Carregar apresentação
A apresentação está carregando. Por favor, espere

1
Bibliotecas Digitais Engenharia Biomédica Universidade do Minho

2
Sumário Introdução Processamento de Texto multilingue Busca de texto multilingue Busca de voz em várias línguas Avaliação de Sistemas Algumas aplicações Futuras direcções

3
O problema Pressão crescente para aceder à informação sem as barreiras tradicionais da cultura e da língua, implica a necessidade de ser capaz de : Encontrar informação em língua estrangeira Ler e interpretar essa informação Juntá-la com informação noutras línguas É necessário o Acesso a Informação Multilingue

4
Acesso a Informação Multilingue Ocupa-se da investigação para o armazenamento, acesso, busca e apresentação de informação em qualquer língua falada no mundo. Duas áreas de interesse principais: Acesso, navegação, visualização Busca e descoberta de informação em várias línguas

5
Processamento de texto em várias línguas A tecnologia de base Codificação de caracteres Requisitos específicos de cada língua Localização e apresentação

6
Busca de Informação Multilingue Cruzar a fronteira da língua … Interrogar uma colecção multilingue numa língua e buscar documentos relevantes noutras línguas Filtrar seleccionar e pontuar os documentos devolvidos

7
BIM é multidisciplinar Envolve investigadores das seguintes áreas: Recuperação de Informação (IR), Processamento de Linguagem Natural, Tradução automática, Sumarização, Processamento de Voz, interpretação de imagens, Interacção H/M Recursos de língua como dicionánrios, thesauri, corpora e colecções de teste.
, Processamento de Linguagem Natural, Tradução automática, Sumarização, Processamento de Voz, interpretação de imagens, Interacção H/M Recursos de língua como dicionánrios, thesauri, corpora e colecções de teste.")
8
Porquê que o BIM é importante? Internacionalização – Países multilingues(Suiça, Canadá) – Áreas de Cooperação Económica (EU, EFTA, NAFTA) Globalização da economia – multinacionais – Empregados falam línguas diferentes – Clientes falam línguas diferentes – Documentos precisam de ser acedidos em várias línguas
 – Áreas de Cooperação Económica (EU, EFTA, NAFTA) Globalização da economia – multinacionais – Empregados falam línguas diferentes – Clientes falam línguas diferentes – Documentos precisam de ser acedidos em várias línguas.")
9
Sociedade de Informação Global Larga gama de aplicações em que a informação tem que estar disponível aos utilizadores indepentemente da língua: – Comércio electrónico – Entretimento – Educação

10
Sociedade de Informação Global WWW como plataforma para disseminação do conhecimento – Ensino à distância – Bibliotecas Digitais….. Fornecedores e consumidores de informação devem ter igualdade de oportunidade Preservação das línguas nacionais…

11
WWW e Internet A Internet ja não está só em Inglês e O perfil dos utilizadores está mudar drasticamente – Usada inicialmente só por académicos, agora está ser para publicidade, divertimento, educação, etc....

12
WWWe Internet Internacionalização da Internet – O grupo das pessoas que não falam inglês é o que regista maior crescimento como novos utilizadores da Internet Em1997, 8.1 milhões utilizadores de língua espanhola Em 2000, 37 milhões……..

13
83M Utilizadores da Internet de língua não inglesa Japonês 17.4% Espanhol 17.1% Alemão 16.8% Francês 10% Chinês 7.7% Holandês 5.3% Sueco 4.3% Coreano 4.4% Italiano 4% Português 2.2%

14
Mudanças na Internet Em 2005, 68% dos utilizadores falarão uma língua diferente do inglês Total dos utilizadores passará de 171 milhões para 345 milhões em 2005 Portanto … 270 milhões não falantes de inglês (dos 83M actuais)
")
15
Inglês 12% 6% 4% 8% 2% 5% 40% 68% não falantes de inglês em 2005 8% 2% 6% 2% EspanholJaponêsAlemãoFrancês ChinêsEscandinavoItalianoHolandês CoreanoPortuguêsOutrosInglês

16
Línguas Mais Faladas 0 200 400 600 800 Nº de Pessoas (Milhões) Chinês Inglês Hindi-Urdu Espanhol Português Bengali Russo Árabe Japanês Fonte: http://www.g11n.com/faq.html
 Chinês Inglês Hindi-Urdu Espanhol Português Bengali Russo Árabe Japanês Fonte:")
17
Tamanho do Web: Crescimento Exponensial 0 1 10 100 1.000 10.000 Out-96Out-97Out-98Out-99Out-00Out-01Out-02Out-03Out-04Out-05 Bilhões de palavras InglêsOutras Europeias Fonte: Extrapolado de Grefenstette e Nioche, RIAO 2000

18
História: objectivos 1978: ISO Standard 5964 thesauri multilingue disponível. Versão revista em 1985 1991: Publicada a norma Unicode, Versão 1.0 1993: ISO/IEC 10646 publicado como "Universal Multiple-Octet Coded Character Set” (UCS).
..")
19
História: objectivos 1995: TANGO um web browser multilingue Netscape/Explorer suportam UNICODE e fontes para outras línguas

20
História: primeiras abordagens 1970: thesaurus (Salton) 1991-94: Projecto EMIR –1º projecto BIM na CE - busca de texto em inglês, francês, alemão 1994: 1 ª tese de doutoramento em BIM por Khaled Radwan (França)
 : Projecto EMIR –1º projecto BIM na CE - busca de texto em inglês, francês, alemão 1994: 1 ª tese de doutoramento em BIM por Khaled Radwan (França)")
21
História: primeiras abordagens 1996 Busca baseada em dicionário (Umass & XEROX Grenoble) 1996 Abordagem baseada em Corpus (ETH Zurich) 1997 Modelo do Espaço Vectorial Generalizado (CMU)
 1996 Abordagem baseada em Corpus (ETH Zurich) 1997 Modelo do Espaço Vectorial Generalizado (CMU)")
22
História: Objectivos da Comunidade de I&D 1996: 1 st Workshop on “Cross-Lingual Information Retrieval” no SIGIR ’96. A comunidade começa a ser identificada à volta desta área. 1997: AAAI Spring Symposium on Cross- Language Text and Speech Retrieval

23
AAAI – O grande desafio Dada uma interrogação em qualquer media e língua, selecionar itens relevantes duma colecção multimedia e multilingue, e apresentá- los ao utilizador da forma mais adequada, com os objectos idênticos ou bastante parecidos nos diferentes média ou língua identificados convenientemente. [AAAI Stanford Symposium 1997]

24
História: Objectivos da Comunidade de I&D 1997: EU-NSF Working Group em Acesso a Informação Multilingue (Multilingual Information Access). 1999: Disponível Relatório NSF/EC/DARPA em Gestão de Informação Multilingue. Cursos/Workshops em MLIA/CLIR comuns em Conferências de Information Retrieval, Computational Linguistics e Digital Libraries em vários pontos do mundo.

25
História: Objectivos de Avaliação 1997: 1 st Cross-Language IR track no TREC (Text REtrieval Conferences) 1998-99: Amaryllis inclui avaliação multilingue em inglês e francês 1999: 1 º Workshop Japonês em IR inclui linha em CLIR (BIM)
 : Amaryllis inclui avaliação multilingue em inglês e francês 1999: 1 º Workshop Japonês em IR inclui linha em CLIR (BIM)")
26
História: Objectivos de Avaliação 1999: começa nos EUA o projecto TIDES (Translingual Information Detection, Extraction, and Summarization). 2000: é iniciado CLEF – Cross-Language Evaluation Forum for European Languages

27
Desafios Suportar o acesso à informação multilingue em vários média (texto, voz e video) Indexar informação em língua estrangeira Buscar informação em várias línguas com uma única interrogação Permitir a navegação na informação devolvida na língua do utilizador
 Indexar informação em língua estrangeira Buscar informação em várias línguas com uma única interrogação Permitir a navegação na informação devolvida na língua do utilizador")
28
Processamento de texto multilingue Codificação de caracteres Detecção da língua Extracção de palavras Remoção de palavras muito frequentes Radicalização (Stemming) Etiquetagem POS Identificação de frases
 Etiquetagem POS Identificação de frases")
29
Processamento de texto multilingue A representação do texto implica: l Conversão de caracteres l Extracção de palavras (tokenization) l Remoção de palavras comuns l Radicalização de palavras Necessidade de conhecimento específico da língua
 l Remoção de palavras comuns l Radicalização de palavras Necessidade de conhecimento específico da língua")
30
Codificação de caracteres Representação binária do alfabeto da língua Texto normalmente codificado numa forma dependente da língua Codificação em um ou dois bytes Norma UNICODE standard para representação de todas as línguas Suportar os códigos nativos ou transformar em UNICODE para processamento ou busca?

31
Codificação de caracteres Codificação específica da língua (alfabeto) : – ChinêsGB, Big5, – Europa OcidentalISO-8859-1 (Latin1) – RussoKOI-8, ISO-8859-5, CP-1251 UNICODE (ISO/IEC 10646) – UTF-8comprimento variável em bytes – UTF-16, UCS-2comprimento fixo de 2 bytes
 : – ChinêsGB, Big5, – Europa OcidentalISO (Latin1) – RussoKOI-8, ISO , CP-1251 UNICODE (ISO/IEC 10646) – UTF-8comprimento variável em bytes – UTF-16, UCS-2comprimento fixo de 2 bytes")
32
UNICODE / ISO 10646 Codificação de 16-bit (2-byte) concebida para contemplar todas línguas escritas 16 bits permitem à volta de 65,000 characteres UNICODE especifica actualmente 38,887 characters Cobre línguas das Americas, Europa, Médio Oriente, Africa, India, Asia Há espaco para novos caracteres ou caracteres específicos para aplicações
 concebida para contemplar todas línguas escritas 16 bits permitem à volta de 65,000 characteres UNICODE especifica actualmente 38,887 characters Cobre línguas das Americas, Europa, Médio Oriente, Africa, India, Asia Há espaco para novos caracteres ou caracteres específicos para aplicações")
33
O WorldWide Web multilingue Codificação dos caracteres especificado no campo do cabeçalho HTTP Content-Type – “Content-type: text/html; charset=iso-2022-JP” Atributo HTML “Lang” pode ser incluído na maioria dos elementos HTML –

34
O WorldWide Web multilingue Outros aspectos – Texto Bidirectional – onde se mistura texto lido da direita para esquerda e lido da esquerda para a direita – Formatos e unidades usados para mostar tempos, datas, pesos, etc.

35
O WorldWide Web multilingue Visualização de material em língua estrangeira… Utilização de um browser multilingue como TANGO… Instalar as fontes localmente na máquina usada… Download fontes para o Browser WWW… Os browsers estão a tentar suportar de forma nativa fontes para todas as línguas (Explorer) Problemas na composição de texto noutras línguas…
 Problemas na composição de texto noutras línguas…")
36
Identificação de língua Definição do problema I: Dado um documento monolingue duma colecção multilingue identificar a língua em que está escrito Definição do Problema II: Dado um documento multilingue identificar a língua de cada parágrafo ou frase

37
Identificação de língua Baseado na codificação específica da língua Usa modelos estatísticos de N-Gramas ou palavras Reconhece caracteres específicos da língua Usa listas de stopwords Usar a língua do último parágrafo ou uma por defeito

38
Extracção de palavras Pontuação separada das palavras. “The train stopped.” “The”, “train”, “stopped”, “.” Palavras separadas em unidades léxicas - incl. Segmentação(Chinese) e separação de formas compostas (Alemão)
 e separação de formas compostas (Alemão).")
39
Segmentação do Chinês

40
Estratégias de Segmentação Escolher um modelo – Strings únicas, strings plausíveis, interpretações palusíveis Combinar evidências – Lexicons, corpora, algoritmos, conhecimento do utilizador Escolher um critério de preferência – String mais longa, detecção de nomes próprios, etc.

41
Segmentação do Alemão Palavras compostas sem restrição – Abendnachrichtensendungsblock Usar análise de composição conjuntamente com o dicionário alemão CELEX (360,000 palavras) – Treuhandanstalt { treuhand, anstalt } – Washington { * was, hing, ton } É crucial a manutenção do dicionário
 – Treuhandanstalt { treuhand, anstalt } – Washington { * was, hing, ton } É crucial a manutenção do dicionário")
42
Remoção de Stop Words stop words frequentes (ex.. “o”, “um”, …) não-stop words frequentes (ex. “medicina” em informação médica) stop words não frequentes (ex. “todavia”) stop Words dependentes e não dependentes do domínio (ex. “computer science” na colecção do ACM)
 stop words não frequentes (ex. todavia ) stop Words dependentes e não dependentes do domínio (ex. computer science na colecção do ACM).")
43
Normalização dos índices Radicalização baseada em regras (e.g. Porter) Análise morfológica (e.g. InXight)
 Análise morfológica (e.g. InXight).")
44
Algoritmo de Stemming de Porter Remoção de sufixos baseada em regras 65 regras aplicadas em 5 iterações Correcção linguística dos radicais não é necessária 36% redução do índices (Inglês) Versões escritas para muitas línguas
 Versões escritas para muitas línguas")
45
Porter Stemming Regra Exemplo (True)IES I (m > 0)IVITI IVE (m > 1)IVE sensitivities sensitiviti sensitive sensit
IES I (m > 0)IVITI IVE (m > 1)IVE sensitivities sensitiviti sensitive sensit")
46
Stemming Francês (ETH) 84 regras de sufixo em 8 grupos RegraGrupo sufixoExemplo er(s), ère(s) teur(s), trice(s) (*)ère er (*)trice teur dernière dernier éducatrice éducateur
 84 regras de sufixo em 8 grupos RegraGrupo sufixoExemplo er(s), ère(s) teur(s), trice(s) (*)ère er (*)trice teur dernière dernier éducatrice éducateur")
47
Stemming Italiano (ETH) 220 regras (plural singular, género, tempos e formas verbais) Regra StemmingExemplo (*c)e ia (*l)cissim[aeio] ce (*e)sse re province provincia dolcissima dolce volesse volere
![Stemming Italiano (ETH) 220 regras (plural singular, género, tempos e formas verbais) Regra StemmingExemplo (*c)e ia (*l)cissim[aeio] ce (*e)sse re province provincia dolcissima dolce volesse volere](http://images.slideplayer.com.br/9/2515190/slides/slide_47.jpg "Stemming Italiano (ETH) 220 regras (plural singular, género, tempos e formas verbais) Regra StemmingExemplo (*c)e ia (*l)cissim[aeio] ce (*e)sse re province provincia dolcissima dolce volesse volere")
48
Análise Morfológica Analisador Inxight LinguistX produz lemas em vez de stems (ao contrário do algoritmo de Porter) Morfologia: flexionar (concordância sem diferença semântica) versus Derivar (pode haver modificação semântica) As decisões para análise morfológica ou stemming é dependente da língua
 Morfologia: flexionar (concordância sem diferença semântica) versus Derivar (pode haver modificação semântica) As decisões para análise morfológica ou stemming é dependente da língua")
49
Part-of-Speech Tagging (Etiquetagem da Fala) Atribuir etiquetas POS de um conjunto normalizado – comprimisso entre # de etiquetas e complexidade Inglês – conjunto de etiquetas típica 50 Francês – conjunto grande 264 pequeno 56 – AFSadjectivo feminino singular – NFSnome feminino singular – V1SPIverbo 1ª pessoa singular presente indicativo Reduzir o conjunto por truncagem da direita para a esquerda
 Atribuir etiquetas POS de um conjunto normalizado – comprimisso entre # de etiquetas e complexidade Inglês – conjunto de etiquetas típica 50 Francês – conjunto grande 264 pequeno 56 – AFSadjectivo feminino singular – NFSnome feminino singular – V1SPIverbo 1ª pessoa singular presente indicativo Reduzir o conjunto por truncagem da direita para a esquerda")
50
Etiquetagem da Fala Estatísticas - Church 1988 Baseadas em Regras – Manuais (Voutilainen 1993) – Aprendizagem (Brill 1992) Combinações - Bell Labs, Xerox- Grenoble Para acesso a informação multilingue, etiquetagem robusta reduz ambiguidade
 – Aprendizagem (Brill 1992) Combinações - Bell Labs, Xerox- Grenoble Para acesso a informação multilingue, etiquetagem robusta reduz ambiguidade")
51
Identificação de Frases Frases não decomponíveis – o significado não é apenas a soma dos significados das componentes) – “Fast food” “comida rápida” Eficácia da busca é aumentada com uma identificação efectiva das frases O recurso de tradução deve incluir traduções correctas para frases não decomponíveis
 – Fast food comida rápida Eficácia da busca é aumentada com uma identificação efectiva das frases O recurso de tradução deve incluir traduções correctas para frases não decomponíveis")
52
Identificação de frases Métodos estatísticos – Eliminar stopwords – Aglomerar por contexto e frequência – Pares de palavras que co-ocorrem >25 vezes Métodos simbólicos – Etiquetar texto como POS – Utilização de regras para identificação

53
Reconhecimento de Nomes de Entidades Um caso particular de reconhecimento de frases Os termos para nomeação de entidades são bastante produtivos Técnicas de processamento precisas não podem depender dum dicionário de termos estável Reconhecimento baseado em regras gramaticais e interpretação

54
Classificação de Nomes de Entidade

55
3. Busca de Texto Multilingue Abordagens Dificuldades Recursos

56
O problema Como podem conceitos representados na interrogação numa dada língua ser unificados com a informação contida em documentos noutras línguas?

57
O problema Interrogação Documento Barreira da língua Representação da interrogação Representação do documento

58
CLIR - Abordagens Tradução Automática Thesauri multilingue Dicionário bilingue Corpora Paralelos/Comparáveis Conceptual Interlingua

59
Tradução automática Traduzir todos documentos para cada um das possíveis línguas de interrogação Não viável para colecções grandes Não viável para muitas línguas de interrogação É uma abordagem muito redundante e dispendiosa para o BIM(CLIR)
")
60
Tradução automática Traduzir a interrogação para a língua do conteúdo que se procura Nao há contexto para uma tradução precisa O sistema selecciona o termo preferido A tradução de interrogações é inadequada para o CLIR

61
Utilização de Thesauri Busca com vocabulário controlado Definição dum conjunto de conceitos para indexação e busca representados por conjuntos de termos em cada língua Eliminação de ambiguidade Alguns resultados garantidos

62
Utilização de Thesauri Problemas Os thesauri são difíceis de construir e manter Atribuir manualmente termos a documentos é dispendioso Estabelecer correspondência entre thesauri em línguas diferentes é complicado! Os utilizadores têm dificuldade em utilizar dicionários na busca de informação

63
Utilização de Dicionários Dicionários em computador bilingues (feitos à medida ou comerciais) Busca dos termos da interrogação e substituir pela sua tradução na língua dos documentos – Tradução automática da interrogação tem 50% da precisão da busca monolingue – Expansão automática da interrogação reduzem a ambiguidade e aumentam a cobertura
 Busca dos termos da interrogação e substituir pela sua tradução na língua dos documentos – Tradução automática da interrogação tem 50% da precisão da busca monolingue – Expansão automática da interrogação reduzem a ambiguidade e aumentam a cobertura")
64
Utilização de Dicionários Problemas Ambiguidade Muitos termos nao constam do dicionário Falta de termos com várias palavras Identificação de frases É necessário um dicionário bilingue para cada par de língua interrogação/documento

65
Utilização Corpora Disponibilizar equivalências léxicas em várias línguas Corpora Paralelo – Equivalência transacional – Exemplo: Corpus ONU em francês, inglês e alemão. Corpora Comparável – Similar para tópico,tempo, etc... – Exemplo: Notícias da Lusa em inglês e português

66
Utilização Corpora Tradução de interrogações usando Corpora Paralelo – Alinhar textos usando informação estatística ou dicionários bilingue – Encontrar correspondências entre palavras na língua fonte e na língua objecto – Extrair informação para traduzir a interrogação para busca na língua objecto

67
Utilização Corpora Tradução de interrogações usando corpora paralelo – Alinha documentos relacionados através de datas, palavras chave, nomes próprios – Constrói um léxico de co-ocorrências – Termos em línguas diferentes relacionados com o mesmo tópico co-ocorrem no mesmo documento – Usa a correspondência para pseudo-traduzir interrogações

68
Abordagens baseadas em Copora Modelo do Espaço Vectorial Generalizado (GVSM) – Usa um corpus bilingue de treino para construir matrizes de documentos & termos ponderados em cada língua – Usa um copora paralelo para cada par de línguas Latent Semantic Indexing – reduz ainda mais o GVSM – requer corpura comparável ou paralelo – dispendioso computacionalmente
 – Usa um corpus bilingue de treino para construir matrizes de documentos & termos ponderados em cada língua – Usa um copora paralelo para cada par de línguas Latent Semantic Indexing – reduz ainda mais o GVSM – requer corpura comparável ou paralelo – dispendioso computacionalmente")
69
Abordagens baseadas em Copora Thesauri de similaridade – Extrai termos equivalentes dum copora multilingue alinhado – Regista equivalências num thesauri externo – Qualidade dependente da qualidade do corpora

70
Documentos em alemão Documentos em francês Construção do Thesaurus Multilingue de Similaridade Alinhar documentos comparáveis Documentos bilingues Francês /Alemão Nordirland irland irlandais ulster protestant Thesaurus de Similaridade

71
Utilização de Corpora Problemas – corpora apropriado é difícil de obter – O corpora de treino tem que ser bastante grande – O corpora tende a ser dependente do domínio e da aplicação

72
Conceptual Interlingua Termos e frases de várias línguas que referenciam o mesmo conceito são colocados em correspondência num esquema independente da língua Permite a unificação de termos equivalentes e sinónimos em todas as línguas

73
Conceptual Interlingua Espaço de conceitos Vocabulário 1 Francês Vocabulário 2 Espanhol Vocabulário 3 Português Conceitos genéricos da língua

74
Vantagens BIM para qualquer combinação de línguas – não apenas bidireccional (Exemplo Português-Japonês) Busca independente da língua baseado em conceitos da linguagem natural Povoar com terminologia um ambiente de conceitos Ambiente bem compreendido para eliminar a ambiguidade do sentido das palavras
 Busca independente da língua baseado em conceitos da linguagem natural Povoar com terminologia um ambiente de conceitos Ambiente bem compreendido para eliminar a ambiguidade do sentido das palavras")
75
Desvantagens Dispendiosos de construir Problemas de cobertura do vocabulário Conceitos dependentes da linguagem

76
Mestrado em Sistemas de Informação Estado da Arte Tradução automática 80% eficácia monolingue em domínio genérico Técnicas baseadas em dicionário 80% eficácia monolingue em domínio genérico Técnicas baseadas em Corpus Comparável e Paralelo 80% eficácia monolingue em domínio genérico 90% monolingue em domínio específico

77
Principais dificuldades da BIM (I) Tradução – ambiguidade – Tradução errada – Identificaçção de frases
 Tradução – ambiguidade – Tradução errada – Identificaçção de frases")
78
Reduzir Ambiguidade Pré-processamento sintático Análise estatística – Co-ocorrência de termos Termos relacionados tendem a o ocorrer em conjunto Desambiguar as traduções usando as estatísticas de co-ocorrência Realimentação do utilizador Pseudo-Realimentação de relevância

79
Pseudo-Realimentação de Relevância Colocar a interrogação na língua fonte Num corpus paralelo ou comparável, fazer a busca para encontrar documentos na língua Usar os documentos equivalentes aos devolvidos para derivar a interrogação na língua objecto Usar a interrogação para obter documentos na língua objecto

80
q q’ Língua A Língua B Pseudo Realimentação de Relevância

81
Principais Dificuldades na BIM (II) Recursos Sistemas de Acesso a Informação Multilingue necessitam de recursos bem concebidos e – Ferramentas de Processamento da Língua – Recursos da Língua Os recursos são bastante caros de adquirir manter actualizar
 Recursos Sistemas de Acesso a Informação Multilingue necessitam de recursos bem concebidos e – Ferramentas de Processamento da Língua – Recursos da Língua Os recursos são bastante caros de adquirir manter actualizar")
82
Recursos – Principais problemas disponibilidade extensibilitdade custo cobertura qualidade normas

83
Ferramentas de Processamento da Língua Ferramentas de identificação da língua Conversão de conjuntos de caracteres Extracção e segmentação de palavras Ferramentas de radicalização/análise morfológica Ver ACL Natural language Software Registry http://registry/dfki/de/

84
Recursos de língua Dicionários Corpora Léxicos e terminologia Thesauri e ontologias Ver ELRA - European Language Resources Association - http://www.icp.grenet.f/ELRA/ Ver LDC - Linguistic Data Consortium http://www.ldc.upenn.edu

85
4. Busca de Fala Multilingue Pouco trabalho realizado Estado bastante experimental

86
Processamento da Fala Multilingue Reconhecedores de voz são normalmente treinados muitas horas usando um corpus de voz etiquetado – Reconhecimento de voz visto como uma caixa preta com saídas fonémica ou léxica – Saída usada como entrada na indexação- o objectivo é indexar o melhor possível documentos falados – Investigação actual principalmente em inglês, com algum trabalho em chinês, japonês e algumas línguas europeias (alemão, francês, italiano, holandês)
")
87
Busca da Fala Multilingue Uma experiência no ETH-Zurich Buscar documentos falados em alemão a partir de interrogações escritas em francês (ETH) Construir uma thesaurus de similaridade Francês- Alemão usando um corpus de notícias da Agência Suíça de Notícias Indexar notícias de rádio em alemão como trigramas de fonemas a partir duma saída de reconhecimento da Fala
 Construir uma thesaurus de similaridade Francês- Alemão usando um corpus de notícias da Agência Suíça de Notícias Indexar notícias de rádio em alemão como trigramas de fonemas a partir duma saída de reconhecimento da Fala")
88
Busca de Fala Multilingue Aceita uma interrogação escrita em francês pelo utilizador Utiliza um thesaurus de similaridade para pseudo- traduzir a interrogação para alemão Usa um dicionário de fonemas para converter o texto na fala correspondente Unifica a interrogação falada com uma coleção de notícias faladas em alemão Devolve os documentos falados Desempenho ~50% do monolingue

89
Direcções Actuais Workshop Johns Hopkins Busca da Fala em várias línguas, verão 2000 Programa DARPA Automatic Content Extraction deve envolver fala em várias línguas Grupo de Trabalho EU-NSF Working Group para estudar o arquivo e busca de documentos falados Grupo de Trabalho DELOS WG para avaliar sistemas de documentos falados em várias línguas

90
Avaliação de Sistemas BIM Porque é importante a avaliação de sistemas O que é que a avaliação implica Programas da avaliação Um Exemplo

91
Porque necessitamos da avaliação? A avaliação implica a compreensão de requisitos e objectivos A avaliação permite que as hipóteses sejam validades e progressos confirmados A avaliação permite a análise de diferentes abordagens e tecnologias

92
A avaliação de sistemas é complexa! Os sistemas BIM consistem na integração de componentes e tecnologias Precisa de se avaliar componentes singulares Precisa de se avaliar o desempenho global do sistema

93
A avaliação de sistemas é complexa! Necessidade de distinguir aspectos metodológicas de aspectos de conhecimento da língua Idealmente, um protocolo de avaliação requer a distinção entre a arquitectura, programa e dados linguísticos

94
Avaliação da Tecnologia e da Usabilidade Avaliação da utilidade: Mostrar o valor da tecnologia para o utilizador Determinar os níveis de tecnologia indispensáveis para uma utilização específica Disponibilizar direcções para escolha de critérios para avaliação da tecnologia Influência da língua e cultura na usabilidade das tecnologias precisa de ser compreendido

95
Organização duma actividade de avaliação Selecionar as tarefas de controlo Disponibilizar dados para testar a afinar os sistemas Definir protocolo e métricas a usar na validação dos resultados O objectivo é uma comparação objectiva entre sistemas e abordagens

96
Principais projectos de avaliação em BIM TIDES: patrocinadores TREC (Text REtrieval Conferences) e TDT (Topic Detection and Tracking) – linha Chinês-Inglês em 2000; TREC focará em Inglês/Frnacês - Árabe in 2001 NTCIR: Nat.Inst. for Informatics, Tokyo. Chinês- Inglês ; Japonês-Inglês C-L tracks AMARYLLIS: focagem em Francês; 2da campanha 98-99 inclui linha BIM ; 3ªa campanha início Set 2001. CLEF: Cross Language Evaluation Forum – Avaliação BIM para línguas europeias

97
Cross-Language Evaluation Forum (CLEF) Fundada pela DELOS Network of Excellence for Digital Libraries e US National Institute for Standards and Technology (NIST) Extensão da linha BIM no TREC (1997- 1999) Coordenação distribuída – sites nacionais para cada língua na colecção multilingue
 Fundada pela DELOS Network of Excellence for Digital Libraries e US National Institute for Standards and Technology (NIST) Extensão da linha BIM no TREC ( ) Coordenação distribuída – sites nacionais para cada língua na colecção multilingue")
98
CLEF – Principais objectivos Promove a investigação, disponibilizando uma infra-estrutura para: Avaliação, teste e afinação de sistemas BIM Comparação e discussão de resultados Construção de plataformas de teste para desenvolvimento de sistemas

99
CLEF 2001 – Descrição da Tarefa 4 linhas principais de avaliação no CLEF 2001: Busca de informação multilingue Busca de informação bilingue Busca de informação monolingue(sem ser Inglês) Busca de informação em domínios específicos Linha experimental para sistemas multilingue interactivos
 Busca de informação em domínios específicos Linha experimental para sistemas multilingue interactivos")
100
CLEF 2001 – Colecção de Dados Corpus Multilingue comparável com documentos de jornais e agências de notícias para 6 línguas (DE,EN,FR,IT,NL,SP). Acima de um milhão de documentos Conjunto de 50 tópicos comuns (dos quais são extraídas as interrogações) criados em 9 línguas europeias (DE,EN,FR,IT,NL,SP+FI,RU,SV) e 3 línguas asiáticas (JP,TH,ZH)
 criados em 9 línguas europeias (DE,EN,FR,IT,NL,SP+FI,RU,SV) e 3 línguas asiáticas (JP,TH,ZH).")
101
Tópicos em DE,EN,FR,IT FI,NL,SP,SV, RU,ZH,JP,TH Inglês AlemãoFrancêsItaliano Sistema de BIM dos participantes Documentos em CLEF 2001 – Busca de Informação Multilingue Uma lista de documentos em DE, EN, FR,IT e SP ordenados por ordem decrescente de relevância estimada Espanhol

102
CLEF 2001 – Busca de Informação Bilingue Tarefa:interrogar colecções em Inglês ou Alemão Objectivo: encontrar documentos na língua objecto, apresentando os resultados por ordem de relevância Tarefa simples para principiantes !

103
CLEF 2001 – Busca de Informação Monolingue Tarefa: interrogar colecções de documentos em FR|DE|IT|NL|SP Objectivo: compreender melhor os problemas da busca de informação dependentes da língua Línguas diferentes apresentam problemas diferentes Aspectos envolvidos incluem a ordem das palavras, morfologia, caracteres diacríticos, variantes da língua

104
CLEF 2001 - Domain-Specific IR Tarefa: interrogar uma base de dados estruturada dum domínio vertical (ciências sociais) em alemão Thesaurus Alemão/Inglês /Russo e tradução para inglês dos títulos dos documentos Tarefa monolingue ou multilingue Objectivo: compreender as implicações de interrogar em domínios específicos
 em alemão Thesaurus Alemão/Inglês /Russo e tradução para inglês dos títulos dos documentos Tarefa monolingue ou multilingue Objectivo: compreender as implicações de interrogar em domínios específicos")
105
CLEF 2001 – BIM Interactivo Tarefa: selecção interactiva de documento numa língua “desconhecida” Objectivo: avaliação da apresentação dos resultados em vez do desempenho do sistema

106
CLEF2000 - Abordagens Sistemas de Tradução Comercial (Systran, Lernout e Hauspie Power Translator) Consulta de dicionários bilingue Corpora paralelo alinhado (derivado do Web) Thesaurus de similaridade(usando corpora comparável) Experimentadas diferentes abordagens para expansão de interrogações e fusão de resultados
 Consulta de dicionários bilingue Corpora paralelo alinhado (derivado do Web) Thesaurus de similaridade(usando corpora comparável) Experimentadas diferentes abordagens para expansão de interrogações e fusão de resultados")
107
CLEF2000 – Técnicas Testadas Testes de avaliação parcial Dicionário de termos derivado de copora paralelo versus tradução automática Utilização de métodos de PLN, isto é identificação de frases, processamento de formas compostas e análise morfológica e sintática Técnicas de radicalização independentes da língua Desambiguar termos de interrogação interactiva Triangulação léxica (Ballestreros)
")
108
Síntese da Avaliação Não é uma competição para descobrir o melhor Cria a oportunidade para testar, afinar e comparar abordagens no sentido de aumentar o desempenho dos sistemas Uma campanha de avaliação cria uma comunidade interessada em avaliar os mesmos aspectos e comparar ideias e experiências.

109
6. Aplicações Sistemas que foram construídos para experiências em IR (TREC, CLEF, NTCIR) – Suportam indexação de documentos em larga escala – Suportam processamento em batch de interrogações longas Sistemas que foram construídos para uso comercial – Disponibilizam resposta rápida às interrogações do utilizador – Suportam actualização dinâmica do conteúdo
 – Suportam indexação de documentos em larga escala – Suportam processamento em batch de interrogações longas Sistemas que foram construídos para uso comercial – Disponibilizam resposta rápida às interrogações do utilizador – Suportam actualização dinâmica do conteúdo.")
115
CINDOR Aceita a interrogação em linguagem natural na língua nativa do utilizador Faz as correspondências da interrogação usando o Conceptual Interlingua Disponibiliza uma lista de documentos ordenados por ranking, agrupados por língua Traduz opcionalmente os documentos em língua estrangeira para a língua nativa do utilizador

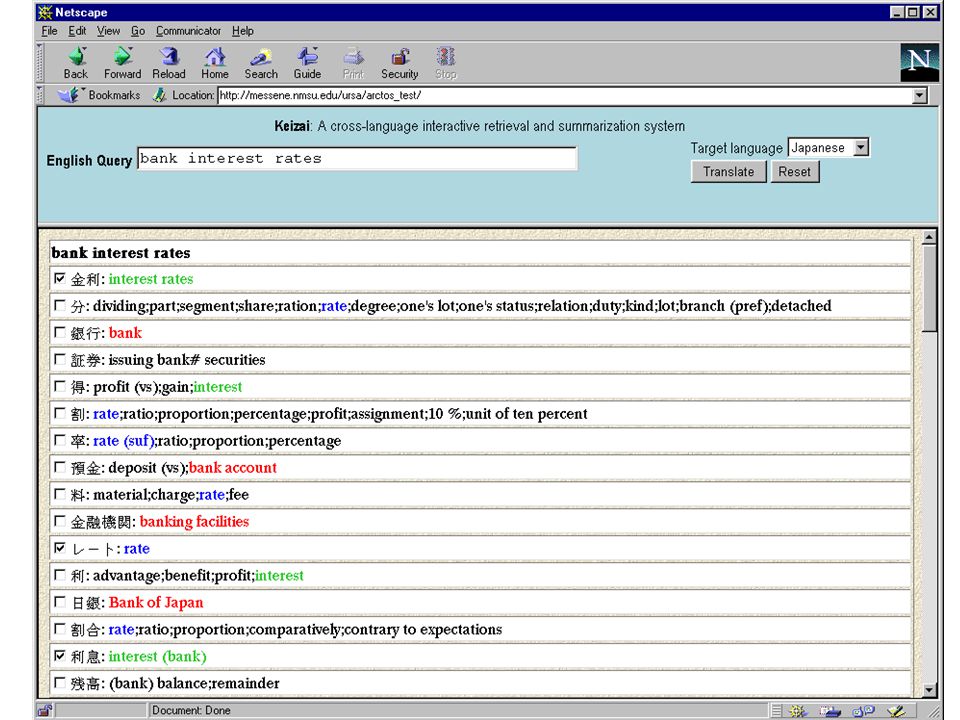
116
I would like information about the possible employment of NATO ground troops in the Kosovo conflict. possible (E) conceivable (E) possible (F) concevable (F) imaginable (F) factible (S) concebible (S) posibilidad (S) ground troups (E) ground forces (E) armées de terre (F) troupes (F) fuerzas terrestres (S) tropas terrestres (S) soldados (S) tropas (S) ejército (S) Kosovo (E) Kosovo (F) Kosovo (S) conflict (E) discord (E) conflit (F) désaccord (F) dissension (F) conflicto (S) discordia (S) enfrentamiento (S) crisis (S) employment (E) engagement (E) commissioning (E) engagement (F) envoyé (F) empleo (S) uso (S) envío (S) NATO (E) North Atlantic Treaty Organization (E) OTAN (F) Organisation du Traité de l’Atlantique Nord (F) OTAN (S) Organizacion del Tratado del Atlantico Norte (S) English Document Excerpt: WASHINGTON, March 29 (AFP) - The United States and Britain beefed up NATO forces as the bombing campaign against Yugoslavia entered a 24-hour phase and US officials warned ground troups in Kosovo were “no magic bullet.” French Document Excerpt: PARIS, 30 mars (AFP) - 25 MARS: Le président américain Bill Clinton déclare ne pas avoir l’intention “d’ envoyer de troupes.” Spanish document Excerpt: BRUSELAS, Mar 28 (AFP) - De enviarse tropas terrestres, posibilidad que decartan actualmente todos los países de la organización, las pérdidas serían considerables, según los estrategas de la OTAN. Interrogação em Inglês Conceptual Interlingua Documents Multilingue
 conceivable (E) possible (F) concevable (F) imaginable (F) factible (S) concebible (S) posibilidad (S) ground troups (E) ground forces (E) armées de terre (F) troupes (F) fuerzas terrestres (S) tropas terrestres (S) soldados (S) tropas (S) ejército (S) Kosovo (E) Kosovo (F) Kosovo (S) conflict (E) discord (E) conflit (F) désaccord (F) dissension (F) conflicto (S) discordia (S) enfrentamiento (S) crisis (S) employment (E) engagement (E) commissioning (E) engagement (F) envoyé (F) empleo (S) uso (S) envío (S) NATO (E) North Atlantic Treaty Organization (E) OTAN (F) Organisation du Traité de l’Atlantique Nord (F) OTAN (S) Organizacion del Tratado del Atlantico Norte (S) English Document Excerpt: WASHINGTON, March 29 (AFP) - The United States and Britain beefed up NATO forces as the bombing campaign against Yugoslavia entered a 24-hour phase and US officials warned ground troups in Kosovo were no magic bullet. French Document Excerpt: PARIS, 30 mars (AFP) - 25 MARS: Le président américain Bill Clinton déclare ne pas avoir l’intention d’ envoyer de troupes. Spanish document Excerpt: BRUSELAS, Mar 28 (AFP) - De enviarse tropas terrestres, posibilidad que decartan actualmente todos los países de la organización, las pérdidas serían considerables, según los estrategas de la OTAN. Interrogação em Inglês Conceptual Interlingua Documents Multilingue.")
117
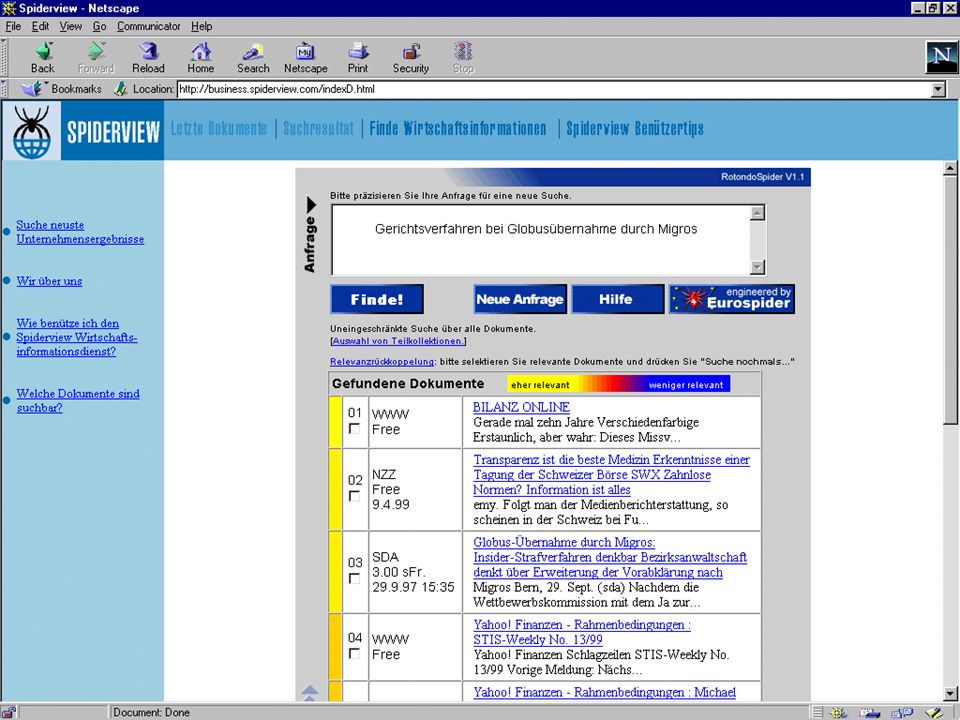
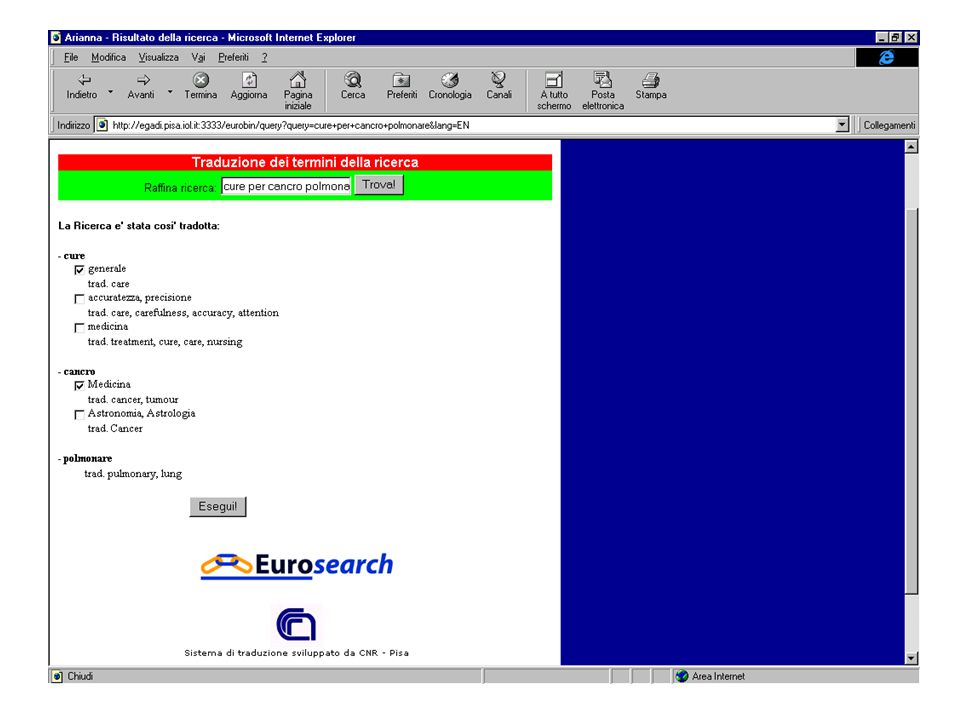
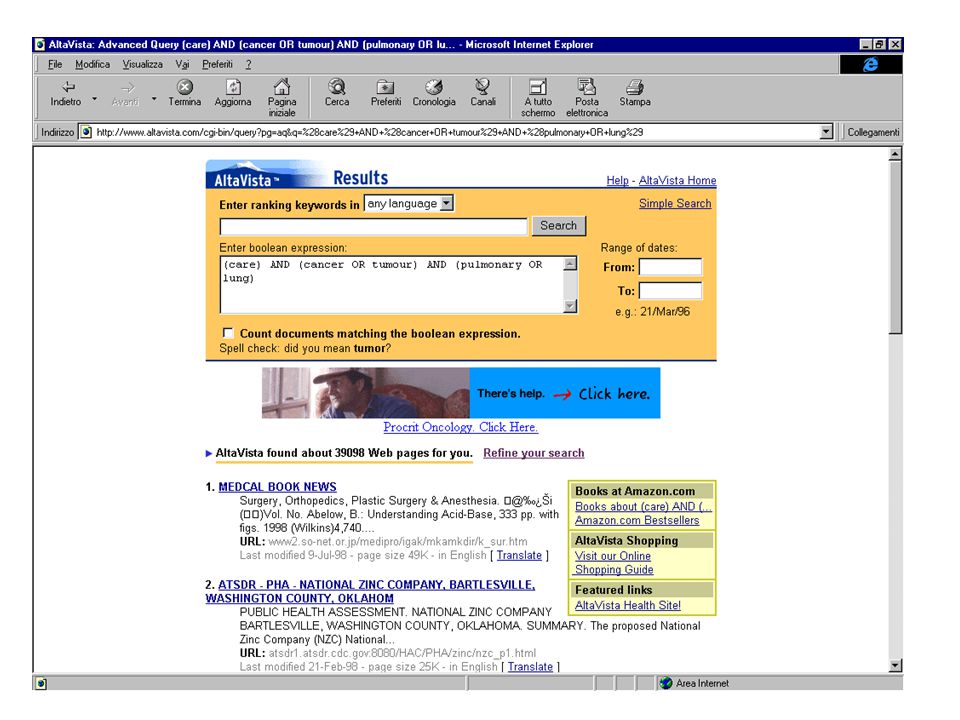
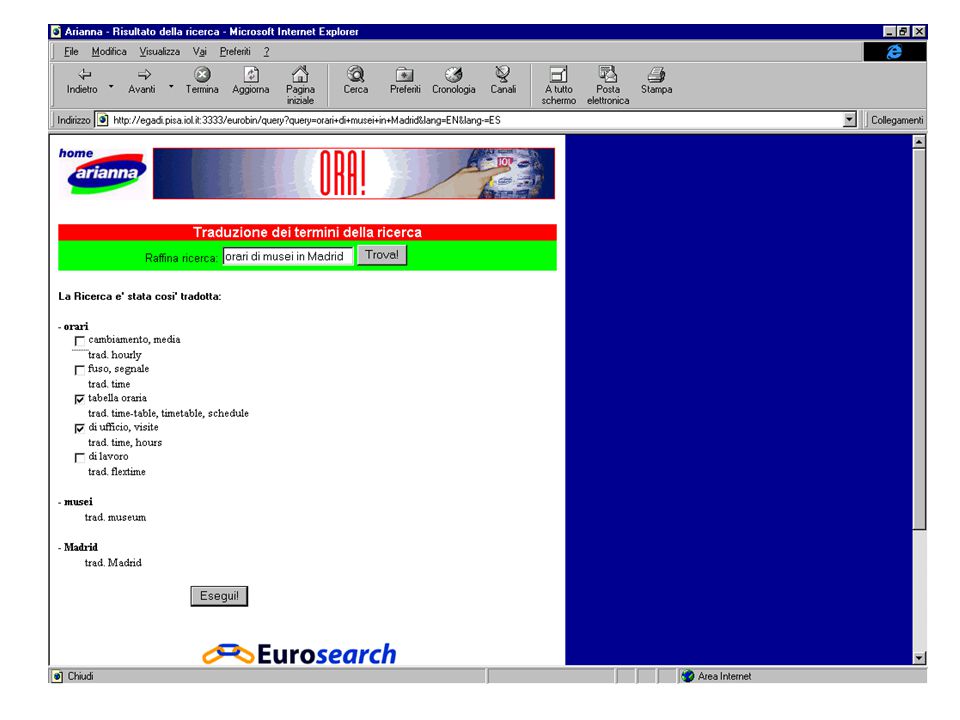
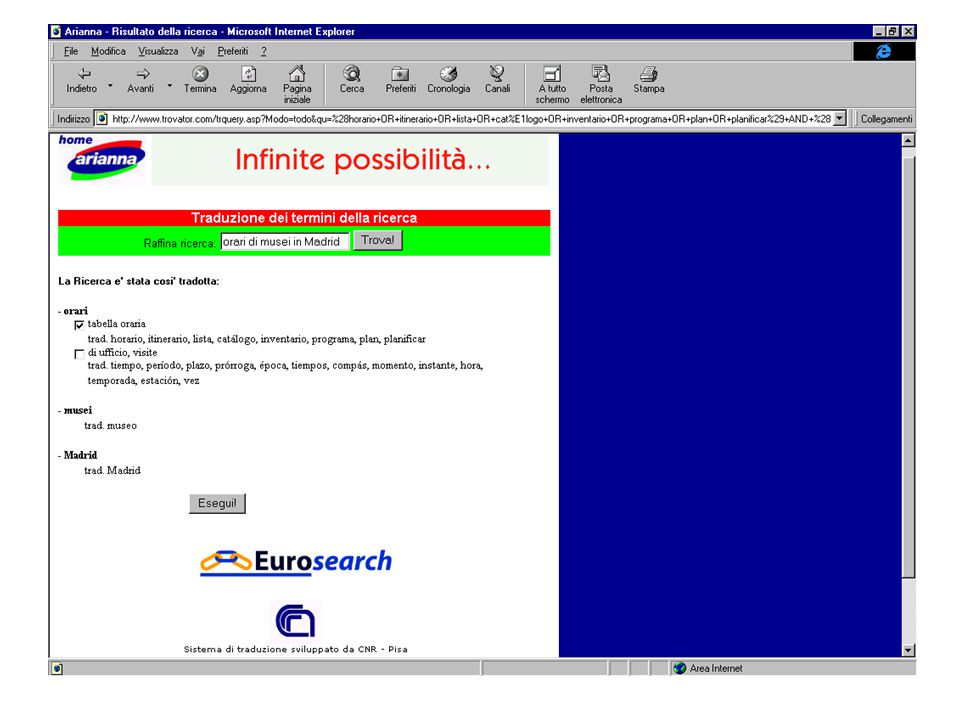
Demo… Introdução da Interrogação

118
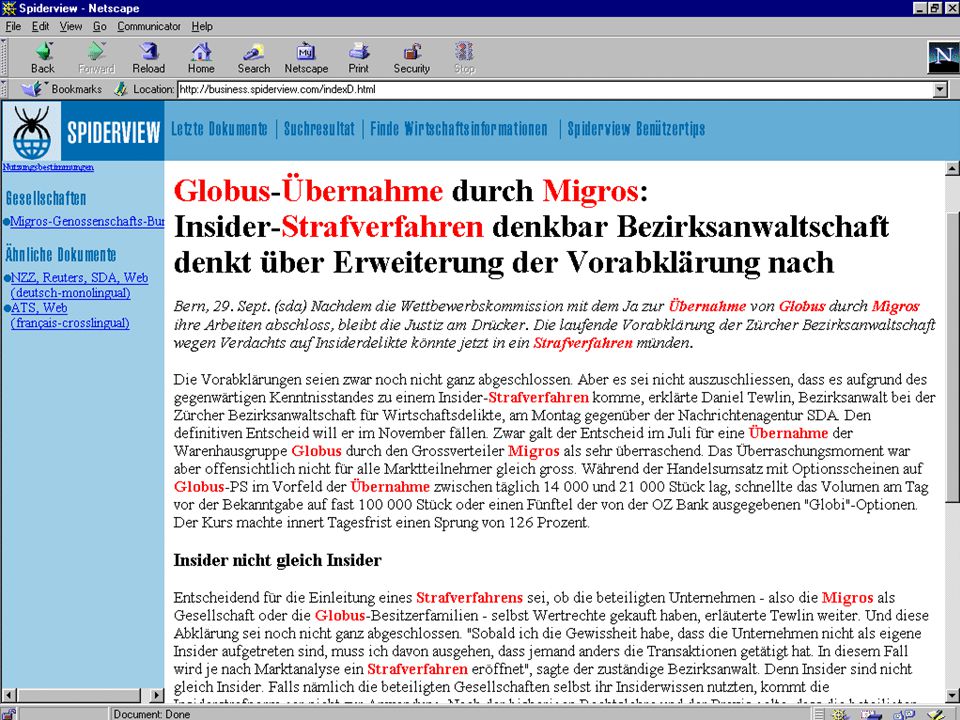
Demo… Ver resultados

119
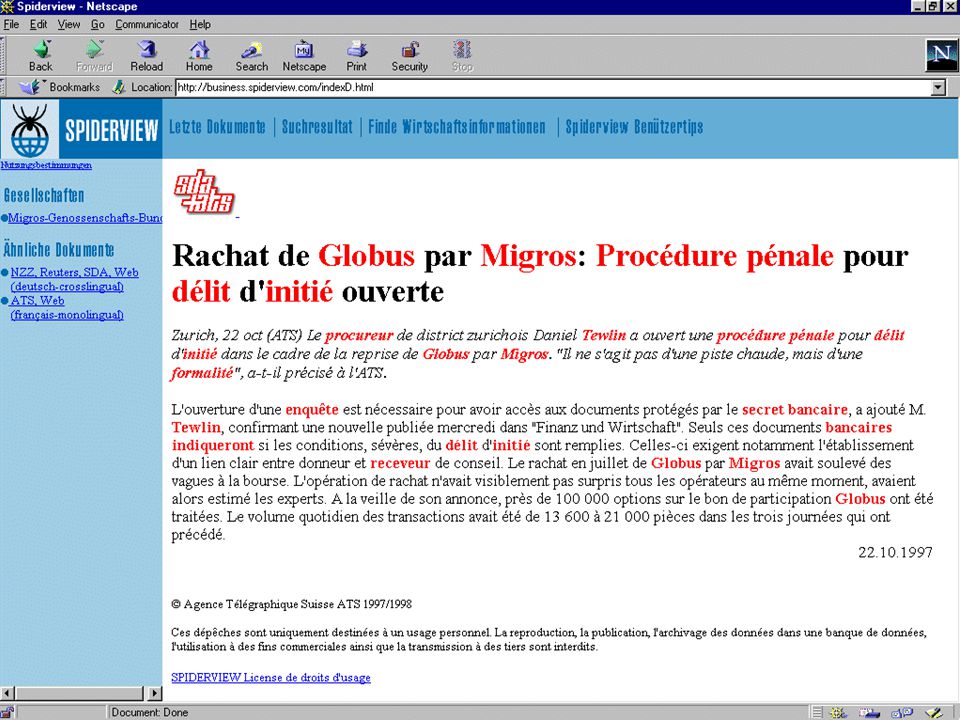
Demo… Traduzir para inglês

120
Demo… Ver documento

126
Aplicações em Biliotecas Digitais (DL) Não muitas a reportar Maior focagem no processamento de texto multilingue em vez de funcionalidades multilingue.
 Não muitas a reportar Maior focagem no processamento de texto multilingue em vez de funcionalidades multilingue.")
127
Projectos de DL em Pisa ETRDL SCHOLNET ECHO

128
ETRDL Interfaces Multilingue (6 languages) – Escolha da língua da interface – Seleccionar a língua da colecção de documentos processamento de texto multilingue
 – Escolha da língua da interface – Seleccionar a língua da colecção de documentos processamento de texto multilingue")
129
Acesso a Informação Multilingue

130
SCHOLNET ETRDL mais a funcionalidade BIM Thesaurus multilingue – Mecanismos para manutenção e actualização do thesaurus Busca em texto livre (abstracts) via pseudo- realimentação de relevância
 via pseudo- realimentação de relevância")
131
ECHO Arquivos de filmes em 4 línguas – Busca Multilingue através dum vocabulário controlado – Experiências numa abordagem baseada em corpus para reconhecimento de voz

132
9. Alguns URLs úteis W3C - WINTER - http://www.w3.org/International/ Cross-Language Information Retrieval - http://www.clis.umd.edu/dlrg/clir/ Cross-Language Evaluation Forum - http://www.iei.pi.cnr.it/DELOS/CLEF Multilingual Metadata - http://purl.org/DC/groups/languages.htm EC - Multilingual Information Society - http://www2.echo.lu/mlis/ DARPA - Translingual Information Detection, Extraction and Summarization - http://www.darpa.mil/ito/research/tides/

133
Mestrado em Sistemas de Informação Créditos Esta apresentação é baseada numa realizada pela Carol Peters na Escola de Verão em Bibliotecas Digitais em Pisa, Julho de 2001

134
Referências Peters, C., Sheridan, P. (2001). " Multilingual Information Access ". In M. Agosti, F. Crestani, G. Pasi (eds.) "Lectures on Information Retrieval", Lecture Notes in Computer Science 1980, Springer Verlag, pp51-80
 Lectures on Information Retrieval , Lecture Notes in Computer Science 1980, Springer Verlag, pp")
Apresentações semelhantes









.>")





>")




