramento e manutenção 6.3 - Produção do relatório final Relatório final Apresentação final 6.4 - Revisão o projeto Documentação de experiências Exemplos: Estruturação de Call Center com televendas Marketing de precisão baseado em segmentação de mercado Refinamento de perfis de clientes Combate a fraudes (cartões de crédito, TRE, TCU, CGU, etc). Gestão epidemiológica Gestão de Ciência & Tecnologia Avaliação do cumprimento de objetivos
. Gestão epidemiológica. Gestão de Ciência & Tecnologia. Avaliação do cumprimento de objetivos.")
23
Modelagem do conhecimento
Objetivo: construção de uma “base de conhecimento” ... IF ... THEN ... Base de Conhecimento

24
Modelagem do conhecimento
... no contexto organizacional Benchmarking, Monitoramento, Head-hunting, ... Inteligência Competitiva Coleta/Busca, Captura, ... INTERNET IO Código de sistemas Método empírico Bases de dados Base de Conhecimento Engenharia do Conhecimento Regras de negócio Casos Requisitos GC Reconhecimento de Padrões Filmes Rotinas Livros Textos Método analítico Planilhas Especificações Gravações Documentos Sistemas de Suporte à Decisão Experiências Observações OLAP Data Mart DW

25
Modelagem do conhecimento
Data Mining Utiliza técnicas sofisticadas de análise estatística e modelagem (aprendizagem de máquina) para descobrir padrões e relações escondidas nas bases de dados das organizações Padrões que métodos tradicionais não encontrariam! Padrões encontrados pela construção de modelos (representações abstratas da realidade) Um bom modelo ajuda a compreender um negócio e sugere ações que podem ajudar uma organização a ter sucesso É um processo iterativo!
 para descobrir padrões e relações escondidas nas bases de dados das organizações. Padrões que métodos tradicionais não encontrariam! Padrões encontrados pela construção de modelos (representações abstratas da realidade) Um bom modelo ajuda a compreender um negócio e sugere ações que podem ajudar uma organização a ter sucesso. É um processo iterativo!")
26
Modelagem do conhecimento
Data Mining Treino (estimativa) do modelo com um conjunto dos dados Teste com os dados restantes Às vezes, é preciso uma validação com um terceiro grupo de dados (grupo de validação) Dados de teste podem ser um fatores de influência no modelo Grupo de validação atua como uma medida independente da precisão do modelo A precisão resultante é uma boa estimativa para como o modelo se irá comportar com futuras bases de dados Isto não garante que o modelo está correto! Se mesma técnica fosse utilizada numa sucessão de bases com dados semelhantes aos de treino e teste, a precisão média estaria próxima à obtida desta forma Por melhor que seja a precisão, não há garantia de que o modelo reflita de fato o mundo real Existem sempre circunstâncias que podem levar a modelos incorretos Treinamento Teste Treino Mineração Modelo BD BD1 BD2 BD3 Ac1 Teste BD1 BD3 BD2 Ac2 Ac Teste Acurácia BD2 BD3 BD1 Ac3
 do modelo com um conjunto dos dados. Teste com os dados restantes. Às vezes, é preciso uma validação com um terceiro grupo de dados (grupo de validação) Dados de teste podem ser um fatores de influência no modelo. Grupo de validação atua como uma medida independente da precisão do modelo. A precisão resultante é uma boa estimativa para como o modelo se irá comportar com futuras bases de dados. Isto não garante que o modelo está correto! Se mesma técnica fosse utilizada numa sucessão de bases com dados semelhantes aos de treino e teste, a precisão média estaria próxima à obtida desta forma. Por melhor que seja a precisão, não há garantia de que o modelo reflita de fato o mundo real. Existem sempre circunstâncias que podem levar a modelos incorretos. Treinamento. Teste. Treino. Mineração. Modelo. BD. BD1. BD2. BD3. Ac1. Teste. BD1. BD3. BD2. Ac2. Ac. Teste. Acurácia. BD2. BD3. BD1. Ac3.")
27
Modelagem do conhecimento
Data Mining Tecnologias de suporte if ... then ... Conhecimento Informação DM DM OLAP DW Dado

28
Modelagem do conhecimento
Data Mining O que Data Mining pode fazer Data Mining permite Confirmar relações empíricas Descobrir padrões novos e úteis Pode trazer melhoria de desempenho, se comparado com os que não utilizam eficientemente estas técnicas Às vezes, descobre-se fatos que podem conduzir a melhorias radicais no negócio! O que Data Mining NÃO pode fazer Não se pode prescindir de conhecer o negócio, compreender os dados disponíveis ou de compreender os métodos analíticos Ajuda a encontrar padrões nos dados, mas nada diz sobre seu valor para a organização! Os padrões encontrados devem ser verificados no mundo real! É conveniente que se compreenda o funcionamento das ferramentas escolhidas e os algoritmos em que se baseiam! Não encontra respostas a perguntas que não se fez – deve-se saber a priori o tipo de padrão que se procura Não substitui analistas e gestores de negócio, mas lhes oferece uma poderosa ferramenta para melhorarem o seu trabalho!

29
Atividades preditivas Atividades descritivas
Modelagem do conhecimento Data Mining Modelos preditivos Utilizam dados com resultados conhecidos para desenvolver um modelo que possa ser utilizado para prever valores para diferentes dados Fazem uma previsão explícita Modelos descritivos Descrevem padrões em dados existentes, que podem ser utilizados para guiar decisões Podem ser utilizados para ajudar a construir um modelo preditivo ou para fazer uma previsão implícita quando formam a base para uma ação ou decisão Data Mining Atividades preditivas Atividades descritivas Classificação Séries temporais Regressão Regras de associação Clustering Sumarização

30
Modelagem do conhecimento
Atividades preditivas Classificação É preciso identificar as características ou casos que indicam a que grupo cada caso pertence Utilizado para compreender os dados existentes e para prever a classe de novas instâncias (variável discreta) Os modelos de classificação são criados examinando dados previamente classificados (casos) e ajustando-se o modelo em construção para mapear o padrão preditivo Os casos existentes podem derivar de uma base de dados histórica ou de uma experiência em que uma amostra de uma base de dados é testada no mundo real Regressão Funciona como a classificação, tendo como saída um valor numérico (variável contínua) No caso mais simples, utilizam-se técnicas estatísticas padrão, como regressão linear No entanto, a maioria dos problemas reais não são projeções lineares, demandando métodos mais sofisticados (geração de modelos não lineares) Séries temporais Baseia-se na evolução temporal para, dados valores referentes a um determinado momento, prever valores em momentos futuros Consideram-se propriedades temporais diferenciadoras, como sazonalidade, efeitos do calendário (feriados), ...
 Os modelos de classificação são criados examinando dados previamente classificados (casos) e ajustando-se o modelo em construção para mapear o padrão preditivo. Os casos existentes podem derivar de uma base de dados histórica ou de uma experiência em que uma amostra de uma base de dados é testada no mundo real. Regressão. Funciona como a classificação, tendo como saída um valor numérico (variável contínua) No caso mais simples, utilizam-se técnicas estatísticas padrão, como regressão linear. No entanto, a maioria dos problemas reais não são projeções lineares, demandando métodos mais sofisticados (geração de modelos não lineares) Séries temporais. Baseia-se na evolução temporal para, dados valores referentes a um determinado momento, prever valores em momentos futuros. Consideram-se propriedades temporais diferenciadoras, como sazonalidade, efeitos do calendário (feriados), ...")
31
Modelagem do conhecimento
Atividades descritivas Agrupamento (Clustering) Divide a base de dados em grupos diferentes Encontrar grupos diferentes cujos membros são aparentemente semelhantes Ao contrário da classificação, não há uma variável que identifique os grupos, ou por quais atributos os dados serão agrupados Os grupos devem ser analisados por alguém que conheça muito bem o negócio Associações Identifica co-ocorrência de valores que caracterizam os casos Por exemplo, itens que, com frequência, aparecem juntos em compras de supermercado Descobrem regras do tipo: Se o item A é parte de um evento, então em x% das vezes (fator de confiança) o item B também é parte do evento Sequenciamento Funciona como a associação, mas os itens relacionados ocorrem em tempos diferentes Para se encontrar seqüências, além da captura dos detalhes de cada transação, é preciso garantir a a origem única de cada sequência Por exemplo, em análise de logs, é preciso associar cada clickstream a um único ator
 Divide a base de dados em grupos diferentes. Encontrar grupos diferentes cujos membros são aparentemente semelhantes. Ao contrário da classificação, não há uma variável que identifique os grupos, ou por quais atributos os dados serão agrupados. Os grupos devem ser analisados por alguém que conheça muito bem o negócio. Associações. Identifica co-ocorrência de valores que caracterizam os casos. Por exemplo, itens que, com frequência, aparecem juntos em compras de supermercado. Descobrem regras do tipo: Se o item A é parte de um evento, então em x% das vezes (fator de confiança) o item B também é parte do evento. Sequenciamento. Funciona como a associação, mas os itens relacionados ocorrem em tempos diferentes. Para se encontrar seqüências, além da captura dos detalhes de cada transação, é preciso garantir a a origem única de cada sequência. Por exemplo, em análise de logs, é preciso associar cada clickstream a um único ator.")
32
Modelagem do conhecimento
Técnicas Análise Estatística Árvores de Decisão (ID3 e suas derivações, ...) Redes Neurais (MLP, ...) Agrupamento (K-médias, ...) Associação (Apriori, ...) ...
 Redes Neurais (MLP, ...) Agrupamento (K-médias, ...) Associação (Apriori, ...) ...")
33
Modelagem do conhecimento
Técnicas Estatística Estuda a coleta, organização e interpretação de dados numéricos Assim como Data Mining, tenta encontrar padrões e regularidades nos dados Data Mining se serve da Estatística para descoberta de padrões, cálculo de aproximações, médias, taxas de erro e desvios Técnicas estatísticas mais utilizadas Técnicas baseadas em modelos lineares e não-lineares Amostragem Avaliação de hipóteses e do conhecimento obtido Modelo bayesiano Análise multivariada

34
Modelagem do conhecimento
Técnicas Classificação Especialista CONHECIMENTO DO DOMÍNIO Variável dependente (classe) Variáveis independentes (atributos) Classificador Especificação do problema Aprendizado de máquina Dados brutos Avaliação
 Variáveis independentes. (atributos) Classificador. Especificação do problema. Aprendizado de máquina. Dados brutos. Avaliação.")
35
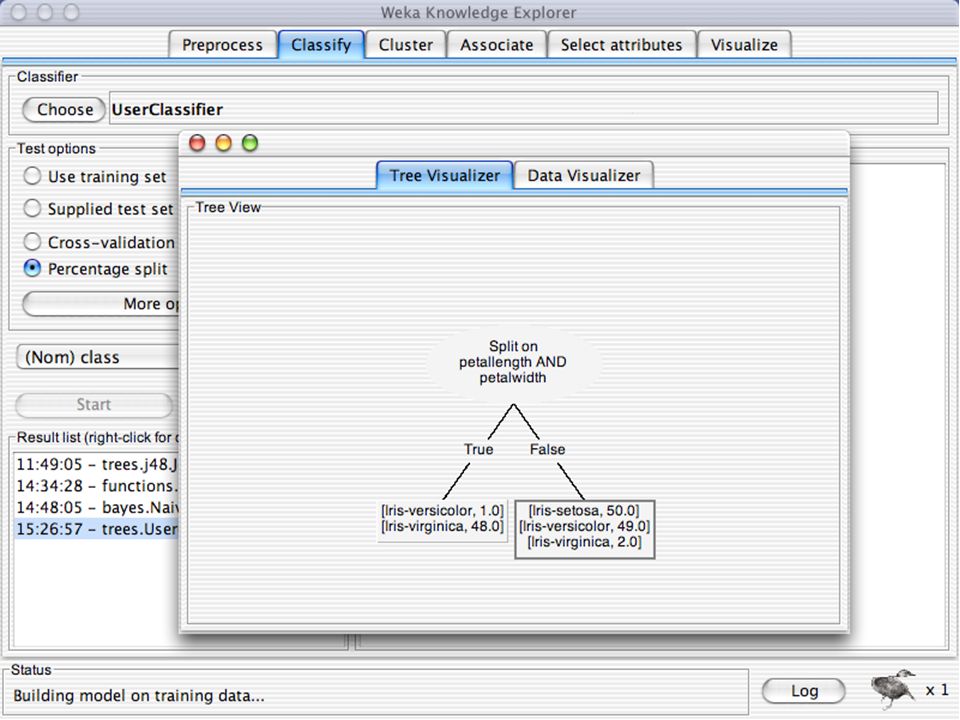
Modelagem do conhecimento
Técnicas Árvores de Decisão Neste caso, o diagrama de retângulos é a representação mais adequada para se visualizar a partição do espaço de características gerada pela árvore de decisão Todos os pontos dentro de um retângulo são classificados da mesma forma, pois todos satisfazem a regra que define o retângulo Dívida o R6 R4 o R1 o o o 20000 o o o o x x o 10000 x R3 o x o x x x x 100 o o o R5 R2 1000 10000 Renda R1: Se R 1000 Então Não rentável R2: Se 1000 < R < E D 100 Então Não rentável R3: Se 1000 < R < E 100 < D < Então Rentável R4: Se 1000 < R < E D Então Não rentável R5: Se R E D < Então Rentável R6: Se R E D Então Não rentável

36
Modelagem do conhecimento
Técnicas Árvores de Decisão Raiz X1 a1 X1 a4 X2 a3 a2 <a1 >a1 Regra Nó X2 X2 <a2 >a2 <a3 >a3 X1 <a4 >a4

37
Modelagem do conhecimento
Técnicas Árvores de Decisão Árvore “pensada” 37

38
Modelagem do conhecimento
Técnicas Árvores de Decisão Ganho de informação Não Sim Outros Pouco E6 E5 E10 Carona E8 E12 E4 E2 Carro E9 E3 E11 E7 E1 Vai pra balada? Fome Sair Álcool UCB Transporte Sono Transporte? carro carona outros +: {E1, E7, E11} –: {E3, E9} +: {E2, E4, E12} –: {E8} +: {E10} –: {E5, E6}

39
Modelagem do conhecimento
Técnicas Árvores de Decisão Ganho de informação Sim Não Carona E12 Carro E11 Outros E10 E9 E5 E3 Pouco E8 E6 E7 E4 E2 E1 Vai pra balada? Fome Sair Álcool UCB Transporte Sono Sono? sim pouco não +: {} –: {E3, E5, E9} +: {E1, E2, E4, E7} –: {E6, E8} +: {E10, E11, E12} –: {} 39

40
Modelagem do conhecimento
Técnicas Árvores de Decisão Árvore calculada 40

41
Modelagem do conhecimento
Técnicas Redes Neurais Artificiais Técnica computacional que utiliza modelos matemáticos inspirados na estrutura neural de organismos inteligentes e que adquirem conhecimento através da experiência

42
Modelagem do conhecimento
Técnicas Redes Neurais Artificiais 42

43
Modelagem do conhecimento
Técnicas Redes Neurais Artificiais Iniciar todas as conexões com wi = 0 (ou aleatórios) Repita Para cada padrão de treinamento (X, d) faça Calcular a saída y Se (d y) então atualizar pesos até o erro ser aceitável Classe B Classe B Classe A Classe A Modelos não lineares Modelos lineares 43
 Repita. Para cada padrão de treinamento (X, d) faça. Calcular a saída y. Se (d y) então atualizar pesos. até o erro ser aceitável. Classe B. Classe B. Classe A. Classe A. Modelos não lineares. Modelos lineares. 43.")
44
Modelagem do conhecimento
Técnicas Agrupamento Dado um conjunto de objetos, colocar os objetos em grupos baseados na similaridade entre eles Utilizado para encontrar padrões inesperados nos dados Aquático Mamífero Ovíparo

45
Modelagem do conhecimento
Técnicas Agrupamento Clustering - Técnica de aprendizado não-supervisionado, ou seja, quando não há uma classe associada a cada exemplo Os exemplos são colocados em clusters (grupos), cujos membros são similares entre si Por outro lado, os clusters devem ser diferentes entre si Representações de agrupamentos: 45
, cujos membros são similares entre si. Por outro lado, os clusters devem ser diferentes entre si. Representações de agrupamentos: 45.")
46
Modelagem do conhecimento
Técnicas Agrupamento Métricas de similaridade A distância é o método mais natural para dados numéricos Valores pequenos indicam maior similaridade Não generaliza muito bem para dados não numéricos (Qual a distância entre “masculino” e “feminino”?) Métricas de Distância mais comuns Hamming - Usada para dados categóricos Euclidiana - Usada para dados numéricos Normalização As distâncias são freqüentemente normalizadas dividindo a distância de cada atributo pelo intervalo de variação (i.e. diferença entre valores máximo e mínimo) daquele atributo Assim, a distância para cada atributo é normalizada para o intervalo [0,1] 46
 Métricas de Distância mais comuns. Hamming - Usada para dados categóricos. Euclidiana - Usada para dados numéricos. Normalização. As distâncias são freqüentemente normalizadas dividindo a distância de cada atributo pelo intervalo de variação (i.e. diferença entre valores máximo e mínimo) daquele atributo. Assim, a distância para cada atributo é normalizada para o intervalo [0,1] 46.")
47
Modelagem do conhecimento
Técnicas Agrupamento Passos para se fazer um agrupamento Passo 1: Escolha aleatória de clusters e cálculo dos centróides (círculos maiores) Passo 2: Atribua cada ponto ao centróide mais próximo Passo 3: Recalcule centróides (neste exemplo, a solução é agora estável) 47
 Passo 2: Atribua cada ponto ao centróide mais próximo. Passo 3: Recalcule centróides (neste exemplo, a solução é agora estável) 47.")
48
Modelagem do conhecimento
Técnicas Agrupamento Exemplo

49
Modelagem do conhecimento
Técnicas Agrupamento Exemplo (K = 2)
")
50
Modelagem do conhecimento
Técnicas Agrupamento Exemplo (K = 3)
")
51
Modelagem do conhecimento
Técnicas Agrupamento Exemplo (K = 4)
")
52
Modelagem do conhecimento
Técnicas Agrupamento Exemplo (K = 5)
")
53
Modelagem do conhecimento
Técnicas Agrupamento Exemplo (K = 6)
")
54
Modelagem do conhecimento
Técnicas Agrupamento Exemplo (K = 7)
")
55
Modelagem do conhecimento
Técnicas Agrupamento Exemplo (K = 8)
")
56
Modelagem do conhecimento
Técnicas Agrupamento Exemplo (K = 9)
")
57
Modelagem do conhecimento
Técnicas Agrupamento Exemplo (K = 10)
")
58
Modelagem do conhecimento
Técnicas Associação Notoriedade em DCBD pela descoberta da relação compra de fraldas cerveja Mas o que fazer? Colocar as fraldas junto com as cervejas para facilitar a venda? Colocá-las distantes para obrigar o cliente a ‘passear’ por outras gôndolas? Decisões cabem ao especialista em marketing, baseado na sua experiência Regras de associação ou regras associativas: {X1, X2, ..., Xn} Y Se todos os itens X1, X2, ..., Xn estão numa transação, então há uma boa chance de se encontrar também Y 58

59
Modelagem do conhecimento
Técnicas Associação O algoritmo Apriori 59

60
Modelagem do conhecimento
Técnicas Associação O algoritmo Apriori Exemplo: Suporte mínimo: 0,3 3 {café,pão,manteiga} 3 3 4 {café,pão} {pão,manteiga} {café,manteiga} 3 5 5 {leite} {café} {cerveja} {pão} {manteiga} {arroz} {feijão} 60

61
Modelagem do conhecimento
Técnicas Associação O algoritmo Apriori Exemplo: Suporte mínimo: 0,3 Conjunto de regras - Conjunto de itens: {café, pão} Se café Então pão [conf = 1,0] Se pão Então café [conf = 0,6] - Conjunto de itens: {café, manteiga} Se café Então manteiga [conf = 1,0] Se manteiga Então café [conf = 0,6] - Conjunto de itens: {pão, manteiga} Se pão Então manteiga [conf = 0,8] Se manteiga Então pão [conf = 0,8] - Conjunto de itens: {café, manteiga, pão} Se café, manteiga Então pão [conf = 1,0] Se café, pão Então manteiga [conf = 1,0] Se manteiga, pão Então café [conf = 0,75] Se café Então manteiga, pão [conf = 1,0] Se manteiga Então café, pão [conf = 0,6] Se pão Então café, manteiga [conf = 0,6] 61

62
Modelagem do conhecimento
Técnicas Associação O algoritmo Apriori Exemplo: Suporte mínimo: 0,3 Conjunto de regras - Padrões descobertos, minsup = 0,3 e minconf = 0,8: Se café Então pão [conf = 1,0] Se café Então manteiga [conf = 1,0] Se pão Então manteiga [conf = 0,8] Se manteiga Então pão [conf = 0,8] Se café, manteiga Então pão [conf = 1,0] Se café, pão Então manteiga [conf = 1,0] Se café Então manteiga, pão [conf = 1,0] 62

63
Ferramentas 63

64
Ferramentas 64

65
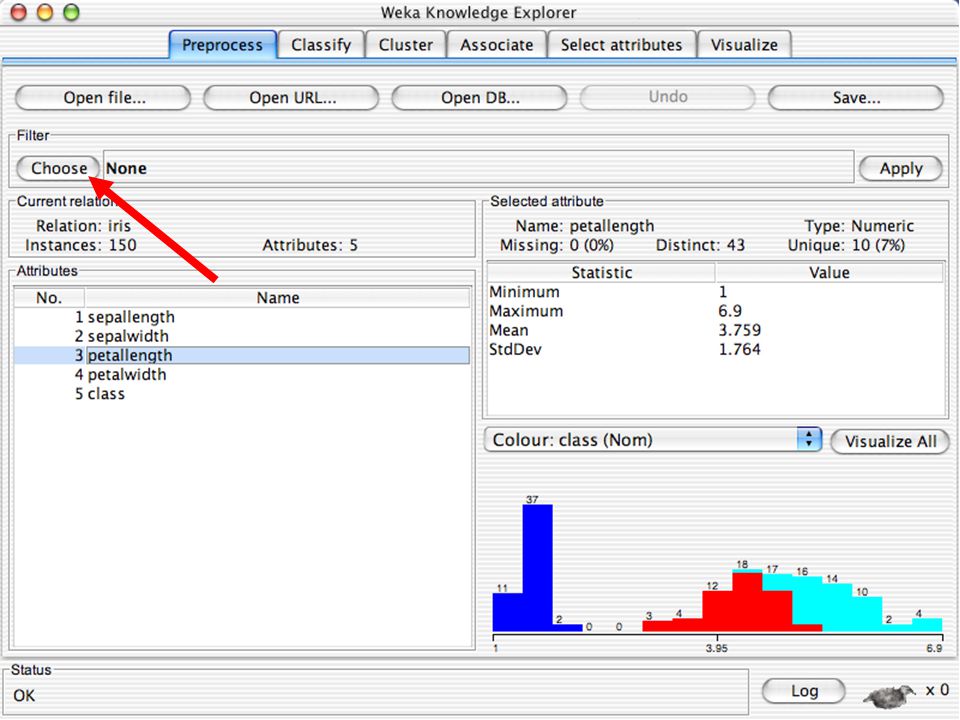
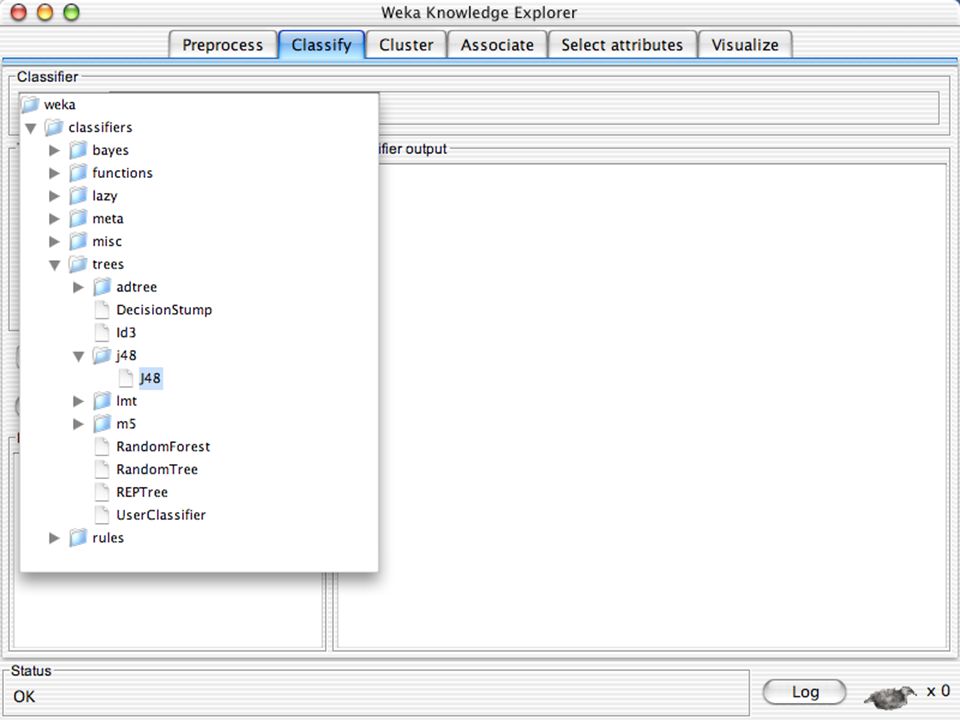
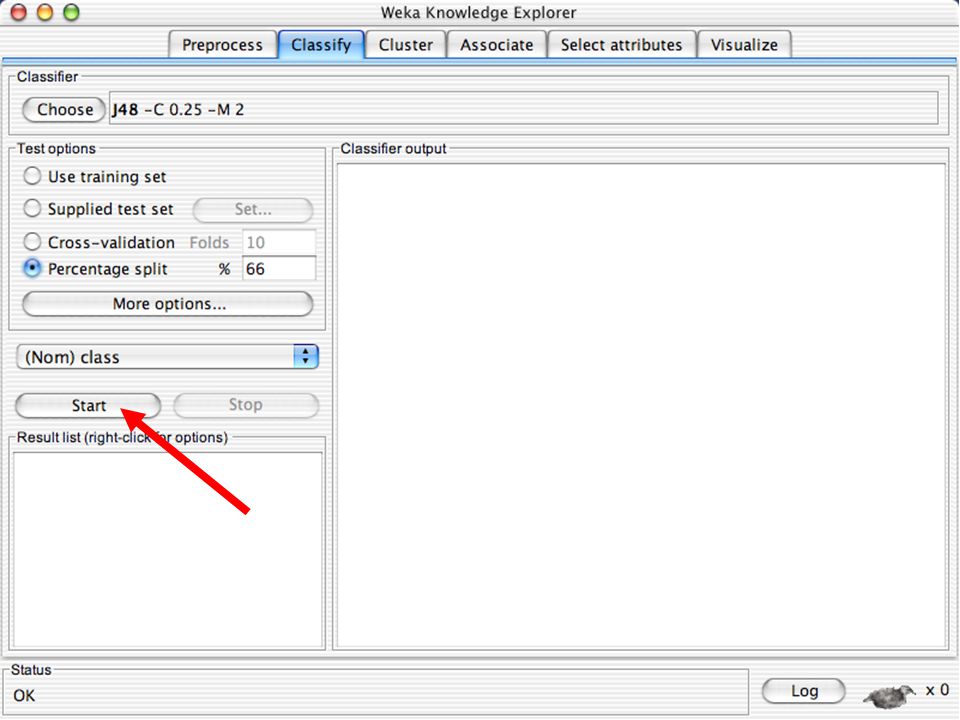
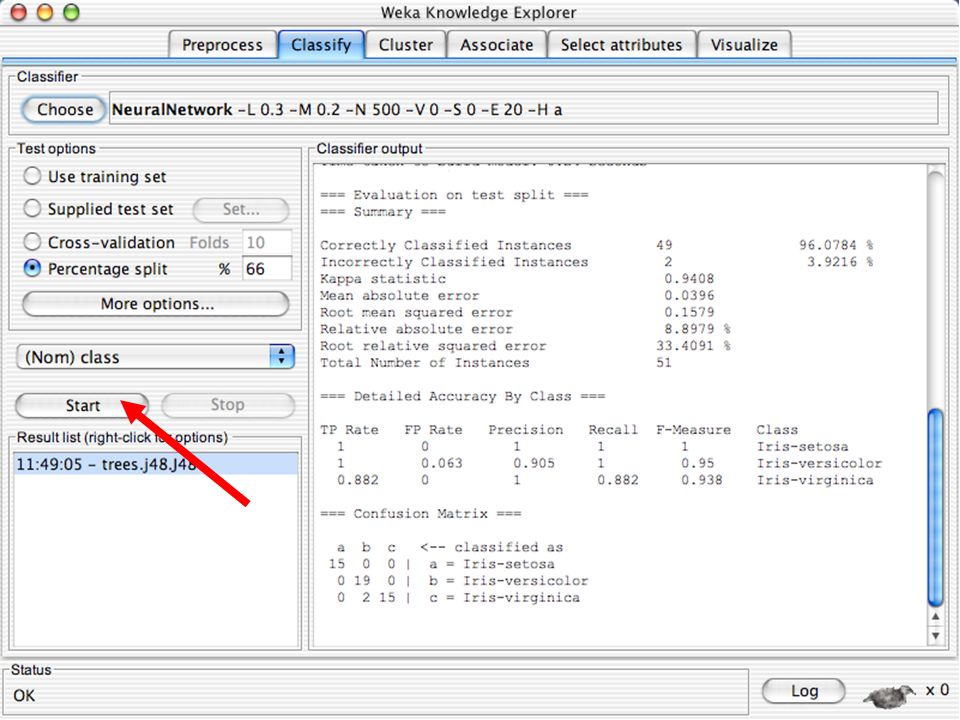
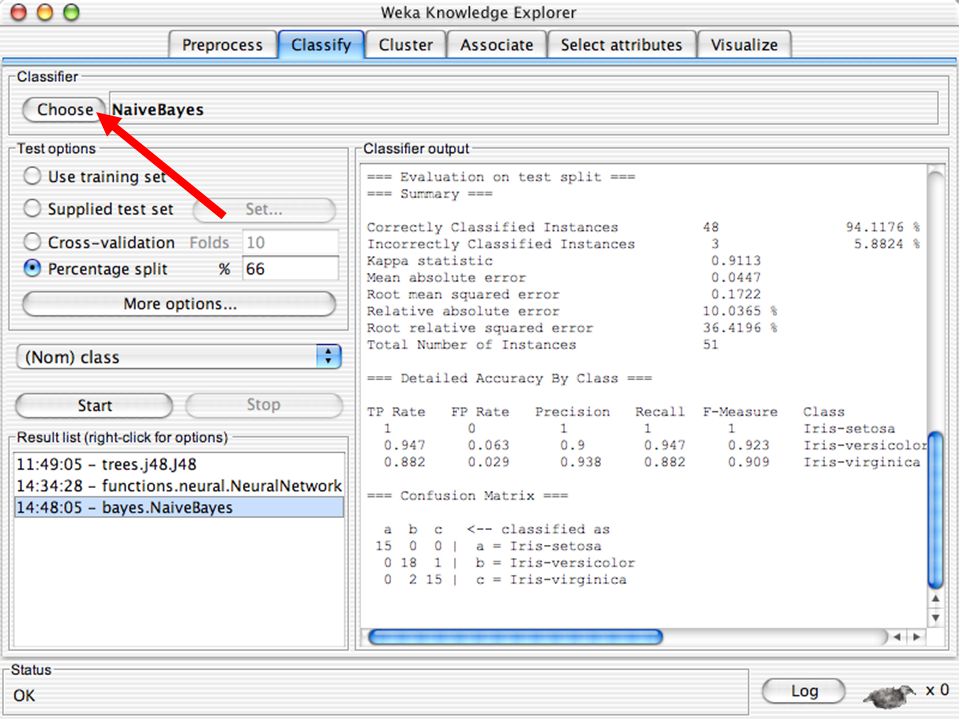
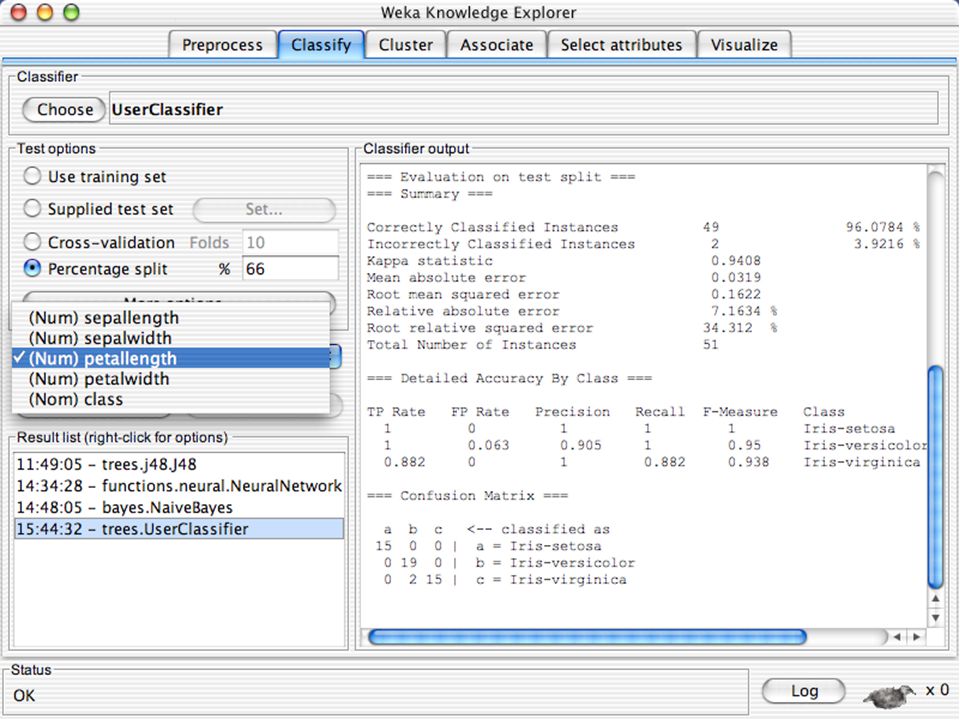
WEKA Software de Aprendizagem de Máquina/Data Mining escrito em Java (GNU Public License) Usado para pesquisa, educação e aplicações Complementa o livro “Data Mining - Practical Machine Learning Tools and Techniques” de Ian W. Witten & Eibe Frank Principais características: Conjunto abrangente de ferramentas para pré-processamento de dados, algoritmos de aprendizagem e métodos de avaliação Interface Gráfica (visualização de dados) Ambiente para comparação de algoritmos de aprendizagem Versões: WEKA 3.3: É a que vamos utilizar para a a apresentação WEKA 3.4: Versão compatível com o livro (2ª Edição) WEKA 3.6: Versão estável atual WEKA 3.7: “Developpment Version” 65
 Ambiente para comparação de algoritmos de aprendizagem. Versões: WEKA 3.3: É a que vamos utilizar para a a apresentação. WEKA 3.4: Versão compatível com o livro (2ª Edição) WEKA 3.6: Versão estável atual. WEKA 3.7: Developpment Version 65.")
66
WEKA Entrada de dados WEKA só manipula arquivos “planos”
Atributo numérico Atributo nominal @relation heart-disease-simplified @attribute age numeric @attribute sex { female, male} @attribute chest_pain_type { typ_angina, asympt, non_anginal, atyp_angina} @attribute cholesterol numeric @attribute exercise_induced_angina { no, yes} @attribute class { present, not_present} @data 63,male,typ_angina,233,no,not_present 67,male,asympt,286,yes,present 67,male,asympt,229,yes,present 38,female,non_anginal,?,no,not_present ... Arquivo no formato .arf 66

67
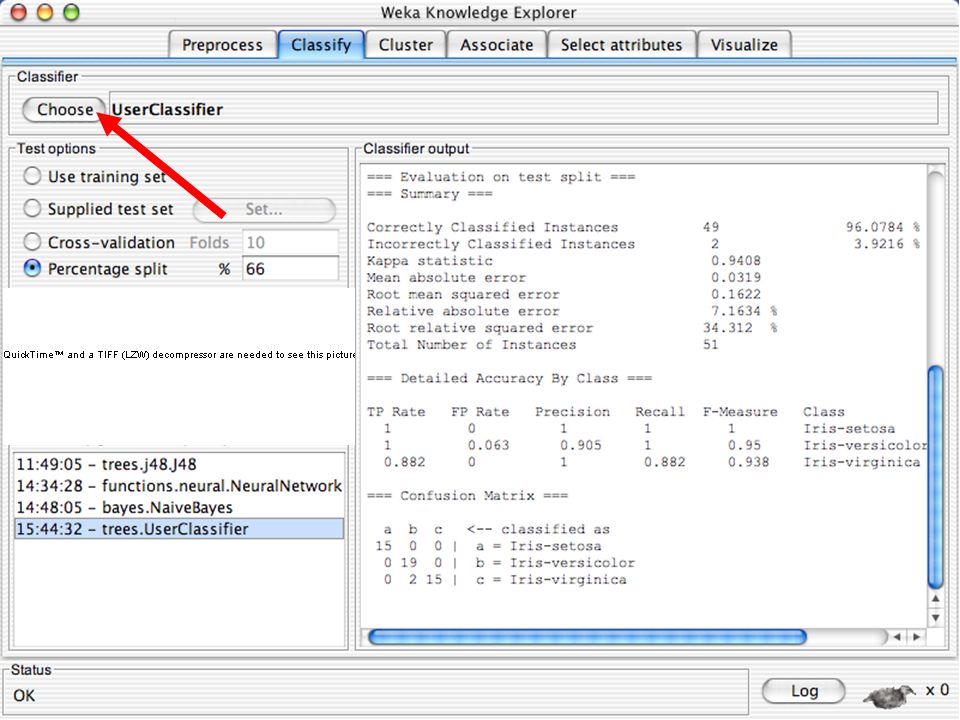
WEKA Abertura 67

68
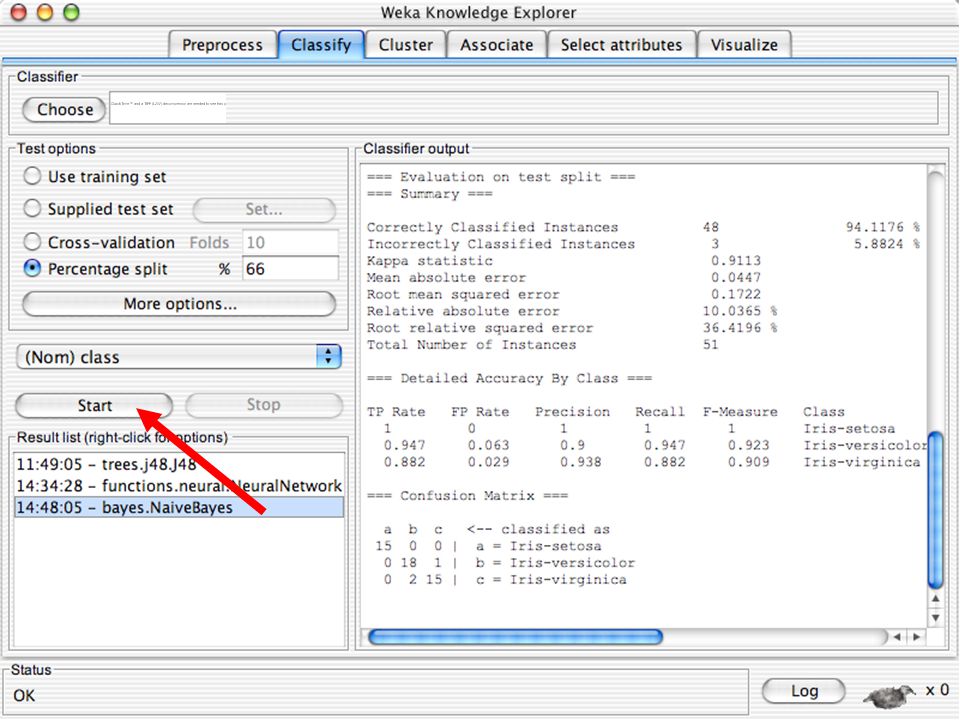
WEKA Abertura Simple CLI Explorer Experimenter KnowledgeFlow
Antiga interface em linha de comando Explorer Principal interface gráfica do WEKA Dá acesso a todas as funcionalidades por meio de seleção de menus e fornecimento de parâmetros Experimenter Permite a realização de experimentos em larga escala com diversas configurações de parâmetros Pode rodar em ambientes de grid KnowledgeFlow Permite executar um conjuto de ações em uma sequência controlada 68

69
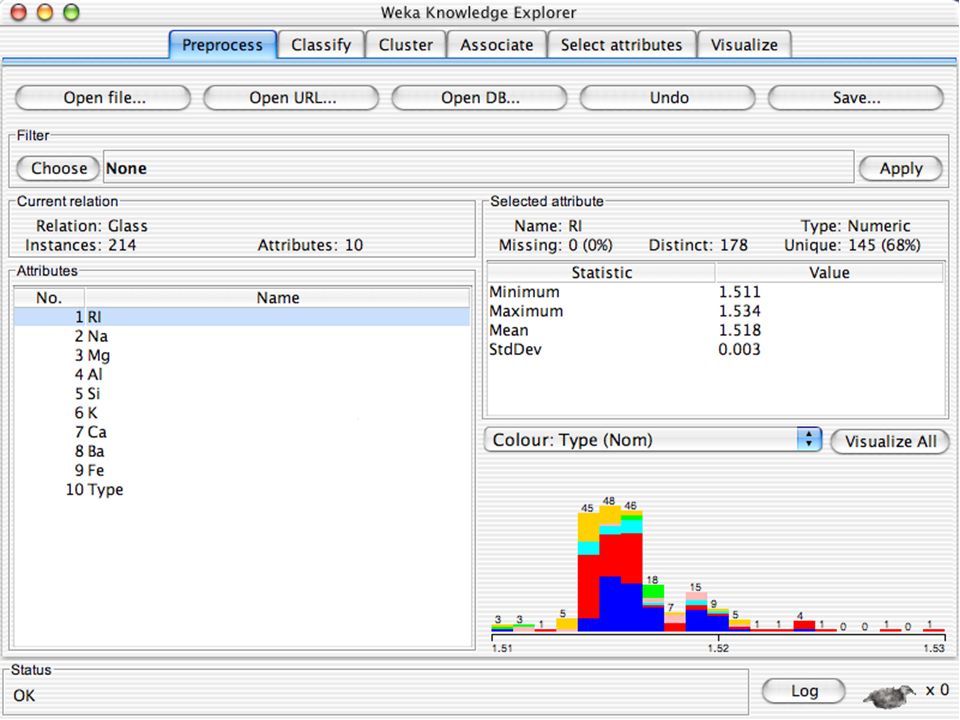
WEKA Pré-processamento
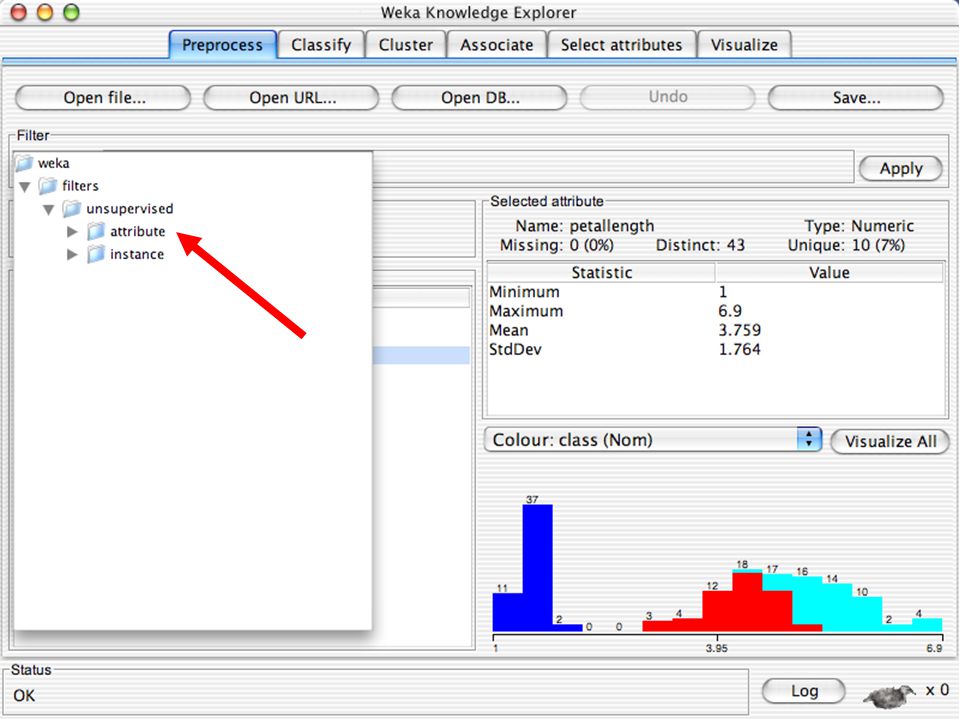
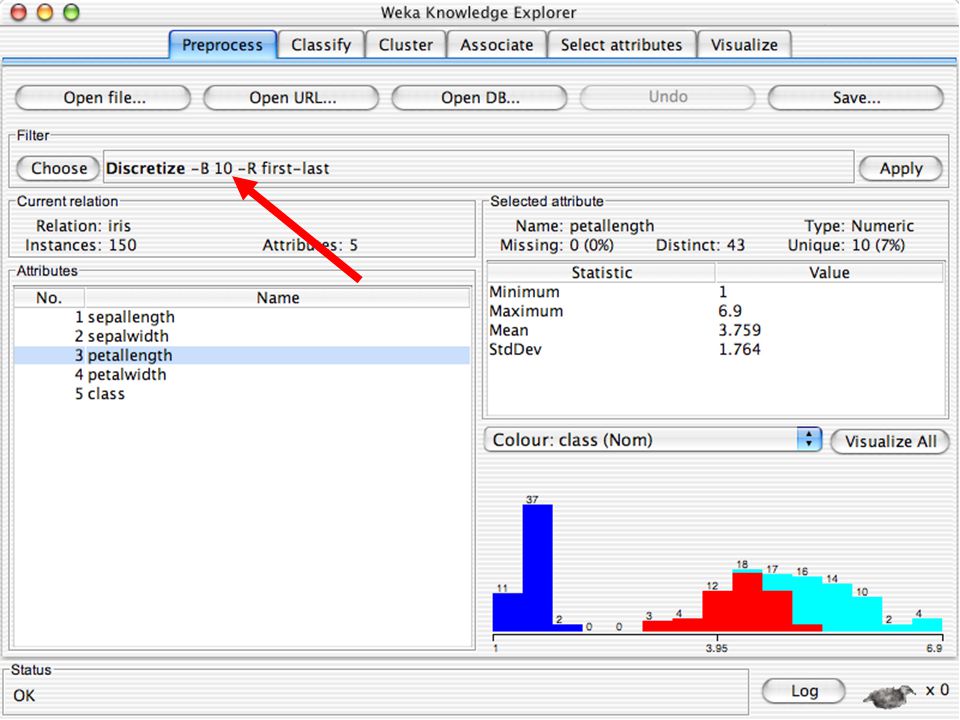
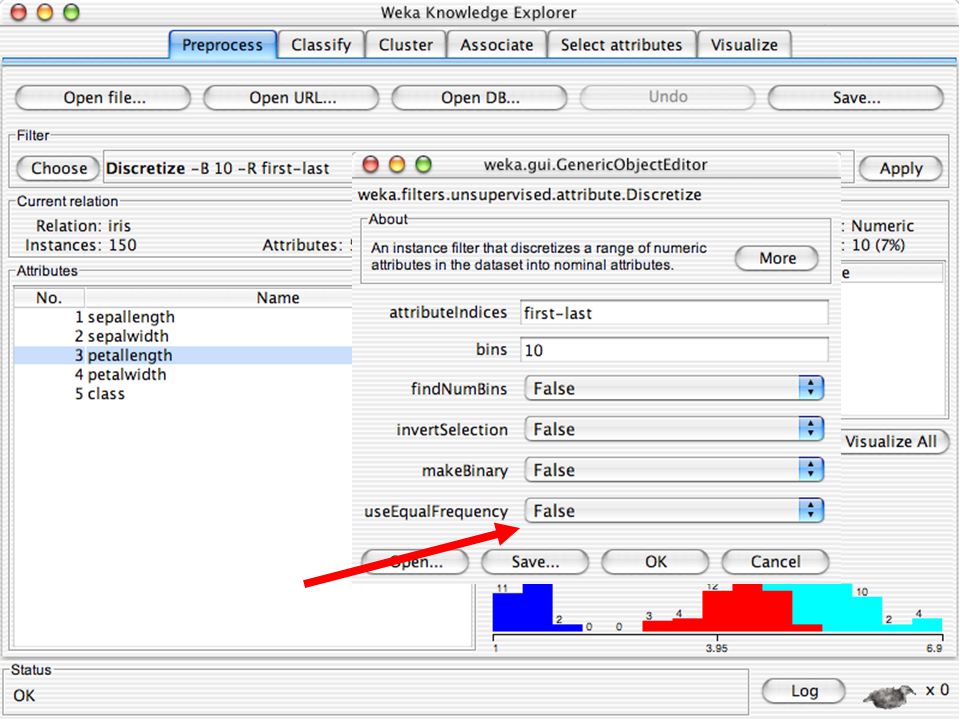
Dados podem ser importados de um arquivo em diversos formatos: ARFF CSV com os nomes das variáveis na primeira linha (pode ser gerado pelo EXCEL) C4.5 (sistema de Quinlan) – 2 arquivos, um com nomes e outro com dados binary – formato gerado pelo Java para compactar grandes arquivos de dados Dados podem também ser lidos de uma URL ou de um banco de dados SQL (usando JDBC) Ferramentas de pré-processamento no WEKA são chamadas “filters” WEKA contém filtros para: Discretização Normalização Amostragem Seleção de atributos Transformação Combinação de atributos … 69
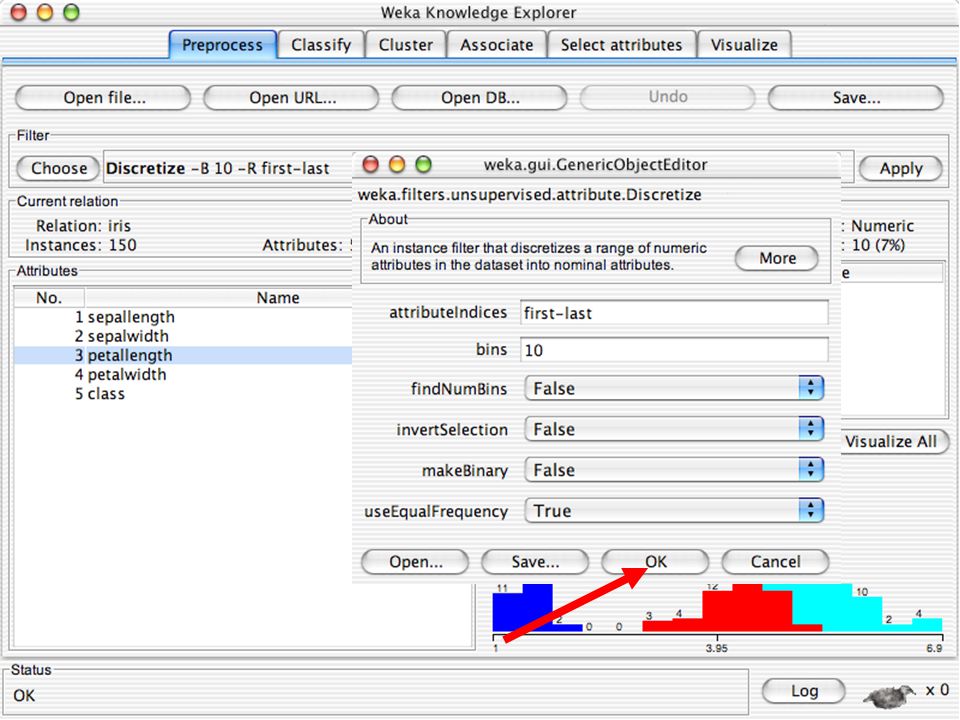
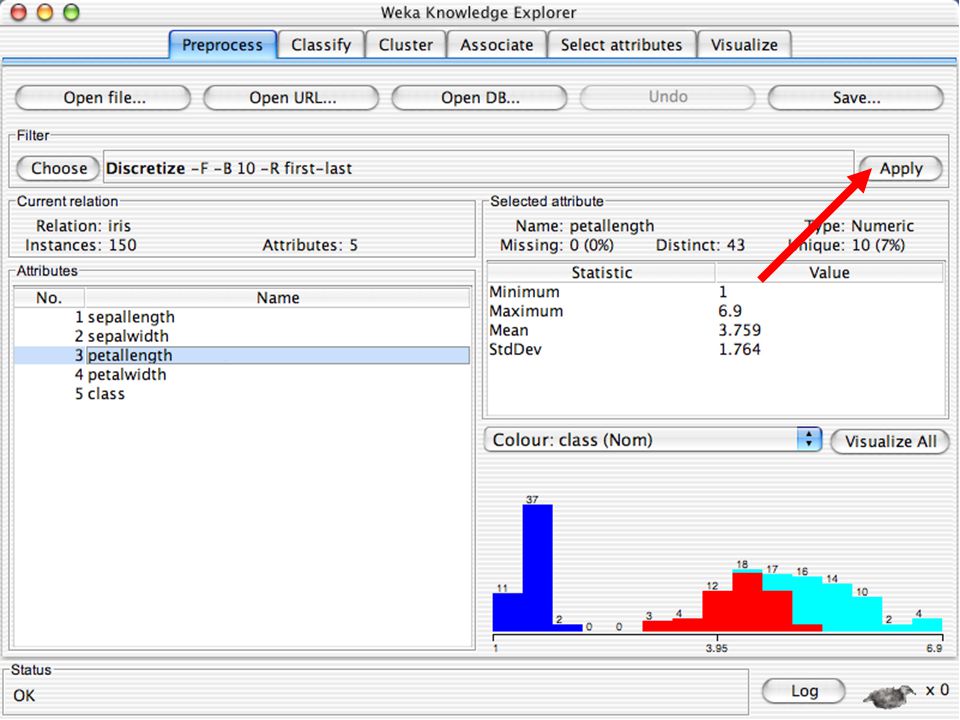
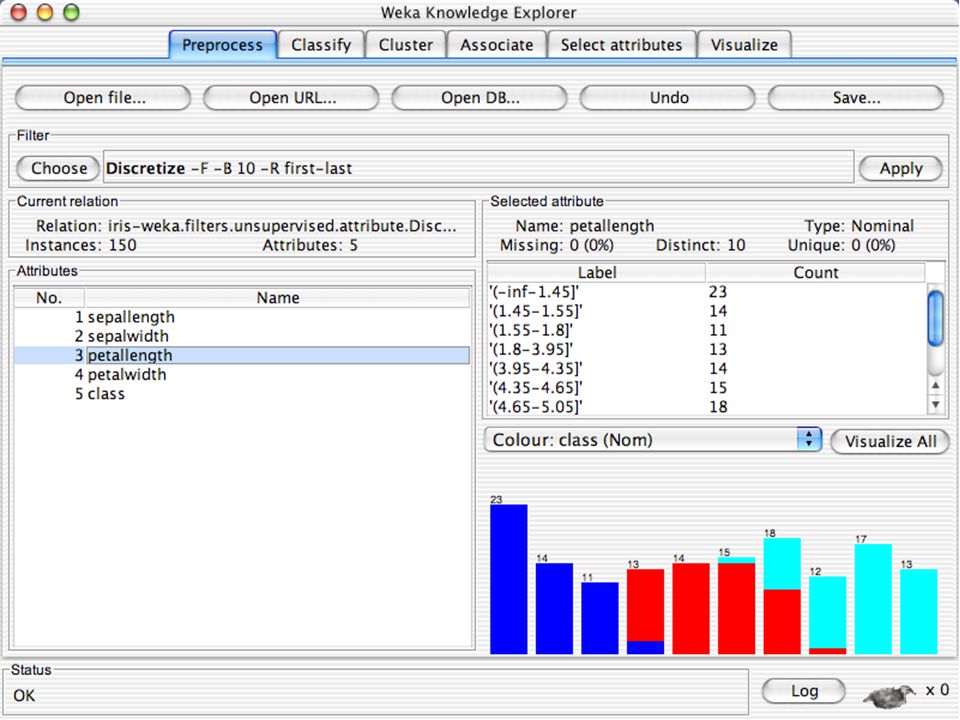
 C4.5 (sistema de Quinlan) – 2 arquivos, um com nomes e outro com dados. binary – formato gerado pelo Java para compactar grandes arquivos de dados. Dados podem também ser lidos de uma URL ou de um banco de dados SQL (usando JDBC) Ferramentas de pré-processamento no WEKA são chamadas filters WEKA contém filtros para: Discretização. Normalização. Amostragem. Seleção de atributos. Transformação. Combinação de atributos. … 69.")
82
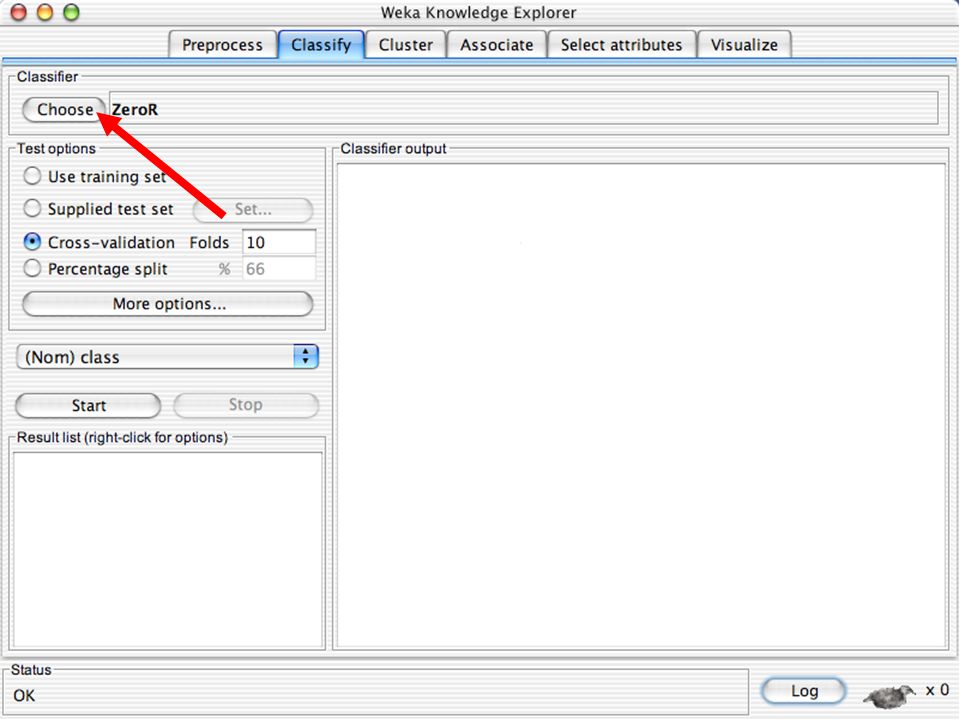
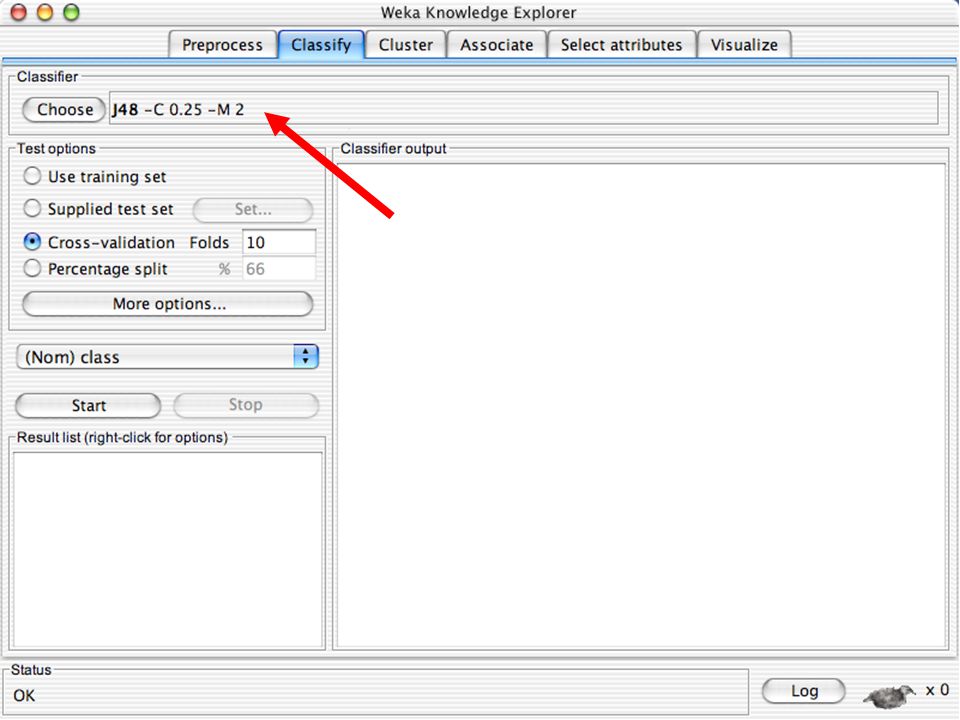
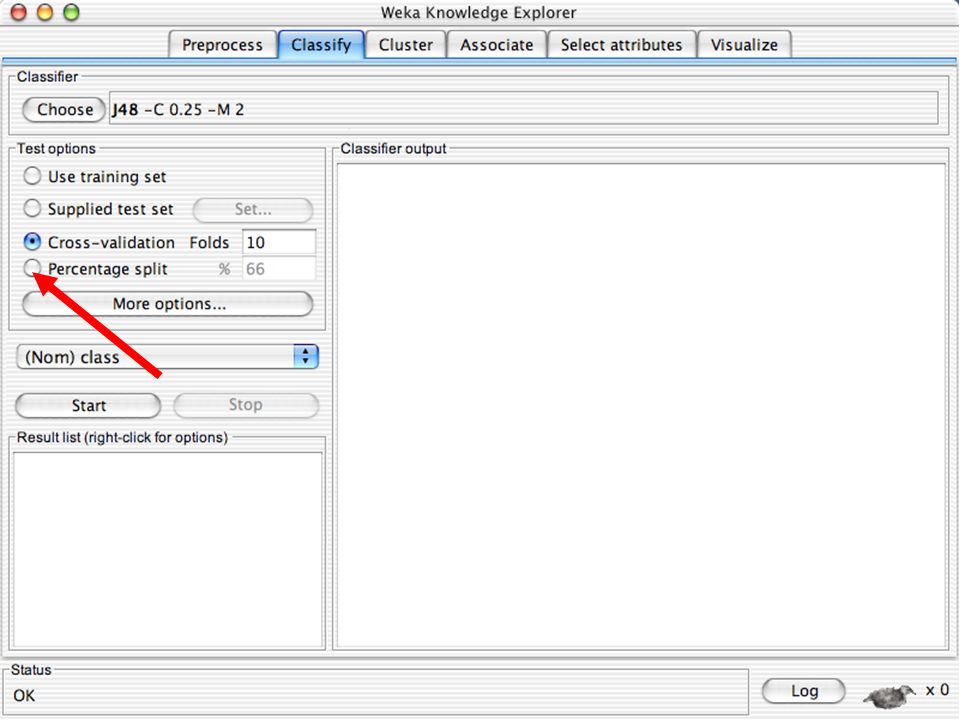
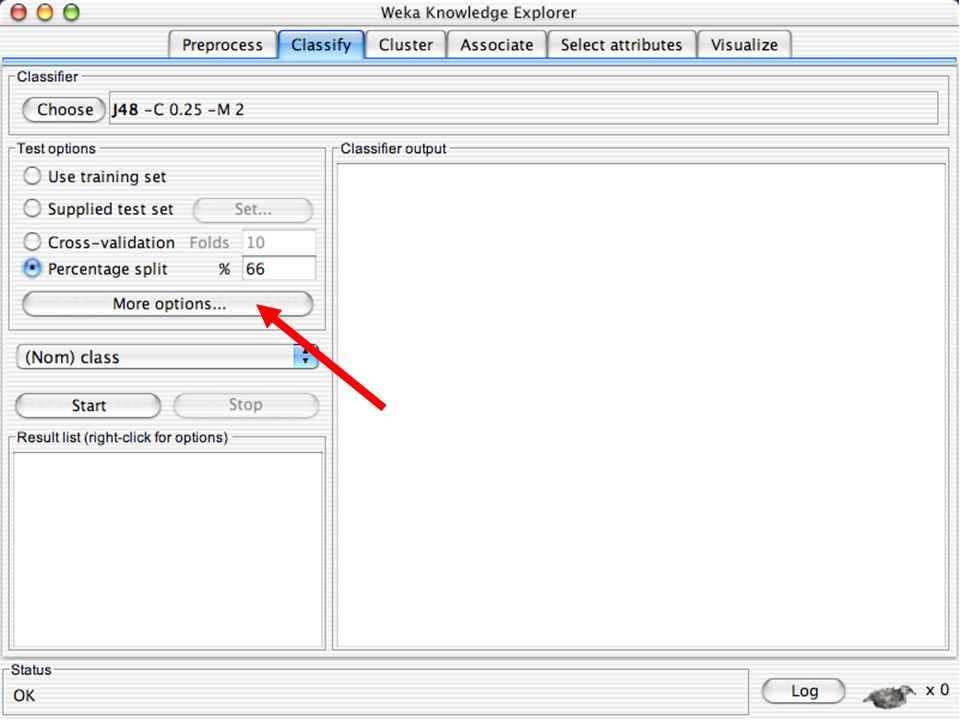
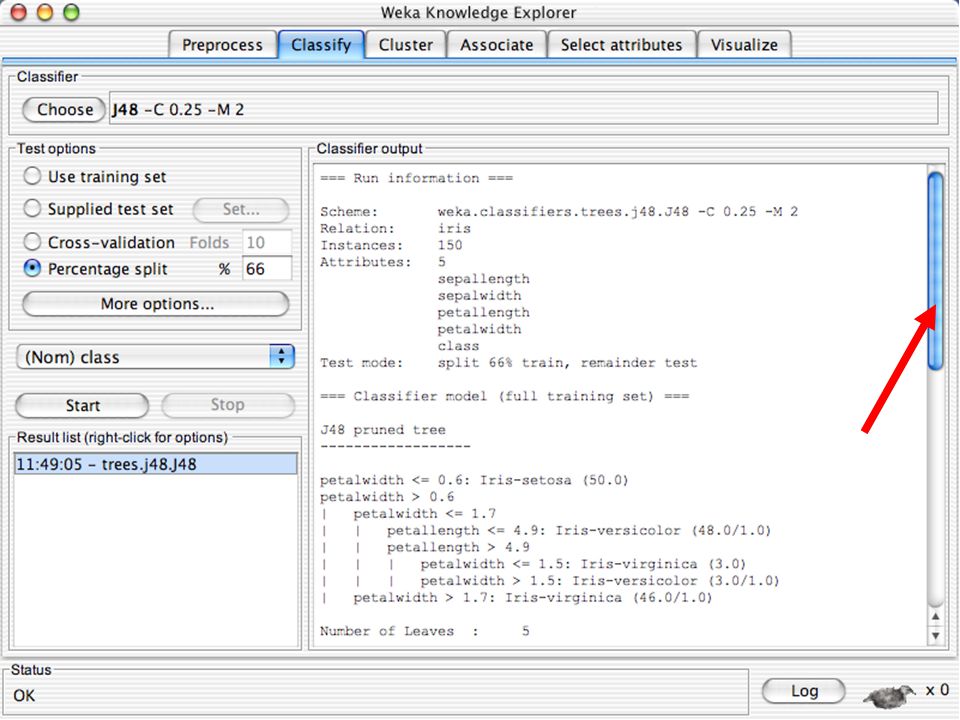
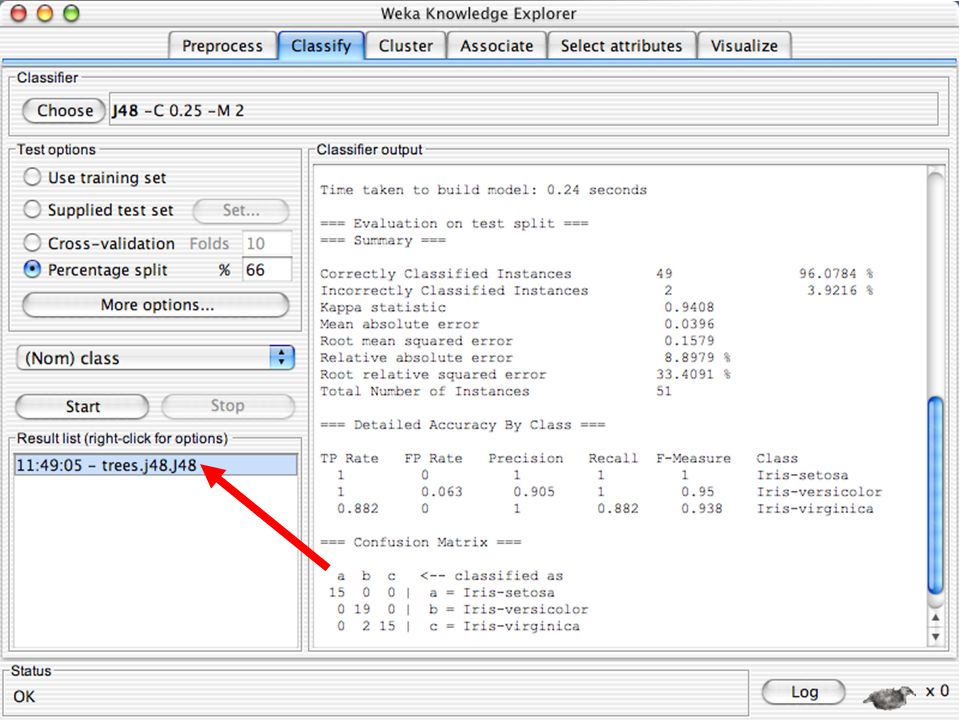
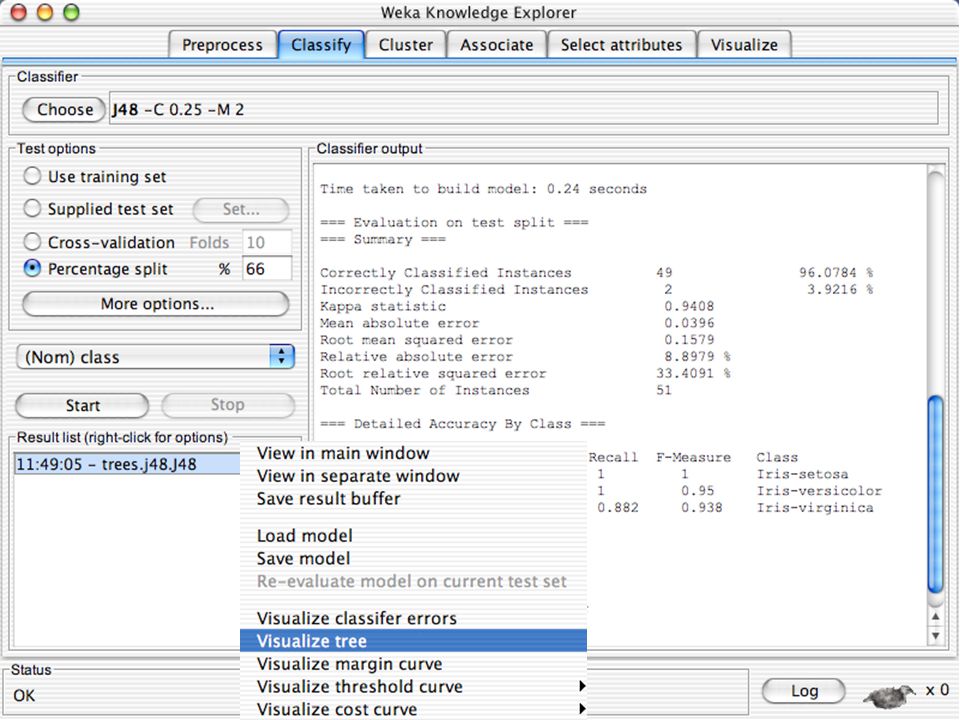
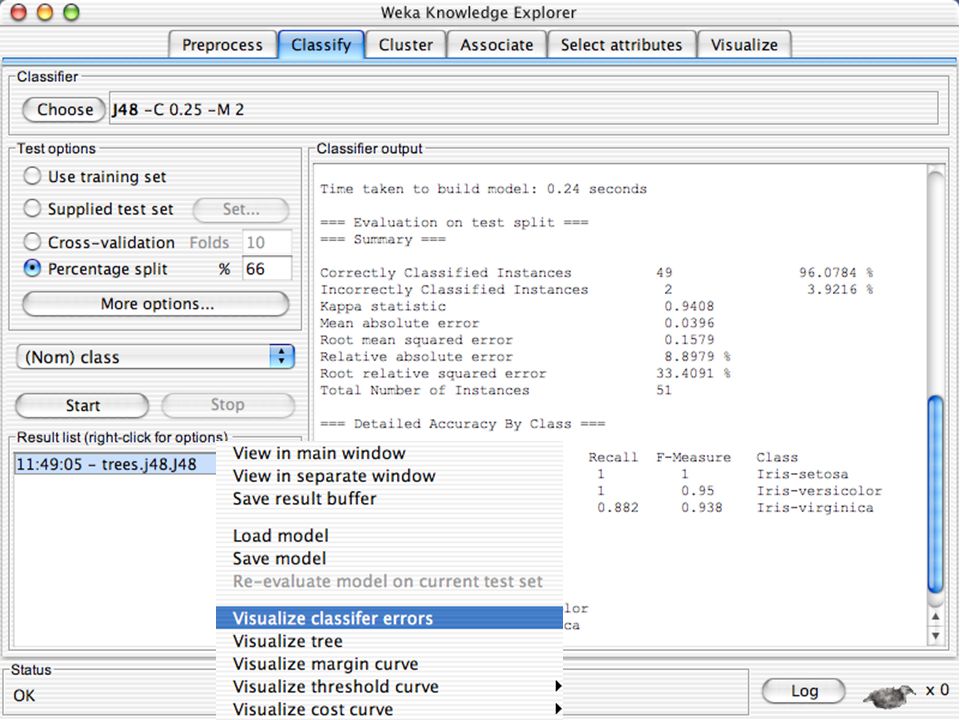
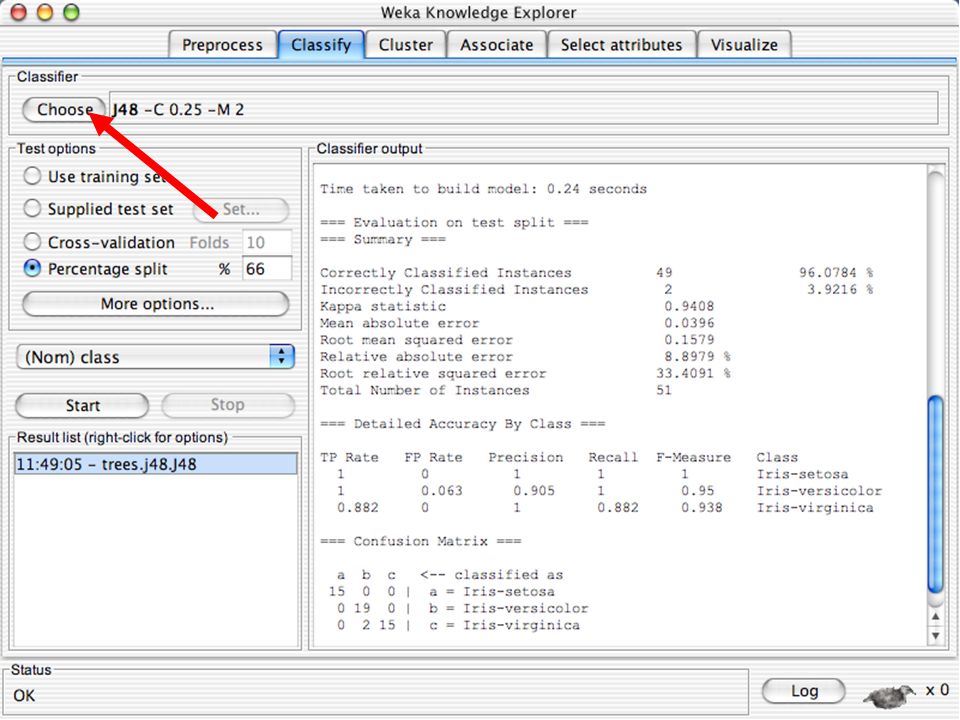
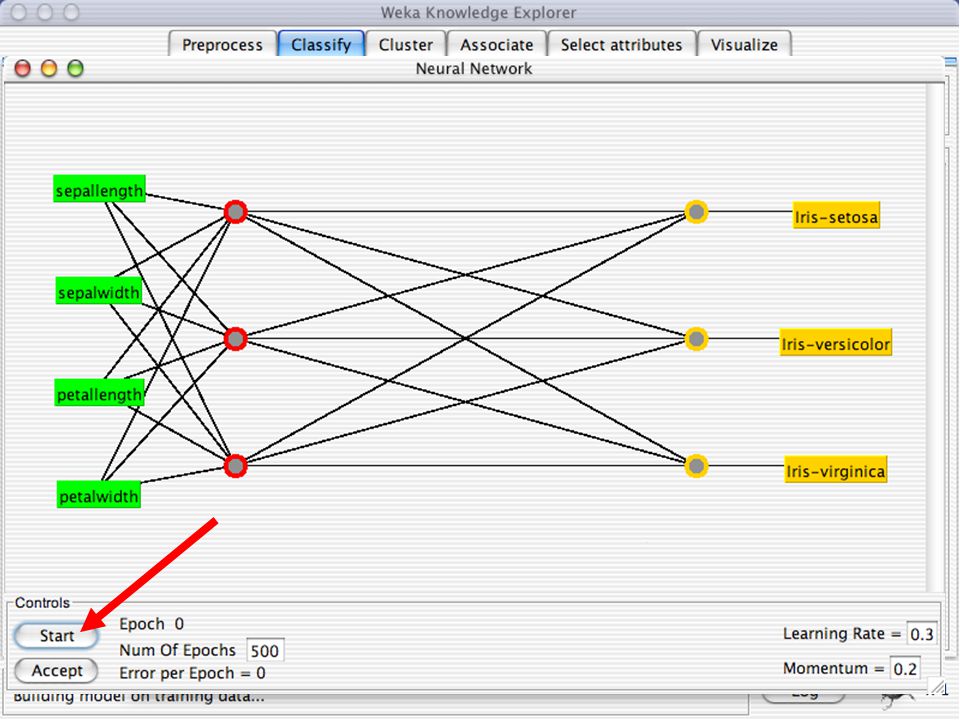
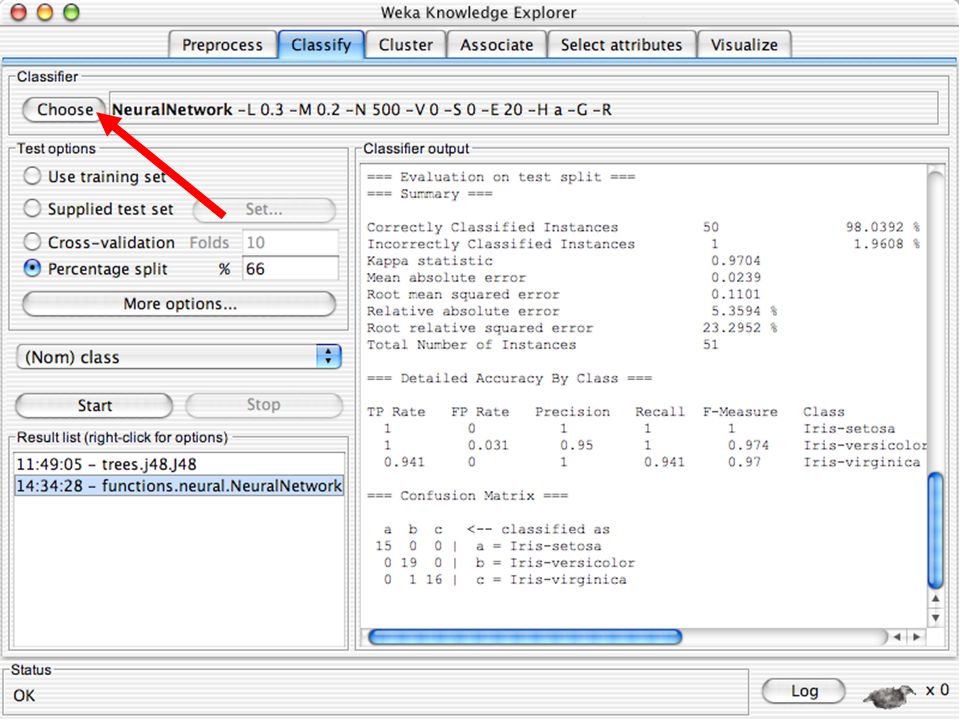
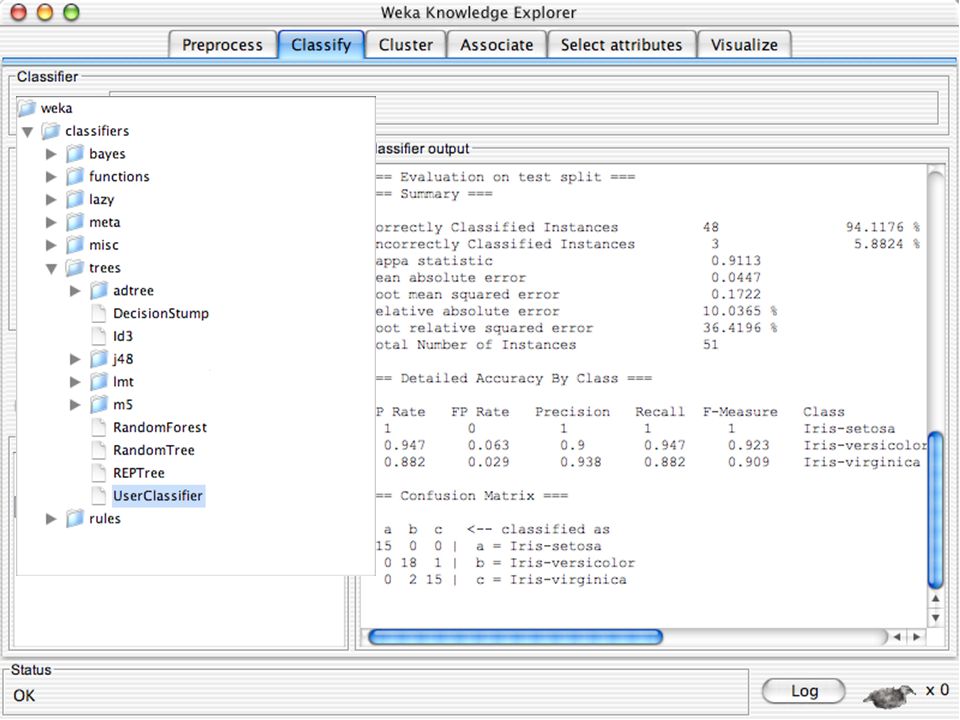
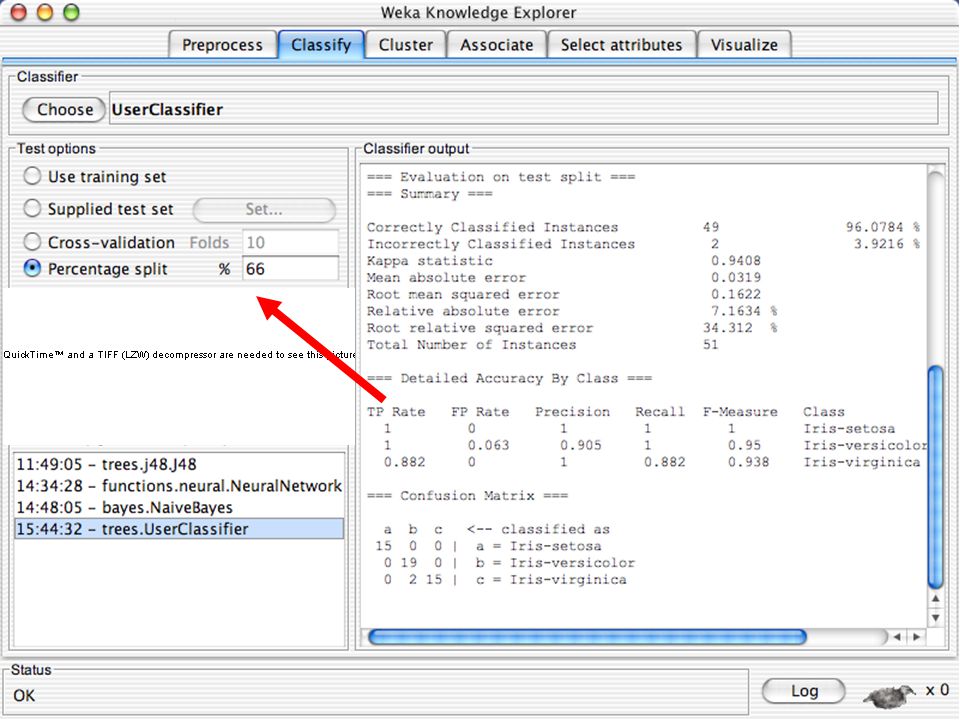
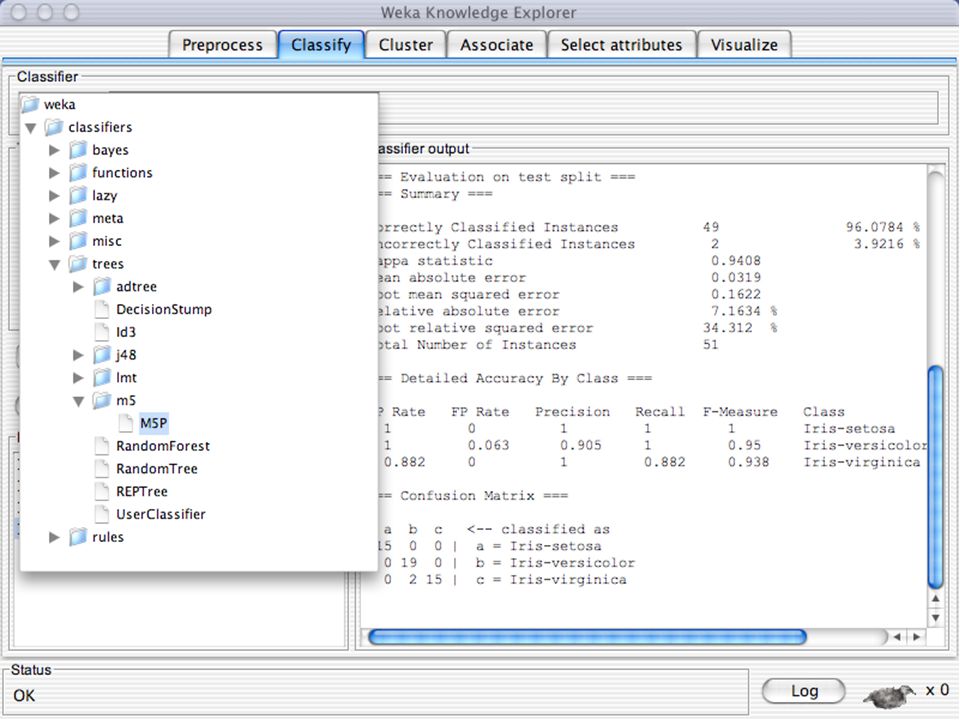
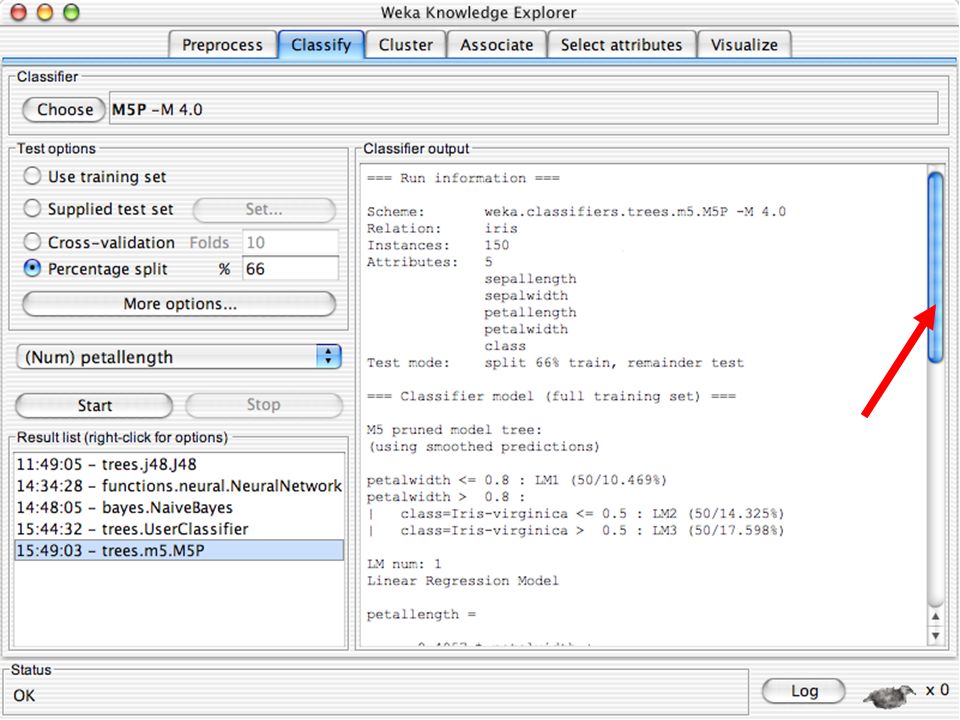
WEKA Construção de “classificadores”
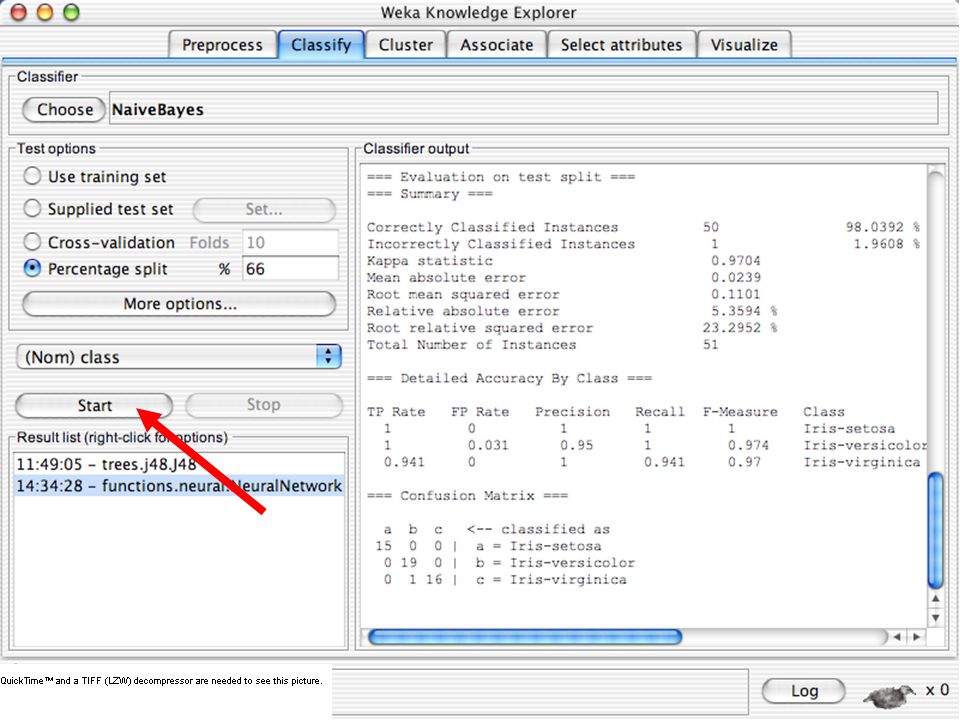
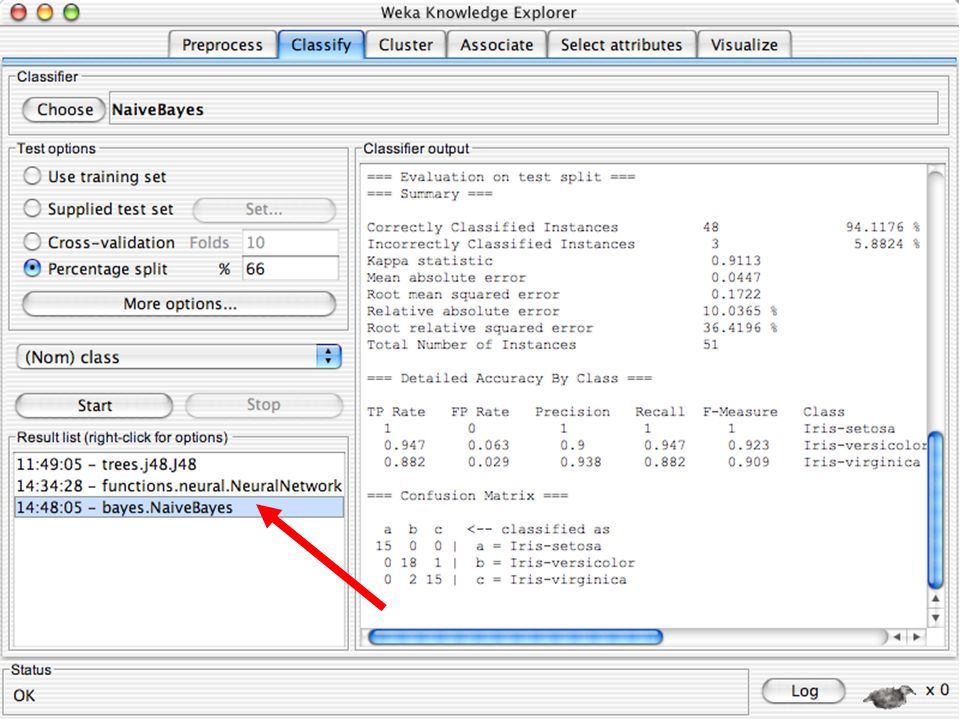
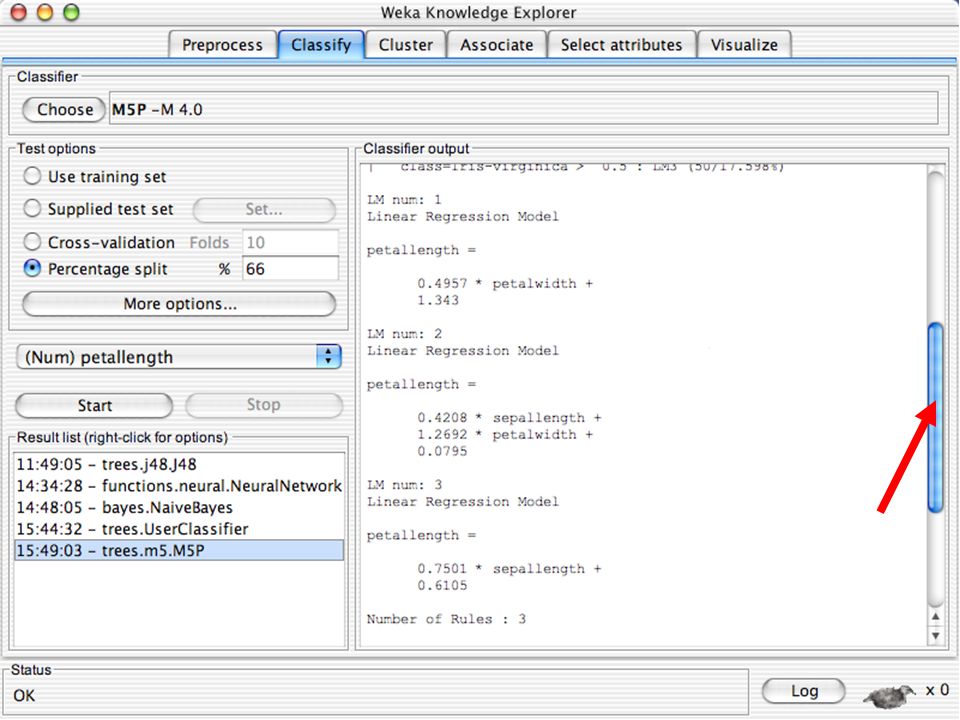
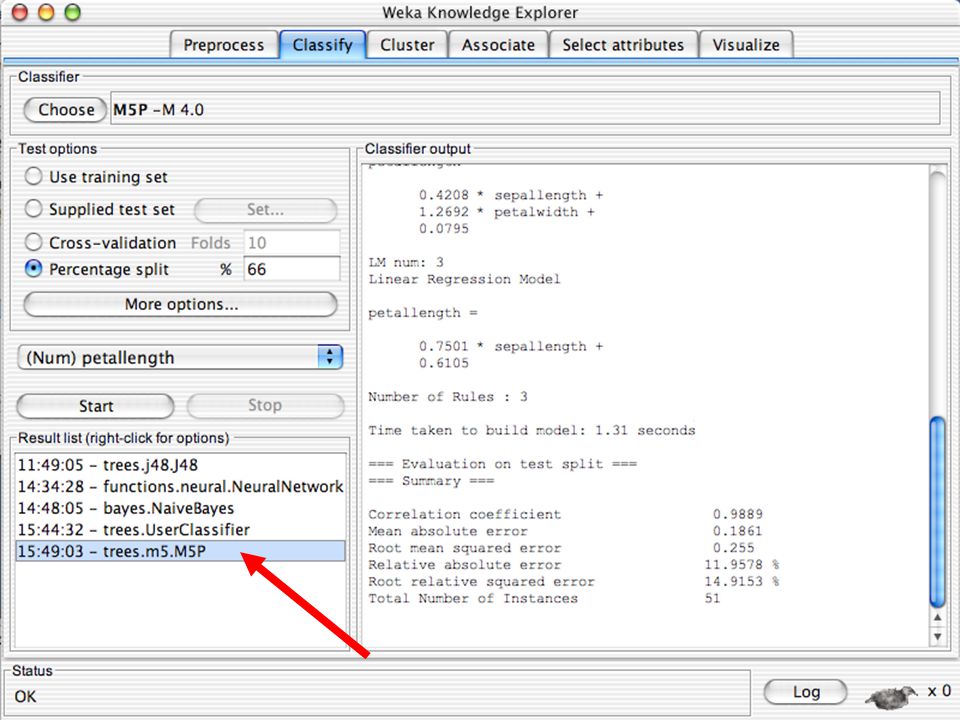
Classificadoes no WEKA são modelos para predição nominal ou de quantidades numéricas (sic) Incluem: Árvores e listas de decisão Classificadores baseados em instâncias “Support Vector Machines” (Método baseado em aprendizagem estatística) Redes neurais (Multi-Layer Perceptrons, …) Regressão logística (Método estatístico de predição de valores de variáveis categóricas) Redes bayesianas (Método probabilístico) … Ferramentas para melhoria do desenpenho dos classificadores (Meta-classificadores) 82
 Incluem: Árvores e listas de decisão. Classificadores baseados em instâncias. Support Vector Machines (Método baseado em aprendizagem estatística) Redes neurais (Multi-Layer Perceptrons, …) Regressão logística (Método estatístico de predição de valores de variáveis categóricas) Redes bayesianas (Método probabilístico) … Ferramentas para melhoria do desenpenho dos classificadores (Meta-classificadores) 82.")
123
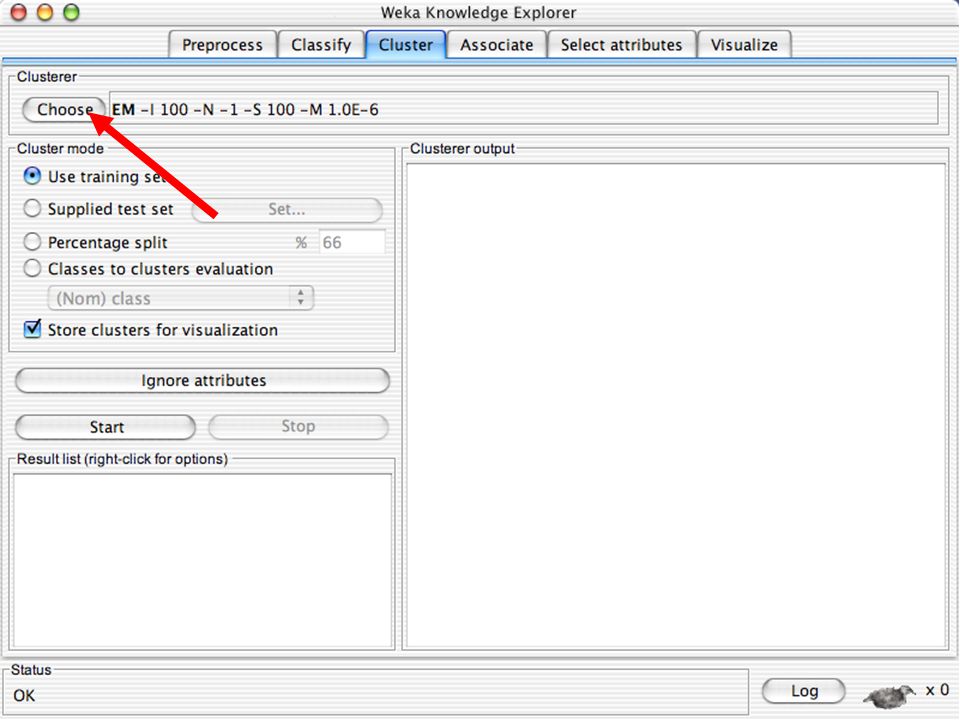
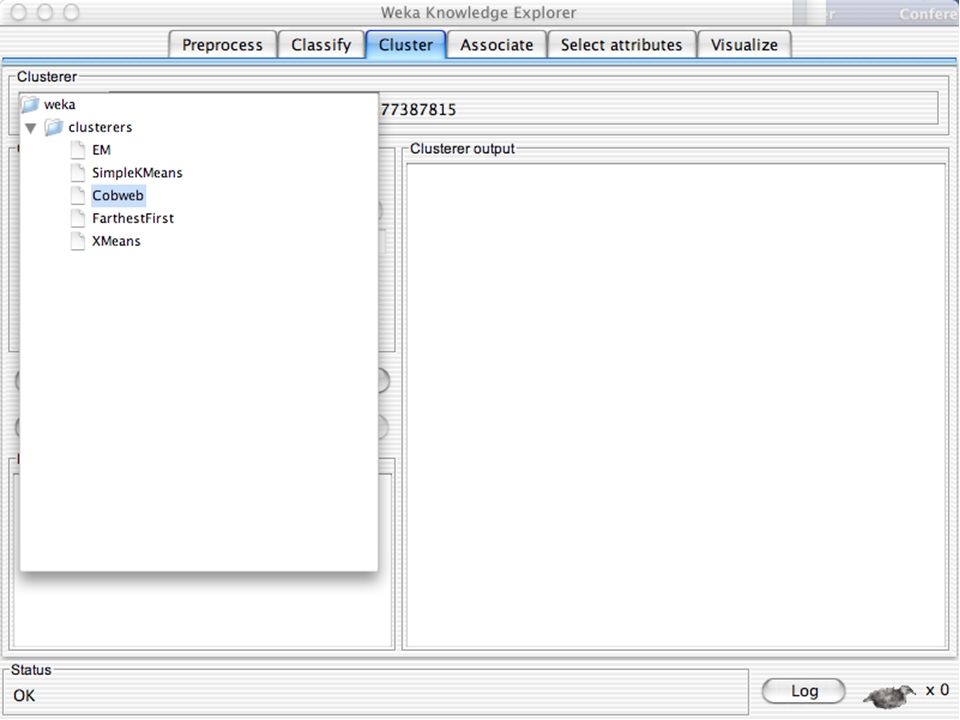
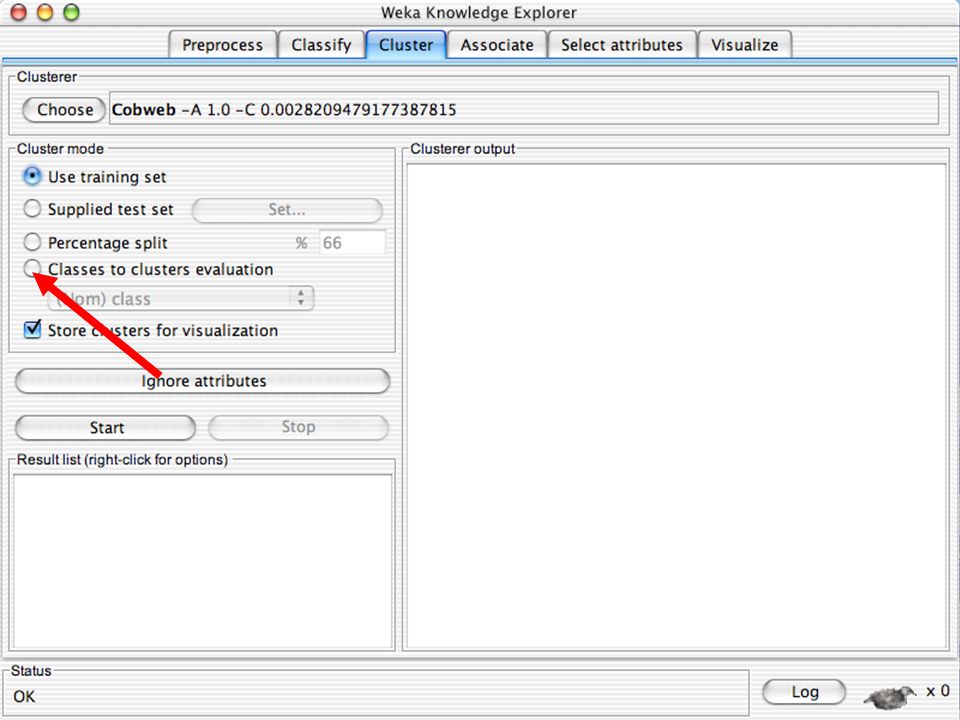
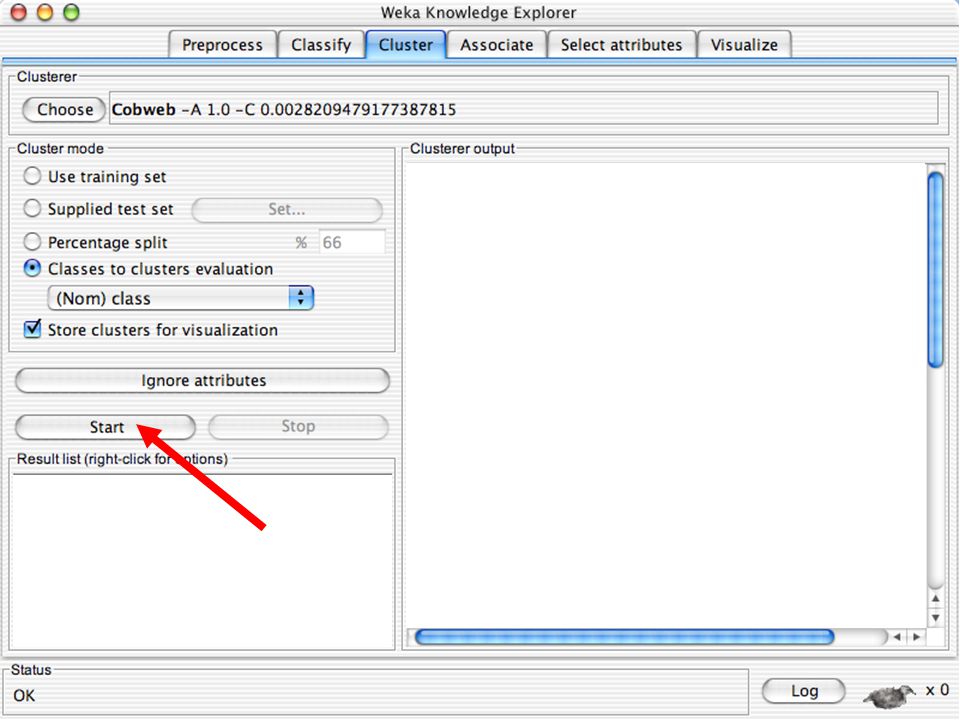
WEKA Agrupamento de dados
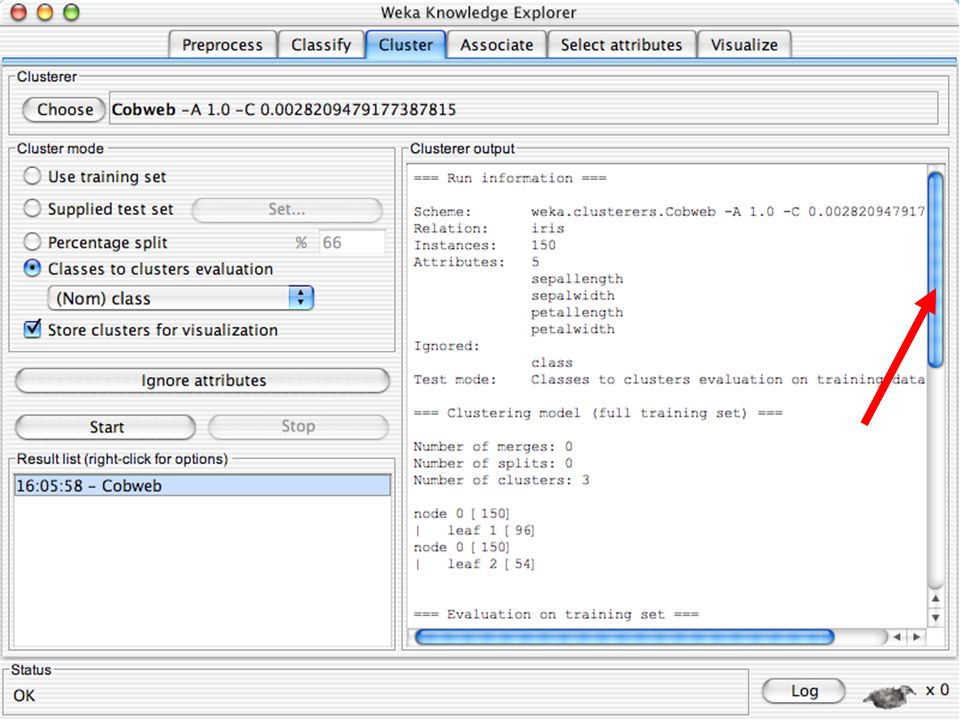
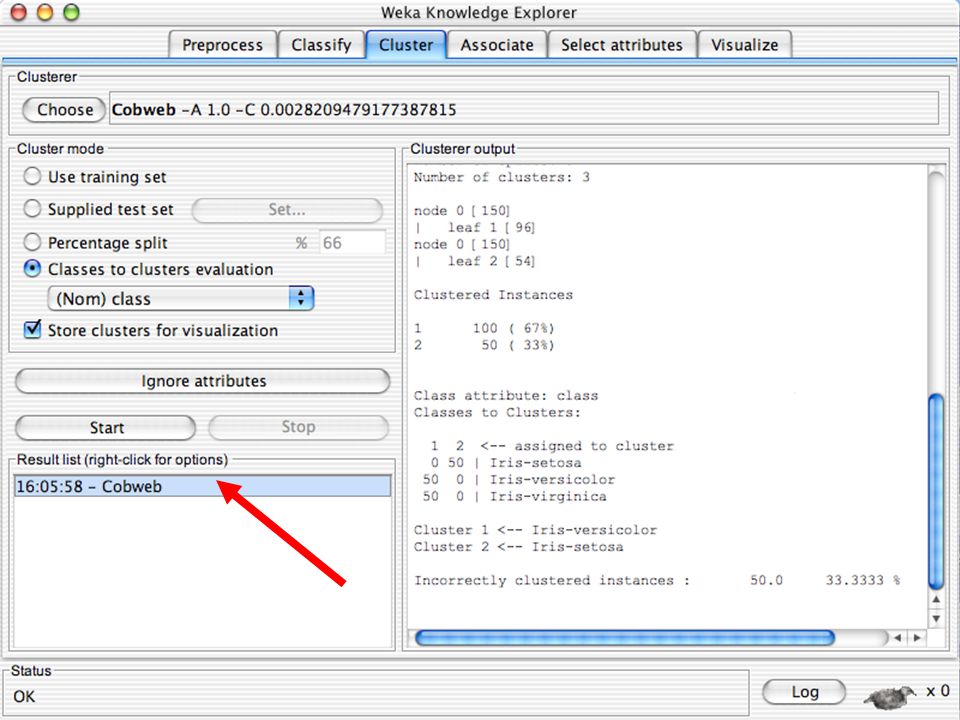
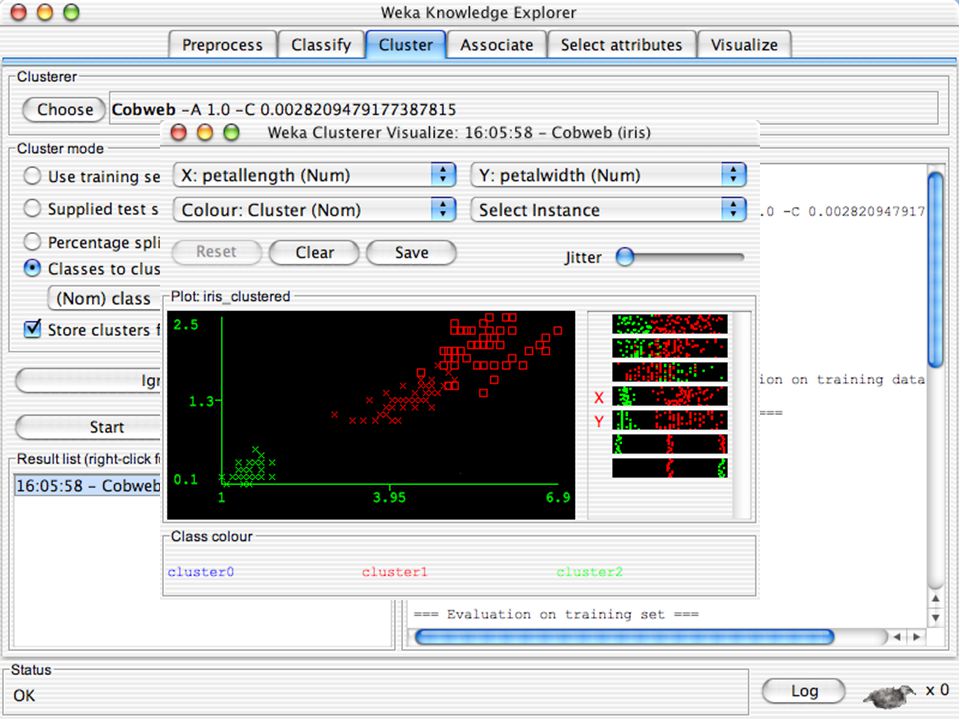
WEKA contém “agrupadores” para encontrar grupos de instâncias similares em um conjunto de dados Métodos implementados: k-Means EM Cobweb X-means FarthestFirst Agrupamentos podem ser visualizados e comparados a agrupamentos “verdadeiros” (se existir) 123
 123.")
134
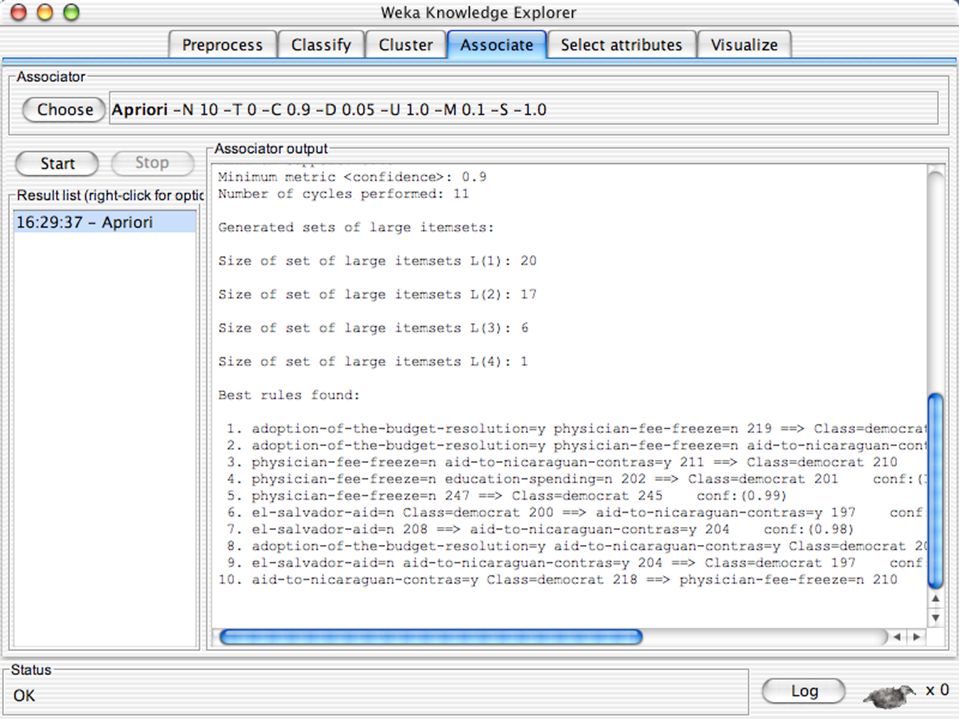
WEKA Associação WEKA contém uma implementação do algoritmo Apriori para aprendizagem de regras de associação Só trabalha com dados discretos Pode identificar dependências estatísticas entre grupos de atributos: leite, manteiga pão (com confiança 0.9 e suporte 4) Apriori pode computar todas as regras com um suporte mínimo e uma certa confiança 134
 Apriori pode computar todas as regras com um suporte mínimo e uma certa confiança")
139
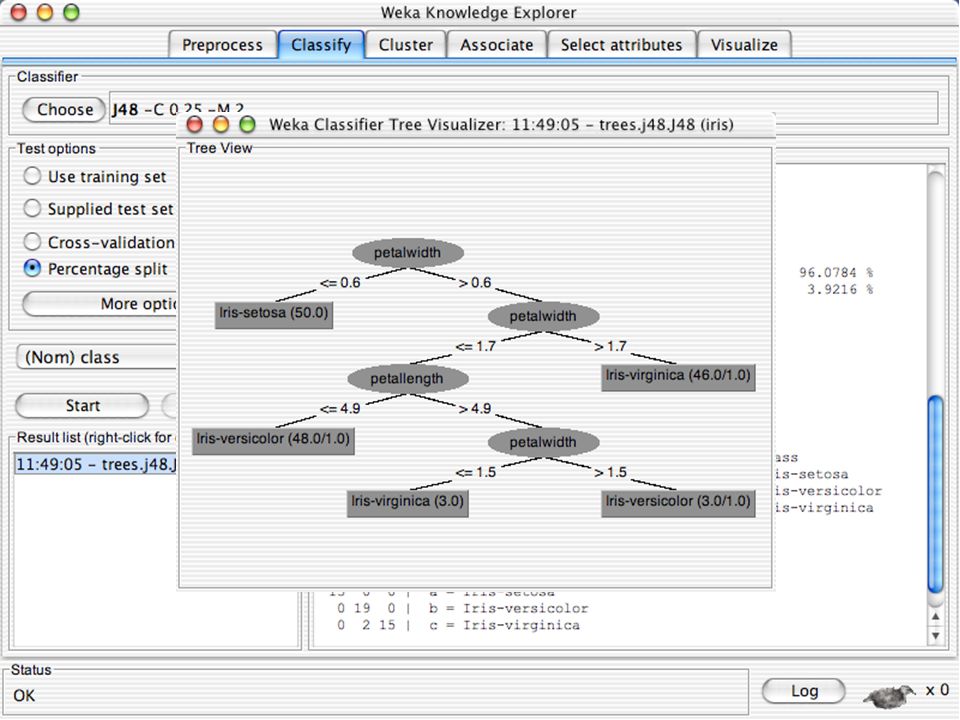
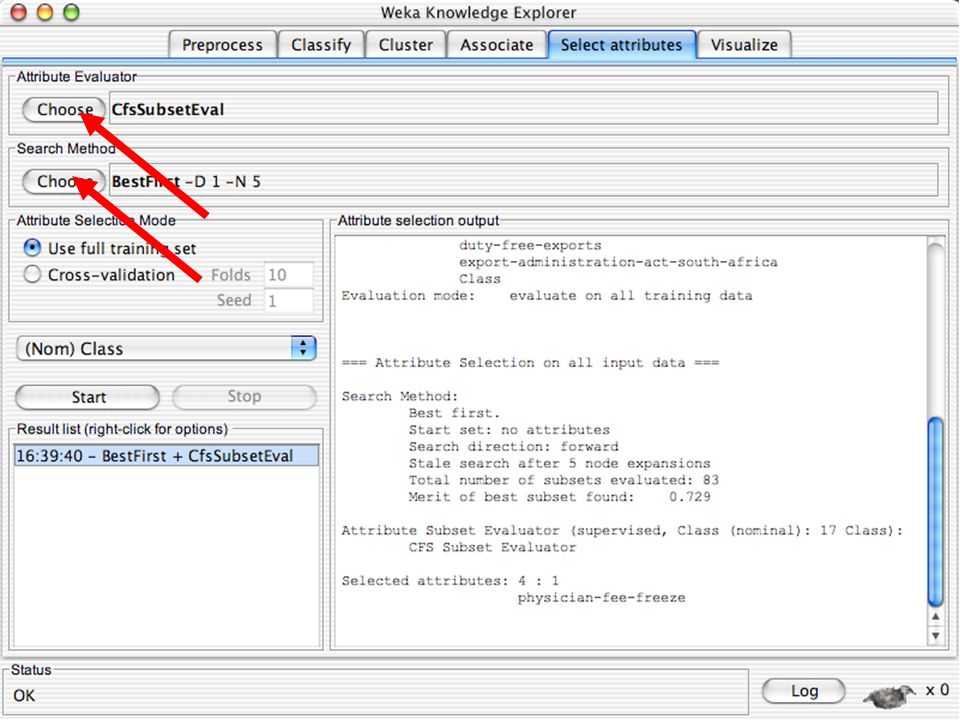
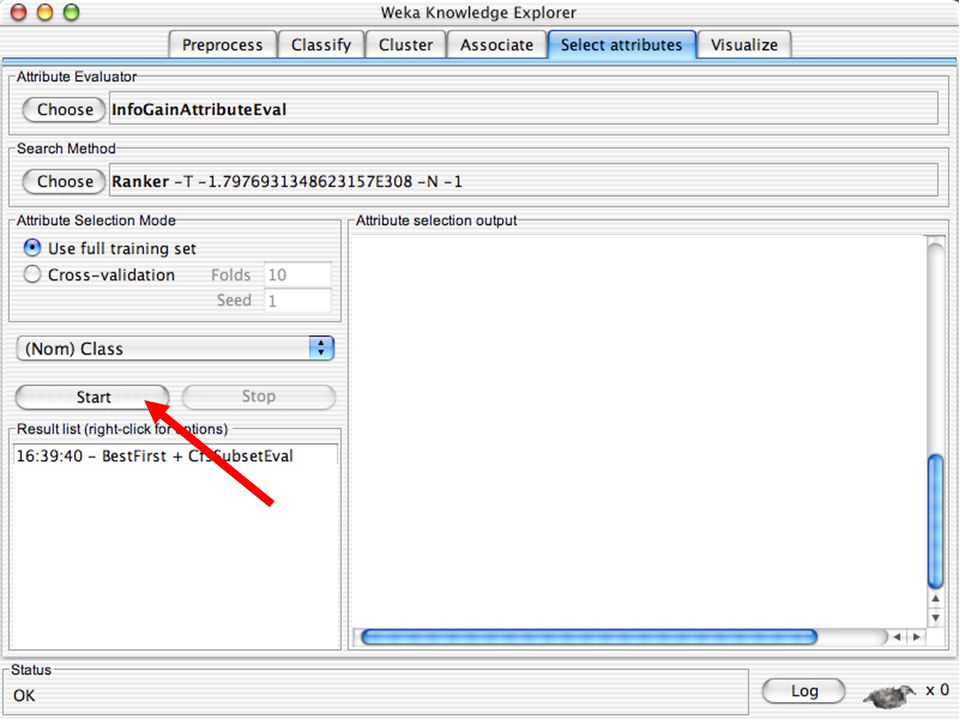
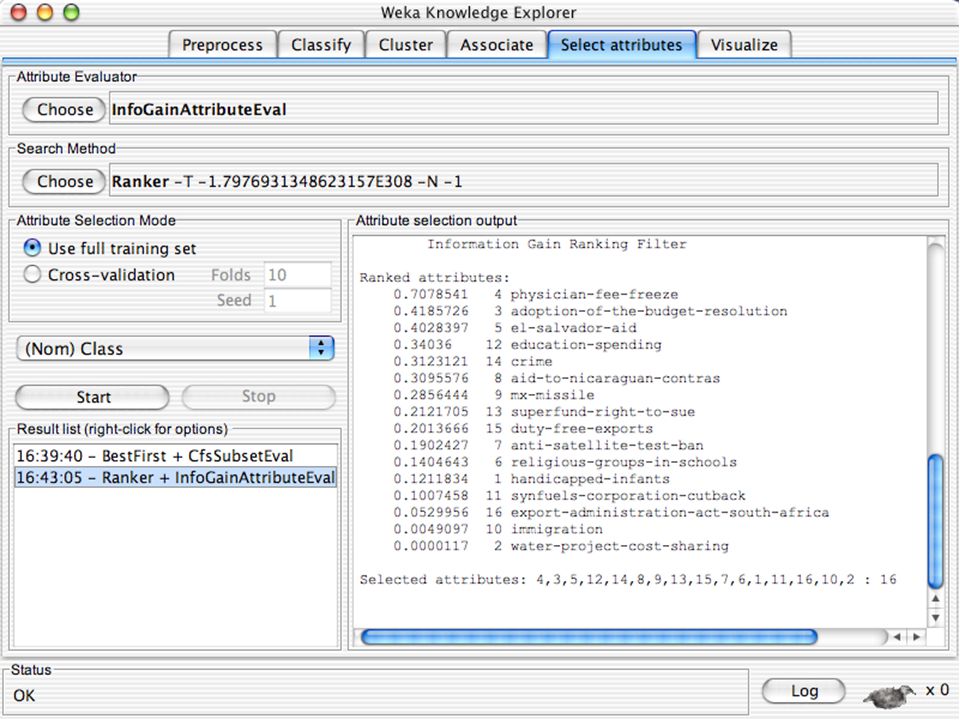
WEKA Seleção de atributos
Painel que pode ser usado para investigar quais (subconjunto de) atributos são os mais preditivos Seus métodos contêm um método de busca e um método de avaliação WEKA disponibiliza combinações (semi-)arbitrárias desses métodos 139
 atributos são os mais preditivos. Seus métodos contêm um método de busca e um método de avaliação. WEKA disponibiliza combinações (semi-)arbitrárias desses métodos")
146
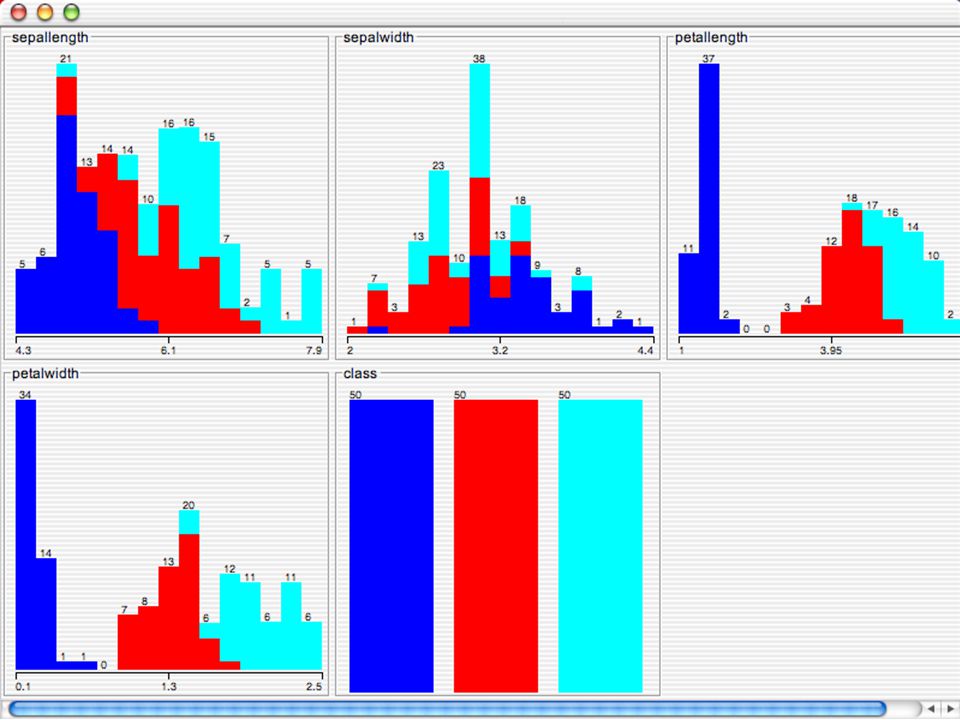
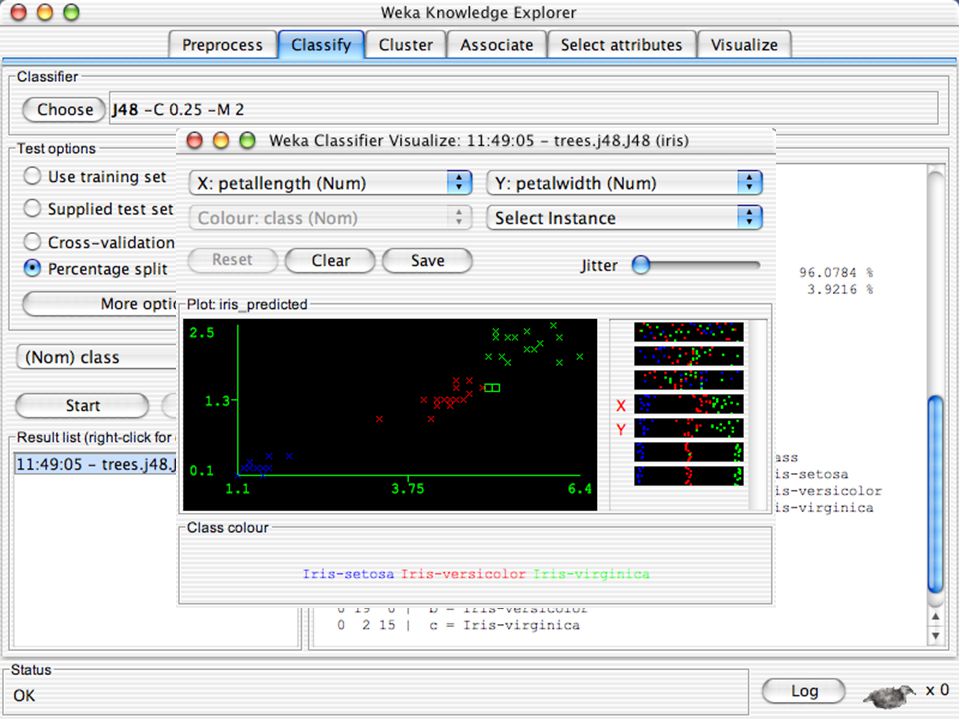
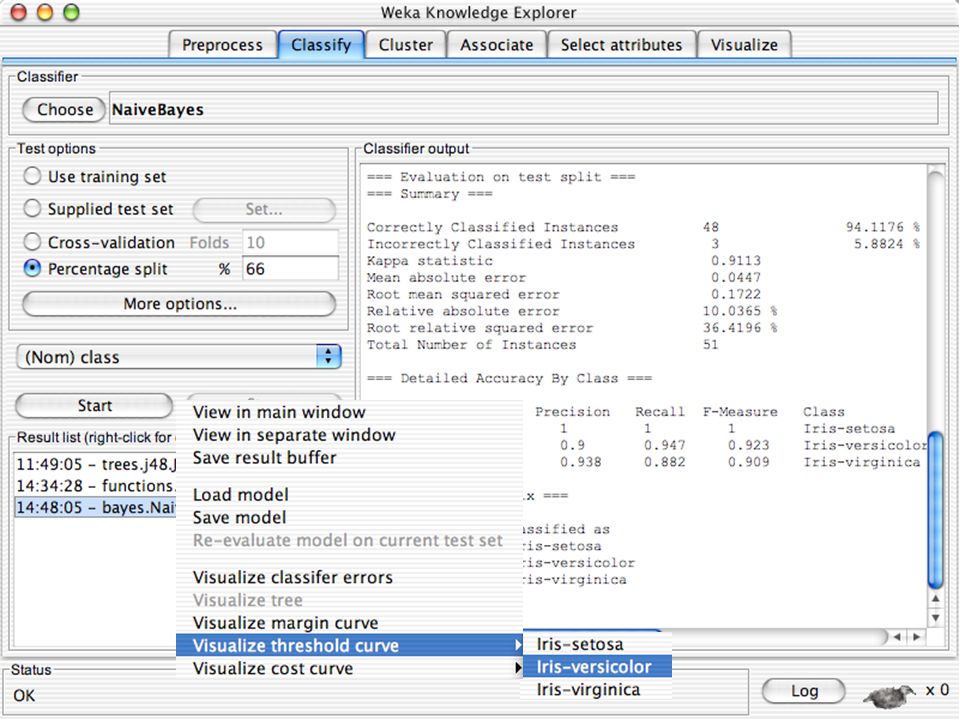
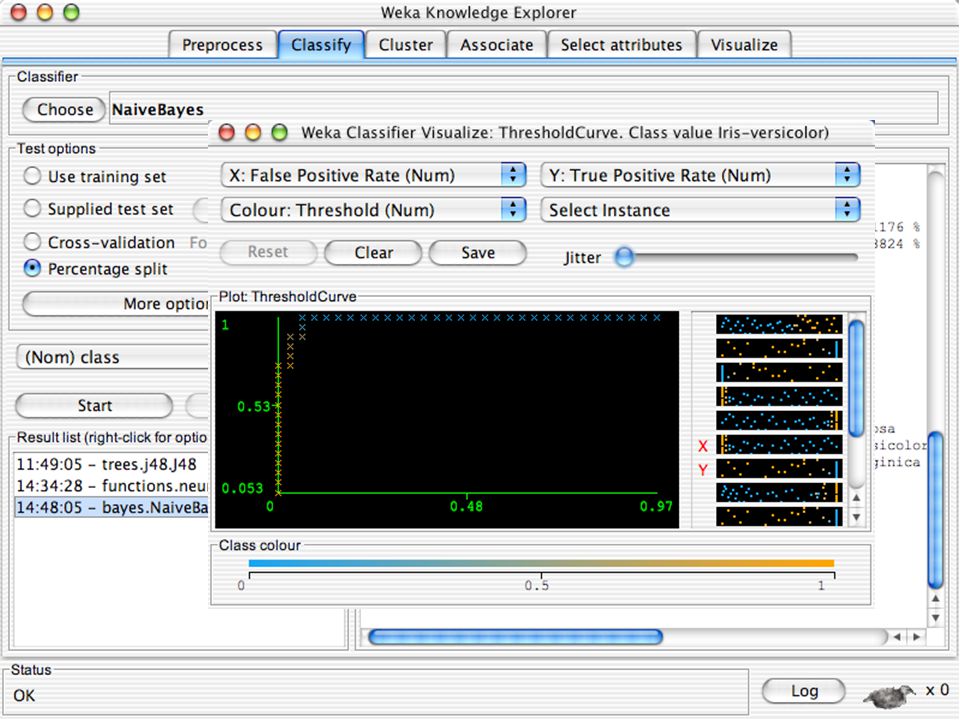
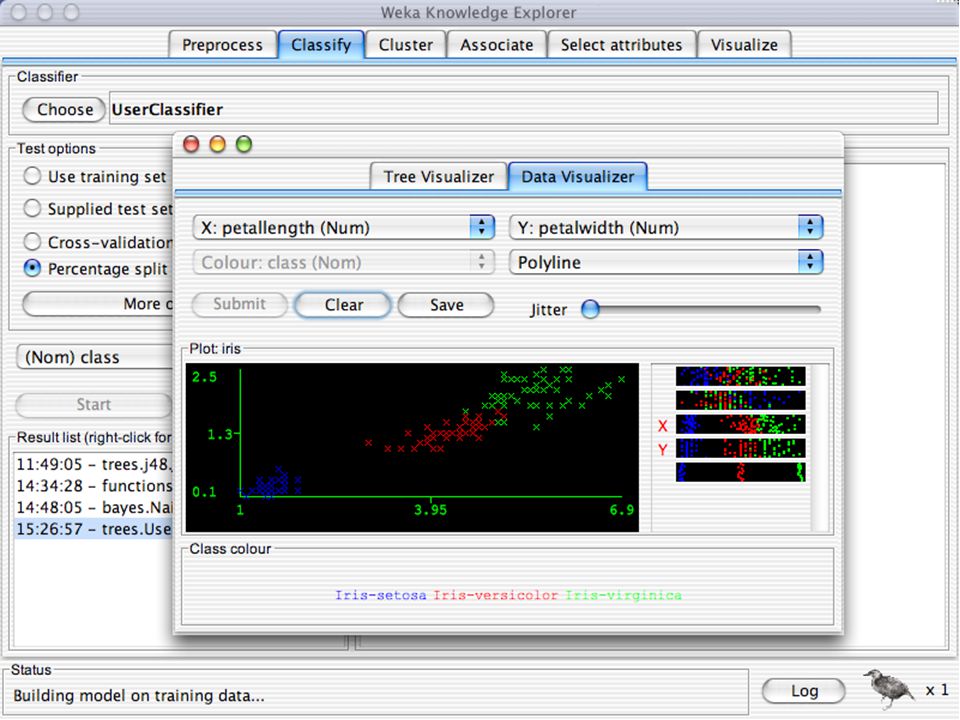
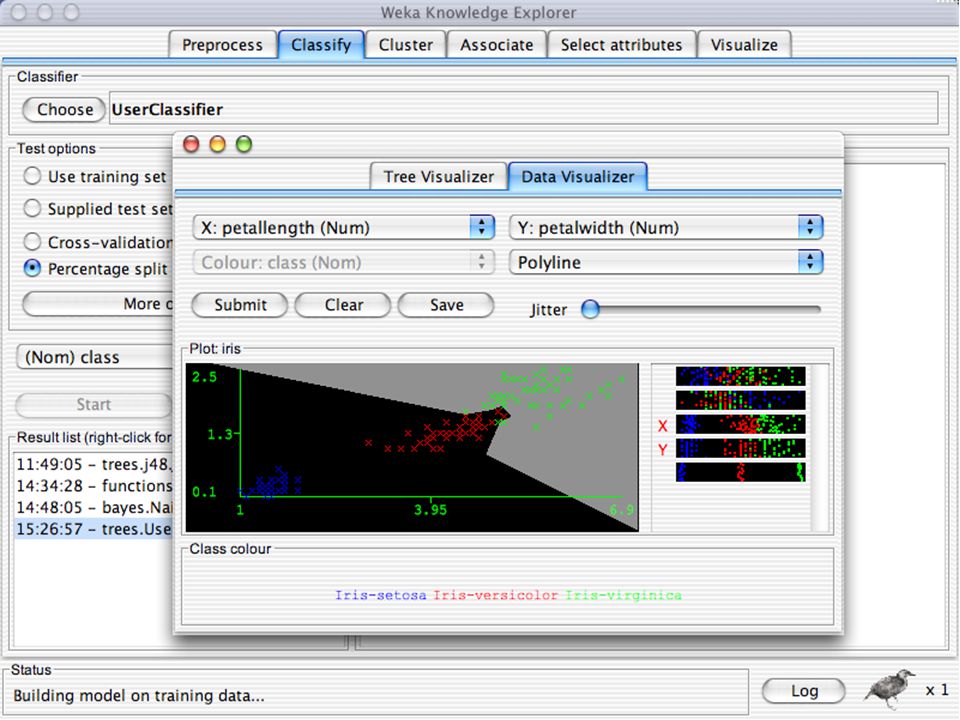
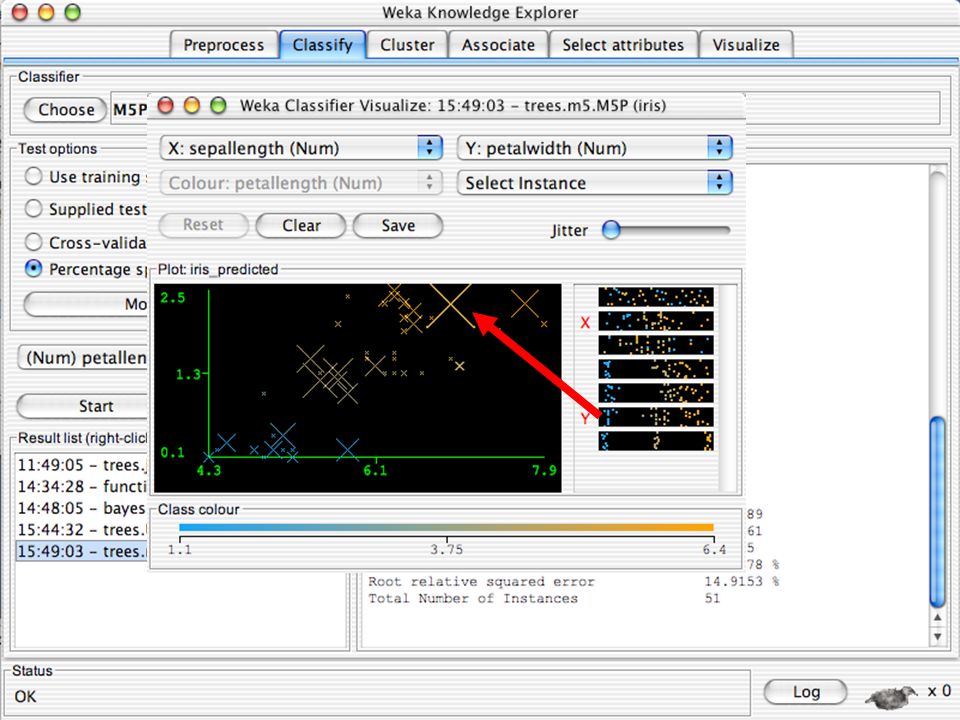
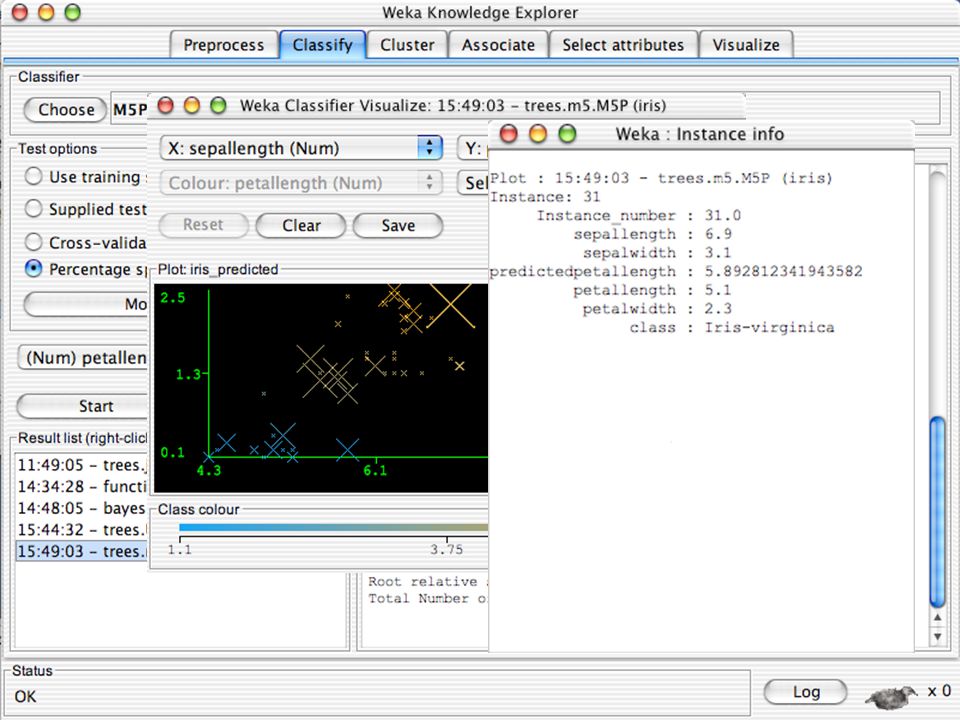
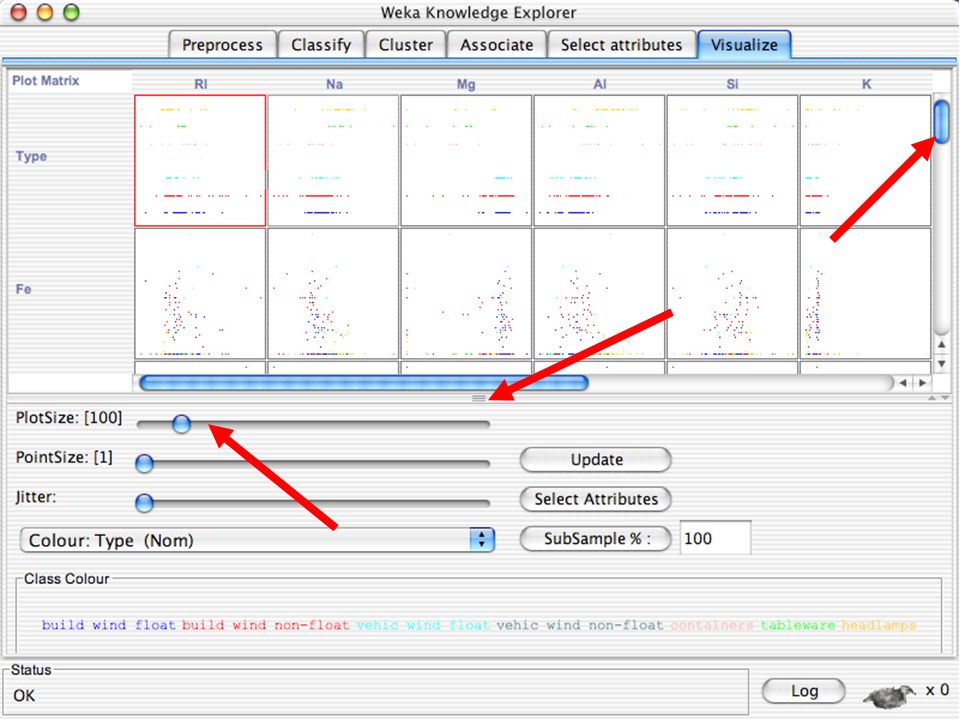
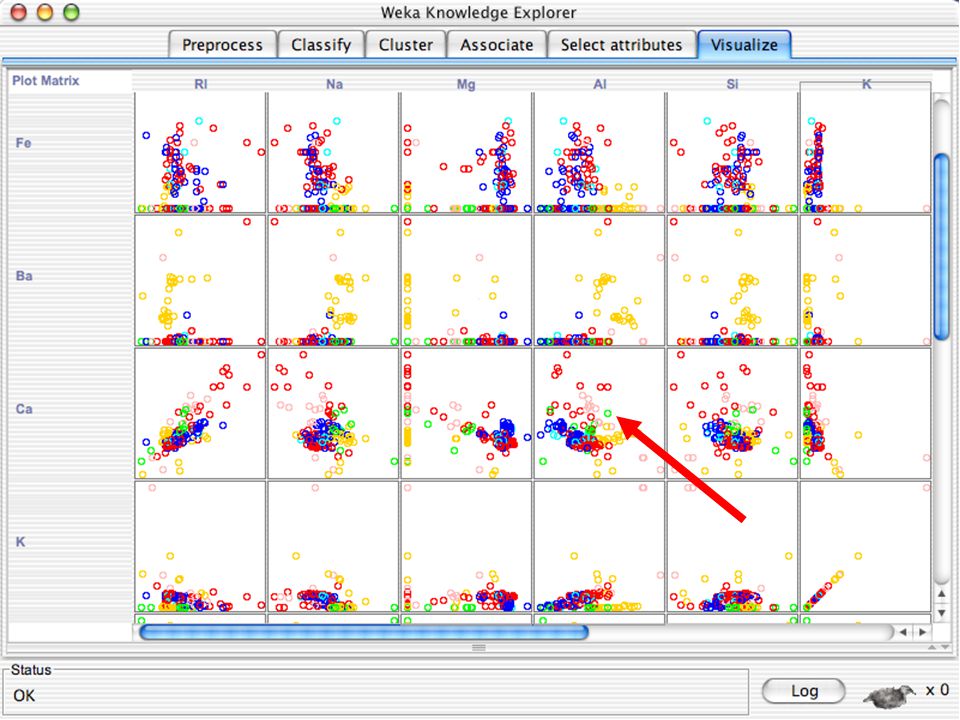
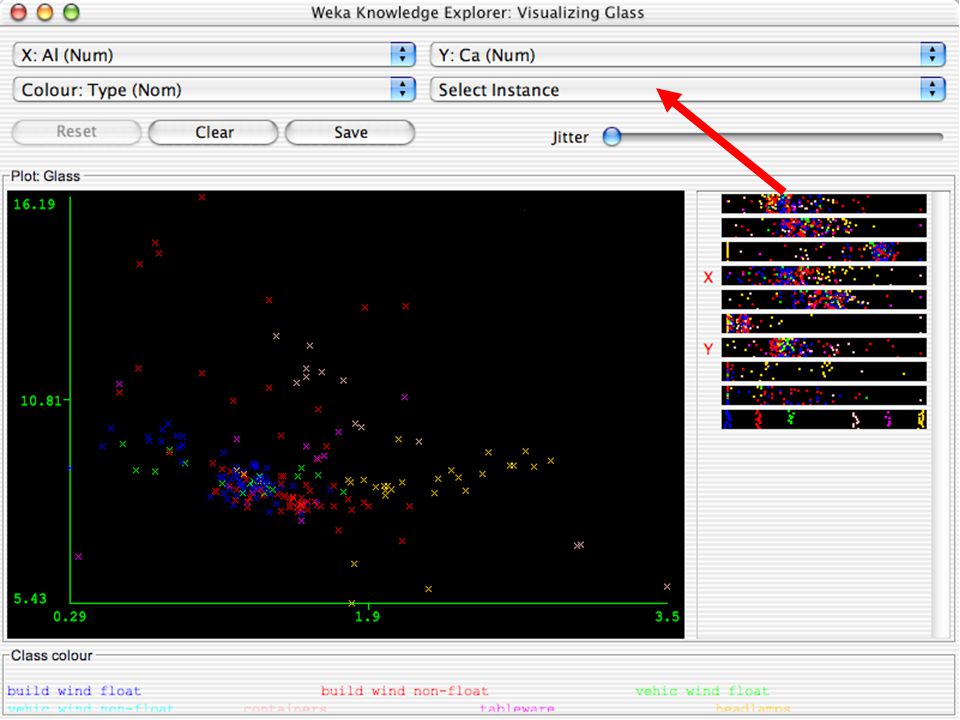
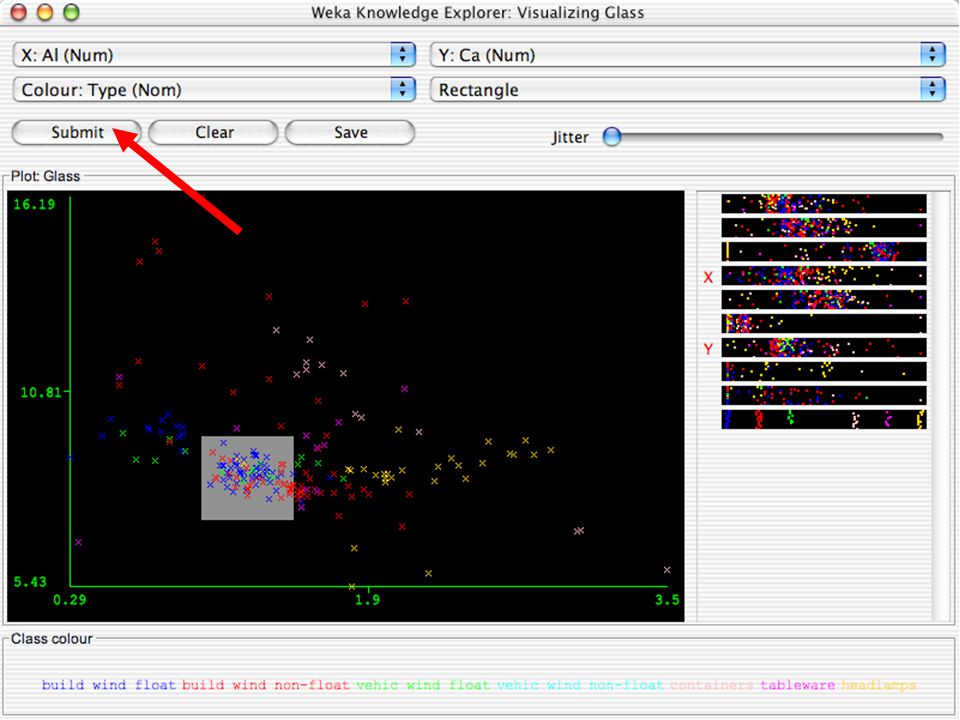
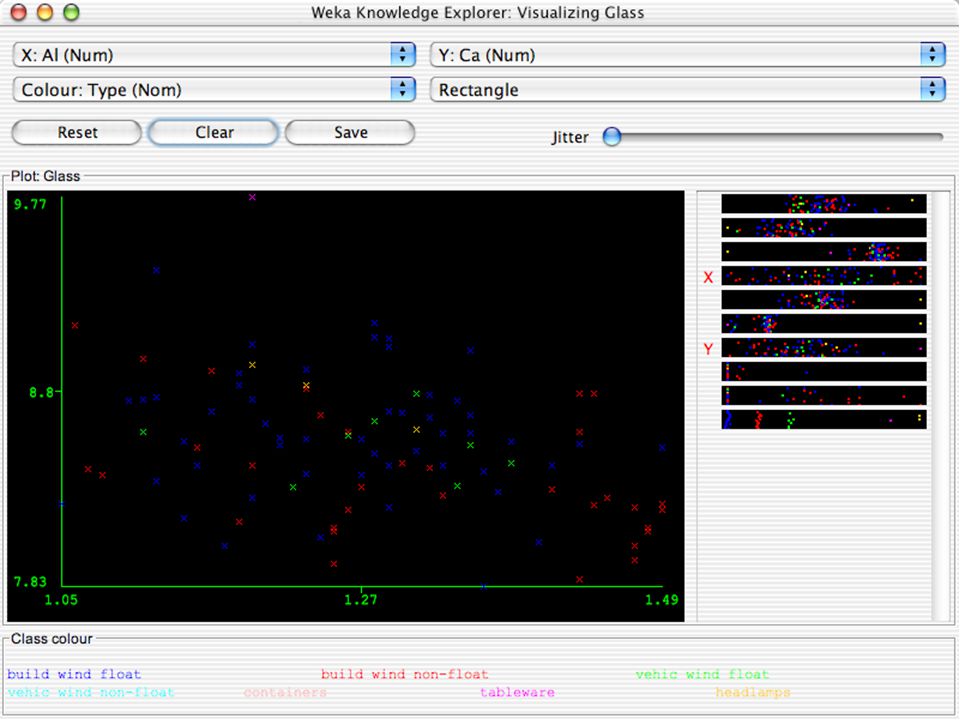
WEKA Visualozação de dados Bastante útil na prática:
Por exemplo, ajuda a determinar a dificuldade do problema de aprendizagem WEKA pode visualizar atributos simples (1-d) e pares de atributos (2-d) Valores de classe codificados por cores Opção de “Jitter” para lidar com atributos nominais (e detectar pontos de dados “escondidos”) Função “Zoom-in” 146
 e pares de atributos (2-d) Valores de classe codificados por cores. Opção de Jitter para lidar com atributos nominais (e detectar pontos de dados escondidos ) Função Zoom-in 146.")
153
Aplicações Mercado Data Mining de sucesso
Pode ser utilizada para controlar custos ou para aumentar lucros Exemplos: Gestão da relação com os clientes: determinando os que podem ir para a concorrência, pode-se agir para retê-los (é geralmente bem mais barato reter um cliente do que adquirir um novo) Marketing: identificando bons candidatos para ofertas e catálogos, pode-se reduzir despesas e aumentar as vendas Data Mining de sucesso Mais importante que a escolha de qualquer algoritmo são Capacidade do construtor do modelo e a forma como um programa suporta o processo de construção do modelo! O grau em que a ferramenta de data mining suporta a exploração interativa dos dados Essa interação é mais eficiente quando os componentes seguintes são bem integrados: Boas ferramentas de visualização para compreender os dados e interpretar os resultados Algoritmos para a construção dos modelos Duas chaves para o sucesso: Formular corretamente o problema que se quer resolver Utilizar os dados corretos 153
 Marketing: identificando bons candidatos para ofertas e catálogos, pode-se reduzir despesas e aumentar as vendas. Data Mining de sucesso. Mais importante que a escolha de qualquer algoritmo são. Capacidade do construtor do modelo e a forma como um programa suporta o processo de construção do modelo! O grau em que a ferramenta de data mining suporta a exploração interativa dos dados. Essa interação é mais eficiente quando os componentes seguintes são bem integrados: Boas ferramentas de visualização para compreender os dados e interpretar os resultados. Algoritmos para a construção dos modelos. Duas chaves para o sucesso: Formular corretamente o problema que se quer resolver. Utilizar os dados corretos")
154
Aplicações Análise e gerenciamento de mercado
Marketing de precisão Gerenciamento de relações com consumidores Análise de cestas de mercado Vendas cruzadas Segmentação de mercado Análise e gerenciamento de risco Previsões retenção de clientes controle de qualidade análise de competitividade Análise e gerenciamento de fraudes 154

155
Aplicações Análise e gerenciamento de mercado Marketing de precisão
Transações com cartões de crédito, cartões de fidelidade, cupons de desconto, requisições de clientes e estudos sobre o estilo de vida dos clientes Marketing dirigido Encontra grupos de clientes “modelo” que compartilham as mesma características: interesses, salário, hábitos de consumo, ... Determinação de padrões de compra ao longo do tempo Conversão de conta simples para conjunta, casamento, ... Análise de vendas cruzadas Associações e correlações entre vendas de produtos Predição baseada na informação de associações Perfil do consumidor Tipos de consumidores que compram quais produtos (agrupamento ou classificação) Identificação dos requisitos dos clientes Identifcação dos melhores produtos para os diferentes clientes Uso de predição para encontrar quais fatores atrairão os consumidores 155
 Identificação dos requisitos dos clientes. Identifcação dos melhores produtos para os diferentes clientes. Uso de predição para encontrar quais fatores atrairão os consumidores")
156
Aplicações Análise corporativa e gerenciamento de risco
Planejamento financeiro e avaliação de crédito Análise e previsão de fluxo de caixa Análise contingente para avaliação de crédito Análise seccional e temporal (razão financeira, análise de tendência, etc.) Planejamento de recursos Sumarização e comparação de recursos e gastos Competição Monitoramento de competidores e mercado Agrupamento de clientes em classes e procedimentos de preços baseados em classes Estratégias para fixação de preços em mercado competitivo 156
 Planejamento de recursos. Sumarização e comparação de recursos e gastos. Competição. Monitoramento de competidores e mercado. Agrupamento de clientes em classes e procedimentos de preços baseados em classes. Estratégias para fixação de preços em mercado competitivo")
157
Aplicações Detecção e gerenciamento de fraudes
Amplamente utilizado em serviços de cartões de crédito, telefonia celular, convênios de saúde, etc Uso de dados históricos para construir modelos do comportamento fraudulento e uso de data mining para identificar instâncias similares Exemplos Seguros de automóveis – Detecção de grupos de pessoas que forjam acidentes Lavagem de dinheiro – Detecção de transações suspeitas de dinheiro (US Treasury's Financial Crimes Enforcement Network) Seguros médicos – Detecção de pacientes ”profissionais” e grupos de doutores coniventes Detecção de tratamento médico inapropriado (A Australian Health Insurance Commission identificou que em muitos casos exames desnecessários eram solicitados - economia de AD$ 1 milhão /ano) Detecção de fraudes telefônicas – Modelo de chamadas telefônicas: destino da chamada, duração, horário e dia da semana; análise de padrões para detectar desvios A British Telecom identificou grupos de clientes com chamadas freqüentes dentro do grupo, especialmente em telefones celulares, e detectou uma fraude milionária Venda a varejo – Analistas estimam que 38% das perdas são devidas a empregados desonestos 157
 Seguros médicos – Detecção de pacientes profissionais e grupos de doutores coniventes. Detecção de tratamento médico inapropriado (A Australian Health Insurance Commission identificou que em muitos casos exames desnecessários eram solicitados - economia de AD$ 1 milhão /ano) Detecção de fraudes telefônicas – Modelo de chamadas telefônicas: destino da chamada, duração, horário e dia da semana; análise de padrões para detectar desvios. A British Telecom identificou grupos de clientes com chamadas freqüentes dentro do grupo, especialmente em telefones celulares, e detectou uma fraude milionária. Venda a varejo – Analistas estimam que 38% das perdas são devidas a empregados desonestos")
158
Aplicações Outras aplicações Esportes Astronomia Internet
IBM Advanced Scout analisou as estatísticas dos jogos da NBA (cestas, bloqueios, assistências, faltas, etc) para auxiliar os times do New York Knicks e do Miami Heat; Astronomia JPL e o Observatório do Monte Palomar descobriram 22 quasars com o auxílio de data mining Internet IBM Surf-Aid aplica algoritmos de data mining a logs de acessos Web à páginas de vendas, para descobrir preferências e comportamentos dos clientes e efetuar análise da efetividade do Web marketing, melhorar a organização do site Web, etc. 158
 para auxiliar os times do New York Knicks e do Miami Heat; Astronomia. JPL e o Observatório do Monte Palomar descobriram 22 quasars com o auxílio de data mining. Internet. IBM Surf-Aid aplica algoritmos de data mining a logs de acessos Web à páginas de vendas, para descobrir preferências e comportamentos dos clientes e efetuar análise da efetividade do Web marketing, melhorar a organização do site Web, etc")
159
Aplicações Tendências Bases de dados heterogêneas,
distribuídas ou legadas Metadados Web Multimídia Texto Data Mining em bases de dados relacionais Informação geo-referenciada ... Tecnologias de suporte ao Data Mining 159

160
Artefatos para a Inteligência
Contatos Telefone UCB: (61) Celular: (61) Artefatos para a Inteligência
 Celular: (61) Artefatos para a Inteligência.")