Carregar apresentação
A apresentação está carregando. Por favor, espere

1
Uma Visão de Análise de Dados Simbólicos Byron Leite Dantas Bezerra Sérgio Ricardo de Melo Queiroz

2
Roteiro Idéia básica Objetos de Primeira e Segunda ordens A Entrada de Análise de Dados Simbólicos Tabela de Dados Simbólicos Origens dos Dados Simbólicos Principais Saídas dos Algoritmos de Análise de Dados Simbólicos Descrições Simbólicas Objetos Simbólicos SODAS Principais passos para a Análise de Dados Simbólicos Exemplos de funções Visão Estrutural e Componentes

3
A Idéia Básica Aristotle Organon (IV B.C.) separou claramente: indivíduos de primeira ordem (como um cavalo ou uma pessoa quaisquer), cada qual correspondendo a um único indivíduo do mundo; de indivíduos de segunda ordem (como o cavalo ou a pessoa, de forma geral), correspondendo a uma classe de indivíduos do mundo.
 separou claramente: indivíduos de primeira ordem (como um cavalo ou uma pessoa quaisquer), cada qual correspondendo a um único indivíduo do mundo; de indivíduos de segunda ordem (como o cavalo ou a pessoa, de forma geral), correspondendo a uma classe de indivíduos do mundo.")
4
Exemplo de Indivíduos de Primeira Ordem

5
Obtendo os Indivíduos de Segunda Ordem

6
Tabela de Dados Simbólicos “Distributions are the numbers of the future.” (Schweitzer, 1984) As células podem conter dados complexos Valores ponderados Valores associados a regras Taxonomias Intervalos Distribuições SDA
 As células podem conter dados complexos Valores ponderados Valores associados a regras Taxonomias Intervalos Distribuições SDA")
7
Exemplo de Tabela de Dados Simbólicos Quantitativo Simples, contínuo, intervalar, multivalorado Categórico Ordinal ou não, Multivalorado, Histograma Taxonomia Dependência hierárquica Dependência lógica Envolvem conhecimento a priori

8
Fontes de Dados Simbólicos A partir de variáveis categóricas Como tipo do empregado Obtido por clusterização De bancos de dados Consultas originando novas variáveis Do conhecimento do especialista De dados confidenciais Para esconder informações privadas. Ex: IBGE De dados estocásticos Distribuição de probabilidade De séries temporais Descrevendo intervalos de tempo

9
Principais Saídas dos Algoritmos SDAs SDA Objeto Simbólico

10
Modelam conceitos ou “entidades físicas” do mundo real Um conceito é definido por uma Intenção = que são as características inerentes do objeto simbólico uma Extensão = que é o conjunto de indivíduos que possuem essas características Exemplo: a(w) = [idade(w) [30, 35] ] [número de filhos(w) 2] Objetos Simbólicos
![Modelam conceitos ou entidades físicas do mundo real Um conceito é definido por uma Intenção = que são as características inerentes do objeto simbólico uma Extensão = que é o conjunto de indivíduos que possuem essas características Exemplo: a(w) = [idade(w) [30, 35] ] [número de filhos(w) 2] Objetos Simbólicos](http://images.slideplayer.com.br/10/2696686/slides/slide_10.jpg "Modelam conceitos ou entidades físicas do mundo real Um conceito é definido por uma Intenção = que são as características inerentes do objeto simbólico uma Extensão = que é o conjunto de indivíduos que possuem essas características Exemplo: a(w) = [idade(w) [30, 35] ] [número de filhos(w) 2] Objetos Simbólicos")
11
S = ( a, R, d C ) Objetos Simbólicos dCdC w y d R É um animal(w) = 99% sim a(w) = [y(w) R d C ]
![S = ( a, R, d C ) Objetos Simbólicos dCdC w y d R É um animal(w) = 99% sim a(w) = [y(w) R d C ]](http://images.slideplayer.com.br/10/2696686/slides/slide_11.jpg "S = ( a, R, d C ) Objetos Simbólicos dCdC w y d R É um animal(w) = 99% sim a(w) = [y(w) R d C ]")
12
Objetos Simbólicos Mundo Real Mundo Modelado Indivíduos - Conceitos Descrições Objetos Simbólicos wdwdw dCdC T estrelas vermelhas S = (a,R,d C ) Ext(S) y R
 Ext(S) y R")
13
Objetos Simbólicos S = ( a, R, d ) R é uma relação. Ex: , , , , , d é uma descrição L L a é um mapeamento de L dependente de R e d, onde é o conjunto de indivíduos e L é {true, false} ou [0,1].

14
Objetos Simbólicos Booleanos L L = {0,1}, ou seja, [y(w) R d] L = {true, false} As variáveis simbólicas podem ser apenas: quantitativa simples, intervalares, categóricas ou multivaloradas. Exemplo a(w) = [y(w) R d] com R definida por [ d’ R d ] = i =1, 2 [ d’ i R i d i ] e R i = y(w) = (cor(w), altura(w)) d = ({R, B, Y}, [10,15] ) Indivíduo u = ({R, Y}, {21}) a(u) = [cor(u) {R, B, Y}] [altura(u) [10,15]] = true false = true.
![Objetos Simbólicos Booleanos L L = {0,1}, ou seja, [y(w) R d] L = {true, false} As variáveis simbólicas podem ser apenas: quantitativa simples, intervalares, categóricas ou multivaloradas.](http://images.slideplayer.com.br/10/2696686/slides/slide_14.jpg "Exemplo a(w) = [y(w) R d] com R definida por [ d’ R d ] = i =1, 2 [ d’ i R i d i ] e R i = y(w) = (cor(w), altura(w)) d = ({R, B, Y}, [10,15] ) Indivíduo u = ({R, Y}, {21}) a(u) = [cor(u) {R, B, Y}] [altura(u) [10,15]] = true false = true..")
15
Objetos Simbólicos Modais L L = [0,1], ou seja, [y(w) R d] L = [0,1] As variáveis simbólicas podem ser complexas Exemplo a(w) = [y(w) R d] onde R é definida por [ d’ R d ] = Max i =1, 2 [ d’ i R i d i ] = i =1, 2 [ d’ i R i d i ] Seja duas distribuições de probabilidade discretas d’ i = r e d i = q de k valores, a comparação entre duas distribuições é definida por r R i q = j=1,k r j q j exp (r j - min (r j, q j )) y(w) = (idade(w), categoria(w)) d = ({(0.2)12, (0.8) [20,28]}, {(0.4) contratante, (0.6) funcionário}) a(u) = [idade(u) R 1 {(0.2)12, (0.8) [20,28]}] * [SPC(u) R2{(0.4) contratante, (0.6) funcionário}]
![Objetos Simbólicos Modais L L = [0,1], ou seja, [y(w) R d] L = [0,1] As variáveis simbólicas podem ser complexas Exemplo a(w) = [y(w) R d] onde R é definida por [ d’ R d ] = Max i =1, 2 [ d’ i R i d i ] = i =1, 2 [ d’ i R i d i ] Seja duas distribuições de probabilidade discretas d’ i = r e d i = q de k valores, a comparação entre duas distribuições é definida por r R i q = j=1,k r j q j exp (r j - min (r j, q j )) y(w) = (idade(w), categoria(w)) d = ({(0.2)12, (0.8) [20,28]}, {(0.4) contratante, (0.6) funcionário}) a(u) = [idade(u) R 1 {(0.2)12, (0.8) [20,28]}] * [SPC(u) R2{(0.4) contratante, (0.6) funcionário}]](http://images.slideplayer.com.br/10/2696686/slides/slide_15.jpg "Objetos Simbólicos Modais L L = [0,1], ou seja, [y(w) R d] L = [0,1] As variáveis simbólicas podem ser complexas Exemplo a(w) = [y(w) R d] onde R é definida por [ d’ R d ] = Max i =1, 2 [ d’ i R i d i ] = i =1, 2 [ d’ i R i d i ] Seja duas distribuições de probabilidade discretas d’ i = r e d i = q de k valores, a comparação entre duas distribuições é definida por r R i q = j=1,k r j q j exp (r j - min (r j, q j )) y(w) = (idade(w), categoria(w)) d = ({(0.2)12, (0.8) [20,28]}, {(0.4) contratante, (0.6) funcionário}) a(u) = [idade(u) R 1 {(0.2)12, (0.8) [20,28]}] * [SPC(u) R2{(0.4) contratante, (0.6) funcionário}]")
16
Extensão de um Objeto Simbólico Caso Booleano EXT(a) = {w / a(w) = true} Caso Modal EXT (S) = {w / a(w) }.
 = {w / a(w) = true} Caso Modal EXT (S) = {w / a(w) }.")
17
SODAS – Symbolic Official Data Analysis System Protótipo disponível gratuitamente http://www.ceremade.dauphine.fr/~touati/sodas-pagegarde.htm Funcionalidades Construção de tabelas de dados simbólicos a partir de BD’s tradicionais Descrição de regras e hierarquias Análise dos através de métodos de análise de dados simbólicos Estatística descritiva Análise Fatorial Agrupamento Árvore de Decisão...

18
Interface do SODAS Barra de menus Métodos de análise disponíveis Aplicação dos métodos

19
Análise de dados com o SODAS 1° Passo: Possuir os dados em um BD relacional Exemplo: Dados sobre os filmes indicados ao Oscar. Nome do filme, ator principal, diretor, ano, local de produção....

20
BD de Filmes: Esquema Relacional

21
Exemplo de indivíduo: Forrest Gump

22
Definição do contexto Indivíduos que deseja-se estudar: Categorias de filmes Cada gênero de filme representa uma categoria: Drama, Ficção científica, Ação, Western,... A descrição de cada classe será obtida através da generalização de seus membros de 1a. Ordem

23
Generalização dos dados Nome do filme. Será desprezado Gênero. Variável que identifica a classe Outras variáveis. Usadas para descrever as classes.

24
Obtendo a tabela de dados simbólicos (1) (2)
 (2)")
25
Importando os dados (1) (2) (3)
 (2) (3)")
26
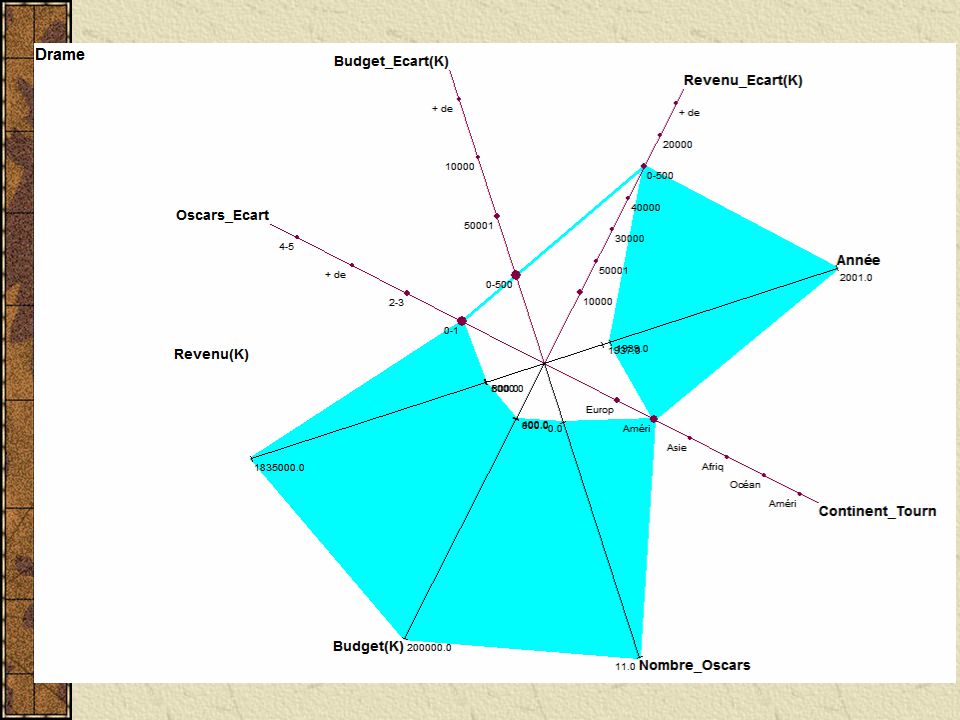
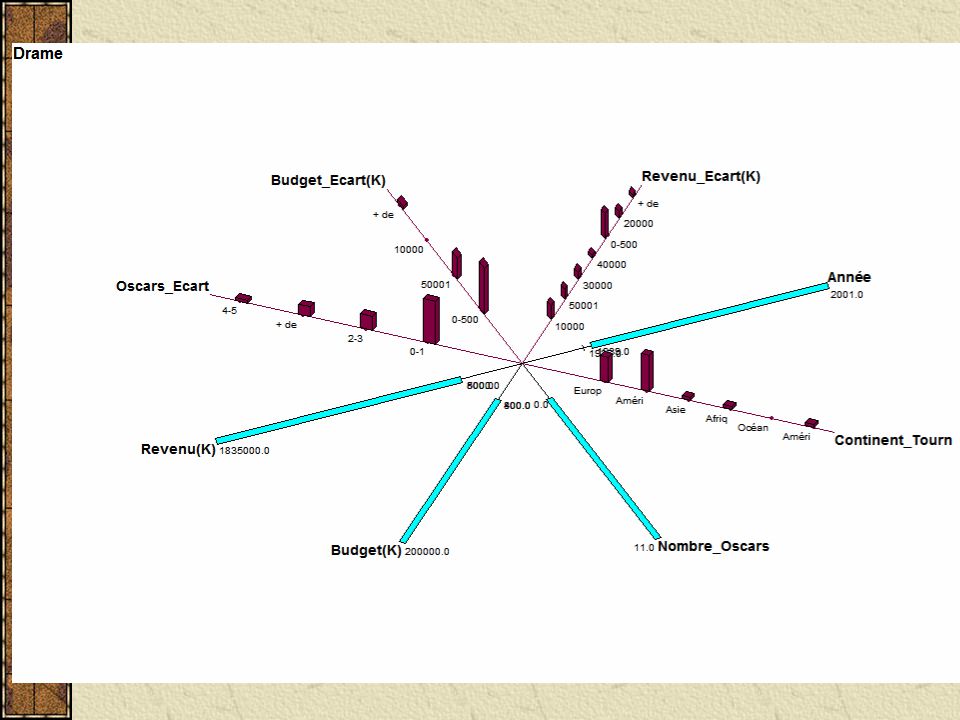
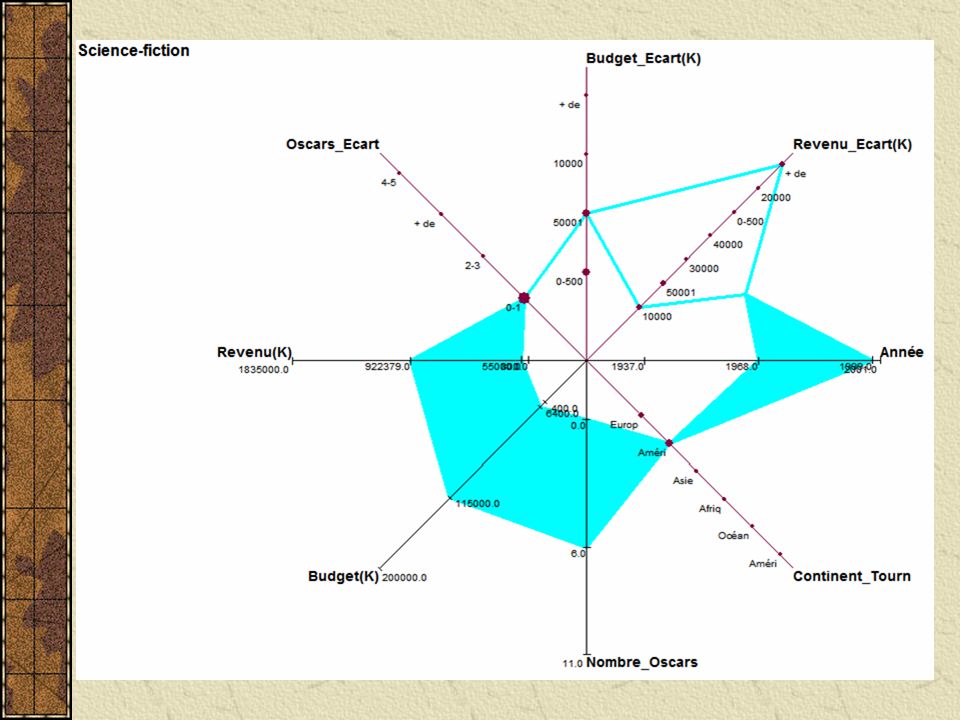
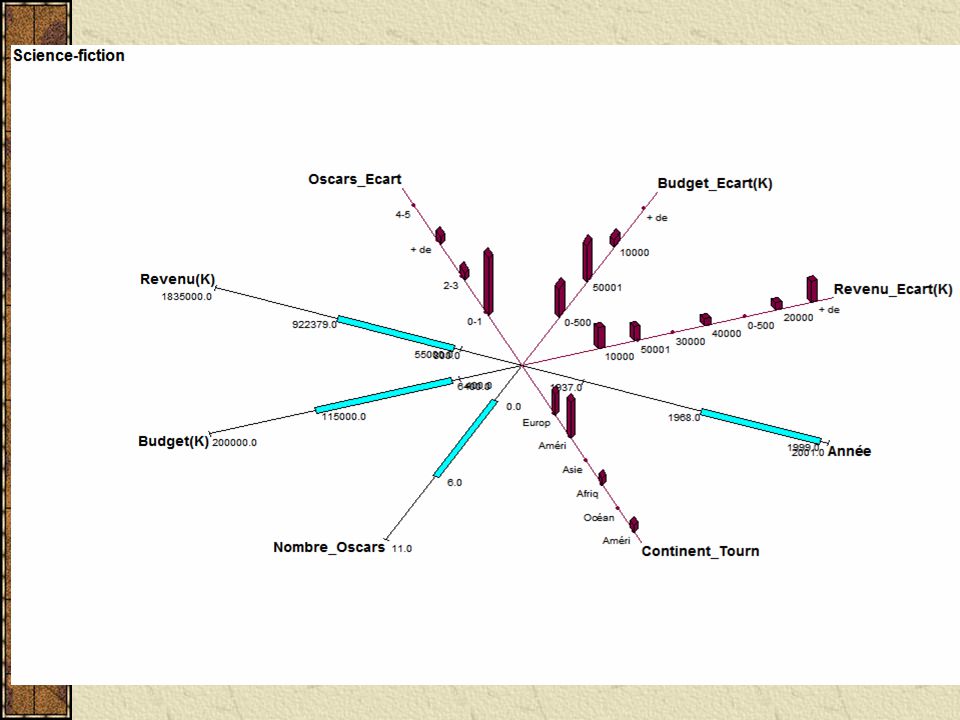
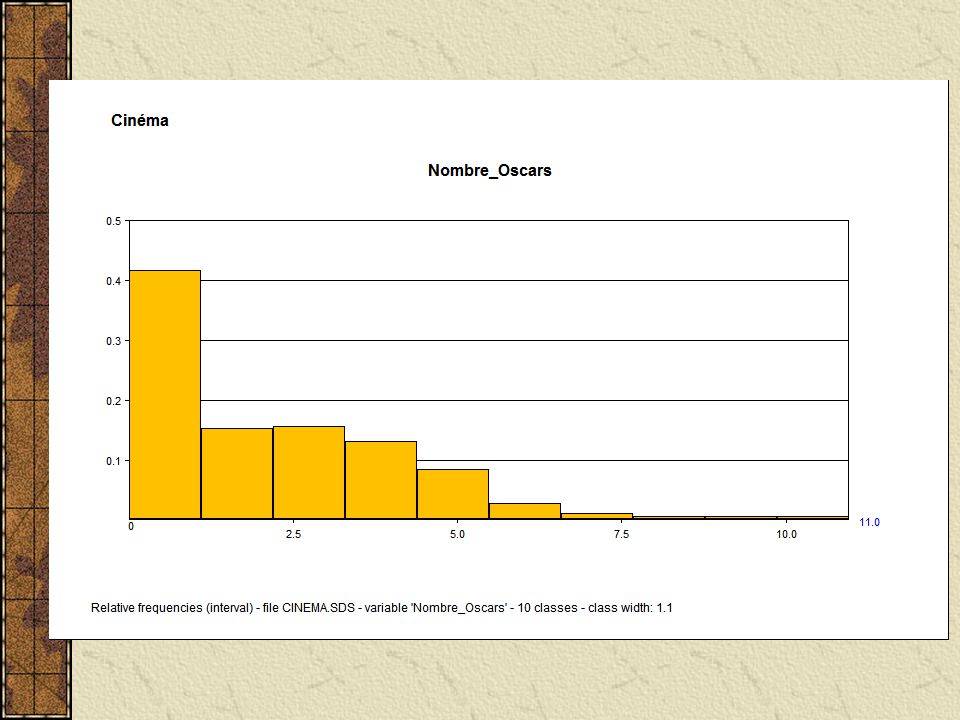
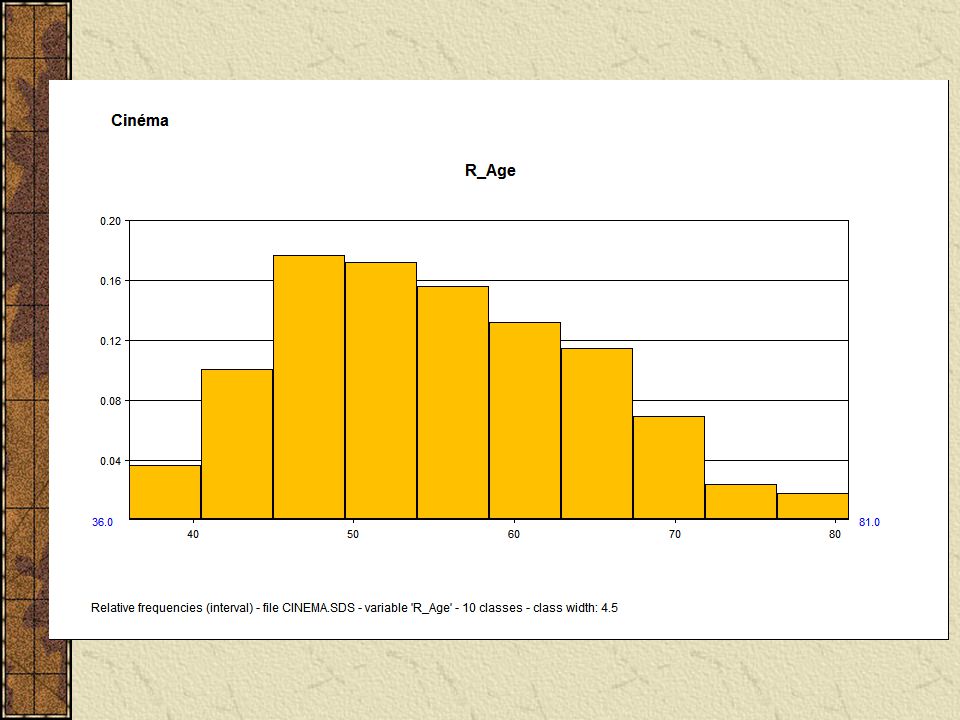
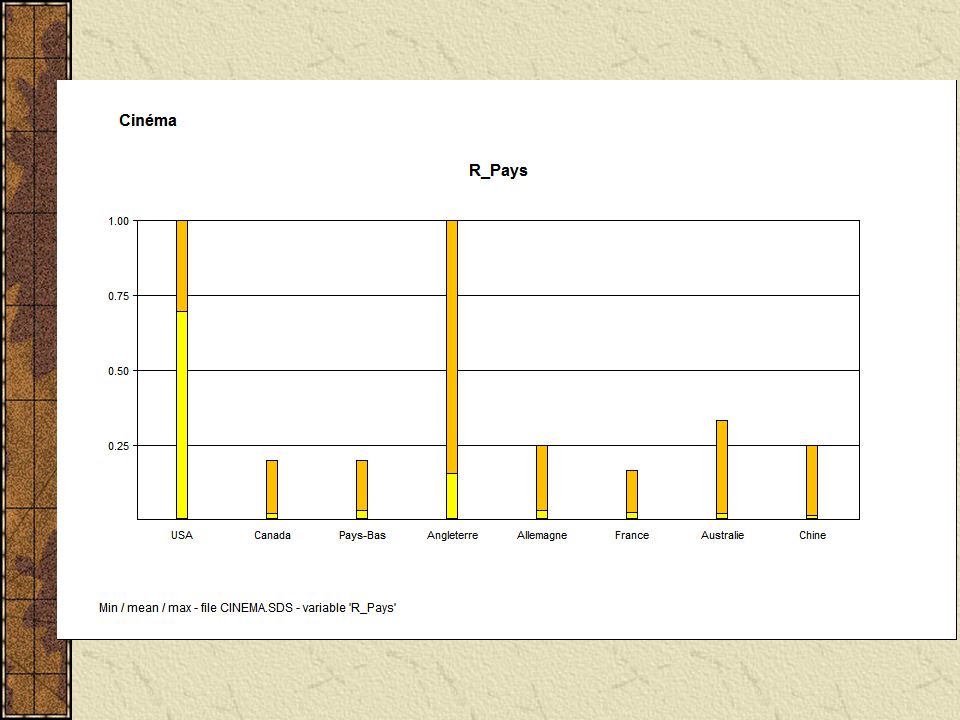
Visualizando os dados importados os "Science-fiction"(10) = [Année = [1968:1999]] ^[Acteur_Principal = {"Arnold Schwarzenneger"(0.3), "Casper Van Dien"(0.1), (...)] ^[Lieu_Tournage = {"Mexique"(0.1), "USA"(0.1), "Tunisie"(0.1), "Californie"(0.4), "Londres"(0.3)}] ^[Continent_Tournage = {"Amérique du Nord"(0.5), "Amérique du Sud"(0.1), "Europe"(0.3), "Afrique"(0.1)}] ^[Nombre_Oscars = [0:6]] ^[Budget(K) = [6400:115000]] ^[Revenu(K) = [55000:922379]] ^[Oscars_Ecart = {"2-3"(0.1), "+ de 6"(0.1), "0-1"(0.8)}] ^[Budget_Ecart(K) = {"50001-100000"(0.5), "100001-150000"(0.1), "0-50000"(0.4)}] ^[Revenu_Ecart(K) = {"400001-500000"(0.1), "100001-200000"(0.3), "200001-300000"(0.1), "50001-100000"(0.2), "+ de 500001"(0.3)}] ^[Nom_Réalisateur = {"Kubrick"(0.1), "Lucas"(0.2), "Emmerich"(0.2),(...)}] ^[R_Région = {"South Shields"(0.1), "Stuttgart"(0.2), "Amsterdam"(0.2), (...)}] ^[R_Pays = {"Canada"(0.2), "USA"(0.3), "Pays-Bas"(0.2), "Angleterre"(0.1), "Allemagne"(0.2)}] ^[R_Age = [46:71]] ^[R_Tranche_Age = {"65-74"(0.1), "45-54"(0.4), "55-64"(0.5)}]
![Visualizando os dados importados os Science-fiction (10) = [Année = [1968:1999]] ^[Acteur_Principal = { Arnold Schwarzenneger (0.3), Casper Van Dien (0.1), (...)] ^[Lieu_Tournage = { Mexique (0.1), USA (0.1), Tunisie (0.1), Californie (0.4), Londres (0.3)}] ^[Continent_Tournage = { Amérique du Nord (0.5), Amérique du Sud (0.1), Europe (0.3), Afrique (0.1)}] ^[Nombre_Oscars = [0:6]] ^[Budget(K) = [6400:115000]] ^[Revenu(K) = [55000:922379]] ^[Oscars_Ecart = { 2-3 (0.1), + de 6 (0.1), 0-1 (0.8)}] ^[Budget_Ecart(K) = { (0.5), (0.1), (0.4)}] ^[Revenu_Ecart(K) = { (0.1), (0.3), (0.1), (0.2), + de (0.3)}] ^[Nom_Réalisateur = { Kubrick (0.1), Lucas (0.2), Emmerich (0.2),(...)}] ^[R_Région = { South Shields (0.1), Stuttgart (0.2), Amsterdam (0.2), (...)}] ^[R_Pays = { Canada (0.2), USA (0.3), Pays-Bas (0.2), Angleterre (0.1), Allemagne (0.2)}] ^[R_Age = [46:71]] ^[R_Tranche_Age = { (0.1), (0.4), (0.5)}]](http://images.slideplayer.com.br/10/2696686/slides/slide_26.jpg "Visualizando os dados importados os Science-fiction (10) = [Année = [1968:1999]] ^[Acteur_Principal = { Arnold Schwarzenneger (0.3), Casper Van Dien (0.1), (...)] ^[Lieu_Tournage = { Mexique (0.1), USA (0.1), Tunisie (0.1), Californie (0.4), Londres (0.3)}] ^[Continent_Tournage = { Amérique du Nord (0.5), Amérique du Sud (0.1), Europe (0.3), Afrique (0.1)}] ^[Nombre_Oscars = [0:6]] ^[Budget(K) = [6400:115000]] ^[Revenu(K) = [55000:922379]] ^[Oscars_Ecart = { 2-3 (0.1), + de 6 (0.1), 0-1 (0.8)}] ^[Budget_Ecart(K) = { (0.5), (0.1), (0.4)}] ^[Revenu_Ecart(K) = { (0.1), (0.3), (0.1), (0.2), + de (0.3)}] ^[Nom_Réalisateur = { Kubrick (0.1), Lucas (0.2), Emmerich (0.2),(...)}] ^[R_Région = { South Shields (0.1), Stuttgart (0.2), Amsterdam (0.2), (...)}] ^[R_Pays = { Canada (0.2), USA (0.3), Pays-Bas (0.2), Angleterre (0.1), Allemagne (0.2)}] ^[R_Age = [46:71]] ^[R_Tranche_Age = { (0.1), (0.4), (0.5)}]")
27
Adicionando Variáveis de Classe Dados já disponíveis sobre as classes Total de oscars Custo médio de um filme Arrecadação média

28
Adicionando Variáveis de Classe

29
Adicionando taxonomias Pays-Bas Amsterdam USA Californie, Chicago, Colorado, Maine, Michigan, New-York, Ohio, Oklahoma, Wisconsin Chine Guangzhou Inglaterra Londres, Ryde, South Shields, Stockton Austrália New South Walles Canada Ontario Allemagne Stuttgart

30
Adicionando taxonomias

31
Visualizando taxonomias

32
Exportando a tabela no formato SODAS

33
Aplicando métodos de análise de dados simbólicos Tabela de dados simbólicos pronta Finalmente podemos passar para a análise

34
Inserindo um método Arrastar o método desejado

35
SOE – Symbolic Object Editor Visualização da tabela de objetos simbólicos Visualização gráfica de cada objeto simbólico 2D 3D

36
SOE

41
STAT – Estatística Elementar para Objetos Simbólicos Freqüências relativas Variáveis intervalares Variáveis modais Capacidades max/min/média Variáveis modais Biplot Variáveis intervalares

46
DIV – Divisive Clustering Método de agrupamento hierárquico Divisivo Usuário informa número de classes desejado

47
PARTITION IN 5 CLUSTERS : -------------------------: Cluster 1 (n=2) : "Western" "Espionnage" Cluster 2 (n=4) : "Science-fiction" "Fantastique" "Comédie fantastique" "Film de guerre" Cluster 3 (n=1) : "Catastrophe" Cluster 4 (n=9) : "Suspense" "Comédie dramatique" "Film historique" "Policier" "Action" "Animation" "Comédie" "Aventure" "Comédie musicale" Cluster 5 (n=1) : "Drame" Explicated inertia : 93.120786 THE CLUSTERING TREE : --------------------- - the number noted at each node indicates the order of the divisions - Ng yes and Nd no +---- Classe 1 (Ng=2) ! !----3- [Budget(K) <= 15800.000000] ! ! ! +---- Classe 4 (Nd=9) ! !----1- [Budget(K) <= 59100.000000] ! ! +---- Classe 2 (Ng=4) ! ! ! !----4- [Budget(K) <= 89700.000000] ! ! ! ! ! +---- Classe 5 (Nd=1) ! ! !----2- [Budget(K) <= 120200.000000] ! +---- Classe 3 (Nd=1)
 <= ] Classe 4 (Nd=9) . ! [Budget(K) <= ] Classe 2 (Ng=4) . ! [Budget(K) <= ] Classe 5 (Nd=1) . ! [Budget(K) <= ] Classe 3 (Nd=1).")
48
TREE – Árvores de decisão Fuzzy ou “Hard” Variável identificadora de classe Nominal Variáveis descritoras Todos os tipos

49
================================== | EDITION OF DECISION TREE | ================================== PARAMETERS : Learning Set : 17 Number of variables : 2 Max. number of nodes: 11 Soft Assign : ( 1 ) FUZZY Criterion coding : ( 3 ) LOG-LIKELIHOOD Min. number of object by node : 5 Min. size of no-majority classes : 2 Min. size of descendant nodes : 1.00 Frequency of test set : 0.00 + --- IF ASSERTION IS TRUE (up) ! --- x [ ASSERTION ] ! + --- IF ASSERTION IS FALSE (down)
 FUZZY Criterion coding : ( 3 ) LOG-LIKELIHOOD Min. number of object by node : 5 Min. size of no-majority classes : 2 Min. size of descendant nodes : 1.00 Frequency of test set : IF ASSERTION IS TRUE (up) x [ ASSERTION ] IF ASSERTION IS FALSE (down).")
50
+---- [ 4 ]Catastrophe ! !----2[ Nombre_Oscars <= 0.000000] ! ! ! ! +---- [ 10 ]Action ! ! ! ! !----5[ Nombre_Oscars <= 1.000000] ! ! ! +---- [ 11 ]Western ! !----1[ Nombre_Oscars <= 1.000000] ! ! +---- [ 12 ]Western ! ! ! !----6[ Nombre_Oscars <= 2.000000] ! ! ! ! ! +---- [ 13 ]Comédie musicale ! ! !----3[ Budget(K) <= 76000.000000] ! +---- [ 7 ]Drame
![+---- [ 4 ]Catastrophe . !----2[ Nombre_Oscars <= ] .](http://images.slideplayer.com.br/10/2696686/slides/slide_50.jpg "[ 10 ]Action . !----5[ Nombre_Oscars <= ] [ 11 ]Western . !----1[ Nombre_Oscars <= ] [ 12 ]Western . !----6[ Nombre_Oscars <= ] [ 13 ]Comédie musicale . !----3[ Budget(K) <= ] [ 7 ]Drame.")
51
SODAS: Resumo

52
Conclusão Análise de dados simbólicos Extensão da análise de dados tradicionais Dados mais complexos Estruturados, probabilísticos, intervalares, multinomiais Análise de dados tradicional Normalmente um caso especial da análise de dados simbólicos SODAS Implementa métodos de análise Existentes para dados tradicionais Árvores de decisão, clustering, estatística descritiva Extendendo-os para dados simbólicos Ferramenta disponível gratuitamente Porém ainda “imatura”.

Apresentações semelhantes












 BREVE HISTÓRICO CARACTERÍSTICAS CONCEITOS DE PROGRAMAÇÃO ORIENTADA A OBJETOS MODELAGEM DE ANÁLISE E DE.>")







